Комментарии 5
В упомянутом low-code решении Datagram SQL-запросы трансформируются в scala-код с использованием Spark SQL
spark.sql("SELECT * FROM people WHERE age > 30 ")или методов класса DataFrame
people.filter("age > 30")?
В Datagram есть несколько видов трансформаций которые можно использовать из визуального редактора, один из видов это блок SparkSQL, который преобразуется в код Scala выдающий на выходе DataSet:
Также есть специализированные визуальные блоки, которые преобразуются в нотацию DataFrame API (фильты, join, группировки, и т.д.)
преобразуется в код
...
val queryResult = spark.sql("SELECT * FROM people WHERE age > 30 ")
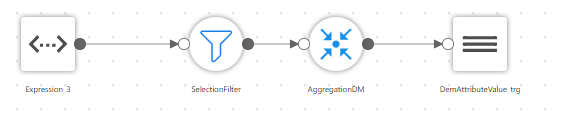
queryResult.as[mainSparkSQLSchema] Также есть специализированные визуальные блоки, которые преобразуются в нотацию DataFrame API (фильты, join, группировки, и т.д.)

преобразуется в код
def getSelectionFilter(spark: SparkSession, Expression_3: Dataset[Expression_3Schema]) = {
import spark.implicits._
Expression_3.filter(s"""age>30""")
}
def getAggregationDM(spark: SparkSession, SelectionFilter: Dataset[Expression_3Schema]) = {
import spark.implicits._
SelectionFilter
.groupBy("id").agg($"id")
.as[AggregationDMSchema]
}
Фактически разницы может и не быть. Оба подхода сводятся к использованию оптимизатора Catalyst. Использование DataFrame API позволяет отловить некоторые ошибки на этапе компиляции, а ошибку в запросе SQL мы увидим только во время выполнения.
Вот статья, в которой производится сравнение: https://community.cloudera.com/t5/Community-Articles/Spark-RDDs-vs-DataFrames-vs-SparkSQL/ta-p/246547
Вот статья, в которой производится сравнение: https://community.cloudera.com/t5/Community-Articles/Spark-RDDs-vs-DataFrames-vs-SparkSQL/ta-p/246547
Классная статья! А сколько сейчас дата-инженеров (да и вообще специалистов) с вашей стороны поддерживают эту махину у Mediascope? Или обучили и полностью передали поддержку и развитие внутрь MS? Это тоже один из критериев зрелости конкретного low-code решения, по которому знания сконцентрированы внутри вендора, что формирует условный «vendor-lock» для клиента.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Применение low-code в аналитических платформах