
HighLoad++ существует давно, и про работу с PostgreSQL мы говорим регулярно. Но у разработчиков все равно из месяца в месяц, из года в год возникают одни и те же проблемы. Когда в маленьких компаниях без DBA в штате случаются ошибки в работе с базами данных, в этом нет ничего удивительного. В крупных компаниях тоже нужны БД, и даже при отлаженных процессах все равно случаются ошибки, и базы падают. Неважно, какого размера компания — ошибки все равно бывают, БД периодически обваливаются, рушатся.
С вами такого, конечно, никогда не случится, но проверить чек-лист не трудно, а сэкономить будущих нервов он может очень прилично. Под катом перечислим топ типичных ошибок, которые совершают разработчики при работе с PostgreSQL, разберемся, почему так делать не надо, и выясним, как надо.
О спикере: Алексей Лесовский (lesovsky) начинал системным администратором Linux. От задач виртуализации и систем мониторинга постепенно пришел к PostgreSQL. Сейчас PostgreSQL DBA в Data Egret — консалтинговой компании, которая работает с большим количеством разных проектов и видит много примеров повторяющихся проблем. Это ссылка на презентацию доклада на HighLoad++ 2018.
Для разминки, несколько историй о том, как возникают ошибки.
Одна из проблем — это то, какими фичами пользуется компания при работе с PostgreSQL. Начинается все просто: PostgreSQL, наборы данных, простые запросы с JOIN. Берем данные, делаем SELECT — все просто.
Потом начинаем использовать дополнительную функциональность PostgreSQL, добавляем новые функции, расширения. Фич становится больше. Подключаем потоковую репликацию, шардирование. Вокруг появляются разные утилиты и обвесы — pgbouncer, pgpool, patroni. Примерно так.

То, как мы храним данные, тоже источник ошибок.
Когда проект только появился, в нем довольно мало данных и таблиц. Достаточно простых запросов, чтобы получать и записывать данные. Но потом таблиц становится все больше. Данные выбираются из разных мест, появляются JOIN. Запросы усложняются и включают в себя CTE-конструкции, SUBQUERY, IN-списки, LATERAL. Допустить ошибку и написать кривой запрос становится гораздо легче.
И это только верхушка айсберга — где-то сбоку могут быть еще 400 таблиц, партиций, из которых тоже изредка читаются данные.
История о том, как продукт сопровождается. Данные всегда нужно где-то хранить, поэтому всегда есть базы данных. Как развивается БД, когда развивается продукт?
С одной стороны, есть разработчики, которые заняты языками программирования. Они пишут свои приложения и развивают навыки в области разработки ПО, не обращая внимания на сервисы. Часто им неинтересно, как работает Kafka или PostgreSQL — они разрабатывают новые фичи в своем приложении, и до остального им дела нет.
С другой стороны — админы. Они поднимают новые инстансы в Amazon на Bare-metal и заняты автоматизацией: настраивают деплой, чтобы хорошо работала выкладка, и конфиги, чтобы сервисы хорошо взаимодействовали между собой.

Складывается ситуация, когда на тонкий тюнинг компонентов, и БД в том числе, не остается времени или желания. Базы работают с дефолтными конфигами, а потом про них и вовсе забывают — «работает, не трогай».
В итоге в самых разных местах разбросаны грабли, которые то и дело прилетают в лоб разработчикам. В этой статье постараемся все эти грабли собрать в один сарайчик, чтобы вы про них знали и при работе с PostgreSQL на них не наступали.
Сначала представим, что у нас есть новый проект — это всегда активная разработка, проверка гипотез и реализация новых фич. В момент, когда приложение только-только появилось и развивается, у него мало трафика, пользователей и клиентов, и все они генерируют небольшие объемы данных. В БД работают простые запросы, которые быстро отрабатываются. Не нужно тягать большие объемы данных, нет никаких проблем.
Но вот пользователей больше, приходит трафик: появляются новые данные, базы растут и старые запросы перестают работать. Нужно достраивать индексы, переписывать и оптимизировать запросы. Появляются проблемы производительности. Все это приводит к алертам в 4 утра, стрессу для админов и недовольству руководства.
Первый пример. Открываем график мониторинга утилизации диска, и видим, что заканчивается свободное пространство на диске.
Смотрим сколько места и чем съедено — оказывается, есть каталог pg_xlog:
Админы баз данных обычно знают, что это за каталог, и его не трогают — существует и существует. Но разработчик, особенно если он смотрит на staging, чешет голову и думает:
— Какие-то логи… Давайте удалим pg_xlog!
Удаляет каталог, база перестает работать. Тут же приходится гуглить, как поднять базу после того, как удалил журналы транзакций.
Второй пример. Опять открываем мониторинг и видим, что места не хватает. На сей раз место занято какой-то базой.
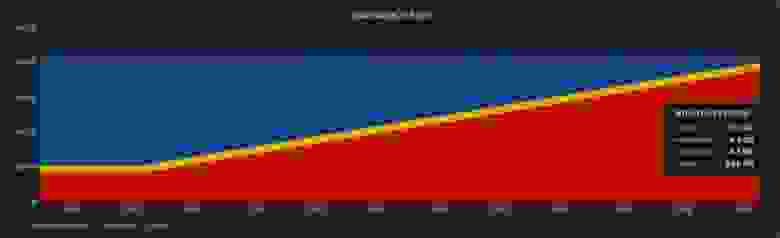
Ищем, какая база занимает больше всего места, какие таблицы и индексы.
Выясняется, что это таблица с историческими логами. Исторические логи нам никогда были не нужны. Они пишутся на всякий случай, и, если бы не проблема с местом, в них бы никто не смотрел до второго пришествия:
— Давайте, зачистим всё, что мм… старше октября!
Составим update-запрос, запустим его, он отработает и удалит часть строк.
Запрос работает 10 минут, но таблица по-прежнему занимает столько же места.
PostgreSQL удаляет строки из таблицы — все верно, но он не возвращает место операционной системе. Такое поведение PostgreSQL неизвестно большинству разработчиков и может сильно удивить.
Третий пример. Например, ОРМ составил интересный запрос. Обычно все винят ОРМ в том, что они составляют «плохие» запросы, которые вычитывают несколько таблиц.
Допустим, там несколько операций JOIN, которые читают таблицы параллельно в несколько потоков. PostgreSQL умеет параллелить операции работы с данными и может читать таблицы в несколько потоков. Но, учитывая, что у нас несколько серверов приложений, этот запрос вычитывает все таблицы несколько тысяч раз в секунду. Получается, что сервер баз данных перегружается, диски не справляются, и все это приводит к ошибке 502 Bad Gateway c бэкенда — база недоступна.
Но это еще не все. Можно вспомнить про другие особенности PostgerSQL.
Как быть? Нужен мониторинг и планирование! Казалось бы — очевидно, но почему-то в большинстве случаев никто не планирует базу, а мониторинг не покрывает всего того, что нужно отслеживать при эксплуатации PostgreSQL. Есть набор четких правил, при соблюдении которых все будет работать хорошо, а не «на авось».
Размещайте базу данных на SSD не раздумывая. SSD давно стали надежными, стабильными и производительными. Энтерпрайзные модели SSD работают годами.
Всегда планируйте схему данных. Не пишите в БД то, что вы сомневаетесь, что понадобится — гарантированно не понадобится. Простой пример — немного измененная таблица одного из наших клиентов.
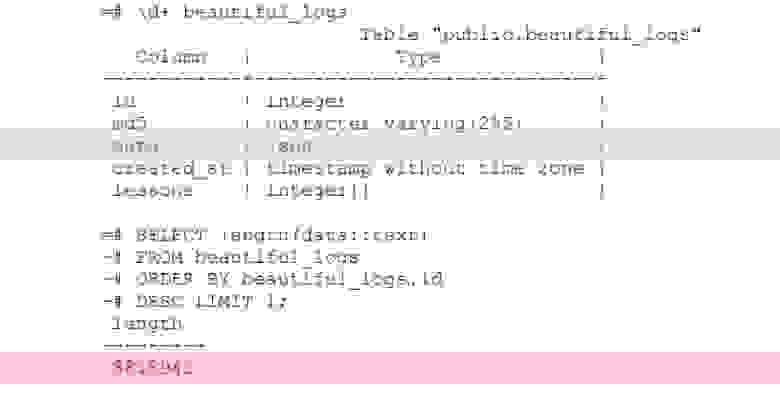
Это таблица логов, в которой есть колонка data с типом json. Условно говоря, в эту колонку можно записать что угодно. Из последней записи этой таблицы видно, что логи занимают 8 Мб. В PostgreSQL нет проблем с хранением записей такой длины. У PostgreSQL очень хороший storage, который прожёвывает такие записи.
Но проблема в том, что когда серверы приложений будут вычитывать данные из этой таблицы, они запросто забьют всю пропускную способность сети, и другие запросы будут страдать. В этом заключается проблема планирования схемы данных.
Используйте партиционирование при любых намеках на историю, которую необходимо хранить больше двух лет. Партиционирование иногда кажется сложным — нужно заморачиваться с триггерами, с функциями, которые будут создавать партиции. В новых версиях PostgreSQL ситуация лучше и сейчас настройка партиционирования сильно проще — один раз сделал, и работает.
В рассмотренном пример удаления данных за 10 минут,
Когда данные рассортированы по партициям, партиция удаляется буквально за несколько миллисекунд, и место ОС отдается сразу. Управлять историческими данными так легче, проще и безопаснее.
Мониторинг — отдельная большая тема, но с точки зрения БД есть рекомендации, которые можно уместить в один раздел статьи.
По умолчанию многие системы мониторинга предоставляют мониторинг процессоров, памяти, сети, дискового пространства, но, как правило, нет утилизации дисковых устройств. Информацию о том, насколько загружены диски, какая пропускная способность в данный момент на дисках и значение latency, нужно всегда добавлять в мониторинг. Это поможет быстро оценить, как загружены диски.
Вариантов мониторинга PostgreSQL очень много, есть на любой вкус. Вот некоторые моменты, которые обязательно должны присутствовать.
За более детальной информацией обратитесь к докладу «Основы мониторинга PostgreSQL» с HighLoad++ Siberia и страницу Monitoring в PostgreSQL Wiki.
Когда мы все спланировали и «обмазались» мониторингом, мы все равно можем столкнуться с некоторыми проблемами.
Обычно разработчик видит БД строчкой в конфиге. Ему не особо интересно, как она устроена внутри — как работает checkpoint, репликация, планировщик. Разработчику и так есть, чем заняться — в todo стоит много интересных вещей, которые ему хочется попробовать.
Незнание предмета приводит к довольно интересным последствиям, когда разработчик начинает писать запросы, которые работают в этой базе. Фантазии при написании запросов порой дают ошеломляющие эффекты.
Есть два типа транзакций. OLTP транзакции — быстрые, короткие, легкие, которые выполняются доли миллисекунд. Они отрабатывают очень быстро, и их очень много. OLAP — аналитические запросы — медленные, долгие, тяжелые, читают большие массивы таблиц и считают статистику.
Последние 2-3 года часто звучит аббревиатура HTAP — Hybrid Transaction / Analytical Processing или гибридный транзакционно-аналитический процессинг. Если вам некогда думать над масштабированием и разнесением OLAP и OLTP запросов, можно говорить: «У нас HTAP!» Но опыт и боль ошибок показывают, что все-таки разные типы запросов должны жить отдельно друг от друга, потому что долгие запросы OLAP блокируют легкие OLTP-запросы.
Так мы подходим к вопросу, как масштабировать PostgreSQL так, чтобы разнести нагрузку, и все остались довольны.
Streaming replication. Самый простой вариант — потоковая репликация. Когда приложение работает с базой, подключаем к этой базе несколько реплик и распределяем нагрузку. Запись по-прежнему идет в мастер-базу, а чтение на реплики. Такой способ позволяет масштабироваться очень широко.
Плюс к отдельным репликам можно подключить еще реплики и получить каскадную репликацию. Отдельные группы пользователей или приложения, которое, например, читает аналитику, можно вынести на отдельную реплику.
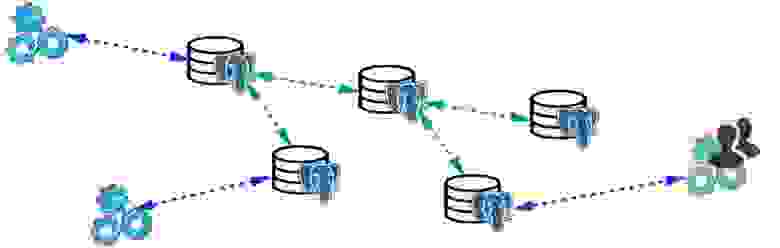
Logical publications, subscriptions — механизм логических публикаций и подписок предполагает наличие нескольких независимых PostgreSQL-серверов с отдельными базами и наборами таблиц. Эти наборы таблиц можно подключать в соседние базы, они будут видны приложениям, которые смогут ими нормально пользоваться. То есть все изменения, которые происходят в источнике, реплицируются на базу назначения и там видны. Прекрасно работает с PostgreSQL 10.
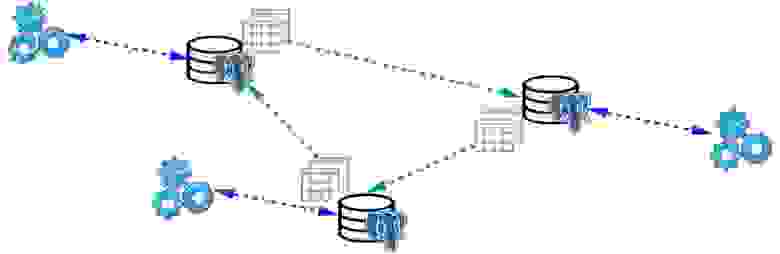
Foreign tables, Declarative Partitioning — декларативное партиционирование и внешние таблицы. Можно взять несколько PostgreSQL и создать там несколько наборов таблиц, которые будут хранить нужные диапазоны данных. Это могут быть данные за конкретный год или данные, собранные по любому range.
С помощью механизма внешних таблиц можно объединить все эти базы в виде партиционированной таблицы в отдельной PostgreSQL. Приложение может работать уже с этой партиционированной таблицей, но на самом деле оно будет читать данные с удаленных партиций. Когда объемы данных больше возможностей одного сервера, то это шардинг.
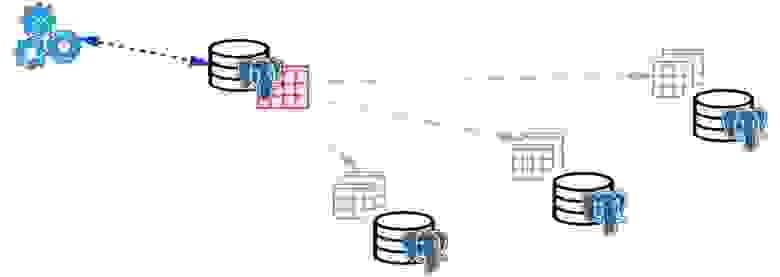
Это все можно объединять в развесистые конфигурации, придумывать разные топологии репликации PostgreSQL, но как все это будет работать и как этим управлять — тема отдельного доклада.
Самый простой вариант — с репликации. Первый шаг — разнести нагрузку на чтение и на запись. То есть писать в мастер, а читать с реплик. Так мы масштабируем нагрузку и выносим чтение с мастера. Кроме того, не забываем про аналитиков. Аналитические запросы работают долго, для них нужна отдельная реплика с отдельными настройками, чтобы долгие аналитические запросы могли не мешать остальным.
Следующий шаг — балансировка. У нас по-прежнему остается та самая строчка в конфиге, которой оперирует разработчик. Ему нужно место, куда он будет писать и читать. Здесь есть несколько вариантов.
Идеальный — реализовывать балансировку на уровне приложения, когда приложение само знает, откуда ему читать данные, и умеет выбирать реплику. Допустим, баланс счета всегда нужен актуальный и его нужно прочитать с мастера, а картинку товара или информацию о нем можно прочитать с некоторой задержкой и сделать это с реплики.
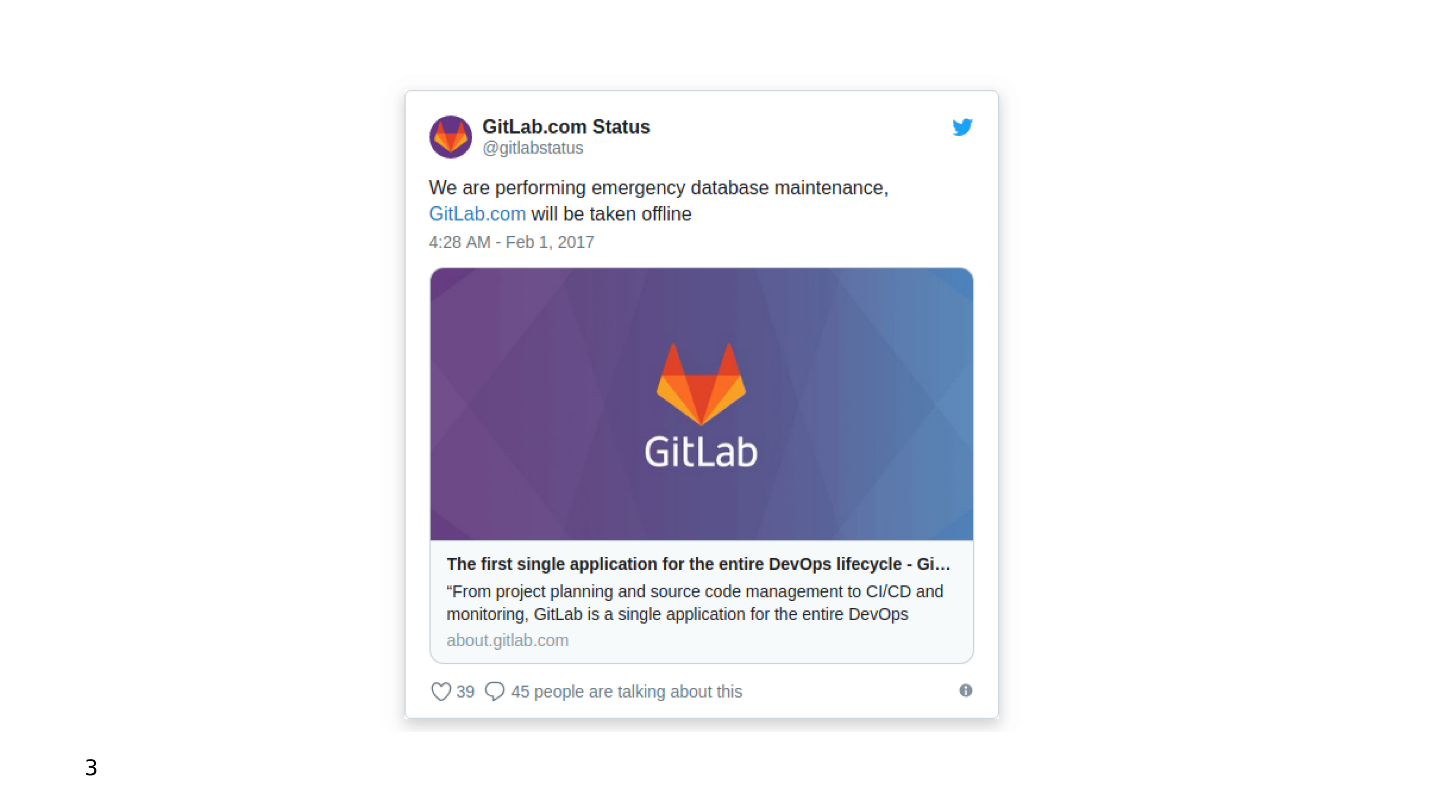
И с репликацией бывают нюансы, самый частый из них — лаг репликации. Можно сделать, как GitLab, и когда накопится лаг, просто дропнуть базу. Но у нас же есть всесторонний мониторинг — смотрим его и видим долгие транзакции.

В общем случае медленные и ничего не делающие транзакции приводят к:
Рассмотрим немного теории о том, как же возникают эти проблемы, и почему механизм долгих и ничего не делающих транзакций (idle transactions) вреден.
В PostgreSQL есть MVCC — условно говоря, движок БД. Он позволяет клиентам конкурентно работать с данными, не мешая при этом друг другу: читатели не мешают читателям, а писатели не мешают писателям. Конечно, есть некоторые исключения, но в данном случае они не важны.
Получается, что в базе для одной строки может существовать несколько версий для разных транзакций. Клиенты подключаются, база выдает им снимки данных, и в рамках этих снимков могут существовать разные версии одной и той же строки. Соответственно, в жизненном цикле базы транзакции сдвигаются, заменяют друг друга, и появляются версии строк, которые уже никому не нужны.
Так возникает необходимость в сборщике мусора — auto vacuum. Долгие транзакции существуют и мешают auto vacuum вычистить ненужные версии строк. Эти мусорные данные начинают кочевать из памяти на диск, из диска в память. На то, чтобы хранить этот мусор, тратятся ресурсы CPU и памяти.
С точки зрения «Кто виноват?», в появлении долгих транзакций виновато именно приложение. Если база будет существовать сама по себе, долгие, ничего не делающие транзакции ниоткуда не возьмутся. На практике же есть следующие варианты появления idle транзакций.
«Давайте сходим во внешний источник». Приложение открывает транзакцию, что-то делает в базе, потом решает обратиться к внешнему источнику, например, Memcached или Redis, в надежде, что потом вернется в базу, продолжит работу и закроет транзакцию. Но если во внешнем источнике происходит ошибка, приложение падает, и транзакция остается незакрытой, пока ее кто-нибудь не заметит и не убьет.
Нет обработки ошибок. С другой стороны, может быть проблема обработки ошибок. Когда опять же приложение открыло транзакцию, решило какую-то задачу в базе, вернулось к исполнению кода, выполнило какие-то функции и вычисления, чтобы дальше продолжить работу в транзакции и закрыть ее. Когда на этих вычисления работа приложения прервалась с ошибкой, код вернулся в начало цикла, а транзакция опять осталась незакрытой.
Человеческий фактор. Например, админ, разработчик, аналитик, работает в каком-нибудь pgAdmin или в DBeaver — открыл транзакцию, что-то в ней делает. Потом человека отвлекли, он переключился на другую задачу, потом на третью, забыл про транзакцию, ушел на выходные, а транзакция продолжает висеть. Производительность базы страдает.
Давайте разберем, что делать в этих случаях.
Все становится еще интересней, когда появляются отложенные задачи, например, нужно аккуратно посчитать агрегаты. И мы подходим к вопросу велосипедостроения.
Больная тема. Бизнесу со стороны приложения нужно производить фоновую обработку событий. Например, рассчитывать агрегаты: минимальное, максимальное, среднее значение, рассылать уведомления пользователям, выставлять счета клиентам, настраивать кабинет пользователя после регистрации или регистрировать в соседних сервисах — делать отложенную обработку.
Суть у таких задач одна — они откладываются на потом. В базе появляются таблицы, которые как раз осуществляют очереди.
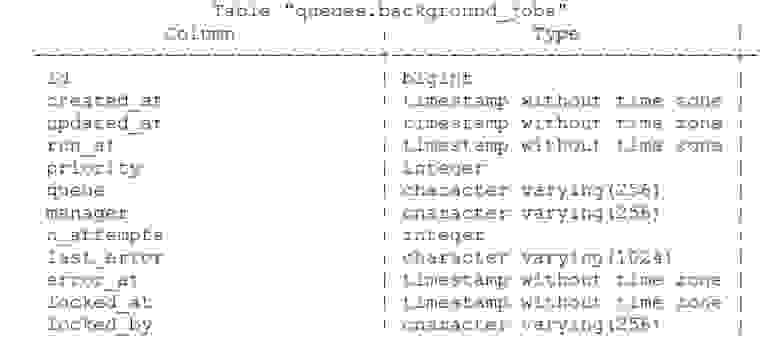
Здесь есть идентификатор задачи, время, когда задача была создана, когда обновлена, хэндлер, который её взял, количество попыток выполнения. Если у вас есть таблица, которая хотя бы отдаленно напоминает эту, значит, у вас есть самописные очереди.
Все это работает прекрасно, пока не появляются долгие транзакции. После этого таблицы, которые работают с очередями, распухают в размерах. Новые jobs все время добавляются, старые удаляются, происходят апдейты — получается таблица с интенсивной записью. Её нужно регулярно чистить от устаревших версий строк, чтобы не страдала производительность.
Растет время обработки — долгая транзакция удерживает блокировку на устаревшие версии строк или мешает vacuum ее почистить. Когда таблица увеличивается в размерах, время обработки тоже увеличивается, так как нужно прочитать много страниц с мусором. Время увеличивается, и очередь в какой-то момент перестает работать вообще.
Ниже пример топа одного нашего заказчика, у которого была самописная очередь. Все запросы как раз связаны с очередью.

Обратите внимание на время выполнения этих запросов — все, кроме одного, работают по двадцать с лишним секунд.
Чтобы решить эти проблемы давно изобретен Skytools PgQ — менеджер очередей для PostgreSQL. Не изобретайте свой велосипед — возьмите PgQ, один раз настройте и забудьте про очереди.
Правда, и у него есть особенности. У Skytools PgQ мало документации. После чтения официальной страницы, складывается ощущение, что ничего не понял. Ощущение растет, когда что-то пробуешь сделать. Все работает, но как работает — не понятно. Какая-то джедайская магия. Но многую информацию можно получить в Mailing-lists. Это не очень удобный формат, но много интересного находится именно там, и эти листы придется читать.
Несмотря на минусы, Skytools PgQ работает по принципу «настроил и забыл». Создается триггерная функция, которая вешается на таблицу, с которой хотим получать изменения, и все работает надежно. Практически про PgQ вспоминают, когда нужно добавить еще одну таблицу в очередь. Использовать PgQ дешевле, чем поддержка и настройка отдельных брокеров.
В своей практике мы выпилили очень много самописных очередей и заменили их на PgQ. Конечно, бывают большие инсталляции PostgreSQL, например, в Авито, где возможностей PgQ не хватает. Но это единичные кейсы, которые решаются отдельно.
Админы хотят от автоматизации получить возможность раскатывать инстансы, чтобы деплой работал без их вмешательства и конфиги раскатывались мгновенно. А разработчики хотят, чтобы деплой работал так, чтобы, как только они закомитили какие-то изменения, они дальше подтянулись, оттестировались, разлились и все бы было хорошо. Конечно, они хотят катить миграции без ручного вмешательства, чтобы не надо было логиниться на сервер, руками выполнять alter.
Все вместе они хотят auto-failover — если вдруг во время работы кластера PostgreSQL произойдет какой-нибудь сбой, роль мастера автоматически перекинется на другой сервер, а мы об этом даже ничего не знали. Но есть несколько очень серьёзных проблем, которые мешают использованию auto-failover.
Split-brain. В нормальном кластере PostgreSQL с мастером и несколькими репликами, запись идет в один сервер, чтение — с реплик. Если происходит сбой, то сервер выключается. Но в PostgreSQL из коробки нет механизма fencing, и часто даже в Kubernets его приходится настраивать отдельно. При сбое приложение может по-прежнему писать в старый мастер, а новое переключившееся приложение начинает писать в новый мастер. Возникает ситуация Split-brain.
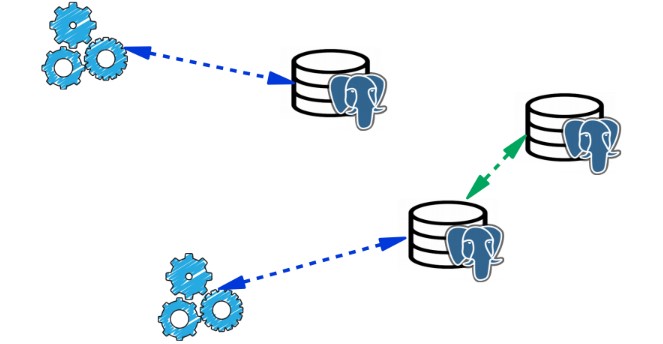
Попытка восстановить консистентность может быть очень тяжелой и потребует много нервов. Когда GitHub столкнулся со Split-brain, им пришлось восстанавливать свою базу из бэкапа.
Cascade failover. Допустим, есть мастер и несколько реплик. Мастер падает, и нагрузка переключается на новый мастер и оставшиеся реплики.
Старый мастер не успел переинициализироваться и стать репликой, а в этот момент падает другой мастер. На это уходят секунды, и вся нагрузка приходится на единственный сервер.
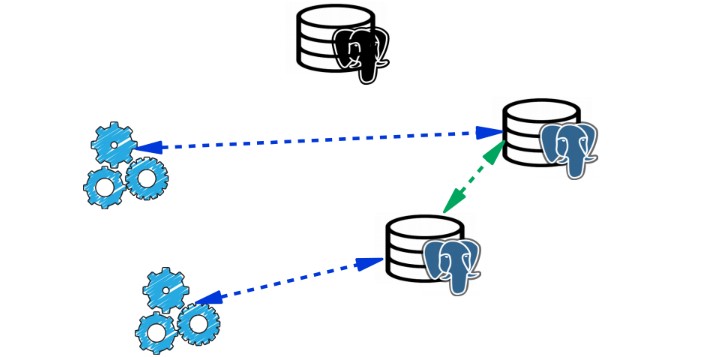
Он не справляется с нагрузкой и тоже отказывает — получается каскадный failover.
Если все же браться за auto-failover, то есть следующие пути.
Bash скрипты — хрупкое решение, которое нужно постоянно тестировать и отлаживать. Один админ ушел, другой пришел и не знает, как этим пользоваться. Если вдруг что-то сломалось, очень тяжело найти, где что произошло. Такое решение требует постоянной доработки.
Ansible playbooks — bash-скрипты на стероидах. Тоже нужно постоянно проверять, что все работает, прогонять на тестовых кластерах.
Patroni — на мой взгляд, один из лучших продуктов, потому что у него есть auto-failover, мониторинг состояния кластера, плюс функция отдачи топологии кластера в service discovery.
PAF — основан на Pacemaker. Тоже интересный инструмент для auto-failover в PostgreSQL, но он уже сложнее и требует знания Pacemaker.
Stolon больше предназначен для облачных задач. Для Kubernetes, например. Stolon сложнее Patroni, но они взаимозаменяемы и можно выбирать между ними.
В последние годы Docker и Kubernetes растут. Это динамично развивающиеся технологии, в которых появляется много нового.
В каждой новой версии добавляется много интересной функциональности, правда при этом старая может перестать работать. С «А что если развернуть базу в Kubernetes...» начинаются разные удивительные истории.
База — это всегда stateful, ее нужно где-то хранить. Где? На ум приходит отказоустойчивое сетевое хранилище. Решения из Open Source: CEPH, GlusterFS, LinStor DRBD. Фундаментальная проблема в том, что все это работает очень медленно и, наверное, никогда не станет работать быстро.
Бонусом вы получаете дополнительную головную боль — необходимость поддерживать кластерную файловую систему. Например, если вы знакомы только с Kubernetes, вам придется глубоко изучить CEPH. Это сложная система с большим багажом своих проблем — придется наращивать свою экспертизу. Если говорить в целом про сетевые хранилища и базы в них, то это работает пока выполняется три требования.
Этот подводит нас к тому, что хорошо использовать Kubernetes и Docker для БД на staging или dev-серверах либо на этапе проверки гипотез. Но для высоких нагрузок, на мой взгляд, Kubernetes и шаредные хранилища не очень хороши.
Но если сильно хочется, то оптимальным вариантом будут local volumes — локальные хранилища без использования шаредных файловых систем, streaming replication — нативная потоковая репликация, через которую идет синхронизация данных и PostgreSQL-операторы, которые предоставляют нам нечто вроде кнопки — нажал, и все заработало. На данный момент есть два таких оператора: Zalando и Crunchy.
Конечно же стоит помнить, что это все динамично развивается. Посмотрите на количество issues и pull requests. Появляются новые фичи, в них могут скрываться ошибки, поэтому внедряйте контейнеризацию без фанатизма.
Когда вы занимаетесь планированием и мониторингом не экономьте на SSD — они относительно дешевы и оттянут проблемы с производительностью на год, а то и больше.
Не пишите в базу все подряд. Практика писать JSON на 8 Мб — это плохо, так делать нельзя.
Мониторинг нужен, причем не оставляйте его в дефолтно настроенном состоянии. Мониторьте PostgreSQL, расширяйте ваш мониторинг.
Разносите нагрузку — Postgres is ready. Старайтесь не читать и не писать данные из одного места. PostgreSQL очень хорошо масштабируется, и есть варианты его масштабирования на любой вкус. Для масштабирования нагрузки используйте: streaming replication; publications, subscriptions; foreign Tables; declarative partitioning.
Избегайте ничего не делающих транзакций. Они снижают производительность и очень медленно, но верно убивают базу.
Если вы делаете что-то, что уже могло понадобиться другим людям, посмотрите вокруг — возможно все уже есть. Это напрямую касается очередей. Не изобретайте самописные очереди, используйте Skytools PgQ!
Если очень хочется базу в Kubernetes, используйте local volumes, streaming replication и PostgreSQL операторы. С этим можно хоть как-то работать, но без фанатизма, потому что все очень быстро меняется.

С вами такого, конечно, никогда не случится, но проверить чек-лист не трудно, а сэкономить будущих нервов он может очень прилично. Под катом перечислим топ типичных ошибок, которые совершают разработчики при работе с PostgreSQL, разберемся, почему так делать не надо, и выясним, как надо.
О спикере: Алексей Лесовский (lesovsky) начинал системным администратором Linux. От задач виртуализации и систем мониторинга постепенно пришел к PostgreSQL. Сейчас PostgreSQL DBA в Data Egret — консалтинговой компании, которая работает с большим количеством разных проектов и видит много примеров повторяющихся проблем. Это ссылка на презентацию доклада на HighLoad++ 2018.
Откуда берутся проблемы
Для разминки, несколько историй о том, как возникают ошибки.
История 1. Фичи
Одна из проблем — это то, какими фичами пользуется компания при работе с PostgreSQL. Начинается все просто: PostgreSQL, наборы данных, простые запросы с JOIN. Берем данные, делаем SELECT — все просто.
Потом начинаем использовать дополнительную функциональность PostgreSQL, добавляем новые функции, расширения. Фич становится больше. Подключаем потоковую репликацию, шардирование. Вокруг появляются разные утилиты и обвесы — pgbouncer, pgpool, patroni. Примерно так.

Каждое ключевое слово — повод появиться ошибке.
История 2. Хранение данных
То, как мы храним данные, тоже источник ошибок.
Когда проект только появился, в нем довольно мало данных и таблиц. Достаточно простых запросов, чтобы получать и записывать данные. Но потом таблиц становится все больше. Данные выбираются из разных мест, появляются JOIN. Запросы усложняются и включают в себя CTE-конструкции, SUBQUERY, IN-списки, LATERAL. Допустить ошибку и написать кривой запрос становится гораздо легче.

И это только верхушка айсберга — где-то сбоку могут быть еще 400 таблиц, партиций, из которых тоже изредка читаются данные.
История 3. Жизненный цикл
История о том, как продукт сопровождается. Данные всегда нужно где-то хранить, поэтому всегда есть базы данных. Как развивается БД, когда развивается продукт?
С одной стороны, есть разработчики, которые заняты языками программирования. Они пишут свои приложения и развивают навыки в области разработки ПО, не обращая внимания на сервисы. Часто им неинтересно, как работает Kafka или PostgreSQL — они разрабатывают новые фичи в своем приложении, и до остального им дела нет.

С другой стороны — админы. Они поднимают новые инстансы в Amazon на Bare-metal и заняты автоматизацией: настраивают деплой, чтобы хорошо работала выкладка, и конфиги, чтобы сервисы хорошо взаимодействовали между собой.

Складывается ситуация, когда на тонкий тюнинг компонентов, и БД в том числе, не остается времени или желания. Базы работают с дефолтными конфигами, а потом про них и вовсе забывают — «работает, не трогай».
В итоге в самых разных местах разбросаны грабли, которые то и дело прилетают в лоб разработчикам. В этой статье постараемся все эти грабли собрать в один сарайчик, чтобы вы про них знали и при работе с PostgreSQL на них не наступали.
Планирование и мониторинг
Сначала представим, что у нас есть новый проект — это всегда активная разработка, проверка гипотез и реализация новых фич. В момент, когда приложение только-только появилось и развивается, у него мало трафика, пользователей и клиентов, и все они генерируют небольшие объемы данных. В БД работают простые запросы, которые быстро отрабатываются. Не нужно тягать большие объемы данных, нет никаких проблем.
Но вот пользователей больше, приходит трафик: появляются новые данные, базы растут и старые запросы перестают работать. Нужно достраивать индексы, переписывать и оптимизировать запросы. Появляются проблемы производительности. Все это приводит к алертам в 4 утра, стрессу для админов и недовольству руководства.
Что не так?
По моему опыту, чаще всего не хватает дисков.
Первый пример. Открываем график мониторинга утилизации диска, и видим, что заканчивается свободное пространство на диске.

Смотрим сколько места и чем съедено — оказывается, есть каталог pg_xlog:
$ du -csh -t 100M /pgdb/9.6/main/*
15G /pgdb/9.6/main/base
58G /pgdb/9.6/main/pg_xlog
72G итогоАдмины баз данных обычно знают, что это за каталог, и его не трогают — существует и существует. Но разработчик, особенно если он смотрит на staging, чешет голову и думает:
— Какие-то логи… Давайте удалим pg_xlog!
Удаляет каталог, база перестает работать. Тут же приходится гуглить, как поднять базу после того, как удалил журналы транзакций.
Второй пример. Опять открываем мониторинг и видим, что места не хватает. На сей раз место занято какой-то базой.

$ du -csh -t 100M /pgdb/9.6/main/*
70G /pgdb/9.6/main/base
2G /pgdb/9.6/main/pg_xlog
72G итогоИщем, какая база занимает больше всего места, какие таблицы и индексы.
Выясняется, что это таблица с историческими логами. Исторические логи нам никогда были не нужны. Они пишутся на всякий случай, и, если бы не проблема с местом, в них бы никто не смотрел до второго пришествия:
— Давайте, зачистим всё, что мм… старше октября!
Составим update-запрос, запустим его, он отработает и удалит часть строк.
=# DELETE FROM history_log
-# WHERE created_at < «2018-10-01»;
DELETE 165517399
Time: 585478.451 msЗапрос работает 10 минут, но таблица по-прежнему занимает столько же места.
PostgreSQL удаляет строки из таблицы — все верно, но он не возвращает место операционной системе. Такое поведение PostgreSQL неизвестно большинству разработчиков и может сильно удивить.
Третий пример. Например, ОРМ составил интересный запрос. Обычно все винят ОРМ в том, что они составляют «плохие» запросы, которые вычитывают несколько таблиц.
Допустим, там несколько операций JOIN, которые читают таблицы параллельно в несколько потоков. PostgreSQL умеет параллелить операции работы с данными и может читать таблицы в несколько потоков. Но, учитывая, что у нас несколько серверов приложений, этот запрос вычитывает все таблицы несколько тысяч раз в секунду. Получается, что сервер баз данных перегружается, диски не справляются, и все это приводит к ошибке 502 Bad Gateway c бэкенда — база недоступна.
Но это еще не все. Можно вспомнить про другие особенности PostgerSQL.
- Тормоза фоновых процессов СУБД — в PostgreSQL есть всякие checkpoint’ы, vacuum’ы, репликация.
- Накладные расходы от виртуализации. Когда база запущена на виртуальной машине, на этой же железке сбоку есть еще виртуальные машины, и они могут конфликтовать за ресурсы.
- Хранилище от китайского производителя NoName, производительность которого зависит от Луны в Козероге или положения Сатурна, и разобраться, почему оно работает именно так, нет возможности. База страдает.
- Дефолтные конфигурации. Это моя любимая тема: заказчик говорит, что у него тормозит база — смотришь, а у него дефолтный конфиг. Дело в том, что дефолтный конфиг PostgreSQL предназначен для того, чтобы запускаться на самом слабом чайнике. База запускается, работает, но когда она работает уже на железе среднего уровня, то этого конфига недостаточно, его нужно тюнить.
Чаще всего PostgreSQL не хватает либо дискового пространства, либо дисковой производительности. К счастью, с процессорами, памятью, сетью, как правило, все более-менее в порядке.
Как быть? Нужен мониторинг и планирование! Казалось бы — очевидно, но почему-то в большинстве случаев никто не планирует базу, а мониторинг не покрывает всего того, что нужно отслеживать при эксплуатации PostgreSQL. Есть набор четких правил, при соблюдении которых все будет работать хорошо, а не «на авось».
Планирование
Размещайте базу данных на SSD не раздумывая. SSD давно стали надежными, стабильными и производительными. Энтерпрайзные модели SSD работают годами.
Всегда планируйте схему данных. Не пишите в БД то, что вы сомневаетесь, что понадобится — гарантированно не понадобится. Простой пример — немного измененная таблица одного из наших клиентов.

Это таблица логов, в которой есть колонка data с типом json. Условно говоря, в эту колонку можно записать что угодно. Из последней записи этой таблицы видно, что логи занимают 8 Мб. В PostgreSQL нет проблем с хранением записей такой длины. У PostgreSQL очень хороший storage, который прожёвывает такие записи.
Но проблема в том, что когда серверы приложений будут вычитывать данные из этой таблицы, они запросто забьют всю пропускную способность сети, и другие запросы будут страдать. В этом заключается проблема планирования схемы данных.
Используйте партиционирование при любых намеках на историю, которую необходимо хранить больше двух лет. Партиционирование иногда кажется сложным — нужно заморачиваться с триггерами, с функциями, которые будут создавать партиции. В новых версиях PostgreSQL ситуация лучше и сейчас настройка партиционирования сильно проще — один раз сделал, и работает.
В рассмотренном пример удаления данных за 10 минут,
DELETE можно заменить на DROP TABLE — такая операция в аналогичных обстоятельствах займет всего несколько миллисекунд.Когда данные рассортированы по партициям, партиция удаляется буквально за несколько миллисекунд, и место ОС отдается сразу. Управлять историческими данными так легче, проще и безопаснее.
Мониторинг
Мониторинг — отдельная большая тема, но с точки зрения БД есть рекомендации, которые можно уместить в один раздел статьи.
По умолчанию многие системы мониторинга предоставляют мониторинг процессоров, памяти, сети, дискового пространства, но, как правило, нет утилизации дисковых устройств. Информацию о том, насколько загружены диски, какая пропускная способность в данный момент на дисках и значение latency, нужно всегда добавлять в мониторинг. Это поможет быстро оценить, как загружены диски.
Вариантов мониторинга PostgreSQL очень много, есть на любой вкус. Вот некоторые моменты, которые обязательно должны присутствовать.
- Подключенные клиенты. Нужно отслеживать, с какими статусами они работают, быстро находить «вредных» клиентов, которые вредят базе, и отключать их.
- Ошибки. Нужно мониторить ошибки, чтобы отслеживать, насколько хорошо работает база: нет ошибок — замечательно, появились ошибки — повод заглянуть в логи и начать разбираться, что идет не так.
- Запросы (statements). Мониторим количественные и качественные характеристики запросов, чтобы примерно оценивать, нет ли у нас медленных, долгих или ресурсоемких запросов.
За более детальной информацией обратитесь к докладу «Основы мониторинга PostgreSQL» с HighLoad++ Siberia и страницу Monitoring в PostgreSQL Wiki.
Когда мы все спланировали и «обмазались» мониторингом, мы все равно можем столкнуться с некоторыми проблемами.
Масштабирование
Обычно разработчик видит БД строчкой в конфиге. Ему не особо интересно, как она устроена внутри — как работает checkpoint, репликация, планировщик. Разработчику и так есть, чем заняться — в todo стоит много интересных вещей, которые ему хочется попробовать.
«Дайте мне адрес базы, дальше я сам». © Anonymous developer.
Незнание предмета приводит к довольно интересным последствиям, когда разработчик начинает писать запросы, которые работают в этой базе. Фантазии при написании запросов порой дают ошеломляющие эффекты.
Есть два типа транзакций. OLTP транзакции — быстрые, короткие, легкие, которые выполняются доли миллисекунд. Они отрабатывают очень быстро, и их очень много. OLAP — аналитические запросы — медленные, долгие, тяжелые, читают большие массивы таблиц и считают статистику.
Последние 2-3 года часто звучит аббревиатура HTAP — Hybrid Transaction / Analytical Processing или гибридный транзакционно-аналитический процессинг. Если вам некогда думать над масштабированием и разнесением OLAP и OLTP запросов, можно говорить: «У нас HTAP!» Но опыт и боль ошибок показывают, что все-таки разные типы запросов должны жить отдельно друг от друга, потому что долгие запросы OLAP блокируют легкие OLTP-запросы.
Так мы подходим к вопросу, как масштабировать PostgreSQL так, чтобы разнести нагрузку, и все остались довольны.
Streaming replication. Самый простой вариант — потоковая репликация. Когда приложение работает с базой, подключаем к этой базе несколько реплик и распределяем нагрузку. Запись по-прежнему идет в мастер-базу, а чтение на реплики. Такой способ позволяет масштабироваться очень широко.
Плюс к отдельным репликам можно подключить еще реплики и получить каскадную репликацию. Отдельные группы пользователей или приложения, которое, например, читает аналитику, можно вынести на отдельную реплику.

Logical publications, subscriptions — механизм логических публикаций и подписок предполагает наличие нескольких независимых PostgreSQL-серверов с отдельными базами и наборами таблиц. Эти наборы таблиц можно подключать в соседние базы, они будут видны приложениям, которые смогут ими нормально пользоваться. То есть все изменения, которые происходят в источнике, реплицируются на базу назначения и там видны. Прекрасно работает с PostgreSQL 10.

Foreign tables, Declarative Partitioning — декларативное партиционирование и внешние таблицы. Можно взять несколько PostgreSQL и создать там несколько наборов таблиц, которые будут хранить нужные диапазоны данных. Это могут быть данные за конкретный год или данные, собранные по любому range.

С помощью механизма внешних таблиц можно объединить все эти базы в виде партиционированной таблицы в отдельной PostgreSQL. Приложение может работать уже с этой партиционированной таблицей, но на самом деле оно будет читать данные с удаленных партиций. Когда объемы данных больше возможностей одного сервера, то это шардинг.

Это все можно объединять в развесистые конфигурации, придумывать разные топологии репликации PostgreSQL, но как все это будет работать и как этим управлять — тема отдельного доклада.
С чего начать?
Самый простой вариант — с репликации. Первый шаг — разнести нагрузку на чтение и на запись. То есть писать в мастер, а читать с реплик. Так мы масштабируем нагрузку и выносим чтение с мастера. Кроме того, не забываем про аналитиков. Аналитические запросы работают долго, для них нужна отдельная реплика с отдельными настройками, чтобы долгие аналитические запросы могли не мешать остальным.
Следующий шаг — балансировка. У нас по-прежнему остается та самая строчка в конфиге, которой оперирует разработчик. Ему нужно место, куда он будет писать и читать. Здесь есть несколько вариантов.
Идеальный — реализовывать балансировку на уровне приложения, когда приложение само знает, откуда ему читать данные, и умеет выбирать реплику. Допустим, баланс счета всегда нужен актуальный и его нужно прочитать с мастера, а картинку товара или информацию о нем можно прочитать с некоторой задержкой и сделать это с реплики.
- DNS Round Robin, на мой взгляд, не очень удобная реализация, поскольку иногда работает долго и не дает необходимого времени при переключении ролей мастера между серверами в случаях failover.
- Более интересный вариант — использование Keepalived и HAProxy. Виртуальные адреса для мастера и набора реплик перекидываются между серверами HAProxy, а HAProxy уже осуществляет балансировку трафика.
- Patroni, DCS в связке с чем-то типа ZooKeeper, etcd, Consul — самый интересный вариант, на мой взгляд. То есть service discovery отвечает за информацию, кто сейчас мастер, а кто реплики. Patroni управляет кластером PostgreSQL’ов, осуществляет переключение — если топология изменилась, эта информация появится в service discovery, и приложения смогут оперативно узнать текущую топологию.
И с репликацией бывают нюансы, самый частый из них — лаг репликации. Можно сделать, как GitLab, и когда накопится лаг, просто дропнуть базу. Но у нас же есть всесторонний мониторинг — смотрим его и видим долгие транзакции.

Приложения и СУБД-транзакции
В общем случае медленные и ничего не делающие транзакции приводят к:
- снижению производительности — не к резкому скачкообразному, а плавному;
- блокировкам и дедлокам, потому что долгие транзакции удерживают блокировки на строки и мешают другим транзакциям работать;
- ошибкам HTTP 50* на бэкенде, к ошибкам в интерфейсе или где-то еще.
Рассмотрим немного теории о том, как же возникают эти проблемы, и почему механизм долгих и ничего не делающих транзакций (idle transactions) вреден.
В PostgreSQL есть MVCC — условно говоря, движок БД. Он позволяет клиентам конкурентно работать с данными, не мешая при этом друг другу: читатели не мешают читателям, а писатели не мешают писателям. Конечно, есть некоторые исключения, но в данном случае они не важны.
Получается, что в базе для одной строки может существовать несколько версий для разных транзакций. Клиенты подключаются, база выдает им снимки данных, и в рамках этих снимков могут существовать разные версии одной и той же строки. Соответственно, в жизненном цикле базы транзакции сдвигаются, заменяют друг друга, и появляются версии строк, которые уже никому не нужны.
Так возникает необходимость в сборщике мусора — auto vacuum. Долгие транзакции существуют и мешают auto vacuum вычистить ненужные версии строк. Эти мусорные данные начинают кочевать из памяти на диск, из диска в память. На то, чтобы хранить этот мусор, тратятся ресурсы CPU и памяти.
Чем дольше транзакции — тем больше мусора и ниже производительность.
С точки зрения «Кто виноват?», в появлении долгих транзакций виновато именно приложение. Если база будет существовать сама по себе, долгие, ничего не делающие транзакции ниоткуда не возьмутся. На практике же есть следующие варианты появления idle транзакций.
«Давайте сходим во внешний источник». Приложение открывает транзакцию, что-то делает в базе, потом решает обратиться к внешнему источнику, например, Memcached или Redis, в надежде, что потом вернется в базу, продолжит работу и закроет транзакцию. Но если во внешнем источнике происходит ошибка, приложение падает, и транзакция остается незакрытой, пока ее кто-нибудь не заметит и не убьет.
Нет обработки ошибок. С другой стороны, может быть проблема обработки ошибок. Когда опять же приложение открыло транзакцию, решило какую-то задачу в базе, вернулось к исполнению кода, выполнило какие-то функции и вычисления, чтобы дальше продолжить работу в транзакции и закрыть ее. Когда на этих вычисления работа приложения прервалась с ошибкой, код вернулся в начало цикла, а транзакция опять осталась незакрытой.
Человеческий фактор. Например, админ, разработчик, аналитик, работает в каком-нибудь pgAdmin или в DBeaver — открыл транзакцию, что-то в ней делает. Потом человека отвлекли, он переключился на другую задачу, потом на третью, забыл про транзакцию, ушел на выходные, а транзакция продолжает висеть. Производительность базы страдает.
Давайте разберем, что делать в этих случаях.
- У нас есть мониторинг, соответственно, нужны алерты в мониторинге. Любая транзакция, которая висит больше часа и ничего не делает — повод посмотреть, откуда она взялась, и разбираться, что не так.
- Следующий шаг — отстрел таких транзакций через задачу в кроне (pg_terminate_backend(pid)) или настройку в конфиге PostgreSQL. Нужны пороговые значения в 10-30 минут, после которых транзакции автоматически завершаются.
- Рефакторинг приложения. Конечно же, нужно выяснить, откуда берутся idle транзакции, почему они происходят и устранять такие места.
Избегайте долгих транзакций любой ценой, потому что они очень сильно влияют на производительность базы данных.
Все становится еще интересней, когда появляются отложенные задачи, например, нужно аккуратно посчитать агрегаты. И мы подходим к вопросу велосипедостроения.
Велосипедостроение
Больная тема. Бизнесу со стороны приложения нужно производить фоновую обработку событий. Например, рассчитывать агрегаты: минимальное, максимальное, среднее значение, рассылать уведомления пользователям, выставлять счета клиентам, настраивать кабинет пользователя после регистрации или регистрировать в соседних сервисах — делать отложенную обработку.
Суть у таких задач одна — они откладываются на потом. В базе появляются таблицы, которые как раз осуществляют очереди.

Здесь есть идентификатор задачи, время, когда задача была создана, когда обновлена, хэндлер, который её взял, количество попыток выполнения. Если у вас есть таблица, которая хотя бы отдаленно напоминает эту, значит, у вас есть самописные очереди.
Все это работает прекрасно, пока не появляются долгие транзакции. После этого таблицы, которые работают с очередями, распухают в размерах. Новые jobs все время добавляются, старые удаляются, происходят апдейты — получается таблица с интенсивной записью. Её нужно регулярно чистить от устаревших версий строк, чтобы не страдала производительность.
Растет время обработки — долгая транзакция удерживает блокировку на устаревшие версии строк или мешает vacuum ее почистить. Когда таблица увеличивается в размерах, время обработки тоже увеличивается, так как нужно прочитать много страниц с мусором. Время увеличивается, и очередь в какой-то момент перестает работать вообще.
Ниже пример топа одного нашего заказчика, у которого была самописная очередь. Все запросы как раз связаны с очередью.

Обратите внимание на время выполнения этих запросов — все, кроме одного, работают по двадцать с лишним секунд.
Чтобы решить эти проблемы давно изобретен Skytools PgQ — менеджер очередей для PostgreSQL. Не изобретайте свой велосипед — возьмите PgQ, один раз настройте и забудьте про очереди.
Правда, и у него есть особенности. У Skytools PgQ мало документации. После чтения официальной страницы, складывается ощущение, что ничего не понял. Ощущение растет, когда что-то пробуешь сделать. Все работает, но как работает — не понятно. Какая-то джедайская магия. Но многую информацию можно получить в Mailing-lists. Это не очень удобный формат, но много интересного находится именно там, и эти листы придется читать.
Несмотря на минусы, Skytools PgQ работает по принципу «настроил и забыл». Создается триггерная функция, которая вешается на таблицу, с которой хотим получать изменения, и все работает надежно. Практически про PgQ вспоминают, когда нужно добавить еще одну таблицу в очередь. Использовать PgQ дешевле, чем поддержка и настройка отдельных брокеров.
Если столкнулись с задачей, с которой кто-то уже скорее всего сталкивался — поищите инструменты, которые уже изобретены. Это особенно относится к очередям.
В своей практике мы выпилили очень много самописных очередей и заменили их на PgQ. Конечно, бывают большие инсталляции PostgreSQL, например, в Авито, где возможностей PgQ не хватает. Но это единичные кейсы, которые решаются отдельно.
Автоматизация
Админы хотят от автоматизации получить возможность раскатывать инстансы, чтобы деплой работал без их вмешательства и конфиги раскатывались мгновенно. А разработчики хотят, чтобы деплой работал так, чтобы, как только они закомитили какие-то изменения, они дальше подтянулись, оттестировались, разлились и все бы было хорошо. Конечно, они хотят катить миграции без ручного вмешательства, чтобы не надо было логиниться на сервер, руками выполнять alter.
Все вместе они хотят auto-failover — если вдруг во время работы кластера PostgreSQL произойдет какой-нибудь сбой, роль мастера автоматически перекинется на другой сервер, а мы об этом даже ничего не знали. Но есть несколько очень серьёзных проблем, которые мешают использованию auto-failover.
Split-brain. В нормальном кластере PostgreSQL с мастером и несколькими репликами, запись идет в один сервер, чтение — с реплик. Если происходит сбой, то сервер выключается. Но в PostgreSQL из коробки нет механизма fencing, и часто даже в Kubernets его приходится настраивать отдельно. При сбое приложение может по-прежнему писать в старый мастер, а новое переключившееся приложение начинает писать в новый мастер. Возникает ситуация Split-brain.

Попытка восстановить консистентность может быть очень тяжелой и потребует много нервов. Когда GitHub столкнулся со Split-brain, им пришлось восстанавливать свою базу из бэкапа.
Cascade failover. Допустим, есть мастер и несколько реплик. Мастер падает, и нагрузка переключается на новый мастер и оставшиеся реплики.
Старый мастер не успел переинициализироваться и стать репликой, а в этот момент падает другой мастер. На это уходят секунды, и вся нагрузка приходится на единственный сервер.

Он не справляется с нагрузкой и тоже отказывает — получается каскадный failover.
Если все же браться за auto-failover, то есть следующие пути.
Bash скрипты — хрупкое решение, которое нужно постоянно тестировать и отлаживать. Один админ ушел, другой пришел и не знает, как этим пользоваться. Если вдруг что-то сломалось, очень тяжело найти, где что произошло. Такое решение требует постоянной доработки.
Ansible playbooks — bash-скрипты на стероидах. Тоже нужно постоянно проверять, что все работает, прогонять на тестовых кластерах.
Patroni — на мой взгляд, один из лучших продуктов, потому что у него есть auto-failover, мониторинг состояния кластера, плюс функция отдачи топологии кластера в service discovery.
PAF — основан на Pacemaker. Тоже интересный инструмент для auto-failover в PostgreSQL, но он уже сложнее и требует знания Pacemaker.
Stolon больше предназначен для облачных задач. Для Kubernetes, например. Stolon сложнее Patroni, но они взаимозаменяемы и можно выбирать между ними.
Контейнеры и оркестрация
В последние годы Docker и Kubernetes растут. Это динамично развивающиеся технологии, в которых появляется много нового.

В каждой новой версии добавляется много интересной функциональности, правда при этом старая может перестать работать. С «А что если развернуть базу в Kubernetes...» начинаются разные удивительные истории.
База — это всегда stateful, ее нужно где-то хранить. Где? На ум приходит отказоустойчивое сетевое хранилище. Решения из Open Source: CEPH, GlusterFS, LinStor DRBD. Фундаментальная проблема в том, что все это работает очень медленно и, наверное, никогда не станет работать быстро.
Бонусом вы получаете дополнительную головную боль — необходимость поддерживать кластерную файловую систему. Например, если вы знакомы только с Kubernetes, вам придется глубоко изучить CEPH. Это сложная система с большим багажом своих проблем — придется наращивать свою экспертизу. Если говорить в целом про сетевые хранилища и базы в них, то это работает пока выполняется три требования.
- Размер базы небольшой, и не нужно передавать Гб и десятки Гб данных между узлами.
- Нет требований к производительности и latency. Если latency увеличивается до десятков или даже сотен миллисекунд — это совершенно нерабочее решение.
- Не страшно потерять данные. Kubernetes развивается, в нем находят какие-то баги. Движки, которые позволяют делать shared storage для Kubernetes, тоже развиваются и там тоже находят баги. В какой-то момент можно просто напороться на баг и все потерять.
Этот подводит нас к тому, что хорошо использовать Kubernetes и Docker для БД на staging или dev-серверах либо на этапе проверки гипотез. Но для высоких нагрузок, на мой взгляд, Kubernetes и шаредные хранилища не очень хороши.
Но если сильно хочется, то оптимальным вариантом будут local volumes — локальные хранилища без использования шаредных файловых систем, streaming replication — нативная потоковая репликация, через которую идет синхронизация данных и PostgreSQL-операторы, которые предоставляют нам нечто вроде кнопки — нажал, и все заработало. На данный момент есть два таких оператора: Zalando и Crunchy.
Конечно же стоит помнить, что это все динамично развивается. Посмотрите на количество issues и pull requests. Появляются новые фичи, в них могут скрываться ошибки, поэтому внедряйте контейнеризацию без фанатизма.
Итоги
Когда вы занимаетесь планированием и мониторингом не экономьте на SSD — они относительно дешевы и оттянут проблемы с производительностью на год, а то и больше.
Не пишите в базу все подряд. Практика писать JSON на 8 Мб — это плохо, так делать нельзя.
Мониторинг нужен, причем не оставляйте его в дефолтно настроенном состоянии. Мониторьте PostgreSQL, расширяйте ваш мониторинг.
Разносите нагрузку — Postgres is ready. Старайтесь не читать и не писать данные из одного места. PostgreSQL очень хорошо масштабируется, и есть варианты его масштабирования на любой вкус. Для масштабирования нагрузки используйте: streaming replication; publications, subscriptions; foreign Tables; declarative partitioning.
Избегайте ничего не делающих транзакций. Они снижают производительность и очень медленно, но верно убивают базу.
Если вы делаете что-то, что уже могло понадобиться другим людям, посмотрите вокруг — возможно все уже есть. Это напрямую касается очередей. Не изобретайте самописные очереди, используйте Skytools PgQ!
Если очень хочется базу в Kubernetes, используйте local volumes, streaming replication и PostgreSQL операторы. С этим можно хоть как-то работать, но без фанатизма, потому что все очень быстро меняется.
Не пропустите новую возможность обсудить высокие нагрузки и услышать среди прочего об администрировании баз данных. На этот раз в Новосибирске, где уже 24 и 25 июня на HighLoad++ Siberia коллега Алексея Андрей Сальников расскажет о том, как построить рабочий процесс, когда у тебя несколько сотен баз данных с абсолютно разной нагрузкой. И еще 38 классных докладов в расписании — отличный повод приехать на конференцию!
