

Защита pod’а от выселения при помощи Pod Disruption Budgets в Kubernetes
Это четвертая и заключительная часть нашего пути (прим. пер. — ссылка на первую статью) для достижения нулевого времени простоя при обновлении Kubernetes-кластера. В предыдущих двух частях мы фокусировались на том, как корректно выключить существующие pod’ы в кластере. Мы описали как использовать хуки preStop для корректного выключения pod’ов и почему важно добавлять задержку в процесс удаления, чтобы подождать, пока процесс удаления pod’а применится для всего кластера. Это поможет в отключении одного pod’а, но не защитит нас от выключения настолько большого количества pod’ов, что наш сервис не сможет функционировать. В этой статье мы будем использовать PodDisruptionBudgets (или PDB), для уменьшения этого риска.
PodDisruptionBudgets: запас допустимого количества упавших pod’ов
Квота количества неработающих pod (PDB) — это счетчик количества сбоев, которые могут быть допущены в данный момент времени для класса pod’ов (запас поломок).
Каждый раз, когда работа pod’а нарушается, если служба посчитает, что количество поломок превысило квоту, операция останавливается до тех пор, пока она не сможет поддерживать квоту. То есть операция drain может быть остановлена до момента, пока загрузятся новые pod’ы, так что квота не будет исчерпана при выселении.
