Весной этого года проходил знаменательный Retro Contest от OpenAI, который был посвящен обучению с подкреплением, meta learning и, конечно же, Sonic’у. Наша команда заняла 4 место из 900+ команд. Область обучения с подкрепление немного отличается от стандартного машинного обучения, а уж этот контест отличался от типичного соревнования по RL. За подробностями прошу под кат.

TL;DR
Правильно затюненый бейзлайн в дополнительных трюках не нуждается… практически.
Intro в обучение с подкреплением

Обучение с подкреплением – область, объединяющая в себе теорию оптимального управления, теорию игр, психологию и нейробиологию. На практике, обучение с подкреплением применяется для решения задач принятия решений и поиска оптимальных стратегий поведения, или политик, которые являются слишком сложными для “прямого” программирования. В этом случае агент обучается по истории взаимодействий со средой. Среда, в свою очередь, оценивая действия агента, предоставляет ему награду (скаляр) – чем лучше поведение агента, тем больше и награда. В итоге, наилучшая политика выучивается у того агента, который научился максимизировать суммарную награду за все время взаимодействия со средой.
В качестве самого простого примера можно провести игру BreakOut. В это старой доброй игре серии Atari человеку/агенту требуется управлять нижней горизонтальной платформой, отбивать мячик и постепенно разбивать им все верхнии блоки. Чем больше сбил — тем больше и награда. Соответственно, то, что видит человек/агент — это изображение с экрана и требуется принять решение в какую сторону двигать нижнюю платформу.

Если Вас заинтересовала тема обучения с подкреплением, cоветую крутой вводный курс от Вышки, а также его более детальный open source аналог. Если же хочется чего-то, что можно почитать, но с примерами – книга, вдохновленная двумя этими курсами. Все эти курсы я обозревал/проходил/помогал в создании, а потому на собственном опыте знаю, что они дают отличный базис.
Про задачу
Основной целью данного соревнования было получить агента, который умел бы хорошо играть в серию игр SEGA – Sonic The Hedgehog. OpenAI тогда только начинала импортировать игры из SEGA в свою площадку для обучения RL агентов, и таким образом решила немного пропиарить этот момент. Даже статью выпустили с устройством всего и подробным описанием базовых методов.
Поддерживались все 3 игры Sonic, каждая с 9 уровнями, на которых, смахнув скупую слезу, можно было даже поиграть, вспоминая детство (предварительно купив их в Steam).
В качестве состояния среды (то, что видел агент) выступало изображение с симулятора – RGB картинка, а в качестве действия агенту предлагалось выбрать какую кнопку на виртуальном джойстике нажать – прыжок/влево/вправо и тд. Очки награды агент получал также как и в оригинальной игре, т.е. за сбор колец, а также за скорость прохождения уровня. По сути, перед нами был оригинальный соник, только пройти его требовалось с помощью нашего агента.
Проходило соревнование с 5 апреля по 5 июня, т.е. всего 2 месяца, что кажется уже довольно таки маловато. Наше команда смогла собраться и зайти на соревнование только в мае, что заставило изучать многое на ходу.
Baselines
В качестве бейзлайнов были даны полные гайды по обучению Rainbow (DQN подход) и PPO (Policy Gradient подход) на одном из возможных уровней в Sonic и сабмита получившегося агента.
Версия Rainbow была основана на малоизвестном проекте anyrl, а вот PPO использовал старые добрые baselines от OpenAI и нам показался куда более предпочтительным.
От описанных в статье подходов опубликованные бейзлайны отличались большей простотой и меньшим наборов “хаков” для ускорения обучения. Таким образом организаторы и идей подкинули и направление задали, но уж решение по использованию и реализации этих идей оставалось за участником соревнования.
Касательно идей, хочется поблагодарить OpenAI за открытость, а в отдельности John Schulman за консультации, идеи и предложения, которые он озвучил в самом начале этого конкурса. Нам как и многим участникам (а уж тем более новичкам в мире RL), это позволило лучше сфокусироваться на основной цели соревнования – meta learning и улучшение генерализации агента, о чем мы сейчас и поговорим.
