Добрый день.
Логи часто и абсолютно не заслуженно обделены вниманием разработчиков. И когда программистам необходимо пропарсить log-файлы, иногда с нескольких десятков серверов одновременно, задача эта ложится на системных администраторов и отнимает у них много времени и сил.
Поэтому, когда случаются проблемы и надо найти ошибку в логах какого-нибудь сервиса, все зависит от того, насколько силен админ и насколько программисты знают, что искать. А еще от того, отработал ли logrotate и не грохнул ли он старые данные…
В таких ситуациях отлично помогает Logstash. Он активно развивается последний год, уже наделал много шуму, и на хабре, например тут и тут, достаточно статей о том, как его поставить и заставить работать на одном сервере. В этой статье я затрону Logstash в качестве сервера обработки, потому что, как агент, он по некоторым параметрам нам не подошел.
Почему? Maxifier представляет собой SaaS-продукт с клиентами в США, Бразилии, в нескольких странах Европы и в Японии, так что у нас около сотни серверов, раскиданных по всему миру. Для оперативной работы нам необходимо иметь удобный доступ к логам наших приложений и быстрый поиск ошибок в них в случае проблем на сторонних сервисах/api, появления некорректных данных т.д. Кстати, похожей системой сборки логов пользуются The Guardian (одни из наших клиентов).
После нескольких случаев сборки логов Rsync-ом со множества серверов мы задумались над альтернативой, менее долгой и трудоемкой. И недавно мы разработали свою систему сборки логов для разных приложений. Поделюсь собственным опытом и описанием, как это работает.

Наши целевые приложения, с которых собираем логи:
1. Демоны на Java (Jetty/Native)
2. Демоны на Node.js
3. Динамически запускаемые Java-приложения (например, узлы кластера)
Критичными для программистов являются ошибки и исключения с многострочными стектрейсами, пролетающими при таких ошибках.
Поэтому главными требованиями были:
1. Хорошая поддержка мультистрочных сообщений.
2. Возможность обработки разного формата сообщений.
3. Легкое конфигурирование источников данных.
Не вдаваясь глубоко в часть конфигурирования, расскажу про составные части и почему они присутсвуют в схеме.
В целом наша схема сбора логов выглядит вот так:
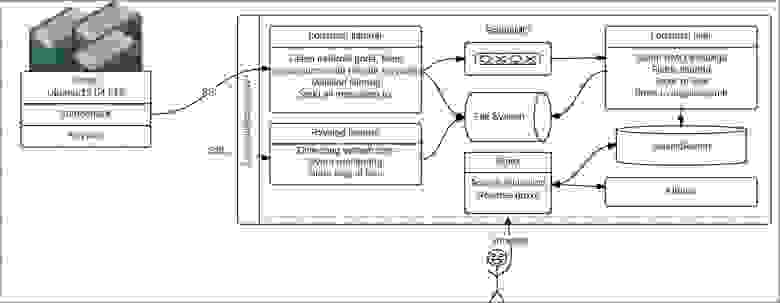
На схеме видно, что мы не держим logstash, который мониторил бы файлы приложений на серверах приложений. Мы посчитали, что неэффективно использовать демона, который во время записи логов потребляет 128 мб памяти и значительную часть мощностей процессора, а насильное ограничение ресурсов тут выглядело бы, как костыль. Поэтому мы стали искать другие, менее требовательные решения для проблемы транспортировки логов.
Rsyslog — уже готовый демон логирования и умеет, казалось бы, все, но дело всегда в мелочах.
Преимущества:
1. Быстр.
2. Умеет отслеживать файлы.
3. Умееткопать и не копать шифровать и не шифровать.
4. Уже есть в системе.
Недостатки:
1. Не умеет пересылать мультистрочные сообщения (Все попытки на сервере получить мультистрочное сообщение целиком оказались тщетны).
2. Не умеет отслеживать файлы по маске.
3. Плохо обрабатывает file truncation.
Как уже говорилось, нам была важна поддержка мультистрочных сообщений, поэтому мы продолжили поиски, но временно подключили сборку логов Rsyslog, чтобы потом организовать поиск по ним.
Lumberjack (ныне известный как logstash-forwarder) — экспериментальный демон для пересылки логов.
Преимущества:
1. Быстр.
2. Минималистичен (Unix-way).
3.Умеет использовать маски.
4. Потребляет минимум ресурсов (написан на Go).
Недостатки:
1. Экспериментальный.
