

Социальные сети — это один из наиболее востребованных на сегодняшний день интернет-продуктов и один из основных источников данных для анализа. Внутри же самих социальных сетей самой сложной и интересной задачей в сфере data science по праву считается формирование ленты новостей. Ведь для удовлетворения всё возрастающих требований пользователя к качеству и релевантности контента необходимо научиться собирать информацию из многих источников, вычислять прогноз реакции пользователя и балансировать между десятками конкурирующих метрик в А/Б-тесте. А большие объемы данных, высокие нагрузки и жесткие требования к скорости ответа делают задачу ещё интереснее.
Казалось бы, задачи ранжирования на сегодня уже изучены вдоль и поперёк, но если присмотреться, то не всё так просто. Контент в ленте очень разнороден — это и фото друзей, и мемасики, вирусные ролики, лонгриды и научпоп. Для того, чтобы собрать всё воедино, необходимы знания из разных областей: компьютерное зрение, работа с текстами, рекомендательные системы, и, в обязательном порядке, современные высоконагруженные хранилища и средства обработки данных. Найти одного человека, обладающего всеми навыками, сегодня чрезвычайно сложно, поэтому сортировка ленты — это по-настоящему командная задача.
С разными алгоритмами ранжирования ленты в Одноклассниках начали экспериментировать еще в 2012-м году, а в 2014-м к этому процессу подключилось и машинное обучение. Это стало возможным, в первую очередь, благодаря прогрессу в области технологий работы с потоками данных. Только начав собирать показы объектов и их признаки в Kafka и агрегируя логи с помощью Samza, мы смогли построить датасет для обучения моделей и рассчитать самые «тянущие» фичи: Click Through Rate объекта и прогнозы рекомендательной системы «по мотивам» работы коллег из LinkedIn.

Очень быстро пришло понимание того, что рабочая лошадка логистической регрессии не может вывезти ленту в одиночестве, ведь у пользователя может быть очень разнообразная реакция: класс, комментарий, клик, сокрытие и т.д., а контент при этом может быть очень разный — фото друга, пост группы или заклашенный другом видосик. У каждой реакции для каждого типа контента своя специфика и своя бизнес-ценность. В итоге мы пришли к концепции «матрицы логистических регрессий»: для каждого типа контента и каждой реакции строится отдельная модель, а затем их прогнозы умножаются на матрицу весов, формируемую руками исходя из текущих бизнес-приоритетов.
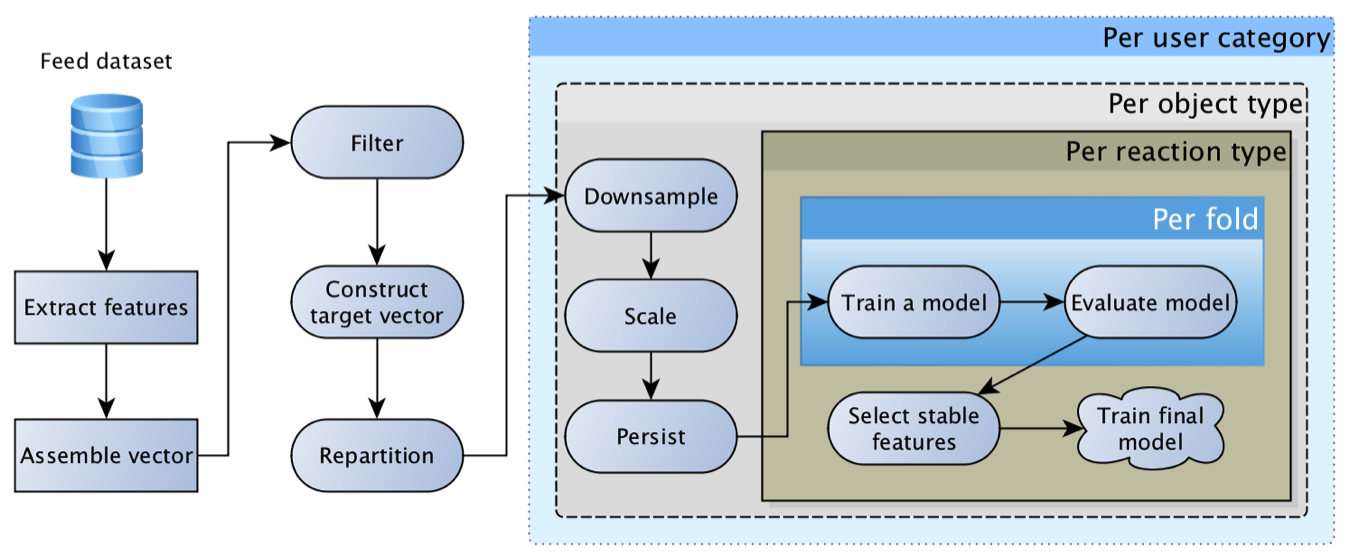
Эта модель оказалась на редкость жизнеспособной и достаточно долго была основной. Со временем она обрастала всё более интересными признаками: для объектов, для пользователей, для авторов, для отношения пользователя с автором, для тех, кто взаимодействовал с объектом, и т.д. В результате первые попытки заменить регрессию нейросетью закончились грустным «фичи у нас слишком закрафченые, сетка буста не дает».
При этом часто наиболее ощутимый буст с точки зрения пользовательской активности давали технические, а не алгоритмические улучшения: зачерпнуть больше кандидатов для ранжирования, точнее отслеживать факты показа, оптимизировать скорость ответа алгоритма, углубить историю просмотров. Подобные улучшения часто давали единицы, а иногда даже десятки процентов прироста активности, тогда как обновление модели и добавление признака чаще давало десятые доли процента прироста.

