
Что такое квадриллион? Это единица с 15-ю нулями, численность популяции муравьев на планете или 100 световых лет в километрах. А еще это объем торгов в рублях на Московской бирже за 2021 год.
Чтобы достичь такого результата, компания должна быть очень технологичной, очень надежной и очень быстрой. Поэтому более 50% штата Биржи – айтишники, работающие с передовым набором технологий, уровень надежности наших ИТ-систем стабильно составляет 99,99%, а еще мы постоянно разгоняем наши системы и процессы. Об одном из примеров такого ускорения рассказывает Григорий Доможиров, разработчик сервиса Data Grid.
– В компании есть куча систем-источников данных с одной стороны и систем-потребителей этих данных с другой. Я разрабатываю сервис, в котором эти данные сохраняются, предоставляя потребителям универсальный интерфейс доступа. Входящих данных генерируется много и происходит это быстро, а мы сохраняем их на скорости свыше 500 тысяч записей в секунду на пике.
Каким должно быть хранилище, чтобы выдерживать такие скорости? Во-первых In-memory, чтобы не тормозить о диск, во-вторых, – распределённым, чтобы распараллеливать запись. Такой класс решений называется In-Memory Data Grid, и яркий его представитель — Apache Ignite. Но просто установить его мало – чтобы добиться от него максимальной производительности, нужно правильно его «приготовить». И сейчас я расскажу, как.
Содержание
Задача
Будем складывать в key-value кеш входящий поток записей. Казалось бы, типичная задача и базовая операция, однако есть как минимум три способа это сделать, и рекомендуемый — не всегда самый быстрый. Неважно, откуда поступают данные (у нас это Apache Kafka), важно, что мы хотим обрабатывать максимально большой поток — то есть, добиться максимального количества записей в секунду при ограниченной задержке. Будет обзор API, подводные камни, бенчмарки влияния множества параметров, а также практические рекомендации на основе опыта разработки и года эксплуатации в проде.
Выбор API
Формализуем задачу. Пусть данные на входе представлены объектом некоторого класса с рядом полей, для определенности таким: «Value Object» или «POJO».
public class Data {
private byte[] payload;
private int int1 = 0;
private int int2 = 0;
private int int3 = 0;
private int int4 = 0;
private int int5 = 0;
private int int6 = 0;
private int int7 = 0;
private int int8 = 0;
private int int9 = 0;
...
}
Тип, имена и значения полей не так важны. Важно, что они примитивного типа, в реалистичном количестве, а объем в байтах можно варьировать. Будем реализовывать такой интерфейс:
write(List<Entry<Integer, Data>> data, IgniteCache<Integer, Data> cache);
и добиваться максимальной скорости выполнения. кеш будет in-memory (не персистентный), атомарный (не транзакционный) и партиционированный. Запускать всё будем на GridGain Community Edition 8.8.3 – это доработанный аналог Apache Ignite 2.8.3, заявляемый как production-ready. В версии Community Edition также бесплатный.
Put
Первая попытка в лоб: есть же
IgniteCache.put(...)! Заполняли бы мы, например, HashMap — так бы и делали. Создадим кеш по умолчанию:ignite.createCache("benchmark");
и переложим в него данные:
data.forEach(entry -> cache.put(entry.getKey(), entry.getValue()));
Каждый объект наполним 200 байтами данных и запустим бенчмарк на кластере из 5 машин (Intel® Xeon® E5-2640 v3 @ 2,60 ГГц с виртуализацией, сеть 1000 Мбит/сек.). Высокопроизводительная распределённая система выдаст… 2555 записей/сек. 😕
Это никуда не годится, что-то мы делаем не так.
Data Streamer
В предыдущих версиях документации было явно написано — не используйте put, используйте IgniteDataStreamer:

Что же, получаем IgniteDataStreamer:
final IgniteDataStreamer<Integer, Data> dataStreamer = ignite.dataStreamer(cache.getName());
и пишем через него те же данные, не забывая, если нужно, периодически flush’ить. Например, каждые 1000 записей, или настроив
IgniteDataStreamer#autoFlushFrequency(long autoFlushFreq):data.forEach(entry -> {
dataStreamer.addData(entry.getKey(), entry.getValue());
if (...) {
dataStreamer.flush();
}
});Получаем 228 493 записей в секунду. Другое дело! Задача решена? В общем случае, оказывается, нет. Если в кеше уже содержится значение для записываемого ключа, то новые данные сохранены не будут.

