

Антиспам Почты Mail.ru — это симбиоз продуктовой логики и инфраструктурных технологий, про который мы решили более подробно рассказать. В основе конечно же лежит инфраструктура, с помощью которой мы получаем возможности для развития моделей машинного обучения, а также платформа ядра, которая обеспечивает работу антиспама в онлайне. Продуктовая логика представлена в виде большого количества эвристик (куда без них) и ручных правил. На вершине продуктовой пирамиды пребывает стек моделей машинного обучения, хотя положение на вершине в данном случае достаточно условно.
В этой статье мы заберемся на эту вершину, где в последнее время часто вбивают новые колышки текстовые модели. Мы спроецируем мир текстовых ML-моделей на наш сервис, поговорим про эволюцию и решение задач Почты, связанных с текстами. Запасайтесь кислородом и свободным временем.
Сегодня наш сервис содержит больше 20 систем машинного обучения, ежедневно обслуживает около 20 млн активных пользователей (без учёта ботов) и обрабатывает 1,5 млрд писем, из которых около 80 % — спам. Примечательно, что из года в год доля спама в общем объёме растёт, в связи с чем может показаться, что мы всё хуже справляемся со своей работой. Но это не так: количество спама, доходящего до пользователей, снижается. А рост доли означает, что спамерам приходится привлекать всё больше ресурсов, чтобы обеспечить доставляемость хотя бы на прежнем уровне.
Ключевые вызовы сервиса
По понятным причинам я не буду останавливаться на том, как именно мы отсеиваем спам. Вместо этого обозначу лишь ключевые проблемы, стоящие перед нами. С течением времени формулировки проблем значительно не меняются, но сами они постоянно раскрываются для нас новыми гранями. Самая важная проблема заключается в том, что нам противостоят люди, которые всё время адаптируются к нашим решениям. Это означает, что решения со временем деградируют, как из-за адаптации спамеров, так и из-за того, что меняются какие-то паттерны переписки и рассылок. В контексте этой статьи отдельно остановлюсь и на сравнительно новой для нас проблеме — тенденции смещения вектора спамерских атак на тексты.
Почему именно тексты? Здесь, скорее всего, сразу несколько причин. Во-первых, потому что тексты гораздо легче генерировать с бо̒льшим разнообразием, чем другие признаки письма. Можно сравнительно недорого создать большую рассылку, наполненную текстом разного качества. Это облегчает спамерам и задачу ценообразования на свои услуги. Чем хуже и менее разнообразен текст в рассылке, тем он дешевле для спамера. Наиболее продвинутые могут использовать самые передовые решения, создавая такие рассылки, которые нашим системам значительно сложнее освоить.

Но более важная причина смещения внимания на текст связана с тем, что это по-прежнему самый понятный способ передачи информации в почтовом сервисе. Пользователи всё ещё ассоциируют почту главным образом с текстовой информацией.
Мы же, в свою очередь, очень благодарны спамерам за выбранную тенденцию, потому что задачи NLP — помимо хайпа — ещё и очень интересная сфера для поиска новых вдохновений, а также проверки наших ресурсов и возможностей на прочность.
Эволюция NLP в антиспаме
Давайте коротко проследим эволюцию текстовых задач в сервисе. Шкала упрощённая, и какие-то подходы применялись одновременно, но здесь будут показаны линейно.
Всё началось с очень простых, незамысловатых намерений (которые мы будем называть интентами) в письмах, не более одного на письмо. Паттерны были очень узки. Наверняка многие из вас на рубеже нулевых и десятых годов получали так называемые нигерийские письма. Смысл примерно следующий: у вас, о чудо, обнаруживается африканский родственник, у которого обнаруживается много денег, которыми он готов с вами поделиться прямо сейчас, только надо ему реквизиты предоставить. Примерно сразу же вслед за этим спамерская мысль переключилась на фишинг. Паттернов тоже было немного, но теперь злоумышленники пытались выманить учётную информацию ваших аккаунтов в разных сервисах.
Постепенно методы и задачи спамеров усложнялись, ширилось их разнообразие. Начали рассылать письма с предложением лёгкого заработка, в которых содержались всевозможные стимулы перейти по ссылкам и обеспечить спамерам CTR. После того, как мы научились успешно бороться с этой проблемой, спамеры нашли способы зашумления содержимого писем так, чтобы нам было сложнее распознать фрагмент, который отвечает за спам. Сначала они делали это с помощью легитимных форм в так называемом порождённом спаме, а со временем — с помощью зашумления различного рода, с добавлением фрагментов из книг или просто абракадабры. Также не забудем, что тексты можно прятать в картинки. Спамеры вот не забыли.
Теперь наконец стоит перейти от спамерской активности к нашей и поговорить про эволюцию текстовых моделей в сервисе. Первые упрощённые паттерны мы использовали сообразно сложности проблемы — простыми линейными классификаторами над мешком слов. Они хорошо работали, несмотря на ограниченный словарь. Как нам всем неплохо известно, проблема bag-of-words — низкая способность к обобщению. Поэтому, как только спам усложнялся и прежние инструменты переставали работать, мы начинали искать новые решения. В этом контексте очень удачно подоспел Facebook со своей моделью FastText. Это позволило нам получить решение нового уровня — глубоко (хотя, как видно с высоты 2021 года, на самом деле совсем неглубоко) обученные эмбеддинги писем.