2. Самостоятельно не поддерживает мультистрочные сообщения.
Logstash (только как агент)
Преимущества:
1. Один и тот же софт для сбора логов везде.
2. Достаточно производительный.
3. Умеет все, что нам нужно.
Недостатки:
1. Java на всех серверах.
2. Высокие требования к памяти, потенциально может влиять на работу других сервисов.
3. Сложный в настройке.
Мы решили протестировать Lumberjack, а если результат не устроит, откатиться на вариант с Logstash на каждом сервере.
Так как Logstash и Lumberjack разрабатывали одни и те же люди, то в придачу мы получили приятные плюшки: например, дополнительные поля — с ними мы смогли узнавать тип приложения логов без парсинга имен файлов.
Мы потестировали этот демон, и единственный баг, который в нем нашли, — когда кончается место, он не может записать state-файл и передает повторные сообщения с предыдущего места или же может не заметить, что файл был зачищен. Мы обычно не допускаем такого, да и все приходит в норму, когда место появляется.
В целом Lumberjack как агент нам понравился. Конфигурация предельно простая, умеет искать по маскам и отлично отслеживает большое количество файлов. Тем более, есть хороший модуль для Puppet, с помощью которого мы без проблем настроили наши серверы. Параллельно с выбором агента мы тестировали logstash — тогда еще он был в версии 1.1.12.
В первую же очередь мы попытались обработать с его помощью мультистрочные сообщения сначала от rsyslog, потом от lumberjack.
Сначала мы попробовали большие регулярные выражения, которые выдает Google на GitHub Gist, но в конечном счете мы пришли к выводу, что лучший вариант — все, что не попадает под наш таймстамп, считать частью предыдущего сообщения. Тем более, Lumberjack никак не видоизменял сообщения от сервиса.
В результате вот такой простой паттерн:
Мы поставили один инстанс Logstash обрабатывать входящие логи, дали ему несколько потоков и стали подключать сервера. Все вроде было бы хорошо, но стали замечать, что время от времени сервер сбрасывал соединения, упирался в память и периодически падал. Даже на 16 Gb в Xmx не давали нужного эффекта.
Мы решили распределить нагрузку на два типа инстансов, и в общем не прогадали.
Первый тип инстансов (1) только слушает tcp соединения и сохраняет raw-файлы (по ним удобно отлаживать фильтры), склеивает мультистрочные сообщения и отправляет их в шину. Он вполне справляется со своей задачей, приводя к загрузке 100% двух ядер в пиковые моменты (наш пик 2500-3000 сообщений в секунду).
Второй тип инстансов (2) забирает сообщения из шины, разделяет их на поля, складывает в elasticsearch и, на всякий случай, в файлы. И, как оказалось, самыми проблематичными были именно инстансы второго типа — то памяти перестанет хватать, то elasticsearch залихорадит. Но благодаря шине данные не терялись, и в инстансах первого типа (1) логи по-прежнему продолжали собираться.
Разгрузка инстанса первого типа привела к тому, что сервер мониторинга в целом потребляет минимум ресурсов и при этом способен в пики выдерживать достаточно большое количество сообщений в единицу времени самостоятельно. Фильтрующие инстансы (второго типа) могут быть ограничены в ресурсах и можно сильно не заботиться об их производительности.
Эта связка проработала у нас около месяца, пока мы не встретили очень странное поведение. Lumberjack-агенты на серверах начали лихорадочно переподключаться к Logstash и тут же отваливались с сообщением о том, что не могут достучаться до слушающего Logstash и вообще там i/o timeout, а слушающий Logstash при беглом взгляде на него казался живым и даже посылал сообщения в шину.
Zabbix отрапортовал, что у процесса закачивается PermGen, мы увеличили память и перезапустили, буквально через 10 минут ситуация повторилась.
Мы начали разбираться, какой из серверов генерирует сообщения, приводящие Logstash в ступор. После недолгих поисков (кстати легко ищется по тому, кто больше всех слал сообщений — об этом Lumberjack сообщает в Syslog), на одном из серверов был обнаружен лог размером в ~ 20 Gb, и он включал в себя несколько строк обьемом по 2-3Gb. Нетрудно догадаться, что происходило: Logstash потихоньку формировал у себя эту строку в памяти, пока не упирался в нее и дальше уже пытался что-то с этим сделать. Для таких случаев мы добавили разделитель для фильтрования подобных сообщений и попросили разработчиков больше так не делать.
Были проблемы и со слишком подробными логами, например Node.js-ного логгера bunyan, на выходе у него было до 30-40(!) полей, естественно в интерфейсе это выглядело ужасно. Тут мы рассудили просто:
1) убирали ненужные поля;
2) переделали приоритет сообщений в человекочитаемый вид.
Не вызвал больших проблем за период использования. 3-гиговый инстанс Elasticsearch нормально обрабатывает индексы и по 5-6 Гб архивированных данных за день. Единственное, что иногда случается, — OutOfMemory, когда пытаются запихнуть большое сообщение или спросить слишком сложный запрос. Но JMX-мониторинг никто не отменял, и Zabbix нормально уведомляет о том, что GC как-то долго работает и было бы неплохо взглянуть на приложение.
Веб-интерфейс Kibana в своем первоначальном виде оказался, мягко выражаясь, сложным даже для программистов, и тем более для людей, далеких от IT (наши аналитики тоже иногда заглядывают в логи). Мы взяли за основу исходный дашбоард, настроили его под свои нужды и заменили им дефолтный дашбоард в Kibana. Теперь он выглядит вот так:

В особо сложных случаях приходится дополнительно подстраивать фильтры и мультипоиск, но случается такое редко и больших проблем не вызывает.
1.Lumberjack — отлично подходит на роль агента сбора логов.
2. Logstash — нормально парсит stacktrace и абсолютное разные логи и нет проблем с гибкостью, но надо адаптировать под свои требования.
3. Kibana — опять же надо адаптировать под потребителя. Иногда работу упрощает даже простое переименовывание полей.
Конечно, есть кейсы, которые данной схемой не покрыть, например, когда надо просто посмотреть конкретный запуск приложения и что происходило, — веб-интерфейс тут наверное не помошник, хотя это, конечно, на вкус и цвет.
Описанная система сборки логов позволила снять с админов часть нагрузки и существенно уменьшила трату их времени и нервов. Да и программистам так гораздо удобнее — теперь, когда возникает ошибка, мы просто даём разрабочикам ссылки на логи в web-интерфейсе вместо неудобной кучи log-файлов. Сейчас система обрабатывает более 1 миллиона сообщений в день от более чем 300 инстансов приложений, не создавая ощутимой нагрузки. Это не предел наших потребностей, скорее всего, цифра увеличится как минимум вдвое, и есть уверенность, что система сможет принять и такую нагрузку.
Kibana config
Логи часто и абсолютно не заслуженно обделены вниманием разработчиков. И когда программистам необходимо пропарсить log-файлы, иногда с нескольких десятков серверов одновременно, задача эта ложится на системных администраторов и отнимает у них много времени и сил.
Поэтому, когда случаются проблемы и надо найти ошибку в логах какого-нибудь сервиса, все зависит от того, насколько силен админ и насколько программисты знают, что искать. А еще от того, отработал ли logrotate и не грохнул ли он старые данные…
В таких ситуациях отлично помогает Logstash. Он активно развивается последний год, уже наделал много шуму, и на хабре, например тут и тут, достаточно статей о том, как его поставить и заставить работать на одном сервере. В этой статье я затрону Logstash в качестве сервера обработки, потому что, как агент, он по некоторым параметрам нам не подошел.
Почему? Maxifier представляет собой SaaS-продукт с клиентами в США, Бразилии, в нескольких странах Европы и в Японии, так что у нас около сотни серверов, раскиданных по всему миру. Для оперативной работы нам необходимо иметь удобный доступ к логам наших приложений и быстрый поиск ошибок в них в случае проблем на сторонних сервисах/api, появления некорректных данных т.д. Кстати, похожей системой сборки логов пользуются The Guardian (одни из наших клиентов).
После нескольких случаев сборки логов Rsync-ом со множества серверов мы задумались над альтернативой, менее долгой и трудоемкой. И недавно мы разработали свою систему сборки логов для разных приложений. Поделюсь собственным опытом и описанием, как это работает.

Наши целевые приложения, с которых собираем логи:
1. Демоны на Java (Jetty/Native)
2. Демоны на Node.js
3. Динамически запускаемые Java-приложения (например, узлы кластера)
Критичными для программистов являются ошибки и исключения с многострочными стектрейсами, пролетающими при таких ошибках.
Поэтому главными требованиями были:
1. Хорошая поддержка мультистрочных сообщений.
2. Возможность обработки разного формата сообщений.
3. Легкое конфигурирование источников данных.
Не вдаваясь глубоко в часть конфигурирования, расскажу про составные части и почему они присутсвуют в схеме.
В целом наша схема сбора логов выглядит вот так:

На схеме видно, что мы не держим logstash, который мониторил бы файлы приложений на серверах приложений. Мы посчитали, что неэффективно использовать демона, который во время записи логов потребляет 128 мб памяти и значительную часть мощностей процессора, а насильное ограничение ресурсов тут выглядело бы, как костыль. Поэтому мы стали искать другие, менее требовательные решения для проблемы транспортировки логов.
Агенты
Rsyslog — уже готовый демон логирования и умеет, казалось бы, все, но дело всегда в мелочах.
Преимущества:
1. Быстр.
2. Умеет отслеживать файлы.
3. Умеет
4. Уже есть в системе.
Недостатки:
1. Не умеет пересылать мультистрочные сообщения (Все попытки на сервере получить мультистрочное сообщение целиком оказались тщетны).
2. Не умеет отслеживать файлы по маске.
3. Плохо обрабатывает file truncation.
Как уже говорилось, нам была важна поддержка мультистрочных сообщений, поэтому мы продолжили поиски, но временно подключили сборку логов Rsyslog, чтобы потом организовать поиск по ним.
Lumberjack (ныне известный как logstash-forwarder) — экспериментальный демон для пересылки логов.
Преимущества:
1. Быстр.
2. Минималистичен (Unix-way).
3.Умеет использовать маски.
4. Потребляет минимум ресурсов (написан на Go).
Недостатки:
1. Экспериментальный.
2. Самостоятельно не поддерживает мультистрочные сообщения.
Logstash (только как агент)
Преимущества:
1. Один и тот же софт для сбора логов везде.
2. Достаточно производительный.
3. Умеет все, что нам нужно.
Недостатки:
1. Java на всех серверах.
2. Высокие требования к памяти, потенциально может влиять на работу других сервисов.
3. Сложный в настройке.
Выбор агента
Мы решили протестировать Lumberjack, а если результат не устроит, откатиться на вариант с Logstash на каждом сервере.
Так как Logstash и Lumberjack разрабатывали одни и те же люди, то в придачу мы получили приятные плюшки: например, дополнительные поля — с ними мы смогли узнавать тип приложения логов без парсинга имен файлов.
Мы потестировали этот демон, и единственный баг, который в нем нашли, — когда кончается место, он не может записать state-файл и передает повторные сообщения с предыдущего места или же может не заметить, что файл был зачищен. Мы обычно не допускаем такого, да и все приходит в норму, когда место появляется.
В целом Lumberjack как агент нам понравился. Конфигурация предельно простая, умеет искать по маскам и отлично отслеживает большое количество файлов. Тем более, есть хороший модуль для Puppet, с помощью которого мы без проблем настроили наши серверы. Параллельно с выбором агента мы тестировали logstash — тогда еще он был в версии 1.1.12.
Logstash
В первую же очередь мы попытались обработать с его помощью мультистрочные сообщения сначала от rsyslog, потом от lumberjack.
Сначала мы попробовали большие регулярные выражения, которые выдает Google на GitHub Gist, но в конечном счете мы пришли к выводу, что лучший вариант — все, что не попадает под наш таймстамп, считать частью предыдущего сообщения. Тем более, Lumberjack никак не видоизменял сообщения от сервиса.
В результате вот такой простой паттерн:
filter {
multiline {
pattern => "(^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})"
negate => true
what => "previous"
}
}
Мы поставили один инстанс Logstash обрабатывать входящие логи, дали ему несколько потоков и стали подключать сервера. Все вроде было бы хорошо, но стали замечать, что время от времени сервер сбрасывал соединения, упирался в память и периодически падал. Даже на 16 Gb в Xmx не давали нужного эффекта.
Мы решили распределить нагрузку на два типа инстансов, и в общем не прогадали.
Первый тип инстансов (1) только слушает tcp соединения и сохраняет raw-файлы (по ним удобно отлаживать фильтры), склеивает мультистрочные сообщения и отправляет их в шину. Он вполне справляется со своей задачей, приводя к загрузке 100% двух ядер в пиковые моменты (наш пик 2500-3000 сообщений в секунду).
Второй тип инстансов (2) забирает сообщения из шины, разделяет их на поля, складывает в elasticsearch и, на всякий случай, в файлы. И, как оказалось, самыми проблематичными были именно инстансы второго типа — то памяти перестанет хватать, то elasticsearch залихорадит. Но благодаря шине данные не терялись, и в инстансах первого типа (1) логи по-прежнему продолжали собираться.
Разгрузка инстанса первого типа привела к тому, что сервер мониторинга в целом потребляет минимум ресурсов и при этом способен в пики выдерживать достаточно большое количество сообщений в единицу времени самостоятельно. Фильтрующие инстансы (второго типа) могут быть ограничены в ресурсах и можно сильно не заботиться об их производительности.
Эта связка проработала у нас около месяца, пока мы не встретили очень странное поведение. Lumberjack-агенты на серверах начали лихорадочно переподключаться к Logstash и тут же отваливались с сообщением о том, что не могут достучаться до слушающего Logstash и вообще там i/o timeout, а слушающий Logstash при беглом взгляде на него казался живым и даже посылал сообщения в шину.
Zabbix отрапортовал, что у процесса закачивается PermGen, мы увеличили память и перезапустили, буквально через 10 минут ситуация повторилась.
Мы начали разбираться, какой из серверов генерирует сообщения, приводящие Logstash в ступор. После недолгих поисков (кстати легко ищется по тому, кто больше всех слал сообщений — об этом Lumberjack сообщает в Syslog), на одном из серверов был обнаружен лог размером в ~ 20 Gb, и он включал в себя несколько строк обьемом по 2-3Gb. Нетрудно догадаться, что происходило: Logstash потихоньку формировал у себя эту строку в памяти, пока не упирался в нее и дальше уже пытался что-то с этим сделать. Для таких случаев мы добавили разделитель для фильтрования подобных сообщений и попросили разработчиков больше так не делать.
Были проблемы и со слишком подробными логами, например Node.js-ного логгера bunyan, на выходе у него было до 30-40(!) полей, естественно в интерфейсе это выглядело ужасно. Тут мы рассудили просто:
1) убирали ненужные поля;
2) переделали приоритет сообщений в человекочитаемый вид.
Elasticsearch
Не вызвал больших проблем за период использования. 3-гиговый инстанс Elasticsearch нормально обрабатывает индексы и по 5-6 Гб архивированных данных за день. Единственное, что иногда случается, — OutOfMemory, когда пытаются запихнуть большое сообщение или спросить слишком сложный запрос. Но JMX-мониторинг никто не отменял, и Zabbix нормально уведомляет о том, что GC как-то долго работает и было бы неплохо взглянуть на приложение.
Интерфейс
Веб-интерфейс Kibana в своем первоначальном виде оказался, мягко выражаясь, сложным даже для программистов, и тем более для людей, далеких от IT (наши аналитики тоже иногда заглядывают в логи). Мы взяли за основу исходный дашбоард, настроили его под свои нужды и заменили им дефолтный дашбоард в Kibana. Теперь он выглядит вот так:

В особо сложных случаях приходится дополнительно подстраивать фильтры и мультипоиск, но случается такое редко и больших проблем не вызывает.
Краткое summary
1.Lumberjack — отлично подходит на роль агента сбора логов.
2. Logstash — нормально парсит stacktrace и абсолютное разные логи и нет проблем с гибкостью, но надо адаптировать под свои требования.
3. Kibana — опять же надо адаптировать под потребителя. Иногда работу упрощает даже простое переименовывание полей.
Конечно, есть кейсы, которые данной схемой не покрыть, например, когда надо просто посмотреть конкретный запуск приложения и что происходило, — веб-интерфейс тут наверное не помошник, хотя это, конечно, на вкус и цвет.
Результат
Описанная система сборки логов позволила снять с админов часть нагрузки и существенно уменьшила трату их времени и нервов. Да и программистам так гораздо удобнее — теперь, когда возникает ошибка, мы просто даём разрабочикам ссылки на логи в web-интерфейсе вместо неудобной кучи log-файлов. Сейчас система обрабатывает более 1 миллиона сообщений в день от более чем 300 инстансов приложений, не создавая ощутимой нагрузки. Это не предел наших потребностей, скорее всего, цифра увеличится как минимум вдвое, и есть уверенность, что система сможет принять и такую нагрузку.
Update
Logstash listener
input {
lumberjack {
charset => "CP1252"
port => 9999
ssl_certificate => "/etc/ssl/changeme.crt"
ssl_key => "/etc/ssl/changeme.key"
}
}
filter {
multiline {
pattern => "(^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})|(^\d+\))|(^{\")"
negate => true
what => "previous"
}
}
output {
file {
path => "/logs/raw/%{host}/%{+YYYY-MM-dd}.log"
}
rabbitmq {
durable => true
exchange => "logstash-exchange"
exchange_type => "direct"
host => "127.0.0.1"
key => "logstash-routing-key"
password => "changeme"
persistent => true
user => "logstash"
vhost => "logstash"
}
}
Logstash filter
input {
rabbitmq {
auto_delete => false
charset => "CP1252"
durable => true
exchange => "logstash-exchange"
exclusive => false
host => "127.0.0.1"
key => "logstash-routing-key"
password => "changeme"
prefetch_count => 4
queue => "logstash-indexer"
type => "logstash-indexer-input"
user => "logstash"
vhost => "logstash"
}
}
filter {
#ugly hack
date { match => ["@timestamp", "ISO8601"] }
mutate {
gsub => ['host', '.example.com', '']
}
#just in case 2 types of applications
if [type] == "custom" {
grok { match => ["message", "(?m)(?<date>\d{4}-\d{2}-\d{2}) (?<time>\d{2}:\d{2}(?::\d{2}(?:\.\d+)?)?) \[%{LOGLEVEL:level}\s?\] - (?<mxf_raw_message>.*)"] }
grok { match => ["message", "(?m)(?<mxf_datetime>\d{4}-\d{2}-\d{2} \d{2}:\d{2}(?::\d{2}(?:\.\d+)?)?) "] }
mutate { replace => ["mxf_datetime", "%{date}T%{time}Z" ] }
date {
match => ["mxf_datetime", "ISO8601"]
target => "mxf_timestamp"
}
mutate { remove_field => ["mxf_datetime"] }
grep {
match => [ "message", "\|" ]
add_tag => "have_id"
drop => false
}
if "have_id" in [tags] {
grok { match => ["message", "\[@%{HOSTNAME:mxf_host} %{GREEDYDATA:mxf_thread} (?<mxf_class>[a-z]{1}[.]{1}[a-z]{1}[.]{1}[a-zA-Z]{1}.*):%{NUMBER:mxf_classline}\|(?<mxf_id>.*):%{NUMBER:mxf_linenum}\]$"] }
#ugly hack for correct mapping
mutate { convert => [ "mxf_linenum", "integer" ] }
} else {
grok { match => ["message", "\[@%{HOSTNAME:mxf_host} %{GREEDYDATA:mxf_thread} (?<mxf_class>[a-z]{1}[.]{1}[a-z]{1}[.]{1}[a-zA-Z]{1}.*):%{NUMBER:mxf_classline}\]$"] }
}
grok { match => ["message", "(?m).*\] - (?<mxf_message>.*)\[@.*"] }
grok { match => ["file", "\/opt\/apps\/%{GREEDYDATA:mxf_version}\/logs\/%{GREEDYDATA:mxf_account}\/%{WORD:mxf_logfilename}.log$"] }
mutate { gsub => ["mxf_aiid","\|",""] }
}
if [type] == "nodejs" {
json { source => "message" }
mutate { rename => ["msg","mxf_message"] }
mutate { rename => ["args.0.code","mxf_response_code"] }
mutate { rename => ["data.service","mxf_service"] }
mutate { rename => ["data.method","mxf_method"] }
mutate { rename => ["t","mxf_request_time"] }
mutate { rename => ["pid","mxf_pid"] }
mutate { rename => ["err.name","mxf_errname"] }
mutate { rename => ["err.stack","mxf_stacktrace"]}
mutate { rename => ["err.message", "mxf_errmsg"] }
mutate { remove_field => ["0", "1", "2", "args", "http", "hostname", "msg", "v", "data", "err","t", "pid","io"] }
if [level] == 60 { mutate { replace => ["level","FATAL"] } }
if [level] == 50 { mutate { replace => ["level","ERROR"] } }
if [level] == 40 { mutate { replace => ["level","WARN"] } }
if [level] == 30 { mutate { replace => ["level","INFO"] } }
if [level] == 20 { mutate { replace => ["level","DEBUG"] } }
if [level] == 10 { mutate { replace => ["level","TRACE"] } }
}
}
output {
elasticsearch_http {
host => "127.0.0.1"
}
}
Kibana config