При этом, предложенный
allowOverwrite(true) мало полезен, т.к. в javadoc к IgniteDataStreamer скрывается крайне важный нюанс, умолченный в документации:
Это значит, что более свежее значение для ключа может быть перезаписано более старым значением!
Более того, вероятно, вы захотите сделать ваш кеш терпимым к потере одного узла кластера настроив 1 бэкап, то есть однократную репликацию.
final CacheConfiguration<Integer, Data> cacheConfiguration =
new CacheConfiguration<Integer, Data>("benchmark")
.setBackups(1)
.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC)
.setAtomicityMode(CacheAtomicityMode.ATOMIC)
.setCacheMode(CacheMode.PARTITIONED);
ignite.createCache(cacheConfiguration);CacheWriteSynchronizationMode.FULL_SYNC заставит Ignite считать запись оконченной только когда она завершена на всех узлах, включая реплики. Будьте внимательны, режим по умолчанию — PRIMARY_SYNC. CacheAtomicityMode.ATOMIC и CacheMode.PARTITIONED — явно указанные значения по умолчанию. В таком режиме (наличие бэкапов и включенный
allowOverwrite) Data Streamer начинает работать через тот самый медленный put. Скорость в таком бенчмарке составила ничтожные 23 623 записи в секунду!Тут можно было бы пофантазировать про фильтр Блума и интеллектуальный вызов
flush(), но реальность проста: не используйте Data Streamer при неуникальных ключах. А при уникальных ключах — это эффективный API, можно использовать.PutAll
Третий способ записи —
IgniteCache.putAll(). Как и раньше, для ограничения задержки будем нарезать входящий поток на пачки (batch-и) и писать их последовательно. data.forEach(entry -> {
final TreeMap<Integer, Data> batch = batchHolder.get();
batch.put(entry.getKey(), entry.getValue());
if (...) {
cache.putAll(batch);
batchHolder.set(new TreeMap<>());
}
});Влияние размера пачки мы рассмотрим ниже. А пока запустим привычный тест и сравним со скоростью записи через Data Streamer при различных параметрах, включая частоту повторения ключей. При неуникальных ключах, как мы помним, использовать Data Streamer нельзя, поэтому значения для Data Streamer в таких случаях отмечены серым и приведены исключительно для сравнения.

Как видите, при уникальных ключах
putAll даёт меньшую, но сравнимую скорость. При увеличении частоты перезаписи по ключу скорость объяснимо резко растёт: из всех записей с одним ключом в рамках batch’а будет записана только одна — самая свежая. Остальные «схлопнутся» в локальной HashMap. Фактически при 50 %-ном повторении ключей в Ignite будет записана половина от входящих POJO, что и даёт примерно вдвое более высокую скорость записи. Полезное свойство, у нас оно особенно активно проявляется при запуске системы.Обратите внимание, что я использовал именно TreeMap. При использовании HashMap вы получите ценное предупреждение в логах:
LT.warn(log, "Unordered map " + m.getClass().getName() +
" is used for " + op.title() + " operation on cache " + name() + ". " +
"This can lead to a distributed deadlock. Switch to a sorted map like TreeMap instead.");При параллельном запуске нескольких
putAll действительно легко получить deadlock, а в трассировке стека серверных узлов — увидеть вереницу блокировок. Не рассчитывайте на то, что putAll никогда не будет вызван параллельно, тем более что это может быть другой процесс на другом компьютере, работающий на том же кластере.Итог таков: если вы пишете данные с уникальными ключами — используйте Data Streamer, иначе —
putAll. Или всегда putAll, если не хотите заморачиваться ;)Влияние параметров потока, кеша и кластера
SQL
Ignite позволяет настроить SQL поверх кеша и делать к нему SQL-запросы, как будто это таблица. Мы, кстати, этим пользуемся. Дает ли это избыточную нагрузку? Давайте посмотрим.