Для установления квоты количества неработающих pod мы создадим ресурс PodDisruptionBudget, соответствующий pod’ам в сервисе. Например, если мы хотим создать такую квоту неработающих pod (PDB), что мы всегда хотим иметь как минимум один доступный pod с Nginx для нашего deployment-примера, мы применим следующую конфигурацию:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginxОна указывает Kubernetes, что мы хотим, чтобы в любое время был доступен как минимум 1 pod, содержащий лейбл app: nginx. Пользуясь этим, мы можем заставить Kubernetes подождать замены pod’а от одного drain-запроса, прежде чем выселять pod’ы другого drain-запроса.
Пример
Чтобы проиллюстрировать, как это работает, давайте вернемся к нашему примеру. Для простоты мы будем игнорировать любые prestop-хуки, readiness probes или запросы от service в этом примере. Мы так же предположим, что мы хотим сделать замену одной ноды кластера на другую. Это значит, что мы расширим наш кластер, удвоив количество нод, с новыми нодами, запущенными с новых образов.
Итак, начнем с нашего кластера с двумя нодами:
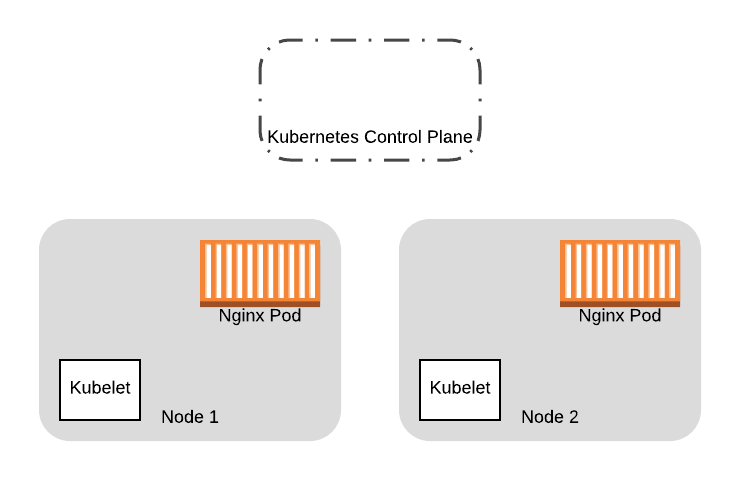
Мы предоставим две дополнительные ноды, которые будут запущены на основе новых образов в ВМ. В конечном итоге, мы перенесем все pod’ы со старых нод на новые:
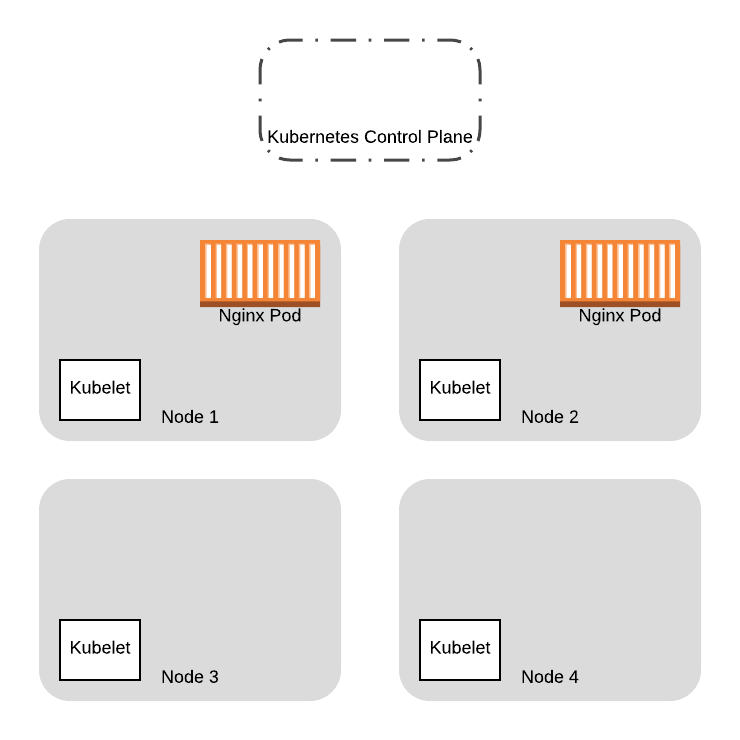
Для замены pod’ов, первым делом мы сделаем drain на старых нодах. В этом примере давайте посмотрим что случится, когда мы одновременно запустим команду drain на обоих нодах, где запущены pod’ы с Nginx. Запрос drain будет запущен как два процесса (на практике, это просто две вкладки в терминале), которые управляют процессом drain для одной из нод.
Обратим внимание, что до этого момента мы упрощали пример, полагая, что команда drain мгновенно отправляет запрос на выселение. В реальности, операция drain сначала включает в себя отметку о том, что нода “порченая” (флаг NoSchedule), поэтому новые pod’ы не смогут быть размещены на новых нодах. В этом примере мы рассмотрим обе фазы отдельно.
Для начала, два потока, управляемые процессом drain отметят ноды как “порченые” и новые pod’ы не смогут быть запущены на них:
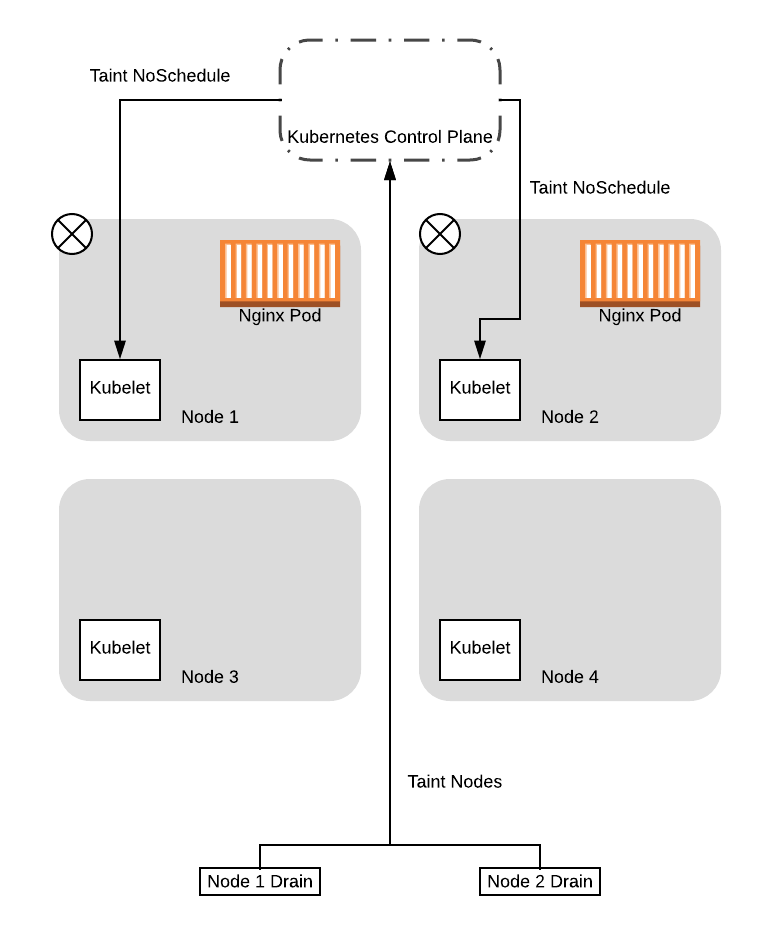
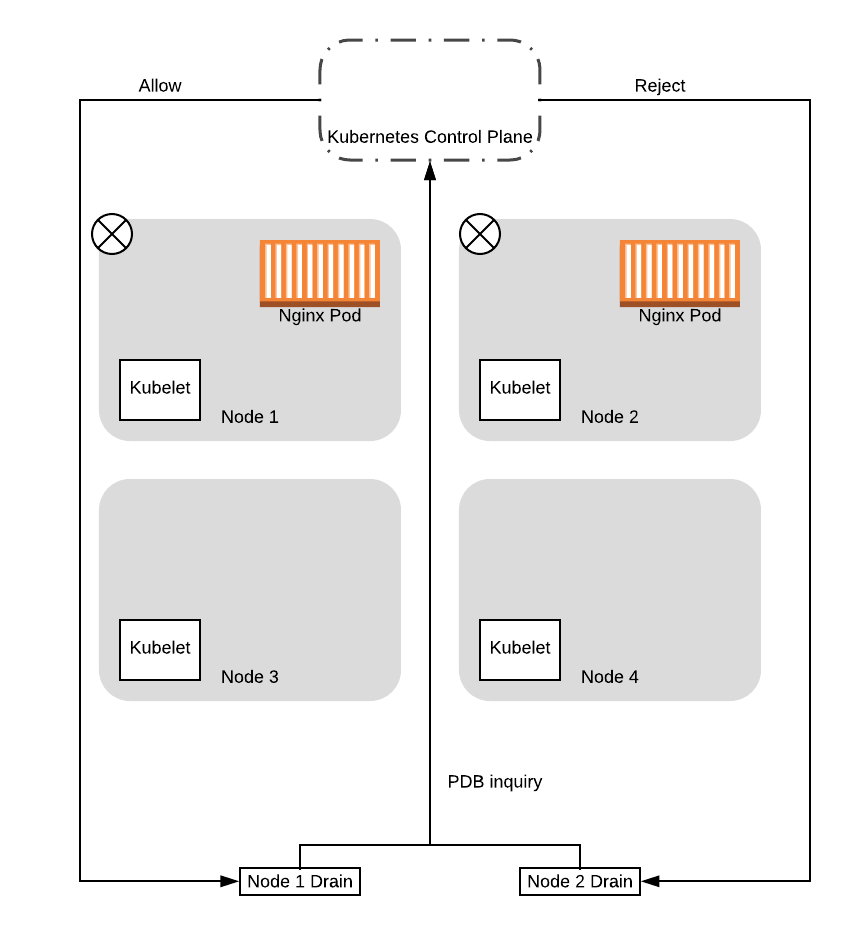
После того, как ноды будут помечены, процессы drain начнут выселять pod’ы с ноды. В том числе, процессы drain будут запрашивать у control plane, не приведет ли выселение к падению сервиса ниже установленного Pod Disruption Budget (PDB).
Заметим, что control plane будет дозировать запросы, обрабатывая один запрос о PDB за раз. Таким образом, в этом случае control plane ответит на один из запросов положительно, но на другой отрицательно. Это связно с тем, что на момент выполнения первого запроса было доступно 2 pod’а. Разрешение на этот запрос уменьшит количество доступных pod’ов до 1, то есть PDB соблюдается. Когда он разрешит выполнение запроса, один pod удалится, и, соответственно, станет недоступен. В этот момент, если приходит второй запрос, control plane отклонит его, так как если его разрешить, количество доступных pod’ов упадет до 0, нарушая установленный PDB.
Учитывая это, в данном примере мы будем предполагать, что нода 1 получила положительный ответ. В этом случае процесс drain для ноды 1 начнет выселение pod’ов, пока процесс drain для ноды 2 будет висеть в ожидании и периодически отправлять запросы снова:
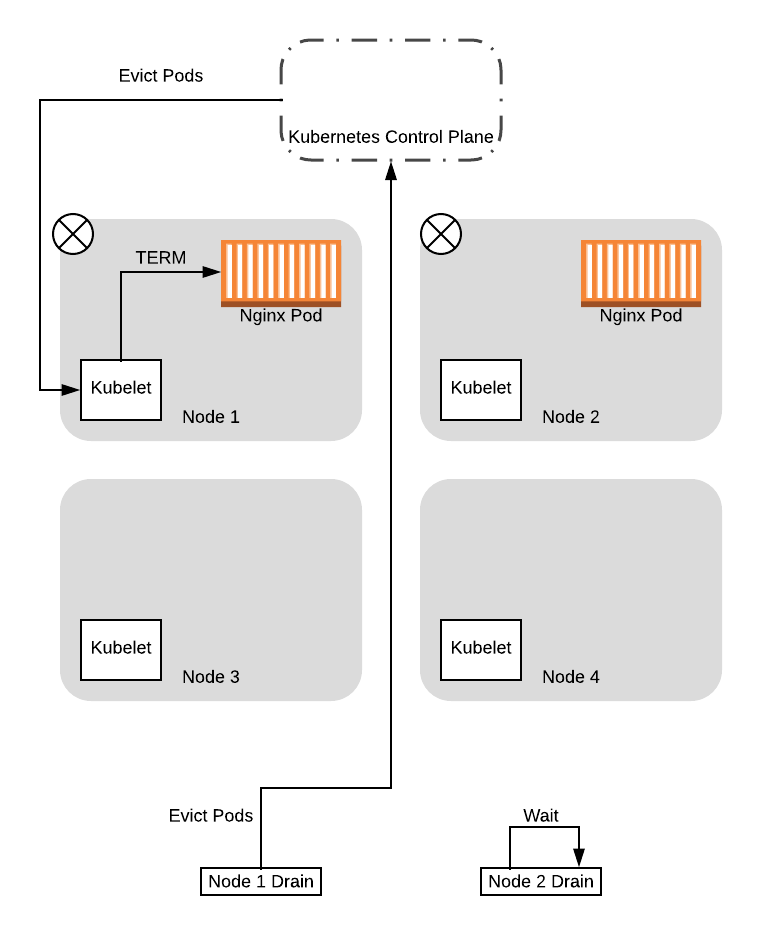
Когда pod’ы будут выселены с первой ноды, они сразу же пересоздадутся контроллером Deployment на одной из доступных нод. В этом случае поскольку старые ноды будут помечены как “порченые” с флагом NoSchedule, scheduler выберет одну из новых нод:
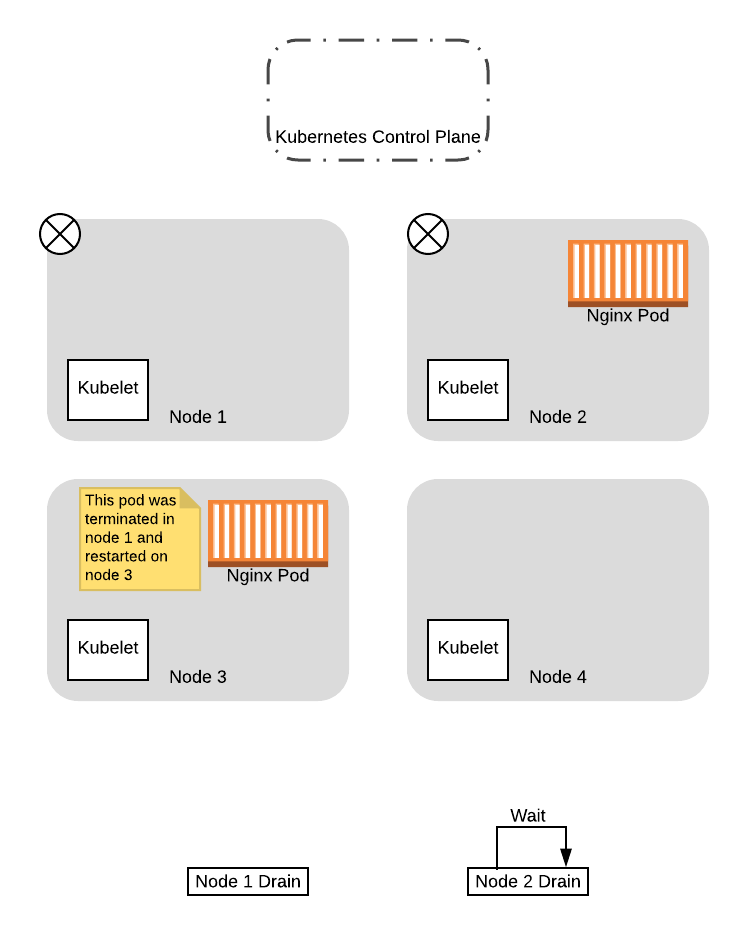
На этом этапе, когда pod был успешно перемещен на новую ноду, а нода 1 очищена, процесс drain для ноды 1 завершится.
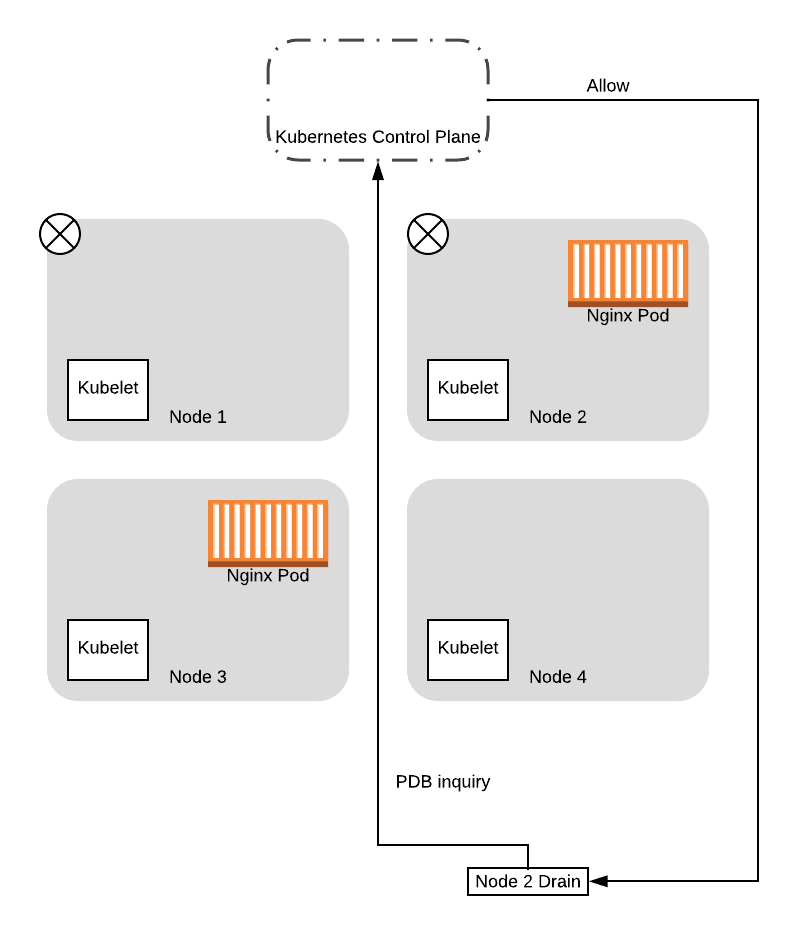
Если процесс drain для ноды 2 снова сделает запрос к control plane о PDB, то он получит положительный ответ. Это объясняется тем, что новый pod, который не будут в дальнейшем выселять, уже запущен, поэтому, позволяя процессу drain для ноды 2 выполняться дальше, вы не сделаете количество доступных pod’ов ниже квоты (PDB). Поэтому процесс выселения на данной ноде продолжится и в конце концов завершится:
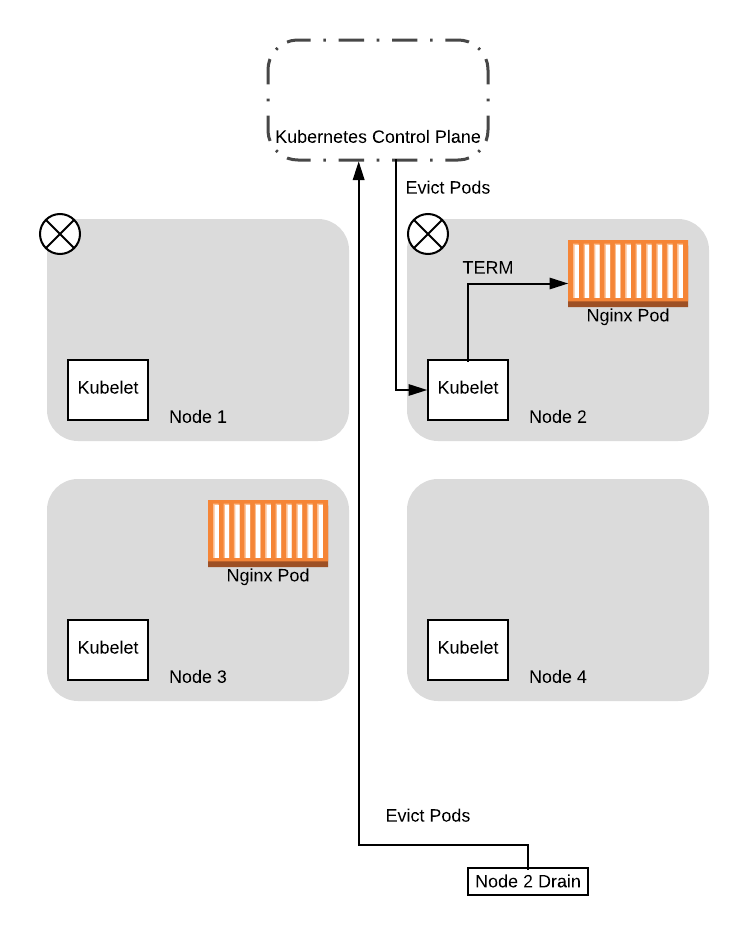
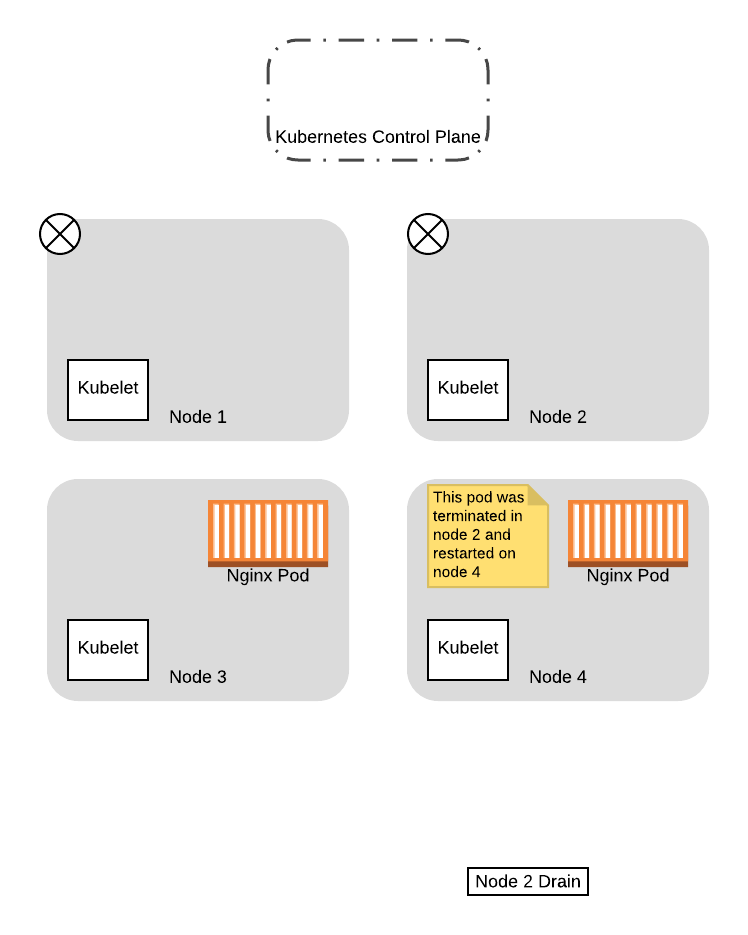
