Графики, отчеты и аналитика – все это так или иначе присутствует в back-office любого, даже совсем маленького, предприятия. Когда в обычных таблицах в Excel/Numbers/Libre становится уже тесно, но data все еще не очень big, традиционные решения для внутренних потребностей компании часто строятся с помощью реляционных баз данных, таких как PostgreSQL, MySQL или MariaDB.
Эти базы данных бесплатны, благодаря SQL удобно интегрируются с остальными компонентами в системе, они популярны и с ними умеют работать большинство разработчиков и аналитиков. Нагрузку (трафик и объемы) они могут переварить достаточно объемную, чтобы спокойно продержаться до того момента, когда компания сможет позволить себе более сложные (и дорогие) решения для аналитики и отчетов.
Однако даже в многократно изученной технологии всегда существуют разные нюансы, способные внезапно прибавить забот инженерам. Помимо надежности, наиболее часто упоминаемая проблема с базами данных – это их производительность. Очевидно, что с ростом количества данных скорость ответа БД падает, но если это происходит предсказуемо и согласуется с ростом нагрузки, то это не так и плохо. Всегда можно заранее увидеть, когда БД начинает требовать внимания и запланировать апгрейд или переход на принципиально другую БД. Гораздо хуже, если производительность БД деградирует непредсказуемо.
Тема улучшения производительности БД стара как мир и очень обширна, и в этой статье хотелось бы сфокусироваться только на одном направлении. А именно, на оценке эффективности планов запросов в БД PostgreSQL, а также изменению этой эффективности во времени, чтобы сделать поведение планировщика БД более предсказуемым.
Несмотря на то, что многие вещи о которых пойдет речь применимы ко всем недавним версиям этой БД, в примерах ниже подразумевается версия 11.2, последняя на текущий момент.
Перед тем, как мы погрузимся в подробности, имеет смысл сделать лирическое отступление и сказать пару слов о том, откуда вообще могут браться проблемы с производительностью в реляционных БД. Чем же именно занята БД, когда она «тормозит»? Нехватка памяти (большое количество обращений к диску или сети), слабый процессор, это все очевидные проблемы с понятными решениями, но что еще может влиять на скорость выполнения запроса?
Для того, чтобы БД ответила на SQL-запрос, ей необходимо построить план запроса (в какие таблицы и колонки посмотреть, какие индексы понадобятся, что оттуда забрать, что с чем сравнить, сколько потребуется памяти и так далее). План этот формируется в виде дерева, узлами в котором являются всего несколько типовых операций, с разной вычислительной сложностью. Вот несколько из них, для примера (N – число строк с которыми нужно провести операцию):
Как можно понять, затратность запроса очень сильно зависит от того, как расположены данные в таблицах и как этот порядок соответствует используемым операциям хэширования. Nested Loop, несмотря на его затратность в O(N2) может быть выгоднее Hash Join или Merge Join когда одна из соединяемых таблиц вырождается до одной-нескольких строк.
Кроме ресурсов CPU, затратность включает в себя и использование памяти. И то, и другое – ограниченный ресурс, поэтому планировщику запросов приходится искать компромисс. Если две таблицы математически выгоднее соединить через Hash Join, но в памяти просто нет места под такую большую хэш-таблицу, БД может быть вынуждена использовать Merge Join, например. А «медленный» Nested Loop вообще не требует дополнительной памяти и готов выдавать результаты прямо сразу после запуска.
Относительную затратность этих операций нагляднее показать на графике. Здесь не абсолютные цифры, просто примерное отношение разных операций.

График Nested Loop «стартует» ниже, т.к. для него не требуется ни дополнительных вычислений, ни выделения памяти или копирования промежуточных данных, но у него затратность O(N2). У Merge Join и Hash Join начальная затратность выше, однако после некоторых величин N они начинают выигрывать во времени у Nested Loop. Планировщик старается выбрать план с наименьшими затратами и на графике выше придерживается разных операций при разном N (зеленая пунктирная стрелка). При числе строк до N1 выгоднее использовать Nested Loop, от N1 до N2 выгоднее Merge Join, далее после N2 выгоднее становится Hash Join, однако Hash Join требует памяти для создания хэш-таблиц. И при достижении N3 этой памяти становится недостаточно, что приводит к вынужденному использованию Merge Join.
При выборе плана планировщик оценивает затратность каждой операции в плане с помощью набора относительной затратности некоторых «атомарных» операций в БД. Как, например, вычисления, сравнения, загрузка страницы в память, и т.п. Вот список некоторых таких параметров из конфигурации по умолчанию, их не так много:
Правда, одних только этих констант мало, нужно еще знать то самое «N», то есть, сколько же именно строк из предыдущих результатов придется обработать в каждой такой операции. Верхняя граница тут очевидна – БД «знает» сколько данных в любой таблице и всегда может посчитать «по-максимуму». К примеру, если у вас две таблицы по 100 строк, то их соединение может дать от 0 до 10000 строк на выходе. Соответственно, у следующей операции на входе может быть до 10000 строк.
