

Apache Spark на сегодняшний день является, пожалуй, наиболее популярной платформой для анализа данных большого объема. Немалый вклад в её популярность вносит и возможность использования из-под Python. При этом все сходятся на том, что в рамках стандартного API производительность кода на Python и Scala/Java сопоставима, но касательно пользовательских функций (User Defined Function, UDF) единой точки зрения нет. Попробуем разобраться в том, насколько увеличиваются накладные расходы в этом случае, на примере задачи проверки решения SNA Hackathon 2019.
В рамках конкурса участники решают задачу сортировки новостной ленты социальной сети и загружают решения в виде набора отсортированных списков. Для проверки качества полученного решения сначала для каждого из загруженных списков вычисляется ROC AUC, а потом выводится среднее значение. Обратите внимание, что вычислить надо не один общий ROC AUC, а персональный для каждого пользователя — готовой конструкции для решения этой задачи нет, поэтому придется писать специализированную функцию. Хороший повод сравнить два подхода на практике.
В качестве платформы для сравнения мы будем использовать облачный контейнер с четырьмя ядрами и Spark, запущенный в локальном режиме, а работать с ним будем посредством Apache Zeppelin. Для сравнения функциональности будем зеркально выполнять один и тот же код в PySpark и Scala Spark. [здесь] Начнем с загрузки данных.
data = sqlContext.read.csv("sna2019/modelCappedSubmit")
trueData = sqlContext.read.csv("sna2019/collabGt")
toValidate = data.withColumnRenamed("_c1", "submit") \
.join(trueData.withColumnRenamed("_c1", "real"), "_c0") \
.withColumnRenamed("_c0", "user") \
.repartition(4).cache()
toValidate.count()val data = sqlContext.read.csv("sna2019/modelCappedSubmit")
val trueData = sqlContext.read.csv("sna2019/collabGt")
val toValidate = data.withColumnRenamed("_c1", "submit")
.join(trueData.withColumnRenamed("_c1", "real"), "_c0")
.withColumnRenamed("_c0", "user")
.repartition(4).cache()
toValidate.count()При использовании стандартного API обращает на себя внимание практически полная идентичность кода, с точностью до ключевого слова val. Время работы существенно не отличается. Теперь попробуем определить нужную нам UDF.
parse = sqlContext.udf.register("parse",
lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType()))
def auc(submit, real):
trueSet = set(real)
scores = [1.0 / (i + 1) for i,x in enumerate(submit)]
labels = [1.0 if x in trueSet else 0.0 for x in submit]
return float(roc_auc_score(labels, scores))
auc_udf = sqlContext.udf.register("auc", auc, DoubleType())val parse = sqlContext.udf.register("parse",
(x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt))
case class AucAccumulator(height: Int, area: Int, negatives: Int)
val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => {
val byLabel = gt.toSet
val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => {
if (byLabel.contains(current)) {
accumulated.copy(height = accumulated.height + 1)
} else {
accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1)
}
})
(accumulator.area).toDouble / (accumulator.negatives * accumulator.height)
})При реализации специфичной функции видно, что Python лаконичнее, в первую очередь из-за возможности использовать встроенную функцию scikit-learn. Однако есть и неприятные моменты — необходимо явно указывать тип возвращаемого значения, тогда как в Scala он определяется автоматически. Выполним операцию:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()Код выглядит практически идентично, но результаты обескураживают.

Реализация на PySpark отрабатывала полторы минуты вместо двух секунд на Scala, то есть Python оказался в 45 раз медленнее. Во время работы top показывает 4 активных процесса Python, работающих на полную, и это говорит о том, что проблемы здесь создает совсем не Global Interpreter Lock. Но! Возможно, проблема именно во внутренней реализации scikit-learn — попробуем воспроизвести код на Python буквально, не обращаясь к стандартным библиотекам.
def auc(submit, real):
trueSet = set(real)
height = 0
area = 0
negatives = 0
for candidate in submit:
if candidate in trueSet:
height = height + 1
else:
area = area + height
negatives = negatives + 1
return float(area) / (negatives * height)
auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType())
toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()
Проведенный эксперимент показывает интересные результаты. С одной стороны, при таком подходе производительность выровнялась, но с другой — пропала лаконичность. Полученные результаты могут говорить о том, что при работе в Python с использованием дополнительных С++ модулей появляются существенные накладные расходы на переход между контекстами. Конечно, подобные накладные расходы есть и при использовании JNI в Java/Scala, однако с примерами деградации в 45 раз при их использовании мне сталкиваться не приходилось.
