«Хочешь сделать красиво - сделай в фотошопе».
Участник проекта.
При любых строительных работах генеральный план является обязательной частью проекта. Готовый генплан предоставляет подробную информацию об объемах работ, объектах строительства, транспортных сообщениях и инженерных коммуникациях разного назначения.
Именно от точности и качества генерального плана зависит безопасность и надежность всего проекта, его функциональность, а их оптимальное проектирование позволяет снизить финансовые и временные затраты уже на самом старте реализации проекта. Очевидно, что при решении подобной задачи хочется максимально автоматизировать оптимальное проектирование генеральных планов и застраховаться от любых ошибок, связанных с человеческим фактором.
Меня зовут Фёдор. В «Цифровом проектировании» я придумываю и разрабатываю различные алгоритмы, которые помогают оптимизировать генеральные планы. В этом тексте я расскажу про математические задачи, с которыми мы сталкиваемся при проектировании генеральных планов, как мы декомпозируем задачу, почему делаем это именно таким образом и какие у нас дальнейшие планы.
Общая постановка задачи
С самого начала стоит уточнить, что разрабатываемый продукт не претендует (по крайней мере на данном этапе) на то, что его результаты будут напрямую реализовываться в неизменном виде. Наша цель - предложить оптимальные по ряду критериев решения, по сравнению с проектируемыми вручную. Далее они частично или полностью могут использоваться при формировании окончательной версии генерального плана для заказчика.
Входные данные нашего проекта следующие:
Список зданий с их свойствами:
геометрические размеры,
класс пожароопасности,
присутствие воспламеняющихся веществ или тепловые потоки (например для факельных установок),
присутствие людей,
функциональная зона (ФЗ) и т.д.;
Список коммуникаций (трубопроводы, линии электропередач, дренажные системы и т.д.), их удельные стоимости прокладки;
Допустимая область строительства;
Направление розы ветров в данной местности.
Вот так выглядит уже сформированный генплан.
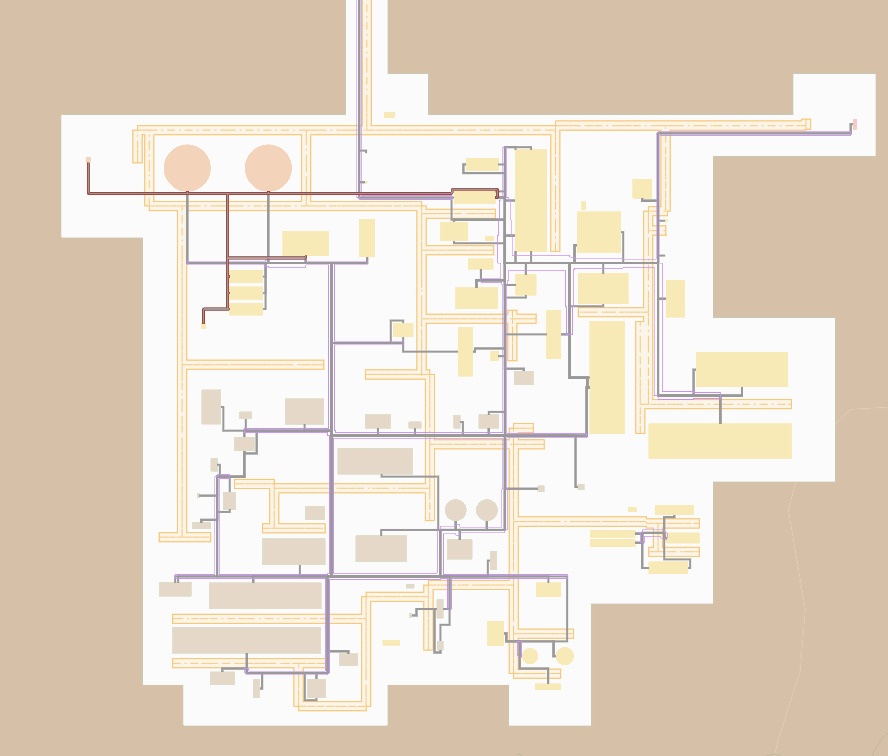
На изображении можно заметить здания, дороги и линии коммуникаций. Наша задача - оптимизировать приходящие к нам данные, чтобы получился подобный итог. Оптимизируем мы следующие значения:
площадь объекта (отрисованный забор вокруг всего площадного объекта);
суммарную площадь застройки (суммарная площадь зданий);
плотность застройки;
длину эстакад коммуникаций (насколько оптимально мы расставили технологические линии).
Целевая функция следующая:

 - стоимость инженерной подготовки (земляные работы, отсыпка),
- стоимость инженерной подготовки (земляные работы, отсыпка),  - стоимость прокладки коммуникаций между зданиями,
- стоимость прокладки коммуникаций между зданиями,  - стоимость прокладки коммуникаций к внешним точкам подключения (прокладка трубопровода к линии, идущей от кустовых скважин, и т.п.),
- стоимость прокладки коммуникаций к внешним точкам подключения (прокладка трубопровода к линии, идущей от кустовых скважин, и т.п.),  - стоимость строительства эстакад, по которым проходят коммуникации и
- стоимость строительства эстакад, по которым проходят коммуникации и  - стоимость прокладки дорог.
- стоимость прокладки дорог.
Таким образом выглядит общая постановка задачи. Решаем мы её сейчас на евклидовой плоскости в двумерном пространстве и пока не учитываем вопросы, связанные с трехмерной структурой проекта и рельефом.
Даже с учётом сделанных предположений оптимизация всех параметров в целевой функции одновременно представляется весьма сложной задачей. Типичный площадной объект имеет порядка сотни зданий, положение каждого определяется тремя параметрами: координаты центра здания и угол поворота, несколько сотен (а при достаточной детализации больше тысячи) коммуникаций. Помимо этого к каждому зданию должна быть проведена дорога.
В целях упрощения задачи мы разбили её на несколько этапов:
Подготовка данных к расчёту
Кластеризация. Здания разбиваются на группы сооружений, которые мы считаем "похожими".
Локальная топология. Размещение зданий относительно друг друга независимо внутри разных кластеров
Глобальная топология. Жёстко зафиксировав относительные положения зданий внутри кластеров размещаем кластера.
Проведение коммуникаций и эстакад.
Проведение дорог.
Расчёт многоугольника площадки.
Мы предполагаем, что здания могут иметь форму только окружности или прямоугольника. При расположении на местности стороны зданий параллельны осям координат. Аналогично, коммуникации и дороги должны быть параллельны координатной сетке.
В последние два этапа углубляться я не буду. Проведение дорог схоже с прокладыванием коммуникаций и эстакад. Кстати, вот материал нашего коллеги Сергея Степанова как раз по этой теме. Расчет ограничивающего многоугольника площадки - задача, выходящая за рамки данной статьи.
Реализация алгоритмической части проекта выполнена на Python. Такой выбор обусловлен возможностью быстро менять функционал, использовать большое количество готовых библиотек. Позже, когда методики и алгоритмы приобретут законченный вид, проект будет переписан на язык со статической типизацией
Итак, данные мы подготовили. Дальше переходим к кластеризации объектов.
Кластеризация
Для чего мы кластеризуем объекты? Кластеризация помогает уменьшить размерность задачи - сначала мы считаем её части, а потом складываем их. Для наглядности сравним две формулы, которые хоть и не относятся к нашему случаю, но помогают понять эффективность такого подхода.
Без кластеризации вычислительная сложность  собирания топологии составляет:
собирания топологии составляет:

где  - число зданий,
- число зданий,  - количество шагов оптимизации,
- количество шагов оптимизации,  - константа соответствующая реализации.
- константа соответствующая реализации.
Если разбить на  кластеров одинакового размера и сначала собирать внутри кластеров, а затем кластера вместе, то вычислительная сложность составит:
кластеров одинакового размера и сначала собирать внутри кластеров, а затем кластера вместе, то вычислительная сложность составит:

Возьмём частный случай, когда в каждом кластере по 5 объектов. тогда  и получаем:
и получаем:

В результате при большом  гораздо выгоднее использовать
гораздо выгоднее использовать  .
.
Кластеризация сильно уменьшает время расчета. Однако нам важно не просто уменьшить размерность, а при этом минимально пожертвовать оптимизацией. Почему мы ей жертвуем?
Разбиваем здания на группы мы по определенному принципу, а следовательно, неравномерно. В одном кластере может оказаться четыре здания, в другом шесть. Сначала мы расставляем здания относительно друг друга в одном кластере, затем, независимо от этого, в другом. Очевидно, что если расставлять сразу эти 10 зданий относительно друг друга, может получиться более оптимальный результат. Как с точки зрения геометрии, так и с точки зрения стоимости связей.
Верхнее ограничение по времени для всего расчета составляет несколько часов. В текущей реализации расстановка порядка сотни кластеризованных зданий занимает около часа (не учитывая другие этапы задачи). При рассмотрении каждого здания как отдельного объекта время вычисления расположения зданий увеличивается до двух-трёх часов.
Как же мы проводим кластеризацию?
Первый важный критерий, который нам необходимо учитывать - правило минимальных попарных расстояний. К примеру - у цистерн есть взрывные зоны. Соответственно, относительно большинства зданий они не могут располагаться ближе определенного расстояния. Также есть стоимости связей, трубопроводов между зданиями (удельная стоимость за метр). В результате, с одной стороны у нас должна быть как можно более компактная площадка, с другой стороны, она должна иметь как можно меньшую стоимость связей.
Ещё нужно учитывать геометрию зданий. При разбивке на кластеры логично положить в один кластер здания со схожей геометрией, т.к. их можно будет удобно расставить.
Мы используем алгоритм аггломеративной кластеризации. На вход он принимает симметричную матрицу различий (nb * nb), (i, j) элемент в которой является различием между зданиями i и j, задаваемого числом от 0 до 1. Различие состоит из описанных критериев с подбираемыми весами.
Кластеризация для зданий со связями основывается на правилах минимальных попарных расстояний между зданиями (оффсеты), стоимостях соединений между зданиями и стоимостях связей с другими функциональными зонами. При этом в одном кластере должны быть здания из одной функциональной зоны, поэтому все здания разбиваются на группы по функциональным зонам и кластеризация происходит в этих группах по отдельности.

Здесь offset - значение оффсета между двумя зданиями, деленное на максимальный оффсет внутри данной функциональной зоны (ФЗ); connection cost - суммарная стоимость связей между двумя зданиями, деленная на максимальную стоимость связей между зданиями в функциональной зоне; functional cost diversity - суммарная стоимость связей данного здания со зданиями из других ФЗ, деленная на максимальную стоимость связи между разными ФЗ.
Кластеризация зданий без связей основывается на оффсетах и геометрических параметрах зданий. В этом случае различие вычисляется по следующей формуле:

Нормированный оффсет вычисляется как в предыдущем случае, а различие по размерам получаем следующим образом:

где


У тех, кто знаком с понятием кластеризации, может возникнуть вопрос: почему мы не можем применить классические алгоритмы вроде «K-ближайших соседей»?.
В нашем случае отношения между объектами не задаются свойствами каждого объекта в отдельности. Offset или стоимость связи не принадлежат одному зданию. Они определены только в том случае, когда мы берем пару объектов. Поэтому мы не можем расположить объекты по всем критериям в пространстве и использовать классические алгоритмы.
Составив матрицу различий, применяем библиотечную реализацию аггломеративной кластеризации с метрикой Уорда. Ниже на картинке можно увидеть пример дендрограммы для одной из функциональных зон. На горизонтальной оси расположены условные обозначения зданий (например 3 - насосная, 4.4 - блок трансформатора и т.д.).

Черная линия на изображении - значение различия, при котором мы перестаем объединять (представляет из себя тоже некоторый коэффициент). Если мы опустим линию ниже, у нас получится больше отдельных объектов, если выше - они объединятся в более крупные кластеры.
Локальная и глобальная топология
Хоть мы и разбили формирование топологии на два этапа, структурно они схожи. Поэтому расскажу о них в одной части.
Нам нужно расставить объекты относительно друг друга. В первом случае мы расставляем здания внутри кластеров. Во втором - расставляем между собой сами кластеры, внутри которых положения зданий уже жестко зафиксированы.


Посмотрев на изображения, можно заметить, что все кластеры у нас прямоугольные. Почему тогда мы не можем воспользоваться классической задачей упаковки?
Наша задача принципиально отличается из-за правила минимальных попарных расстояний. Здание №1 может иметь правило стоять не ближе девяти метров к зданию №2. Здание №2 может иметь правило стоять не ближе шести метров от здания №3. А здание №3 может иметь минимальное расстояние сто метров от здания №1.

Подобные линии обозначают, что здания стоят относительно друга друга на офсете +/- 10%. Подойти ближе они практически не могут. Также важно понимать, что ограничения по расстоянию могут быть не с соседними зданиями, а с расположенными далеко друг от друга.
В нашем проекте эти ограничения мы называем «активными ограничениями» - ближе приблизиться здания не могут, а слово активные означает, что ограничение уже действует. Эти ограничения мы используем для критериев определения плотности, оптимальности решения. Чем больше активных ограничений, тем выше плотность. Если у нас их нет, значит мы можем продолжать стягивать здания.
Раз задача отличается от задачи упаковки, нам пришлось придумать свое решение. Мы используем два алгоритма на физических аналогиях. Концептуально они похожи, отличаются только в реализации.
Повторим критерии. Мы хотим, чтобы площадка была наиболее плотная и при этом нам важно снизить стоимость коммуникаций.
Поскольку изначально мы не знаем, как пройдут коммуникации, мы говорим, что уменьшаем ожидаемую стоимость коммуникаций, пытаясь расположить здания ближе друг к другу. Чем дороже между собой связаны здания, тем ближе друг к другу мы их пытаемся расположить. Даже небольшая корректировка положения здания может сильно изменить конфигурацию эстакад.
Это довольно условная оптимизация, но решать подобную задачу целиком проблематично. На проекте может быть несколько сотен коммуникаций. При фиксированном расположении зданий нам нужно провести граф, по которому мы их проведем. На нашем небольшом графе они проводятся за 5-10 минут. После этого мы понимаем, как они проходят, и снова переставляем здания и прокладываем коммуникации. В результате нужно провести множество итераций, что займет неоправданно много времени.
Первый алгоритм, который мы используем, основан на силовом методе. К каждой паре зданий рассчитываются расстояния. Пока здания дальше, чем оффсет, они притягиваются друг к другу. Чем больше стоимость связи между ними, тем сильнее притяжение. Если здания подходят к оффсету, начинается отталкивание.
![F(x) = (1 + \text{connection$\_$cost}) \cdot \left[- \frac{1}{a x} - \frac{\sqrt{n_b}}{1 + \exp^{-2 \alpha x}} + \frac{x}{a} \exp^{\frac{1 - x^2}{a^2}} + \ln x\right]](https://habrastorage.org/getpro/habr/upload_files/8ee/c10/b7b/8eec10b7b9b77940779dc7c799761ee8.svg)
 - безразмерное расстояние между двумя зданиями (геометрическое расстояние, поделённое на минимально допустимое),
- безразмерное расстояние между двумя зданиями (геометрическое расстояние, поделённое на минимально допустимое),  - параметр, определяющий значение
- параметр, определяющий значение  , при котором третье слагаемое максимально:
, при котором третье слагаемое максимально:  , а
, а  - число зданий, участвующих в оптимизации. Значение данной силы равно 0, если
- число зданий, участвующих в оптимизации. Значение данной силы равно 0, если  . Если здания находятся друг к другу на расстоянии ближе чем
. Если здания находятся друг к другу на расстоянии ближе чем  , то они отталкиваются, если на большем, то притягиваются. Если между двумя зданиями должна быть проведена линия коммуникации, то значение силы умножается на величину
, то они отталкиваются, если на большем, то притягиваются. Если между двумя зданиями должна быть проведена линия коммуникации, то значение силы умножается на величину  , где
, где  - удельная стоимость прокладки коммуникации. Это тем больше увеличивает силу притяжения, чем больше стоимость связи между зданиями.
- удельная стоимость прокладки коммуникации. Это тем больше увеличивает силу притяжения, чем больше стоимость связи между зданиями.
Для введенной силы можно выписать формулу целевой функции между двумя зданиями:

Глобальная сборка отличается тем, что мы смотрим на расстояния между кластерами как на расстояния между зданиями, которые наиболее близко относительно друг друга к нарушению оффсета. Стоимость связи между кластерами - это сумма связей между зданиями в этих кластерах.
Второй алгоритм основан на энергетическом методе. Он оптимизирует целевую функцию, учитывая данные линейные ограничения (оффсеты, разрешённая зона строительства и т.д.). Целевая функция второго алгоритма:

Наличие двух похожих алгоритмов обусловлено историческими (в контексте проекта) причинами. В ближайшее время они будут объединены в один метод.
Построение коммуникаций и дорог
При фиксированном расположении зданий мы уже можем провести коммуникации и дорожные проезды. Важно учитывать, что коммуникации и дороги не должны «накладываться» друг на друга, но могут пересекаться. Поэтому нам приходится решать, что проводить в первую очередь. Для объектов, прокладываемых первыми, получится более оптимальное расположение, чем при последующем, потому что изначально влияет меньше ограничений. Мы в первую очередь прокладываем коммуникации, поскольку стоимость их прокладки обычно в разы превышает стоимость строительства дорог.
Построение коммуникаций представляет из себя уже более классическую задачу. Сначала строится граф, по которому будут проводиться коммуникации. Изначально мы не знаем, где они пройдут, соответственно не знаем точной ширины эстакад. Поэтому мы берем примерные параметры. По техническим требованиям до эстакады должно быть 2 метра, примерную ширину эстакады мы ожидаем также 2 метра. Поэтому мы строим граф с учетом имеющихся ограничений. На расстоянии 3 метров проводим от здания прямую линию до упора в границу другого здания, либо до края площадки. Такое действие мы проводим для каждой стороны всех зданий.
Для того, чтобы мы смогли правильно расположить здания с учетом проведения коммуникаций на следующем этапе, мы искусственно увеличиваем расстояния между зданиями ещё на этапе топологии. Если у зданий минимальное расстояние 1 метр, то нам их нужно расположить не самым близким образом, а с учетом прокладки коммуникаций (не менее 3 метров).
Далее мы начинаем строить коммуникации в определенном порядке. На этом этапе применяется классический алгоритм Дейкстры. Ребра графа мы перевзвешиваем, потому что нам известна стоимость прокладки.
Там, где мы провели коммуникацию, подразумевается эстакада. Значит, стоимость строительства эстакады для следующей коммуникации, проходящей по этому ребру, равна нулю. Поэтому, от того, какой порядок прокладки коммуникаций мы выберем, сильно зависит итоговый результат.
Поскольку мы знаем ширину проведенных коммуникаций, мы можем уже построить эстакады. На выходе получается следующая картинка.

