

Привет, я Юрий Буйлов, занимаюсь разработкой в CarPrice, а также внедряю практики DevOps, микросервисы и Kubernetes. Хочу рассказать про Kubernetes в духе пиратства — только не про управление большим красивым кораблем на парусах, а, скорее, про флот маленьких неприглядных рыбацких лодочек, местами ржавых, но очень быстрых, шустрых и опасных.
Будет интересно тем, кто разрабатывает или переводит инфраструктуру на микросервисы, внедряет DevOps поверх Kubernetes и всячески идет в cloud native. Расскажу про наш путь, в конце статьи поделюсь нашими наработками окружения для микросервисов — дам ссылку на шаблон, который будет удобен для разработчиков и тестировщиков.
Эта статья — по видео выступления на конференции @Kubernetes Conference by Mail.ru Cloud Solutions, если не хотите читать, можно посмотреть.
Как мы жили до Kubernetes: dev-серверы, bare metal и Ansible
Мы жили и живем в режиме постоянных изменений и экспериментов: АВ-тесты, проверка различных гипотез. Запускаем новые сервисы, потом, если что-то не работает, выпиливаем.
Когда-то у нас был монолит на РНР, который приносил много боли и страдания. Чтобы обеспечить приемлемый time-to-market, мы пошли типичным путем — стали пилить этот монолит на микросервисы. В итоге получилось, что большой монолит превратился во много маленьких монолитов. Это нормально, так происходит у всех, кто сталкивался с подобной задачей.
Затем мы начали пробовать другие технологии, в частности у нас появился Golang, он в дальнейшем стал основным языком разработки. Встали вопросы: как это все разрабатывать, тестировать и развертывать? Ответ был очевиден — нужен dev-сервер. У каждого разработчика должен быть dev-сервер, куда он сможет подсоединяться, чтобы писать там качественный и высокопроизводительный код.
В итоге ребята написали dev-сервер. Получился веб-интерфейс, который управлял docker-compose на серверах. Там же был контейнер c Source Code, который монтировалcя в docker-compose. Разработчик мог подключиться по SSH и программировать. Тестировщики тоже там работали, все прекрасно функционировало.

Но с ростом количества сервисов работать стало невозможно. Настал момент, когда надо было что-то деплоить, не распаковывать же контейнеры. Мы взяли bare metal, накатили туда Docker. Потом взяли Ansible, написали несколько ролей. Каждая роль — это сервис, где лежал docker-compose, который «приезжал» на одну из тачек.

Так мы жили: в nginx прописывали руками upstream, говорили, на какой порт надо идти, где этот сервис живет. Был даже yaml-файл, где были перечислены все порты, чтобы приложения за них не конкурировали.
Как мы пришли к Kubernetes и построили на нем инфраструктуру
Очевидно, что так жить нельзя, нужна оркестрация. Мы это поняли в 2017-2018 годах, тогда было непонятно, где эту оркестрацию взять. Kubernetes только начинался, были HashiCorp Nomad, Rancher, OpenShift. Мы попробовали Nomad, он был неплох, но нам не хотелось переписывать docker-compose на конфиги Nomad.
Про Kubernetes мы сразу поняли, что зарубежные коллеги пытались его делать, у них не всегда получалось. И у нас не было бородатых админов, которые могли нам сделать кластер. Стали думать, как это реализовать. Уже тогда Kubernetes был, например, в Амазон, но мы помним блокировки, после которых экстренно переезжали. Поэтому такой вариант сразу отбросили, тем более там дорогой трафик.
А потом Kubernetes появился на платформе Mail.ru Cloud Solutions в виде сервиса Mail.ru Cloud Containers. Мы уже перенесли туда с Амазон свое S3-хранилище, решили попробовать и K8s. Развернули в облаке кластер, все заработало.
Для пробы решили задеплоить там какой-нибудь stateless-сервис. Взяли API для мобильных приложений, развернули — работает. Направили туда 50% трафика — работает. Да, что-то падало периодически, но ребята чинили, всё было нормально. В итоге перевели всю инфраструктуру, сейчас она строится вокруг Kubernetes, в основном — это dev- и stage-серверы.

