
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- Fast Differentiable Sorting and Ranking (Google Brain, 2020)
- MaxUp: A Simple Way to Improve Generalization of Neural Network Training (UT Austin, 2020)
- Deep Nearest Neighbor Anomaly Detection (Jerusalem, Israel, 2020)
- AutoML-Zero: Evolving Machine Learning Algorithms From Scratch (Google, 2020)
- SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training (RheinMain University, Germany, 2019)
- High-Resolution Daytime Translation Without Domain Labels (Samsung AI Center, Moscow, 2020)
- Incremental Few-Shot Object Detection (UK, 2020)
1. Fast Differentiable Sorting and Ranking
Авторы статьи: Mathieu Blondel, Olivier Teboul, Quentin Berthet, Josip Djolonga (Google Brain, 2020)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
Авторы из Google Brain изобрели алгоритм быстрого дифференцируемого ранжирования и сортировки (O(n logn) по времени, O(n) по месту) для использования в end2end обучаемых пайплайнах. Сходу предложили два применения: differentiable Spearman’s rank correlation coefficient and soft least trimmed squares
Сначала проблема сортировки и ранжирования формулируется как проблема оптимизации на задаче сета перестановок (permutations). Чтоб получить непрерывный вид задачи оптимизации, авторы пользуются такой абстракцией из комбинатороики как перестановочный многогранник (permutohedron) (это n-мерный выпуклый многогранник, вложенный в n-мерное евклидово пространство, который является выпуклой оболочкой всех n! точек, получающихся перестановками координат вектора). Вершинами многогранника являются как раз перестановки.

Провели следующие эксперименты:
- Top-k classification loss function
- Label ranking via soft Spearman’s rank correlation coefficient
- Robust regression via soft least trimmed squares
Top-k classification loss function
На датасетах CIFAR-10 и CIFAR-100 и маленьких сеточках (4 Conv2D with 2 max- pooling layers, ReLU activation, 2 fully connected layers with batch norm on each) сравнили свои алгоритмы с существующими аналогами.
Алгоритмы авторов обозначены на графиках как r_Q и r_E. Показали себя лучше или сравнимо с аналогами, но существенно быстрее (nlogn vs n^2)
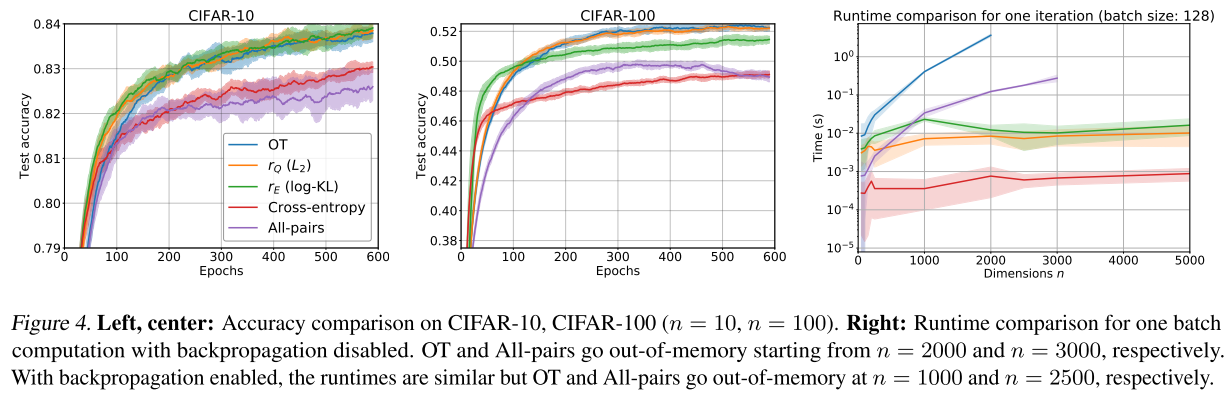
В задаче Label ranking via soft Spearman’s rank correlation coefficient используется коэффициент корреляции Спирмана в предложенной авторами дифференцируемой форме непосредственно как лосс, а в задаче Robust regression via soft least trimmed squares авторы сортируют лоссы и игнорируют топ-k лоссов, чтоб повысить устойчивость к шумным лейблам в задаче регрессии. И там, и там показаны улучшения и т.д. и т.п.
