 Полгода назад мы закончили миграцию всех наших stateless сервисов в kubernetes. На первый взгляд задача достаточно простая: нужно развернуть кластер, написать спецификации приложений и вперед. Из-за одержимости в вопросе обеспечения стабильности в работе нашего сервиса пришлось сразу начать разбираться с тем, как работает k8s и тестировать различные сценарии отказов. Больше всего вопросов у меня возникало ко всему, что касается сети. Один из таких "скользких" моментов — работа сервисов (Services) в kubernetes.
Полгода назад мы закончили миграцию всех наших stateless сервисов в kubernetes. На первый взгляд задача достаточно простая: нужно развернуть кластер, написать спецификации приложений и вперед. Из-за одержимости в вопросе обеспечения стабильности в работе нашего сервиса пришлось сразу начать разбираться с тем, как работает k8s и тестировать различные сценарии отказов. Больше всего вопросов у меня возникало ко всему, что касается сети. Один из таких "скользких" моментов — работа сервисов (Services) в kubernetes.
В документации нам говорят:
- выкатите приложение
- задайте liveness/readiness пробы
- создайте сервис
- дальше все будет работать: балансировка нагрузки, обработка отказов итд.
Но на практике все несколько сложнее. Давайте посмотрим, как оно работает на самом деле.
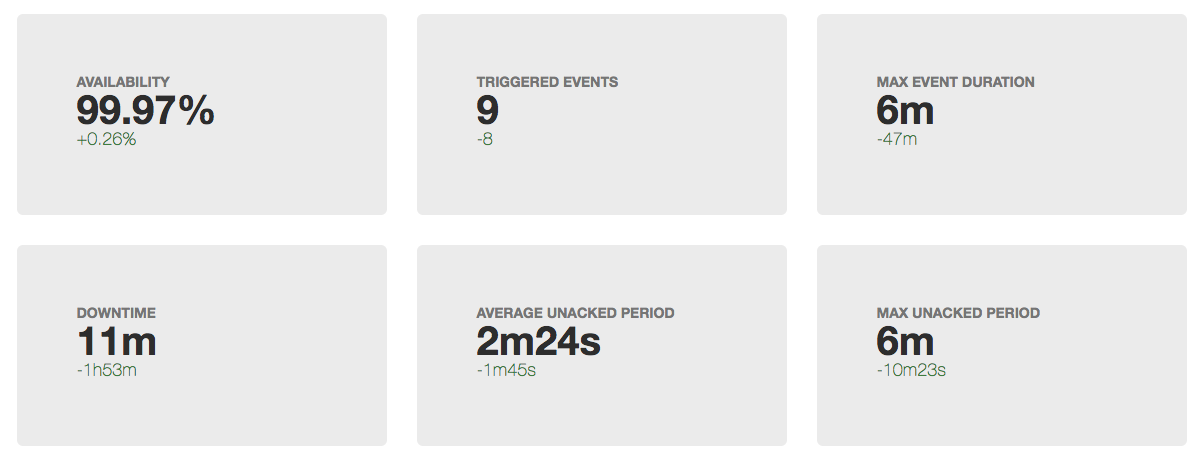
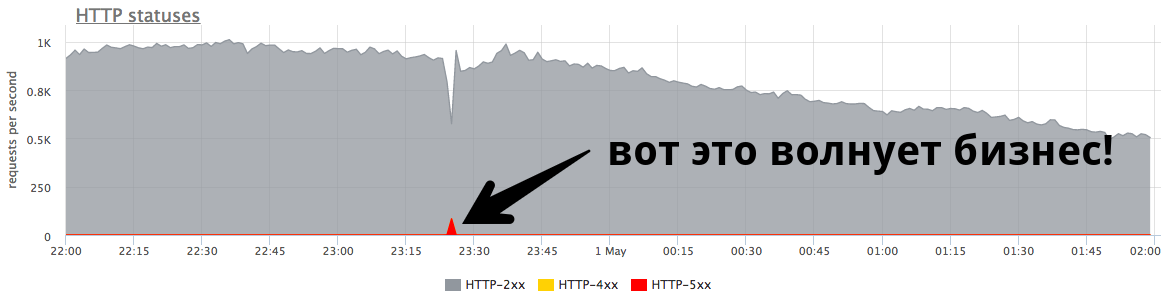