Особенности оценивания решений
Самое интересное начиналось в момент оценивания агентов. В типичных соревнованиях/бенчмарках по RL алгоритмы тестируются в той же среде, где они были обучены, что способствует алгоритмам, которые хороши в запоминании и имеют много гиперпараметров. В этом же конкурсе тестирование алгоритма проводилось на новых уровнях Sonic’а (которые так никому и не показали), разработанных командой OpenAI специально для этого конкурса. Вишенкой на торте был факт, что в процессе тестирования агенту также выдавалась награда по ходу прохождения уровня, что давало возможность дообучаться непосредственно в процессе тестирования. Однако, в этом случае стоило помнить, что тестирование было ограничено как по времени — 24 часа, так и по тикам игры — 1 миллион. При этом OpenAI всячески поддерживали создание таких агентов, которые могли бы быстро дообучаться под новые уровни. Как уже говорилось, получение и изучение таких решений и было основной задачей OpenAI по ходу этого конкурса.
В академической среде направление изучения политик, которые могут быстро адаптироваться к новым условия, называется meta learning, и в последние годы оно активно развивается.
Дополнительно, в отличии от привычных соревнований на kaggle, где весь сабмит сводится к отправке своего файла с ответами, в этом соревновании (да и вообще в RL соревнованиях) от команды требовалось обернуть свое решение в docker-контейнер с заданным API, собрать его и отправить docker образ. Это повышало порог входа в соревнование, однако сделало процесс решений куда более честным – ресурсы и время для docker образа были ограничены, соответственно, слишком тяжелые и/или медленные алгоритмы просто не проходили отбор. Как мне кажется, такой подход к оцениваю является куда более предпочтительным, так как дает возможность исследователям без “домашнего кластера из DGX и AWS” посоревноваться наравне с любителями стеканья 100500 моделей. Надеюсь увидеть больше такого рода соревнований в будущем.
Команда
Колесников Сергей (scitator)
RL enthusiast. На момент соревнования — студент ФИВТ МФТИ, писал и защищал диплом по прошлогоднему конкурсу NIPS: Learning to Run (статью о котором надо бы тоже написать).
Senior Data Scientist @ Dbrain – приносим production-ready конкурсы с докером и ограниченными ресурсами в реальный мир.
Павлов Михаил (fgvbrt)
Старший разработчик-исследователь ДипхакЛаб. Неоднократно участвовал и занимал призовые места в хакатонах и конкурсах по обучению с подкреплением.
Сергеев Илья (sergeevii123)
RL enthusiast. Попал на один из хакатонов по RL от Deephack и все завертелось. Data Scientist @ Avito.ru — computer vision для разных внутренних проектов.
Сорокин Иван (1ytic)
Занимается распознаванием речи в speechpro.ru.