Практический вывод, кажется, такой — теперь есть относительно быстрые реализации дифференцируемого ранжирования и сортировки, можно использовать в пайплайнах.
2. MaxUp: A Simple Way to Improve Generalization of Neural Network Training
Авторы статьи: Chengyue Gong, Tongzheng Ren, Mao Ye, Qiang Liu (UT Austin, 2020)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
Новая техника для улучшения генерализации обучения, которая подняла топ-1 СОТУ на имаджнете с 85.5% до 85.8% (EfficientNet B-8) и показала стабильный прирост на других архитектурах и задачах.
Метод представляет собой некоторую смесь техники аугментаций и адверсериал трейннинга: каждый сэмпл в батче аугментируется m раз, находится один с макс лоссом среди аугментированных вариантов (для каждого сэмпла), и бэкпроп проводится только по ним. То есть минимизируется максимальный лосс (в отличие от среднего лосса, в случае с обычными аугментациями).
В статье приводится теоретическое обоснование с доказательством, что Maxup — это gradient-norm regularization для обычного случая минимизации лосса по всему батчу. Maxup легко имплементится, не добавляет много вычислительной сложности и легко смешивается с остальными способами аугментации.
Авторы проверили качество на обычных ResNet-50 бейзлайнах для имаджнет, а также на других архитектурах. Для CutMix+MaxUp на EfficientNet B-7 авторы получили СОТУ 85.8% топ-1. На остальных бейзлайнах репортят стабильный прирост.

Также показали прирост на двух датасетах NLP — Penn Treebank и WikiText-2.
Дополнительно показали прирост в задаче Adversarial Certification (это когда алгоритм должен обеспечить очень высокую вероятность устойчивости к определённым типам adversarial атак.
В будущем авторы планируют использовать MaxUp на большем количестве моделей (например, BERT), а также прикрутить его к transfer и semi-supervised learning.
3. Deep Nearest Neighbor Anomaly Detection
Авторы статьи: Liron Bergman, Niv Cohen, Yedid Hoshen (Jerusalem, Israel, 2020)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
Использование kNN поверх имаджнет-фичей аутперформит (почти) все SOTA подходы для anomaly detection по картинкам, и особенно хорошо заходит для group anomaly detection.
Авторы предложили следующий простой подход для использования kNN для задачи anomaly detection.
Берём предобученный резнет и экстрактим фичи из картинок по датасету, из фичей получаем таблицу для kNN.
Semi-supervised Anomaly Detection:
- считаем, что все инпут изображения "нормальные";
- на инференсе берём фичи изображения, находим к нему K ближайших с помощью kNN;
- считаем среднюю дистанцию до ближайших соседей, по трешхолду классифицируем аномалия/не аномалия.
Unsupervised Anomaly Detection:
- после экстракции из датасета фичей считаем расстояния для каждого изображения до всех остальных;
- предполагаем, что аномалии ни на что не похожи, и их мало, так что выбрасываем из датасета изображения с максимальными kNN расстояниями (авторы выкидывали до 50%);
- оставшиеся изображения можно с большой уверенностью считать "нормальными", поэтому дальше можно работать по схеме из п.1 (Semi-supervised Anomaly Detection).
Group Image Anomaly Detection:
- задача в том, чтоб определить, является ли сет картинок аномальным (при том, что сами картинки по отдельности могут быть нормальными);
- фичи сета получаются банальным усреднением фичей картинок из сета;
- дальше обычный kNN по этим фичам как в п.1.
Авторы сравнили этот подход на нескольких датасетах, (почти) везде получили заметный прирост (их подход называется DN2 (Deep Nearest-Neighbors)).

Авторы также обнаружили:
- чем глубже резнет, тем лучшие фичи он экстрактит (качество детекции выше в их подходе);
- лучшим числом количества соседей K является число 2.
Для задачи group anomaly detection лучше всего зашло объединение фичей именно через mean (сравнивали ещё через max и concat).
