Предыстория
Уже много лет мы помогаем нашим клиентам отправлять потребителям хорошие, информативные и человеческие письма. В них вместо сухого “Добрый день” мы пишем “Здравствуйте, Никита!”, а вместо “Ваш баланс пополнился” сообщаем “вы получили 25 баллов”. Но маркетологи становятся все изобретательнее, и современное письмо от интернет-магазина должно выглядеть так:
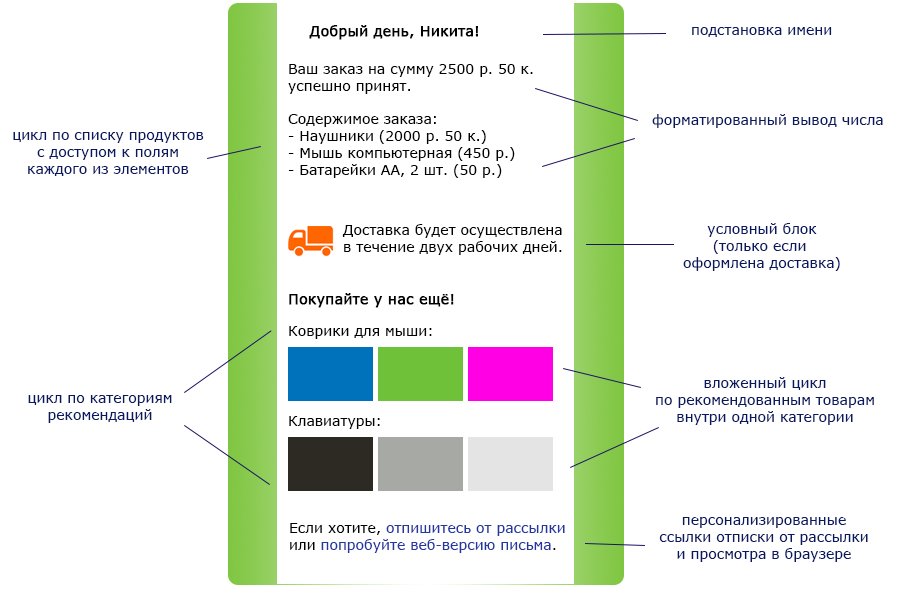
И мы хотим уметь генерировать такие письма автоматически.
Наш старый, проверенный временем шаблонный движок умеет вставлять в нужные места письма параметры, подставлять вместо отсутствующего значения что-то по умолчанию и писать “1 рубль, 2 рубля, 5 рублей”, причем делает это хорошо. Но он не предназначен для сложных ветвлений, циклов и любой другой сложной логики. Поэтому для формирования сложных писем как на картинке нам приходилось прибегать к коду на C#, и выглядело это так:

Мы оказались в не очень приятной вселенной, где желание клиента выделить курсивом слово в письме приводит к тикету на программиста и выкладке на продакшн. Мы в этой вселенной задерживаться не хотели, и стало понятно, что нам нужен новый шаблонный движок, который должен уметь:
- вывод простых параметров
- вывод сложных многоуровневых параметров (Recipient.Address.City.Name)
- условия
- циклы
- арифметические операции
И это только бизнес-требования, основанные на реальных сценариях. А поскольку мы хотим, чтобы при заведении рассылки менеджеру было легко заводить рассылки и сложно ошибиться, нам нужны еще:
- внятные сообщения об ошибках
- валидация используемых в шаблоне параметров
- расширяемость (возможность добавлять свои функции)
А поскольку мы иногда шлем миллионы писем в час, нам необходима хорошая производительность, а значит:
- прекомпиляция шаблона
- возможность переиспользования шаблона и потокобезопасность
Мы рассмотрели несколько доступных шаблонных движков, начиная Liquid и заканчивая Mustache, и все они немного со странностями. Кто-то при ошибке не падает с исключением, а просто рендерит пустую строку. Где-то синтаксис такой, что мы, будучи программистами, не смогли понять, как написать условие. Мы всерьез подошли к безумной идее использовать близкий и понятный нам Razor для формирования писем, но отказались от неё из-за досадной мелочи: получалось, что составитель шаблона рассылки мог выполнять произвольный .NET-код в процессе, отправляющем письмо.
И конечно же, в итоге мы решили написать свой шаблонный движок. Со статической типизацией и цепочками фильтров.
Дизайн языка
Практически сразу мы приняли решение отказаться от совместимости с чем-либо. Отказались от обратной совместимости с предыдущим шаблонным движком: синтаксис должен быть таким, чтобы можно было органично расширять язык пять лет в будущем, а не подстраиваться под то, что разработано за пять лет в прошлом. Отказались от совместимости с каким-то стандартом де-факто, по которому все верстают шаблоны писем: его просто нет. Мы оказались перед абсолютно белой доской, на которой нужно было нарисовать синтаксис нашего языка, и сразу начали придумывать себе рамки, в которых можно творить.
Во-первых, язык должен встраиваться в HTML, а значит, должен предусматривать escape-последовательности, отделяющие блоки нашего кода от остальной разметки.
Мы остановились на таком варианте:

Идея разделять выводящие инструкции ${ … } и не выводящие, служебные инструкции @{ … } навеяна имплицитными и эксплицитными выражениями из Razor. Попробовали посмотреть, как это будет выглядеть в реальной HTML-вёрстке, и да, так оказалось лучше и нагляднее.
Позже вспомнили, что такой же синтаксис используется в TypeScript для string interpolation (а в C# – другой, но тоже похожий). Стало приятно: если Андерс Хейлсберг посчитал это хорошим синтаксисом, то мы на верном пути.
Во-вторых, мы подумали, кто будет пользоваться нашим языком шаблонов. С большой вероятностью вёрстку письма будет делать верстальщик, которому близок и понятен javascript. С другой стороны, дорабатывать вёрстку по мелочам и править мелочи в логике скорее всего будет менеджер, который не знает javascript, но знает английский язык и здравый смысл. Поэтому наш синтаксис в итоге получился больше похож на Паскаль, с нормальными человеческими словами and, or, not вместо закорючек и амперсандов.
В итоге остановились на таком синтаксисе:

Осталось всего ничего: сдуть пыль с “книги дракона” и реализовать лексический разбор, синтаксический анализ, семантический анализ, а потом обеспечить генерацию выходного результата – письма.
Парсинг и ANTLR
Всем должно быть очевидно, что придуманный нами язык по классификации Хомского описывается контекстно-свободной LL-грамматикой, для разбора которой, соответственно, достаточно реализовать LL(*)-парсер. И тут же мы столкнулись с небольшой проблемой: мы почти ничего в этом не понимаем и не умеем.
Мы хорошо умеем делать сложный веб-фронтенд с большим количеством javascript, делать сложную серверную валидацию, работать с терабайтными базами данных и решать проблемы производительности и многопоточности в условиях тысяч транзакций в минуту. А вот языковые грамматики – не совсем наша компетенция. А на разработку шаблонного движка у нас в идеале две недели.
На этом месте мы пошли и ввели в гугле в строку поиска чит-код: ANTLR. Эффект не был мгновенным, но после пары дней, потраченных на чтение документации и эксперименты, мы получили такой прогресс, на который при ручной разработке ушло бы несколько недель. Итак, что такое Antlr и что он берет на себя?
ANTLR (ANother Tool for Language Recognition) – открытая библиотека, написанная Терренсом Парром, преподавателем университета Сан-Франциско и автором десятка с лишним научных статей о формальных грамматиках и их разборе. Её понемногу используют для задач парсинга ребята из Google, Oracle и Microsoft (например, в ASP.NET MVC). Antlr полностью берёт на себя лексический и синтаксический разбор текста, руководствуясь формальным описанием грамматики языка.
Конечно, не всё было безоблачно. При близком знакомстве Antlr оказался java-утилитой, которую нужно запускать из командной строки, пытаясь подобрать правильные аргументы из противоречащих друг другу статей документации, чтобы она сгенерировала C#-код, на который будет ругаться StyleCop. Документация нашлась, но не всё, что реализовано в утилите, описано в документации, и – вот это было ударом – не всё, что описано в документации (официальной книге от автора библиотеки) уже реализовано в утилите. Поддержка C# оказалось не такой полной, как поддержка Java, а из работающих вспомогательных инструментов мы нашли только плагин к эклипсу.
На всё это можно смело закрывать глаза, потому что после того, как мы заставили эту дурацкую штуку работать, мы получили код, который принимает поток с текстом, а возвращает полностью готовое синтаксическое дерево и классы для его обхода.