Благодаря всему вышесказанному, мы успешно перенесли оба pod’а на новые ноды, избежав ситуации, когда у нас не было доступно ни одного pod’а для обслуживания приложения. Более того, нам не нужно было внедрять какую-то дополнительную логику для согласования drain процессов, так как Kubernetes обработал все это для нас на основе заданной нами конфигурации!
Итоги
Теперь подытожим все, что мы рассмотрели в данной серии постов:
- Как использовать lifecycle хуки для реализации возможности корректно выключать наши приложения так, чтобы они завершались корректно.
- Как pod’ы удаляются из системы и почему необходимо вводить задержку в процесс выключения
- Как задать запас неработающих pod’ов (PDB), что бы убедиться, что мы всегда будем иметь определенное количество pod’ов для непрерывной работы приложения в случае сбоев.
При использовании всех этих функций вместе, мы можем достичь нашей цели — нулевого времени простоя при выкатывании обновлений!
Но не верьте мне на слово! Идите и примените эту конфигурацию в деле. Вы даже можете написать автоматизированные тесты при помощи terratest, используя функции модуля k8s и возможность постоянно проверять endpoint. В конце концов, один из важных уроков, который мы извлекли при написании 300 тыс. строк инфраструктурного кода, заключается в том, что инфраструктурный код без автоматических тестов не работает.
Чтобы получить полностью внедренную и протестированную версию обновлений кластера Kubernetes для нулевого временем простоя на AWS и других ресурсах, посетите Gruntwork.io.
Также читайте другие статьи в нашем блоге:
- Zero Downtime Deployment и базы данных
- Kubernetes: почему так важно настроить управление ресурсами системы?
- Cборка динамических модулей для Nginx
- Разбираемся с пакетом Context в Golang
- Три простых приема для уменьшения Docker-образов
- Резервное копирование большого количества разнородных web-проектов