Но если знать хоть немного о природе данных в таблицах, это число строк можно предсказать более точно. Например, для двух таблиц по 100 строк из примера выше, если вы заранее знаете, что объединение даст не 10 тысяч строк, а те же 100, предполагаемая затратность следующей операции сильно сокращается. В этом случае данный план мог бы стать эффективнее других.
Для того чтобы у планировщика была возможность более точно предсказывать размер промежуточных результатов, в PostgreSQL используется сбор статистики по таблицам, которая копится в pg_statistic, или в ее более удобочитаемом варианте – в pg_stats. Обновляется она автоматически при запуске vacuum, либо явно при команде ANALYZE. В этой таблице хранится разнообразная информация о том, какие данные и какой природы имеются в таблицах. В частности, гистограммы значений, процент пустых полей и другая информация. Все это планировщик использует, чтобы более точно спрогнозировать объемы данных для каждой операции в дереве плана, и, таким образом, более точно посчитать затратность операций и плана в целом.
Возьмем, например, запрос:
Предположим, что гистограмма значений в колонке «t1.a» выявила, что значения, большие 100 встречаются в примерно 1% строк таблицы. Тогда можно предсказать, что такая выборка вернет около сотой доли всех строк из таблицы «t1».
БД дает возможность посмотреть на прогнозируемую затратность плана через команду EXPLAIN, а фактическое время его работы — с помощью EXPLAIN ANALYZE.
Вроде бы с автоматической статистикой теперь все должно быть хорошо, но и тут могут быть сложности. Об этом есть хорошая статья от компании Citus Data, с примером неэффективности автоматической статистики и о сборе дополнительной статистики с помощью CREATE STATISTICS (доступна с PG 10.0).
Итак, для планировщика существуют два источника ошибок в вычислении затратности:
В сложных запросах составление и прогнозирование всех возможных планов может само по себе занять массу времени. Что толку вернуть данные за 1 секунду, если БД только планировала запрос минуту? В PostgreSQL есть для такой ситуации Geqo optimizer, это планировщик, который строит не все возможные варианты планов, а начинает с нескольких случайных и достраивает наилучшие, прогнозируя пути снижения затратности. Все это тоже не улучшает точность прогноза, хотя и ускоряет нахождение хоть какого-нибудь более-менее оптимального плана.
Если все складывается удачно, ваш запрос отрабатывает максимально быстро. С ростом количества данных скорость выполнения запросов в БД постепенно увеличивается, и через некоторое время, наблюдая за ней, можно примерно предсказать, когда потребуется увеличить память или число ядер CPU или расширить кластер и т.п.
Но нужно учитывать то, что у оптимального плана существую конкуренты с близкой затратностью на выполнение, которых мы не видим. И если БД внезапно меняет план запроса на другой, это становится сюрпризом. Хорошо, если БД «перескочит» на более эффективный план. А если нет? Посмотрим, например, на картинку. Это прогнозируемая затратность и реальное время выполнения двух планов (красного и зеленого):
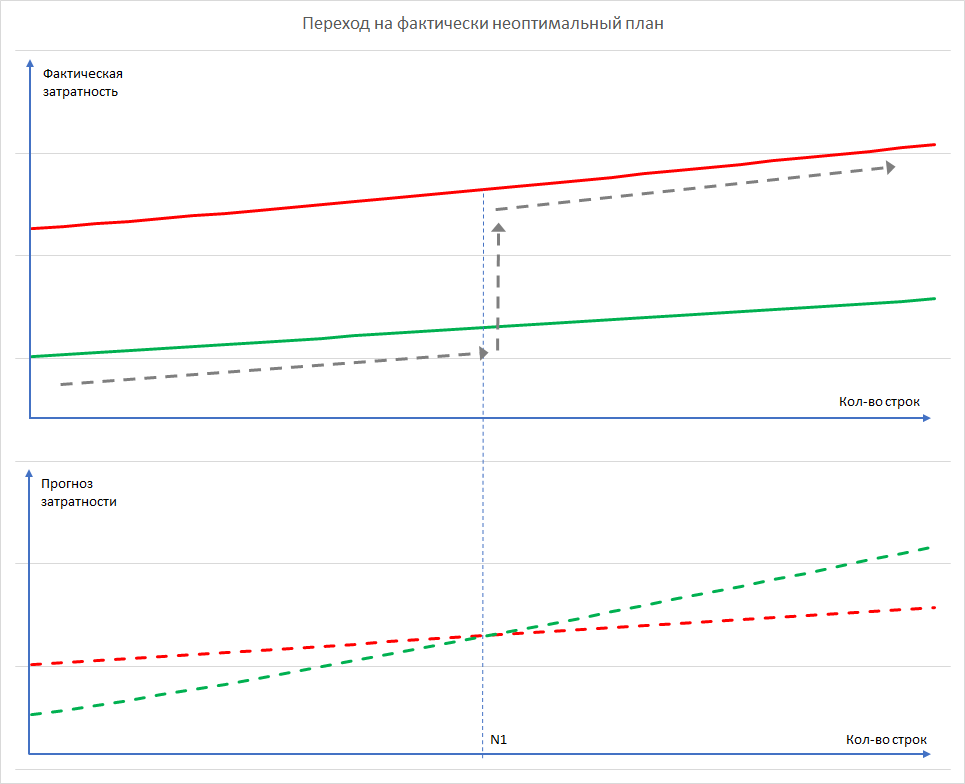
Здесь зеленым изображен один план и красным – его ближайший «конкурент». Пунктиром изображен график прогнозируемой затратности, сплошной линией – реальное время. Серой пунктирной стрелкой изображен выбор планировщика.