Для более детального анализа проведем два дополнительных эксперимента: с использованием чистого Python без Spark, чтобы измерить вклад именно от вызова пакета, и с увеличенным размером данных в Spark, чтобы амортизировать накладные расходы и получить более точное сравнение.
def parse(x):
return [int(s.strip()) for s in x[1:-1].split(",")]
def auc(submit, real):
trueSet = set(real)
height = 0
area = 0
negatives = 0
for candidate in submit:
if candidate in trueSet:
height = height + 1
else:
area = area + height
negatives = negatives + 1
return float(area) / (negatives * height)
def sklearn_auc(submit, real):
trueSet = set(real)
scores = [1.0 / (i + 1) for i,x in enumerate(submit)]
labels = [1.0 if x in trueSet else 0.0 for x in submit]
return float(roc_auc_score(labels, scores))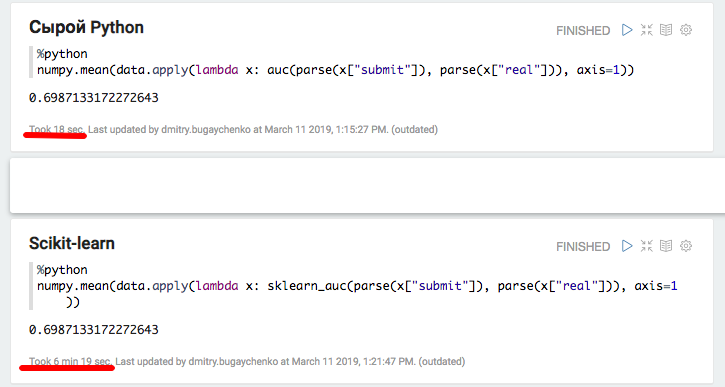
Эксперимент с локальным Python и Pandas подтвердил предположение о существенных накладных расходах при использовании дополнительных пакетов — при использовании scikit-learn скорость уменьшается более чем в 20 раз. Однако, 20 это не 45 — попробуем «раздуть» данные и снова сравнить производительность Spark.
k4 = toValidate.union(toValidate)
k8 = k4.union(k4)
m1 = k8.union(k8)
m2 = m1.union(m1)
m4 = m2.union(m2).repartition(4).cache()
m4.count()
Новое сравнение показывает преимущество по скорости Scala-реализации над Python в 7-8 раз — 7 секунд против 55. Напоследок попробуем «самое быстрое, что есть в Python» — numpy для подсчета суммы массива:
import numpy
numpy_sum = sqlContext.udf.register("numpy_sum",
lambda x: float(numpy.sum(x)), DoubleType())val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)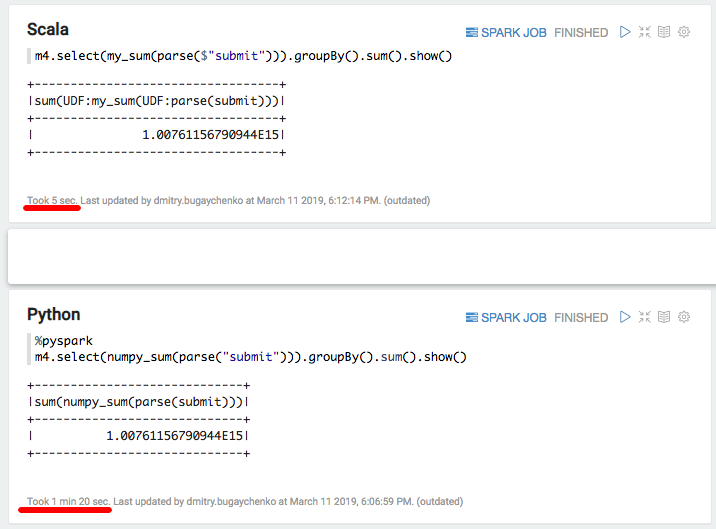
Опять существенное замедление — 5 секунд Scala против 80 секунда Python. Подводя итоги, можно сделать следующие выводы:
- Пока PySpark действует в рамках стандартного API, по скорости он действительно может быть сравним со Scala.
- При появлении специфичной логики в виде User Defined Functions производительность PySpark заметно снижается. При достаточном объеме информации, когда время обработки блока данных превышает несколько секунд, Python-реализация работает в 5-10 медленнее из-за необходимости перемещать данные между процессами и тратить ресурсы на интерпретацию Python.
- Если же появляется использование дополнительных функций, реализованных в C++ модулях, то возникают дополнительные расходы на вызов, и разница между Python и Scala увеличивается до 10-50 раз.
В итоге, несмотря на всю прелесть Python, применение его в связке со Spark не всегда выглядит оправданным. Если данных не так много, чтобы накладные расходы на Python стали значимыми, то стоит подумать, а нужен ли здесь Spark? Если данных много, но обработка происходит в рамках стандартного Spark SQL API, то нужен ли здесь Python?
Если же данных много и часто приходится сталкиваться с выходящими за пределы SQL API задачами, то для выполнения того же объема работ при использовании PySpark придется увеличивать кластер в разы. Например, для Одноклассников стоимость капитальных расходов на кластер Spark увеличилась бы на многие сотни миллионов рублей. А если попробовать воспользоваться расширенными возможностями библиотек экосистемы Python, то есть риск замедления не просто в разы, а на порядок.
Некоторое ускорение можно получить, используя относительно новую функциональность векторизованных функций. В этом случае на вход UDF подается не отдельно взятый ряд, а пакет из нескольких рядов в виде Pandas Dataframe. Однако разработка этой функциональности еще не завершена, и даже в этом случае разница будет значительной.
Альтернативой может быть поддержание обширной команды data engineer-ов, способных оперативно закрывать потребности data scientist-ов дополнительными функциями. Или всё-таки погрузиться в мир Scala, благо это не так сложно: многие необходимые инструменты уже существуют, появляются обучающие программы, выходящие за рамки PySpark.
