

Компания «УРУС» попробовала Kubernetes в разных видах: самостоятельный деплоймент на bare metal, в Google Cloud, а затем перенесла свою платформу в облако Mail.ru Cloud Solutions (MCS). Как выбирали нового облачного провайдера и как удалось мигрировать к нему за рекордные два часа рассказывает Игорь Шишкин (t3ran), старший системный администратор «УРУС».
Чем занимается «УРУС»
Есть много способов улучшить качество городской среды, и один из них — сделать ее экологически безопасной. Как раз над этим работают в компании «УРУС — Умные цифровые сервисы». Здесь внедряют решения, которые помогают предприятиям контролировать важные экологические показатели и уменьшать негативное влияние на окружающую среду. Датчики собирают данные о составе воздуха, уровне шума и другие параметры, а затем отправляют их в единую платформу «УРУС — Экомон» для анализа и составления рекомендаций.
Как устроена работа «УРУС» изнутри
Типичный клиент «УРУСа» — компания, которая располагается в жилой зоне или рядом с ней. Это может быть завод, порт, железнодорожное депо или любой другой объект. Если наш клиент уже получал предупреждение, был оштрафован за загрязнение окружающей среды или сам хочет издавать меньше шумов, снизить количество вредных выбросов, он приходит к нам, и мы уже предлагаем ему готовое решение по экологическом мониторингу.
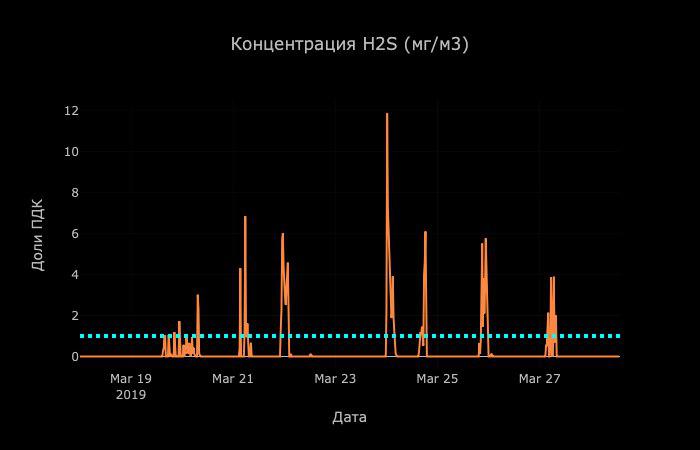
На графике мониторинга концентрации H2S видны регулярные ночные выбросы расположенного рядом предприятия
Устройства, которые мы используем в «УРУС», содержат в себе несколько сенсоров, которые собирают информацию о содержании определенных газов, уровне шума и другие данные для оценки экологической обстановки. Точное количество сенсоров всегда определяется конкретной задачей.

В зависимости от специфики измерений, устройства с датчиками могут располагаться на стенах зданий, столбах и в других произвольных местах. Каждое такое устройство собирает информацию, агрегирует ее и отправляет на шлюз приема данных. Там мы сохраняем данные на длительное хранение и предообратываем для последующего анализа. Простейший пример того, что мы получаем на выходе после анализа — это индекс качества воздуха, он же AQI.
Параллельно на нашей платформе работает много других сервисов, но в основном они носят обслуживающий характер. Например, сервис нотификации отправляет клиентам уведомления, если какой-то из отслеживаемых параметров (допустим, содержание СО2) превысил допустимое значение.
Как мы храним данные. История с Kubernetes на bare metal
В проекте экомониторинга «УРУС» есть несколько хранилищ данных. В одном мы держим «сырые» данные — то, что мы получили непосредственно от самих устройств. Это хранилище представляет собой «магнитную» ленту, как на старых кассетах, с историей всех показателей. Второй тип хранилища используется для предобработанных данных — данных с устройств, обогащенных метаданными о связях сенсоров и показания самих устройств, принадлежности к организациям, местам расположения и т. д. Эта информация позволяет в динамике оценить, как менялся за определенный промежуток времени тот или иной показатель. Хранилище «сырых» данных мы используем в том числе как бэкап и для восстановления предобработанных данных, если такая необходимость возникнет.
