

Это продолжение практикума по развертыванию Kubernetes-кластера на базе облака Mail.ru Cloud Solutions и созданию MVP для реального приложения, выполняющего транскрибацию видеофайлов из YouTube.
Я Василий Озеров, основатель агентства Fevlake и действующий DevOps-инженер (опыт в DevOps — 8 лет), покажу все этапы разработки Cloud-Native приложений на K8s: от запуска кластера до построения CI/CD и разработки собственного Helm-чарта.
Напомню, что в первой части статьи мы выбрали архитектуру приложения, написали API-сервер, запустили Kubernetes c балансировщиком и облачными базами, развернули кластер RabbitMQ через Helm в Kubernetes. Во второй части настроили и запустили приложение для преобразования аудио в текст, сохранили результат и настроили автомасштабирование нод в кластере.
В третьей части осталось добавить небольшие улучшения, в частности настроить мониторинг, а также мы построим CI/CD и разработаем собственный Helm-чарт.
Также запись практикума можно посмотреть: часть 1, часть 2, часть 3.
Мониторинг с помощью Prometheus
Первое, что нам нужно сделать для получения кастомных метрик — это установить Prometheus, который будет собирать метрики с наших сервисов. Устанавливать его, как и RabbitMQ, будем через Helm. Но это не Prometheus в чистом виде, по его компонентам пройдемся позднее.
Используя команду helm search repo prometheus-stack, находим prometheus-stack:

Чтобы поиск выполнился корректно, необходимо предварительно убедиться в наличии репозитория prometheus-community с помощью helm repo list и добавить его при необходимости:

Если репозитория в списке нет, добавьте его командой helm repo add prometheus-community https://prometheus-community.github.io/helm-charts.
В результатах поиска нас интересует kube-prometheus-stack — скачиваем его и распаковываем:
helm pull prometheus-community/kube-prometheus-stack
tar zxvf kube-prometheus-stack-12.5.0.tgzКопируем values-файл в текущую директорию и называем его values.prometheus.stage.yaml:
cp kube-prometheus-stack/values.yaml values.prometheus.stage.yamlПри загрузке Helm-чартов придерживаемся стандартного правила. Загруженные Values мы не редактируем, чтобы чарт можно было легко обновлять в дальнейшем. Вместо этого переносим их на уровень выше и называем по имени сервиса (prometheus или rabbit) и окружения (stage, dev, prod и так далее). Очевидно, что для разных окружений настройки будут отличаться.
Отредактируем values.prometheus.stage.yaml. Чтобы включить Ingress для Prometheus, находим в файле блок ingress, устанавливаем в поле enabled значение true и прописываем имя хоста prometheus.stage.kis.im:
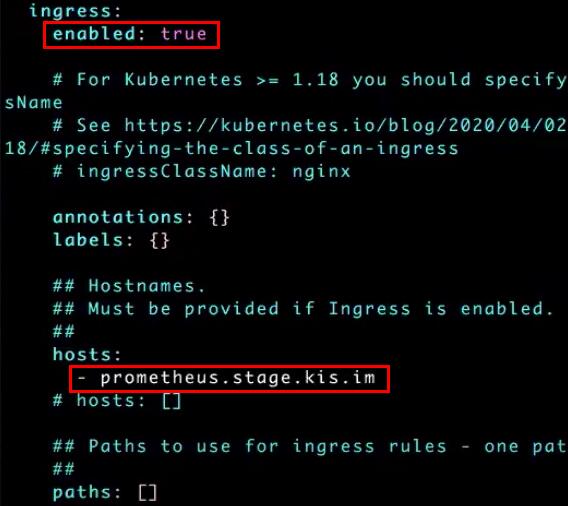
Далее создаем новый Namespace — monitoring:
kubectl create ns monitoringИ деплоим в него prometheus-stack:
helm -n monitoring upgrade --install prometheus-stack -f values.prometheus.stage.yaml
./kube-prometheus-stack/Деплой запущен:
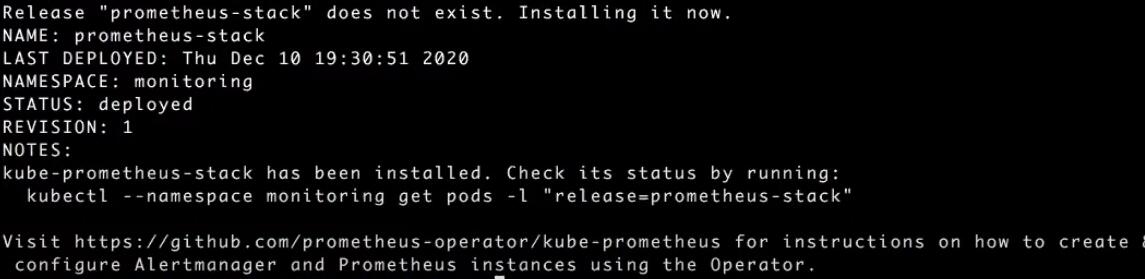
Проверим статус деплоя:
helm -n monitoring listЗапись появилась, значит все ок:

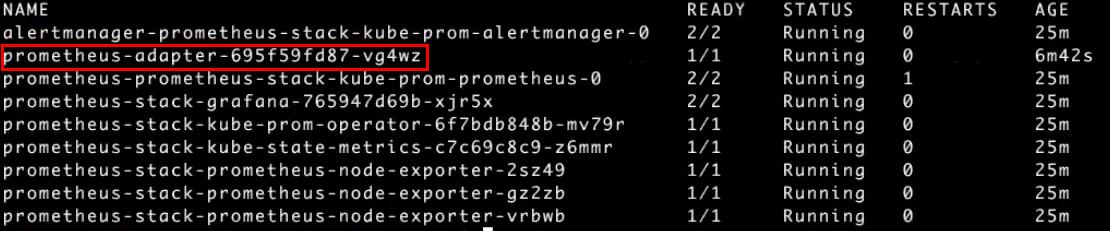
Теперь проверим, что запустились поды с помощью kubectl -n monitoring get pods:

Запустилось сразу несколько сервисов: alertmanager, prometheus, grafana, prometheus-operator, kube-state-metrix, node-exporter. Экспортеры (node-exporter) будут собирать информацию с каждой ноды кластера — поэтому их три штуки. Они управляются DaemonSet. При добавлении новых узлов в кластере для них будут автоматически созданы отдельные экспортеры.
Так как мы на этапе настройки подключали Ingress для Prometheus, мы можем обратиться по адресу prometheus.stage.kis.im (предварительно добавив его в DNS) и посмотреть все таргеты. Видим, что с kube-proxy метрики у нас не собираются, а все остальное успешно работает:

Prometheus Operator создает кастомные ресурсы. Просмотреть их можно, используя команду get crd (Custom Resource Definition) kubectl get crd:

Если необходимо собирать метрики со своих приложений, нужно добавить в этот список новый ресурс: либо serviceMonitor, который находит сервисы и обращается к их Endpoints, либо podMonitor, который находит поды и начинает мониторить их. Как только вы создадите этот ресурс, Prometheus Operator это обнаружит и обновит конфигурацию Prometheus. В результате ресурсы попадут в общий список, и Prometheus начнет их мониторить. Это логика работы любого оператора в Prometheus: операторы создают кастомные ресурсы, управляя которыми, вы можете влиять на работу мониторинга.
Для добавления нашего serviceMonitor открываем файл values.rabbitmq.stage.yaml и находим секцию Prometheus Metrics. Устанавливаем в поле enabled значение true.
Теперь этот Helm Chart подключит к RabbitMQ специальный плагин rabbitmq_prometheus, который сможет отдавать метрики в Prometheus:

В секции serviceMonitor также прописываем enabled: true. Эта настройка отвечает за создание serviceMonitor — ресурса, необходимого Prometheus:

В секции additionalLabels добавляем метку release: prometheus-stack:

Эта метка необходима для того, чтобы установленный нами ранее Prometheus-stack обнаружил новый serviceMonitor. В настройках Prometheus-stack при установке указываются метки, на основании которых он будет определять нужные podMonitor и serviceMonitor. Благодаря этому можно установить несколько Prometheus-stack в одном кластере, и они не будут пересекаться.
Теперь нужно обновить RabbitMQ. Предварительно мы указываем аутентификационные переменные auth.password и auth.erlangCookie, загрузив их из секретов, так как иначе будет предупреждение о том, что переменные уже были созданы:
export RABBITMQ_PASSWORD=$(kubectl get secret --namespace stage rabbitmq -o jsonpath=”{.data.rabbitmq-password}” | base64 --decode)
export RABBITMQ_ERLANG_COOKIE=$(kubectl get secret --namespace stage rabbitmq -o jsonpath=”{.data.rabbitmq-erlang-cookie” | base64 --decode)Теперь можно обновлять RabbitMQ:
helm -n stage upgrade rabbitmq -f values.rabbitmq.stage.yaml --set
auth.password=$RABBITMQ_PASSWORD --set auth.erlangCookie=$RABBITMQ_ERLANG_COOKIE ./rabbitmqПосле перезапуска RabbitMQ с помощью kubectl get crd в списке ресурсов появится servicemonitors — наш новый ресурс:

И в нем — rabbitmq, который создал Helm Chart RabbitMQ через kubectl -n stage get servicemonitors:

Если вывести содержимое сервисного монитора rabbitmq, то увидим правила его работы. В namespaceSelector указан отслеживаемый Namespace — stage. В matchLabels описаны искомые метки подов — instance: rabbitmq, name: rabbitmq. Таким образом, монитор находит Endpoints всех подходящих подов и добавляет их в список мониторинга Prometheus:

Если мы сейчас обновим таргеты в Prometheus, то увидим в списке stage/rabbitmq/0. Helm Chart добавил serviceMonitor для RabbitMQ, и Prometheus увидел наш новый сервис:

Теперь здесь можно посмотреть, например, метрику rabbitmq_queue_messages_ready — количество сообщений в статусе Ready. На текущий момент их 0:
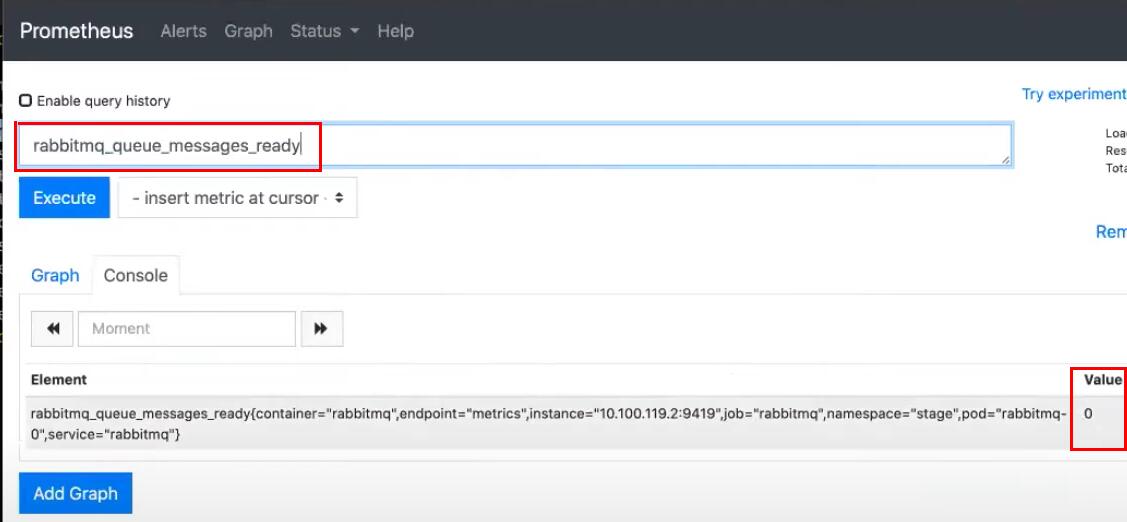
Давайте отправим новое сообщение с использованием нашего API:
curl -X POST -d '{"name": "federer20", "video_url":
"https://youtube.com/watch?v=n2wfFRsQ-qk" }' -H 'X-API-KEY: 804b95f13b714ee9912b19861faf3d25' -s http://api.stage.kis.im/requests | jq .Запрос добавлен:

Значение метрики в Prometheus обновится:
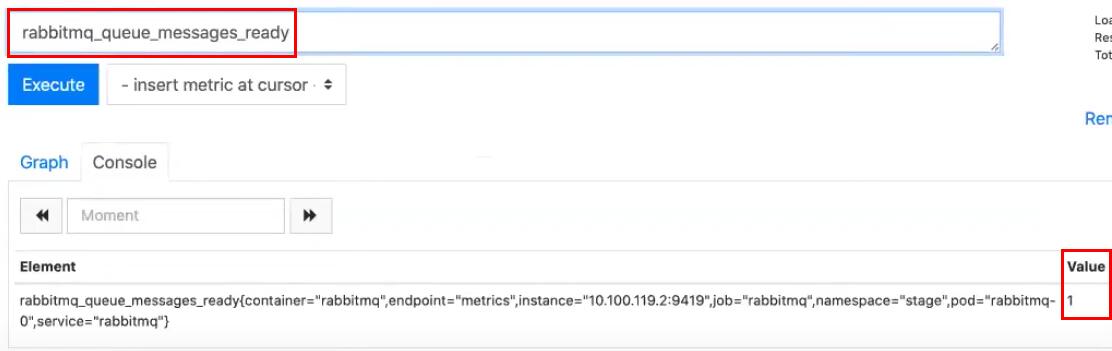
Следует учитывать, что метрика rabbitmq_queue_messages_ready показывает общее число сообщений. Если для вашего приложения требуется получение числа сообщений с разбиением по очередям, можно установить другой RabbitMQ Exporter.
Теперь необходимо научиться передавать метрики из Prometheus в Kubernetes, в кастомную группу custom.metrics.k8s.io, чтобы мы могли использовать их для нашего автоскейлинга. По умолчанию Prometheus этого делать не умеет, поэтому установим через Helm еще один продукт — prometheus-adapter с помощью helm search repo prometheus-adapter:

Загружаем и распаковываем первый Helm-чарт:
helm pull prometheus-community/prometheus-adapter
tar zxvf prometheus-adapter-2.8.1.tgzКопируем его values.yaml и открываем полученный файл values.pa.stage.yaml для редактирования:
cp prometheus-adapter/values.yaml values.pa.stage.yaml
vi values.pa.stgage.yamlВ файле нас интересует установка URL Prometheus. Прочие настройки можно оставить по умолчанию:
# Url to access prometheus
prometheus:
# Value is templated
url: http://prometheus-stack-kube-prom-prometheus.monitoring.svs
port: 9090
path: ""Получить искомый URL поможет команда kubectl -n monitoring get svc:

URL формируется по маске <NAME из вывода команды>.<Namespace (в нашем случае monitoring)>.svc.
Сохраняем yaml-файл и деплоим prometheus-adapter:
helm -n monitoring upgrade --install prometheus-adapter -f values.pa.stage.yaml
./prometheus-adapter/Все получилось:
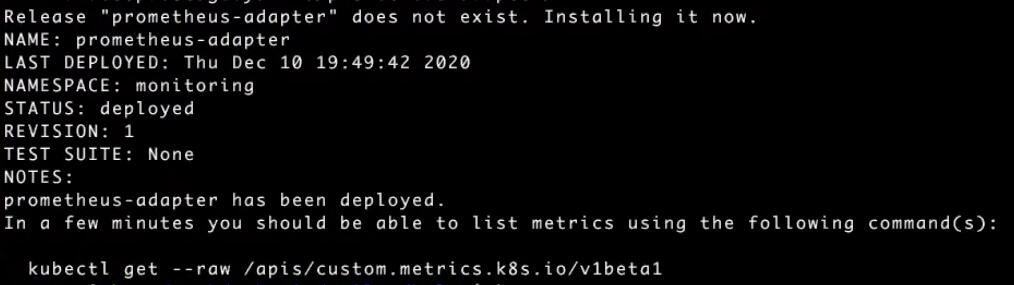
После успешной установки он появляется в списке подов, проверяем kubectl -n monitoring get pods:
Prometheus-adapter создает новую группу метрик в apis/custom.metrics.k8s.io/v1beta1. Мы можем обратиться к ней напрямую:
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq . | lessМы видим все метрики Prometheus, которые prometheus-adapter перенес в Kubernetes:

Чтобы ограничить число метрик, необходимо в файле values.pa.stage.yaml в блоке с правилами переноса метрик rules отключить признак default и указать свои, кастомные метрики. Это более правильный подход:
rules:
default: true
custom: []
# - seriesQuery: '{__name__=~"^some_metric_count$"}'
# resources:
# template: <<.Resource>>Мы можем посмотреть интересующую нас метрику rabbitmq_queue_messages_ready для всех подов в Namespace stage:
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/stage/pods/*/rabbitmq_queue_messages_ready | jq . | lessЗначение метрики 5751. Это количество сообщений в очереди на текущий момент:

Теперь мы можем отредактировать ранее созданный файл hpa.yaml для Horizontal Pod Autoscaler. В типе метрики type укажем Pods, в названии метрики metricName — rabbitmq_queue_messages_ready, в целевом значении — 1:
metrics:
- type: Pods
pods:
metricName: rabbitmq_queue_messages_ready
targetAverageValue: 1Сохраняем файл под именем hpa-custom.yaml, удаляем прежнюю версию converter-hpa и применяем новый файл. Теперь при увеличении числа сообщений в очереди Horizontal Pod Autoscaler будет создавать новые поды:
kubectl -n stage delete hpa converter-hpa
kubectl -n stage apply -f hpa-custom.yamlПримечание: во время вебинара эта кастомная метрика у нас почему-то не собиралась. Но позже все заработало, поэтому если у вас будет такая же проблема — попробуйте повторно применить настройки из файла.
Helm-чарт для приложения и настройка CI/CD в GitLab
Следующая задача — автоматизировать развертывание нашего приложения. До этого мы деплоили его через YAML-файлы. Но очевидно, что при большом числе файлов это становится крайне неудобным. Поэтому и появились чарты, внутри которых можно описывать множество шаблонов. Создадим собственный Helm-чарт для деплоя приложения.
Для начала создадим новый репозиторий в GitLab. Назовем его converter-api, сделаем приватным:

У нашего приложения есть Dockerfile, с помощью которого мы его собираем файлы с описанием зависимостей (go.mod, go.sum), и непосредственно код нашего приложения (main.go, requests.go). Эти файлы мы и поместим в репозиторий:
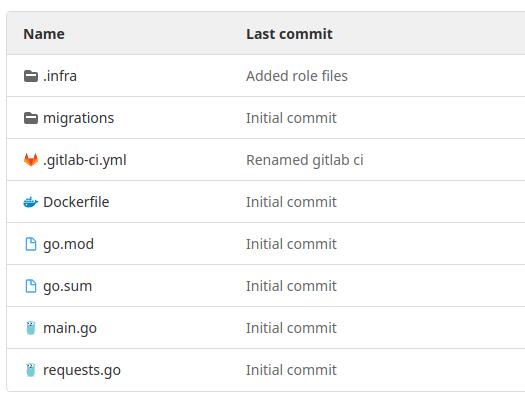
Инициализируем Git, создаем начальный коммит:
git init
git add -A
git commit -m 'Initial commit'Добавляем удаленный репозиторий origin и отправляем изменения в GitLab:
git remote add origin git@gitlab.com:vozerov/converter-api.git
git push origin masterВот ссылка на созданный репозиторий: https://gitlab.com/vozerov/converter-api
Рассмотрим содержимое файла gitlab-ci.yml, который описывает наш пайплайн.
В начале мы экспортируем в variables DOCKER_TLS_CERTDIR — это нужно для работы сервиса Docker-in-Docker. Так как мы будем запускаться внутри Docker, в нем нам еще раз понадобится Docker, чтобы собрать контейнер.
Далее идет описание stages: сначала мы билдим, затем деплоим. На стадии build мы логинимся в Docker Hub (используя переменную DOCKER_HUB_TOKEN), после этого применяем команды docker_build и docker_push. И указываем наш образ (IMAGE_NAME), куда это все запушить, и номер версии. Версия будет указываться с помощью хэша Git-коммита (CI_COMMIT_SHORT_SHA).
Примечание: поясню подробнее про назначение CI_COMMIT_SHORT_SHA. На каждый push собирается контейнер с тегом хэша коммита. Но кроме сборки и тестирования в автоматическом режиме больше с контейнером ничего не происходит, задеплоить его никуда нельзя. Деплоить можно только теги. Соответственно, когда GitLab видит тег, привязанный к коммиту, он больше не собирает Docker-контейнер, а скачивает предыдущий, который уже был собран и прошел тестирование с этим хэшом:
variables:
DOCKER_TLS_CERTDIR: "/certs"
stages:
- build
- deploy
build:
stage: build
image: docker:latest
services:
- docker:19.03.12-dind
variables:
IMAGE_NAME: vozerov/converter-api:${CI_COMMIT_SHORT_SHA}
before_script:
- echo "$DOCKER_HUB_TOKEN" | docker login -u vozerov --password-stdin
script:
- docker build -t ${IMAGE_NAME} ./
- docker push ${IMAGE_NAME}Далее переходим к деплою. Деплой использует отдельный образ helm-deployer. Внутри это Alpine с установленными Helm и kubectl. После этого, используя переменную KUBECONFIG, экспортируем настройки Kubernetes, которые необходимы для подключения к кластеру. Добавляем приватный ключ командой gpg (об этом более подробно пойдет речь ниже). И деплоим, используя Helm: переходим в директорию .infra и выполняем стандартный helm upgrade, как мы делали это ранее с RabbitMQ, prometheus-adapter, prometheus-stack и так далее.
При деплое мы устанавливаем converter-api в заданный Namespace и указываем два values-файла: values и secrets. Secrets необходимы нам для того, чтобы не хранить секретные переменные в environment либо файле, о чем мы ранее говорили. Также добавляем image.tag, который устанавливает версию (тег) нашего Docker-образа, который необходимо задеплоить. И в завершение указываем директорию с чартом (chart/).
Примечание: совместно с ключом --wait можно использовать ключ --atomic. В таком случае, если при деплое не обновится какой-то ресурс, произойдет откат релиза. Однако wait не выводит логи. Поэтому вместо него можно использовать дополнительные утилиты для вывода логов при деплое, например, werf/kubedog. Он позволяет в real-time режиме получать сообщения о запуске контейнеров, ошибках и так далее:
.deploy_template:
stage: deploy
image: vozerov/helm-deployer:latest
script:
# Setting up kubeconfig
- export KUBECONFIG=${KUBECONFIG}
# Setup GPG for Helm secrets
- echo "$HELM_GPG_KEY" > .helm_secrets_gpg_key.key
- gpg --allow-secret-key-import --import .helm_secrets_gpg_key.key
# Deploy via Helm
- cd .infra/
- helm secrets upgrade --wait --install converter-api --namespace ${KUBE_NAMESPACE} --values values.${BUILD_VARIANT}.yaml --values secrets.${BUILD_VARIANT}.yaml --set image.tag=${CI_COMMIT_SHORT_SHA} chart/Далее в gitlab-ci.yml следует описание двух environment: deploy_dev и deploy_prod. Для первой будут браться файлы values.dev.yaml и secrets.dev.yaml, для второй values.stage.yaml и secrets.stage.yaml. Так как мы в своем проекте вместо dev использовали stage, отредактируем файл — пропишем в блоке deploy_dev в переменных KUBE_NAMESPACE и BUILD_VARIANT значение stage вместо dev:
deploy_dev:
extends: .deploy_template
variables:
KUBE_NAMESPACE: "stage"
BUILD_VARIANT: "stage"
environment:
name: dev
when: manual
deploy_prod:
extends: .deploy_template
variables:
KUBE_NAMESPACE: "prod"
BUILD_VARIANT: "prod"
environment:
name: prod
only:
- master
when: manualПереходим к настройке переменных, на которые ссылается gitlab-ci.yml.
Во-первых, необходимо указать DOCKER_HUB_TOKEN, чтобы мы могли подключиться к DOCKER_HUB. Для этого я перехожу на hub.docker.com и создаю новый публичный репозиторий converter-api:

Далее в Docker Hub выбираем «Account Settings» и в пункте меню «Security» создаем новый токен с именем mcs:

После создания открывается окно, откуда можно скопировать сгенерированный токен:

Возвращаемся в GitLab и выбираем раздел «Settings» — «CI/CD» — «Variables». Создаем новую переменную с именем DOCKER_HUB_TOKEN, присваиваем ей значение скопированного токена, убираем флажок Protect variable, чтобы переменная была доступна во всех Branch:

Следующая переменная для настройки — KUBECONFIG. Она необходима, чтобы мы из Docker-образа могли подключиться к нашему кластеру. Самый простой вариант ее заполнения — взять содержимое файла kub-vc-dev_kubeconfig.yaml и полностью перенести его в переменную. Но при этом будут переданы полные права абсолютно на весь кластер. Это не самое правильное решение.
Поэтому стоит обратиться к RBAC (Role Based Access Control), доступному в Kubernetes. Принцип работы RBAC можно объяснить на примере трех простых файлов. У меня они расположены в папке roles: sa.yaml, role.yaml, rb.yaml:

В файле sa.yaml описывается создание нового сервисного аккаунта. В метаданных указывается его имя — deployer:
apiVersion: v1
kind: ServiceAccount
metadata:
name: deployerПрименяем полученный файл kubectl -n stage apply -f sa.yaml и создаем аккаунт. Если вывести список сервисных аккаунтов с помощью kubectl -n stage get sa, в нем отобразится созданный нами deployer:

При создании сервисный аккаунт сразу формирует себе секрет — токен, под которым он может обращаться к Kubernetes API:
kubectl -n stage get sa deployer -o yamlВидим имя этого секрета:

Мы можем вывести содержимое секрета по его имени с помощью kubectl -n stage get secret deployer-token-p4r7q -o yaml:

Если мы декодируем его в base64, то получим соответствующий токен. Запишем его в переменную TOKEN с помощью TOKEN=$(echo '<...token...>' | base64 -d)`:

Переходим к файлу role.yaml. В нем создается роль и описываются действия, доступные для пользователей, которым эта роль назначена. Здесь для различных API групп определяются доступные ресурсы (в секции resources) и способ доступа к ним (в секции Verbs). Символ * в Verbs означает, что возможны любые действия с ресурсом: get, list, update, watch, create и так далее:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployer
rules:
- apiGroups:
- ""
resources:
- pods
- pods/log
- services
- configmaps
- secrets
verbs:
- '*'
- apiGroups:
- "apps"
resources:
- deployments
- replicasets
verbs:
- '*'
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- '*'Применяем файл role.yaml для создания роли deployer:
kubectl -n stage apply -f role.yaml Наконец, в файле rb.yaml (Role Binding) сервисный аккаунт и роль связываются друг с другом:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deployer-rb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: deployer
subjects:
- kind: ServiceAccount
name: deployerПрименяем файл rb.yaml. После этого аккаунту deployer будет сопоставлена роль deployer:
kubectl -n stage apply -f rb.yamlСледует учесть, что созданные нами Role и Role Binding не кластерные, они относятся только к одному Namespace. В остальных Namespace аккаунту все будет запрещено. Для добавления доступа к нескольким Namespace нужно использовать Cluster Role и Cluster Role Binding. Логика работы с ними точно такая же.
Теперь применим команду set-credentials для добавления нового пользователя deployer-stage в kubectl config. При добавлении укажем токен, сохраненный ранее в переменную TOKEN:
kubectl config set-credentials deployer-stage --token=$TOKENТеперь мы можем работать под данным пользователем. Далее изменяем текущий контекст, выбирая пользователя deployer-stage:
kubectl config set-context --current --user=deployer-stageИ можем проверить созданные ограничения доступа. Попробуем вывести поды в Namespace stage с помощью kubectl -n stage get pods:

Команда выполнилась успешно, а теперь попробуем вывести поды в Namespace default с помощью kubectl get pods default:

Команда завершилась с ошибкой Forbidden и сообщением «User “system:serviceaccount:stage:deployer” cannot list resource “pods” in API group ““ in the namespace “default”».
Также мы не добавляли пользователю права на выполнение pods exec, то есть заходить внутрь пода — поэтому мы, например, не сможем выполнить команду kubectl -n stage exec -it ubuntu -- bash:

Но созданного пользователя вполне хватит для того, чтобы деплоить наши изменения.
Теперь нам остается лишь добавить переменную в GitLab. Для этого копируем содержимое обновленного файла kub-vc-dev_kubeconfig.yaml в значение новой переменной KUBECONFIG в GitLab:
cat ~/Downloads/kub-vc-dev_kubeconfig.yamlИ видим содержимое файла kub-vc-dev_kubeconfig.yaml:

При копировании важно в секции users оставить только добавленного нами пользователя deployer-stage с его токеном. Остальных пользователей необходимо убрать при добавлении значения переменной.
В качестве типа переменной необходимо выбрать File. Это означает, что в переменной KUBECONFIG будет путь к файлу с введенным содержимым. Это важно, так как kubectl будет смотреть на этот файл:

Последняя переменная, которую нам необходимо заполнить в GitLab — это HELM_GPG_KEY. Она связана с использованием утилиты Sops для шифрования секретов. Давайте перейдем в папку Infra. У нас здесь находятся файлы values и secrets для сред prod и stage:

В файлах values мы храним открытые переменные, например, информацию по Ingress, public_env_variables и так далее. Это все можно отдавать в открытый доступ:
ingress:
annotations: {}
fqdn: api.dev.kis.im
public_env_variables:
LISTEN: ":8080"А в файлах secrets у нас хранятся зашифрованные переменные: RABBIT_URI, PGSQL_URI и так далее. Посмотрим cat secrets.stage.yaml:

Для шифрования используется Sops — утилита от создателей Mozilla, которая применяет PGP-ключи для шифрования и дешифрования файлов. Для просмотра ключей можно вызвать команду gpg -k:
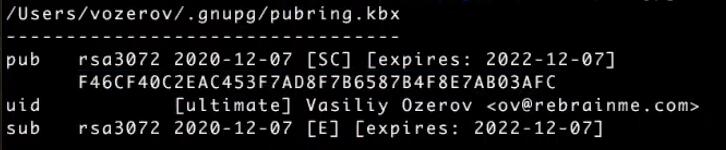
Для демонстрации работы Sops создадим новый текстовый файл test.txt, используя публичную часть PGP-ключа:
sops --pgp F46CF40C2EAC453F7AD8F7B6584B4F8E7AB03AFC text.txtВнутри файла укажем некоторый текст и сохраним его:

Теперь при открытии файла в поле data можно увидеть зашифрованное значение:

Чтобы дешифровать файл, применим команду sops –d test.txt:

То есть логика такая: вы создаете у себя локально PGP-ключ, с помощью него и Sops выполняете шифрование секретных переменных и отправляете все в Git-репозиторий. А для того, чтобы это расшифровали члены вашей команды, вы передаете им приватную часть PGP-ключа, например, через One Time Secret или One Password. Они импортируют ключ себе и после этого могут работать с секретными переменными.
Конечно, использовать Sops необязательно, это один из возможных вариантов работы с секретами. Но в нашем проекте мы его используем — поэтому заполним переменную HELM_GPG_KEY значением приватной части PGP-ключа. Для этого возьмем публичную часть ключа и применим к ней команду:
gpg --armor --export-secret-key --ex F46CF40C2EAC453F7AD8F7B6584B4F8E7AB03AFCСоздадим в GitLab переменную HELM_GPG_KEY и скопируем в нее результат вывода предыдущей команды:

Вернемся к файлу gitlab-ci.yml, чтобы пояснить работу с ключами PGP. Здесь сначала происходит импорт приватной части ключа из переменной HELM_GPG_KEY. Затем с использованием плагина secrets секреты расшифровываются и передаются в helm, который выполняет деплой:
# Setup GPG for Helm secrets
- echo "$HELM_GPG_KEY" > .helm_secrets_gpg_key.key
- gpg --allow-secret-key-import --import .helm_secrets_gpg_key.key
# Deploy via Helm
- cd .infra/
- helm secrets upgrade --wait --install converter-api --namespace ${KUBE_NAMESPACE} --values values.${BUILD_VARIANT}.yaml --values secrets.${BUILD_VARIANT}.yaml --set image.tag=${CI_COMMIT_SHORT_SHA} chart/Теперь кратко пройдемся по описанию нашего Helm-чарт. Переходим в папку /app-git/.infra/chart. Основное, что здесь есть — это папка templates, в которой описаны все ресурсы, которые необходимо создать для приложения:

Открываем deployment.yaml. В нем указываются метаданные, Labels, количество реплик, селекторы и так далее.
Здесь стоит обратить внимание на environment-переменные. Переменные из public_env_variables сразу прописываются в Deployment. Приватные переменные из private_env_variables предварительно создаются в секретах, а здесь для них в секции valueFrom указывается, в каком они находятся секрете и под каким ключом. Сами секреты создаются в secret.yaml:
env:
{{- range $key, $value := .Values.public_env_variables }}
- name: {{ $key }}
value: {{ $value | quote }}
{{- end }}
{{- range $key, $value := .Values.private_env_variables }}
- name: {{ $key }}
valueFrom:
secretKeyRef:
name: {{ $root.Chart.Name }}-env
key: {{ $key }}
{{- end }}Выполняем отправку всех внесенных изменений в GitLab и переходим к запуску наших пайпланов. Сначала выполняем Build:

Затем деплоим на Dev и Prod:

В случае успешной сборки можно применить команду helm -n stage list и увидеть наш релиз converter-api, который автоматически создаст все необходимые ресурсы:

Например, если применить команду kubectl -n stage get ingress, то можно увидеть добавленный converter-api-chart:

Соответственно, с этого момента все изменения можно отправлять в Git: чарты, переменные и так далее. Будет производиться автоматический деплой, а ручные действия больше не понадобятся.
Выводы: чему мы научились
Мы с вами рассмотрели основные этапы построения Cloud-Native приложения на базе Kubernetes-кластера. Подобрали оптимальную архитектуру для нужд нашей системы и последовательно добавили все необходимые компоненты: API-сервер, брокер сообщений RabbitMQ, базу данных PostgreSQL, бакет S3 и обработчики, отвечающие за конвертацию видео в текст. Много работали непосредственно с самим кластером: выполнили его настройку в облаке и познакомились с большим количеством команд его клиента kubectl. Научились деплоить приложения как через YAML-файлы, так и через Helm Charts. Наконец, коснулись таких важных моментов, как автомасштабирование, мониторинг и построение CI/CD-конвейеров.
Разумеется, мы охватили далеко не все возможности K8s. Да и приложение было далеко не самым сложным. Однако перед собой я ставил цель показать вам, что Kubernetes, о котором многие пишут и говорят, но далеко не все решаются использовать, не так сложен на практике. А при использовании Managed-решений от облачных провайдеров работа с Kubernetes-кластером становится по-настоящему удобной и быстрой: как минимум, сокращается время настройки и уменьшаются затраты на оборудование благодаря автомасштабированию.
Надеюсь, представленная в статье информация поможет вам начать работу с Kubernetes либо вывести ее на более качественный уровень.
Новым пользователям платформы Mail.ru Cloud Solutions доступны 3000 бонусов после полной верификации аккаунта. Вы сможете повторить сценарий из статьи или попробовать другие облачные сервисы.
Что еще почитать по теме:
