

Глава 1: Чёрный лебедь.
Кто-нибудь из вас когда-нибудь слышал о теории “Чёрный лебедь”? Если говорить вкратце, то данная теория рассматривает труднопрогнозируемые события, которые несут за собой огромные последствия для всей системы. К примеру, ваш кластер k8s располагается в ДЦ в конкретно взятом регионе. Всё было прекрасно, но с берега пришло цунами и его затопило, вследствие чего все сервера стали недоступны и ваше приложение не работает. Так кто же в этом будет виноват? Карма? Подводные землетрясения? Ответ прост - вы сами.

Любая отказоустойчивая система подразумевает один простой принцип - избыточность входящих в неё ресурсов. В нашем случае - распределение всех компонентов кластера в различных ЦОД в разных регионах. В таком случае выход из строя части серверов никак не повлияет на стабильность работоспособности всей системы.
Так, с этим разобрались. Но как проверить, присутствует ли в кластере k8s отказоустойчивость на самом деле?
Глава 2: Без хаоса не было бы и порядка.
История началась в далёком 2011 году, когда Netflix начали миграцию в облако и именно в этот момент Грегу Орзеллу пришло в голову решение проблемы отсутствия надлежащего тестирования устойчивости системы. Так большая компания, включающая в себя на данный момент больше тысячи it-специалистов начала придерживаться следующей методологии:
Зачем ждать, когда произойдет сбой? Давайте устраивать сбои самостоятельно.
Задача же всех остальных - коллективно решать возникающие проблемы, не понижая основных показателей работоспособности инфраструктуры.
Интересный факт.
Основная метрика Netflix - это вовлеченность клиентов, которую измеряют как количество воспроизведений видео в секунду.
Так началось первое зарождение Chaos engineering на основе продукта Chaos monkey.

Сразу возникает логичный вопрос из определения, написанного выше. А в чем отличие от Load Testing? Ведь по сути оба этих подхода тестируют систему.
Ответ достаточно прост, и становится очевиден в ходе изучения методологии подхода: если в рамках нагрузочного тестирования происходит создание нагрузки на все компоненты системы, то в рамках Chaos engineering смысловая нагрузка тестов заключается в создании помех в различных предполагаемых точках отказа дисков, сети, ядра и др.
Читать об этом конечно интересно, а делать это ещё интереснее. В поисках open-source инструментов, с помощью которых можно разломать свой кластер, сразу же натыкаешься на Chaos Monkey и kube-monkey.
Chaos Monkey случайным образом завершает работу экземпляров виртуальных машин и контейнеров, работающих в вашей производственной среде. Данный инструмент работает только лишь в качестве интеграции через Spinnaker, что сразу явно не понравится более чем половине пользователей использующих другие системы для развертывания приложений.
Инструмент kube-monkey сделан на подобии Chaos Monkey, но не требует каких-либо дополнений для своей работы, взаимодействует он как с Kubernetes, так и с Openshift. Развернуть kube-monkey можно через helm chart. Уже интересней, но функционал оставляет желать лучшего, так как инструмент сам по себе имеет только одну функцию убивать по labels поды в определённые промежутки времени.
kube-monkey/enabled: enabled
kube-monkey/identifier: nginx
kube-monkey/mtbf: '1'
kube-monkey/kill-mode: random-max-percent
kube-monkey/kill-value: '100'После недолгих поисков чего-то более интересного для Chaos Engineering, рано или поздно находишь его: грааль, который пытался найти не кто иной как Харрисон Форд Индиана Джонс.

