Уважаемые читатели, доброго дня!
В данной статье ведущий консультант бизнес-направления Big Data Solutions компании «Неофлекс», подробно описывает варианты построения витрин переменной структуры с использованием Apache Spark.
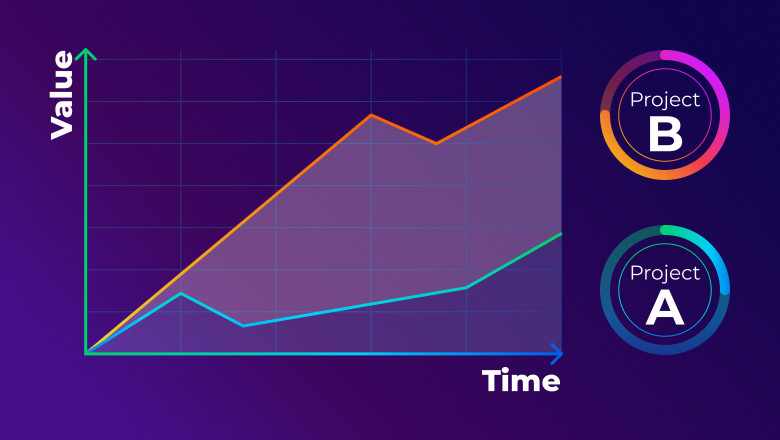
В рамках проекта по анализу данных, часто возникает задача построения витрин на основе слабо структурированных данных.
Обычно это логи, или ответы различных систем, сохраняемые в виде JSON или XML. Данные выгружаются в Hadoop, далее из них нужно построить витрину. Организовать доступ к созданной витрине можем, например, через Impala.
В этом случае схема целевой витрины предварительно неизвестна. Более того, схема еще и не может быть составлена заранее, так как зависит от данных, а мы имеем дело с этими самыми слабо структурированными данными.
Например, сегодня логируется такой ответ:
{source: "app1", error_code: ""}
а завтра от этой же системы приходит такой ответ:
{source: "app1", error_code: "error", description: "Network error"}
В результате в витрину должно добавиться еще одно поле — description, и придет оно или нет, никто не знает.
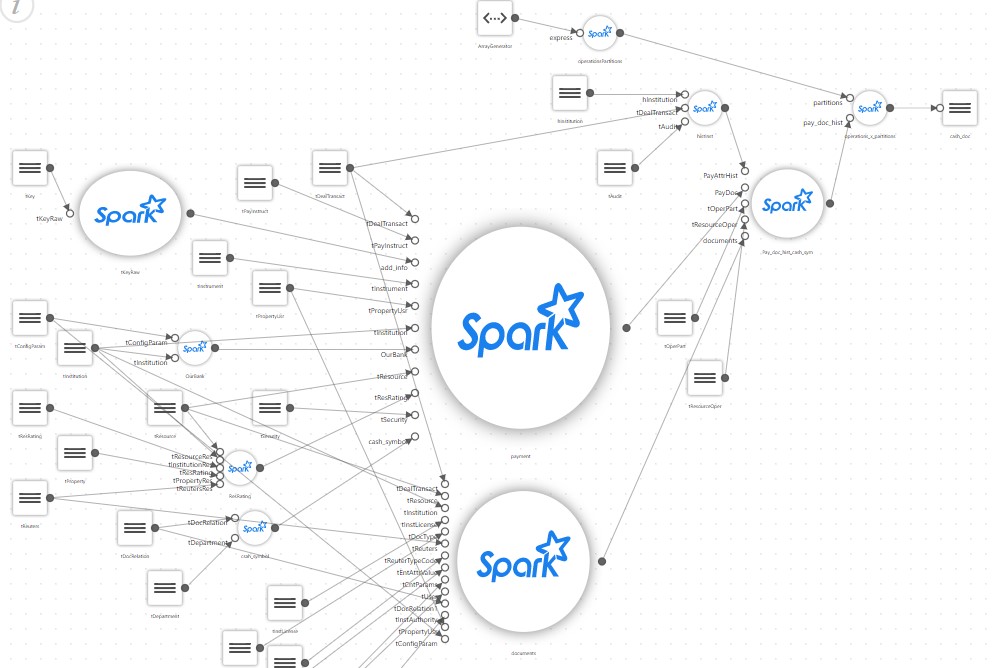
Задача создания витрины на таких данных довольно стандартная, и у Spark для этого есть ряд инструментов. Для парсинга исходных данных есть поддержка и JSON, и XML, а для неизвестной заранее схемы предусмотрена поддержка schemaEvolution.
С первого взгляда решение выглядит просто. Надо взять папку с JSON и прочитать в dataframe. Spark создаст схему, вложенные данные превратит в структуры. Далее все нужно сохранить в parquet, который поддерживается в том числе и в Impala, зарегистрировав витрину в Hive metastore.
Вроде бы все просто.