

Привет, Хабр! С вами снова Артём, Team Lead Data Scientist из МегаФона. Надеюсь, вам понравилась первая статья серии о нестандартных методах кодирования категориальных данных. Если помните, в ней был приведен довольно простой метод, в рамках которого мы рассматривали объекты как строки и превращали их в эмбеддинги с помощью LSA. Настало время для продолжения. Садитесь поудобнее и готовьтесь погрузиться в таинственный мир построения векторных представлений объектов, выраженных изначально в категориальных переменных. Держите ссылку на репозиторий, где можно самим всё попробовать и поэкспериментировать.
И снова пролог, или «минута воспоминаний»

Подход из прошлой статьи был довольно прост, поэтому имел определенные минусы. Например, длительное время кодирования и неравномерность распределения информации между компонентами эмбеддинга. При этом обрезка ухудшала качество на тестовой задаче классификации, а значит, мы теряли информацию. Теперь же перейдем к немного более изощрённым методам, которые помогут устранить некоторые из этих недостатков.
Отмечу, что на эксперименты меня вдохновила довольно любопытная статья.
Думаю, вам также будет интересна ссылка на мой доклад на Data Fest 2021 по рассматриваемой теме. Можете ознакомиться, будет легче погружаться. Стоит учитывать, что с момента записи выступления удалось оптимизировать код, поэтому некоторые методы стали работать лучше, а результаты чуть поменялись.
Теперь перейдем к делу. Но для начала вспомним нашу исходную задачу:
- Мы получаем эмбеддинги для объектов, выраженных в категориальных переменных. Такие эмбеддинги могут быть полезны для решения задач supervised learning (классификация, регрессия) и unsupervised learning (кластеризация, визуализация, простейшие рекомендательные системы).
- В наших экспериментах используем датасет с платформы Kaggle.

- Для построения эмбеддингов используем подход обучения без учителя (unsupervised learning), то есть не задействуем таргет при обучении. Такой подход может сильно облегчить жизнь в некоторых реальных кейсах, потому что нам не нужна размеченная выборка.
- Схема кодирования категориальных объектов:

- Схема проверки качества на задаче классификации:
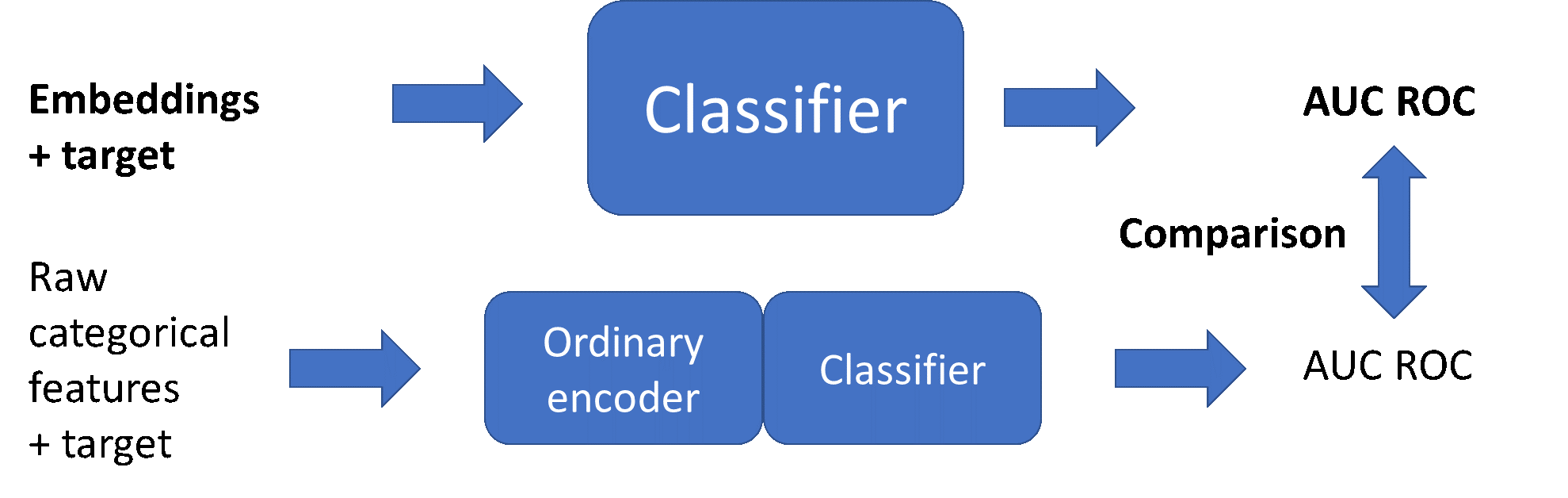
Цель экспериментов - получить качество, сравнимое с некоторыми привычными подходами кодирования категориальных данных, что будет означать сохранение достаточного количества информации из исходных объектов в их эмбеддингах.
Результаты тестирования подхода из предыдущей статьи цикла (будем считать его базой):
1) Характеристики времени работы:
Время обучения для размерности 700 (230 тыс. образцов): 18 мин.
Время кодирования тестовых данных (70 тыс. образцов): 34 сек.
2) Результаты классификации с использованием полученных векторных представлений размерности 700.
Алгоритм | AUC ROC |
LightGBM | 0.751 |
LogisticRegression | 0.772 |
Для сравнения ниже представлены результаты классификации с использованием некоторых привычных методов обработки.
Алгоритм | AUC ROC |
LightGBM (встроенный обработчик) | 0.783 |
LightGBM (ohe) * | 0.756 |
LogisticRegression (ohe) * | 0.800 |
LogisticRegression (ordinal enc., scaled) | 0.719 |
* Количество бинарных признаков после one-hot кодирования - более 16 тыс.
Ноутбук с кодом, где получены все результаты из предыдущей статьи доступен тут.
И снова NLP, или «смешать, но не взбалтывать»

