Последнее время в Email-маркетинге все чаще используются автоматические рассылки определенным группам потребителей. Типичные задачи:
- поздравить с днем рожденья
- позвать на сайт, если потребитель на него долго не заходил
- сделать персонализированное предложение (делим потребителей на сегменты и рассылаем каждому сегменту свое письмо)
В этой статье мы расскажем, как мы решали эту задачу — от написания каждой отдельной рассылки разработчиком с нуля 3 года назад, до заведения рассылок менеджером через веб-интерфейс в настоящее время. Рассказ может быть интересен не только тем, кто занимается Email-маркетингом но и вообще всем, кому приходится реализовывать периодическое выполнение сложных операций над определенными выборками потребителей (знаю, что звучит очень абстрактно, но в итоге именно такую абстрактную задачу нам и пришлось решить).
Первые реализации
3 года назад подобные задачи возникали крайне редко и мы каждый раз реализовывали их с нуля. При этом возникали одни и те же вопросы:
- Как помечать потребителей, которым мы уже отправили это письмо?
- Как максимально быстро обработать всех потребителей и при этом не тормозить работу сайтов (которые обращаются к тем же записям в БД)?
На первый вопрос ответ для нас был очевиден: в нашей системе сохраняется информации о всех значимых действиях, выполняемых потребителем (вход на сайт, изменение персональных данных) или над ним (розыгрыш приза, отправка уведомления). Кроме того, мы используем действия для разнообразных технических пометок потребителей. Так что при отправке автоматической рассылки, мы также решили выдавать потребителю особое
действие-маркер, в качестве пометки, что эта автоматическая рассылка ему уже была отправлена. Чтобы повторно не отправлять рассылку, к условию рассылки всегда добавляется условие “у потребителя нет действия-маркера”.
На втором вопросе мы набили множество шишек, связанных с блокировками в БД, и в итоге пришли к следующему шаблону:
- Отправка рассылок идет из windows-сервиса, который периодически проверяет не появилось ли новых потребителей, подходящих под условия.
- В сервисе первым шагом делается один запрос к БД с уровнем изоляции Read Uncommitted. Этот запрос вытаскивает Id всех потребителей, которым надо отправить письмо. Из-за низкого уровня изоляции такой запрос не накладывает блокировок на записи в БД и, как следствие, крайне слабо влияет на работу сайта. Однако он не гарантирует чистоту данных и их надо повторно проверить с более высоким уровнем изоляции.
- После того, как мы вытащили Id потребителей, для каждого потребителя мы выполняем отдельную транзакцию с уровнем изоляции Serializable. В этой транзакции мы заново проверяем подходит ли потребитель под условия и если да, отправляем ему письмо и выдаем действие-маркер. Так как мы обрабатываем каждого потребителя в отдельной транзакции, блокировки накладываются только на данные одного потребителя и на работу остальных потребителей не влияют. Так как такая транзакция очень короткая, у потребителя, которому отправляют письмо, также не будет особых проблем, если он в это время ходит по сайту. Уровень изоляции транзакции должен быть именно Serializable, чтобы ненароком не отправить одно письмо дважды, или не отправить письмо тому потребителю, который внезапно перестал подходить под условия. Хотя, если мы гарантируем, что отправка одной и той же рассылки может идти только из одного потока и с одного сервера, а также забьем на небольшую вероятность того, что одному потребителю могут отправится две рассылки с взаимоисключающими условиями, то можно использовать и Read Committed транзакцию.