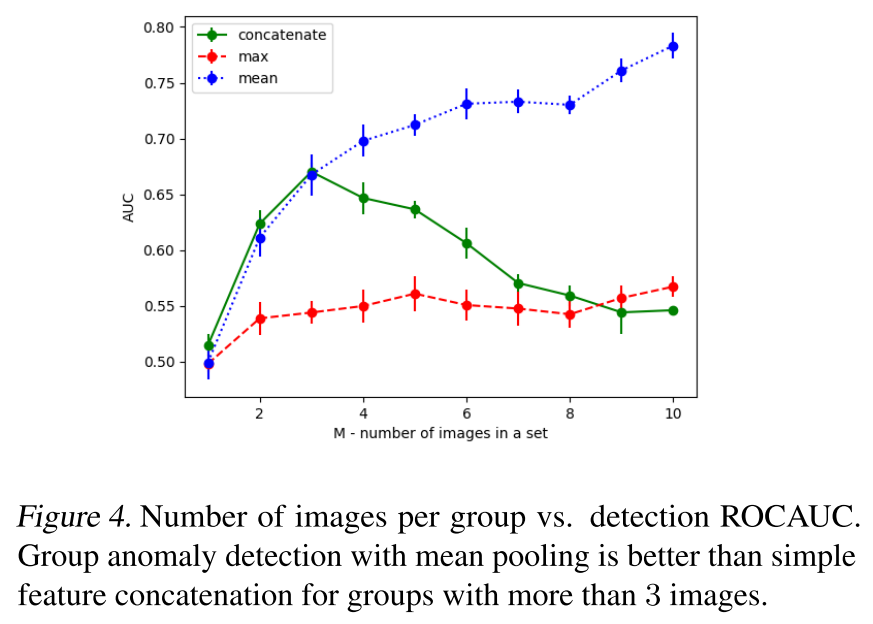
От автора обзора: Думаю, если ещё ResNet предварительно потюнить под целевой домен, да ещё с каким-нибудь angular лоссом, то всё будет работать ещё лучше. Сам давно использую подход "а бахнем-ка kNN поверх резнет-фичей", работает очень хорошо.
4. AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Авторы статьи: Esteban Real, Chen Liang, David R. So, Quoc V. Le (Google, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Ресерчеры гугла сделали следующий шаг в задаче AutoML — определили пространство поиска так, что может быть найдена не только архитектура, но и сам ML — алгоритм: градиентный спуск, релу, нормализация градиентов, усреднение весов, регуляризации и т.п. — используя базовые математические операции как строительные блоки.
Алгоритм ищет программу — последовательность инструкций. Каждая инструкция имеет свою операцию, которая определяет её функцию. Операции были выбраны по критерию "typically learned by high-school level". Намеренно были исключены концепции машин лернинга, декомпозиции матриц и производные.
У алгоритма есть три функции-компонента — Setup, Predict и Learn. Их evaluation состоит из двух циклов обучения и валидации, в цикле процессится не батч, а один сэмпл для простоты.
Поиск программы происходит с помощью эволюционного алгоритма, в ходе которого из популяции отбрасывается самый старый алгоритм, из оставшихся выбирается лучший, а затем копируется и подвергается мутации с помощью одной из операций:
- вставить/удалить случайную инструкцию в случайном месте компонента;
- рандомизировать все инструкции компонента;
- модифицировать один из аргументов инструкции случайным выбором.
В процессе обучения алгоритм учится на CIFAR-10 и иногда на MNIST для регуляризации. Этот подход позволил найти, к примеру, алгоритм обучения двухслойной нейросети через бэкпроп и градиентный спуск.

На следующей схеме показан прогресс эволюции лучшего алгоритма популяции с пометками на некоторых ключевых этапах. Алгоритм заново открыл такие интересные вещи:
- добавлять шум к инпуту, что можно расценивать как регуляризатор;
- совершать билинейные операции;
- нормализовать градиенты (что обычно используется для невыпуклых оптимизаций и помогает с проблемой затухающих и взрывающихся градиентов);
- матрица весов, используемая во время инференса это аккумуляция всех весов после всех шагов обучения, что можно рассматривать как усреднение весов во время обучения, так как у этих двух сэтапов будут одинаковые предикты.