Начнём с метода, который задействует аппарат обработки естественного языка, но несколько иначе, чем предыдущий подход.
А для того, чтобы желающие могли сами поэкспериментировать с кодом, всё необходимое есть в ноутбуке по этой ссылке.
Итак, в этом методе мы будем использовать вложенные циклы, пробегаться по парам переменных, а потом объединять результаты. Опишу по шагам:
Во внешнем цикле группируем train часть выборки по значениям каждой категориальной переменной. Назовем переменную, по значениям которой проходит группировка, group_key.
Во внутреннем цикле для каждой из остальных категориальных переменных (passive_key) берем столбец со всеми значениями категорий в данной группе group_key и записываем в строку. Таким образом, для каждой пары group_key — passive_key имеем по строке на категорию group_key.
Потом полученные строки для данной пары кодируем с использованием CountVectorizer, получаем разреженную матрицу большой размерности.
Затем применяем Truncated SVD для уменьшения размерности до нужной.
Примерная схема процесса показана ниже (для простоты показана обработка одной из пар group_key – passive_key):

После объединения результатов для каждого group_key получаем векторы, состоящие из частей, относящихся к разным passive_key.
Размерность получившихся векторов можно подсчитать по формуле:

где ncomp – усечённая размерность после SVD,
ncat – количество категориальных признаков в исходном датасете.
Видно, что эта размерность зависит от количества категориальных переменных и количества компонент на выходе Truncated SVD, а не от числа категорий каждой переменной. Этот момент один из ключевых, которые нужно учитывать при выборе метода.
Посмотрим на результаты тестирования данного подхода.
Характеристики времени работы кодировщика в ноутбуке Google Colab:
Время обучения для размерности 1595 (230 тыс. образцов): 2 мин. 47 сек.
Время кодирования тестовых данных (70 тыс. образцов): 8 сек.
Сразу отметим высокую скорость работы, она намного выше, чем в нашем базовом подходе.
Теперь посмотрим на результаты классификации с использованием полученных векторных представлений размерности 1595:
Алгоритм | AUC ROC |
LightGBM | 0.770 |
LogisticRegression | 0.759 |
По сравнению с базовым подходом получаем повышение качества на модельной задаче классификации на алгоритме LightGBM, но при этом небольшую просадку на логистической регрессии. Вероятно, это связано со сравнительно высокой корреляцией компонент векторов.
Видно, что оба показателя качества сравнимы с результатами привычных подходов обработки категориальных данных (приведены во вступлении). Отмечу, что дополнительный подбор гиперпараметров добавил бы качества. В любом случае, в векторах сохранилось достаточно много информации из исходных переменных, что хорошо.
Посмотрим на результаты визуализации объектов.


* метод t-SNE
** метод MDS
Заметны кластеры на первой картинке, при этом картина MDS изменилась незначительно. Кластеры – это уже хорошо, тоже характеризуют информативность.
Пришло время промежуточных выводов. На что же здесь стоит обратить внимание?
В качестве плюсов отметим высокую скорость кодирования, информативность эмбеддингов, простор для улучшений NLP-части, гибкость в плане размерности полученных векторных представлений. Этот метод может сильно сократить размерность по сравнению c one-hot кодированием при большой кардинальности признаков.
К ограничениям метода можно отнести то, что его стоит применять только для не очень большого количества категориальных признаков, среди которых много переменных с достаточно высокой кардинальностью. Это связано с тем, что размерность векторных представлений, в соответствии с формулой для её оценки, определяется размерностью исходного признакового пространства. Также могут возникать вопросы по поводу масштабирования компонент векторов и проблемы из-за их корреляции.
Вероятностный подход, или «магия энтропии»

Теперь проверим, как в деле получения векторных представлений объектов может помочь теория вероятностей. Ссылка на код для экспериментов тут.
По аналогии с предыдущим подходом, будем использовать вложенные циклы, работать с каждой парой переменных, а потом объединять результаты.
Во внешнем цикле группируем train по значениям каждой категориальной переменной (group_key).
Во внутреннем цикле для каждой из остальных переменных (passive_key) по категориям group_key строим распределения по значениям, то есть сколько раз значения group_key - passive_key встречались вместе.
Далее будем работать с этими условными распределениями и вычислять энтропии.
Примерная схема для обработки одной из пар group_key- passive_key выглядит следующим образом:
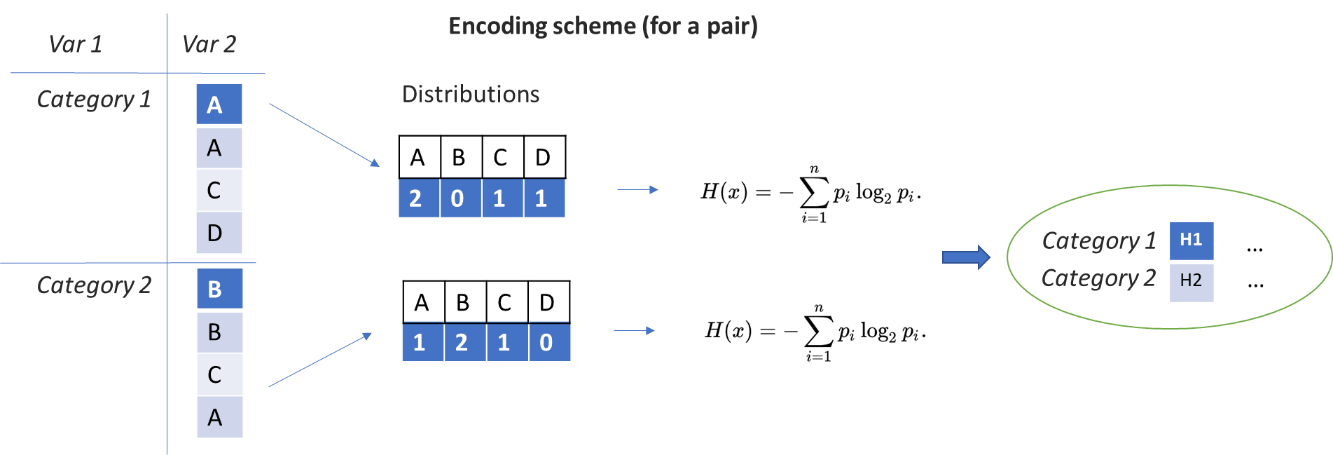
После объединения результатов для каждого group_key получаем векторы, состоящие из энтропий распределений различных passive_key.
Размерность теперь зависит только от количества категориальных переменных, она меньше, чем в предыдущем подходе:

где ncat – количество категориальных признаков в исходном датасете.
Посмотрим на результаты тестирования этого метода.
Характеристики времени работы кодировщика в ноутбуке Google Colab:
Время обучения для размерности 506 (230 тыс. образцов): 36 сек.
Время кодирования тестовых данных (70 тыс. образцов): 3 сек.
Теперь посмотрим на метрики на модельной задаче.
Алгоритм | AUC ROC |
LightGBM | 0.768 |
LogisticRegression | 0.740 |
Итак, получаем самую высокую скорость работы. Этому достижению помогла оптимизация изначального варианта кода. По качеству – небольшая просадка на обоих алгоритмах, хотя эта просадка не так значима, учитывая сокращение размерности векторов в 3 раза, что является плюсом.
Теперь посмотрим на визуализации


* метод t-SNE
** метод MDS
Видим, что на обеих картинках теперь видны кластеры, чего не было в предыдущих случаях. Вероятно, это связано с высокой информативностью эмбеддингов при сравнительно низкой их размерности. Магия энтропии в действии?
Подведем итог по рассмотренному методу. На самом деле, свои плюсы и минусы этот подход почти полностью наследует от предыдущего. Дополнительным преимуществом является сравнимое качество при сильно меньшей размерности эмбеддингов, а также меньший дисбаланс в масштабе значений компонент эмбеддинга. К минусам можно также отнести меньшую гибкость, чем в рассмотренных ранее методах, так как размерность фиксирована.
Эпилог, или «разложим всё по полочкам»

Пришло время сделать выводы о рассмотренных в серии статей методах.
Резюмируем:
Мы рассмотрели три подхода, которые в парадигме unsupervised learning с помощью аппарата NLP и теории вероятностей позволяют получать неплохие векторные представления для объектов, состоящих в исходном виде только из категориальных переменных.
Полученные векторные представления могут быть полезны при решении широкого класса задач: от классификации до построения рекомендательных систем.
Для случаев с большим количеством категориальных переменных низкой кардинальности хороший выбор - первый из рассмотренных подходов, для остальных случаев полезны и другие описанные методы.
Для визуализации объектов лучшим показал себя подход с энтропией.
Традиционно закончу статью той самой мыслью:
Искать что-то новое и полезное можно не только там, где ещё ничего не открыто, а ещё и там, где сначала казалось, что открывать уже нечего.
Кстати говоря, уже успели поработать в репозитории и поэкспериментировать с кодом? Или, быть может, уже опробовали что-то в своих кейсах? Делитесь в комментариях, обсудим ваши результаты. Спасибо за прочтение и удачи в дальнейших экспериментах!
P.S. А ещё я и мой добрый единомышленник Иван периодически проводим прямые эфиры в telegram с интересными людьми из Data Science, плавно переходящие в авторский подкаст «Данные люди». Присоединяйтесь к нашему каналу @bigdatapeople.