Подходы и решение
После быстрого тестирования предложенных бейзлайнов, наш выбор пал на подход от OpenAI – PPO, как более сформированный и интересный вариант для развития своего решения. К тому же, судя по их статье к этому соревнованию, PPO агент справлялся с задачей немного лучше. Из этой же статьи родились первые улучшения, которые мы использовали в нашем решении, но обо все по порядку:
Совместное обучение PPO на всех доступных уровнях
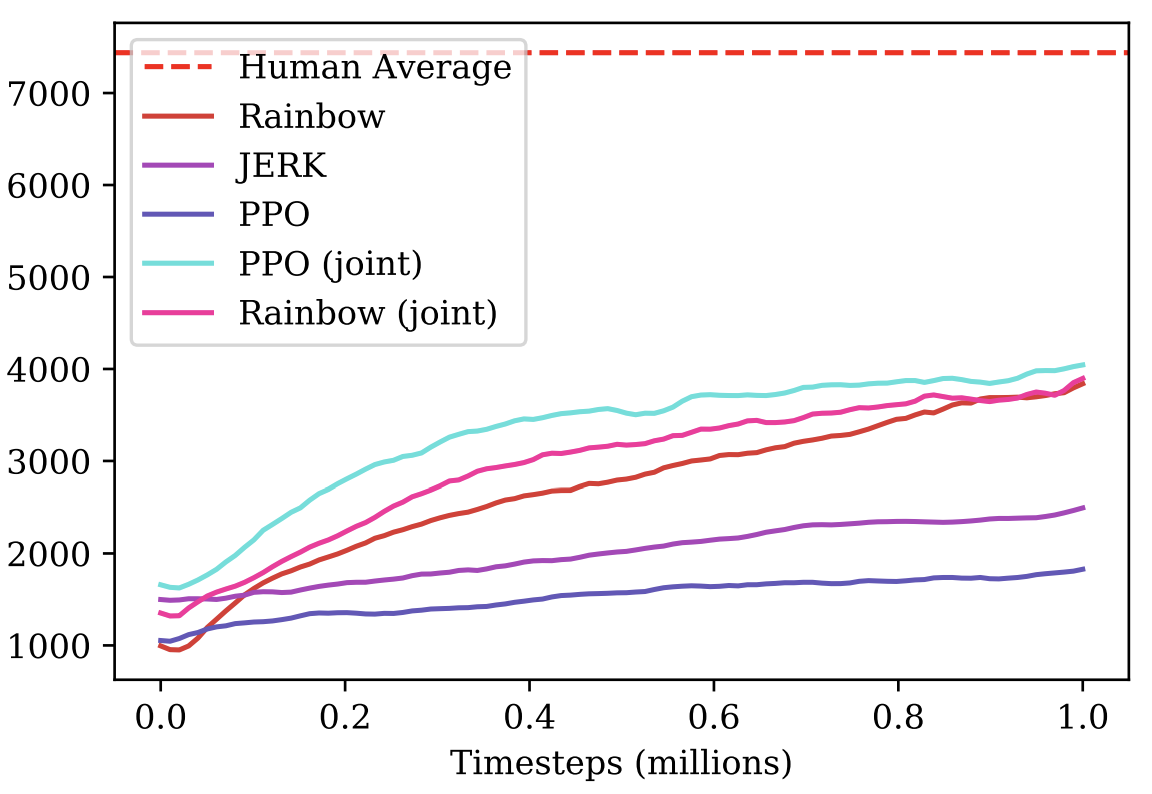
Выложенный бейзлайн обучался только на одном из доступных 27 уровнях Sonic. Однако, с помощью небольших модификаций, обучение возможно было распараллелить сразу на все 27 уровней. Благодаря большему разнообразию при обучении, полученный агент имел куда большую генерализацию и лучшее понимание устройства мира Sonic, а потому справлялся на порядок лучше.
Дообучение в процессе тестирования
Возвращаясь к основной идее соревнования, meta learning, требовалось найти подход, который бы имел максимальную генерализацию и мог легко адаптироваться под новые среды. А для адаптации требовалось дообучать имеющегося агента под тестируемую среду, что, собственно, и было сделано (на каждом тестовом уровне агент делал 1 млн шагов, что было достаточно, чтобы подстроиться под конкретный уровень). По окончании каждой из тестовых игр, агент оценивал полученную награду и оптимизировал свою политику с использованием только что полученной истории. Тут важно отметить, что при таком подходе важно не забыть весь свой прежний опыт и не деградировать под конкретные условия, что, по сути, и является основным интересом meta learning, так как такой агент сразу же теряет всю имеющуюся способность к генерализации.
Exploration bonuses
Углубляясь в условия вознаграждения за уровень – агенту подавали награду за продвижение вперед вдоль x — координаты, соответственно он мог застревать на некоторых уровнях, когда сначала надо было идти вперед, а потом назад. Было решено сделать для агента добавку к награде, так называемую count based exploration, когда агенту давалась небольшая награда, если он попадал в состояние в котором еще не был. Были реализованы 2 типа exploration bonus: на основе картинки и на основе x-координаты агента. Награда на основе картинки считалась следующим образом: для каждой локации пикселя в картинке считалось сколько раз встречалась каждое значение за эпизод, награда была обратно пропорциональна произведению по всем локациям пикселей того сколько раз встречались значения в этих локациях за эпизод. Награда на основе x-координаты считалась похожим образом: для каждой x-координаты (с определенной точностью) считалось сколько раз агент был в этой координате за эпизод, награда обратно пропорционально этому количеству для текущей x-координаты.
