
Существующие сегодня 3D-сенсоры, основанные на
измерении времени прохождения луча света, подобные Kinect, могут довольно неплохо составлять карту глубин изображения, если в сцене нет полупрозрачных и отражающих поверхностей, преломляющих и искажающих путь световых лучей. Дождь, струи воды, туман или предметы из стекла или прозрачного пластика просто заслоняют более далёкие объекты, так как сенсор распознаёт только самое первое отражение сигнала.
На конференции Siggraph Asia, которая прошла в Гонконге на прошлой неделе, учёные из MIT Media Lab
представили новую разработку, основанную на том же принципе. В ней используется обычный лазерный диод и недорогой сенсор. Стоимость оборудования составила всего лишь порядка 500 долларов. Единственное существенное отличие прототипа от коммерческих аналогов, таких как Kinect, заключается в прошивке.
Вместо простой периодической модуляции импульсов инфракрасного лазера, прототип MIT использует специально подобранные последовательности импульсов, имеющие автокорреляционную функцию с очень узким единичным пиком (такие сигналы используются в эхолокации и телекоммуникациях для точного измерения времени задержки сигнала. Более подробно о них можно почитать в статье "
Основные принципы цифровой беспроводной связи. Ликбез", в разделе «Автокорреляционная функция. Коды Баркера»). Камера хорошо различает первые отражения от поверхности прозрачного предмета и следующие за ними отражения от более далёких объектов. Она даже способна получить чёткое изображение надписи, закрытой матовым экраном.

 Сегменту wearable computers (подстрочник с английского «надеваемые компьютеры») два десятка лет. Отцом нательных компьютеров считается профессор Торонтского университета Стив Манн (Steve Mann). В 1970-х и 80-х годах он создал несколько нательных систем общего пользования, включая устройства считывания, биологической обратной связи и мультимедиа. В 1981 году он разработал мультимедийную компьютерную систему для крепления на спину с наголовным дисплеем для одного глаза. С тех пор Манн каждый день носит какой-нибудь нательный компьютер.
Сегменту wearable computers (подстрочник с английского «надеваемые компьютеры») два десятка лет. Отцом нательных компьютеров считается профессор Торонтского университета Стив Манн (Steve Mann). В 1970-х и 80-х годах он создал несколько нательных систем общего пользования, включая устройства считывания, биологической обратной связи и мультимедиа. В 1981 году он разработал мультимедийную компьютерную систему для крепления на спину с наголовным дисплеем для одного глаза. С тех пор Манн каждый день носит какой-нибудь нательный компьютер.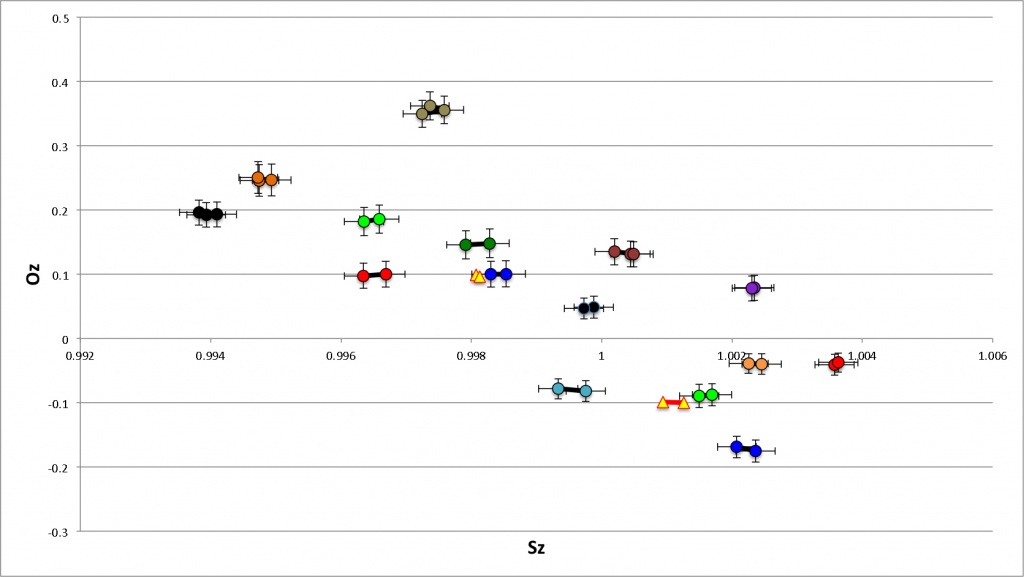
 От переводчика: Это двенадцатая, последняя статья из
От переводчика: Это двенадцатая, последняя статья из 
 От переводчика: Это первая статья из
От переводчика: Это первая статья из 