Предположим, что в один прекрасный вечер пятницы прогнозируемое число строк в некоторой промежуточной операции достигает N1 и «красный» прогноз начинает выигрывать у «зеленого». Планировщик начинает использовать его. Фактическое же время выполнения запросов сразу подскакивает (переход с зеленой сплошной линии на красную), то есть график деградации БД принимает вид ступеньки (а может и «стены»). На практике такая «стена» может увеличить время выполнения запроса на порядок и больше.
Стоит отметить, что такая ситуация, вероятно, более типична для бэкофиса и аналитики, чем для фронтенда, поскольку последний обычно приспособлен к большему количеству одновременных запросов и, следовательно, использует более простые запросы в БД, где и ошибка в прогнозах плана меньше. Если же это БД для построения отчетности или аналитики, запросы могут быть произвольно сложными.
Возникает вопрос, а можно ли как-нибудь было предвидеть такие вот «подводные» невидимые планы? Ведь проблема даже не в том, что они не оптимальны, а в том, что переключение на другой план может произойти непредсказуемо, и, по закону подлости, в самый неудачный для этого момент.
Напрямую, к сожалению, их не увидеть, но можно поискать альтернативные планы путем изменения собственно весов, по которым они выбираются. Смысл такого подхода в том, чтобы убрать из поля зрения текущий план, который планировщик считает оптимальным, чтобы оптимальным стал какой-нибудь из ближайших его конкурентов, и, таким образом, его можно было бы увидеть через команду EXPLAIN. Периодически проверяя изменения затратности в таких «конкурентах» и в основном плане можно оценить вероятность того, что БД скоро «перескочит» на другой план.
Кроме сбора данных о прогнозах альтернативных планов можно их запускать и измерять их производительность, что также дает представление о внутреннем «самочувствии» БД.
Давайте посмотрим, какие средства у нас есть для таких экспериментов.
Во-первых, можно прямо «запрещать» конкретные операции с помощью переменных сессии. Удобно то, что их не надо менять в конфиге и перезагружать БД, их значение меняется только в текущей открытой сессии и не влияет на остальные сессии, так что можно экспериментировать прямо на реальных данных. Вот их список со значениями по умолчанию. Почти все операции включены:
Запрещая или разрешая отдельные операции, мы заставляем планировщик выбирать другие планы, которые мы можем увидеть все той же командой EXPLAIN. На самом деле, «запрет» операций не запрещает их использование, а просто сильно увеличивает их затратность. В PostgreSQL каждой «запрещенной» операции автоматически «накидывается» затратность равная 10 миллиардам условных единиц. При этом в EXPLAIN суммарные веса плана могут получиться запредельно высокими, но на фоне этих десятков миллиардов вес остальных операций хорошо просматривается, так как он обычно укладывается в меньшие порядки.
Особого интереса заслуживают две операции из перечисленных:
Например, возьмем некоторые реальные цифры из запросов, оптимизацией которых мы занимались в нашей компании.
План 1. Со всеми разрешенными операциями суммарная затратность наиболее оптимального плана составляла 274962.09 единиц.
План 2. С «запрещенным» nested loop затратность выросла до 40000534153.85. Вот эти 40 миллиардов, составляющие основную часть затратности – это 4 раза использованный Nested Loop, несмотря на запрет. А оставшиеся 534153.85 – это как раз и есть прогноз затратности всех остальных операций в плане. Он, как мы видим, примерно в 2 раза превышает затратность оптимального плана, то есть достаточно близок к нему.
План 3. С «запрещенным» Hash Join затратность составила 383253.77. План был действительно составлен без использования операции Hash Join, так как мы не видим никаких миллиардов. Затратность его, тем не менее, на 30% выше, чем у оптимального, что тоже очень близко.
В реальности же времена выполнения запросов были такие:
План 1 (все операции разрешены) выполнился за ~ 9 минут.
План 2 (с «запрещенным» nested loop) выполнился за 1.5 секунды.
План 3 (с «запрещенным» hash join) выполнился за ~ 5 минут.
Причина, как можно заметить, в ошибочном прогнозе затратности Nested Loop. И действительно, при сравнении EXPLAIN c EXPLAIN ANALYZE в нем обнаруживается ошибка с определением того самого злосчастного N на промежуточной операции. Вместо прогнозируемой одной строки Nested Loop встретился с несколькими тысячами строк, из-за чего время выполнения запроса выросло на пару порядков.
Экономия с «запрещенным» Hash Join связана с заменой хэширования на сортировку и Merge Join, который отработал в данном случае быстрее чем Hash Join. Заметим, что этот план 2 в реальности почти в два раза быстрее «оптимального» плана 1. Хотя прогнозировалось, что он будет медленнее.