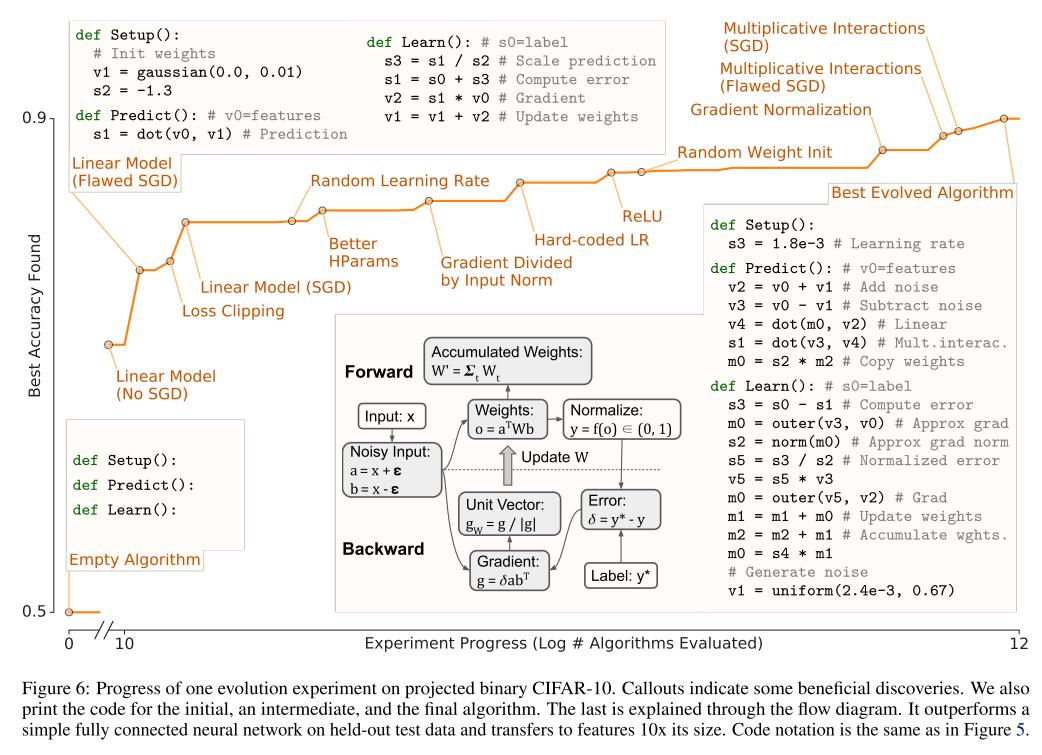
Дальше авторы взяли алгоритм (двухслойная нейросеть) из Figure 5 и инициализировали популяции им, и стали задавать разные челенжи для обучения, чтоб посмотреть, как алгоритм будет адаптироваться:
- Мало обучающих примеров
Алгоритм подобрал операцию, известную как noisy ReLU. - Быстрое обучение / малое количество эпох
Алгоритм подобрал операцию LR decay. - Большое количество классов (все 10 из CIFAR, до этого использовалось 2 для простоты)
Алгоритмы иногда использовали среднее матрицы весов как лернинг рейт. Авторы не смогли это объяснить, но это статистически значимый выбор, который по каким-то причинам хорошо перформит.
Из-за простоты подхода и ограничений пространства поиска, подход авторов, который назвали AutoML-Zero пока не может найти некоторые СОТА-техники, вроде батчнорма или свёртки, но найденные им алгоритмы всё равно впечатляют.
5. SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Авторы статьи: Markus Eberts, Adrian Ulges (RheinMain University, Germany, 2019)
Оригинал статьи :: GitHub project
Автор обзора: Вадим Титко (в слэке Vadbeg)
Модель, которая одновременно решает, как проблему entity recognition, так и relation classification.
Span-based подход предполагает что каждое подмножество токенов – это потенциальная сущность (entity). То есть модель просматривает все возможные подпоследовательности и находит те, которые являются сущностями. Бонусы:
- Было показано, что правильный выбор негативных классов (не являющимися entity) и их количество в предложении сильно бустит точность сетки.
- Локализация контекста (то есть информации, которая описывает нужную сущность) очень важна.
- Лучше использовать полностью pre-trained BERT (зачем он –> дальше).

Подход:
Ядром модели является предобученный BERT. На вход модели подаются byte-pair encoded токены (то есть не treehouse, a tree и house). Это позволяет уменьшить количество токенов в целом. BERT выдаёт n + 1 эмбеддинг (n – длина входного предложения), (n + 1)’ый эмбеддинг содержит контекст всего предложения.Подход ребят заключается в том, что они пытаются найти сущность среди каждой подпоследовательности токенов. Пример: {we, will, rock, you} разобьётся на {we}, {we, will}, {will, rock, you}, и т.д.
Дальше всё происходит в три этапа:
Span classification:
- Выбирается подпоследовательность эмбеддингов (например, s3), они выделены красным. Они проходят через maxpooling.
- Из width embeddings выбирается подходящий по длине. Эти эмбеддинги – это обучающийся параметр. Их смысл в том, чтобы показывать сети: эта последовательность какая-то длинная, вряд ли это сущность.
- Выбранный width embedding и эмбеддинг после maxpooling конкатенируются.
- И дальше конкатенируем (n + 1)’ый эмбеддинг из BERT. Он даёт нам понятие о контексте.
- Дальше пихаем получившийся вектор в softmax classifier. Он выплёвывает нам класс span’а (может выплюнуть None)
Span filtering:
Тут всё просто. Откидываем None spans и те, длина которых больше 10.
Relation classification:
- Из тех сущностей, которые остались, выбираем две. Высовываем из каждой вектор полученный в 1.c
- Если между ними есть слова –> это наш контекст (оранжевый). Прогоняем его через maxpooling. Если контекста нет -> вектор состоящий из одного нуля.
- Конкатенируем всё это (в статье этот пункт чуточку хитрее). Прогоняем через sigmoid-layer classifier. Получаем отношение между сущностями. Ну или None.
В тренировке ничего необычного. Для entity recognition и relation classification свой лосс (берётся средний по бачту). Дальше они просто суммируются. Вопрос был в количестве отрицательных сэмплов на предложение. Сошлись на том, что 100 достаточно.
Также смотрели как лучше выбирать контекст (оранжевый на схеме модели). В итоге для любой длины текста выигрывает локализированный контекст (тоесть тот, который зажат между двумя сущностями).
Ну и о том как лучше поступить с BERT. В итоге лучше всего подходит pretrained BERT (для научных статеек — SciBERT).
Ну и что у них получилось. В итоге SOTA для следующих задач:
- Relation Extraction on CoNLL04;
- Relation Extraction on ADE Corpus ;
- Joint Entity and Relation Extraction on SciERC.
6. High-Resolution Daytime Translation Without Domain Labels
Авторы статьи: Ivan Anokhin, Pavel Solovev, Denis Korzhenkov, Alexey Kharlamov, Taras Khakhulin, Alexey Silvestrov, Sergey Nikolenko, Victor Lempitsky, Gleb Sterkin (Samsung AI Center, Moscow, 2020)
Оригинал статьи :: Video :: Blog
Автор обзора: Денис Корженков (в слэке dkorzhenkov)
HiDT — новая image-to-image модель, позволяющая решать задачу смены стиля изображения без использования разметки во время обучения.
Пример ниже: левый столбец — исходные изображения, столбцы справа — результат трансфера.

Что было раньше
В последние годы img2img translation с помощью ганов последовательно освобождался от ограничений, присущих ранним моделям:
- CycleGAN позволил обучаться на выборке, где не было известно, какие картинки из разных доменов соответствуют друг другу (есть картинки с лошадями и есть картинки с зебрами, ни для одной лошади в обычной выборке не найдется картинки-близнеца с зеброй на том же фоне и в той же позе).
- UNIT ввел понятие единого пространства контентов для изображений из разных доменов (грубо говоря, контент — это “некоторое животное в определенной позе на фоне ландшафта”. Генератор лошадей преобразует это животное в лошадь, а генератор зебр — в зебру).
- MUNIT добавил к единому пространству контентов специфичное для каждого домена пространство стилей (если попросту, возьмем два разных стиля из домена зебр — добавив их к одному и тому же контенту, получим зебр с разными полосками)
- FUNIT унифицировал пространство стиля между всеми доменами. Теперь один и тот же генератор для всех доменов принимает тензор контента, вектор стиля и возвращает результат. То есть возьмем картинку лошади и извлечем контент. Возьмем картинку с зеброй и извлечем стиль. Смешаем эти контент и стиль — получим лошадь с первой картинки в обличии зебры.