Теперь, зная ширины эстакад, мы можем двигать здания. Двигаем к эстакадам мы те здания, к которым через эти эстакады проходят коммуникации. На каждом шаге рассчитывается, как здания стоят относительно друг друга и эстакад. Далее они сдвигаются и проводятся новые расчеты.
Зная, где проходят эстакады, мы уже можем отказаться от кластеризации, потому что подразумеваем, что на этом этапе глобально двигать здания не нужно. Поэтому мы можем все здания двигать отдельно. В результате получаем изображение с корректными эстакадами.
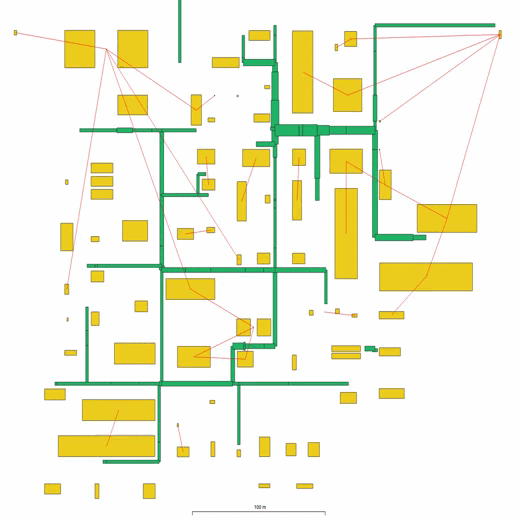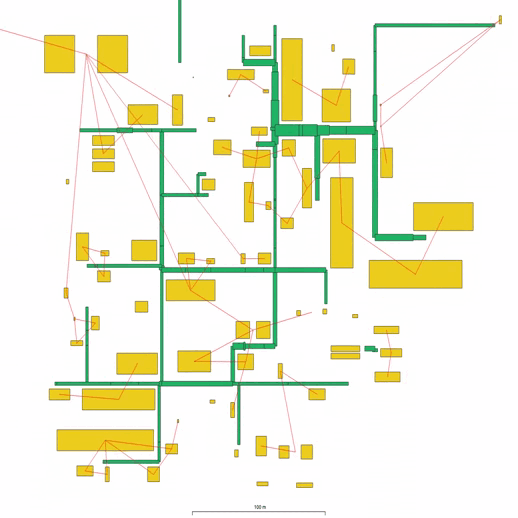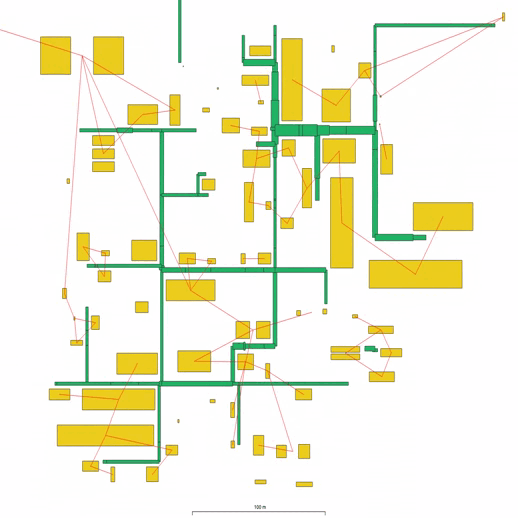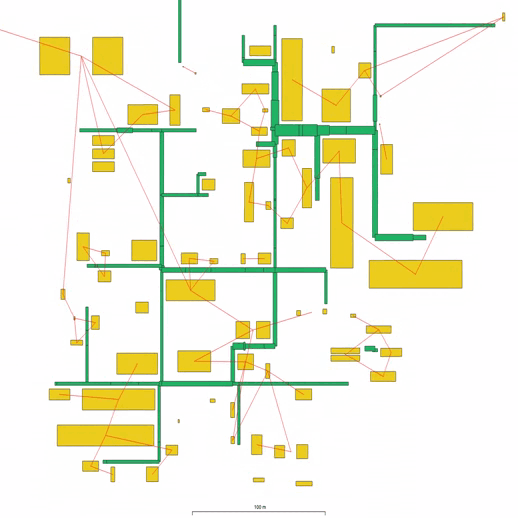
Следующий этап - проведение дорог. Он схож с проведением коммуникаций, однако стоит учитывать, что на этом этапе влияет уже больше ограничений.
Что мы планируем учитывать в дальнейшем?
В ближайших планах - ввести учет внешних точек подключения. С определенных сторон к площадным объектам должны подходить дороги, трубопроводы нефтепроводы и т.д. Разумно размещать объекты, связанные с ними, рядом. К примеру - КПП пропуска на объект разумно разместить ближе к дороге, которая к нему подходит.
Позднее мы планируем приступим к реализации трехмерной геометрии, добавить возможность рассчитывать взаимодействие на природу, добавить правило максимально допустимых расстояний.
Но уже сейчас наши алгоритмы помогают сильно упростить разработку подобных генеральных планов, с помощью которых специалист может быстро обрабатывать множество вариантов и принимать оптимальные решения.