Настроить SQL можно через аннотации в POJO или в конфигурации кеша при его создании, cпособы эквивалентны. Мы используем второй из них, это позволяет применять универсальные классы POJO, не зависящие от Ignite. Включаем SQL:
Код
final LinkedHashMap<String, String> fields = new LinkedHashMap<>();
fields.put("payload", byte[].class.getName());
fields.put("int1", Integer.class.getName());
fields.put("int2", Integer.class.getName());
fields.put("int3", Integer.class.getName());
fields.put("int4", Integer.class.getName());
fields.put("int5", Integer.class.getName());
fields.put("int6", Integer.class.getName());
fields.put("int7", Integer.class.getName());
fields.put("int8", Integer.class.getName());
fields.put("int9", Integer.class.getName());
cacheConfiguration.setQueryEntities(Collections.singleton(new QueryEntity()
.setValueType(Data.class.getName())
.setTableName("Data")
.setFields(fields)));Замеряем при разном размере кластера, методе записи, количестве бэкапов, размере batch’а, объёме данных и использовании Binary Object (обсудим ниже):
Таблица с результатами
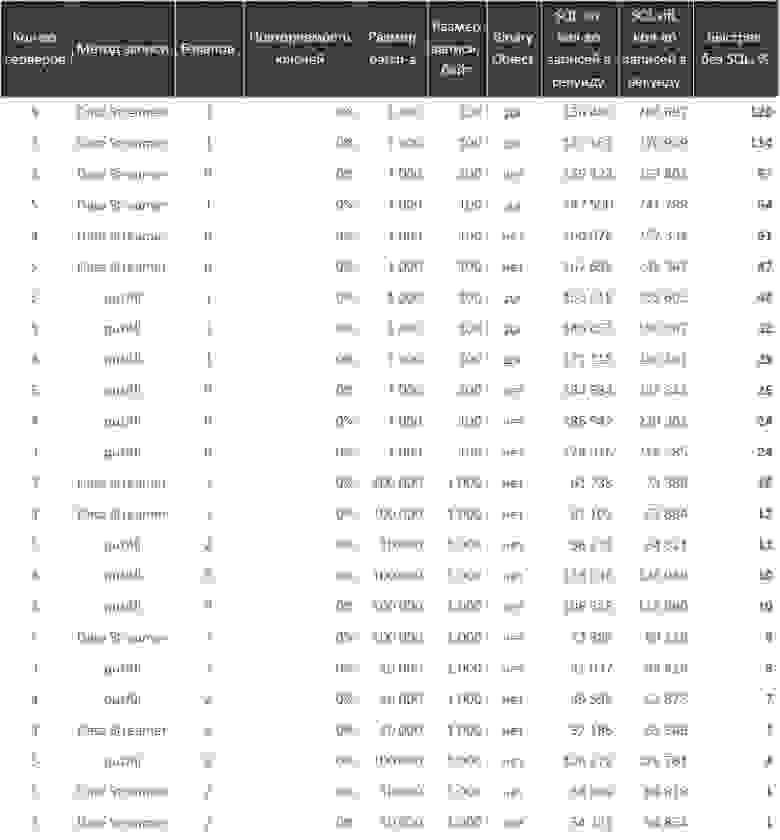
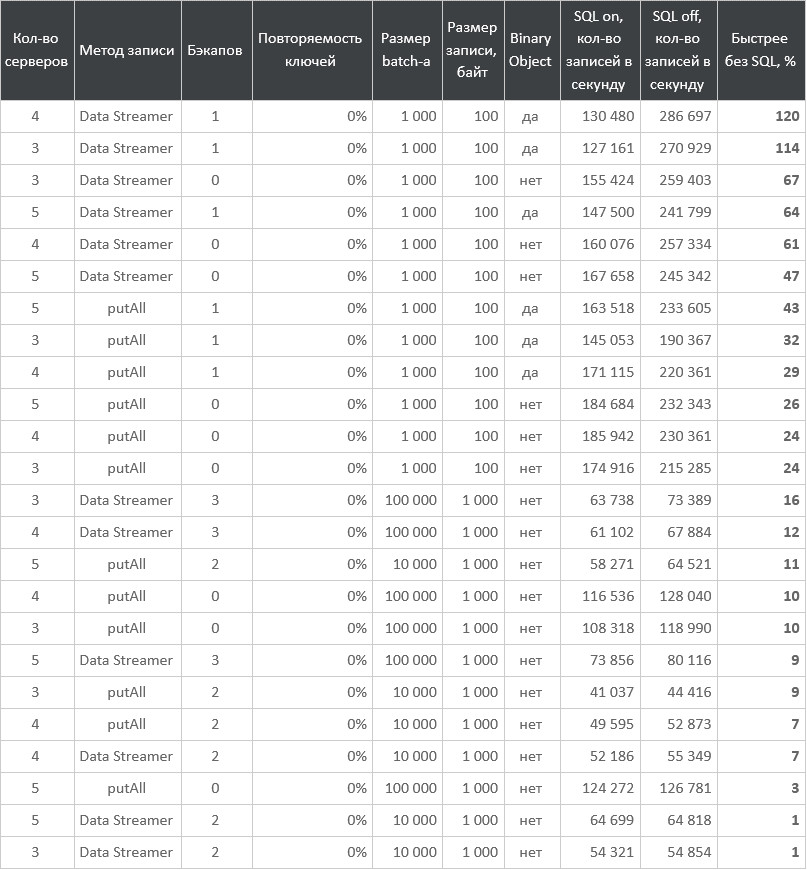
Как видите, избыточная нагрузка сильно различается: от практически нуля до более чем двух раз. В реальности, скорее всего, вы включите SQL только в том случае, если он вам нужен. А с возможным overhead останется только смириться.