У каждого разработчика свой Minikube в VMware, с которым он работает. Новые проекты запускаем в Kubernetes в облаке MCS, там же разворачиваем Managed MySQL, который сразу прилетает со всеми слейвами, репликациями и бэкапами в S3.
У нас еще осталось legacy на bare metal, в том числе докер-кластер под управлением Ansible, но когда-нибудь мы с этим разберемся.
Как жить с зоопарком технологий и не страдать
Зоопарк технологий теперь не так страшен, как это было, скажем, в 2011 году. Это даже нормально, если ты можешь брать специализированные инструменты и технологии из разных мест и использовать, как хочется. К примеру, мы используем для каких-то вещей Golang, но Data Scientist работают на Python, их не заставишь писать на GO или РНР.
В целом у нас два правила:
- dockerize: обязательно должны быть контейнеры;
- observability: эти контейнеры должны быть наблюдаемы.
Если продолжить аналогию с зоопарком: есть клетки, и не так важно, кто в этих клетках сидит. Главное, чтобы вода и еда поступали регулярно, автоматически и единообразно, а «продукты жизнедеятельности» сервисов, то есть логи, куда-то централизованно отгружались.
Для observability у нас стандартный стек: каждое приложение пишет логи в stdout, откуда централизованно все переносится в EFK. То есть разработчик может прийти и посмотреть логи в Kibana. App-метрики мы скидываем в Prometheus, дашборды и alerts стандартно в Grafana. Jaeger — это Opentracing-история, которая показывает, кто к какому сервису обращается, если мы не знаем или не хотим с этим разбираться другими способами.

Как со всем этим разрабатывать и тестировать
Допустим, к нам приходит новый разработчик, он видит 100 сервисов и 100 репозиториев. У него сразу возникают вопросы. Как развернуть эти 100 сервисов, а как настроить? Где базы данных? Какие есть учетные записи? И таких вопросов много. Из-за этого выход нового разработчика занимал неприличное время, он мог неделю сидеть и все настраивать.
В результате мы выстрадали 1-Click среду разработки. У каждого разработчика есть свой Minikube с условно бесконечными ядрами и памятью, развернутый в облаке VMware. Плюс база данных — она ежедневно приходит с продакшена, обфусцируется, сжимается и кладется на ZFS. Это личная разработка нашего админа. Мы долго занимались cost cutting, нам нужно было дать всем разработчикам базу и при этом не разориться.
В ZFS есть снапшоты, разработчик по API может за две секунды накатить базу прямо с продакшена. С автотестами та же история: запускаем по API, и все работает.

Так сегодня выглядит development flow:

Разработчик счастлив, DevOps и админы счастливы, потому что все процессы единообразны, повторяемы и унифицированы. Но есть одно но.
Многоуровневая система слоев
Как говорил Линус Торвальдс: «Talk is cheap. Show me the code». Итак, мы используем многоуровневую систему слоев. Есть банальные слои: dev, stage, prod, которые приходят на ум всем, кто собирается делать CI/CD.
Но есть еще разработчики, им нужны какие-то свои домены, какие-то user specific-истории, поэтому у нас есть слой users values. Но и этого мало — нужно же еще тестировать. Допустим, мы сделали ветку, может быть, несколько сервисов, и это нужно передать тестировщику так, чтобы у него оно повторилось. Для этого у нас есть слой со значениями для тасков, то есть tasks values.
Еще один, немного холиварный момент — мы не используем Tiller, остановились на Helm, но используем его по факту как шаблонизатор. То есть используем только helm-template, он на выходе дает yaml-файл, который можно отнести в Minikube или кластер, и больше ничего не надо.

