
Вам сюда, если хотите знать, как приручить широкоизвестный в кругах Python-разработчиков фреймворк под названием Сelery. И даже, если в вашем проекте Celery уверенно выполняет базовые команды, то финтех опыт может открыть вам неизведанные стороны. Потому что финтех — это всегда Big Data, а с ней и необходимость фоновых задач, пакетной обработки, асинхронного API и т.д.

Прелесть рассказа Олега Чуркина про Celery на Moscow Python Conf ++ помимо подробных инструкций, как настроить Celery под нагрузку и как его мониторить, в том, что можно позаимствовать полезные наработки.
О спикере и проекте: Олег Чуркин (Bahusss) 8 лет разрабатывает Python-проекты разной сложности, работал в многих известных компаниях: Яндексе, Рамблере, РБК, Лаборатории Касперского. Сейчас техлид в финтех-старапе StatusMoney.
Проект работает с большим количеством финансовых данных пользователей (1,5 терабайта): аккаунтами, транзакциями, мерчантами и т.д. В нем каждый день запускается до миллиона задач. Может быть, кому-то это число не покажется по-настоящему большим, но для маленького стартапа на скромных мощностях это существенный объем данных, и разработчикам пришлось столкнуться с разными проблемами на пути к стабильному процессу.
Олег рассказал о ключевых моментах работы:
И поделился парой проектных утилит, которые реализуют недостающую в Celery функциональность. Как выяснилось, в 2018 году и такое может быть. Далее текстовая версия доклада от первого лица.
Проблематика
Требовалось решить следующие задачи:
К фоновым задачам относятся любые типы уведомлений: email, push, desktop — все это посылается в фоновых задачах по триггеру. Таким же образом запускается периодическое обновление финансовых данных.
В фоновом режиме выполняются разные специфические проверки, например, проверка пользователя на фрод. В финансовых стартапах много сил и внимания уделяется именно безопасности данных, поскольку мы позволяем пользователям добавлять свои банковские аккаунты в нашу систему, и можем видеть все их транзакции. Мошенники могут попробовать воспользоваться нашим сервисом для чего-то нехорошего, например, для проверки баланса украденного аккаунта.
Последняя категория фоновых задач — это maintenance задачи: что-то подкрутить, посмотреть, поправить, замониторить и т.д.
Для рассылки уведомлений, только массовой, используется пакетная обработка данных. Большой объем данных, которые мы получаем от наших пользователей, приходится предрасчитывать и обрабатывать определенным образом, в т.ч. в пакетном режиме.
В это же понятие входит классический Extract, Transform, Load:
Ни для кого не секрет, что асинхронный API можно сделать с помощью простого polling-а запросов: фронтенд инициирует процесс на бэкенде, бэкенд запускает задачу, которая периодически сама себя запускает, «поллит» результаты и обновляет state в базе. Фронтенд показывает пользователю этот интерактив — state меняется. Это позволяет:
В нашем сервисе пока этого хватает, но в будущем скорее всего придется на что-то другое переписать.
Требования к инструментам
Чтобы реализовать эти задачи, у нас были такие требования к инструментам:
Какой инструмент выбрать?
Какие есть варианты на рынке в 2018 году для решения этих задач?
Когда-то давно для менее амбициозных задач я написал удобную библиотеку которая все еще используется в некоторых проектах. Она проста в эксплуатации и выполняет задачи в фоне. Но при этом никакие брокеры не нужны (ни Celery, ни другие), только сервер приложений uwsgi, у которого есть спулер (spooler) — такая штука, которая запускается как отдельный воркер. Это очень простое решение — все задачи хранятся условно в файлах. Для простых проектов этого хватает, но для нашего было недостаточно.
Так или иначе мы рассмотрели:
Многообещающий кандидат 2018
Сейчас я бы обратил ваше внимание на Dramatiq. Это библиотека от адепта Celery, который познал все минусы Celery и решил все переписать, только очень красиво. Преимущества Dramatiq:
Некоторое время назад у Dramatiq были проблемы с лицензиями: сначала была AGPL, потом заменили на LGPL. Но сейчас можно попробовать.
Но в 2016 году кроме Celery взять было особо нечего. Нам понравилась его богатая функциональность, и тогда он идеально подходил под наши задачи, потому что уже тогда был зрелый и функциональный:
Особенности проекта
Расскажу про наш контекст, чтобы дальнейший рассказ был понятнее.
Мы используем Redis как брокер сообщений. Я слышал много историй и слухов о том, что Redis теряет сообщения, что он не приспособлен быть брокером сообщений. На продакшен опыте это не подтверждается, а, как выясняется, Redis сейчас работает более производительно, чем RabbitMQ (именно с Celery, как минимум, видимо, проблема в коде интеграции с брокерами). В версии 4 починили брокер Redis, он действительно перестал терять задачи при рестартах и работает вполне стабильно. В 2016 году в Celery собирались отказаться от Redis и сконцентрироваться на интеграции с RabbitMQ, но, к счастью, этого не произошло.
В случае проблем с Redis, если нам потребуется серьезная high availability, то мы, поскольку используем мощности Amazon, переключимся на Amazon SQS или Amazon MQ.
Мы не используем result backend для хранения результатов, потому что предпочитаем хранить результаты сами где хотим, и проверять их так, как хотим. Мы не хотим, чтобы Celery за нас это делал.
Мы используем pefork pool, то есть процесс-воркеры, которые создают для дополнительного concurrency отдельные форки процессов.
Unit of work
Обсудим базовые элементы, чтобы ввести в курс дела тех, кто еще не пробовал Celery, а только собирается. Unit of work для Celery — это задача. Приведу пример простой задачи, которая посылает email.
Простая функция и декоратор:
Запуск задачи прост: либо вызываем функцию и задача выполнится в runtime (send_email(email="python@example.com")), либо в воркере, то есть тот самый эффект задачи в фоне:
За два года работы с Celery при высоких нагрузках мы вывели правила хорошего тона. Было много граблей, мы научились их обходить, и я поделюсь как.
Оформление кода
В задаче может находиться различная логика. Вообще Celery способствует тому, чтобы вы держали задачки в файлах или в packages tasks, или импортировали их откуда-то. Иногда получается нагромождение бизнес-логики в одном модуле. На наш взгляд, тут правильный подход с точки зрения модульности приложения — держать минимум логики в задаче. Мы используем задачки только как «запускаторы» кода. То есть задача не несет в себе логику, а триггерит запуск кода в Background.
Весь код мы выносим во внешние классы, которые используют еще какие-то классы. Все задачи по сути состоят из двух строчек.
Простые объекты в параметрах
В примере выше в задачу передается некий id. Во все задачи, которые мы используем, мы передаем только маленькие скалярные данные, id. Мы не сериализуем модели Django, чтобы их передавать. Даже в ETL, когда приходит из внешнего сервиса большой блоб данных, мы его сначала сохраняем и потом запускаем задачу, которая читает по id весь этот блоб и обрабатывает.