 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента. 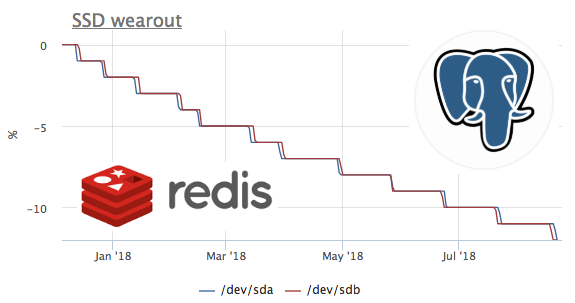
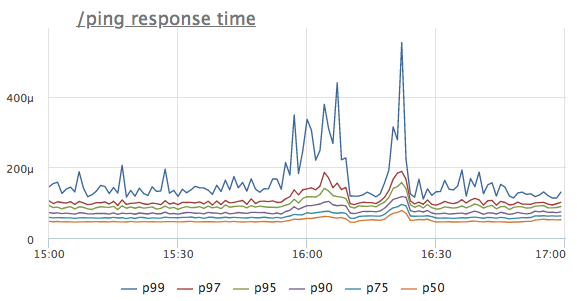 Не так давно в датацентре, в котором мы арендуем серверы случился очередной мини-инцидент. Никаких серьезных последствий для нашего сервиса в итоге не было, по имеющимся метрикам нам удалось понять что происходит буквально за минуту. А потом я представил, как пришлось бы ломать голову, если бы не хватало всего 2х простеньких метрики. Под катом коротенькая история в картинках.
Не так давно в датацентре, в котором мы арендуем серверы случился очередной мини-инцидент. Никаких серьезных последствий для нашего сервиса в итоге не было, по имеющимся метрикам нам удалось понять что происходит буквально за минуту. А потом я представил, как пришлось бы ломать голову, если бы не хватало всего 2х простеньких метрики. Под катом коротенькая история в картинках.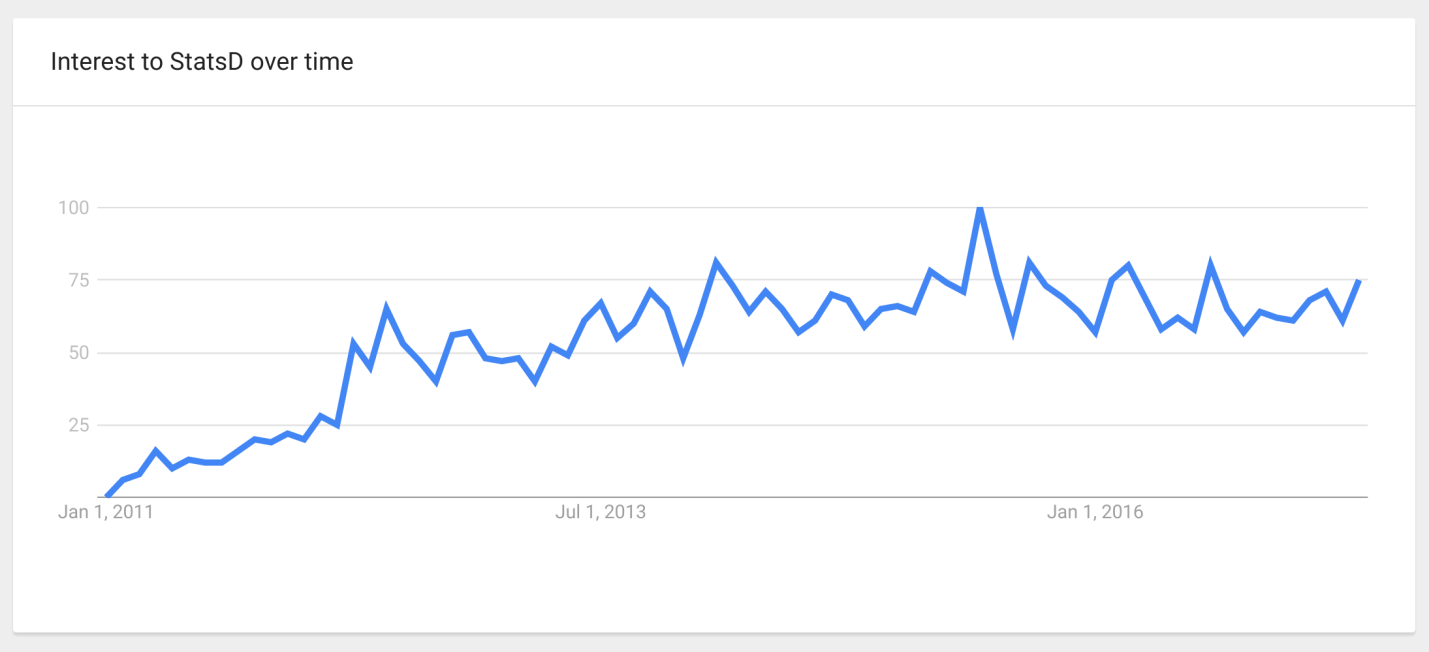
 Еще 4 года назад использование контейнеров в production было экзотикой, но сейчас это уже норма как для маленьких компаний, так и для больших корпораций. Давайте попробуем посмотреть на всю эту историю с devops/контейнерами/микросервисами ретроспективно, взглянуть еще раз свежим взглядом на то, какие задачи мы изначально пытались решить, какие решения у нас есть сейчас и чего не хватает для полного счастья?