На практике, если ваш запрос внезапно (после апгдейда БД или просто сам собой) стал выполняться значительно дольше чем до этого, попробуйте для начала запретить либо Hash Join либо Nested Loop и посмотреть, как это влияет на скорость выполнения запроса. В удачном случае вам удастся хотя бы запретить новый неоптимальный план, и, вернуться к предыдущему, быстрому.
Для того чтобы это сделать не нужно изменять конфигурационные файлы PostgreSQL с рестартом базы, достаточно просто в любой консоли изменить значение нужной переменной на время открытой сессии с БД. Остальные сессии не будут затронуты, конфигурация изменится только для вашей текущей сессии. Например, так:
Второе средство повлиять на выбор плана – это изменение собственно весов низкоуровневых операций. Здесь универсального рецепта нет, но, к примеру, если у вас БД с «разогретым» кэшем и данные целиком помещаются в памяти, вполне вероятно, что затратность последовательной подгрузки страницы не отличается от затратности подгрузки случайной страницы. Тогда как в конфиге по умолчанию случайная в 4 раза более затратна чем последовательная.
Или, другой пример, условная затратность запуска параллельной обработки равна по умолчанию 1000, тогда как затратность подгрузки страницы 1.0. Начинать имеет смысл с изменения только одного из параметров за раз, чтобы определить влияет ли именно он на выбор плана. Самые простые способы – это для начала выставить параметр в 0 или в какое-нибудь высокое значение (1 миллион).
Однако нужно помнить, что, улучшив производительность в одном запросе вы можете ухудшить ее в другом. В общем, тут широкое поле для экспериментов. Лучше пробовать менять их по одному, по очереди.
Рассказ про планировщик был бы неполным без упоминания, как минимум, двух расширений PostgreSQL.
Первое – это SR_PLAN, для сохранения рассчитанного плана и принудительного использования его в дальнейшем. Это помогает сделать поведение БД более предсказуемым в смысле выбора плана.
Второе – Adaptive Query Optimizer, которое реализует обратную связь планировщику от реального времени выполнения запроса, то есть планировщик измеряет фактические результаты выполненного запроса и корректирует свои планы в будущем с учетом этого. БД таким образом, «самонастраивается» для конкретных данных и запросов.
Теперь, когда с планированием запросов мы более или менее разобрались, посмотрим, что еще можно улучшить как в самой БД, так и в приложениях, которые ее используют, чтобы получить максимум производительности от нее.
Предположим, что план запроса уже оптимален. Если исключить самые очевидные проблемы (мало памяти или медленный диск/сеть), то остаются еще затраты на расчет хэшей. Здесь, вероятно, кроются великие возможности для будущего улучшения PostgreSQL (с помощью GPU или даже SSE2/SSE3/AVX инструкций CPU), однако пока этого нет и вычисления хэшей почти не используют аппаратные возможности «железа». В этом базе данных можно немного помочь.
Если вы обратили внимание, по умолчанию индексы в PostgreSQL создаются как b-tree. Их полезность в том, что они достаточно универсальны. Такой индекс можно использовать и с условиями равенства, и с условиями сравнения (больше или меньше). Поиск элемента в таком индексе – это логарифмическая затратность. Но если ваш запрос содержит только условие равенства, индексы можно создавать еще и как hash index, затратность поиска в котором — константа.
Далее, еще можно попытаться изменить запрос так чтобы использовать параллельное его выполнение. Чтобы понять, как именно его переписать, лучше всего ознакомиться со списком случаев, когда параллелизм автоматически запрещается планировщиком и избегать таких ситуаций. Руководство на эту тему достаточно кратко описывает все ситуации, поэтому нет смысла повторять их здесь.
Что же делать, если запрос все же плохо получается сделать параллельным? Весьма грустно наблюдать, как в вашей мощной многоядерной БД, где вы единственный клиент, одно ядро занято на 100%, а все остальные ядра просто на это смотрят. В этом случае приходится помогать базе со стороны приложения. Поскольку каждой сессии назначается свое ядро, можно открыть их несколько и поделить общий запрос на части, делая более короткие и более быстрые выборки, объединяя их в общий результат уже в приложении. Это позволит занять максимум доступных ресурсов CPU в БД PostgreSQL.
В заключение хотелось бы отметить, что перечисленные возможности диагностики и оптимизации – это всего лишь верхушка айсберга, однако они достаточно просты в использовании и могут помочь быстро идентифицировать проблему прямо на рабочих данных без риска испортить конфиг или нарушить работу других приложений.
Удачных вам запросов, с точными и короткими планами.
Эти базы данных бесплатны, благодаря SQL удобно интегрируются с остальными компонентами в системе, они популярны и с ними умеют работать большинство разработчиков и аналитиков. Нагрузку (трафик и объемы) они могут переварить достаточно объемную, чтобы спокойно продержаться до того момента, когда компания сможет позволить себе более сложные (и дорогие) решения для аналитики и отчетов.
