

Если вы работаете с Kubernetes, то, вероятно, kubectl — одна из самых используемых вами утилит. А всякий раз, когда вы тратите много времени на работу с определенным инструментом, стоит хорошо его изучить и научиться эффективно использовать.
Команда Kubernetes aaS от Mail.ru перевела статью Даниэля Вейбеля, в которой вы найдете советы и приемы для эффективной работы с kubectl. Также она поможет глубже понять работу Kubernetes.
По словам автора, цель статьи — сделать вашу ежедневную работу с Kubernetes не только более эффективной, но и более приятной!
Введение: что такое kubectl
Перед тем как учиться использовать kubectl более эффективно, нужно получить базовое понимание того, что это такое и как работает.
С точки зрения пользователя, kubectl — панель управления, которая позволяет выполнять операции Kubernetes.
С технической точки зрения, kubectl — клиент Kubernetes API.
Kubernetes API — это HTTP REST API. Этот API — настоящий пользовательский интерфейс Kubernetes, через который он полностью контролируется. Это означает, что каждая операция Kubernetes представляется как конечная точка API и может быть выполнена HTTP-запросом к этой конечной точке.
Следовательно, основная задача kubectl — выполнять HTTP-запросы к API Kubernetes:

Kubernetes — полностью ресурсно-ориентированная система. Это означает, что он поддерживает внутреннее состояние ресурсов, и все операции Kubernetes являются операциями CRUD.
Вы полностью контролируете Kubernetes, управляя этими ресурсами, и Kubernetes выясняет, что делать, основываясь на текущем состоянии ресурсов. По этой причине ссылка на API Kubernetes организована в виде списка типов ресурсов со связанными с ними операциями.
Давайте рассмотрим пример.
Предположим, вы хотите создать ресурс ReplicaSet. Чтобы это сделать, вы описываете ReplicaSet в файле по имени
replicaset.yaml, затем запускаете команду:$ kubectl create -f replicaset.yamlВ результате будет создан ресурс ReplicaSet. Но что происходит за кулисами?
В Kubernetes есть операция создания ReplicaSet. Как и любая другая операция, она предоставляется в качестве конечной точки API. Конкретная конечная точка API для этой операции выглядит так:
POST /apis/apps/v1/namespaces/{namespace}/replicasetsКонечные точки API всех операций Kubernetes можно найти в справочнике API (включая указанную выше конечную точку). Чтобы сделать фактический запрос к конечной точке, надо предварительно добавить URL-адрес сервера API к путям конечной точки, которые перечислены в справочнике по API.
Следовательно, когда вы выполняете указанную выше команду, kubectl отправляет HTTP-запрос POST к вышеуказанной конечной точке API. Определение ReplicaSet, которое вы указали в файле
replicaset.yaml, передается в теле запроса.Именно так работает kubectl для всех команд, которые взаимодействуют с кластером Kubernetes. Во всех этих случаях kubectl просто отправляет HTTP-запросы к соответствующим конечным точкам API Kubernetes.
Обратите внимание, что можно полностью управлять Kubernetes с помощью такой утилиты как
curl, вручную отправляя HTTP-запросы в API Kubernetes. Kubectl просто упрощает использование API Kubernetes.Это основы того, что такое kubectl и как он работает. Но есть еще кое-что об API Kubernetes, что должен знать каждый пользователь kubectl. Давайте кратко окунемся во внутренний мир Kubernetes.
Внутренний мир Kubernetes
Kubernetes состоит из набора независимых компонентов, которые выполняются как отдельные процессы на узлах кластера. Некоторые компоненты работают на главных узлах, другие — на рабочих узлах, каждый компонент выполняет свою специальную задачу.
Вот наиболее важные компоненты на главных нодах:
- Хранилище — хранит определения ресурсов (обычно это etcd).
- API сервер — предоставляет API и управляет хранилищем.
- Диспетчер контроллеров — гарантирует, что статусы ресурсов соответствуют спецификациям.
- Планировщик — планирует поды на рабочих узлах.
И вот один самый важный компонент на рабочих нодах:
- Kubelet — управляет запуском контейнеров на рабочей ноде.
Чтобы понять, как эти компоненты работают вместе, рассмотрим пример.
Предположим, вы только что выполнили
kubectl create -f replicaset.yaml, после чего kubectl сделал HTTP-запрос POST к конечной точке API-интерфейса ReplicaSet (передавая определение ресурса ReplicaSet).Что происходит в кластере?
- После выполнения
kubectl create -f replicaset.yamlAPI-сервер сохраняет определение вашего ресурса ReplicaSet в хранилище:

- Далее запускается контроллер ReplicaSet в диспетчере контроллеров, который обслуживает создание, изменение и удаление ресурсов ReplicaSet:
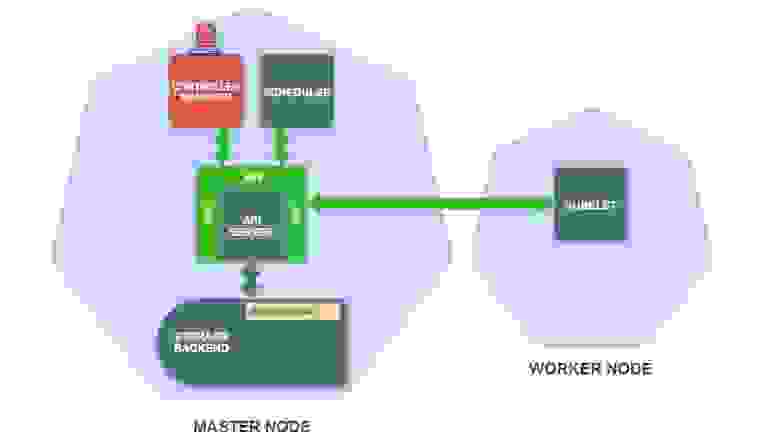
- Контроллер ReplicaSet создает определение пода для каждой реплики ReplicaSet (в соответствии с шаблоном пода в определении ReplicaSet) и сохраняет их в хранилище:

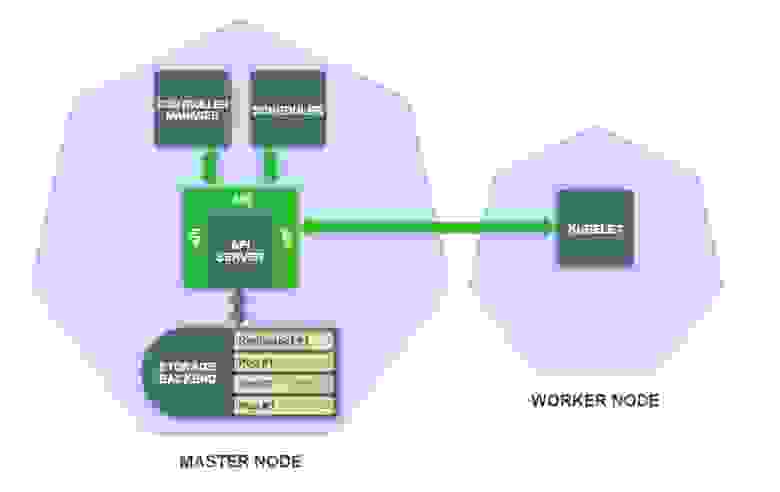
- Запускается планировщик, отслеживающий поды, которые еще не были назначены ни одной рабочей ноде:

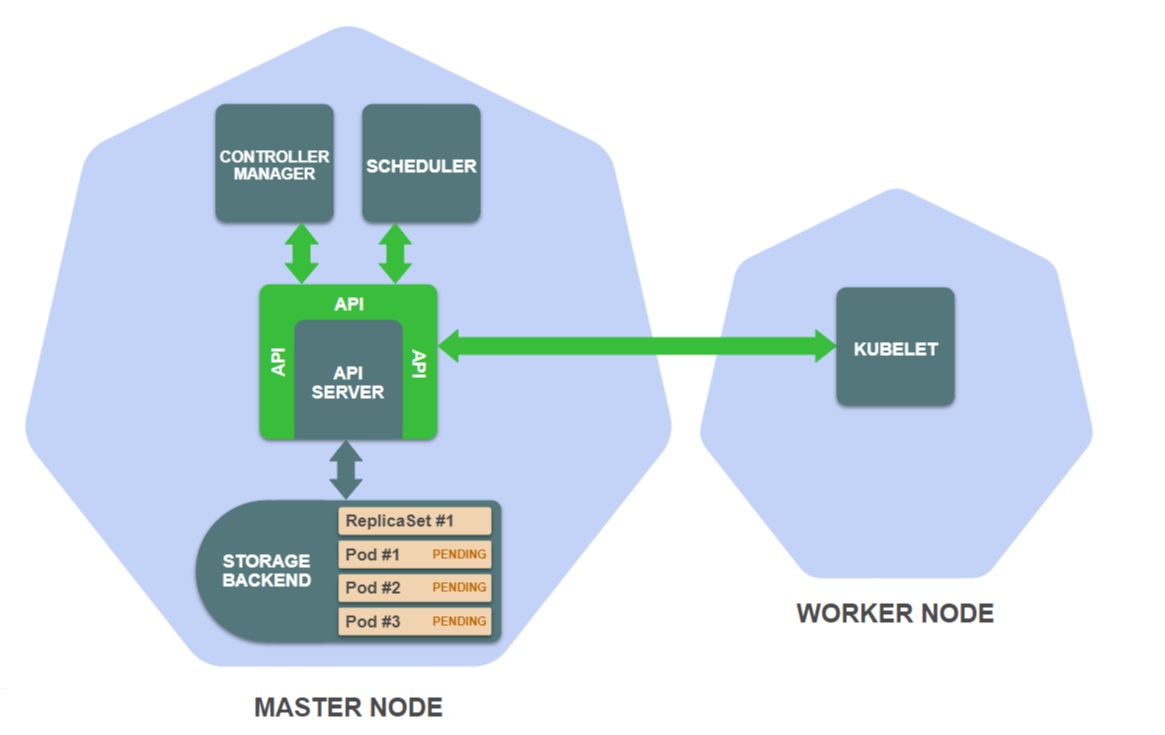
- Планировщик выбирает подходящую рабочую ноду для каждого пода и добавляет эту информацию в определение пода в хранилище:
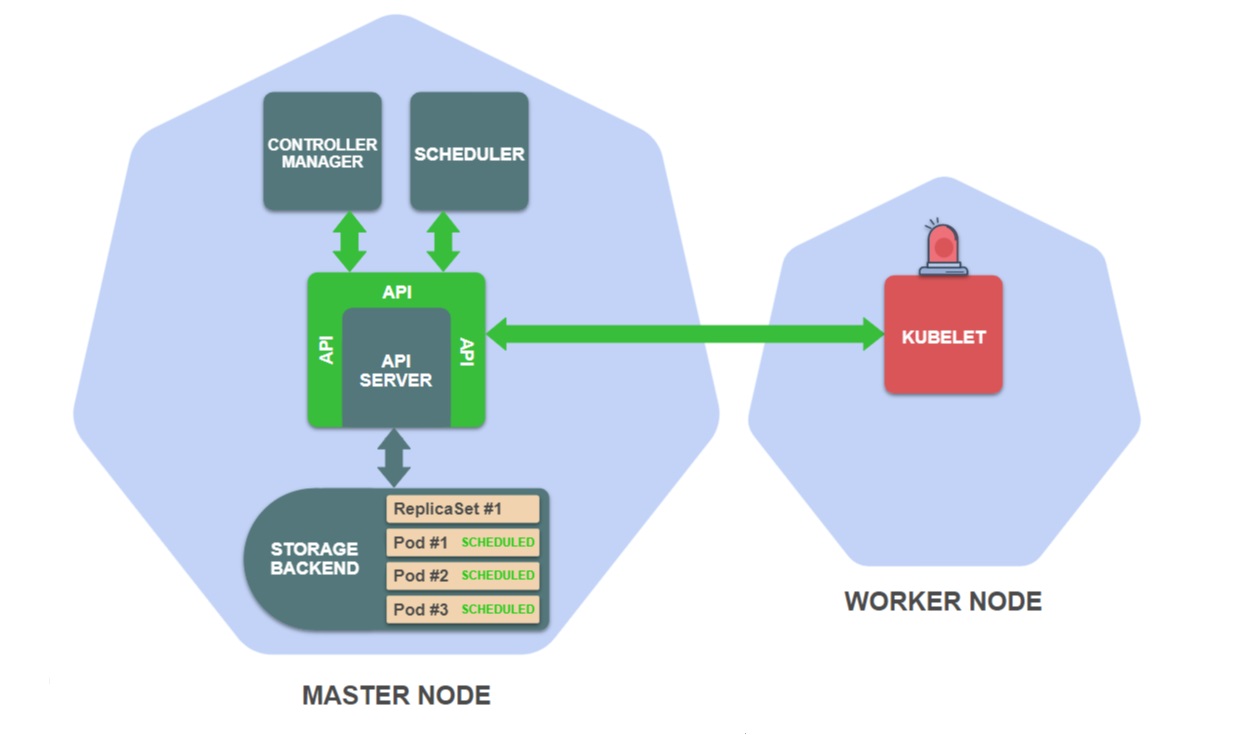
- На рабочей ноде, которой назначен под, запускается Kubelet, он отслеживает поды, назначенные этой ноде:

- Kubelet считывает определение пода из хранилища и дает команды среде выполнения контейнеров, например Docker, на запуск контейнеров на ноде:





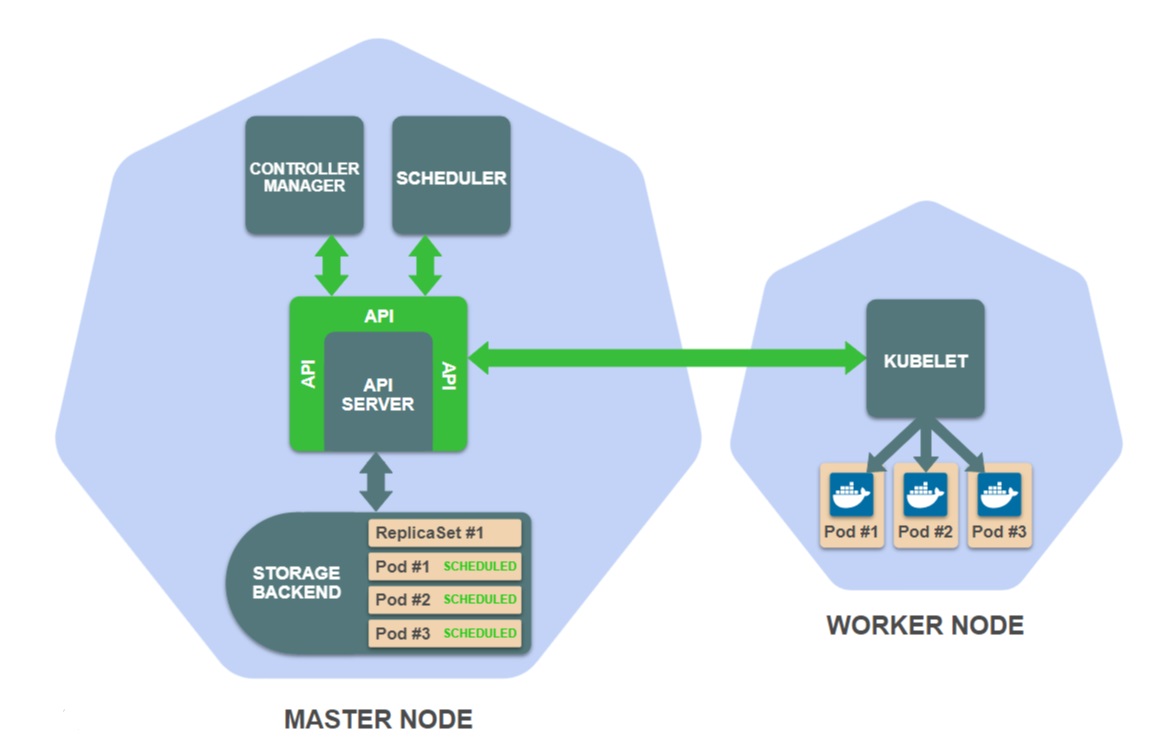
Ниже текстовый вариант этого описания.
Запрос API к конечной точке создания ReplicaSet обрабатывается сервером API. Сервер API аутентифицирует запрос и сохраняет определение ресурса ReplicaSet в хранилище.
Это событие запускает контроллер ReplicaSet, который является подпроцессом диспетчера контроллеров. Контроллер ReplicaSet следит за созданием, обновлением и удалением ресурсов ReplicaSet в хранилище и получает уведомление о событии, когда это происходит.
Задача контроллера ReplicaSet — убедиться, что существует нужное количество подов реплики ReplicaSet. В нашем примере подов пока не существует, поэтому контроллер ReplicaSet создает эти определения подов (в соответствии с шаблоном пода в определении ReplicaSet) и сохраняет их в хранилище.
Создание новых подов запускает планировщик, отслеживающий определения подов, которые еще не запланированы для рабочих нод. Планировщик выбирает подходящую рабочую ноду для каждого пода и обновляет определения пода в хранилище.
Обратите внимание, что до этого момента нигде в кластере не выполнялся код рабочей нагрузки. Всё, что было сделано до сих пор, — это создание и обновление ресурсов в хранилище на главном узле.
Последнее событие запускает Kubelet, которые следят за подами, запланированными для их рабочих нод. Kubelet рабочей ноды, для которой установлены ваши поды ReplicaSet, должен дать указание среде выполнения контейнеров, например Docker, загрузить требуемые образы контейнеров и запустить их.
В этот момент, наконец, ваше приложение ReplicaSet запущено!
Роль API Kubernetes
Как вы увидели в предыдущем примере, компоненты Kubernetes (за исключением сервера API и хранилища) смотрят за изменением ресурсов в хранилище и изменяют информацию о ресурсах в хранилище.
Конечно, эти компоненты не взаимодействуют с хранилищем напрямую, а только через Kubernetes API.
Рассмотрим следующие примеры:
- Контроллер ReplicaSet использует конечную точку API list ReplicaSets c параметром
watchдля наблюдения за изменениями ресурсов ReplicaSet. - Контроллер ReplicaSet использует конечную точку API create Pod (создать под) для создания подов.
- Планировщик использует конечную точку API patch Pod (изменить под) для обновления подов с информацией о выбранной рабочей ноде.
Как вы видите, это то же самое API, к которому обращается kubectl. Использование одного и того же API для работы внутренних компонентов и внешних пользователей является фундаментальной концепцией дизайна Kubernetes.
Теперь можно обобщить, как работает Kubernetes:
- Хранилище сохраняет состояние, то есть ресурсы Kubernetes.
- API сервер предоставляет интерфейс к хранилищу в виде Kubernetes API.
- Все остальные компоненты и пользователи Kubernetes читают, наблюдают и манипулируют состоянием (ресурсами) Kubernetes через API.
Знание этих концепций поможет лучше понять kubectl и использовать его по максимуму.
Теперь давайте рассмотрим ряд конкретных советов и приемов, которые помогут повысить производительность работы с kubectl.
1. Ускорение ввода при помощи дополнения команд
Один из наиболее полезных, но часто упускаемых из виду приемов, позволяющих повысить производительность работы с kubectl, — дополнение команд.
Дополнение команд позволяет автоматически заполнять отдельные части команд kubectl клавишей Tab. Это работает для подкоманд, опций и аргументов, в том числе таких сложных, как имена ресурсов.
Посмотрите, как работает дополнение команд kubectl:

Дополнение команд работает для командных оболочек Bash и Zsh.
Официальное руководство содержит детальные инструкции по настройке автодополнения, но ниже мы приведем краткую выдержку.
Как работает дополнение команд
Дополнение команд — функция оболочки, которая работает с помощью скрипта дополнения. Скрипт дополнения — сценарий оболочки, который определяет поведение дополнения для конкретной команды.
Kubectl автоматически генерирует и выводит скрипты дополнения для Bash и Zsh с помощью следующих команд:
$ kubectl completion bashИли:
$ kubectl completion zshТеоретически — достаточно подключить вывод этих команд в соответствующую командную оболочку, чтобы kubectl смог дополнять команды.
На практике — способ подключения отличается для Bash (включая различия между Linux и MacOS) и Zsh. Ниже мы рассмотрим все эти варианты.
Bash в Linux
Скрипт дополнения для Bash зависит от пакета bash-completion, поэтому сначала необходимо установить его:
$ sudo apt-get install bash-completionИли:
$ yum install bash-completionВы можете протестировать, что пакет установлен успешно с помощью следующей команды:
$ type _init_completionЕсли при этом выводится код функции оболочки, то bash-completion правильно установлен. Если команда выдает ошибку «Не найдено», необходимо добавить следующую строку в ваш файл
~ / .bashrc:$ source /usr/share/bash-completion/bash_completionНужно ли добавлять эту строку в файл
~ / .bashrc или нет, зависит от менеджера пакетов, который вы использовали для установки bash-completion. Для APT это необходимо, для YUM нет.После установки bash-completion нужно настроить все так, чтобы скрипт дополнения kubectl был включен во всех сеансах оболочки.
Один из способов сделать это — добавить следующую строку в файл
~ / .bashrc:source <(kubectl completion bash)Другой способ — добавить скрипт дополнения kubectl в каталог
/etc/bash_completion.d (создайте его, если он не существует):$ kubectl completion bash >/etc/bash_completion.d/kubectlВсе скрипты дополнения в каталоге
/etc/bash_completion.d автоматически включаются в bash-completion.Оба варианта одинаково применимы.
После перезагрузки командной оболочки автодополнение команд kubectl будет работать.
Bash в MacOS
В MacOS настройка несколько сложнее. Дело в том, что по умолчанию в MacOS стоит Bash версии 3.2, а скрипт автодополнения kubectl требует версии Bash не ниже 4.1 и не работает в Bash 3.2.
Применение устаревшей версии Bash в MacOS связано с вопросами лицензирования. Bash версии 4 распространяется под лицензией GPLv3, которую не поддерживает Apple.
Для настройки автодополнения kubectl в MacOS нужно установить более свежую версию Bash. Вы также можете установить обновленный Bash как командную оболочку по умолчанию, что убережет в будущем от массы проблем. Это несложно, детали приведены в статье «Обновление Bash в MacOS».
Перед тем как продолжить, убедитесь, что вы используете свежую версию Bash (проверьте вывод
bash --version).Скрипт автодополнения в Bash зависит от проекта bash-completion, поэтому вначале нужно установить его.
Вы можете установить bash-completion при помощи Homebrew:
$ brew install bash-completion@2Здесь
@2 обозначает bash-completion версии 2. Автодополнение kubectl требует bash-completion v2, а bash-completion v2 требует версии Bash минимум 4.1.Вывод команды
brew-install содержит секцию Caveats, в которой указано, что нужно добавить в файл ~/.bash_profile:export BASH_COMPLETION_COMPAT_DIR=/usr/local/etc/bash_completion.d
[[ -r "/usr/local/etc/profile.d/bash_completion.sh" ]] && .
"/usr/local/etc/profile.d/bash_completion.sh"Однако я рекомендую добавлять эти строки не в
~/.bash_profile, а в ~/.bashrc. В этом случае автодополнение будет доступно не только в основной, но и в дочерних командных оболочках.После перезагрузки командной оболочки можете проверить корректность установки при помощи следующей команды:
$ type _init_completionЕсли в выводе вы видите shell-функцию, то все настроено правильно.
Теперь нужно сделать так, чтобы автодополнение kubectl было включено во всех сеансах.
Один из способов — добавить следующую строку в ваш
~/.bashrc:source <(kubectl completion bash)Второй способ — добавить скрипт автодополнения в папку
/usr/local/etc/bash_completion.d:$ kubectl completion bash
>/usr/local/etc/bash_completion.d/kubectlЭтот способ сработает, только если вы устанавливали bash-completion при помощи Homebrew. В этом случае bash-completion загружает все скрипты из этой директории.
Если вы устанавливали kubectl при помощи Homebrew, то не нужно выполнять предыдущий этап, так как скрипт автодополнения будет автоматически размещен в папке
/usr/local/etc/bash_completion.d во время установки. В этом случае автодополнение kubectl начнет работать сразу же, как только вы установите bash-completion.В итоге все эти варианты эквивалентны.
Zsh
Скрипты автодополнения для Zsh не требуют никаких зависимостей. Всё, что нужно — это включить их при загрузке командной оболочки.
Вы можете сделать это, добавив строку в свой
~/.zshrc файл:source <(kubectl completion zsh)Если вы получили ошибку
not found: compdef после перезагрузки вашей оболочки, нужно включить встроенную функцию compdef. Ее можно включить, добавив в начало вашего файла ~/.zshrc следующее:autoload -Uz compinit
compinit2. Быстрый просмотр спецификаций ресурсов
Когда вы создаете определения ресурсов YAML, нужно знать поля и их значение для этих ресурсов. Одно из мест для поиска этой информации — в справочнике по API, который содержит полные спецификации всех ресурсов.
Однако переключаться на веб-браузер каждый раз, когда нужно что-то искать, неудобно. Поэтому kubectl предоставляет команду
kubectl explain, которая показывает спецификации всех ресурсов прямо в вашем терминале.Формат команды следующий:
$ kubectl explain resource[.field]...Команда выведет спецификацию запрошенного ресурса или поля. Выведенная информация идентична той, что содержится в руководстве API.
По умолчанию
kubectl explain показывает только первый уровень вложенности полей. Посмотреть, как это выглядит можно тут.
Можно отобразить все дерево, если добавить опцию
--recursive:$ kubectl explain deployment.spec --recursiveЕсли вы не знаете точно, какие именно ресурсы нужны, то можете отобразить их все следующей командой:
$ kubectl api-resourcesЭта команда отображает имена ресурсов в форме множественного числа, например,
deployments вместо deployment. Она также отображает краткое имя, например deploy, для тех ресурсов, у которых оно есть. Не беспокойтесь об этих различиях. Все эти варианты имен эквивалентны для kubectl. То есть вы можете использовать любой из них для kubectl explain.Все нижеследующие команды равнозначны:
$ kubectl explain deployments.spec
# или
$ kubectl explain deployment.spec
# или
$ kubectl explain deploy.spec3. Используйте пользовательский формат вывода столбцов
По умолчанию формат вывода команды
kubectl get:$ kubectl get pods
NAME READY STATUS RESTARTS AGE
engine-544b6b6467-22qr6 1/1 Running 0 78d
engine-544b6b6467-lw5t8 1/1 Running 0 78d
engine-544b6b6467-tvgmg 1/1 Running 0 78d
web-ui-6db964458-8pdw4 1/1 Running 0 78dТакой формат удобен, но он содержит ограниченное количество информации. По сравнению с полным форматом определения ресурса, тут выводится всего несколько полей.
В этом случае можно использовать пользовательский формат вывода столбцов. Он позволяет определять, какие данные выводить. Вы можете вывести любое поле ресурса отдельным столбцом.
Использование пользовательского формата определяется с помощью опций:
-o custom-columns=<header>:<jsonpath>[,<header>:<jsonpath>]...Вы можете определить каждый столбец вывода парой
<header>:<jsonpath>, где <header> — название столбца, а <jsonpath> — выражение, определяющее поле ресурса.Давайте посмотрим на простой пример:
$ kubectl get pods -o custom-columns='NAME:metadata.name'
NAME
engine-544b6b6467-22qr6
engine-544b6b6467-lw5t8
engine-544b6b6467-tvgmg
web-ui-6db964458-8pdw4Вывод содержит один столбец с именами подов.
Выражение в опции выбирает имена подов из поля
metadata.name. Это потому что имя пода определяется в дочернем поле name поля metadata в ресурсном описании пода. Детальнее можно ознакомиться в руководстве API либо набрать команду kubectl explain pod.metadata.name. Теперь допустим, что вы хотите добавить дополнительный столбец к выводу, например, показывая ноду, на которой работает каждый под. Для этого вы можете просто добавить соответствующую спецификацию столбца в опцию пользовательских столбцов:
$ kubectl get pods \
-o custom-columns='NAME:metadata.name,NODE:spec.nodeName'
NAME NODE
engine-544b6b6467-22qr6 ip-10-0-80-67.ec2.internal
engine-544b6b6467-lw5t8 ip-10-0-36-80.ec2.internal
engine-544b6b6467-tvgmg ip-10-0-118-34.ec2.internal
web-ui-6db964458-8pdw4 ip-10-0-118-34.ec2.internalВыражение выбирает имя ноды из
spec.nodeName — когда под назначается ноде, ее имя прописывается в поле spec.nodeName ресурсной спецификации пода. Более подробную информацию можно посмотреть в выводе kubectl explain pod.spec.nodeName. Учтите, что поля ресурсов Kubernetes чувствительны к регистру.
Вы можете посмотреть любое поле ресурса в виде столбца. Просто просмотрите спецификацию ресурса и попробуйте ее с любыми полями, которые вам нравятся.
Но сначала давайте подробнее рассмотрим выражения выбора полей.
Выражения JSONPath
Выражения для выбора полей ресурсов базируются на JSONPath.
JSONPath — это язык для выборки данных из JSON-документов. Выбор одного поля — самый простой случай использования JSONPath. У него гораздо больше возможностей, включая селекторы, фильтры и так далее.
Kubectl explain поддерживает ограниченное количество возможностей JSONPath. Ниже описаны возможности и примеры их использования:
# Выбрать все элементы списка
$ kubectl get pods -o custom-columns='DATA:spec.containers[*].image'
# Выбрать специфический элемент списка
$ kubectl get pods -o custom-columns='DATA:spec.containers[0].image'
# Выбрать элементы списка, попадающие под фильтр
$ kubectl get pods -o custom-columns='DATA:spec.containers[?(@.image!="nginx")].image'
# Выбрать все поля по указанному пути, независимо от их имени
$ kubectl get pods -o custom-columns='DATA:metadata.*'
# Выбрать все поля с указанным именем, вне зависимости от их расположения
$ kubectl get pods -o custom-columns='DATA:..image'Особое значение имеет оператор []. Многие поля ресурсов Kubernetes являются списками, и этот оператор позволяет выбирать элементы этих списков. Он часто используется с подстановочным знаком как [*], чтобы выбрать все элементы списка.
Примеры применения
Возможности использования пользовательского формата вывода столбцов безграничны, так как вы можете отобразить любое поле или комбинацию полей ресурса в выводе. Вот несколько примеров приложений, но не стесняйтесь исследовать их самостоятельно и находить полезные для вас применения.
- Отображение образов контейнеров для подов:
$ kubectl get pods \ -o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image' NAME IMAGES engine-544b6b6467-22qr6 rabbitmq:3.7.8-management,nginx engine-544b6b6467-lw5t8 rabbitmq:3.7.8-management,nginx engine-544b6b6467-tvgmg rabbitmq:3.7.8-management,nginx web-ui-6db964458-8pdw4 wordpress
Эта команда отображает имена образов контейнеров для каждого пода.
Помните, что под может содержать несколько контейнеров, тогда имена образов будут выведены в одной строке через запятую. - Отображение зон доступности нод:
$ kubectl get nodes \ -o custom-columns='NAME:metadata.name,ZONE:metadata.labels.failure-domain\.beta\.kubernetes\.io/zone' NAME ZONE ip-10-0-118-34.ec2.internal us-east-1b ip-10-0-36-80.ec2.internal us-east-1a ip-10-0-80-67.ec2.internal us-east-1b
Эта команда удобна, если ваш кластер размещен в публичном облаке. Она отображает зону доступности для каждой ноды.
Зона доступности — это облачная концепция, ограничивающая зону репликации географическим регионом.
Зоны доступности для каждой ноды получаются через специальную метку —failure-domain.beta.kubernetes.io/zone. Если кластер запущен в публичном облаке, эта метка создается автоматически и заполняется именами зон доступности для каждой ноды.
Метки не являются частью спецификации ресурсов Kubernetes, так что вы не найдете информации о них в руководстве API. Однако их можно увидеть (как и любые другие метки), если запросить информацию о нодах в формате YAML или JSON:
$ kubectl get nodes -o yaml # или $ kubectl get nodes -o json
Это отличный способ узнать больше о ресурсах, в дополнение к изучению ресурсных спецификаций.
4. Легкое переключение между кластерами и пространствами имен
Когда kubectl выполняет запрос к Kubernetes API, перед этим он читает файл kubeconfig, чтобы получить все необходимые параметры для коннекта.
По умолчанию файл kubeconfig — это
~/.kube/config. Обычно этот файл создается или обновляется особой командой.Когда вы работаете с несколькими кластерами, ваш файл kubeconfig содержит параметры подключения ко всем этим кластерам. Вам нужен способ указать команде kubectl, с каким именно кластером вы работаете.
Внутри кластера вы можете создать несколько пространств имен — разновидность виртуального кластера внутри физического кластера. Kubectl определяет, какое пространство имен использовать также по данным файла kubeconfig. Значит, вам также нужен способ указать команде kubectl, с каким пространством имен работать.
В этой главе мы расскажем, как это работает и как добиться эффективной работы.
Обратите внимание, что у вас может быть несколько файлов kubeconfig, перечисленных в переменной среды KUBECONFIG. В этом случае все эти файлы будут объединены в одну общую конфигурацию во время выполнения. Вы также можете изменить применяемый по умолчанию файл kubeconfig, запуская kubectl с параметром
--kubeconfig. Смотрите официальную документацию.Файлы kubeconfig
Давайте посмотрим, что же именно содержит файл kubeconfig:

Как вы видите, файл kubeconfig содержит набор контекстов. Контекст состоит из трех элементов:
- Cluster — URL API сервера кластера.
- User — учетные данные аутентификации пользователя в кластере.
- Namespace — пространство имен, используемое при присоединении к кластеру.
На практике часто используют один контекст на кластер в своем файле kubeconfig. Тем не менее у вас может быть несколько контекстов на кластер, различающихся по пользователю или пространству имен. Однако такая конфигурация с несколькими контекстами встречается нечасто, так что обычно существует взаимно-однозначное сопоставление между кластерами и контекстами.
В любой момент времени один из контекстов является текущим:

Когда kubectl читает конфигурационный файл, то всегда берется информация из текущего контекста. В примере выше kubectl будет коннектиться к кластеру Hare.
Соответственно, чтобы переключиться на другой кластер, нужно изменить текущий контекст в файле kubeconfig:

Теперь kubectl будет коннектиться к кластеру Fox.
Чтобы переключиться на другое пространство имен в том же самом кластере, нужно изменить значение элемента namespace для текущего контекста:
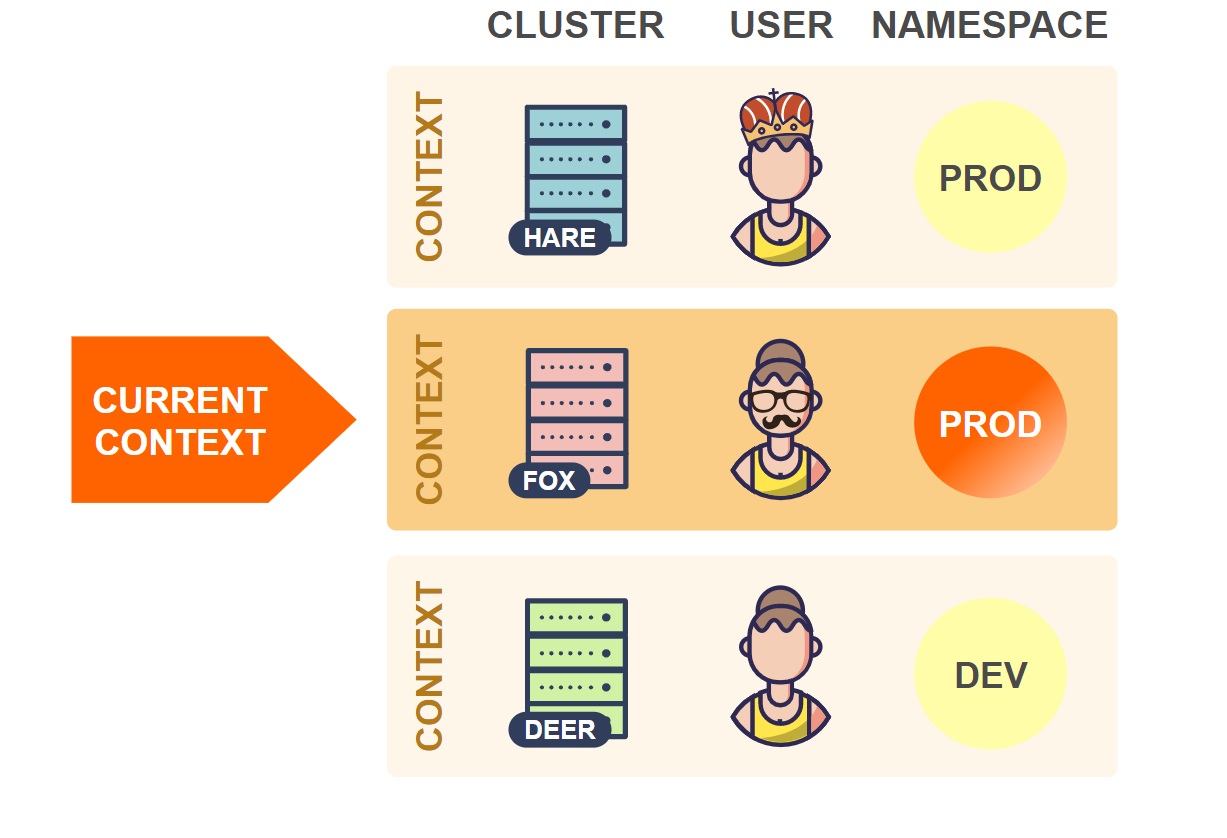
В вышеприведенном примере kubectl будет использовать пространство имен Prod кластера Fox (ранее было установлено пространство имен Test).
Обратите внимание, что kubectl также предоставляет параметры
--cluster, --user, --namespace и --context, которые позволяют перезаписывать отдельные элементы и сам текущий контекст, независимо от того, что установлено в файле kubeconfig. Смотрите kubectl options.Теоретически вы можете вручную менять параметры в файле kubeconfig. Но это неудобно. Для упрощения этих операций существуют разнообразные утилиты, которые позволяют менять параметры в автоматическом режиме.
Используйте kubectx
Очень популярная утилита для переключения между кластерами и пространствами имен.
Утилита предоставляет команды
kubectx и kubens для изменения текущего контекста и пространства имен соответственно.Как уже упоминалось, изменение текущего контекста означает изменение кластера, если у вас есть только один контекст на кластер.
Вот пример выполнения этих команд:

По сути, эти команды просто редактируют файл kubeconfig, как было описано выше.
Чтобы установить
kubectx, следуйте инструкциям на Github.Обе команды поддерживают автодополнение имен контекстов и пространств имен, что позволяет не вводить их полностью. Инструкции по настройке автодополнения тут.
Другой полезной функцией
kubectx является интерактивный режим. Он работает совместно с утилитой fzf, которую необходимо устанавливать отдельно. Установка fzf автоматически делает доступным интерактивный режим в kubectx. В интерактивном режиме вы можете выбирать контекст и пространство имен через интерактивный интерфейс свободного поиска, предоставленный fzf.Использование алиасов командной оболочки
Вам не нужны отдельные инструменты для изменения текущего контекста и пространства имен, потому что kubectl также предоставляет команды для этого. Так, команда
kubectl config предоставляет подкоманды для редактирования файлов kubeconfig. Вот некоторые из них:
kubectl config get-contexts: вывести все контексты;kubectl config current-context: получить текущий контекст;kubectl config use-context: изменить текущий контекст;kubectl config set-context: изменить элемент контекста.
Однако использовать эти команды напрямую не очень удобно, потому что они длинные. Можно сделать для них алиасы командной оболочки, которые легко выполнить.
Я создал набор алиасов на основе этих команд, которые предоставляют функциональность, аналогичную kubectx. Здесь вы можете увидеть их действие:

Обратите внимание, что алиасы используют fzf для предоставления интерактивного интерфейса свободного поиска (как в интерактивном режиме kubectx). Это означает, что вам нужно установить fzf, чтобы использовать эти алиасы.
Вот сами определения алиасов:
# Получить текущий контекст
alias krc='kubectl config current-context'
# Список всех контекстов
alias klc='kubectl config get-contexts -o name | sed "s/^/ /;\|^ $(krc)$|s/ /*/"'
# Изменить текущий контекст
alias kcc='kubectl config use-context "$(klc | fzf -e | sed "s/^..//")"'
# Получить текущее пространство имен
alias krn='kubectl config get-contexts --no-headers "$(krc)" | awk "{print \$5}" | sed "s/^$/default/"'
# Список всех пространств имен
alias kln='kubectl get -o name ns | sed "s|^.*/| |;\|^ $(krn)$|s/ /*/"'
# Изменить текущее пространство имен
alias kcn='kubectl config set-context --current --namespace "$(kln | fzf -e | sed "s/^..//")"'Чтобы установить эти алиасы, нужно добавить приведенные выше определения в ваш файл
~/.bashrc или ~/.zshrc и перезагрузить вашу оболочку.Использование плагинов
Kubectl позволяет загружать плагины, которые исполняются так же, как основные команды. Можно, например, установить плагин kubectl-foo и запускать его, выполняя команду
kubectl foo.Было бы удобно менять контекст и пространство имен таким способом, например, запускать
kubectl ctx для смены контекста и kubectl ns для смены пространства имен.Я написал два плагина, которые делают это:
Работа плагинов базируется на алиасах из предыдущего раздела.
Вот как они работают:

Обратите внимание, что плагины используют fzf для предоставления интерактивного интерфейса свободного поиска (как в интерактивном режиме kubectx). Это означает, что вам нужно установить fzf, чтобы использовать эти алиасы.
Чтобы установить плагины, нужно загрузить сценарии оболочки с именами kubectl-ctx и kubectl-ns в любой каталог в вашей переменной PATH и сделать их исполняемыми, например, с помощью
chmod +x. Сразу после этого вы сможете использовать kubectl ctx и kubectl ns.5. Сокращение ввода с автоалиасами
Алиасы командной оболочки — хорошая возможность ускорить ввод. Проект kubectl-aliases содержит около 800 сокращений для основных команд kubectl.
Вы можете удивиться — как запомнить 800 алиасов? Но не нужно помнить их все, ведь они строятся по простой схеме, которая приведена ниже:

Например:
- kgpooyaml — kubectl get pods oyaml
- ksysgsvcw — kubectl -n kube-system get svc w
- ksysrmcm — kubectl -n kube-system rm cm
- kgdepallsl — kubectl get deployment all sl
Как вы видите, алиасы состоят из компонентов, каждый из которых обозначает определенный элемент команды kubectl. Каждый алиас может иметь один компонент для базовой команды, операции и ресурса и несколько компонентов для параметров. Вы просто «заполняете» эти компоненты слева направо в соответствии с приведенной выше схемой.
Tекущая подробная схема находится на GitHub. Там вы также можете найти полный список псевдонимов.
Например, алиас kgpooyamlall равноценен команде
kubectl get pods -o yaml --all-namespaces.Относительный порядок опций неважен: команда
kgpooyamlall эквивалентна команде kgpoalloyaml.Вы можете не использовать все компоненты как алиасы. Например
k, kg, klo, ksys, kgpo также можно использовать. Более того, в командной строке можно комбинировать алиасы и обычные команды или опции:Например:
- Вместо
kubectl proxyможно написатьk proxy. - Вместо
kubectl get rolesможно написатьkg roles(в настоящее время не существует алиаса для ресурса Roles). - Чтобы получить данные по конкретному поду, можно использовать команду
kgpo my-pod — kubectl get pod my-pod.
Учтите, что некоторые алиасы требуют аргумент в командной строке. Например, алиас
kgpol означает kubectl get pods -l. Опция -l требует аргумент — спецификацию метки. Если вы используете алиас, то он будет выглядеть как kgpol app=ui. Из-за того, что часть алиасов требует аргументы, алиасы а, f и l нужно использовать последними.
В общем, как только вы освоите эту схему, то сможете интуитивно вывести алиасы из команд, которые хотите выполнить, и сэкономить много времени на вводе.
Инсталляция
Чтобы инсталлировать kubectl-aliases, нужно скачать файл .kubectl_aliases с GitHub и включить его в файл
~/.bashrc или ~/.zshrc:source ~/.kubectl_aliasesАвтодополнение
Как мы уже говорили, вы часто добавляете дополнительные слова к алиасу в командной строке. Например:
$ kgpooyaml test-pod-d4b77b989Если вы используете автодополнение команды kubectl, то, вероятно, использовали автодополнение для таких вещей, как имена ресурсов. Но можно ли сделать это, когда используются алиасы?
Это очень важный вопрос, потому что, если автодополнение не работает, вы лишитесь части преимуществ алиасов.
Ответ зависит от того, какую командную оболочку вы используете:
- Для Zsh автодополнение для алиасов работает «из коробки».
- Для Bash, к сожалению, необходимы некоторые действия, чтобы заставить работать автодополнение.
Включение автодополнения для алиасов в Bash
Проблема с Bash состоит в том, что он пытается дополнить (всякий раз, когда вы нажимаете Tab) алиас, а не команду, на которую ссылается алиас (как, например, делает Zsh). Поскольку у вас нет скриптов дополнения для всех 800 псевдонимов, автодополнение не работает.
Проект complete-alias предоставляет общее решение этой проблемы. Он подключается к механизму дополнения для алиасов, внутри дополняет алиас до команды и возвращает варианты дополнения для дополненной команды. Это означает, что дополнение для алиаса ведет себя точно так же, как для полной команды.
Далее я сначала объясню, как установить complete-alias, а затем — как его настроить, чтобы включить дополнение для всех псевдонимов kubectl.
Установка complete-alias
Прежде всего, complete-alias зависит от bash-completion. Поэтому перед установкой complete-alias необходимо убедиться, что bash-completion установлен. Инструкции по установке были даны ранее для Linux и MacOS.
Важное примечание для пользователей MacOS: как и скрипт автодополнения kubectl, сomplete-alias не работает с Bash 3.2, который по умолчанию используется в MacOS. В частности, complete-alias зависит от bash-completion v2 (
brew install bash-completion@2), для которого требуется как минимум Bash 4.1. Это означает, что для использования complete-alias в MacOS нужно установить более новую версию Bash.Вам нужно скачать скрипт bash_completion.sh из репозитория GitHub и включить его в своем файле
~/.bashrc:source ~/bash_completion.shПосле перезагрузки командной оболочки complete-alias будет полностью установлен.
Включение автодополнения для алиасов kubectl
Технически complete-alias предоставляет функцию оболочки
_complete_alias. Эта функция проверяет алиас и возвращает подсказки дополнения для команды алиаса.Для связывания функции с определенным алиасом нужно использовать встроенный механизм Bash complete, чтобы установить
_complete_alias как функцию дополнения алиаса.В качестве примера возьмем алиас k, обозначающий команду kubectl. Чтобы установить
_complete_alias в качестве функции дополнения для этого алиаса, вы должны выполнить следующую команду:$ complete -F _complete_alias kРезультатом этого является то, что всякий раз, когда вы автодополняете алиас k, вызывается функция
_complete_alias, которая проверяет алиас и возвращает подсказки дополнения для команды kubectl.В качестве второго примера давайте возьмем алиас
kg, который обозначает kubectl get:$ complete -F _complete_alias kgТочно так же, как и в предыдущем примере, когда вы автодополняете kg, вы получаете те же самые подсказки дополнения, которые получили бы для
kubectl get.Обратите внимание, что так можно использовать complete-alias для любого алиаса в вашей системе.
Следовательно, чтобы включить автодополнение для всех алиасов kubectl, нужно выполнить указанную выше команду для каждого из них. Следующий фрагмент делает именно это при условии, что вы установили kubectl-aliases в
~/.kubectl-aliases:for _a in $(sed '/^alias /!d;s/^alias //;s/=.*$//' ~/.kubectl_aliases);
do
complete -F _complete_alias "$_a"
doneЭтот кусок кода нужно поместить в ваш
~/.bashrc, перезагрузить командную оболочку и для всех 800 алиасов kubectl станет доступным автодополнение.6. Расширение kubectl при помощи плагинов
Начиная с версии 1.12, kubectl поддерживает механизм плагинов, которые позволяют расширять его функции дополнительными командами.
Если вы знакомы с механизмами плагинов Git, то плагины kubectl построены по такому же принципу.
В этой главе мы расскажем, как устанавливать плагины, где их искать и как создавать собственные плагины.
Инсталляция плагинов
Плагины kubectl распространяются в виде простых исполняемых файлов с именем вида
kubectl-x. Префикс kubectl- является обязательным, далее следует новая подкоманда kubectl, которая позволяет вызывать плагин.Например, плагин hello будет распространяться в виде файла с именем
kubectl-hello.Чтобы установить плагин, нужно скопировать файл
kubectl-x в любой каталог в вашей переменной PATH и сделать его исполняемым, например с помощью chmod +x. Сразу после этого вы можете вызвать плагин с помощью kubectl x.Вы можете использовать следующую команду для вывода списка всех плагинов, которые в настоящее время установлены в вашей системе:
$ kubectl plugin listЭта команда также отображает предупреждения, если у вас есть несколько плагинов с одинаковыми именами, или если есть файл плагинов, который не является исполняемым.
Поиск и инсталляция плагинов при помощи Krew
Плагины Kubectl пригодны для совместного или повторного использования подобно программным пакетам. Но где можно найти плагины, которыми поделились другие?
Проект Krew направлен на предоставление унифицированного решения для совместного использования, поиска, установки и управления плагинами kubectl. Проект называет себя «менеджером пакетов для плагинов kubectl» (Krew похож на Brew).
Krew — это список плагинов kubectl, которые вы можете выбирать и устанавливать. При этом Krew — тоже плагин для kubectl.
Это значит, что установка Krew работает, по сути, как установка любого другого плагина kubectl. Вы можете найти подробные инструкции на странице GitHub.
Наиболее важные команды Krew:
# Поиск в списке плагинов
$ kubectl krew search [<query>]
# Посмотреть информацию о плагине
$ kubectl krew info <plugin>
# Установить плагин
$ kubectl krew install <plugin>
# Обновить все плагины до последней версии
$ kubectl krew upgrade
# Посмотреть все плагины, установленные через Krew
$ kubectl krew list
# Деинсталлировать плагин
$ kubectl krew remove <plugin>Учтите, что инсталляция плагинов при помощи Krew не мешает инсталляции плагинов стандартным способом, описанным выше.
Обратите внимание, что команда
kubectl krew list отображает только те плагины, которые были установлены с помощью Krew, тогда как команда kubectl plugin list перечисляет все плагины, то есть те, которые установлены с помощью Krew, и те, которые установлены другими способами.Поиск плагинов в других местах
Krew — молодой проект, на данный момент в его списке всего около 30 плагинов. Если вы не можете найти то, что нужно, можно найти плагины в другом месте, например на GitHub.
Я рекомендую смотреть раздел GitHub kubectl-plugins. Там вы найдете несколько десятков доступных плагинов, которые стоит посмотреть.
Написание собственных плагинов
Вы можете сами создавать плагины — это нетрудно. Вам нужно создать исполняемый файл, который делает то, что нужно, назвать его в виде
kubectl-x и установить, как было описано выше.Файл может быть bash-скриптом, python-скриптом или скомпилированным go-приложением — это неважно. Единственное условие — чтобы он мог напрямую выполняться в операционной системе.
Давайте создадим пример плагина прямо сейчас. В предыдущем разделе вы использовали команду kubectl для вывода списка контейнеров для каждого пода. Можно легко превратить эту команду в плагин, который вы можете вызвать, например с помощью
kubectl img.Создайте файл
kubectl-img следующего содержания:#!/bin/bash
kubectl get pods -o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image'Теперь сделайте файл исполняемым с помощью
chmod +x kubectl-img и переместите его в любой каталог в вашем PATH. Сразу после этого вы можете использовать плагин kubectl img.Как уже упоминалось, плагины kubectl могут быть написаны на любом языке программирования или сценариев. Если вы используете сценарии командной оболочки, то преимущество в возможности легко вызывать kubectl из плагина. Однако вы можете писать более сложные плагины на реальных языках программирования, используя клиентскую библиотеку Kubernetes. Если вы используете Go, то также можете использовать библиотеку cli-runtime, которая существует специально для написания плагинов kubectl.
Как поделиться своими плагинами
Если вы считаете, что ваши плагины могут быть полезны для других, не стесняйтесь делиться им на GitHub. Обязательно добавьте их в тему kubectl-plugins.
Вы также можете запросить добавление вашего плагина в список Krew. Инструкции о том, как это сделать, есть в репозитории GitHub.
Автодополнение команд
В настоящее время плагины не поддерживают автодополнение. То есть вы должны вводить полное имя плагина и полные имена аргументов.
В репозитории GitHub kubectl для этой функции есть открытый запрос. Таким образом, возможно, что эта функция будет реализована когда-нибудь в будущем.
Удачи!!!
Что еще почитать по теме:

{kind=link}