Chaos-mesh - исключительно занимательный продукт, который нельзя не оставить без внимания. Самое время его распробовать и объяснить, почему это приложение такое крутое!
Сразу можно пробежаться по основным преимуществам перед другими продуктами:
Наличие Helm charts;
Плагин для Grafana;
Наличие web панели;
Регулярные релизы с обновлениями и новым функционалом;
Обширное количество экспериментов для тестирования.
Но обо всём по подробнее. Установим в наш k8s chaos-mesh. Добавляем репозиторий и указываем необходимые fields для создания ingress.
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm repo update
helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-mesh --set dashboard.create=true --create-namespace --set dashboard.ingress.enabled=true --set dashboard.ingress.hosts[0].name=chaos.local --set dashboard.ingress.ingressClassName=nginx --set ChaosDaemon.runtime=containerdПолучаем в итоге следующий результат:
kubectl -n chaos-mesh get po
NAME READY STATUS RESTARTS AGE
chaos-controller-manager-69497948df-8hpzj 1/1 Running 0 2m5s
chaos-controller-manager-69497948df-kmm2z 1/1 Running 0 2m
chaos-controller-manager-69497948df-tkvkz 1/1 Running 0 2m3s
chaos-daemon-tjw2s 1/1 Running 0 2m2s
chaos-dashboard-6bc747df86-c5zgw 1/1 Running 0 18mВ частности, у нас есть:
Chaos Dashboard: компонент визуализации Chaos Mesh. Chaos Dashboard предлагает набор удобных веб-интерфейсов, с помощью которых пользователи могут манипулировать экспериментами Chaos и наблюдать за ними. В то же время Chaos Dashboard также предоставляет механизм управления разрешениями RBAC.
Chaos Controller Manager: основной логический компонент Chaos Mesh. Chaos Controller Manager в первую очередь отвечает за планирование и управление экспериментами Chaos. Этот компонент содержит несколько контроллеров CRD - таких как контроллер рабочего процесса, контроллер планировщика и контроллеры различных типов ошибок.
Chaos Daemon: основной исполнительный компонент. Chaos Daemon работает в режиме Daemonset и по умолчанию имеет разрешение Privileged (которое можно отключить). Этот компонент в основном взаимодействует с определенными сетевыми устройствами, файловыми системами, ядрами, взламывая целевое пространство имен подов.
В итоге после несложного разворачивания мы получаем достаточно приятную web-панель с интуитивно понятной навигацией, но для её корректной работы требуется предоставить ServiceAccount, у которого есть Role/RoleBinding на namespace или же ClusterRole/ClusterRoleBinding.
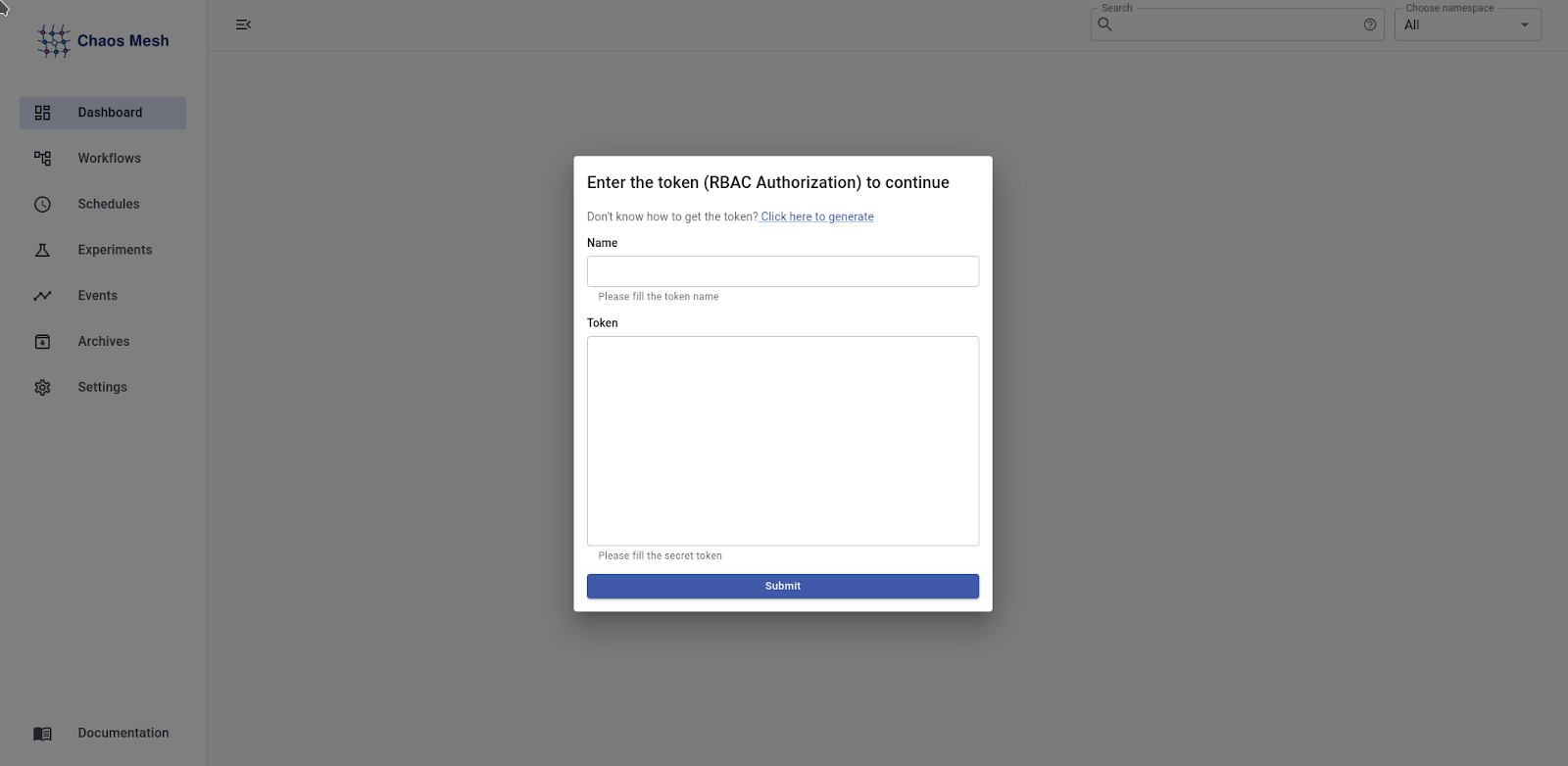
И это весьма разумно - ведь каждый пользователь, который будет пользоваться данным инструментом в рабочем кластере, не сможет случайно (или намеренно?) помешать работоспособности приложений, располагающихся в других namespace.
Но прежде чем создать необходимый ServiceAccount нужно понять, что мы будем тестировать. В рамках этой статьи я решил остановиться на простом и наглядном приложении dokuwiki. Добавляем репозиторий и совершаем его установку в наш кластер k8s.
helm repo add bitnami-azure https://marketplace.azurecr.io/helm/v1/repo
helm install dokuwiki bitnami-azure/dokuwiki -n dokuwiki –create-namespaceПосле чего проверяем результат, что наше приложение поднялось корректно и отдаёт нам 200 код ответа. Мой результат представлен на картинке ниже.
Время вернуться к нашему ServiceAccount! Создадим его вместе со всеми необходимыми ресурсами и правами для взаимодействия с подами в namespace dokuwiki.
cat << EOF > rbac.yaml
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: dokuwiki
name: account-dokuwiki-manager-urcaf
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: dokuwiki
name: role-dokuwiki-manager-urcaf
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups:
- chaos-mesh.org
resources: [ "*" ]
verbs: ["get", "list", "watch", "create", "delete", "patch", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: bind-dokuwiki-manager-urcaf
namespace: dokuwiki
subjects:
- kind: ServiceAccount
name: account-dokuwiki-manager-urcaf
namespace: dokuwiki
roleRef:
kind: Role
name: role-dokuwiki-manager-urcaf
apiGroup: rbac.authorization.k8s.io
EOF
kubectl apply -f rbac.yaml
kubectl -n dokuwiki create token account-dokuwiki-manager-urcafПолученный токен от ServiceAccount вставляем в поле авторизации в web-панели chaos-mesh и приступаем к Хаосу!

Попробуем смоделировать эксперимент, состоящий из различных тестов, и детально настроить их под конкретные уязвимые места. После чего посмотрим на наших графиках мониторинга, что же происходит с системой.
P.S.
Для мониторинга инфраструктуры заранее был поднят стандартный kube-prometheus-stack, и произведена настройка всех простейших dashboards.
Для наглядности и реалистичности создадим подобие нагрузки путём применения Apache Benchmark.
apt install apache2-utilsУстанавливаем пакеты и запускаем нагрузку, открывая 10 соединений с использованием Keep-Alive, и будем нагружать dokuwiki в течение 60 секунд через эти соединения:
ab -kc 10 -t 60 http://dokuwiki.local/После чего получаем нагрузку в 100rps. Чтобы проблем с нодой не было, и всё прошло замечательно, рекомендую установить limits на контейнер с приложением, так как если этого не сделать, последствия для вашей ноды в кластере могут быть весьма печальными.
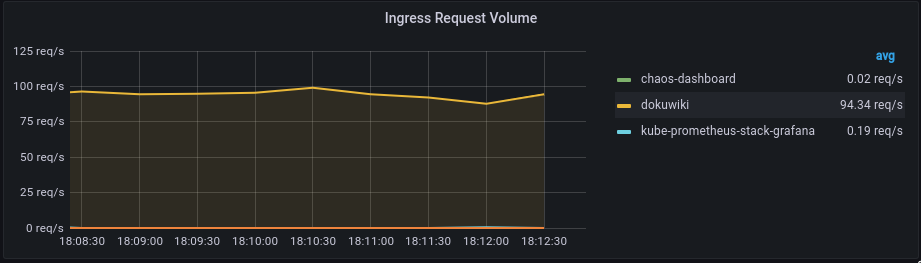
Глава 3: Теория хаоса правильна, кроме того, что хаос совсем не хаотичен, а полностью контролируем.
Попробуем смоделировать ситуацию, когда одна из наших реплик приложения становиться недоступна. Изначально в рамках настройки dokuwiki было указано создание двух реплик для отказоустойчивости приложения.
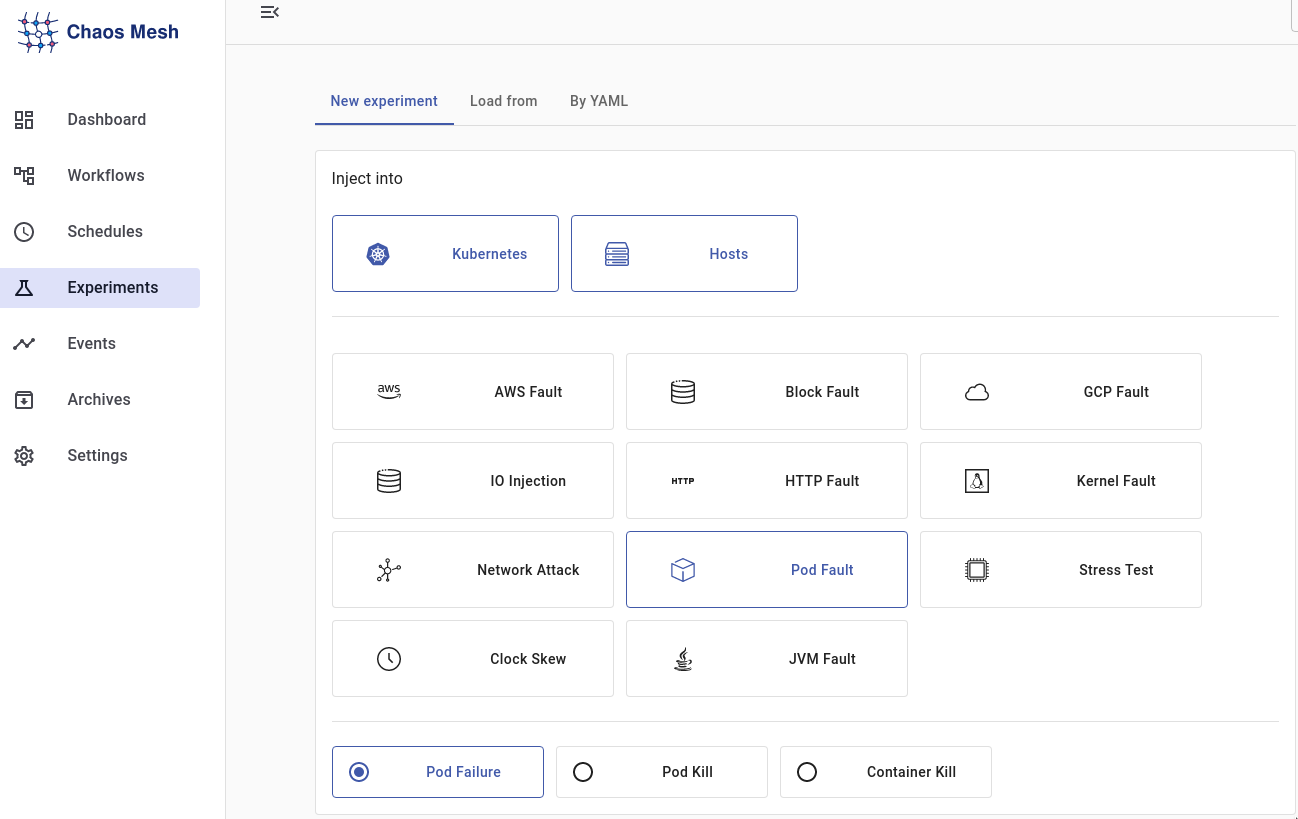
Важным отличительным удобством во всей настройке данного ПО является универсальность выбора цели и локализации воздействия тестирования - а именно выбор label интересующего нас пода или же вариации количества нагружаемых контейнеров/подов приложения в зависимости либо от строгой цифры( к примеру 3 пода из 5), либо от процентного соотношения. В данном эксперименте была произведена настройка убийства 50% любых подов, попадающих под label.

Также немаловажным моментом является автоматический подбор всех выше описанных параметров, проверка корректности составления эксперимента со стороны chaos-mesh и архивация всех когда-либо созданных тестов.

Производим запуск теста и смотрим, что из этого вышло. В нашем chaous-mesh мы видим следующую картину:
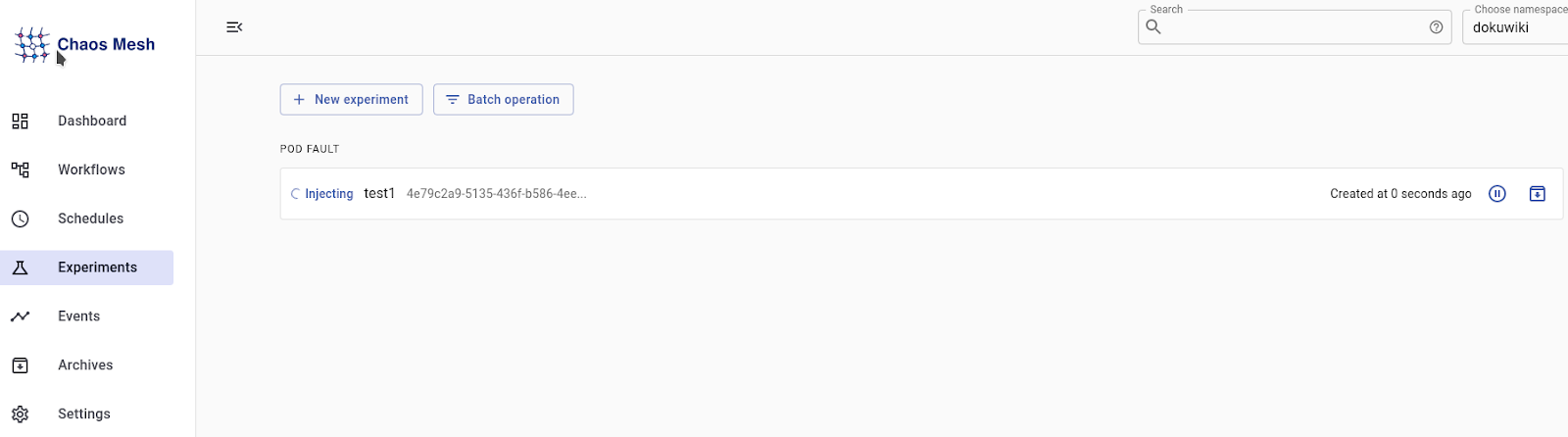
K8S:
kubectl -n dokuwiki get po
NAME READY STATUS RESTARTS AGE
dokuwiki-8f58c9d65-56ng7 0/1 Running 1 (27s ago) 2d18h
dokuwiki-8f58c9d65-7z6tw 1/1 Running 0 2d18hКак видно из представленных результатов, на графике заметна явная просадка rps созданных нами ранее с помощью Apache Benchmark:

Помимо самого наглядного теста, представленного выше, можно также произвести тестирование не только kubernetes, но и самих Node, на которых располагаются наши поды. В число всех этих экспериментов входит:
Создание ошибок в DNS;
Создание iowaits-диска;
Имитация ошибок Pod;
Моделирование сбоев Ядра Linux;
Создание проблем в работоспособности сети;
Создание нагрузки в контейнере и на ноде;
Выход из рабочего состояния ноды;
и др.
Помимо приятного разнообразия тестов, также преимущества данной технологии заключаются в различного рода интеграциях с облаками GCP, AWS, Azure, что расширяет функционал тестирования приложения и не даёт вам ограничений в творческом полёте.
Глава 4: Создание единого мира исходит от огромного количества фрагментов и хаоса.
На текущий момент помимо запуска различного рода тестов, scheduling этих процессов, сохранение исследований, появился новый функционал, который нельзя не отметить - создание полноценной модели тестирования всех составляющих кластера, включающих в себя большое количество заранее настроенных экспериментов, запускаемых как параллельно, так и последовательно.
К примеру, в данном Workflow представлено параллельное выполнение Experiments с различным временем выполнения:

Запуск этапов выполнения экспериментов происходит последовательно, и время их выполнения устанавливается вами с помощью timeout. В первую очередь, будет запущен “workfowtestexample”, а уже после его выполнения произойдет параллельный запуск “networkerror” и “stessresource”. После запуска нашего тестирования видим следующую картину в мониторинге:

При условии, что трафик поступающих в наше приложение изначально оставался таким же как и был, можно явно заметить снижение rps на ingress dokuwiki, что объясняется ошибками, возникающими в DNS.
Также в ходе дальнейшего нагрузочного тестирования самого контейнера в поде можно увидеть значительное увеличение его ресурсопотребления, превышающего установленные заранее лимиты, и, как следствие, возникновение некорректных кодов ответа площадки:

В настоящее время Workflow Chaos Mesh поддерживает следующие функции:
Последовательный запуск тестов.
Параллельный запуск тестов.
Условная ветвь, включающая в себя проверку состояния приложения и оставляющая за собой право остановить все рабочие процессы тестирования в случае некорректного статуса ответа приложения.
Глава 5: Почитал, осознал, применил, сломал, починил и улыбнулся.

Chaos engineering - это необычайно полезная, хоть и достаточно непривычная методология подхода исследования отказоустойчивости своей рабочей инфраструктуры. Согласитесь, ведь ситуация, когда происходит падение продакшена, достаточно страшна. Но если производить это падение осознанно, произведя перед этим предварительную подготовку, то это убережет вас от множества проблем в будущем и покажет все возможные потенциальные точки отказа вашей системы. И хотя многие живут и работают по принципу “Не надо ломать то, что работает”, в современном контексте реальности этот принцип не работает, и ребята из Netflix это доказали.
P.S.: еще больше новостей и статей по теме DevOps - в нашем telegram-канале DevOps FM, присоединяйтесь, чтобы быть в курсе.
Рекомендации для чтения:

{kind=link}