Исходная позиция
Однако даже в многократно изученной технологии всегда существуют разные нюансы, способные внезапно прибавить забот инженерам. Помимо надежности, наиболее часто упоминаемая проблема с базами данных – это их производительность. Очевидно, что с ростом количества данных скорость ответа БД падает, но если это происходит предсказуемо и согласуется с ростом нагрузки, то это не так и плохо. Всегда можно заранее увидеть, когда БД начинает требовать внимания и запланировать апгрейд или переход на принципиально другую БД. Гораздо хуже, если производительность БД деградирует непредсказуемо.
Тема улучшения производительности БД стара как мир и очень обширна, и в этой статье хотелось бы сфокусироваться только на одном направлении. А именно, на оценке эффективности планов запросов в БД PostgreSQL, а также изменению этой эффективности во времени, чтобы сделать поведение планировщика БД более предсказуемым.
Несмотря на то, что многие вещи о которых пойдет речь применимы ко всем недавним версиям этой БД, в примерах ниже подразумевается версия 11.2, последняя на текущий момент.
Перед тем, как мы погрузимся в подробности, имеет смысл сделать лирическое отступление и сказать пару слов о том, откуда вообще могут браться проблемы с производительностью в реляционных БД. Чем же именно занята БД, когда она «тормозит»? Нехватка памяти (большое количество обращений к диску или сети), слабый процессор, это все очевидные проблемы с понятными решениями, но что еще может влиять на скорость выполнения запроса?
Освежим воспоминания
Для того, чтобы БД ответила на SQL-запрос, ей необходимо построить план запроса (в какие таблицы и колонки посмотреть, какие индексы понадобятся, что оттуда забрать, что с чем сравнить, сколько потребуется памяти и так далее). План этот формируется в виде дерева, узлами в котором являются всего несколько типовых операций, с разной вычислительной сложностью. Вот несколько из них, для примера (N – число строк с которыми нужно провести операцию):
| Что выполняется | Затратность | |
|---|---|---|
| Операции выборки данных SELECT … WHERE … | ||
| Загружаем каждую строку из таблицы и проверяем условие. | O(N) | |
(b-tree index) |
Данные есть прямо в индексе, поэтому ищем по условию нужные элементы индекса и берем данные оттуда. | O(log(N)), поиск элемента в отсортированном дереве. |
(hash index) |
Данные есть прямо в индексе, поэтому ищем по условию нужные элементы индекса и берем данные оттуда. | O(1), поиск элемента в хэш-таблице, без учета затратности создания хэшей |
| Bitmap Heap Scan | Выбираем номера нужных строк по индексу, затем загружаем только нужные строки и проводим с ними дополнительные проверки. | Index Scan + Seq Scan (M), Где M – число найденных строк после Index Scan. Предполагается что M << N, т.е. индекс полезнее чем Seq Scan. |
| Операции соединения (JOIN, SELECT из нескольких таблиц) | ||
| Nested Loop | Для каждой строки из левой таблицы ищем подходящую строку в правой таблице. | O(N2). Но если одна из таблиц значительно меньше другой (словарь) и практически не растет со временем, то фактическая затратность может снизиться до O(N). |
| Hash Join | Для каждой строки из левой и правой таблицы считаем хэш, за счет чего уменьшается число переборов возможных вариантов соединения. | O(N), но в случае очень неэффективной функции хэша или большого количества одинаковых полей для соединения может быть и O(N2) |
| Merge Join | Сортируем по условию левую и правую таблицы, после чего объединяем два отсортированных списка | O(N*log(N)) Затраты на сортировку + проход по списку. |
| Операции агрегации (GROUP BY, DISTINCT) | ||
| Group Aggregate | Сортируем таблицу по условию агрегации и потом в отсортированном списке группируем соседние строки. | O(N*log(N)) |
| Hash Aggregate | Считаем хэш для условия агрегации, для каждой строки. Для строк с одинаковым hash проводим агрегацию. | O(N) |
Как можно понять, затратность запроса очень сильно зависит от того, как расположены данные в таблицах и как этот порядок соответствует используемым операциям хэширования. Nested Loop, несмотря на его затратность в O(N2) может быть выгоднее Hash Join или Merge Join когда одна из соединяемых таблиц вырождается до одной-нескольких строк.
Кроме ресурсов CPU, затратность включает в себя и использование памяти. И то, и другое – ограниченный ресурс, поэтому планировщику запросов приходится искать компромисс. Если две таблицы математически выгоднее соединить через Hash Join, но в памяти просто нет места под такую большую хэш-таблицу, БД может быть вынуждена использовать Merge Join, например. А «медленный» Nested Loop вообще не требует дополнительной памяти и готов выдавать результаты прямо сразу после запуска.
Относительную затратность этих операций нагляднее показать на графике. Здесь не абсолютные цифры, просто примерное отношение разных операций.

График Nested Loop «стартует» ниже, т.к. для него не требуется ни дополнительных вычислений, ни выделения памяти или копирования промежуточных данных, но у него затратность O(N2). У Merge Join и Hash Join начальная затратность выше, однако после некоторых величин N они начинают выигрывать во времени у Nested Loop. Планировщик старается выбрать план с наименьшими затратами и на графике выше придерживается разных операций при разном N (зеленая пунктирная стрелка). При числе строк до N1 выгоднее использовать Nested Loop, от N1 до N2 выгоднее Merge Join, далее после N2 выгоднее становится Hash Join, однако Hash Join требует памяти для создания хэш-таблиц. И при достижении N3 этой памяти становится недостаточно, что приводит к вынужденному использованию Merge Join.
