Данными Mediascope ежедневно пользуется большинство участников медиарекламного рынка и каждый день наши клиенты совершают множество запросов как к самим данным, так и к нашим сервисам расчета и анализа медиапоказателей. Поэтому нам нередко приходится решать самые разные задачи, связанные с оптимизацией нагрузки на инфраструктуру. В этой статье вы найдете интересный кейс управления нагрузкой на кластер ClickHouse (CH), который решили внутри Mediascope. Команда нашего отдела разработки систем расчета и доставки прошла большой путь: от неуместного применения МL до простого, но рабочего решения.
Немного вводных на старте
Кластер: 4 ноды, 256gb ram + 24 processor cores, hdd disks.
Репликация «мастер-мастер» для возможности осуществлять запросы на любую из нод.
Нагрузка порядка 11 запросов в секунду в пике, запросы крайне неоднородные. Среднее время выполнения запроса от 1 до 30 секунд. Особо тяжелые запросы могут выполняться минуты.
С какой проблемой мы столкнулись
Располагаем системой, состоящей из следующий компонентов:

Эта система на основе параметров рассчитывает различные показатели медиапланирования. Описание базовых показателей по разным медиа можно найти в гайде нашей компании, хотя это неполный список для нашей системы, поскольку она умеет считать гораздо более комплексные показатели.
Клиент на вход отправляет задачу в виде «посчитать охваты некоторого сайта за период год, в месячной разбивке, в разрезе мужчины/женщины». На выходе получаем результат в виде коллекции ячеек.
"cells": [
{
"coord": {
"dtPoint": {
"type": "month_id",
"val": "2021-01-01"
},
"demoPoint": {
"type": "sex",
"val": "xxxx"
},
"mediaPoint": {
"type": "site",
"val": "xxxx"
},
"usetypePoint": {
"type": "usetype_id",
"val": "1"
}
},
"valuse": {
"reach": 31678.12312412
}
}
]На основе входной задачи в сервисе Task Manager формируется от 1 до N подзадач. Подзадачи формируются по алгоритму, позволяющему разбить задачу на отдельные запросы, данные которых не пересекаются и их возможно объединить при формировании результата. Очевидно, нужна очередь, которая будет ограничивать нагрузку на кластер. Именно здесь начинается все самое интересное.
По умолчанию в ClickHouse и написанной системе мы можем управлять потоком запросов только статически. Можно попробовать установить максимальное количество задач на пользователя или суммарное максимальное количество задач не более заданного числа, или же использовать в CH параметры max_concurrency_queries, но запросы крайне неоднородны и это приводит к одной из двух ситуаций неэффективной нагрузки CPU:
Проблема 1
(много простых задач, которые упираются в статический лимит и не дают нагрузить кластер)

Проблема 2
(много сложных задач, которые не упираются в статический лимит и дают нагрузить кластер в потолок с последующим падением производительности)

После коммуникации с коллегами в официальном чате ClickHouse мы выяснили, что внутри CH нет устройств по ограничению использования ресурсов, тем более динамических, хотя обещают в этом году выпустить фичи с подобным функционалом.
Как мы решали проблему
Решение №1. ML

Для ознакомления с предметной областью, возможностями «решающих деревьев» рекомендуем статью. В ней есть и описание инструмента, который мы использовали – CatBoost.
Вернемся к управлению нагрузкой. Мы приняли решение представить наш кластер в виде ограниченного ресурса, к примеру – 1000 «попугаев». При этом мы пытались связать «попугаев» либо со временем выполнения, занятой оперативной памятью в процессе расчета, либо с процессорным временем. Разбив запрос на отдельные составляющие, удалось выделить фичи для модели. Была уверенность, что можно получить крайне привлекательное решение в виде автоматического взвешивания задачи:
Приходит задача → оценивается → проверяется текущий объем «попугаев», если достаточно, то отправляется на расчет, нет – ожидает ресурсов.
К сожалению, уже в процессе создания структуры датасета, на основе которого планировалось строить решающее дерево, появились первые проблемы.

В ячейках представлены диапазоны. Комбинация всех вариантов параметров даёт нам ~3 168 000 задач. Расчет одной задачи занимает в среднем до 30 секунд. Чтобы просчитать все варианты последовательно потребовалось бы 1 100 000 дней. Время расчета при параллельном запуске составляло бы 1000 дней. Необходимо также учитывать ограничения по ресурсам, чтобы исключить взаимное влияние на доступной нам инфраструктуре.
Следующим шагом была оптимизация набора фич:
уменьшили диапазоны;
часть заменили бинарными значениями (есть/нет);
что-то вообще выкинули.
В итоге за неделю удалось собрать данные для обучения модели. Написали сервис, описали алгоритм, подключили модель и получили следующий результат:
До

После
На первый взгляд, графики снизу вытянулись, одни и те же расчеты сжались во времени. Все отлично, немного оптимизации и можно в прод. Однако более детальный анализ показал, что предсказание неплохо работает, потому что мы использовали одни и те же задачи для обучения и теста. Реальные задачи от пользователя не всегда взвешивались верно, процент промахов был большой. Мы вышли на несколько новых итераций более глубокого изучения технологии и инструмента, попробовали еще несколько моделей, но нужного нам результата это не принесло. Поэтому мы окончательно пришли к выводу, что решение задачи с помощью ML не оправдывает ресурсы и время, которое требуется на внедрение.
Решение №2. Prometheus Probes
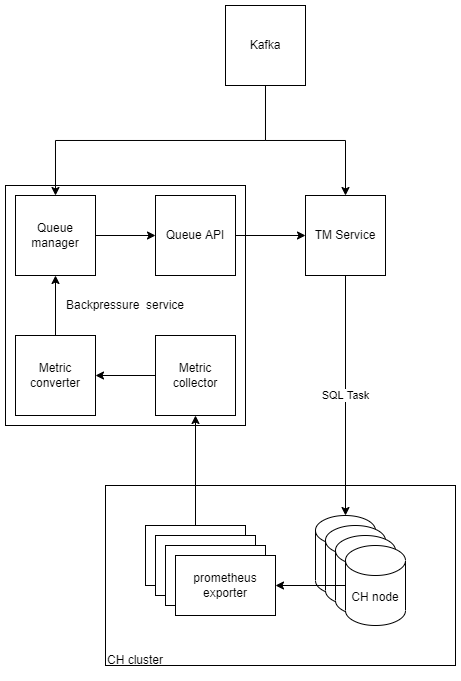
Второе решение оказалось намного проще – это ограничение потока задач, если сервера, на которых развернут CH, исчерпали все лимиты по CPU и памяти. На каждой ноде был установлен prometheus exporter. Сервис собирает необходимые метрики real time, находит среднюю загрузку всего кластера в процентах и через API позволяет брать на расчет следующие задачи из очереди или пропускает запросы, ожидая падения нагрузки.
Главной проблемой было описать алгоритм мягкой загрузки кластера. Если постоянно отдавать какое-то заданное число задач (Х), то возможны ситуации, что эти X сверхсложных задач создадут нагрузку выше допустимой. При старте расчета новым пользователем мы разрешаем перевод в статус IN_PROGRESS небольшого количества задач, далее ступенькой повышаем их количество. Поскольку мы не знаем объем нагрузки, который может дать каждая задача, лимит держим на уровне 90-95% нагрузки на CPU, чтобы избежать проблемы с задачами, которые превышают потолок.
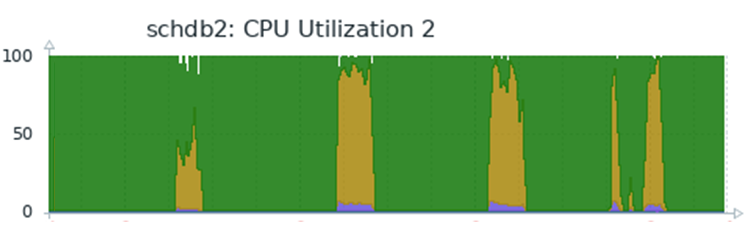
Так выглядит нагрузка на испытываемой части кластера после внедрения второго решения:
(все 4 ноды загружены довольно равномерно и профиль нагрузки идентичен)

Сейчас мы используем это решение во всех публичных API. На протяжении последнего полугода сервисы показывают стабильные показатели работы.
Бонус вместо заключения. Как еще можно улучшить обратную связь через метрики
Во время разработки мы обнаружили еще одно узкое место – это сама задача. Первая версия системы позволяла задавать такие параметры, при которых одна задача могла разделяться на более чем 100 подзадач.
Тело запроса (версия 1):
{
"header": {
"name": "habr_task",
"facility": "mobile"
},
"statistics": {
"names": [
"Stat1",
"Stat2"
]
},
"filters": {
"date": {
"from": "2019-11-01",
"to": "2019-12-31"
}
},
"structure": {
"date": "",
"param_type1": "month",
"param_type2": [
"param1",
"param2"
],
"param_type3": true
}
}В структуре мы видим “data = month”, значит мы считаем данные в разрезе месяца.
В фильтре заданы 2 месяца → 2 возможных варианта.
param_type1 = одному значению 350 → 1 возможный вариант.
param_type2 = param1 или param2 → 2 возможных варианта.
param_type3 = true → в нашем случае за true спрятано 4 возможных варианта.
Перемножаем 212*4 = 16 отдельных подзадач. Одна подзадача ~ один SQL-запрос (зависит от количества статистик).
Главная проблема в том, что количество param_type1 может быть 10, а это уже 160 запросов и абсолютно другая нагрузка на ClickHouse.
Мы решили изменить в новой версии системы тело запроса так, чтобы сплит на подзадачи был более предсказуемый, ограничив возможность сплита только по параметру Date. Информативность сохранили за счет динамического управления состава ячейки через параметр Slices. Размер ячейки перестал быть статическим и может быть детализированным любым набором доступных Slices.
Тело запроса (версия 2):
{
"filter": {
"Filter1": {
"operand": "AND",
"elements": [
{
"unit": "researchDate",
"relation": "IN",
"value": [
"2020-01-01"
]
}
]
},
"Filter2": {
"operand": "AND",
"elements": [
{
"unit": "param1",
"relation": "IN",
"value": [
1
]
}
]
}
},
"statistics": [
"reach"
],
"slices": [
"researchDate",
"param1"
]
}Нагрузка стала более предсказуемой. Мы видим меньше ситуаций, где проскакивают задачи, которые могут превысить установленный потолок.
Дальше мы планируем перевести backpressure-сервис на уровень работы с подзадачами. Так мы будем находиться максимально близко к БД и управлению количеством запросов в нее. Это позволит нам выравнивать нагрузку с еще большей точностью.
