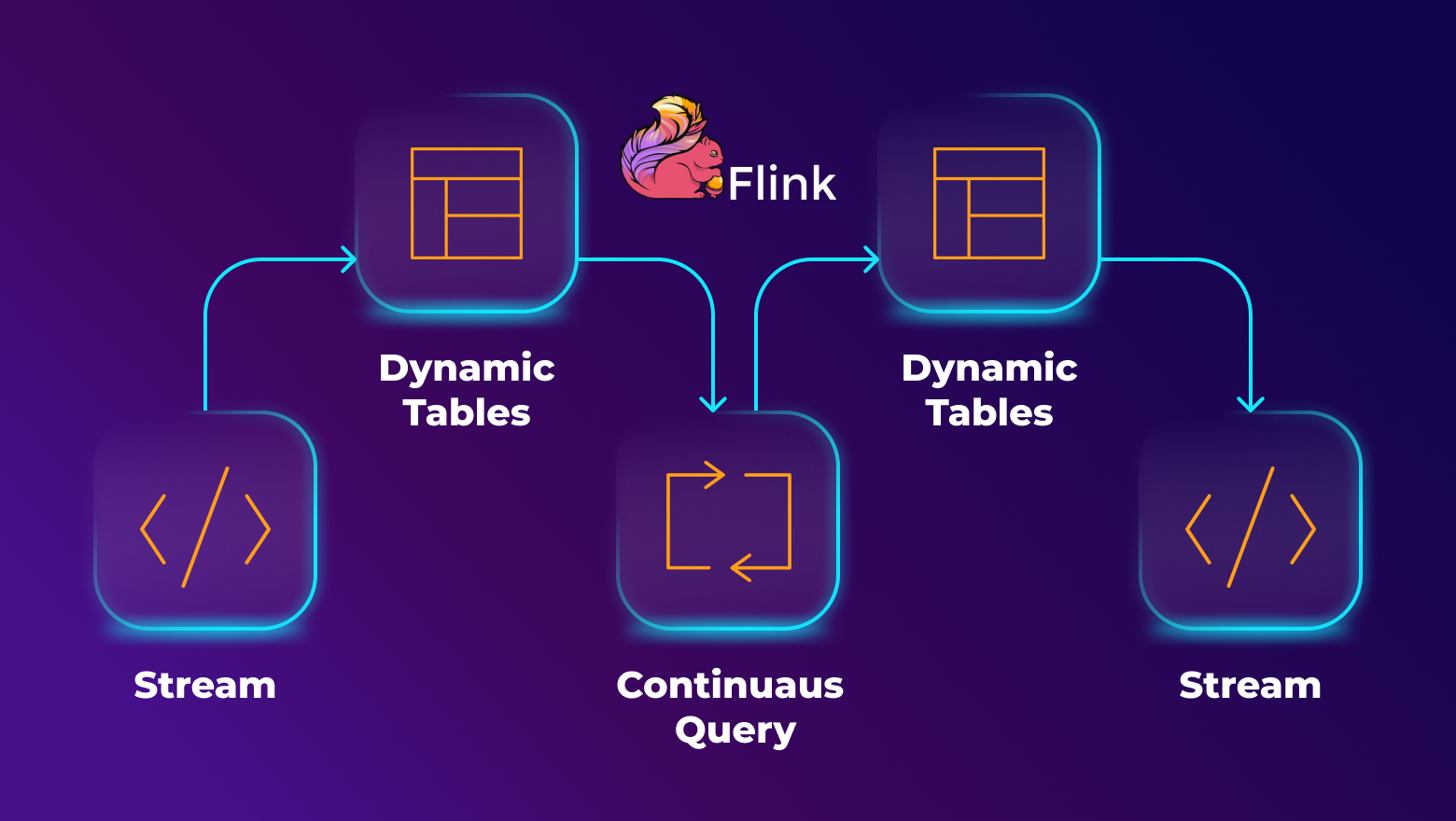
Часто специалисты, работающие с классическими реляционными базами данных, например, с PostgreSQL, испытывают затруднения в работе при переходе на систему хранения больших данных типа Apache Hive. Это связано с непониманием того, как можно использовать в новой среде уже наработанные подходы и методы работы с данными.
В данной статье рассмотрены некоторые особенности использования языка SQL в реляционных СУБД и Apache Hive. Кроме того, проведен сравнительный обзор возможностей и подходов, а также применение партиционирования на практике.
Материал будет полезен специалистам младших и средних грейдов, которые используют в своей практике SQL, но имеют мало опыта в Hive или Postgres.