При выборе плана планировщик оценивает затратность каждой операции в плане с помощью набора относительной затратности некоторых «атомарных» операций в БД. Как, например, вычисления, сравнения, загрузка страницы в память, и т.п. Вот список некоторых таких параметров из конфигурации по умолчанию, их не так много:
| Константа относительной затратности | Значение по умолчанию |
|---|---|
| seq_page_cost | 1.0 |
| random_page_cost | 4.0 |
| cpu_tuple_cost | 0.01 |
| cpu_index_tuple_cost | 0.005 |
| cpu_operator_cost | 0.0025 |
| parallel_tuple_cost | 0.1 |
| parallel_setup_cost | 1000.0 |
Правда, одних только этих констант мало, нужно еще знать то самое «N», то есть, сколько же именно строк из предыдущих результатов придется обработать в каждой такой операции. Верхняя граница тут очевидна – БД «знает» сколько данных в любой таблице и всегда может посчитать «по-максимуму». К примеру, если у вас две таблицы по 100 строк, то их соединение может дать от 0 до 10000 строк на выходе. Соответственно, у следующей операции на входе может быть до 10000 строк.
Но если знать хоть немного о природе данных в таблицах, это число строк можно предсказать более точно. Например, для двух таблиц по 100 строк из примера выше, если вы заранее знаете, что объединение даст не 10 тысяч строк, а те же 100, предполагаемая затратность следующей операции сильно сокращается. В этом случае данный план мог бы стать эффективнее других.
Оптимизация плана «из коробки»
Для того чтобы у планировщика была возможность более точно предсказывать размер промежуточных результатов, в PostgreSQL используется сбор статистики по таблицам, которая копится в pg_statistic, или в ее более удобочитаемом варианте – в pg_stats. Обновляется она автоматически при запуске vacuum, либо явно при команде ANALYZE. В этой таблице хранится разнообразная информация о том, какие данные и какой природы имеются в таблицах. В частности, гистограммы значений, процент пустых полей и другая информация. Все это планировщик использует, чтобы более точно спрогнозировать объемы данных для каждой операции в дереве плана, и, таким образом, более точно посчитать затратность операций и плана в целом.
Возьмем, например, запрос:
SELECT t1.important_value FROM t1 WHERE t1.a > 100Предположим, что гистограмма значений в колонке «t1.a» выявила, что значения, большие 100 встречаются в примерно 1% строк таблицы. Тогда можно предсказать, что такая выборка вернет около сотой доли всех строк из таблицы «t1».
БД дает возможность посмотреть на прогнозируемую затратность плана через команду EXPLAIN, а фактическое время его работы — с помощью EXPLAIN ANALYZE.
Вроде бы с автоматической статистикой теперь все должно быть хорошо, но и тут могут быть сложности. Об этом есть хорошая статья от компании Citus Data, с примером неэффективности автоматической статистики и о сборе дополнительной статистики с помощью CREATE STATISTICS (доступна с PG 10.0).
Итак, для планировщика существуют два источника ошибок в вычислении затратности:
- Относительная затратность примитивных операций (seq_page_cost, cpu_operator_cost, и так далее) по умолчанию могут сильно отличаться от реальности (cpu cost 0.01, srq page load cost – 1 или 4 для random page load). Далеко не факт, что 100 сравнений будут равны 1 загрузке страницы.
- Ошибка с прогнозом числа строк в промежуточных операциях. Фактическая затратность операции в таком случае может сильно отличаться от прогноза.
В сложных запросах составление и прогнозирование всех возможных планов может само по себе занять массу времени. Что толку вернуть данные за 1 секунду, если БД только планировала запрос минуту? В PostgreSQL есть для такой ситуации Geqo optimizer, это планировщик, который строит не все возможные варианты планов, а начинает с нескольких случайных и достраивает наилучшие, прогнозируя пути снижения затратности. Все это тоже не улучшает точность прогноза, хотя и ускоряет нахождение хоть какого-нибудь более-менее оптимального плана.
Внезапные планы — конкуренты
Если все складывается удачно, ваш запрос отрабатывает максимально быстро. С ростом количества данных скорость выполнения запросов в БД постепенно увеличивается, и через некоторое время, наблюдая за ней, можно примерно предсказать, когда потребуется увеличить память или число ядер CPU или расширить кластер и т.п.
Но нужно учитывать то, что у оптимального плана существую конкуренты с близкой затратностью на выполнение, которых мы не видим. И если БД внезапно меняет план запроса на другой, это становится сюрпризом. Хорошо, если БД «перескочит» на более эффективный план. А если нет? Посмотрим, например, на картинку. Это прогнозируемая затратность и реальное время выполнения двух планов (красного и зеленого):

Здесь зеленым изображен один план и красным – его ближайший «конкурент». Пунктиром изображен график прогнозируемой затратности, сплошной линией – реальное время. Серой пунктирной стрелкой изображен выбор планировщика.