Как устроен репозиторий K8s-helm
Как я говорил, у нас есть очевидные слои dev, prod и stage, там лежит от каждого сервиса по yaml-файлу, когда пилим новый сервис, добавляем файл.
Дополнительно есть папочка dev.server с самым интересным. Там лежат bash-скрипты, которые помогают, например, создать нового пользователя: не создавать 100 сервисов руками и не заполнять yaml-файлы, а просто запустить в одну команду. Именно там генерируются все эти yaml-файлы.
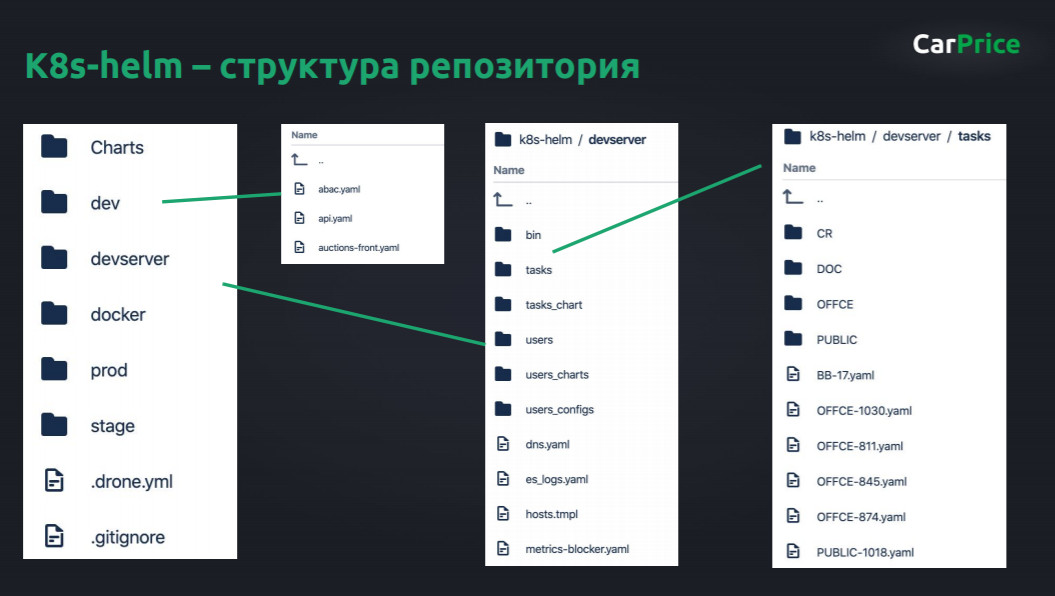
В этой же папке есть подпапка tasks. Если нам нужно сделать какие-то специфичные values для нашего развертывания, мы просто создаем внутри папки с номерами задач, коммитим ветку. Дальше говорим тестировщику: «В репозитории лежит такая-то ветка, бери и запускай». Он запускает, дергает команду, которая лежит в папочке bin, и всё работает — не нужно настраивать руками. Чудо DevOps — инфраструктура как код.
В итоге процесс сводится к трем командам:
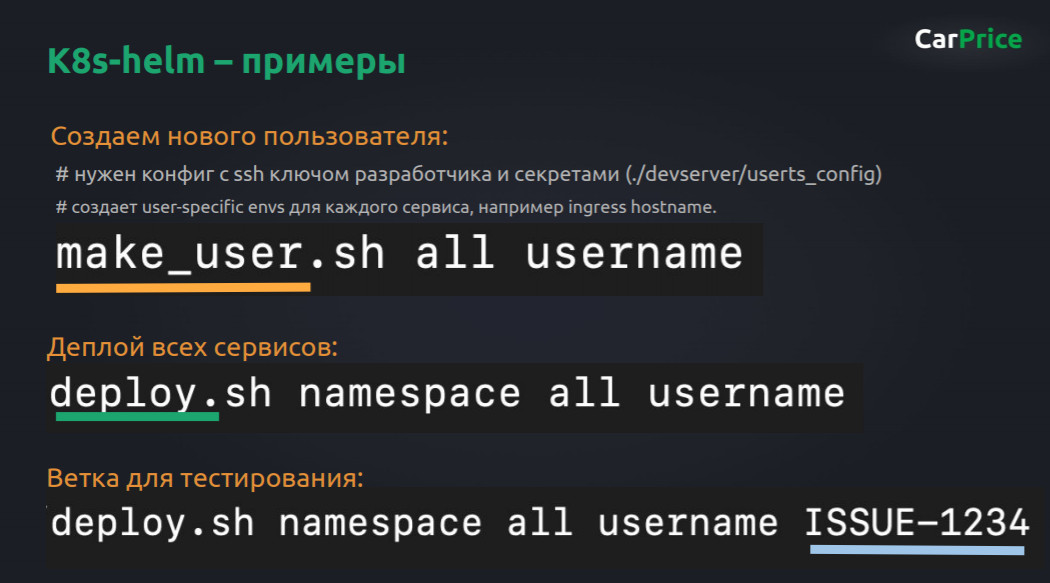
Когда приходит новый разработчик, ему дают Minikube, папку-архив с сертификатами и домен. В общем, ему нужен только kubectl и Helm. Он клонирует репозиторий к себе, показывает kubectl путь до своего конфига, запускает команду make_user со своим именем. И для всех сервисов ему создаются копии. Причем они не просто создаются — там есть база данных, которую ему выдали, разработчик прописал для нее credentials, и все эти credentials разъезжаются по другим сервисам.
Пользователь создан, как теперь все задеплоить? Тут тоже ничего сложного — запускаем deploy.sh со его именем, и всё приезжает разработчику в дефолтный namespace в его Minikube, всё сразу доступно на его домене.
Если разработчик что-то напрограммировал, он берет issue ID и отдает тестировщику. Тестировщик копирует эту ветку, запускает деплой, и в его кластере появляется окружение с новой фичей.
Сборка K8s-helm
Сам репозиторий дополнительно собирается и встроен в CI/CD-процессы. Здесь ничего особенного — просто kubectl с сертификатами и Helm.
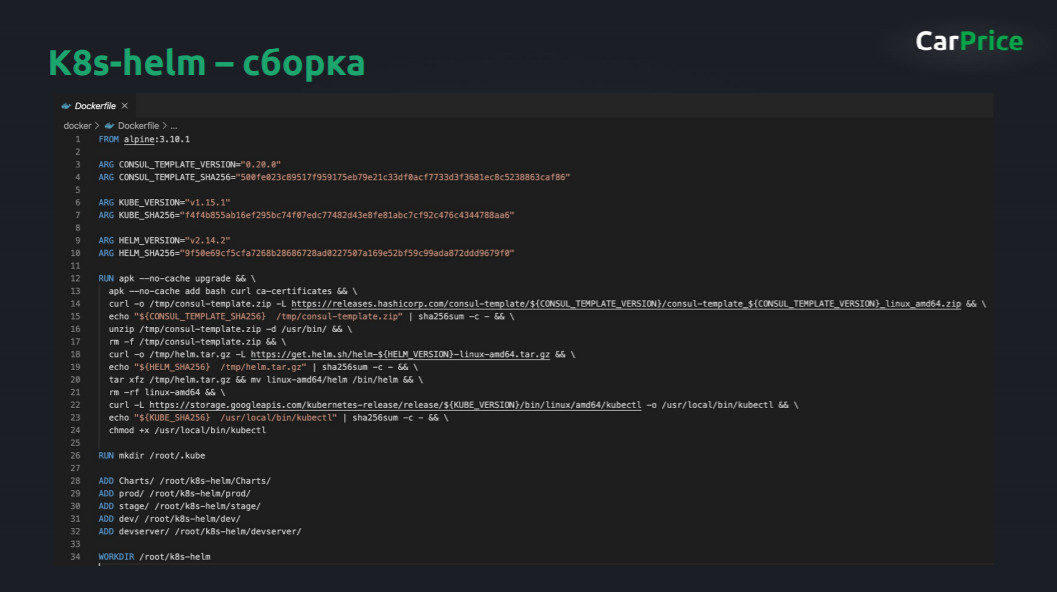
В проекте это выглядит следующим образом:

Предположим, вы задеплоили, и есть стадия, когда нужно сначала задеплоить stage, а потом прогнать там тесты с помощью Jenkins. Из репозитория у вас есть образ, собранный с Helm. Мы запускаем команду deploy namespace service_stage run — и все взлетает.
Потом идет CI, здесь .drone.yml, но примерно то же самое будет в GitLab или где-то еще.
Дальше запускается Jenkins, который прогоняет тесты на stage. Если все окей, то запускается почти такой же деплой, но уже на прод. То есть этот механизм не только облегчает жизнь разработчикам и тестировщикам, но и используется для доставки фич на прод.
Мы любим open source, хотим вкладываться в развитие DevOps, поэтому сделали шаблон, который вы можете использовать, и залили его на гитхаб. Там есть всё, о чем я рассказал: можно брать, смотреть, тестировать и применять. Пригодится всем, кто внедряет микросервисы, или страдает от того, что команда внедряет микросервисы, или хочет строить DevOps-процессы вокруг этого.
Другие наши статьи по теме:
- 24 полезных инструментов Kubernetes: развертывание и управление.
- Посекундный биллинг, маркетплейс и песочницы для Big Data: что могут тестовые среды в облаке.
- Как Kubernetes помог в 7 раз сократить время на разработку
Этот доклад впервые прозвучал на @Kubernetes Conference by Mail.ru Cloud Solutions. Смотрите видео других выступлений и подписывайтесь на анонсы мероприятий в Telegram Вокруг Kubernetes в Mail.ru Group.