Само собой после реализации нескольких рассылок по этому шаблону, мы решили вынести шаблонный код. Для этого был создан класс
BatchMailing, и для каждой новой рассылки мы создавали и регистрировали в специальном реестре его наследника. В наследнике необходимо было перегрузить следующие свойства и методы:
- шаблон действия-маркера (раньше мы называли шаблон типом действия: думаю, для разработчиков это более понятный термин), которое выдается при отправке письма
- метод, отправляющий письмо
- метод, выполняющий дополнительные действия (например, вместе с отправкой поздравления с днем рожденья, мы можем выдавать потребителю баллы на счет)
- метод, который формирует Expression<Func<Customer, bool>>, проверяющий, что потребитель подходит под условие
Свойство и первые два метода никогда никаких проблем не вызывали, но вот составить
Expression было довольно таки не просто. Этот Expression использовался два раза — сначала в Read Uncommitted запросе, чтобы вытащить Id потребителей, а затем в Serializable транзакции, чтобы повторно проверить подходит ли потребитель под условие. Его было нужно написать так, чтобы
Linq to SQL смог его транслировать в T-SQL. Условия могли быть довольно сложными и в них всегда возникали проблемы. Ни одну рассылку нельзя было завести не написав на нее кучку тестов. Кроме того, для отправки СМС и email мы завели разных промежуточных наследников от BatchMailing. Когда же нам надо было отправить и email и СМС, приходилось копипастить. У меня были идеи как это исправить, но так как автоматические рассылки клиенты просили не так уж и часто, это была низкоприоритетная задача.
Замена наследования композицией
2 года назад при разработке очередной рекламной кампании клиент попросил сделать ему сразу 8 разных автоматических рассылок. При этом частично условия в рассылках повторялись. Тут уже не оставалось сомнений, что больше так жить нельзя, и я взялся за переписывание нашей архитектуры. Для того чтобы справится со всеми описанными выше проблемами достаточно было применить наш любимый прием: замену наследования композицией. Этот прием настолько много раз нам помогал, что я советую использовать композицию вместо наследования везде, где это возможно (ну или как минимум рассматривать такой вариант). Если вы создаете базовый абстрактный класс с мыслью “для каждой конкретной задачи у меня будет наследник перегружающий методы и свойства”, сразу спрашивайте себя “а почему бы мне вместо этого не регистрировать для каждой задачи экземпляр класса, передавая ему разные настройки”. И только если вы уверены, что композиция здесь не подходит, используйте наследование. Если подходит и то и то, всегда склоняйтесь к композиции — так получается гораздо более гибкая и понятная архитектура.
В нашей ситуации:
- вместо перегрузки свойства, возвращающего шаблон действия-маркера, это свойство проставляется экземпляру класса
- вместо перегрузки методов отправляющих письма/смс и выполняющих дополнительную логику, у экземпляра класса проставляется произвольная операция, которую нужно совершить над потребителем. При этом операция может быть комбинацией из других операций
- вместо перегрузки метода формирующего Expression, экземпляру класса проставляется условие. При этом условия можно комбинировать через И/ИЛИ
Так как кроме отправки рассылок эта сущность теперь может выполнять любые произвольные операции над потребителем, рассылкой ее называть некорректно. Фактически это класс который делает какую-то абстрактную работу над заданной выборкой потребителей. Не придумав ничего лучше, мы стали называть это
триггерами (в маркетинге их примерно так и называют, так что название неплохое). Меня, честно говоря, немного пугало то, что я ввел в систему крайне абстрактную сущность, которую можно назвать
DoSomeWorkOnSomeCustomers. Но никакого смысла в специализации триггеров не было, так что я решил над этим не заморачиваться, и в принципе больших проблем с пониманием, что такое триггер, у клиентов не возникает.
Регистрация триггера выглядела примерно следующим образом:
Add(new Trigger(“Приглашение на сайт для пришедших через канал one-to-one”)
{
MarkerActionTemplateSystemName = “InvitationMarker”,
TriggerAction = new TriggerActionCombination(
new GeneratePasswordForCustomerTriggerAction(),
new SendEmailTriggerAction(“InvitationMailing”)),
TriggerCondition = new AndTriggerConditionSet(
new CustomerHasSubscripionCondition(),
new CustomerHasEmailTriggerCondition(),
new CustomerHadFirstActionOverChannelCondition(“OneToOne”)),
});
Интерфейс
TriggerAction’а крайне прост:
public interface ITriggerAction
{
void Execute(
ModelContext modelContext, // класс для работы с БД
Customer customer);
}
Базовый класс для условий триггера выглядит следующим образом:
public class TriggerCondition
{
private readonly Func<ModelContext, Expression<Func<Customer, bool>>> triggerExpressionBuilder;
public TriggerCondition(Func<ModelContext, Expression<Func<Customer, bool>>> triggerExpressionBuilder)
{
if (triggerExpressionBuilder == null)
throw new ArgumentNullException("triggerExpressionBuilder");
this.triggerExpressionBuilder = triggerExpressionBuilder;
}
public Expression<Func<Customer, bool>> GetExpression(ModelContext modelContext)
{
return triggerExpressionBuilder(modelContext, brand);
}
// Используется в Read Uncommitted транзакции для получения спиcка Id потребителей, подходящих под условие
public IQueryable<Customer> ChooseCustomers(ModelContext modelContext, IQueryable<Customer> customers)
{
if (modelContext == null)
throw new ArgumentNullException("modelContext");
if (customers == null)
throw new ArgumentNullException("customers");
var expression = GetExpression(modelContext);
return customers.Where(expression).ExpandExpressions();
}
// Используется в Serializable транзакции, для проверки, что потребитель все еще подходит под условие
public bool ShouldTrigger(ModelContext modelContext, Customer customer)
{
if (modelContext == null)
throw new ArgumentNullException("modelContext");
if (customer == null)
throw new ArgumentNullException("customer");
var expression = GetExpression(modelContext);
// Можно бы было просто вызывать expression.Evaluate(customer),
// но тогда для сложных условий выполнилось бы несколько запросов в БД вместо одного
return modelContext.Repositories.Get<CustomerRepository>().Items
.Where(aCustomer => aCustomer == customer)
.Where(aCustomer => expression.Evaluate(aCustomer))
.ExpandExpressions()
.Any();
}
}
Для часто используемых условий мы создавали наследников от
TriggerCondition, в которых строился конкретный Expression в зависимости от переданных в конструктор параметров.
Все, надоело, сами заводите свои триггеры
С использованием архитектуры, описанной выше, мы заводили триггер менее чем за пол часа, за счет комбинирования уже написанных условий и TriggerAction’ов. Однако и этого нам было мало. Следующим шагом мы захотели полностью исключить разработчиков из процесса заведения триггеров. Причем как это делать в общих чертах я понял уже через пару месяцев после реализации предыдущей версии архитектуры. Условия триггеров были один в один похожи на
фильтры, которые мы используем в админке. Наша система фильтров позволяет описывать сложные условия, включая запросы к связанным сущностям, а также позволяет комбинировать их через И/ИЛИ. Фильтр формирует Expression, с помощью которого уже можно отфильтровывать сущности в БД. И для всего этого уже был написан UI и сериализация. Оставалось лишь добавить пару фильтров, которые часто нужны для триггеров, но не имели смысла при обычной работе со списком потребителей (например: “с действия прошло N дней”). Для TriggerAction’ов надо было написать UI и структуру для хранения их в БД, но тут тоже в общем все было понятно. Однако оставались еще небольшие вопросы, над которым пришлось поломать голову:
- отсылку любого письма мы к этому времени стали регистрировать как действие, и действие-маркер стало лишним — мы и так могли определить, кому мы отправляли письмо, и вообще хотелось бы избавиться от выдачи лишних действий везде, где это было возможно
- кроме простых триггеров, которые выполняли определенный набор операций один раз над каждым потребителем, у нас появились периодические триггеры. Надо было придумать как это все перенести в БД и при этом позволить использовать произвольные маркеры
- маркетологи придумывают триггеры не отдельно друг от друга, а в качестве цепочек, в которых есть как триггеры так и операции, выполняемые потребителем на сайте (письмо с предложением зайти на сайт и что-то сделать → потребитель выполняет несколько операций на сайте → начисляются бонусные баллы и посылается письмо об этом). Хотелось бы если и не реализовать это сразу, то оставить задел на будущее, чтобы было не сложно описывать зависимости между триггерами и операциями
Все эти три проблемы связаны с тем, как мы определяем выполнился ли триггер над потребителем или нет. Если заводить для каждого триггера и операции на сайте свой маркер, задача сильно упрощается, но плодить лишние действия в системе очень не хотелось. Была даже идея заставлять менеджеров составлять фильтр таким образом, чтобы он полностью отвечал за то, можно ли сейчас выполнить действие над потребителем (и соответственно частота повторения триггера описывалась бы условием в фильтре), однако данный подход слишком уж располагает к ошибкам. После долгих мучительных размышлений мне все-таки пришла идея, как отслеживать выполнение триггеров без дополнительных сущностей и без усложнения работы менеджера.