Предположим, что в один прекрасный вечер пятницы прогнозируемое число строк в некоторой промежуточной операции достигает N1 и «красный» прогноз начинает выигрывать у «зеленого». Планировщик начинает использовать его. Фактическое же время выполнения запросов сразу подскакивает (переход с зеленой сплошной линии на красную), то есть график деградации БД принимает вид ступеньки (а может и «стены»). На практике такая «стена» может увеличить время выполнения запроса на порядок и больше.
Стоит отметить, что такая ситуация, вероятно, более типична для бэкофиса и аналитики, чем для фронтенда, поскольку последний обычно приспособлен к большему количеству одновременных запросов и, следовательно, использует более простые запросы в БД, где и ошибка в прогнозах плана меньше. Если же это БД для построения отчетности или аналитики, запросы могут быть произвольно сложными.
Как же с этим жить?
Возникает вопрос, а можно ли как-нибудь было предвидеть такие вот «подводные» невидимые планы? Ведь проблема даже не в том, что они не оптимальны, а в том, что переключение на другой план может произойти непредсказуемо, и, по закону подлости, в самый неудачный для этого момент.
Напрямую, к сожалению, их не увидеть, но можно поискать альтернативные планы путем изменения собственно весов, по которым они выбираются. Смысл такого подхода в том, чтобы убрать из поля зрения текущий план, который планировщик считает оптимальным, чтобы оптимальным стал какой-нибудь из ближайших его конкурентов, и, таким образом, его можно было бы увидеть через команду EXPLAIN. Периодически проверяя изменения затратности в таких «конкурентах» и в основном плане можно оценить вероятность того, что БД скоро «перескочит» на другой план.
Кроме сбора данных о прогнозах альтернативных планов можно их запускать и измерять их производительность, что также дает представление о внутреннем «самочувствии» БД.
Давайте посмотрим, какие средства у нас есть для таких экспериментов.
Во-первых, можно прямо «запрещать» конкретные операции с помощью переменных сессии. Удобно то, что их не надо менять в конфиге и перезагружать БД, их значение меняется только в текущей открытой сессии и не влияет на остальные сессии, так что можно экспериментировать прямо на реальных данных. Вот их список со значениями по умолчанию. Почти все операции включены:
| Используемые операции | Значение по умолчанию |
|---|---|
| enable_bitmapscan enable_hashagg enable_hashjoin enable_indexscan enable_indexonlyscan enable_material enable_mergejoin enable_nestloop enable_parallel_append enable_seqscan enable_sort enable_tidscan enable_parallel_hash enable_partition_pruning |
on |
| enable_partitionwise_join enable_partitionwise_aggregate |
off |
Запрещая или разрешая отдельные операции, мы заставляем планировщик выбирать другие планы, которые мы можем увидеть все той же командой EXPLAIN. На самом деле, «запрет» операций не запрещает их использование, а просто сильно увеличивает их затратность. В PostgreSQL каждой «запрещенной» операции автоматически «накидывается» затратность равная 10 миллиардам условных единиц. При этом в EXPLAIN суммарные веса плана могут получиться запредельно высокими, но на фоне этих десятков миллиардов вес остальных операций хорошо просматривается, так как он обычно укладывается в меньшие порядки.
Особого интереса заслуживают две операции из перечисленных:
- Hash Join. Ее сложность — O(N), но при ошибке с прогнозом в размере результата можно не поместиться в память и придется делать Merge Join, с затратностью O(N*log(N)).
- Nested Loop. Ее сложность O(N2), поэтому ошибка в прогнозе размеров квадратично влияет на скорость выполнения такого соединения.
Например, возьмем некоторые реальные цифры из запросов, оптимизацией которых мы занимались в нашей компании.
План 1. Со всеми разрешенными операциями суммарная затратность наиболее оптимального плана составляла 274962.09 единиц.
План 2. С «запрещенным» nested loop затратность выросла до 40000534153.85. Вот эти 40 миллиардов, составляющие основную часть затратности – это 4 раза использованный Nested Loop, несмотря на запрет. А оставшиеся 534153.85 – это как раз и есть прогноз затратности всех остальных операций в плане. Он, как мы видим, примерно в 2 раза превышает затратность оптимального плана, то есть достаточно близок к нему.
План 3. С «запрещенным» Hash Join затратность составила 383253.77. План был действительно составлен без использования операции Hash Join, так как мы не видим никаких миллиардов. Затратность его, тем не менее, на 30% выше, чем у оптимального, что тоже очень близко.
В реальности же времена выполнения запросов были такие:
План 1 (все операции разрешены) выполнился за ~ 9 минут.
План 2 (с «запрещенным» nested loop) выполнился за 1.5 секунды.
План 3 (с «запрещенным» hash join) выполнился за ~ 5 минут.
Причина, как можно заметить, в ошибочном прогнозе затратности Nested Loop. И действительно, при сравнении EXPLAIN c EXPLAIN ANALYZE в нем обнаруживается ошибка с определением того самого злосчастного N на промежуточной операции. Вместо прогнозируемой одной строки Nested Loop встретился с несколькими тысячами строк, из-за чего время выполнения запроса выросло на пару порядков.