Эксперименты с mixup
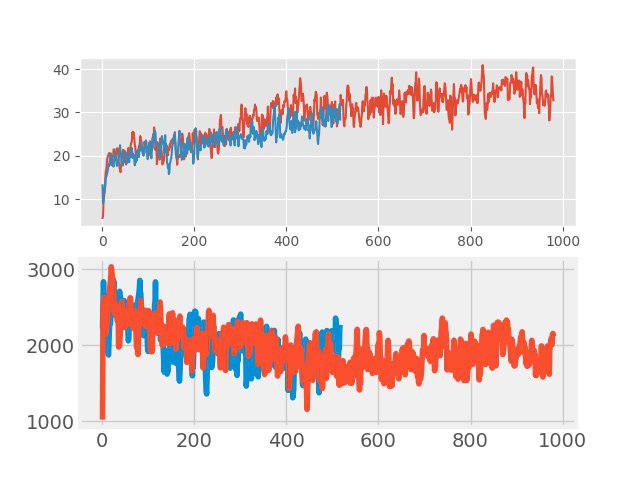
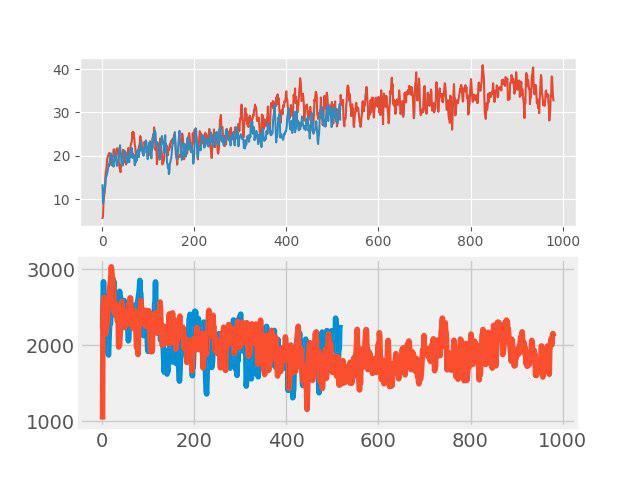
В “обучение с учителем” недавно стал использоваться простой, но эффективный, метод аугментации данных, т.н. mixup. Идея очень простая: делается сложение двух произвольных входных образов и этому новому образу назначается взвешенная сумма соответствующих меток (например, 0.7 dog + 0.3 cat). В таких задачах, как классификация образов и распознавание речи, mixup показывает хорошие результаты. Поэтому было интересно проверить этот метод для RL. Аугментация делалась в каждом большом батче, состоящем из нескольких эпизодов. Входные картинки миксовались по пикселям, а вот с метками все было не так просто. Значения returns, values и neglogpacs смешивались взвешенной суммой, а вот действие (actions) выбиралось от примера с максимальным коэффициентом. Непосредственно ощутимого прироста такое решение не показало (хотя, казалось бы, должен был быть прирост к генерализации), но и не ухудшало baseline. На графиках ниже сравнивается алгоритм PPO с mixup (красный) и без mixup (синий): вверху — награда во время обучения, внизу — длина эпизода.