Нужно больше Expression’ов
Так как триггер выполняет абстрактный
шаг операции (бывший TriggerAction) над потребителем, причем почти всегда этот шаг операции уникален (например, определенное письмо отсылается или определенный приз выдается только из этого триггера), то в этот шаг можно вынести логику проверяющую выполнился ли он. Так как в триггере может быть несколько шагов операции, то менеджеру надо будет выбрать какой из них является
маркером (проверять выполнение каждого шага не имеет смысла). Однако просто, реализовать в шаге операции метод, возвращающий
Expression<Func<Customer,bool>> нельзя, так как пришлось бы в каждом шаге операции формировать один Expression для одноразовых триггеров, другой для периодических. Тут нас спасает то, что практически любая операция над пользователем в нашей системе выдает ему действие. Соответственно шаг операции может отфильтровать те действия, которые были выдан им. Большинство шагов операции выдают конкретное действие и для них метод, формирующий Expression для фильтрации действий, выглядит вот так:
public sealed override Expression<Func<CustomerAction, bool>> GetIsMarkerExpression(ModelContext modelContext)
{
return action => action.ActionTemplateId == ActionTemplateId;
}
Но, например, у шага, выдающего приз, он выглядит следующим образом:
public override Expression<Func<CustomerAction, bool>> GetIsMarkerExpression(ModelContext modelContext)
{
IQueryable





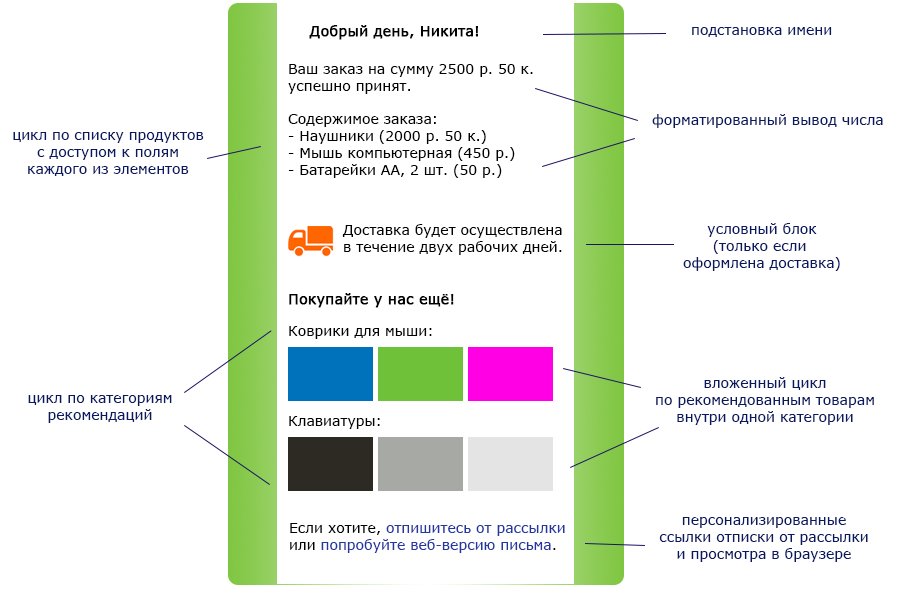

 У нас в солюшене 51 проект. В 10 из них используется TypeScript. Объем минимизированного JavaScript-кода ~1 MB. TypeScript-код одних проектов зависит от кода других проектов. Для многих React-компонентов используются глобальные переменные.
У нас в солюшене 51 проект. В 10 из них используется TypeScript. Объем минимизированного JavaScript-кода ~1 MB. TypeScript-код одних проектов зависит от кода других проектов. Для многих React-компонентов используются глобальные переменные.