FastText оказался хорошей штукой, которая позволила решить проблемы второй волны усложнения интента — первые незашумлённые заработки, а также порожденный спам. Но у этих моделей есть один серьёзный изъян: эмбеддинг всего письма формируется как усреднение эмбеддингов входящих в него слов. Такое усреднение естественным образом приводит к потере существенной информации для классификаторов. Таким образом, мы уперлись в потолок неглубоких подходов, столкнувшись при этом с отсутствием инструментов для того, чтобы подружить углубление моделей с жесткими ограничениями онлайн-продакшена.
В этом контексте такое событие, как появление PyTorch, стало определяющим для всей индустрии (окей, для нашей скромной команды). Благодаря этому фреймворку появилась возможность бесшовно подружить Python-обучения и С++ инференс. Более того, PyTorch обеспечил нам единый API для различных ML-архитектур в эксплуатации. Чем мы не преминули воспользоваться и с течением времени существенно обогатили наш модельный ряд.
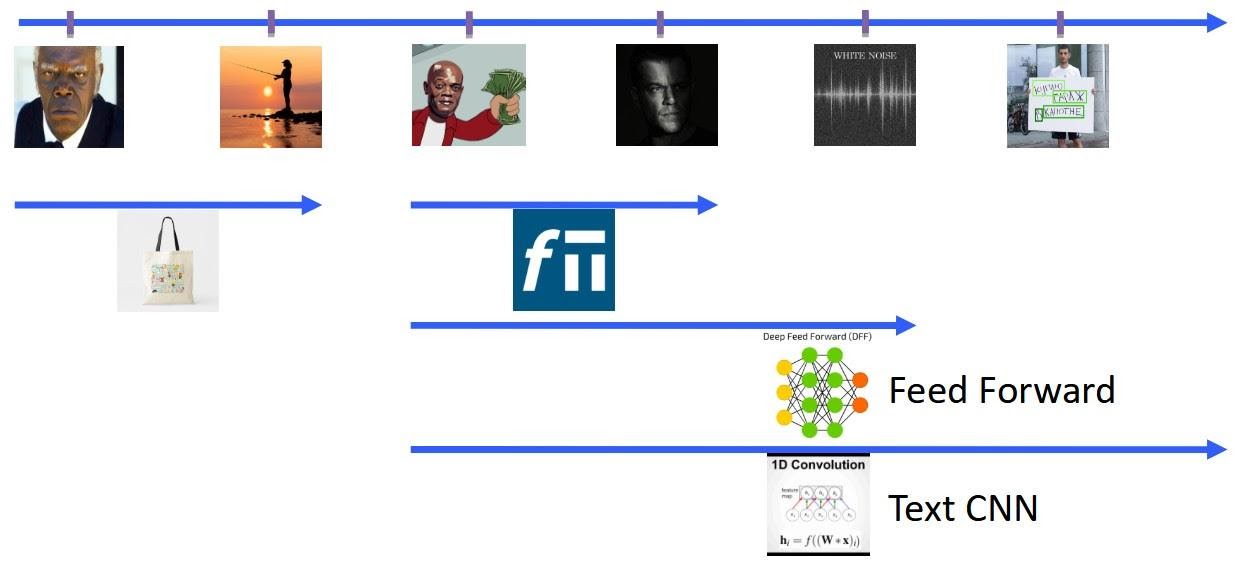
Сначала перешли от линейных моделей над эмбедингами FastText к полносвязным (FeedForward) моделям различной степени глубины в надежде на то, что нелинейности частично решат проблему усреднения. Так и оказалось, качество на датасетах заметно подросло. В конечном счете пришли к варианту с классификаторами на основе текстовых свёрток (TextCNN) над словарными эмбеддингами. Эту концепцию мы позаимствовали у коллег из компьютерного зрения и радостно её адаптировали. Забегая вперёд, получилось очень круто, а почему — поймём после описания критериев.
Критерии оценки моделей
Рассмотрим критерии, по которым мы оцениваем свои модели. Помимо очевидной основы в виде оценки качества на обучающих выборках и в эксплуатации мы выделили для себя 4 критерия:
- Новые слова. Возможность адаптации под изменение словаря сервиса, то есть возможность не ломаться под натиском новых слов. Не все модели этому удовлетворяют.
- Интерпретируемость модели. Насколько мы понимаем решение наших моделей, видим их сильные и слабые стороны. Чем лучше мы понимаем модели, тем больше нового можем узнать о домене в процессе их эксплуатации.
- Учёт контекста. Одни и те же слова в разном контексте имеют разное значение. Если модели не умеют это определять, то возникает очевидная дыра для спамеров.
- Механизм Attention. Возможность на уровне архитектуры (возможно, неявно) выделять более и менее значимые части писем. В противном случае приходится действовать «в среднем по больнице», теряя суть спамного интента, намеренно упрятанного спамерами среди прочей болтовни.