Запись с серверного узла
Немного теории. Все узлы кластера Ignite могут быть одного из трех типов: клиентский, серверный или тонкий клиент. Тонкий клиент долгое время имел ограниченный API, его я рассматривать не буду. Полагаю, производительность на запись будет близка к «толстому» клиенту. Тип узла задается в конфигурации Ignite при его запуске:
Ignition.start(new IgniteConfiguration().setClientMode(true) ...)
Основное отличие клиентского узла от серверного в том, что он не хранит данные. Все данные кеша хранятся на серверных узлах.
Из этого свойства следует потенциальное ускорение при записи с серверного узла: не нужно лишний раз гонять данные по сети с клиента на сервер. Все вышеприведённые примеры выполнены с клиентского узла. Если вы захотите писать с серверного узла, то советую посмотреть на singleton service и compute jobs.
Результаты бенчмарков при различных параметрах кеша и данных:
Таблица с результатами


Видим незначительное ускорение на кластере из пяти серверных узлов и более существенное на кластере из двух.
Размер POJO
Очевидно, что чем больше весит каждая запись в байтах, тем дольше она будет передаваться по сети, потенциально замедляя процесс записи. Запускаем бенчмарки и получаем:

Таблицы с результатами

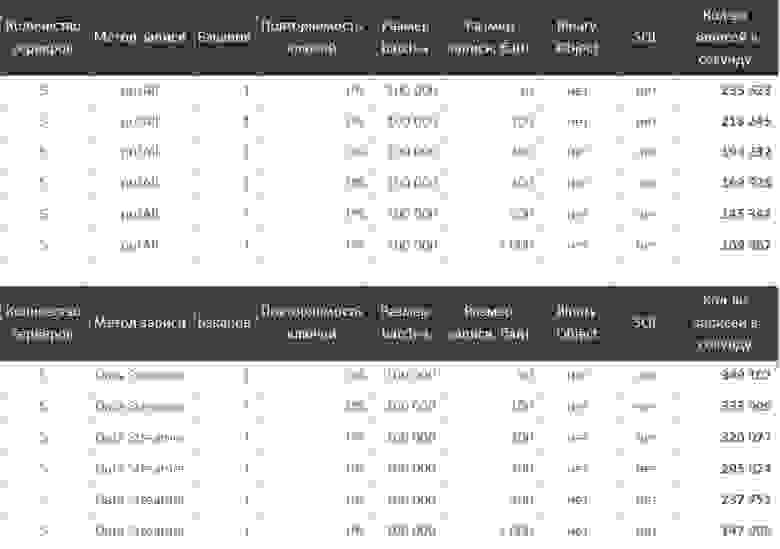
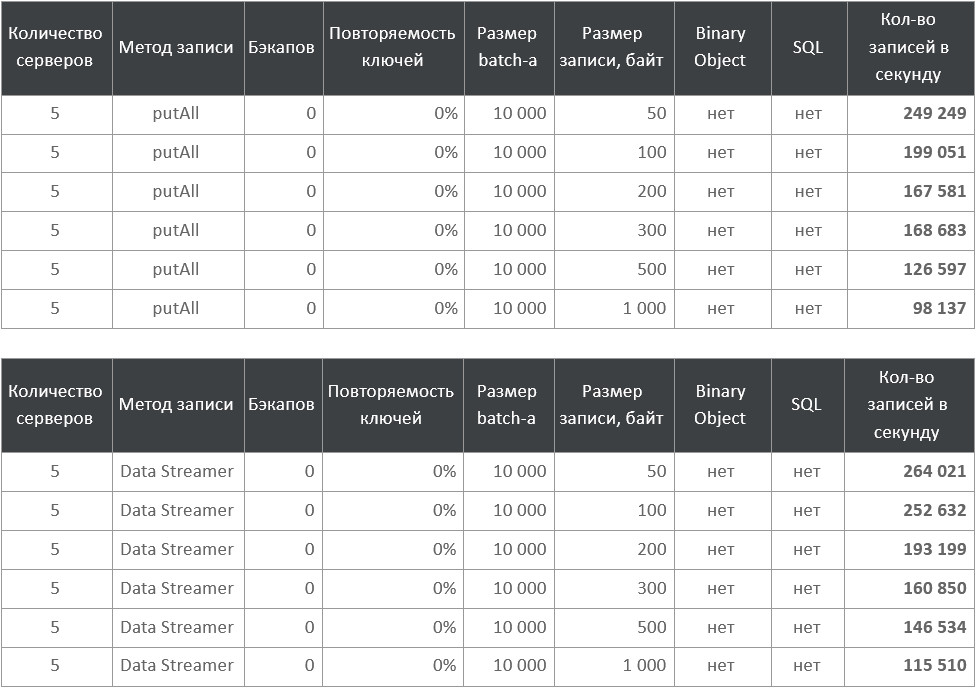

Не стоит сравнивать линии между собой, важно, что вне зависимости от способа записи и наличия бэкапа по мере роста размера объекта скорость записи ожидаемо падает. При небольших значениях разница особенно существенна.
Размер batch’а
Один из параметров — размер записываемой пачки в штуках. Для Data Streamer — это частота flush’а, для
putAll — размер накапливаемой Map. Увеличивая размер пачки мы жертвуем задержкой в угоду вероятного повышения скорости. Давайте посмотрим, действительно ли это того стоит:
Таблицы с результатами




Тут есть необъяснимая просадка при 10 000, а в остальном скорость растёт, особенно сильно при увеличении размера пачки до 1 000.
Количество бэкапов
Один из параметров кеша — количество бэкапов, то есть дополнительных узлов кластера, на которые будет записана реплика каждой партиции данных. Количество бэкапов определяет, сколько серверных узлов кластера может одновременно его покинуть, например, «упасть». Если узлы будут покидать кластер последовательно, то бэкапы будут перераспределяться по оставшимся узлам, чтобы поддерживалось заданное количество.
Очевидно, что чем больше бэкапов, тем больше нужно будет выполнить записей, что замедлит процесс записи в кеш.
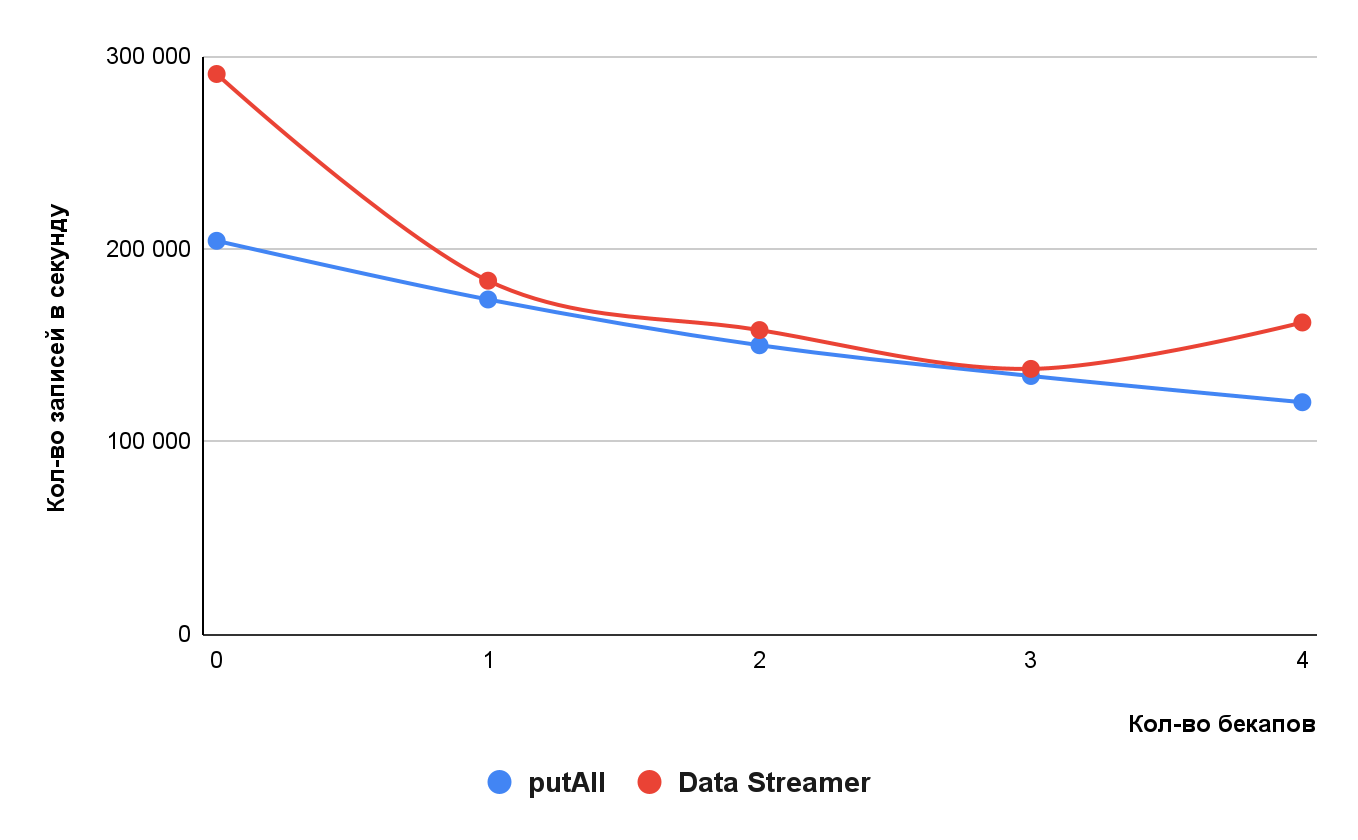
Таблицы с результатами
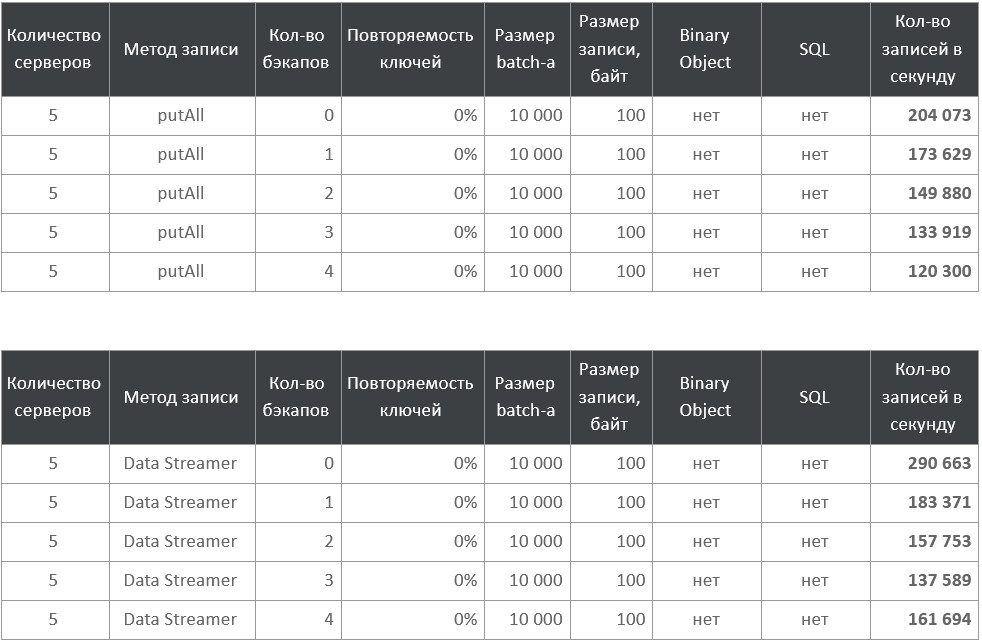
Здесь мы видим примерно линейную зависимость для
putAll. Для Data Streamer — более сложную с аномалией на четырёх бэкапах, которую я объяснить не могу.Размер кластера
Пришло время проверить Ignite на горизонтальную масштабируемость. Поскольку записываемые данные распределяются по всем серверным узлам кластера, увеличение его размера будет распараллеливать запись, теоретически увеличивая скорость. Проверяем:

Таблица с результатами


Признаем наличие горизонтального масштабирования, хоть и с не очень большим коэффициентом.