Когда мы несколько лет назад искали, как решить проблему с хранением, у нас было два варианта для выбора платформы: Kubernetes и OpenStack. Но так как последний выглядит довольно монструозно (просто посмотрите на его архитектуру, чтобы убедиться в этом), то мы остановились именно на Kubernetes’е. Еще одним аргументом в его пользу стало относительно простое программное управление, возможность более гибко нарезать даже железные ноды по ресурсам.
Параллельно с освоением самого Kubernetes мы изучали и способы хранения данных, пока мы все наши хранилища держали в Kubernetes на своем железе, мы получили отличную экспертизу. Все, что у нас тогда было, жило именно на Kubernetes’е: statefull-хранилище, система мониторинга, СI/CD. Kubernetes стал для нас all-in-one платформой.
Но нам хотелось работать с Kubernetes’ом как с сервисом, а не заниматься его поддержкой и разработкой. Плюс нам не нравилось то, во сколько нам обходится его содержание на bare metal, а разработка требовалась нам постоянно! Например, одной из первых задач стало вписать Ingress-контроллеры Kubernetes в сетевую инфраструктуру нашей организации. Это громоздкая задача, особенно если представить, что на тот момент ничего не было готово для программного управления ресурсами вроде DNS-записей или выделения IP-адресов. Позже мы начали экспериментировать с внешним хранилищем данных. До имплементации PVC-контроллера так и не добрались, но уже тогда стало понятно, что это большой фронт работ, под который нужно выделять отдельных специалистов.
Переход на Google Cloud Platform — временное решение
Мы поняли, что так дальше продолжаться не может, и перенесли наши данные с bare metal на Google Cloud Platform. На самом деле, тогда для российской компании было не так много интересных вариантов: кроме Google Cloud Platform аналогичный сервис предлагал только Amazon, но мы все-таки остановились на решении от Google. Тогда оно показалось нам экономически более выгодным, более близким к Upstream, не говоря уже о том, что Google сам по себе — это своеобразный PoC Kubernetes в Production.
Первая серьезная проблема появилась на горизонте параллельно с тем, как росла наша клиентская база. Когда у нас появилась необходимость хранить персональные данные, мы оказались перед выбором: или работаем с Google и нарушаем российские законы, или ищем альтернативу в РФ. Выбор, в целом, был предсказуем. :)
Каким мы видели идеальный облачный сервис
К началу поисков мы уже знали, что хотим получить от будущего облачного провайдера. Какой сервис мы искали:
- Быстрый и гибкий. Такой, чтобы мы в любой момент оперативно могли добавить новую ноду или что-то развернуть.
- Недорогой. Нас очень волновал финансовый вопрос, так как мы были ограничены в ресурсах. Мы уже знали, что хотим работать с Kubernetes, и теперь стояла задача минимизировать его стоимость, чтобы увеличить или хотя бы сохранить эффективность использования этого решения.
- Автоматизированный. Мы планировали работать с сервисом через API, без менеджеров и телефонных звонков или ситуаций, когда нужно вручную поднимать несколько десятков нод в авральном режиме. Так как большинство процессов у нас автоматизированы, того же мы ждали от облачного сервиса.
- С серверами в РФ. Конечно, мы планировали соблюдать российское законодательство и тот самый 152-ФЗ.
В то время провайдеров Kubernetes по модели aaS в России было мало, при этом, выбирая провайдера, нам было важно не поступиться нашими приоритетами. Команда Mail.ru Cloud Solutions, с которой мы начали работать и сотрудничаем до сих пор, предоставила нам полностью автоматизированный сервис, с поддержкой API и удобной панелью управления, в которой есть Horizon — с ним мы могли быстро поднять произвольное количество нод.