Как разные модели соответствуют этим критериям? Модели на Bag of Words удовлетворяют только интерпретируемости, с которой у всех прочих моделей как раз всё сложно. Стандартный FastText-классификатор при этом по умолчанию не умеет attention. Похожие проблемы сохраняются и у FeedForward-классификатора поверх эмбеддинга FastText, с той лишь разницей, что «усреднение по больнице» происходит нелинейно.
Полноценным attention обладает из рассмотренного нами семейства моделей только TextCNN поверх словарных эмбеддингов (все совпадения параметров слоев на картинке с нашими моделями абсолютно случайны).
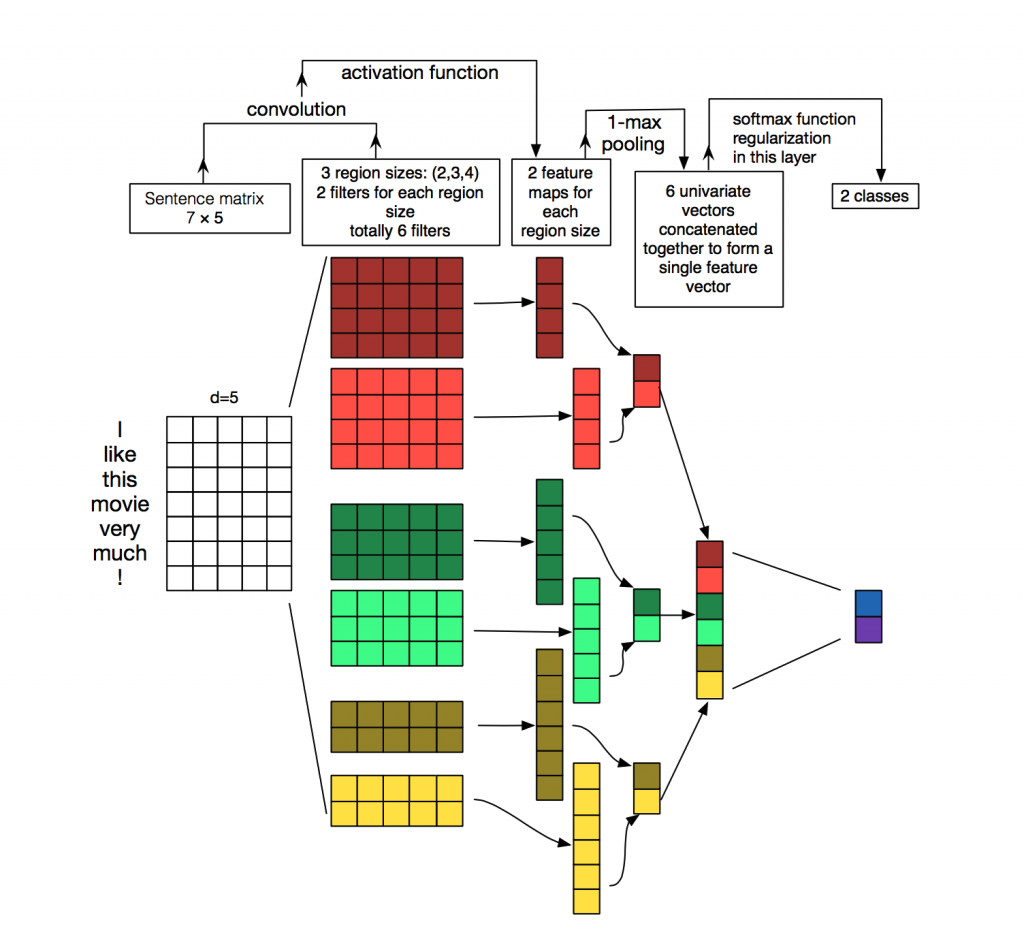
У таких моделей вообще всё хорошо, кроме интерпретации. Вспоминая про качество на выборках, мы и тут обнаруживаем прирост в несколько процентов. И вообще кажется, что со свёрточными сетями мы достаточно близко подошли к идеалу.
Проблема будущих нас
Но давайте в карандаше нарисуем картинку относительно недалёкого будущего, чтобы понять, что может пойти не так. Вспомним, что спамный интент постоянно усложняется, а с ним и наши решения. Это означает, что с каждым новым усложнением мы медленнее реагируем на него, потому что нужно подбирать всё более сложную модель, адаптировать и обучать с нуля. Кроме того, мы расширяем наш парк моделей, что удорожает эксплуатацию.
Хочется придумать универсальное решение, позволяющее выявлять любые спамерские намерения до их осуществления. Это позволит нам превентивно реагировать на новые ходы. По сути, у нас появляется пятый критерий для оценки моделей: обобщаемость. Модель должна уметь решать задачи, на которых она изначально не была обучена. Кто-то из вас, наверное, уже слышит шёпот таких терминов, как transfer learning и, конечно же, трансформеры. Эту, самую интересную, часть нашего пути подробно разберём во второй части — stay tuned.