Binary Object
Ignite хранит данные в своём бинарном формате. Когда мы пишем в кеш объекты нашего класса, они будут в него сериализованы с помощью reflection. Можно ли помочь в этом Ignite’у? Да. Есть механизм Binary Object — обёртки над бинарным представлением. Выглядит вот так:
final BinaryObjectBuilder builder = Ignite.binary().builder(Data.class.getName());
builder.setField("payload", payload, byte[].class);
...
builder.setField("int9", int9, Integer.class);
final BinaryObject binaryObj = builder.build();Чтобы записывать полученный Binary Object в кеш, нужно получить его бинарное представление:
IgniteCache<Integer, BinaryObject> binaryCache = ignite.cache("cacheName").withKeepBinary();
Фактически мы вместо reflection говорим Ignite, что мы пишем объект вот такого класса (указываем
String), и в нём есть поля вот с такими названиями (указываем String) с вот такими значениями (передаем Object). Другое полезное свойство Binary Object — вам не обязательно даже иметь класс для ваших данных! Например, можно взять ResultSet какого-нибудь SQL-запроса и переложить поля из него сразу в Binary Object. Какое название класса передать, на самом деле, не важно. Он не обязан быть в classpath ни у клиента, ни у серверного узла, ни даже существовать в принципе. Существование класса понадобится при чтении из кеша, если вы захотите читать его в виде объектов этого класса, а не через Binary Object или SQL. Отмечу, что признак .withKeepBinary() — это свойство представления кеша. В один и тот же кеш можно писать как через POJO, так и через Binary Object.Настоятельно рекомендую использовать именно сигнатуру с указанием класса третьим аргументом:
<T> BinaryObjectBuilder setField(String name, T val, Class<? super T> type)
вместо
BinaryObjectBuilder setField(String name, Object val)
Почему? Дело в том, что Ignite хранит и распространяет по кластеру метаинформацию об известных типах и их полях. Когда для какого-то типа (его название вы передаете в
Ignite.binary().builder(typeName)) вы впервые вызовете BinaryObjectBuilder setField(String name, Object val) с новым name, то Ignite выполнит val.getClass(), чтобы запомнить, к какому классу относится поле name. Если val окажется null, это станет невозможным и Ignite будет считать это поле класса Object, что станет ошибкой. Дальнейшие setField с val != null не помогут: изменение типа полей невозможно. кеш будет сломан до перезапуска кластера.Быстрее ли писать через Binary Object? Если сначала переводить объекты Data в Binary Object и потом их писать:
final List<Entry<Integer, Data>> data = ...;
final Stream<Entry<Integer, BinaryObject>> binaryStream = data.stream().map(...);
binaryStream.forEach(entry -> {
dataStreamer.addData(entry.getKey(), entry.getValue());
if (...) {
dataStreamer.flush();
}
});то нет:

А вот если подготовить Binary Object заранее:
final List<Entry<Integer, BinaryObject>> data = ...;
data.forEach(entry -> {
dataStreamer.addData(entry.getKey(), entry.getValue());
if (...) {
dataStreamer.flush();
}
});то будет быстрее:

Ускорение до полутора раз! Рекомендую, мы всё пишем через Binary Object. Читайте следующий раздел, чтобы узнать, как использовать второй подход.
Дополнительные советы
Распараллельте запись и подготовку данных
Выше мы рассматривали скорость записи уже готового
List<Dаta> или List<BinaryObjеct>. В реальности его нужно откуда-то получить, вероятно, десериализовать и/или создать BinaryObject, что требует времени. Следовательно, подготовку данных нельзя делать последовательно с вызовом putAll(...), который блокируется до окончания записи. Распараллелить подготовку данных можно с помощью небокируемого putAllAsync(...), возвращающего IgniteFuture<Vоid>. Вызывайте putAllAsync, и пока Ignite трудится над записью, готовьте следующую пачку, чтобы, как только запись завершится, начать новую, не давая Ignite’у простаивать. Примерно так:private IgniteFuture<Void> currentWriteFuture;
public void pollAndWriteLoop() {
while (!Thread.currentThread().isInterrupted()) {
final Iterable<byte[]> serializedPojos = pollSerializedData();
final Map<Integer, BinaryObject> batch = deserializeAndCollect(serializedPojos); //CPU expensive
currentWriteFuture.get(); //throws IgniteInterruptedException extends RuntimeException
currentWriteFuture = cache.putAllAsync(batch);
}
}Обратите внимание, что операция
IgniteFuture.get() ожидаемо блокирующая, но вместо контролируемого java.lang.InterruptedException бросает unchecked org.apache.ignite.IgniteInterruptedException. Не забывайте про него.Используйте CacheEntryProcessor
Бывает, что вы хотите для определенного ключа обновить только некоторые поля записи, не изменяя остальные. Может быть, вы даже не имеете полной записи чтобы записать ее любым описанным выше методом. Ни в коем случае не пытайтесь прочитать запись, обновить ее на клиенте и записать целиком обратно. Это и не атомарно, и очень долго. Используйте специальный механизм Ignite EntryProcessor, он позволяет вместо записи отправить в Ignite код, который выполнится на серверном узле, хранящем запись для указанного ключа. Этому коду будет доступно текущее значение и возможность его обновить. Примерно так:
public class PojoUpdateProcessor implements CacheEntryProcessor<Integer, Data, Void> {
public PojoUpdateProcessor(byte[] newPayload, int newInt3) {
...