Как нам удалось мигрировать в MCS за два часа
В подобных переездах многие компании сталкиваются с трудностями и неудачами, но в нашем случае их не было. Нам повезло: так как мы до начала миграции уже работали на Kubernetes’е, мы просто поправили три файла и запустили свои сервисы на новой облачной платформе, в MCS. Напомню, что к тому времени мы окончательно ушли с bare metal и жили на Google Cloud Platform. Потому сам переезд занял не больше двух часов, плюс еще немного времени (около часа) ушло на копирование данных с наших устройств. Тогда мы уже использовали Spinnaker (мультиоблачный CD-сервис для обеспечения Continous Delivery). Его мы тоже оперативно добавили в новый кластер и продолжили работать в обычном режиме.
Благодаря автоматизации процессов разработки и CI/CD Kubernetes’ом в «УРУС» занимается один специалист (и это я). На каком-то этапе со мной работал еще один системный администратор, но потом оказалось, что всю основную рутину мы уже автоматизировали а со стороны нашего основного продукта задач все больше и имеет смысл направить ресурсы на это.
Мы получили от облачного провайдера то, что ожидали, так как начали сотрудничество без иллюзий. Если и были какие-то инциденты, то в основном технические и такие, которые легко объяснить относительной свежестью сервиса. Главное, что команда MCS оперативно устраняет недочеты и быстро реагирует на вопросы в мессенджерах.
Если сравнивать опыт работы с Google Cloud Platform, то в их случае я даже не знал, где находится кнопка обратной связи, так как в ней просто не было необходимости. А если какие-то проблемы и случались, Google сам рассылал уведомления в одностороннем порядке. Но в случае с MCS большим плюсом я считаю то, что они находятся максимально близко к российским клиентам — и территориально, и ментально.
Как мы видим работу с облаками в будущем
Сейчас наша работа тесно завязана на Kubernetes’е, и он полностью устраивает нас с точки зрения инфраструктурных задач. Поэтому мы не планируем куда-то с него мигрировать, хотя постоянно вводим новые практики и сервисы для упрощения рутинных задач и автоматизации новых, повышения стабильности и надежности сервисов… Сейчас запускаем сервис Chaos Monkey (а конкретно мы используем chaoskube, но концепции это не меняет :), который изначально был создан в Netflix. Chaos Monkey делает одну простую вещь: в произвольное время удаляет произвольный под в Kubernetes’е. Это нужно, чтобы наш сервис нормально жил с количеством инстансов n–1, так мы приучаем себя быть готовыми к любым неполадкам.
Сейчас я вижу использование сторонних решений — тех же облачных платформ — как единственно правильное для молодых компаний. Обычно в начале пути они ограничены в ресурсах, как кадровых, так и финансовых, а строить и содержать собственное облако или дата-центр слишком дорого и трудозатратно. Cloud-провайдеры позволяют минимизировать эти затраты, у них можно быстро получить ресурсы, необходимые для работы сервисов здесь и сейчас, причем оплачивать эти ресурсы по факту. Что касается компании «УРУС», то мы пока останемся верны Kubernetes’у в облаке. Но кто знает, возможно, нам придется расширяться географически, или внедрять решения на базе какого-то специфического оборудования. Или, может, количество потребляемых ресурсов оправдает собственный Kubernetes на bare-metal, как в старые добрые времена. :)
Что мы вынесли из опыта работы с облачными сервисами
Мы начали использовать Kubernetes на bare metal, и даже там он был по-своему хорош. Но сильные его стороны удалось раскрыть именно в качестве aaS-компонента в облаке. Если поставить цель и все максимально автоматизировать, то получится избежать vendor lock-in и переезд между облачными провайдерами займет пару часов, а нервные клетки останутся с нами. Другим компаниям мы можем посоветовать: хотите запустить свой (облачный) сервис, имея ограниченные ресурсы и максимальный velocity для разработки — начинайте прямо сейчас с аренды облачных ресурсов, а свой дата-центр стройте после того, как о вас напишет Forbes.
В нашем телеграм-канале — новости об этом и других сервисах на облачной платформе Mail.ru Cloud Solutions.
Что еще почитать:
1. Как CarPrice стал самой цифровой компанией российского авторынка.
2. Как собрать гибридное облако с помощью Kubernetes, которое может заменить DBaaS.