Если так не делать, то мы видели очень большие спайки потребляемой памяти у Redis. Сообщение начинает занимать больше памяти, сеть сильно загружается, количество обработанных задач (производительность) падает. Пока объект доходит до выполнения, задачи становятся не актуальными, объект уже удален. Данные нужно было сериализовать — не все хорошо сериализуется в JSON в Python. Нам нужна была возможность при retry задач как-то быстро решать, что делать с этими данными, получать их снова, запускать над ними какие-то проверки.
Идемпотентные задачи
Такой подход рекомендуют сами разработчики Celery. При повторном выполнении участка кода никаких побочных-эффектов произойти не должно, результат должен быть тот же. Не всегда этого просто добиться, особенно если идет взаимодействие с многими сервисами, или двухфазные коммиты.
Но когда вы все делаете локально, то всегда можете проверять, что входящие данные существуют и актуальны, над ними действительно можно совершить работу, и использовать транзакции. Если к одной задаче много запросов в базу и что-то может пойти не так во время выполнения — используйте транзакции, чтобы откатить ненужные изменения.
Обратная совместимость
Несколько интересных побочных эффектов было у нас при деплое приложения. Неважно, какой тип деплоя вы используете (blue+green или rolling update), всегда возникнет ситуация, когда старый код сервиса создает сообщения для нового кода воркера, и наоборот, старый воркер принимает сообщения от нового кода сервиса, потому что он раскатился «первее» и туда трафик пошел.
Мы ловили ошибки и теряли задачи, пока не научились поддерживать обратную совместимость между релизами. Обратная совместимость заключается в том, что между релизами задачи должны работать безопасно, независимо от того, какие параметры приходят в эту задачу. Поэтому во всех задачах мы сейчас делаем «резиновую» сигнатуру (**kwargs). Когда в следующем релизе вам потребуется добавить новый параметр, вы его из **kwargs возьмете в новом релизе, а в старом не возьмете — у вас ничего не сломается. Как только меняется сигнатура, а Celery об этом не знает, он падает и выдает ошибку, что такого параметра нет в задаче.
Более строгий способ избегать подобных проблем — это версионирование очередей задач между релизами, но он достаточно сложен в реализации и мы пока оставили его в беклоге.
Таймауты
Проблемы могут возникнуть из-за недостаточного количества или неправильных таймаутов.
Поэтому все задачки у нас обвешаны таймаутами, в том числе глобальными для всех задач, и для каждой конкретной задачи тоже проставлены таймауты.
Обязательно должны быть проставлены: soft_limit_timeout и expires.
Expires — это сколько задача может жить в очереди. Нужно чтобы задачи не накапливались в очередях в случае проблем. Например, если мы сейчас хотим сообщить о чем-то пользователю, но что-то случилось, и задача может выполниться только завтра — в этом нет смысла, завтра сообщение уже будет неактуально. Поэтому на уведомления у нас достаточно маленький expires.
Обратите внимание на использование eta (countdown) + visibility_timeout. В FAQ описана такая проблема с Redis — так называемый visibility timeout у брокера Redis. По умолчанию его значение один час: если через час воркер видит, что задачу никто не взял к исполнению, то повторно добавляет ее в очередь. Таким образом, если countdown равен двум часам, уже через час брокер выяснит, что эта задача еще не выполнилась, и создаст еще одну такую же. А через два часа выполнится две одинаковых задачи.
Retry policy
Для тех задач, которые можно повторить, или которые могут выполниться с ошибками, мы используем Retry policy. Но используем аккуратно, чтобы не завалить внешние сервисы. Если быстро повторять задачи, не указывая exponential backoff, то внешний сервис, а может быть и внутренний, могут просто не выдержать.
Параметры retry_backoff, retry_jitter и max_retries хорошо бы указывать явно, особенно max_retries. retry_jitter — параметр, который позволяет внести немножко хаоса, чтобы задачи не начали повторятся одновременно.
Утечки памяти
В целом работа с памятью у Python очень спорная. Вы потратите много времени и нервов, чтобы понять, почему происходит утечка, а потом выяснится, что она даже не в вашем коде. Поэтому всегда, начиная проект, проставляйте лимит памяти на воркер: worker_max_memory_per_child.
Это гарантирует, что однажды не придет OOM Killer, не убьет все воркеры, и вы не потеряете все задачи. Celery будет сам перезапускать воркеры, когда нужно.
Приоритет выполнения задач
Всегда есть задачи, которые нужно выполнять раньше всех, быстрее всех — они должны быть выполнены прямо сейчас! Есть задачи, которые не так важны — пусть выполнятся в течение дня. Для этого у задачи есть параметр priority. В Redis он работает достаточно интересно — создается новая очередь с именем, в которое добавляется priority.
Мы используем другой подход — отдельные воркеры для приоритетов, т.е. по старинке создаем воркеры для Celery с разными «важностями»:
Celery multi start — это хелпер, который помогает запустить всю конфигурацию Celery на одной машине и из одной командной строки. В этом примере мы создаем ноды (или воркеры): high_priority и low_priority, 2 и 6 — это concurrency.
Два воркера high_priority постоянно обрабатывают очередь urgent_notifications. Эти воркеры больше никто не займет, они будут только читать важные задачи из очереди urgent_notifications.
Для неважных задач есть low_priority очередь. Там 6 воркеров, которые принимают сообщения из всех остальных очередей. Также low_priority воркеры мы подписываем на urgent_notifications, чтобы они могли помочь, если воркеры с high_priority не будут справляться.
Мы используем эту классическую схему для приоритезации задач.
Extract, Transform, Load
Чаще всего ETL выглядит как цепочка задач, каждая из которых получает на вход данные из предыдущей задачи.
В примере три задачи. В Celery есть подход к distributed processing и несколько полезных утилит, в том числе функция chain, которая делает из трех таких задач один pipeline:
Celery сам разберет pipeline, выполнит по порядку сначала первую задачу, потом полученные данные передаст во вторую, данные, которые вернет вторая задача, передаст в третью. Так мы реализуем простые ETL pipelines.
Для более сложных цепочек приходится подключать дополнительную логику. Но важно иметь в виду, что если в этом chain возникнет проблема в одной задаче, то весь chain развалится. Если вы не хотите такого поведения, то обрабатывайте exception и продолжайте выполнение, либо останавливайте всю цепочку по исключению.
На самом деле эта цепочка внутри выглядит как одна большая задача, в которой содержатся все задачи со всеми параметрами. Поэтому если злоупотребить количеством задач в цепочке, то получится очень высокое потребление памяти и замедление общего процесса. Создание цепочек из тысяч задач — плохая идея.
Пакетная обработка задач
Теперь самое интересное: что происходит, когда нужно отправить письмо двум миллионам пользователей.
Вы пишите такую функцию обхода всех пользователей:
Правда, чаще всего функция будет получать не только id пользователей, но и вымывать вообще всю таблицу users. Для каждого пользователя будет запускаться своя задача.