}
@Override
public Void process(MutableEntry<Integer, Data> mutableEntry, Object... objects) throws EntryProcessorException {
final Data currentPojo = mutableEntry.getValue();
...
mutableEntry.setValue(...);
return null;
}}Вызывается при помощи
IgniteCache.invoke(K key, CacheEntryProcessor<K,V,T> entryProcessor, Object... arguments) и подобных. Ваш класс, реализующий CacheEntryProcessor, должен находится в classpath серверных узлов, либо необходимо включить peer class loading. Вне зависимости от того, как вы пишете в кеш, в EntryProcessor можно использовать BinaryObject. Это позволяет, например, написать универсальный EntryProcessor, который изменяет любые указанные поля любого кеша:
Код
public class NoArgBinaryObjectMutator implements CacheEntryProcessor<Object, BinaryObject, Object> {
private static final long serialVersionUID = 1L;
private final Map<String, Object> updatedNonNullFields;
private final Map<String, Class<?>> updatedToNullFields;
private final Map<String, Class<?>> notAffectedFields;
private final String typeName;
@SuppressWarnings("unused") @IgniteInstanceResource
private Ignite ignite;
public NoArgBinaryObjectMutator(Map<String, Object> updatedNonNullFields, Map<String, Class<?>> updatedToNullFields, Map<String, Class<?>> notAffectedFields, String typeName) {
this.updatedNonNullFields = updatedNonNullFields;
this.updatedToNullFields = updatedToNullFields;
this.notAffectedFields = notAffectedFields;
this.typeName = typeName;
}
@Override
public Object process(MutableEntry<Object, BinaryObject> entry, Object... arguments) throws EntryProcessorException {
final BinaryObject value = entry.getValue();
final BinaryObjectBuilder objectBuilder;
if (value == null) {
objectBuilder = ignite.binary().builder(typeName);
notAffectedFields.forEach((fieldName, fieldClass) -> objectBuilder.setField(fieldName, null, fieldClass));
} else {
objectBuilder = value.toBuilder();
}
updatedNonNullFields.forEach(objectBuilder::setField);
updatedToNullFields.forEach((fieldName, fieldClass) -> objectBuilder.setField(fieldName, null, fieldClass));
entry.setValue(objectBuilder.build());
return null;
}
}Важная особенность: как я писал выше, когда вы впервые вызываете
setField(...) для какого-то поля, Ignite распространяет по кластеру мета-информацию о новом поле в указанном типе. Это очень небыстрый процесс, замедляющий запись. Поэтому лучше с первой же записью передать в BinaryObject все ожидаемые поля класса. Для тех, которые пока проставлять не хотите, — со значением null. Итоговая памятка
Главный вывод: самый быстрый способ записи в Ignite — IgniteDataStreamer, но его можно использовать, только если ключи в вашем кеше уникальны, то есть заведомо не может быть обновления записи для уже существующего ключа. Иначе используйте только
IgniteCache.putAllAsync, распараллеливая подготовку и запись данных — производительность сравнима с IgniteDataStreamer. А также:- Пишите через BinaryObject вместо POJO своего класса. При этом используйте метод
setFieldс сигнатурой из трех аргументов(String, T, Class<? extends T>), а не двух. При первой записи в кеш обязательно добавьте в объект BinaryObject все поля класса, включая те, что равныnull. - Пишите настолько большими batch’ами, насколько можете себе позволить.
- Настройте кеш с умом: включенный SQL, большой backup factor и лишние или тяжёлые поля уменьшают скорость записи.
- Запись можно ускорить, выполняя её с серверного узла. Может помочь singleton service.
- Если вам нужно поменять лишь несколько полей из многих, то используйте Entry Processor.
- У вас есть возможность горизонтального масштабирования при помощи увеличения количества машин в кластере.