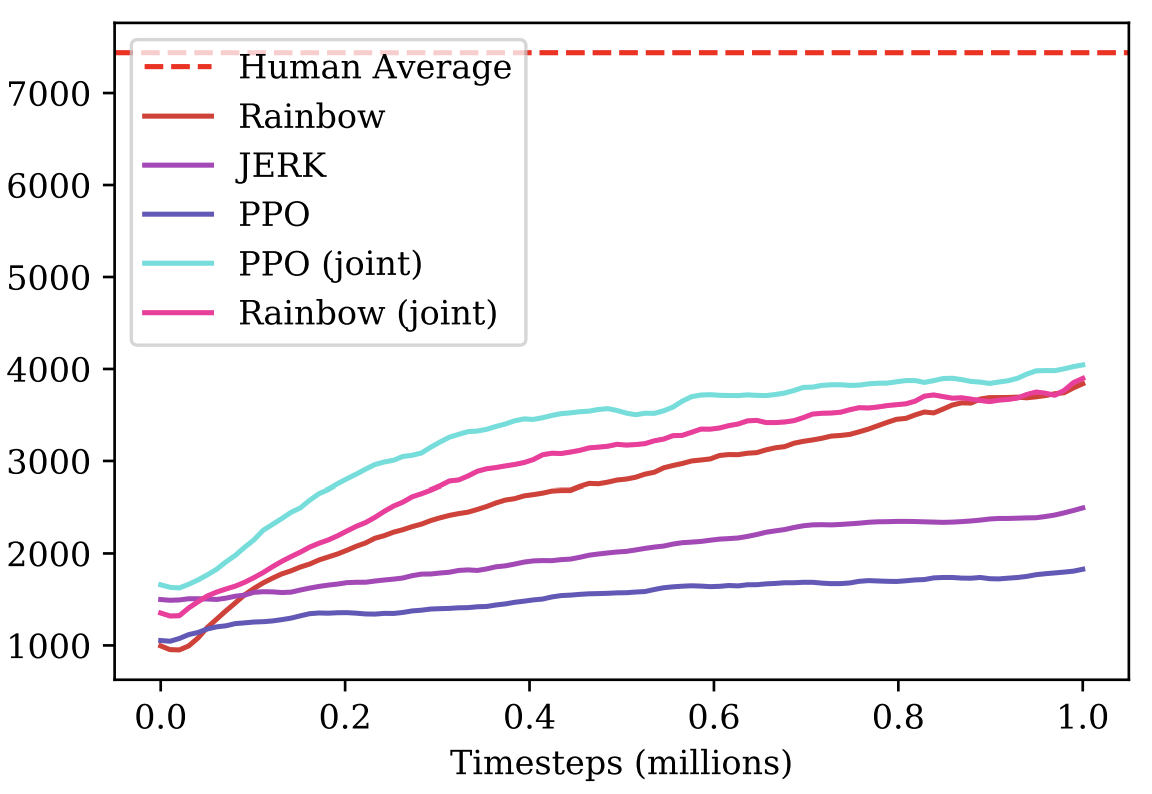
Подбор лучшей начальной политики
Данное улучшение было сделано одним из последних и дало очень существенный вклад в итоговый результат. На тренировочном уровне было обучено несколько разных политик с разными гиперпараметрами. На тестовом уровне первые несколько эпизодов каждая из них тестировалась и для дальнейшего обучения выбиралась та политика, которая давала максимальную тестовую награду за свой эпизод.
Bloopers
А теперь в вопросу о том, что было испробовано, но “не полетело”. В конце концов, это не новая SOTA статья, чтобы что-то скрывать.
- Изменение архитектуры сети: SELU activation, self-attention, SE blocks
- Neuroevolution
- Создание своих уровней Sonic – все подготовили, но банально не хватило времени
- Мета-обучение через MAML и REPTILE
- Ансамблирование нескольких моделей и дообучение в процессе тестирования каждой из моделей с помощью importance sampling
Итоги
По прошествии 3 недель с окончания конкурса OpenAI выложили результаты. На еще 11 дополнительно созданных уровнях наша команда получила почетное 4 место, перепрыгнув с 8го на публичном тесте, и обогнав затюненые бейзлайны от OpenAI.