Что получилось улучшить?
Всем этим моделям во время обучения нужна разметка доменов (требуется знать, кто на картинке — лошадь, зебра или крокодил). Авторы HiDT избавились от этого ограничения. Правда, не на задаче перерисовке животных, а для того, чтобы научиться по одной пейзажной фотографии создавать статичный таймлапс (то есть время дня меняется, но облака остаются на месте).
Ключом к успеху стало использование во время обучения как стилей, извлеченных из тренировочных изображений, так и просемплированных из априорного распределения — это позволило создать “хорошее пространство”, где также возможны интерполяции между разными стилями. Второй важный компонент — использование дискриминатора, обусловленного на стиль (архитектура — projection discriminator).
Еще одно улучшение, предложенное в статье, это необычная схема повышения разрешения для выхода генеративной модели. Авторы предлагают делать трансфер стиля в низком разрешении для нескольких разных даунсэмпленных версий исходного hi-res изображения, а затем отдельной сеткой собрать эти lo-res выходы в единое изображение наподобие методов из области multiframe image restoration.

Оказалось, что такой подход может пригодиться не только для задачи генерирования таймлапсов. Он также позволяет делать неплохой artistic style transfer.
Пример style transfer: исходные картины — на главной диагонали, oстальные изображения — выходы модели.

7. Incremental Few-Shot Object Detection
Авторы статьи: Juan-Manuel Perez-Rua, Xiatian Zhu, Timothy Hospedales, Tao Xiang (UK, 2020)
Оригинал статьи
Автор обзора: Александр Бельских (в слэке belskikh)
Модификация CentreNet для задачи Incremental Few-Shot Detection (iFSD) (когда новые классы добавляются в модель инкрементально без изменения базовых классов). Получившаяся модель перформит few-shot детекцию на уровне с СОТА-моделями, но не нуждается в дообучении на новые классы при их добавлении + не страдает от катастрофического забывания базовых классов после добавления новых.
За базу взят anchor-box free детектор CentreNet (статья Objects as Points), суть которого в том, что он из Hourglass бэкбоуна (юнетоподобного) достаёт фичи, из которых потом для каждого класса генерятся хитмапы. Из хитмапов регрессятся центры и размеры ббоксов. Этот же подход можно использовать для детекции кейпонитов и 3д позы.
Модификация
Так как хитмапы для каждого класса генерятся с помощью сверточного кернела, авторы решили добавить к модели генератор, который научится генерить веса этого кернела для ранее не виденных классов (обожаю это, нейронка генерит веса для нейронки. Похожее было во Few Shot Vid-to-Vid), а дальше этот кернел будет генерить хитмапы для нового класса со стандартным для этой модели постпроцессингом.
Таким образом, процесс обучения/инференса сетки выглядит примерно так:
- Сначала CentreNet Обучается в обычном режиме на наборе базовых классов.
- Далее берётся сетка генератор, которая повторяет архитектурой энкодер бэкбоуна, и в начале обучения инициализируется весами обученного на предыдущем шаге бэкбоуна.
- Далее набирается какой-то сет изображений для обучения генератора, задача которого — научиться предсказывать кернелы по набору изображений одного класса.
- В процессе обучения генератор предиктит веса кернела, которые используются для создания классового хитмапа. Т.к. у нас есть ground truth веса, полученные на стадии 1, мы можем получить ground truth фичемапы. Лоссом является L1 между хитмапом из сгенерированного кернела и ground truth.
- Далее для добавления на инференс новых классов нужно только получить веса кернела с помощью генератора и предиктить в стандартном режиме.

Авторы сравнились с несколькими СОТА-подходами, добавляя класс по 1, 5 и 10 изображениям. Везде получили сопоставимое либо выше качество + сохранение качества на базовых классах из-за отсутствия катастрофического забывания.
Также их модель очень устойчива по сравнению с аналогами к катастрофическому зыбыванию при инкрементальном добавлении классов.

Еще 7 обзоров статей представлены во 2-ой части.
