
Овечка Долли из заголовка — это ставшее нарицательным имя первого успешного клона высокоуровневого живого существа, созданного наукой. И хотя в биологии клоны пока еще область экспериментальная, в IT и в области хранения данных тема клонов обосновалась крепко и широко.
Возможность быстро (и что немаловажно — экономично, с точки зрения занимаемого пространства и времени) создать полную копию тех или иных обширных данных — задача сегодня очень востребованная. Такой клон данных можно было бы использовать для задач тестирования, разработки, и прочих экспериментов, когда нежелательно или прямо невозможно делать это на «боевых данных».
Практический пример того, где и как можно применить клоны.
Допустим, в нашей компании используется большая база данных, в которой сосредоточен весь наш бизнес, например база ERP-системы. Разумеется бизнес живет и растет, вместе с ростом нашей компании, группа разработки пишет новую функциональность для базы, проектирует новые рабочие места, пишет в базе какую-то новую бизнес-логику. И все это им надо тестировать и проверять на данных. Причем чем более объемные и реальные данные будут у них — тем эффективнее и точнее будет их тестирование.
В идеале им нужно тестироваться на реальных данных, на реальной базе вашей компании. Однако кто ж в здравом уме пустит на «боевую» базу тестировать что-то?
Вот если бы можно было создать точную копию базы, в ее текущем состоянии, специально для тестирования!
Но для создания полного, независимого клона, нам понадобится объем хранения как минимум равный емкости основной базы. Да еще и быстродействие такой базы должно бы быть, в идеале, равное «боевой», то есть не подойдет копировать их на «кучу USB-дисков». Я уж не говорю о том, что по условиям внедрения, например, такой ERP-системы, как SAP, в развернутой инфраструктуре просто обязательно должны быть подразделения разработки и QA (Quality Assurance, валидации и проверки), а зачастую еще нужна и база для проведения тренингов и обучения новых пользователей, и у каждой обязательно должна быть своя копия текущей базы, на которой проходит разработка и контроль приложений, а также обучение персонала.
Именно такие требования часто приводят к тому, что предприятия, внедряющие ERP, автоматически попадают еще и на две-три дополнительные к основной системы хранения, или вдвое-втрое большее количество дисков в ней, тратясь не только на их приобретение, но и на эксплуатацию, обслуживание, администрирование, и так далее. А ведь еще важно поддерживать актуальность копий, а значит регулярно накатывать изменения на копии, поддерживая их в актуальном к основному экземпляру состояния.
И сделать тут ничего нельзя. Держать несколько идентичных копий базы необходимо.
Или все же можно?
И вот тут начинают играть клоны.
Клоны — это полные копии данных, работающие как полноценные копии, то есть не просто «на чтение», но как обычная копия. Содержимое такого клона можно не только читать, но и изменять, то есть полноценно писать в него, неотличимо, для приложения, от работы с обычным разделом данных.
Сделать клон можно тремя путями. Во-первых, просто скопировать данные в свободное место, и поддерживать его актуальность вручную. Это очевидно, и не интересно. Это скорее копия, а не клон. Такой вариант занимает огромное пространство дорогого места хранения и много времени на свое создание.
Второй вариант — так называемые Copy-on-Write (COW) копии. В них записи, которые, допустим, тестируемое приложение хочет занести в свою «копию» вызывают копирование исходных данных в специальное зарезервированное пространство, при этом сохранятся как исходный набор данных, так и их изменения. Проблемы тут те же самые, что и у COW-снэпшотов, это почти втрое снижает производительность работы такого хранилища. И это тоже неинтересно.
А третий вариант реализовал NetApp.
Как вы уже знаете, лежащая в основе всех систем хранения NetApp структура размещения блоков данных под названием WAFL, устроена таким образом, что изменения блоков в ней делаются не внутрь фактически изменяемых блоков, а в свободное пространство тома, куда затем переставляются указатели текущего состояния данных.
Такая схема позволяет легко и изящно решить проблему с изменяемыми блоками в клоне. Клон всегда остается неизменной виртуальной «копией» данных (а значит мы можем не занимать им место на диске, а просто ссылаясь из него на блоки исходных данных), а все изменения блоков, которые мы делаем над экземплярами клонов накапливаются отдельно.
Следовательно, место на диске такие клоны занимают только в объеме внесенных в клоны изменений.
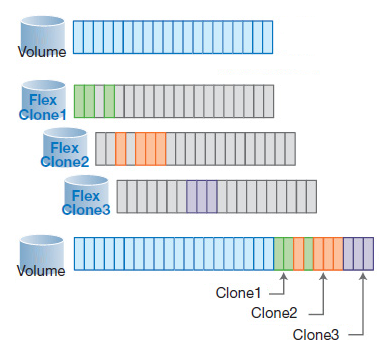
Если ваши программисты в отделе разработки наизменяли в своих виртуальных копиях клонов базы, размером 6TB, пару терабайт данных — то их клон займет на диске из свободного места ровно эти 2TB, и только.

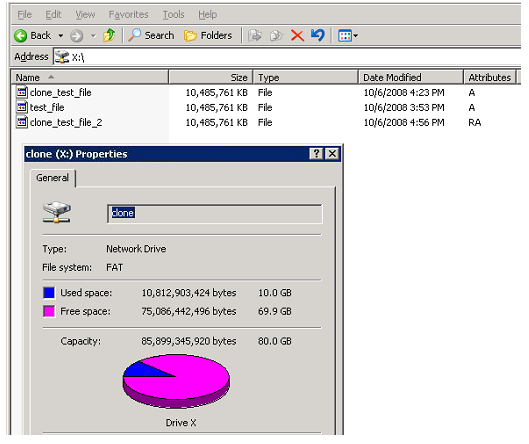
На скриншоте вы видите, как на практике выглядит такой клон. На диске находится три файла, каждый, с точки зрения Экплорера размером 10GB, однако занятое на диске место всеми тремя — всего 10GB.
Полезно также и то, что такие клоны могут легко «отрываться» от исходного тома, и, если это необходимо, превращаться в физическую копию.
Разработчики проверяли процесс апгрейда базы на новую версию, или тестировали патчи? Проапгрейдили, проверили весь софт на корректную работу с новой версией, убедились, что все работает на обновленной базе — и легко подменили рабочий том на проапдейченный и проверенный «клон», со всеми сделанными в этом клоне изменениями, который, в данном случае, становится теперь вполне полноценным томом.
Кстати сказать, таких клонов может быть до 255 на каждом томе (не на систему в целом — на каждый том!), и вы можете не ограничивать себя количеством клонов. Если у ваших разработчиков есть несколько вариантов, и они хотели бы выбрать один из них — просто дайте им по клону на каждый вариант, пусть экспериментируют и выберут, сравнив все желаемые варианты разом.
Как вы видите, наличие такого простого и эффективного механизма клонирования данных, зачастую изменяет сам подход к их использованию. То что раньше не делалось, «потому что это невозможно», как пример — та же практическая отладка на реальных данных, или параллельная разработка на объемных многогига- и терабайтных данных теперь, с такими клонами, вполне реализуема.
На картинке в заголовке статьи —

{kind=link}