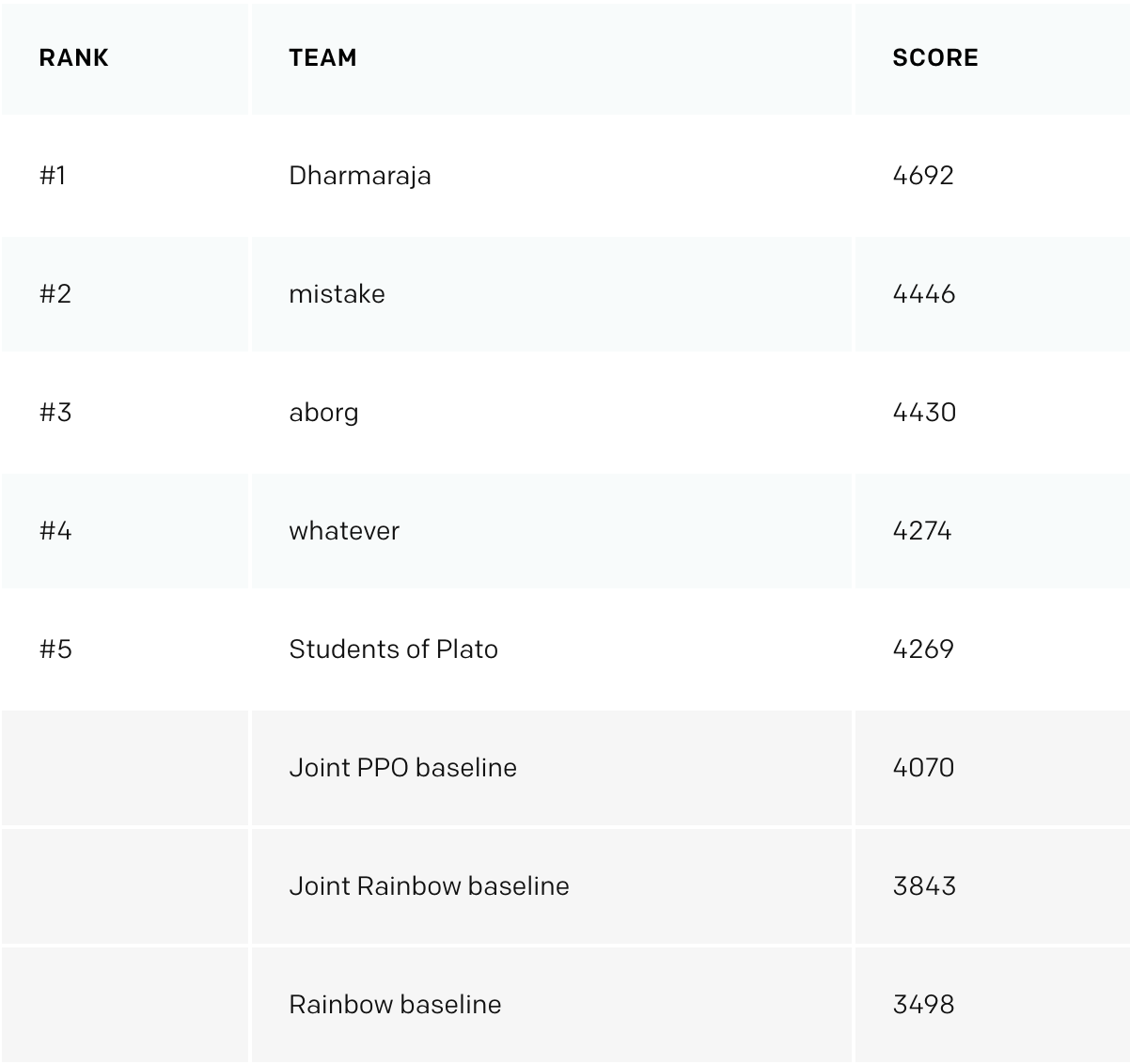
Основные отличительные моменты, которые “полетели” у первой 3ки:
- Доработанная система действий (придумали свои кнопки, убрали лишние);
- Исследование состояний через hash от входной картинки;
- Большее количество обучающих уровней;
Дополнительно хочется отметить, что в этом конкурсе кроме победы активно поощрялось выкладывание описания своих решений, а также материалов, которые помогали другим участникам — за это также была отдельная номинация. Что, опять же, повышало ламповость конкурса.
Послесловие
Лично мне данное соревнование, как и тема meta learning, очень понравилось. За время участия я ознакомился с большим списком статей (некоторые из них я даже не забыл) и узнал огромное количество разных подходов, которые надеюсь применять в будущем.
В лучших традиция участия в соревновании, весь код доступен и выложен на гитхаб.