Экономия с «запрещенным» Hash Join связана с заменой хэширования на сортировку и Merge Join, который отработал в данном случае быстрее чем Hash Join. Заметим, что этот план 2 в реальности почти в два раза быстрее «оптимального» плана 1. Хотя прогнозировалось, что он будет медленнее.
На практике, если ваш запрос внезапно (после апгдейда БД или просто сам собой) стал выполняться значительно дольше чем до этого, попробуйте для начала запретить либо Hash Join либо Nested Loop и посмотреть, как это влияет на скорость выполнения запроса. В удачном случае вам удастся хотя бы запретить новый неоптимальный план, и, вернуться к предыдущему, быстрому.
Для того чтобы это сделать не нужно изменять конфигурационные файлы PostgreSQL с рестартом базы, достаточно просто в любой консоли изменить значение нужной переменной на время открытой сессии с БД. Остальные сессии не будут затронуты, конфигурация изменится только для вашей текущей сессии. Например, так:
SET enable_hashjoin=’on’;
SET enable_nestloop=’off’;
SELECT …
FROM …
(и остальная часть анализируемого запроса)
Второе средство повлиять на выбор плана – это изменение собственно весов низкоуровневых операций. Здесь универсального рецепта нет, но, к примеру, если у вас БД с «разогретым» кэшем и данные целиком помещаются в памяти, вполне вероятно, что затратность последовательной подгрузки страницы не отличается от затратности подгрузки случайной страницы. Тогда как в конфиге по умолчанию случайная в 4 раза более затратна чем последовательная.
Или, другой пример, условная затратность запуска параллельной обработки равна по умолчанию 1000, тогда как затратность подгрузки страницы 1.0. Начинать имеет смысл с изменения только одного из параметров за раз, чтобы определить влияет ли именно он на выбор плана. Самые простые способы – это для начала выставить параметр в 0 или в какое-нибудь высокое значение (1 миллион).
Однако нужно помнить, что, улучшив производительность в одном запросе вы можете ухудшить ее в другом. В общем, тут широкое поле для экспериментов. Лучше пробовать менять их по одному, по очереди.
Альтернативные варианты лечения
Рассказ про планировщик был бы неполным без упоминания, как минимум, двух расширений PostgreSQL.
Первое – это SR_PLAN, для сохранения рассчитанного плана и принудительного использования его в дальнейшем. Это помогает сделать поведение БД более предсказуемым в смысле выбора плана.
Второе – Adaptive Query Optimizer, которое реализует обратную связь планировщику от реального времени выполнения запроса, то есть планировщик измеряет фактические результаты выполненного запроса и корректирует свои планы в будущем с учетом этого. БД таким образом, «самонастраивается» для конкретных данных и запросов.
Чем еще занимается БД, когда она «тормозит»?
Теперь, когда с планированием запросов мы более или менее разобрались, посмотрим, что еще можно улучшить как в самой БД, так и в приложениях, которые ее используют, чтобы получить максимум производительности от нее.
Предположим, что план запроса уже оптимален. Если исключить самые очевидные проблемы (мало памяти или медленный диск/сеть), то остаются еще затраты на расчет хэшей. Здесь, вероятно, кроются великие возможности для будущего улучшения PostgreSQL (с помощью GPU или даже SSE2/SSE3/AVX инструкций CPU), однако пока этого нет и вычисления хэшей почти не используют аппаратные возможности «железа». В этом базе данных можно немного помочь.
Если вы обратили внимание, по умолчанию индексы в PostgreSQL создаются как b-tree. Их полезность в том, что они достаточно универсальны. Такой индекс можно использовать и с условиями равенства, и с условиями сравнения (больше или меньше). Поиск элемента в таком индексе – это логарифмическая затратность. Но если ваш запрос содержит только условие равенства, индексы можно создавать еще и как hash index, затратность поиска в котором — константа.
Далее, еще можно попытаться изменить запрос так чтобы использовать параллельное его выполнение. Чтобы понять, как именно его переписать, лучше всего ознакомиться со списком случаев, когда параллелизм автоматически запрещается планировщиком и избегать таких ситуаций. Руководство на эту тему достаточно кратко описывает все ситуации, поэтому нет смысла повторять их здесь.
Что же делать, если запрос все же плохо получается сделать параллельным? Весьма грустно наблюдать, как в вашей мощной многоядерной БД, где вы единственный клиент, одно ядро занято на 100%, а все остальные ядра просто на это смотрят. В этом случае приходится помогать базе со стороны приложения. Поскольку каждой сессии назначается свое ядро, можно открыть их несколько и поделить общий запрос на части, делая более короткие и более быстрые выборки, объединяя их в общий результат уже в приложении. Это позволит занять максимум доступных ресурсов CPU в БД PostgreSQL.
В заключение хотелось бы отметить, что перечисленные возможности диагностики и оптимизации – это всего лишь верхушка айсберга, однако они достаточно просты в использовании и могут помочь быстро идентифицировать проблему прямо на рабочих данных без риска испортить конфиг или нарушить работу других приложений.
Удачных вам запросов, с точными и короткими планами.