Отдельную сложность при экспериментах с обновлением модели создавал ребаланс контента — распределения прогнозов «новой» модели часто могли значимо отличаться от предшественника, что приводило к перераспределению трафика и обратной связи. В итоге, сложно оценить качество новой модели, так как сначала нужно откалибровать баланс контента (повторить процесс настройки весов матрицы по бизнес-целям). Изучив опыт коллег из Facebook, мы поняли, что модель нуждается в калибровке, и сверху логистической регрессии пристроилась регрессия изотоническая :).
Часто в процессе подготовки новых контентных признаков мы испытывали фрустрацию — простая модель, использующая базовые коллаборативные техники, может дать 80 %, или даже 90 % результата, тогда как модная нейросетка, обучавшаяся неделю на супердорогих GPU, идеально детектит котиков и машинки, но даёт прирост метрик только в третьем знаке. Подобный эффект часто можно увидеть и при внедрении тематических моделей, fastText и других эмбедингов. Побороть фрустрацию удалось, взглянув на валидацию под правильным углом: производительность коллаборативных алгоритмов существенно улучшается по мере накопления информации об объекте, тогда как для «свежих» объектов контентные признаки дают ощутимый буст.
Но, конечно, когда-нибудь результаты логистической регрессии должны были быть улучшены, и добиться прогресса удалось, применив недавно вышедший XGBoost-Spark. Интеграция была непростой, но, в итоге, модель наконец-то стала модной-молодёжной, а метрики приросли на проценты.
Наверняка из данных можно извлечь гораздо больше знаний и вывести ранжирование ленты на новую высоту — и сегодня у каждого появилась возможность попробовать свои силы в этой нетривиальной задаче на конкурсе SNA Hackathon 2019. Соревнование проходит в два этапа: с 7 февраля по 15 марта загружайте решение одной из трех задач. После 15 марта будут подведены промежуточные итоги, и 15 человек из топа лидерборда по каждой из задач получат приглашения на второй этап, который пройдёт с 30 марта по 1 апреля в московском офисе Mail.ru Group. Кроме того, приглашения на второй этап получат три человека, оказавшиеся в лидерах рейтинга на конец 23 февраля.
Почему задачи три? В рамках онлайн-этапа мы предлагаем три набора данных, в каждом из которых представлен только один из аспектов: изображение, текст или информация о разнообразных коллаборативных признаках. И только на втором этапе, когда эксперты в разных областях соберутся вместе, будет раскрыт общий датасет, позволяющий найти точки для синергии разных методов.
Заинтересовала задача? Присоединяйтесь к SNA Hackathon :)