В этой задаче есть несколько проблем:
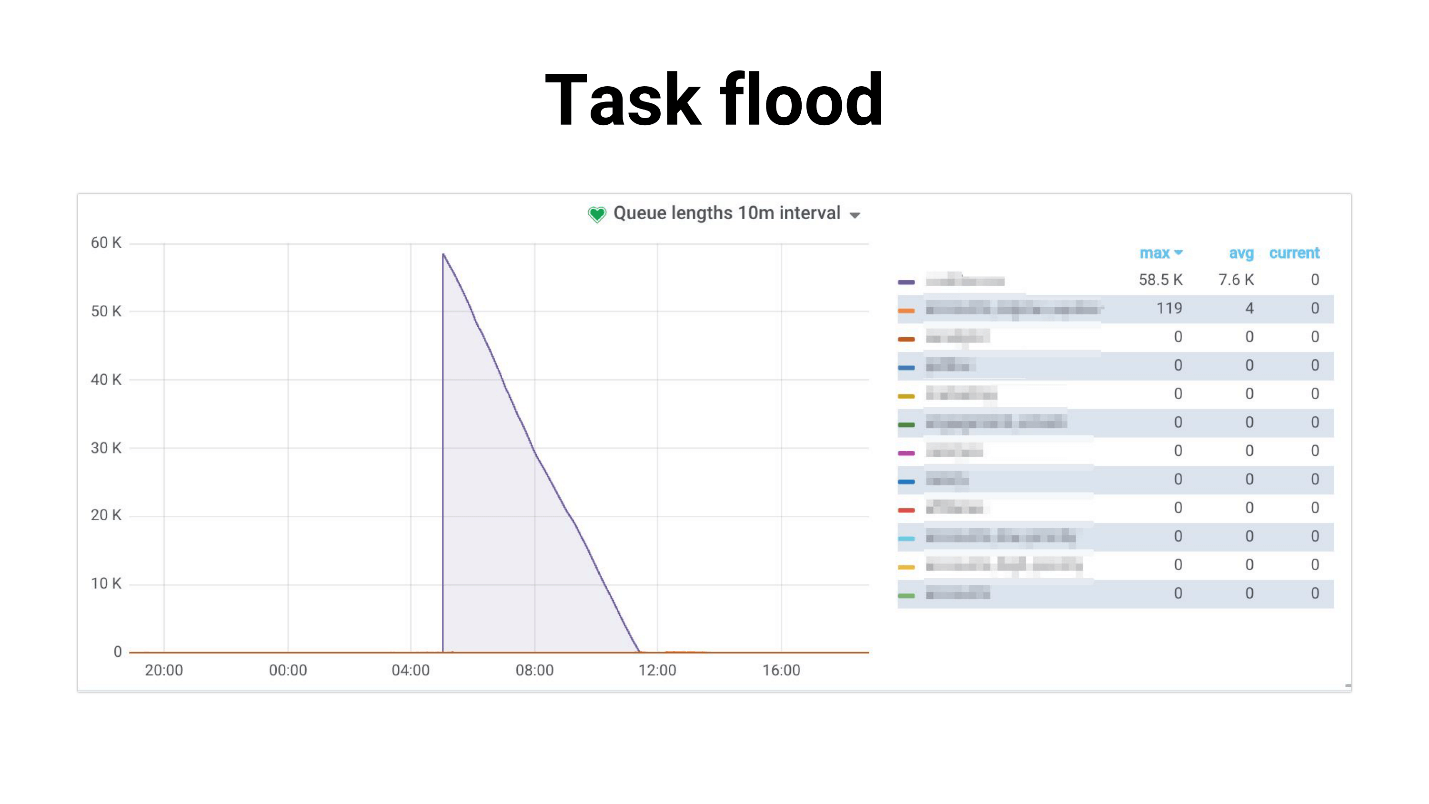
Я назвал это Task flood, на графике выглядит примерно так.

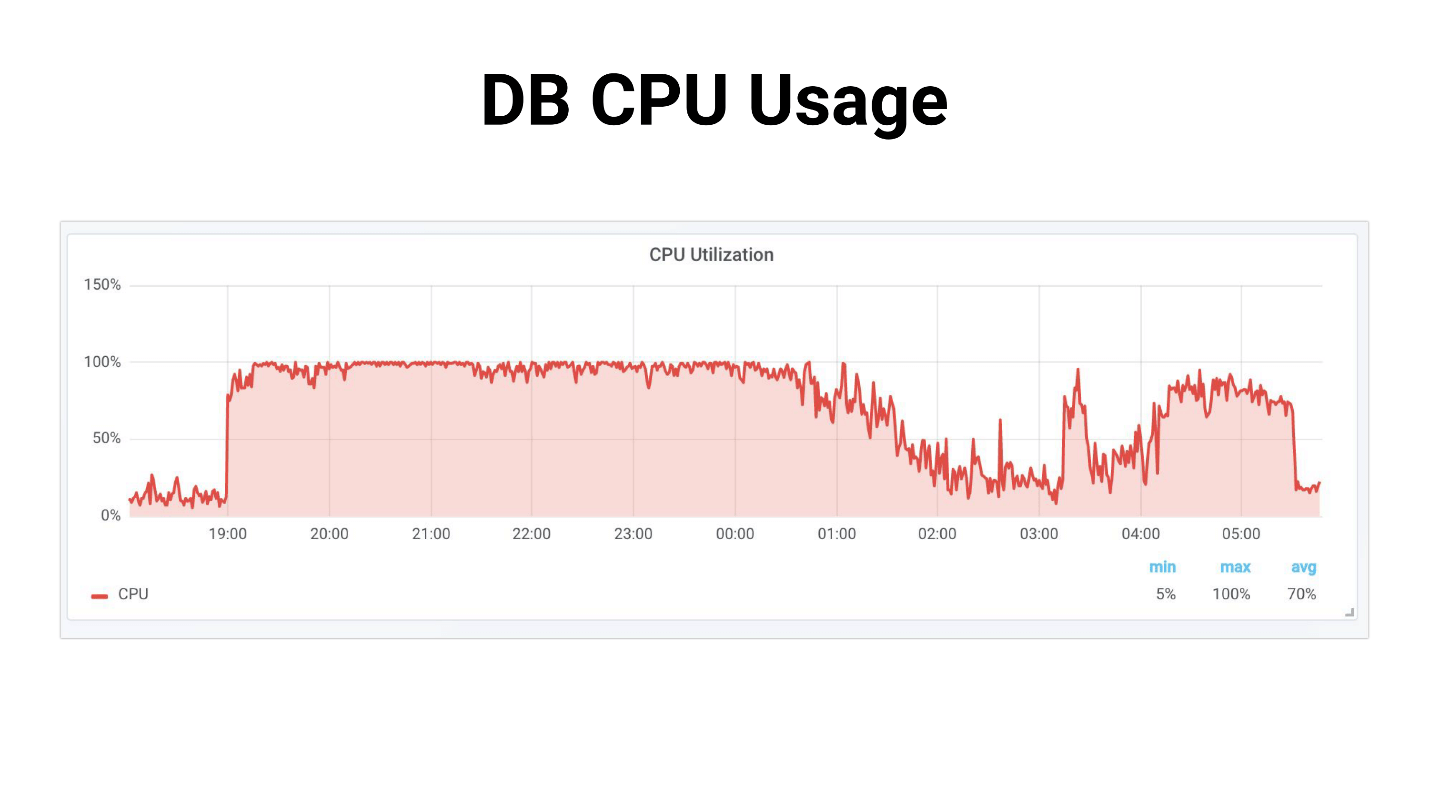
Возникает наплыв задач, которые воркеры потихонечку начинают обрабатывать. Происходит следующее, если задачи используют master-реплику, весь проект начинает просто трещать — ничего не работает. Ниже пример из нашей практики, где DB CPU Usage был 100 % несколько часов, мы, честно говоря, успели испугаться.
Проблема как раз в том, что система сильно деградирует с увеличением количества пользователей. Задача, которая занимается диспетчеризацией:
Происходит Task flooding: задачи накапливаются в очередях и создают большую нагрузку не только на внутренние сервисы, но и на внешние.
Мы пробовали уменьшать конкурентность воркеров, это помогает в каком-то смысле — снижаются нагрузки на сервис. Или можно масштабировать внутренние сервисы. Но это не решит проблему задачи-генератора, которая все еще очень много на себя берет. И никак не влияет на зависимость от производительности внешних сервисов.
Генерация задач
Мы решили пойти по другому пути. Чаще всего нам не нужно запускать все 2 млн задач прямо сейчас. Нормально, что рассылка уведомлений всем пользователям займет, например, 4 часа, если эти письма не так важны.
Сначала мы попробовали использовать Celery.chunks:
Это не изменило ситуацию, потому что, несмотря на итератор, все user_id будут загружены в память. И все воркеры получают цепочки задач, и хотя воркеры будут немного отдыхать, мы остались не удовлетворены этим решением в итоге.
Мы пробовали выставить rate_limit на воркеры, чтобы они обрабатывали только определенное количество задач в секунду, и выяснили, что на самом деле rate_limit указанный как для задачи, это rate_limit для воркера. То есть если вы указываете rate_limit для задачи, это не значит, что задача будет выполняться 70 раз в секунду. Это значит, что воркер ее будет выполнять 70 раз в секунду, и в зависимости от того, что у вас с воркерами, этот лимит может меняться динамически, т.е. реальный лимит rate_limit * len(workers).
Если воркер запускается или останавливается, то суммарный rate_limit меняется. Более того, если у вас задачи медленные, то весь prefetch в очереди, который наполняет воркер, будет забит этими медленными задачами. Воркер смотрит: «О, у меня эта задача в rate_limit-е, я ее больше не могу исполнять. И все следующие задачи в очереди точно такие же — пусть они повисят!» — и ждет.
Chunkificator
В итоге мы решили, что напишем свое, и сделали маленькую библиотеку, которую назвали Chunkificator.
Она принимает sleep_timeout и initial_chunk, и вызывает сама себя с новым chunk. Chunk — это абстракция либо над integer-списками, либо над date или datetime списками. Мы передаем chunk в функцию, которая получает пользователей только с этим chunk, и запускает задачи только для этого chunk.
Таким образом генератор задач запускает только то количество задач, которое нужно, и не потребляет много памяти. Картина стала такой.
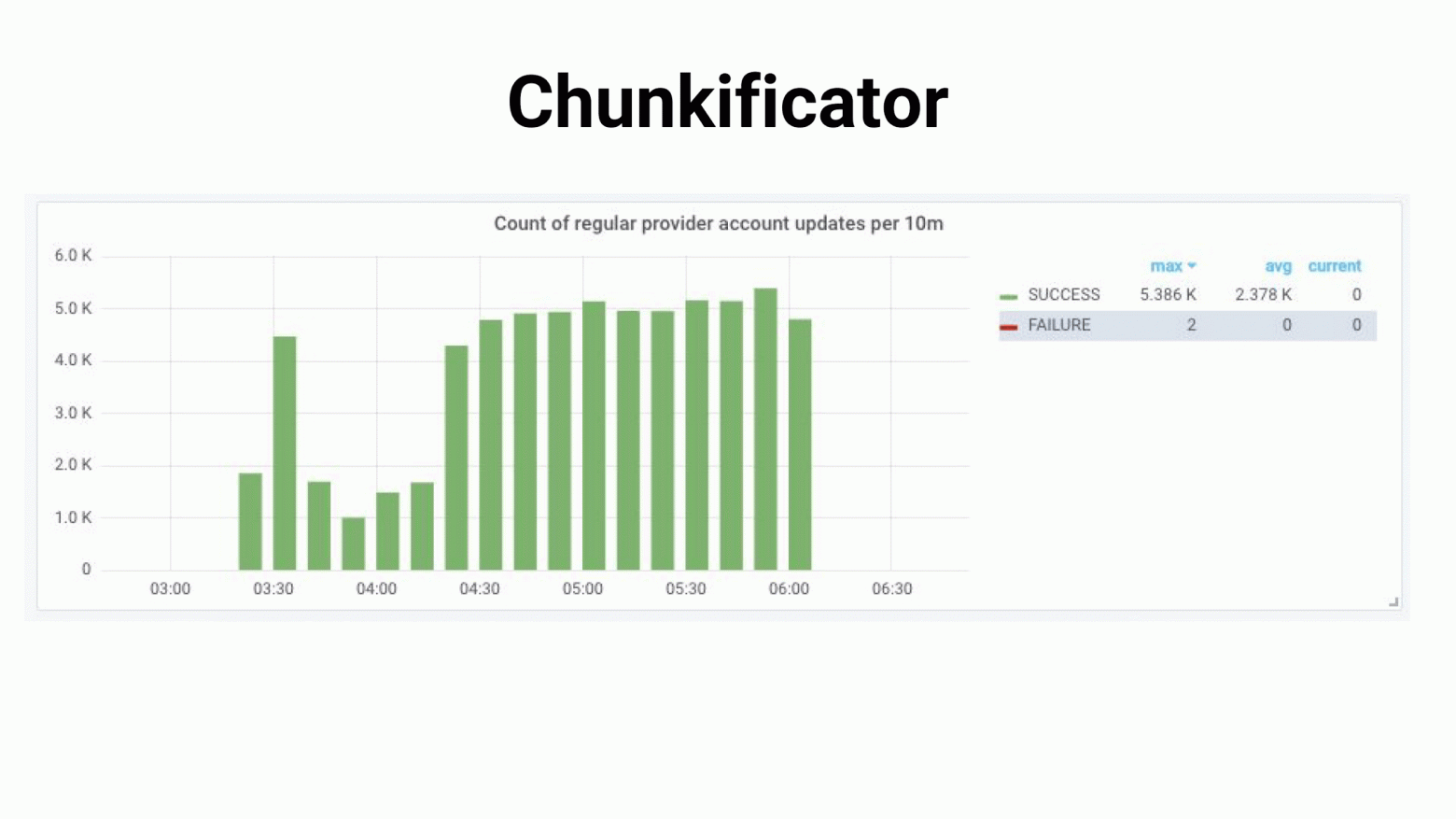
Изюминки добавляет то, что мы используем sparse chunk, то есть мы используем в качестве chunk id инстансов в БД (некоторые из них могут быть пропущены, поэтому и задач может быть меньше). В итоге нагрузка получилась более равномерная, процесс стал дольше, но все живы-здоровы, база не напрягается.
Библиотека реализована для Python 3.6+ и доступна на GitHub. Есть нюанс, который я планирую исправить, но пока для datetime-chunk нужен pickle serializer — многие на это не смогут пойти.
Пара риторических вопросов — откуда вся эта информация взялась? Как мы узнали, что у нас были проблемы? Как узнать, что проблема скоро станет критична и её уже нужно начинать решать?
Ответ — это, конечно, мониторинг.
Мониторинг
Я очень люблю мониторинг, люблю все мониторить и держать руку на пульсе. Если вы не держите руку на пульсе, то вы будете постоянно наступать на грабли.
Стандартные вопросы мониторинга:
Мы пробовали несколько вариантов. У Celery есть интерфейс CLI, он достаточно богат и дает:
Но в нем сложно реально что-то замониторить. Он лучше подходит для локальных изысков, или если вы хотите на runtime изменить какой-то rate_limit.
NB: нужен доступ к продакшен-брокеру, чтобы использовать интерфейс CLI.
Celery Flower позволяет сделать то же самое, что и CLI, только через веб-интерфейс, и то не всё. Зато строит некоторые простые графики и позволяет менять настройки «на лету».
В целом Celery Flower подходит, для того чтобы просто посмотреть, как все работает, в небольших сетапах. К тому же он поддерживает HTTP API, то есть удобен, если вы пишете автоматизацию.
Но мы остановились на Prometheus. Взяли текущий экспортер: пофиксили в нем утечки памяти; добавили метрики по типам exception; добавили метрики по количеству сообщений в очередях; интегрировали с aлертами в Grafana и радуемся. Он тоже выложен на GitHub, можно посмотреть здесь.
Примеры в Grafana

Выше статистика по всем исключениям: какие исключения для каких задач. Ниже время выполнение задач.

Чего не хватает в Celery?
Это развесистый фреймворк, в нем много всего, но нам не хватает! Не хватает маленьких фич, таких как:
Выводы
Несмотря на то, что Celery — это фреймворк, которым многие пользуется в продакшене, он состоит из 3 библиотек — Celery, Kombu и Billiard. Все эти три библиотеки разрабатывают соразработчики, и они могут релизнуть одну зависимость и сломать вашу сборку.

Поэтому, надеюсь, что вы уже как-то разобрались и сделали ваши сборки детерминистическими.
На самом деле выводы не настолько печальные. Celery справляется со своими задачами в нашем финтех-проекте под нашей нагрузкой. Мы наработали опыт, которым я с вами поделился, и вы можете применить наши решения или доработать их и тоже преодолеть все свои трудности.
Не забывайте, что мониторинг должен являться основной частью вашего проекта. Только с помощью мониторинга вы сможете узнать, где же у вас что-то не так, что нужно поправить, добавить, исправить.
Контакты спикера Олега Чуркина: Bahusss, facebook и github.

Прелесть рассказа Олега Чуркина про Celery на Moscow Python Conf ++ помимо подробных инструкций, как настроить Celery под нагрузку и как его мониторить, в том, что можно позаимствовать полезные наработки.
О спикере и проекте: Олег Чуркин (Bahusss) 8 лет разрабатывает Python-проекты разной сложности, работал в многих известных компаниях: Яндексе, Рамблере, РБК, Лаборатории Касперского. Сейчас техлид в финтех-старапе StatusMoney.
Проект работает с большим количеством финансовых данных пользователей (1,5 терабайта): аккаунтами, транзакциями, мерчантами и т.д. В нем каждый день запускается до миллиона задач. Может быть, кому-то это число не покажется по-настоящему большим, но для маленького стартапа на скромных мощностях это существенный объем данных, и разработчикам пришлось столкнуться с разными проблемами на пути к стабильному процессу.
Олег рассказал о ключевых моментах работы:
- Какие задачи хотели решить с помощью фреймворка, почему выбрали Celery.
- Как помог Celery.
- Как настроить Celery под нагрузку.
- Как мониторить состояние Celery.
И поделился парой проектных утилит, которые реализуют недостающую в Celery функциональность. Как выяснилось, в 2018 году и такое может быть. Далее текстовая версия доклада от первого лица.
Проблематика
Требовалось решить следующие задачи:
- Запускать отдельные фоновые задачи.
- Делать пакетные обработки задач, то есть запускать сразу много задач.
- Встроить процесс Extract, Transform, Load.
- Реализовать асинхронный API. Оказывается, асинхронный API можно реализовать не только с помощью асинхронных фреймворков, но и вполне себе синхронных;
- Выполнять периодические задачи. Ни один проект не обходится без периодических задач, для некоторых можно обойтись Cron, но есть и более удобные инструменты.
- Построить триггерную архитектуру: на срабатывание триггера запускать задачу, которая обновит данные. Делается это, чтобы компенсировать недостаток runtime-мощностей предрасчетом данных в фоновом режиме.
К фоновым задачам относятся любые типы уведомлений: email, push, desktop — все это посылается в фоновых задачах по триггеру. Таким же образом запускается периодическое обновление финансовых данных.
В фоновом режиме выполняются разные специфические проверки, например, проверка пользователя на фрод. В финансовых стартапах много сил и внимания уделяется именно безопасности данных, поскольку мы позволяем пользователям добавлять свои банковские аккаунты в нашу систему, и можем видеть все их транзакции. Мошенники могут попробовать воспользоваться нашим сервисом для чего-то нехорошего, например, для проверки баланса украденного аккаунта.
Последняя категория фоновых задач — это maintenance задачи: что-то подкрутить, посмотреть, поправить, замониторить и т.д.
Для рассылки уведомлений, только массовой, используется пакетная обработка данных. Большой объем данных, которые мы получаем от наших пользователей, приходится предрасчитывать и обрабатывать определенным образом, в т.ч. в пакетном режиме.
В это же понятие входит классический Extract, Transform, Load:
- загружаем данные из внешних источников (внешний API);
- сохраняем необработанными;
- запускаем задачи, которые считывают и обрабатывают данные;
- сохраняем обработанные данные в нужном месте в нужном формате, чтобы потом удобно использовать в UI, например.
Ни для кого не секрет, что асинхронный API можно сделать с помощью простого polling-а запросов: фронтенд инициирует процесс на бэкенде, бэкенд запускает задачу, которая периодически сама себя запускает, «поллит» результаты и обновляет state в базе. Фронтенд показывает пользователю этот интерактив — state меняется. Это позволяет:
- запускать polling задачи из других задач;
- запускать разные задачи в зависимости от условий.
В нашем сервисе пока этого хватает, но в будущем скорее всего придется на что-то другое переписать.
Требования к инструментам
Чтобы реализовать эти задачи, у нас были такие требования к инструментам:
- Функциональность, необходимая для реализации наших амбиций.
- Масштабируемость без костылей.
- Мониторинг системы, для того чтобы понять, как она работает. Мы используем репортинг ошибок, поэтому интеграция с Sentry будет не лишней, с Django тоже.
- Производительность, потому что задач у нас много.
- Зрелость, надежность и активная разработка — очевидные вещи. Мы искали инструмент, который будет поддерживаться и развиваться.
- Адекватность документации — без документации никуда.
Какой инструмент выбрать?
Какие есть варианты на рынке в 2018 году для решения этих задач?
Когда-то давно для менее амбициозных задач я написал удобную библиотеку которая все еще используется в некоторых проектах. Она проста в эксплуатации и выполняет задачи в фоне. Но при этом никакие брокеры не нужны (ни Celery, ни другие), только сервер приложений uwsgi, у которого есть спулер (spooler) — такая штука, которая запускается как отдельный воркер. Это очень простое решение — все задачи хранятся условно в файлах. Для простых проектов этого хватает, но для нашего было недостаточно.
Так или иначе мы рассмотрели:
- Celery (10K звезд на GitHub);
- RQ (5К звезд на GitHub);
- Huey (2К звезд на GitHub);
- Dramatiq (1К звезд на GitHub);
- Tasktiger (0,5К звезд на GitHub);
- Airflow? Luigi?
Многообещающий кандидат 2018
Сейчас я бы обратил ваше внимание на Dramatiq. Это библиотека от адепта Celery, который познал все минусы Celery и решил все переписать, только очень красиво. Преимущества Dramatiq:
- Набор всех необходимых фич.
- Заточенность на производительность.
- Поддержка Sentry и метрик для Prometheus «из коробки»
- Небольшая и понятно написанная кодовая база, code autoreload.
Некоторое время назад у Dramatiq были проблемы с лицензиями: сначала была AGPL, потом заменили на LGPL. Но сейчас можно попробовать.
Но в 2016 году кроме Celery взять было особо нечего. Нам понравилась его богатая функциональность, и тогда он идеально подходил под наши задачи, потому что уже тогда был зрелый и функциональный:
- имел периодические задачи из коробки;
- поддерживал несколько брокеров;
- интегрировался с Django и Sentry.
Особенности проекта
Расскажу про наш контекст, чтобы дальнейший рассказ был понятнее.
Мы используем Redis как брокер сообщений. Я слышал много историй и слухов о том, что Redis теряет сообщения, что он не приспособлен быть брокером сообщений. На продакшен опыте это не подтверждается, а, как выясняется, Redis сейчас работает более производительно, чем RabbitMQ (именно с Celery, как минимум, видимо, проблема в коде интеграции с брокерами). В версии 4 починили брокер Redis, он действительно перестал терять задачи при рестартах и работает вполне стабильно. В 2016 году в Celery собирались отказаться от Redis и сконцентрироваться на интеграции с RabbitMQ, но, к счастью, этого не произошло.
В случае проблем с Redis, если нам потребуется серьезная high availability, то мы, поскольку используем мощности Amazon, переключимся на Amazon SQS или Amazon MQ.
Мы не используем result backend для хранения результатов, потому что предпочитаем хранить результаты сами где хотим, и проверять их так, как хотим. Мы не хотим, чтобы Celery за нас это делал.
Мы используем pefork pool, то есть процесс-воркеры, которые создают для дополнительного concurrency отдельные форки процессов.
Unit of work
Обсудим базовые элементы, чтобы ввести в курс дела тех, кто еще не пробовал Celery, а только собирается. Unit of work для Celery — это задача. Приведу пример простой задачи, которая посылает email.
Простая функция и декоратор:
@current_app.task
def send_email(email: str):
print(f'Sending email to email={email}')
Запуск задачи прост: либо вызываем функцию и задача выполнится в runtime (send_email(email="python@example.com")), либо в воркере, то есть тот самый эффект задачи в фоне:
send_email.delay(email="python@example.com")
send_email.apply_async(
kwargs={email: "python@example.com"}
)
За два года работы с Celery при высоких нагрузках мы вывели правила хорошего тона. Было много граблей, мы научились их обходить, и я поделюсь как.
Оформление кода
В задаче может находиться различная логика. Вообще Celery способствует тому, чтобы вы держали задачки в файлах или в packages tasks, или импортировали их откуда-то. Иногда получается нагромождение бизнес-логики в одном модуле. На наш взгляд, тут правильный подход с точки зрения модульности приложения — держать минимум логики в задаче. Мы используем задачки только как «запускаторы» кода. То есть задача не несет в себе логику, а триггерит запуск кода в Background.
@celery_app.task(queue='...')
def run_regular_update(provider_account_id, *args, **kwargs):
"""..."""
flow = flows.RegularSyncProviderAccountFlow(provider_account_id)
return flow.run(*args, **kwargs)
Весь код мы выносим во внешние классы, которые используют еще какие-то классы. Все задачи по сути состоят из двух строчек.
Простые объекты в параметрах
В примере выше в задачу передается некий id. Во все задачи, которые мы используем, мы передаем только маленькие скалярные данные, id. Мы не сериализуем модели Django, чтобы их передавать. Даже в ETL, когда приходит из внешнего сервиса большой блоб данных, мы его сначала сохраняем и потом запускаем задачу, которая читает по id весь этот блоб и обрабатывает.
Если так не делать, то мы видели очень большие спайки потребляемой памяти у Redis. Сообщение начинает занимать больше памяти, сеть сильно загружается, количество обработанных задач (производительность) падает. Пока объект доходит до выполнения, задачи становятся не актуальными, объект уже удален. Данные нужно было сериализовать — не все хорошо сериализуется в JSON в Python. Нам нужна была возможность при retry задач как-то быстро решать, что делать с этими данными, получать их снова, запускать над ними какие-то проверки.
Если вы передаете большие данные в параметрах, одумайтесь! Лучше в задаче передавать маленький скаляр с малым количеством информации, и по этой информации в задаче получить все необходимое.
Идемпотентные задачи
Такой подход рекомендуют сами разработчики Celery. При повторном выполнении участка кода никаких побочных-эффектов произойти не должно, результат должен быть тот же. Не всегда этого просто добиться, особенно если идет взаимодействие с многими сервисами, или двухфазные коммиты.
Но когда вы все делаете локально, то всегда можете проверять, что входящие данные существуют и актуальны, над ними действительно можно совершить работу, и использовать транзакции. Если к одной задаче много запросов в базу и что-то может пойти не так во время выполнения — используйте транзакции, чтобы откатить ненужные изменения.
Обратная совместимость
Несколько интересных побочных эффектов было у нас при деплое приложения. Неважно, какой тип деплоя вы используете (blue+green или rolling update), всегда возникнет ситуация, когда старый код сервиса создает сообщения для нового кода воркера, и наоборот, старый воркер принимает сообщения от нового кода сервиса, потому что он раскатился «первее» и туда трафик пошел.
Мы ловили ошибки и теряли задачи, пока не научились поддерживать обратную совместимость между релизами. Обратная совместимость заключается в том, что между релизами задачи должны работать безопасно, независимо от того, какие параметры приходят в эту задачу. Поэтому во всех задачах мы сейчас делаем «резиновую» сигнатуру (**kwargs). Когда в следующем релизе вам потребуется добавить новый параметр, вы его из **kwargs возьмете в новом релизе, а в старом не возьмете — у вас ничего не сломается. Как только меняется сигнатура, а Celery об этом не знает, он падает и выдает ошибку, что такого параметра нет в задаче.
Более строгий способ избегать подобных проблем — это версионирование очередей задач между релизами, но он достаточно сложен в реализации и мы пока оставили его в беклоге.
Таймауты
Проблемы могут возникнуть из-за недостаточного количества или неправильных таймаутов.
Не ставить таймаут на задачу — это зло. Это значит, что вы не понимаете, что происходит в задаче, как должна работать бизнес-логика.
Поэтому все задачки у нас обвешаны таймаутами, в том числе глобальными для всех задач, и для каждой конкретной задачи тоже проставлены таймауты.
Обязательно должны быть проставлены: soft_limit_timeout и expires.
Expires — это сколько задача может жить в очереди. Нужно чтобы задачи не накапливались в очередях в случае проблем. Например, если мы сейчас хотим сообщить о чем-то пользователю, но что-то случилось, и задача может выполниться только завтра — в этом нет смысла, завтра сообщение уже будет неактуально. Поэтому на уведомления у нас достаточно маленький expires.
Обратите внимание на использование eta (countdown) + visibility_timeout. В FAQ описана такая проблема с Redis — так называемый visibility timeout у брокера Redis. По умолчанию его значение один час: если через час воркер видит, что задачу никто не взял к исполнению, то повторно добавляет ее в очередь. Таким образом, если countdown равен двум часам, уже через час брокер выяснит, что эта задача еще не выполнилась, и создаст еще одну такую же. А через два часа выполнится две одинаковых задачи.
Если estimation time или countdown превышают 1 час, то, скорее всего, при использовании Redis получится дублирование задач, если вы, конечно, не изменили значение visibility_timeout в настройках соединения с брокером.
Retry policy
Для тех задач, которые можно повторить, или которые могут выполниться с ошибками, мы используем Retry policy. Но используем аккуратно, чтобы не завалить внешние сервисы. Если быстро повторять задачи, не указывая exponential backoff, то внешний сервис, а может быть и внутренний, могут просто не выдержать.
Параметры retry_backoff, retry_jitter и max_retries хорошо бы указывать явно, особенно max_retries. retry_jitter — параметр, который позволяет внести немножко хаоса, чтобы задачи не начали повторятся одновременно.
Утечки памяти
К сожалению, утечки памяти возникают очень легко, а найти и исправить их сложно.
В целом работа с памятью у Python очень спорная. Вы потратите много времени и нервов, чтобы понять, почему происходит утечка, а потом выяснится, что она даже не в вашем коде. Поэтому всегда, начиная проект, проставляйте лимит памяти на воркер: worker_max_memory_per_child.
Это гарантирует, что однажды не придет OOM Killer, не убьет все воркеры, и вы не потеряете все задачи. Celery будет сам перезапускать воркеры, когда нужно.
Приоритет выполнения задач
Всегда есть задачи, которые нужно выполнять раньше всех, быстрее всех — они должны быть выполнены прямо сейчас! Есть задачи, которые не так важны — пусть выполнятся в течение дня. Для этого у задачи есть параметр priority. В Redis он работает достаточно интересно — создается новая очередь с именем, в которое добавляется priority.
Мы используем другой подход — отдельные воркеры для приоритетов, т.е. по старинке создаем воркеры для Celery с разными «важностями»:
celery multi start
high_priority low_priority
-c:high_priority 2 -c:low_priority 6
-Q:high_priority urgent_notifications
-Q:low_priority emails,urgent_notifications
Celery multi start — это хелпер, который помогает запустить всю конфигурацию Celery на одной машине и из одной командной строки. В этом примере мы создаем ноды (или воркеры): high_priority и low_priority, 2 и 6 — это concurrency.
Два воркера high_priority постоянно обрабатывают очередь urgent_notifications. Эти воркеры больше никто не займет, они будут только читать важные задачи из очереди urgent_notifications.
Для неважных задач есть low_priority очередь. Там 6 воркеров, которые принимают сообщения из всех остальных очередей. Также low_priority воркеры мы подписываем на urgent_notifications, чтобы они могли помочь, если воркеры с high_priority не будут справляться.
Мы используем эту классическую схему для приоритезации задач.
Extract, Transform, Load
Чаще всего ETL выглядит как цепочка задач, каждая из которых получает на вход данные из предыдущей задачи.
@task
def download_account_data(account_id)
…
return account_id
@task
def process_account_data(account_id, processing_type)
…
return account_data
@task
def store_account_data(account_data)
…
В примере три задачи. В Celery есть подход к distributed processing и несколько полезных утилит, в том числе функция chain, которая делает из трех таких задач один pipeline:
chain(
download_account_data.s(account_id),
process_account_data.s(processing_type='fast'),
store_account_data.s()
).delay()
Celery сам разберет pipeline, выполнит по порядку сначала первую задачу, потом полученные данные передаст во вторую, данные, которые вернет вторая задача, передаст в третью. Так мы реализуем простые ETL pipelines.
Для более сложных цепочек приходится подключать дополнительную логику. Но важно иметь в виду, что если в этом chain возникнет проблема в одной задаче, то весь chain развалится. Если вы не хотите такого поведения, то обрабатывайте exception и продолжайте выполнение, либо останавливайте всю цепочку по исключению.
На самом деле эта цепочка внутри выглядит как одна большая задача, в которой содержатся все задачи со всеми параметрами. Поэтому если злоупотребить количеством задач в цепочке, то получится очень высокое потребление памяти и замедление общего процесса. Создание цепочек из тысяч задач — плохая идея.
Пакетная обработка задач
Теперь самое интересное: что происходит, когда нужно отправить письмо двум миллионам пользователей.
Вы пишите такую функцию обхода всех пользователей:
@task
def send_report_emails_to_users():
for user_id in User.get_active_ids():
send_report_email.delay(user_id=user_id)
Правда, чаще всего функция будет получать не только id пользователей, но и вымывать вообще всю таблицу users. Для каждого пользователя будет запускаться своя задача.
В этой задаче есть несколько проблем:
- Задачи запускаются последовательно, то есть последняя задача (двухмиллионный пользователь) запустится минут через 20 и, может быть, к этому времени уже сработает таймаут.
- Загружаются все id пользователей сначала в память приложения, а потом в очередь — delay() выполнит 2 млн задач.
Я назвал это Task flood, на графике выглядит примерно так.
Возникает наплыв задач, которые воркеры потихонечку начинают обрабатывать. Происходит следующее, если задачи используют master-реплику, весь проект начинает просто трещать — ничего не работает. Ниже пример из нашей практики, где DB CPU Usage был 100 % несколько часов, мы, честно говоря, успели испугаться.

Проблема как раз в том, что система сильно деградирует с увеличением количества пользователей. Задача, которая занимается диспетчеризацией:
- требует больше и больше памяти;
- дольше выполняется и может быть «убита» по таймауту.
Происходит Task flooding: задачи накапливаются в очередях и создают большую нагрузку не только на внутренние сервисы, но и на внешние.
Мы пробовали уменьшать конкурентность воркеров, это помогает в каком-то смысле — снижаются нагрузки на сервис. Или можно масштабировать внутренние сервисы. Но это не решит проблему задачи-генератора, которая все еще очень много на себя берет. И никак не влияет на зависимость от производительности внешних сервисов.
Генерация задач
Мы решили пойти по другому пути. Чаще всего нам не нужно запускать все 2 млн задач прямо сейчас. Нормально, что рассылка уведомлений всем пользователям займет, например, 4 часа, если эти письма не так важны.
Сначала мы попробовали использовать Celery.chunks:
send_report_email.chunks(
({'user_id': user.id} for user in User.objects.active()),
n=100
).apply_async()
Это не изменило ситуацию, потому что, несмотря на итератор, все user_id будут загружены в память. И все воркеры получают цепочки задач, и хотя воркеры будут немного отдыхать, мы остались не удовлетворены этим решением в итоге.
Мы пробовали выставить rate_limit на воркеры, чтобы они обрабатывали только определенное количество задач в секунду, и выяснили, что на самом деле rate_limit указанный как для задачи, это rate_limit для воркера. То есть если вы указываете rate_limit для задачи, это не значит, что задача будет выполняться 70 раз в секунду. Это значит, что воркер ее будет выполнять 70 раз в секунду, и в зависимости от того, что у вас с воркерами, этот лимит может меняться динамически, т.е. реальный лимит rate_limit * len(workers).
Если воркер запускается или останавливается, то суммарный rate_limit меняется. Более того, если у вас задачи медленные, то весь prefetch в очереди, который наполняет воркер, будет забит этими медленными задачами. Воркер смотрит: «О, у меня эта задача в rate_limit-е, я ее больше не могу исполнять. И все следующие задачи в очереди точно такие же — пусть они повисят!» — и ждет.
Chunkificator
В итоге мы решили, что напишем свое, и сделали маленькую библиотеку, которую назвали Chunkificator.
@task
@chunkify_task(sleep_timeout=...l initial_chunk=...)
def send_report_emails_to_users(chunk: Chunk):
for user_id in User.get_active_ids(chunk=chunk):
send_report_email.delay(user_id=user_id)
Она принимает sleep_timeout и initial_chunk, и вызывает сама себя с новым chunk. Chunk — это абстракция либо над integer-списками, либо над date или datetime списками. Мы передаем chunk в функцию, которая получает пользователей только с этим chunk, и запускает задачи только для этого chunk.
Таким образом генератор задач запускает только то количество задач, которое нужно, и не потребляет много памяти. Картина стала такой.

Изюминки добавляет то, что мы используем sparse chunk, то есть мы используем в качестве chunk id инстансов в БД (некоторые из них могут быть пропущены, поэтому и задач может быть меньше). В итоге нагрузка получилась более равномерная, процесс стал дольше, но все живы-здоровы, база не напрягается.
Библиотека реализована для Python 3.6+ и доступна на GitHub. Есть нюанс, который я планирую исправить, но пока для datetime-chunk нужен pickle serializer — многие на это не смогут пойти.
Пара риторических вопросов — откуда вся эта информация взялась? Как мы узнали, что у нас были проблемы? Как узнать, что проблема скоро станет критична и её уже нужно начинать решать?
Ответ — это, конечно, мониторинг.
Мониторинг
Я очень люблю мониторинг, люблю все мониторить и держать руку на пульсе. Если вы не держите руку на пульсе, то вы будете постоянно наступать на грабли.
Стандартные вопросы мониторинга:
- Справляется ли текущая конфигурация worker/concurrency с нагрузкой?
- Какая есть деградация времени выполнения задач?
- Как долго задачи висят в очереди? Вдруг очередь уже переполнена?
Мы пробовали несколько вариантов. У Celery есть интерфейс CLI, он достаточно богат и дает:
- inspect — информацию о системе;
- control — управлять настройками системы;
- purge — очистить очереди (форс-мажор);
- events — консольный UI для отображения информации о выполняемых задачах.
Но в нем сложно реально что-то замониторить. Он лучше подходит для локальных изысков, или если вы хотите на runtime изменить какой-то rate_limit.
NB: нужен доступ к продакшен-брокеру, чтобы использовать интерфейс CLI.
Celery Flower позволяет сделать то же самое, что и CLI, только через веб-интерфейс, и то не всё. Зато строит некоторые простые графики и позволяет менять настройки «на лету».
В целом Celery Flower подходит, для того чтобы просто посмотреть, как все работает, в небольших сетапах. К тому же он поддерживает HTTP API, то есть удобен, если вы пишете автоматизацию.
Но мы остановились на Prometheus. Взяли текущий экспортер: пофиксили в нем утечки памяти; добавили метрики по типам exception; добавили метрики по количеству сообщений в очередях; интегрировали с aлертами в Grafana и радуемся. Он тоже выложен на GitHub, можно посмотреть здесь.
Примеры в Grafana

Выше статистика по всем исключениям: какие исключения для каких задач. Ниже время выполнение задач.

Чего не хватает в Celery?
Это развесистый фреймворк, в нем много всего, но нам не хватает! Не хватает маленьких фич, таких как:
- Автоматическая перезагрузка кода при разработке — не поддерживает это Celery — перезапускай.
- Метрики для Prometheus из коробки, а вот Dramatiq умеет.
- Поддержка task lock — чтобы только одна задача выполнялась в один момент времени. Это можно сделать самостоятельно, но в Dramatiq и в Tasktiger есть удобный декоратор, который гарантирует, что все остальные такие же задачи будут заблокированы.
- Rate_limit для одной задачи — не для воркера.
Выводы
Несмотря на то, что Celery — это фреймворк, которым многие пользуется в продакшене, он состоит из 3 библиотек — Celery, Kombu и Billiard. Все эти три библиотеки разрабатывают соразработчики, и они могут релизнуть одну зависимость и сломать вашу сборку.
Поэтому, надеюсь, что вы уже как-то разобрались и сделали ваши сборки детерминистическими.
На самом деле выводы не настолько печальные. Celery справляется со своими задачами в нашем финтех-проекте под нашей нагрузкой. Мы наработали опыт, которым я с вами поделился, и вы можете применить наши решения или доработать их и тоже преодолеть все свои трудности.
Не забывайте, что мониторинг должен являться основной частью вашего проекта. Только с помощью мониторинга вы сможете узнать, где же у вас что-то не так, что нужно поправить, добавить, исправить.
Контакты спикера Олега Чуркина: Bahusss, facebook и github.
Следующая большая Moscow Python Conf++ пройдет в Москве 5 апреля. В этом году мы в экспериментальном режиме попробуем уместить всю пользу в один день. Докладов будет не меньше, целый поток выделим иностранным разработчикам известных библиотек и продуктов. К тому же пятница — идеальный день для афтерпати, которая, как известно, является неотъемлемой составляющей конференции про общение.
Присоединяйтесь к нашей профессиональной Python-конференции — подавать доклад здесь, бронировать билет здесь. А пока идет подготовка, здесь будут появляться статьи по Moscow Python Conf++ 2018.
