
Насколько популярна сегодня тема атомарных данных, настолько же она обширна для одной статьи. Можно подробно останавливаться на разных аспектах атомарности: например, анализировать memory ordering, рассуждать о lock-free алгоритмах с использованием атомиков или исследовать производительность атомиков на разных платформах.
Под катом мы рассмотрим некоторые базовые принципы работы с атомарными типами данных в языке C++. А именно: осветим работу с атомарными данными, основные операции с ними в стандартной библиотеке C++, а также некоторые аспекты использования атомиков с пользовательскими типами данных.
Обращаемся к истории
Привет, Хабр! Меня зовут Александр Ключев, в МойОфис я ведущий инженер-программист и занимаюсь разработкой кросс-платформенного почтового клиента. В работе нашей команде часто приходится сталкиваться с многопоточностью, в частности — с атомиками. Этот опыт и натолкнул меня на мысль о создании статьи (возможно, не одной) по данной тематике.
Начну с очевидного тезиса: многопоточность в С++ до 11-го стандарта не существовала. Поэтому ответом на классический вопрос про race condition, когда мы меняем общую переменную из разных потоков применительно к древним версиям — до С++11, является даже не undefined behavior, а то, что такая ситуация некорректна в принципе.
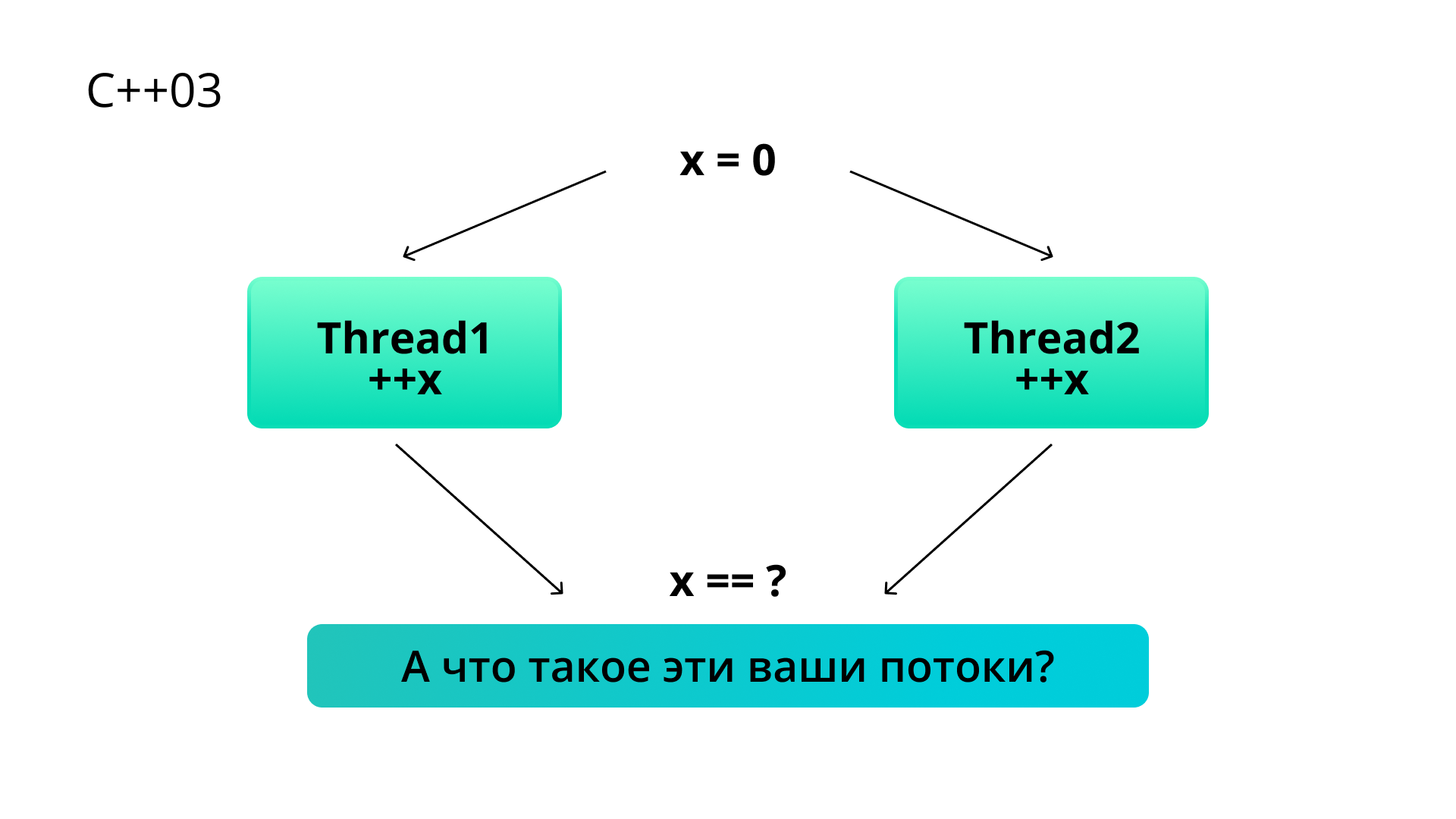
Разумеется, мы уже давно пишем многопоточные программы, и разработчики компиляторов знают об этом. Поэтому формально история создания потоков и многопоточной обработки не запрещена. Разработчики создавали многопоточные библиотеки под разные платформы, но каждый раз — «на свой страх и риск»: в стандарте потоков не существовало, и каждый разработчик компилятора мог реализовывать многопоточную логику как ему угодно.
В C++ 11 ситуация кардинальным образом изменилась. В стандарт наконец-то добавили понятие потока исполнения, информацию о том, что их может быть несколько и о том, что именно должно происходить, когда некий код выполняется из разных потоков.
Поэтому с появлением стандарта C++ 11 ответом на тот же вопрос про race condition уже однозначно является UB. Казалось бы, ситуация улучшилась незначительно. Однако смысл в том, что наряду с фактом признания потоков в стандарте возникла и масса вопросов относительно того, как многопоточный код должен работать.

Стандарт языка C++, как и в случае с многими другими языками программирования, не описывается в терминах конкретного «железа», а вместо этого описывается в терминах некой абстрактной вычислительной машины. Так вот, до C++ 11 эта абстрактная машина была строго однопоточная. В C++ 11 в ней появилась возможность создавать новые потоки. Соответственно возникли вопросы по поводу работы с общей памятью из разных потоков, на которые комитетчикам пришлось ответить: зафиксировать правила обращения к памяти из разных потоков.
Причем тут память?
Почему вообще инкремент из разных потоков приводит к UB?
Дело в том, что переменная «x» лежит в оперативной памяти, и когда мы ее инкрементируем, нам нужно именно там ее и обновить. Поэтому даже такая простая операция, как инкремент, это на самом деле три разные операции: чтение, модификация и запись (RMW).
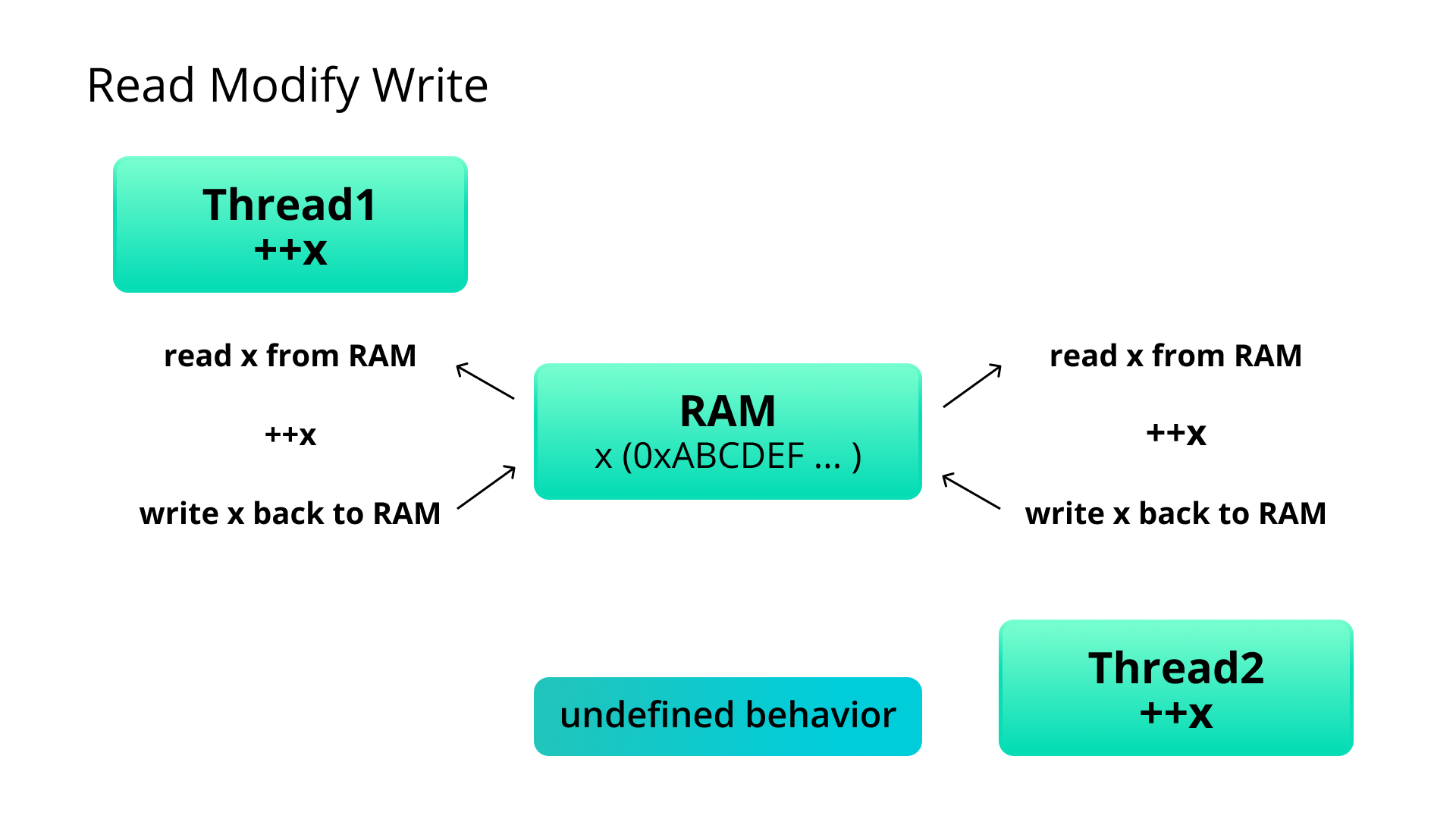
При этом в любую из этих операций может вмешаться другой поток и сломать всю логику. Когда процессор работает с данными из своего кэша, проблем не возникает, но как правило, процессор должен обновлять данные именно в оперативной памяти.
Несмотря на то, что результатом инкремента из разных потоков является UB, стандарт перестал игнорировать многопоточность: в нем были добавлены инструменты для многопоточной работы, а также, что самое важное, в модели памяти появились уточнения про многопоточную работу.
В стандарте 11 нам явили шаблонный класс std::atomic<T>. Операции с обычными типами не являются атомарными, поскольку это всегда RMW. А вот операции с типами, обернутыми шаблонным классом std::atomic<T>, гарантировано атомарны, хотя все еще происходит RMW. Возникает вопрос: какая же магия здесь задействована? Увы, никакой магии нет, все это работает через блокировки и/или взаимодействие процессоров (CPU).
И теперь, если мы инкрементируем ту же переменную, обернутую std::atomic из разных потоков, стандарт нам гарантирует корректное поведение и детерминированый результат.

Рассказываем о std::atomic<T>
Рассмотрим языковые конструкции этого шаблонного класса, как им пользоваться, и в чем состоит его специфика.
Итак, у шаблонного типа есть базовые операции. Далее, путем частичной или полной специализации для разных типов добавляются другие разные операции.
Базовые операции
Операция load(), которая просто возвращает значение:
std::atomic<bool> other;
other = atomicBool.load();В данном случае, полный аналог операции other = atomicBool.
Однако таким образом присваивать атомарные переменные нельзя. Проблема в том, что интерфейс std::atomic содержит только операции, которые можно выполнять атомарно (далее в тексте рассмотрим и другие примеры подобных операций). С точки зрения такого интерфейса, присваивание вида other = atomicBool некорректно, поскольку нельзя присвоить одной атомарной переменной другую атомарную переменную и сделать это атомарно; речь идет о двух отдельных, не связанных операциях, — чтении и записи.
Тем не менее присваивать атомарные переменные все еще нужно, поэтому разрешили такой синтаксис: other = atomicBool.load();
Из него следует более очевидное поведение: две операции прочитать из atomicBool и записать в other. Основная цель такого интерфейса — не допустить у пользователя лишней иллюзии, что он выполняет атомарно то, что не может выполнить атомарно.
Также из базовых методов есть is_lock_free.
std::cout << "is_lock_free = " << std::boolalpha << atomicBool.is_lock_free() << std::endl;Я уже упоминал, что std::atomic в некоторых случаях работает через блокировки. is_lock_free() — это рантайм-функция, возвращающая true, если тип свободен от блокировок, или же false, если для обеспечения атомарности используется мьютекс.
Трудно представить себе некую бизнес-логику, которая могла бы опираться в рантайме на использование is_lock_free() и, в зависимости от результата, идти по разным веткам кода с использованием lock-free алгоритмов или же без них. Но для учебных целей или же для тестирования аппаратных возможностей конкретного железа это вполне интересный вариант.
Мы можем проверить для разных типов, являются ли они lock-free на данном железе, а потом уже, в compile time, с помощью шаблонной специализации или SFINAE заложить разное поведение для этих типов.
Еще есть переменная static constexpr bool is_always_lock_free, которую можно использовать в compile time для определения, является ли тип lock-free или нет. Но она возвращает true только в том случае, если тип всегда является lock-free, независимо от железа.
Помимо load() есть симметричная операция store(). Она нужна для присваивания значения в атомарную операцию.
atomicBool.store(true); // atomic store without return valueНаряду с store и load все еще допустимо использовать оператор присваивания. В разных style-гайдах по-разному описаны рекомендации по этому поводу. Тем не менее бывает ситуация, когда при чтении или записи нам нужно передать дополнительный параметр — memory order, упорядочивание доступа к памяти). В этом случае нужно обязательно использовать load или store.
Тему memory ordering в этой статье я решил подробно не освещать. Основная же идея такая.
Компилятор и CPU могут переупорядочивать операции чтения/записи (при условии, что это переупорядочивание никак не затронет функциональность однопоточного кода), то есть могут быть фактически выполнены в порядке, отличном от того, который определен в коде. Проблема с этим может возникнуть в многопоточной среде, когда потоки, запускаемые на разных CPU, при общении могут увидеть операции в таком переупорядоченом порядке, который ломает логику работы с общими данными.
Обычно такие проблемы решаются с помощью мьютексов, но мы обсуждаем атомики. И в этом контексте memory ordering — это enum, определяющий, какие типы переупорядочиваний запрещены:
memory_order_acquire: гарантирует, что ни одна операция чтения не будет перемещена до текущей операции чтения.memory_order_release: гарантирует, что ни одна операция записи не будет перемещена после текущей операции.memory_order_acq_rel: комбинация двух предыдущих гарантий.memory_order_relaxed: вообще не дает никаких гарантий по переупорядочиванию.memory_order_seq_cst: cамый строгий memory ording, дефолтный для операций чтения/записи, запрещающий любые переупорядочивания.
Как видно из описания, memory_order_relaxed — самый слабый вид memory ordering, он не дает никаких гарантий, но при этом самый эффективный с точки зрения производительности работы с атомиками.
По умолчанию для store/load используется самый строгий и в тоже время самый неэффективный memory_order_seq_cst, но при этом мы избавлены от различных постэффектов, связанных с переупорядочиванием, которые нужно иметь в виду. Использование операции присваивания "=" эквивалентно использованию операции load/store с memory_order_seq_cst.
Отмечу и операцию exchange bool previousValue = atomicBool.exchange(false). Присвоит значение false переменной atomicBool и при этом вернет предыдущее значение переменной atomicBool. И все это выполнит атомарно.
Более сложный вариант операции обмена — compare_exchange_strong/compare_exchange_weak.
compare_exchange_strong:
const bool desired = true;
bool exchanged = atomicBool.compare_exchange_strong(expected, desired);Сравнивает значение переменной atomicBool с expected. Если значения совпадают, то записывает в atomicBool значение desired и возвращает true или изменяет значение expected на текущее значение atomicBool, и возвращает false в противном случае. Необходимость изменения значения expected вполне логична и нужна для того, чтобы не перевычитывать новое значение atomicBool, хотя и не всегда очевидна.
Схематично логика работы функции следующая:
template <class T>
bool compare_exchange_strong(T& expected, const T& desired)
{
if(atomicBool == expected)
{
atomicBool = desired;
return true;
}
else
{
expected = atomicBool;
return false;
}
}При этом compare_exchange_strong выполняется атомарно.
Семантика работы операции compare_exchange_weak похожа на compare_exchange_strong.
Разница лишь в том, что для compare_exchange_weak возможны ложные срабатывания. Они бывают вызваны тем, что на некоторых процессорных архитектурах используются инструкции LL/SC (Load-Linked/Store-Conditional) вместо CAS для решения так называемой ABA-проблемы.
Из-за такой особенности compare_exchange_weak должен быть использован в цикле:
expected = false;
while (!current.compare_exchange_weak(expected, true) && !expected);Однако при работе с lock-free структурами данных нам, как правило, все равно приходится организовывать циклы для выполнения операции CAS, поэтому в данном случае использование compare_exchange_weak оправдано. Встает резонный вопрос: а как же работает compare_exchange_strong на тех самых платформах где отсутствуют необходимые инструкции? Никакой магии — compare_exchange_strong реализуется внутри как вызов compare_exchange_weak в цикле.
Полезность применения compare_exchange_weak наглядно демонстрируется на примерах разработки lock-free структур — скажем, lock-free стека. Опустим описание интерфейса и рассмотрим только две базовые функции, добавление и извлечение элемента из стека:
void push(const T& data)
{
node* new_node = new node(data, head.load());
while(!head.compare_exchange_weak(new_node->next, new_node));
}Обратите внимание на условие цикла: compare_exchange_weak сравнивает head с new_node->next и при удачном сравнении заменяет значение head на new_node. При неудачном сравнении compare_exchange_weak сохраняет текущее значение head в new_node->next, избавляя нас от надобности делать это самим.
Зачем здесь нужен compare_exchange? Почему бы просто не заменить значение? Проблема в том, что если другой поток в это время совершит вставку в стек, мы можем потерять это значение. В цикле мы проверяем, что head, который мы собираемся заменить, действительно тот самый, который мы загрузили в node->next.
Для реализации функции pop потребуется два действия:
заменить указатель текущего головного узла на следующий
возвратить значения элемента
void pop(T& result)
{
node* old_head = head.load();
while (!head.compare_exchange_weak(old_head, old_head->next));
result = old_head->data;
}Здесь мы используем ту же технику. Цикл while нужен, чтобы удостовериться, что мы меняем именно тот head, который загрузили на первой строке. Обратите внимание: поскольку тут все равно нужен цикл в операции CAS, то нет смысла в использовании compare_exchange_strong, и поэтому мы используем compare_exchange_weak.
Выше я рассказывал только про atomic bool. Если же создать std::atomic, для указателя добавляются новые атомарные операции:
atomicPtr.fetch_add(1);
atomicPtr.fetch_sub(1);
atomicPtr++;
atomicPtr--;
atomicPtr += 1;
atomicPtr -= 1;Для целых чисел:
int previous = atomicInt.fetch_and(2); // 0b101010 & 0b10
previous = atomicInt.fetch_or(3); // 0b10 | 0b11
previous = atomicInt.fetch_xor(3);
atomicInt &= 2;
atomicInt |= 2;
atomicInt ^= 2;Вызов атомарного умножения и деления запрещены, так как это неатомарные операции:
atomicInt *= 2;
atomicInt /= 2;Казалось бы, современные процессоры давно такие операции поддерживают. Но стандарт на то и стандарт, что должен работать везде, даже на таком старом железе, где нет аппаратной поддержки операций умножения/деления.
Вместо этого можно использовать такой синтаксис: atomicInt = atomicInt * 2;, который явно дает понять, что операция неатомарна.
В шаблон можно завернуть любые типы, которые являются trivial copyable и copy constructible. Но в зависимости от того, как тип расположен в памяти, атомарность для него реализована или за счет мьютекса или за счет аппаратных инструкций (lock-free). Функция is_lock_free() как раз дает нам понять, как именно реализована атомарность для того или иного типа.
Попробуем поэкспериментировать с тем, как меняется поведение в зависимости от лэйаута данных в памяти. Рассмотрим следующие примеры:
std::atomic<uint64_t> bigAtomic;
std::cout << "bigAtomic is_lock_free = " << std::boolalpha << bigAtomic.is_lock_free() << std::endl;
struct ByteStruct {
uint8_t value;
};
std::atomic<ByteStruct> byteAtomic;
std::cout << "byteAtomic is_lock_free = " << std::boolalpha << byteAtomic.is_lock_free() << std::endl;
struct TwoBytesStruct {
uint8_t value;
uint8_t value2;
};
std::atomic<TwoBytesStruct> twoBytesAtomic;
std::cout << "twoBytesAtomic is_lock_free = " << std::boolalpha << twoBytesAtomic.is_lock_free() << std::endl; Результаты вывода:
bigAtomic is_lock_free = true
byteAtomic is_lock_free = true
twoBytesAtomic is_lock_free = trueТут все довольно логично: uint64_t, 1-байтовая и 2-х байтовые структуры — lock-free.
// lib atomic is required
struct ThreeBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
};
std::atomic<ThreeBytesStruct> threeBytesAtomic;
std::cout << "threeBytesAtomic is_lock_free = " << std::boolalpha << threeBytesAtomic.is_lock_free() << std::endl;Результат вывода:
threeBytesAtomic is_lock_free = false3-х байтовая структура уже не is_lock_free. Интересно, почему же? В процессоре есть только 2^n разрядные регистры. Поэтому для того, чтобы совершать операции с 3-х байтовой структурой, нужно помещать эту структуру в регистр большего размера, при этом паддингом заполнять свободное место, что чревато проблемами. Или же использовать несколько регистров для хранения, при этом за один такт операцию с такими данными уже не выполнить.
struct FourBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
uint8_t value4;
};
std::atomic<FourBytesStruct> fourBytesAtomic;
std::cout << "fourBytesAtomic is_lock_free = " << std::boolalpha << fourBytesAtomic.is_lock_free() << std::endl;Результат вывода:
fourBytesAtomic is_lock_free = true Тут все опять же логично: 2^n байтовая структура.
// lib atomic is required
struct SevenBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
uint8_t value4;
uint8_t value5;
uint8_t value6;
uint8_t value7;
};
std::atomic<SevenBytesStruct> sevenBytesAtomic;
std::cout << "sevenBytesAtomic is_lock_free = " << std::boolalpha << sevenBytesAtomic.is_lock_free() << std::endl;Результат вывода:
sevenBytesAtomic is_lock_free = false 7-и байтовых регистров нет, поэтому тут тоже все сходится.
struct SixteenBytesStruct {
uint16_t value;
uint16_t value2;
uint16_t value3;
uint16_t value4;
uint16_t value5;
uint16_t value6;
uint16_t value7;
uint16_t value8;
};
std::atomic<SixteenBytesStruct> sixteenBytesAtomic;
std::cout << "sixteenBytesAtomic is_lock_free = " << std::boolalpha << sixteenBytesAtomic.is_lock_free() << std::endl;Результат вывода:
sixteenBytesAtomic is_lock_free = false 16 — это степень 2х, но is_lock_free — false.
Дело в том, что на процессоре, где выполняется код, нет 16-и байтовых регистров (на другом процессоре, где такие есть, вывод будет иной). Поэтому мы опять-таки упираемся в необходимость хранения такой структуры в нескольких регистрах.
struct OtherFourBytesStruct {
uint8_t value;
uint16_t value2;
uint8_t value3;
};
std::atomic<OtherFourBytesStruct> otherFourBytesAtomic;
std::cout << "otherFourBytesAtomic is_lock_free = " << std::boolalpha << otherFourBytesAtomic.is_lock_free() << std::endl;Результат вывода:
otherFourBytesAtomic is_lock_free = false Из-за выравнивания структура OtherFourBytesStruct уже имеет размер 6 и поэтому не lock-free. Стоит отключить выравнивание, и она станет lock-free.
Что же работает быстрее?
Итак, мы имеем два популярных способа избегания race condition: с помощью мьютекса, либо с помощью атомика на основе аппаратных инструкций (lock-free). Встает резонный вопрос, что же из этого работает быстрее. В большинстве случаев, конечно, атомики работают быстрее.
Тем не менее нужно отметить, что производительность, как при использовании атомиков, так и при использовании мьютексов зависит от ряда факторов:
Реализации компилятора. Конечно же много зависит от того, как реализованы мьютекс и атомики в конкретном компиляторе. Не секрет, к примеру, что в современных компиляторах мьютексы, прежде чем перейти в режим ядра и усыпить тред используют активное ожидание (lock-free) с помощью атомика.
Операционной системы. Куда же без операционной системы, ведь в конечном счете используются примитивы синхронизации, предоставляемые ОС.
Архитектуры железа. Железо может быть разное, как и набор поддерживаемых инструкций. Атомики в конечном счете используют процессорные инструкции, поэтому наличие или отсутствие тех или иных инструкций может стать решающим фактором.
Количества CPU и ядер. C ростом количества процессорных единиц, как правило, профит от использования атомиков по сравнению с мьютексами увеличивается.
Алгоритма программы. Очевидный и последний в списке, при этом важнейший пункт. Прежде чем выбирать между различными механизмами защиты от race condition, стоит подумать о том, можно ли реализовать алгоритм программы таким образом, чтобы гонок не было в принципе.
Как это работает
Как я уже упоминал, в случае lock_free атомарной переменной мы имеем дело все с той же операцией RMW. Как же все это работает без блокировок? На самом деле, блокировка там есть, только несколько иного вида — аппаратная. Давайте поговорим о том, что это за блокировка.

Предположим, CPU1 хочет сделать инкремент переменной X. Работа происходит с данными в общей оперативной памяти, поэтому первым делом:
Нужно заблокировать шину данных.
На самом деле, блокировка шины выглядит тоже довольно неэффективно, поэтому на современных процессорах блокируется какая-то область оперативной памяти, содержащая данные, например, кэш-линия. После того, как область данных заблокирована, порядок действий простой:
Прочитать данные.
Инкремент.
Записать данные обратно и разблокировать шину (кэш-линию).
Рассказать другим процессорам о том, что данные поменялись.
Последний шаг важен, поскольку у каждого процессора есть свой кэш, в котором изменяемые данные могут уже содержаться. Для того, чтобы их инвалидировать, как раз и нужно процессорное общение.
Происходит оно по специальным протоколам. Например, протокол mesi или moesi. Эти протоколы слишком простые и поэтому используются только в учебных целях. Но даже на примере реализации этих протоколов можно убедиться, насколько это нетривиальная задача.
Тут возникает вопрос, а зачем тогда вообще нужен процессорный кэш, если он так все усложняет. Дело в том, что оперативная память работает на порядок медленнее, чем процессоры, и чтобы не расходовать процессорное время понапрасну, процессоры снабжены дополнительной быстродействующей памятью гораздо меньшего объема, по причине своей дороговизны. Называется это процессорным кэшем. Когда процессор считывает данные из оперативки, он помещает их в кэш, и при последующей необходимости работы с этими данными, вместо того, чтобы обращаться к оперативке, берет их из кэша.
Если сравнивать программную блокировку в случае мьютекса и аппаратную в случае lock-free атомика, то помимо разницы в быстродействии, которая уже упоминалась, стоит упомянуть такое узкое место как возможность возникновения взаимоблокировки в случае неправильного использования мьютексов. В случае с аппаратной блокировкой программист уже не может допустить такой ошибки. И это тоже можно бросить в копилку атомиков.
***
Будем рады увидеть в комментариях ваши пожелания, уточнения и вопросы по содержанию материала. Обязательно сообщите нам, если тема или её отдельные аспекты оказались для вас интересны и полезны: возможно, мы углубимся в рассказ об атомарных операциях и типах данных в будущих статьях на Хабре.