Мы не стали писать парсер шаблона и никогда не планируем этим заниматься в будущем. Мы описали грамматику языка, доверив Antlr решение скучных бытовых проблем, связанных с его парсингом, себе оставили интересные и неожиданные проблемы, связанные со всем остальным.
Грамматика языка: лексические правила
Описание грамматики ANTLR складывается из набора рекурсивных правил. Любому, кто на первом-втором курсе познакомился с БНФ, диаграммами Вирта или другими способами описания формальных языков, эта идея будет близка и понятна.
Точно так же нам близка идея максимального отделения лексического разбора от синтаксического анализа. Мы с радостью воспользовались возможностью разнести по разным файлам правила, определяющие терминалы и примитивные токены языка, от синтаксических правил, описывающих более сложные составные и высокоуровневые конструкции.
Взялись за правила лексера. Самая важная задача – сделать так, чтобы мы распознавали наш язык только внутри блоков ${ ... } и @{ .... }, а остальной текст письма оставляли неизменным. Иными словами, грамматика нашего языка – островная грамматика, где текст письма – неинтересный для нас “океан”, а вставки в фигурных скобках – интересные “острова”. Блок океана для нас абсолютно непрозрачен, мы хотим его видеть одним крупным токеном. В блоке острова мы хотим максимально конкретный и мелкий разбор.
К счастью, Antlr поддерживает островные грамматики из коробки благодаря механизму лексических режимов. Сформулировать правила, по которым мы делим текст на “океан” и “острова” было не совсем тривиально, но мы справились:

Эти правила переводят парсер в режим “внутри инструкции”. Их два, потому что ранее мы решили иметь немного различный синтаксис для управляющих инструкций и инструкций вывода.
В режиме “внутри инструкции” симметричное правило, которое при встрече с закрывающей фигурной скобкой возвращает парсер в основной режим.

Ключевые слова “popMode” и “pushMode” намекают нам, что есть у парсера есть стек режимов, и они могут быть вложенными с какой-то внушительной глубиной, но для нашей грамматики достаточно переходить из одного режима в другой и потом возвращаться обратно.
Осталось описать в “океане” правило, которое будет описывать всё остальное, весь текст, который не является входом в режим инструкций:

Это правило воспримет как Fluff (ерунда, шелуха, незначительный мусор) любую цепочку символов, не содержащую @ и $, либо ровно один символ $ или @. Цепочку токенов Fluff потом можно и нужно склеить в одну строковую константу.
Важно понимать, что лексер пытается применять правила максимально жадно, и если текущий символ удовлетворяет двум правилам, всегда будет выбрано правило, захватывающее наибольшее число следующих символов. Именно поэтому, когда в тексте встретится последовательность ${, лексер воспримет её как OutputInstructionStart, а не как два токена Fluff по одному символу.
Итак, мы научились находить “острова” нашей грамматики. Это стерильное и контролируемое пространство внутри шаблона, где мы решаем, что можно, а что нельзя, и что означает каждый символ. Для этого понадобятся другие лексические правила, которые работают внутри режима инструкции.
Мы не пишем компилятор Python и хотим разрешать ставить пробелы, табуляции и переносы строк везде, где это выглядит резонным. К счастью, и это тоже Antlr позволяет:

Такое правило, конечно же, может существовать только в режиме “острова”, чтобы мы не вырезали пробелы и переносы строк в тексте письма.
Остальное несложно: смотрим на утвержденный пример синтаксиса и методично описываем все лексемы, которые в нем встречаем, начиная с DIGIT

и заканчивая ключевыми словами (IF, ELSE, AND и другие):

Регистронезависимость выглядит страшновато, но в документации резонно написано, что лексический разбор – штука точная и подразумевающая максимально явное описание, и эвристике по определению регистра во всех алфавитах мира там не место. Мы не стали с этим спорить. Зато у нас else if воспринимается как один токен (что удобно), но при этом он не elsif и не elseif, как это бывает в некоторых языках.
Откуда-то из глубин воспоминаний о первом и втором курсе, растревоженных словами про БНФ и диаграммы Вирта, всплывает понимание, как описать IDENTIFIER так, чтобы идентификатор мог начинаться только с буквы:

Еще несколько десятков не самых сложных правил, и можно вынырнуть на уровень выше – в синтаксический разбор.
Грамматика языка: синтаксические правила
Структура любого письма в нашем шаблонизаторе проста и напоминает зебру: статические блоки вёрстки чередуются с динамическими. Статические блоки – это куски вёрстки с подстановкой параметров. Динамические – это циклы и ветвления. Мы описали эти основные блоки таким набором правил (приведен не полностью):

Синтаксические правила описываются таким же образом, как и лексические, но базируются они не на конкретных символах (терминалах), а на описанных нами лексемах (с большой буквы) или других синтаксических правилах (с маленькой буквы).
Разобрав текст этим набором правил, получили что-то подобное:
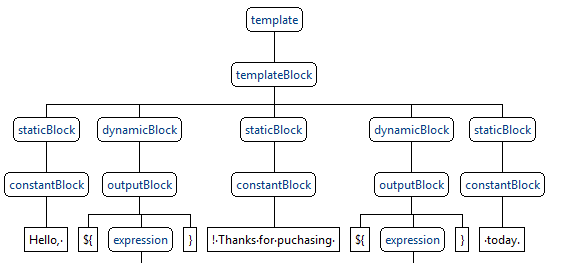
В статических и динамических блоках может быть набор инструкций произвольной сложности, начиная выводом одиночного параметра и заканчивая сложным ветвлением по результатам выполнения арифметических операций внутри цикла. Всего у нас получилось порядка 50 синтаксических правил такого вида:

Здесь мы описываем сложное условное высказывание, в котором обязателен блок if, может быть несколько блоков else if и может быть (но не обязательно) один блок else. В блоке If внутри знакомый нам templateBlock – тот самый, который может быть чем угодно, в том числе другим условием.
Где-то на этом месте наша грамматика начала быть по-настоящему рекурсивной, и стало жутковато. Поставив последнюю закрывающую фигурную скобку, мы сгенерировали при помощи ANTLR код парсера нашей грамматики, подключили его к нашему проекту и задумались, что со всем этим делать.
От дерева к дереву
Результат работы Antlr начиная с 4 версии – парсер, который превращает текст в так называемое concrete syntax tree, оно же парсерное дерево. Под concrete подразумевается, что дерево содержит в себе всю информацию о синтаксисе, каждое служебное слово, каждую фигурную скобку и запятую. Это полезное дерево, но не совсем то, которое нужно для наших задач. Основные его проблемы – слишком сильная связанность с синтаксисом языка (который неизбежно будет меняться) и совершенная неосведомленность о нашей предметной области. Поэтому мы решили обходить это дерево ровно один раз и строить на его основе своё дерево, которое ближе к abstract syntax tree и удобнее в дальнейшем использовании.
Требования к дереву такие:
- не должно содержать подробностей синтаксиса (нам важно, что идёт ветвление на три ветки, а слова
if,else ifиelseне интересны) - должно поддерживать все типовые сценарии обхода (рендеринг письма с подстановкой значений параметров, получение списка параметров и их типов)
Упрощенный интерфейс вершины нашего дерева в итоге выглядит примерно так (набор потомков и логика их обхода слишком разные для разных узлов, поэтому в общем интерфейсе их нет):
internal interface ITemplateNode
{
void PerformSemanticAnalysis(AnalysisContext context);
void Render(StringBuilder resultBuilder, RenderContext renderContext);
}Вдохновившись рассказами создателей Roslyn о красно-зелёных деревьях, решили, что наше дерево будет полностью immutable. Во-первых, с таким кодом просто удобнее и проще работать, не задаваясь вопросами о состоянии и последовательности изменений. Во-вторых, это самый простой способ обеспечить потокобезопасность, а значит – возможность использовать один прекомпилированный шаблон письма для отправки во многих потоках. В общем, красота, осталось его построить.
Обходить парсерное дерево, сгенерированное Antlr, предлагается при помощи паттерна Visitor. Сам Antlr предоставляет интерфейс визитора, а также базовую реализацию, которая обходит все вершины дерева в глубину, но ничего при этом не делает.
Конечно, есть вариант сделать один гигантский визитор, в котором будет реализован обход всех наших правил, которых вроде и не так много, а вроде как почти 50. Но гораздо удобнее оказалось описать несколько разных визиторов, задача каждого из которых – сконструировать одну вершину нашего результирующего дерева.
Например, для обхода условий внутри @{ if } … {else if } … {else } .. @{ end if } мы используем специальный визитор:
internal class ConditionsVisitor : QuokkaBaseVisitor<ConditionBlock>
{
public ConditionsVisitor(VisitingContext visitingContext)
: base(visitingContext)
{
}
public override ConditionBlock VisitIfCondition(QuokkaParser.IfConditionContext context)
{
return new ConditionBlock(
context.ifInstruction().booleanExpression().Accept(
new BooleanExpressionVisitor(visitingContext)),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
public override ConditionBlock VisitElseIfCondition(QuokkaParser.ElseIfConditionContext context)
{
return new ConditionBlock(
context.elseIfInstruction().booleanExpression().Accept(
new BooleanExpressionVisitor(visitingContext)),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
public override ConditionBlock VisitElseCondition(QuokkaParser.ElseConditionContext context)
{
return new ConditionBlock(
new TrueExpression(),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
}Он инкапсулирует в себе логику создания объекта ConditionBlock из фрагмента синтаксического дерева, описывающего ветку условного оператора. Поскольку внутри условия может быть произвольный кусок шаблона (грамматика-то рекурсивная), управление для разбора всего внутри снова передается универсальному визитору. Наши визиторы связаны рекурсивно примерно так же, как и правила граммматики.
На практике с такими маленькими визиторами легко и удобно работать: в них определен обход только тех элементов языка, которые мы ожидаем увидеть в каждом конкретном месте, а их работа заключается либо в инстанцировании новой вершины дерева, которое мы строим, либо в передаче управления другому визитору, который занимается более узкой задачей.

На этом же этапе мы избавляемся от некоторых неизбежных артефактов формальной грамматики, таких, как избыточные скобки, конъюнкции и дизъюнкции с одним аргументом и прочие вещи, необходимые для определения лево-рекурсивной грамматики и абсолютно ненужные для прикладных задач.
И в результате получаем из такого дерева
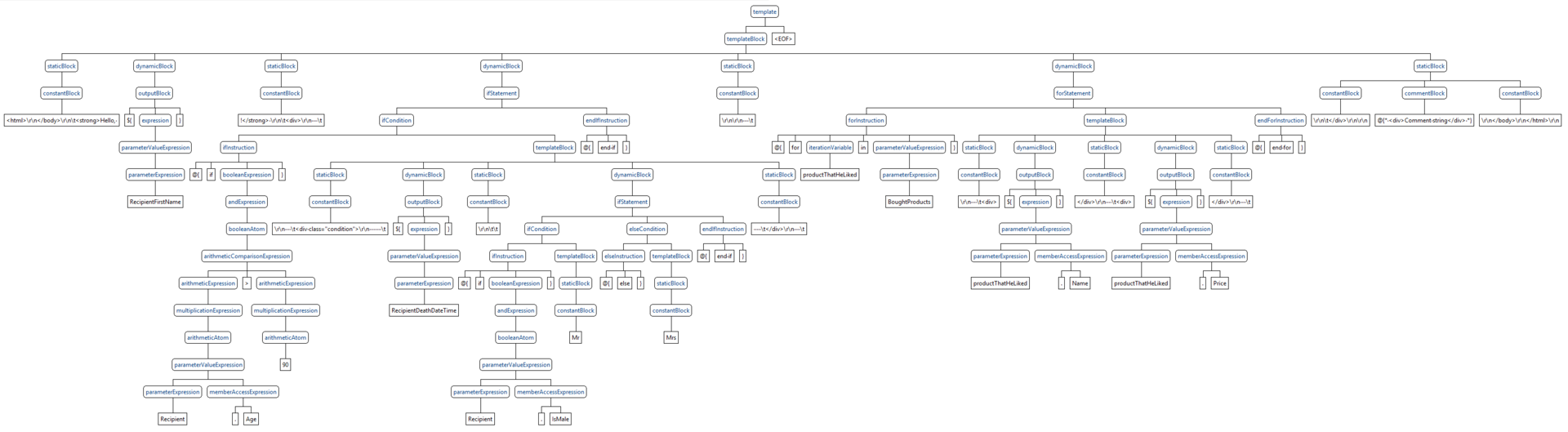
такое

Это дерево гораздо лучше укладывается в голове, не содержит бесполезной информации, его узлы инкапсулируют реализацию конкретных инструкций, и вообще с ним можно работать.
Осталось совсем немного – обойти его несколько раз. И первый, обязательный обход – это обход для семантического анализа.
Получение списка параметров и типизация
Одна из ключевых задач нашего шаблонизатора – умение найти в тексте письма все используемые в нем параметры. Цель понятна: валидировать и не давать сохранить шаблон, в котором встречаются параметры, которые мы не сможем подставить в письмо. Например, Recipient.Email мы знаем, а Recipietn.Eamil – нет. Для нас важно, чтобы отправитель узнал об ошибке в шаблоне сразу при его сохранении, а не при попытке отправить письмо.
Однако это не единственное направление валидации параметров. Хотим ли мы давать написать в письме ${ Recipient.Email + 5 }, зная, что Email у нас в системе – строковое поле? Кажется, нет. Значит, мы должны не только найти все параметры в письме, но и определить их тип. На этом месте мы обдумали типизацию и поняли, что она у нас статическая (что хорошо), но при этом неявная (что удобно пользователю, но неудобно нам). Ощутили мимолетный импульс заставить менеджера декларировать в начале письма все параметры явно, указывая тип. Удобство пользователя победило, импульс подавили. Придется определять тип “на лету” исходя из контекста.
Система типов нашего шаблонизатора выглядит так:
- примитивный тип
- целое число
- дробное число
- логическое значение
- дата-время
- составной тип, содержащий именованные свойства любого типа
- множественный тип (массив, коллекция, список, как угодно), содержащий несколько значений одного определенного типа
Подход к решению задачи простой: для того, чтобы определить тип параметра, входящего в письмо, достаточно найти все его использования в тексте и попытаться определить непротиворечивый тип, удовлетворяющий всем вхождениям или же сообщить об ошибке шаблона. На практике это оказалось не самой простой задачей с кучей особенных случаев, которые надо учесть.
Оказалось, что у переменных цикла есть область видимости. Оказалось, что бывают вложенные циклы по списку списков. Оказалось, что можно проходить в цикле по одному и тому же списку в двух разных местах в шаблоне, и обращаться там к разным полям элементов списка. В общем, понадобился крепкий статический анализ, над которым пришлось как следует подумать, а также несколько десятков юнит-тестов, но результатом мы довольны.

Глядя на этот шаблон, мы можем сказать, что у потребителя должен быть массив продуктов, а каждый продукт имеет цену и массив категорий, а у каждой категории должен быть как идентификатор Id, так и название Name. Теперь достаточно спросить нашу систему, есть ли в ней параметры такой структуры, и никаких сюрпризов при отправке не будет. Или почти никаких.
Рендеринг
Финальное испытание уже не казалось сложным: к моменту отрисовки текста письма у нас на руках вся структура шаблона, и достаточно просто еще раз обойти дерево, предоставляя каждому узлу возможность что-то записать в поток (или вернуть строку).
На практике же пришлось здесь решить еще порцию задачек по программированию для начинающих: булева логика, арифметические вычисления и сравнения, вложенные области определения переменных, приведение типов и обработка ошибок.
Могут ли быть ошибки при рендеринге письма, если мы потратили столько усилий на статическую типизацию параметров и валидацию шаблона еще до отправки письма? К сожалению, да:

Вывод такого значения приведет к ошибке, если B = 0. Заманчивая идея – усилить систему типов для таких случаев, но легко вообразить и такой сценарий, где всё совсем-совсем непредсказуемо:

Мы смирились с тем, что ситуация, когда конкретный набор параметров в письме приводит к ошибке рендеринга, не предотвращается статическим анализом, и стали выбирать между двумя вариантами:
- Иметь reasonable defaults (при выводе null-значения выводить пустую строку, при использовании в условии null-значения возвращать false, при делении на ноль работать с NaN и так далее)
- Соблюдать принцип fail fast
Решили так: отправить кривое письмо гораздо хуже, чем не отправить никакое вообще. Отправленное уже не вернешь, а не отправленное можно исправить и повторить. Поэтому fail fast, понятный, простой и без эвристик, нам подходит гораздо лучше.
Раз мы не боимся ошибок и неудач во время отрисовки письма, теперь можно допустить к этому процессу и других программистов. Можно вообразить несколько десятков полезных функций, которые как-либо преобразуют примитивные значения: вычисление каких-нибудь криптографических хэшей для подстановки в письмо, округления дробей, добавление параметров в ссылку. Львиную долю этих возможностей мы оставили за бортом шаблонизатора, чтобы пользователи библиотеки расширяли его снаружи. К счастью, это не сложно, а типы аргументов и возвращаемого значения строго типизированы:
internal class ToUpperTemplateFunction : ScalarTemplateFunction<string, string>
{
public ToUpperTemplateFunction()
: base(
"toUpper",
new StringFunctionArgument("string"))
{
}
public override string Invoke(string argument1)
{
return argument1.ToUpper(CultureInfo.CurrentCulture);
}
}Остаётся учесть мелкие детали: подставить уникальные ссылки для трекинга кликов и открытий, сгенерировать ссылки отписки и просмотра веб-версии письма, отвалидировать переданные параметры, и письмо готово к отправке.
Итоги
Приняв примерно сотню мелких и больших решений, мы наконец отрендерили своё первое письмо с циклами и условиями. Мы написали свой собственный шаблонный движок, практически с нуля, и в процессе поняли, что синдром Not invented here – плохо, но если правда не находится ничего, что удовлетворяет нашим требованиям, надо брать и делать своё.
Сейчас, отправив с его помощью несколько сотен миллионов сообщений и увидев, как наши менеджеры каждый день верстают письма в десятки раз сложнее, чем это казалось возможным, можно с уверенностью сказать, что он в итоге работает.
Как раз момент для того, чтобы проанализировать проделанную работу, сохранить куда-нибудь файл с несколькими сотнями доработок, которые хочется сделать, описать процесс в блоге и взяться за следующую задачу.