Еще 4 года назад использование контейнеров в production было экзотикой, но сейчас это уже норма как для маленьких компаний, так и для больших корпораций. Давайте попробуем посмотреть на всю эту историю с devops/контейнерами/микросервисами ретроспективно, взглянуть еще раз свежим взглядом на то, какие задачи мы изначально пытались решить, какие решения у нас есть сейчас и чего не хватает для полного счастья? С появлением docker у нас, как у сервиса мониторинга немного усложнилась жизнь. Как я
С появлением docker у нас, как у сервиса мониторинга немного усложнилась жизнь. Как я 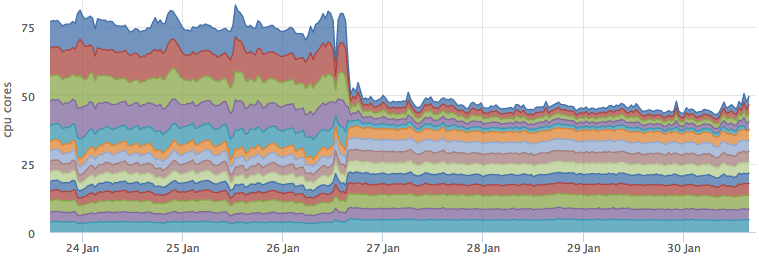
 Перевод статьи директора по инфраструктуре @Synthesio — крик души про усталось от алертов и боль от не cloud-ready мониторинга.
Перевод статьи директора по инфраструктуре @Synthesio — крик души про усталось от алертов и боль от не cloud-ready мониторинга. Я уже рассказывал про
Я уже рассказывал про 
 Сейчас существует достаточно много систем для хранения и обработки метрик (timeseries db), но ситуация с агентами (софтом, который собирает метрики) сложнее. Не так давно появился
Сейчас существует достаточно много систем для хранения и обработки метрик (timeseries db), но ситуация с агентами (софтом, который собирает метрики) сложнее. Не так давно появился  В 2008 году в списке рассылки pgsql-hackers началось
В 2008 году в списке рассылки pgsql-hackers началось  Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры.
Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры.