
За 3 последних года в Контуре случилось больше тысячи инцидентов разной степени эпичности. Причины разные: например, 36% вызвано некачественным релизом, а 14% — работами по обслуживанию железа в дата-центре. Откуда статистика? После каждого инцидента пишется отчёт — постмортем. Их пишут дежурные инженеры, которые отреагировали на уведомление об аварии и первыми начали разбираться в ее причинах. Постмортемы анализируются, выявляются и устраняются причины инцидентов, чтобы в дальнейшем подобные инциденты не возникали. Но так было не всегда.
Алексей Кирпичников (BeeVee) с 2008 года программировал в Яндекс. Пробки, работал над спортивными спецпроектами, был тимлидом команды бэкенда Яндекс.Такси. С 2014 года занимается DevOps и инфраструктурой в Контуре — разрабатывает инструменты, которые облегчают жизнь разработчиков из продуктовых команд. Идея писать и анализировать постмортемы появилась пять лет назад, и за это время постмортемы обросли шаблонами, глоссарием, памятками, скриншотами и аналитикой. Но не это самое сложное — труднее было преодолеть инертность, страхи и непонимание смысла отчетов об инцидентах среди инженеров. Что в итоге получилось и какую непоправимую пользу может нанести «диванная аналитика» — в расшифровке доклада Алексея.

Обратите внимание — под ножки стола разной длины подложены книжки «Метрики», «Тесты» и «Деплой».
В Контуре после приема на работу дают набор сувениров: ручка, кружка, блокнот. Я пришел в СКБ Контур в новую инфраструктурную команду 5 лет назад, когда компании как раз исполнилось 25 лет.

Контур тех времен, да и сейчас тоже — это продуктовая компания, в которой несколько десятков продуктов разрабатывало столько же команд, независимых друг от друга в плане выбора технологий и инструментов.
В то время я впервые прочитал «Проект ’’Феникс’’» и был окрылен новомодными идеями DevOps-практик. Я стал записывать в блокнот свои идеи улучшений, и сейчас это артефакт с пятнами от кофе и историческими записями.
За 5 лет мы далеко шагнули вперед во всех этих направлениях. У нас появилась своя система алертинга Moira, система оркестрации приложений и куча инструментов. Но из всего перечисленного написание отчетов об инцидентах оказалось самой сложной для внедрения инженерной практикой. Инженеры любят всякие инструменты — прикрутить какую-то систему хостинга или CI, что-то заскриптовать, автоматизировать, а писать отчеты не любят, хотя в этой практике много пользы.
Я расскажу, как мы внедряли у себя постмортемы и какую пользу получаем. Возможно, наши грабли помогут пройти этот путь быстрее и набить меньше шишек. Прежде, чем начать рассказывать про постмортемы, разберемся с определением.
Что из этого — инцидент?
Чтобы понять, что из этого факапы, обратимся к опыту гуру — Google, Atlassian, PagerDuty. Гуру знают, как готовить дежурства, on-call инженеров и как писать отчеты, чтобы их понять. В их онлайн-гайдах есть определения инцидентов.
Определение от PagerDuty.
Звучит логично, но определение расплывчатое. На практике слабо помогает понять, что инцидент, а что нет.
В книге Site Reliability Engineering от Google есть четкие критерии:
У Контура нет опубликованного определения факапа, но мы сформулировали свои критерии для определения, что является инцидентом.
Внешние или внутренние пользователи заметили деградацию сервиса. Пример №3 с Grafana, которая лежала, однозначный инцидент. Продакшн не сломался и внешние пользователи этого не заметили, но несмотря на это, для Контура это факап, так как не работали внутренние инструменты.
Везение. В примере №2 сервис для офисных работников лежал ночью 2 часа — повезло, что он упал ночью. В следующий раз может не повезти, и поэтому ночной инцидент тоже требует разбирательства, как если бы произошел днем.
Инцидент касается нескольких команд. Это определение мы берем из PagerDuty. Разбор инцидента — хорошая причина нескольким командам вместе поработать. Культура «С нашей стороны пуля вылетела, а у вас что-то сломалось — это вы виноваты» искореняется совместным разбором.
Минимум один инженер считает, что это инцидент. Самое расплывчатое, но и самое важное определение. Простое правило: если инженер считает, что это стоит отчета, значит, это стоит отчета. Если вас пугает, что инженеры начнут на любой чих писать отчеты и любую мелочь называть аварией, это не так. Инженеры — разумные люди, доверяйте им.
С определением и разными видами ущерба разобрались. Перейдем к тому, как извлекать пользу из инцидентов.
Простую инструкцию, которую я дам дальше, вы сможете применить у себя, даже не пройдя статью до конца. Но все-таки до конца дочитайте.
Сначала найдите виновных. Затем проведите с инженерами «воспитательную» работу.
Такой подход считается традиционным для классических вертикально -ориентированных корпораций с начальником, который всех ругает и может увольнять. Одна из основ DevOps-движения и DevOps-идеологии — это уход от вертикально интегрированных организаций к горизонтальным, к большему доверию к сотрудникам.
Проиллюстрирую эту смену парадигмы инструкцией Джона Олспоу, одного из лидеров DevOps-движения, который раньше работал CTO в Etsy. Инструкция взята из его канонической статьи 2013 года «Blameless Post Mortem and a Just Culture».
Спросите инженеров:
Это главное в рекомендации Джона.
Угроза наказания: переобучение, устранение от продакшн или увольнение, мотивирует людей врать. А нам важна истина. Отчет об инциденте — это и есть то самое недостающее звено обратной связи в процессе разработки и выкладывания фич в продакшн.
В старой парадигме разработчики разработали, перекинули поделку через забор operations-инженерам, а те как-то пытаются заставить ее работать. Их раздражает любое обновление, потому что оно может все сломать, а инженеры с таким трудом все запустили.

Это убедит тимлидов и менеджеров разработки в полезности постмортемов. Но загвоздка в том, что трудно заставить инженеров делать то, что они считают бессмысленным и бесполезным. У нас в компании есть инженерная культура, и я не могу просто прийти, помахать указом генерального директора и потребовать, чтобы все писали постмортемы. Мне нужно убедить инженеров в этом.

Как «продать» инженерам идею постмортемов? Обойти возражения, показать, почему постмортемы — круто, продемонстрировать пользу от отчетов, что это не просто отписка, лишь бы начальник отстал.
Это первая проблема инженера, который разбирает факап — вот кончится война, тогда и поговорим! Когда происходит факап, хочется быстро его починить, а писать непонятные нудные и длинные отчеты не хочется.
Для решения проблемы есть лайфхак, как что-то писать прямо во время аварии. Его популяризовал Артемий Лебедев:
Проиллюстрирую метод прогрессивного джипега с помощью картинки. На медленном интернете картинка загружается не сразу, а этапами.

Во время пожара вам не нужно писать крутой и длинный отчет. Вам достаточно того, что в левом верхнем углу. Достаточно пометить те вещи, которые сложно будет восстановить по памяти. Не пытайтесь писать связный литературный текст в тот момент, когда на продакшене все сломано.
Хронологию потом очень трудно восстановить, если не записать сразу. Пример записи из реального постмортема в Контуре.
Это короткое и простое наблюдение с меткой времени. По этой хронологии позже легко восстановить последовательность событий и найти причину поломки. Но если ничего не записывать прямо во время пожара, то будет сложно или вообще невозможно восстановить события позднее.
Удобная вещь, особенно при работе с веб-сайтом или десктопным приложением. Ситуацию иногда сложно описать словами, а скриншот — это одно нажатие горячей клавиши.

Первое возражение отработали. Записать минимальные сведения, небольшой отчет во время инцидента не сложно и не отнимает драгоценное время. Когда все закончится, его нужно заполнить и оформить в понятный и связный документ.
Вы два дня не спали и чинили серьезную аварию, фатально отстали по всем задачам, которые собирались выполнить за эту неделю. Но оказывается нужно еще что-то делать, а ведь пожар уже потушен! В этот момент настигает невообразимая лень.
Полностью победить проблему не получится. Но можно заранее облегчить себе работу.
Это первое и главное. Велик страх пустого документа, который требуется заполнить осмысленным текстом. Гораздо легче, если заготовлен шаблон. Обычно он состоит из разделов и вопросов в них. Вписываем ответы на вопросы в каждый раздел, и шаблон заполняется.
Шаблоны отчета об инциденте большие. Подробно о них почитайте у гуру. Во всех документах и книгах, на которые я ссылаюсь, есть шаблоны инцидента, которые используются в компаниях. По нашему опыту могу добавить следующее.
В нашем шаблоне есть раздел «Ущерб» с подразделами.
Раздел «Качественная оценка». В нем описывается, что видит перед собой инженер, когда заполняет эту часть шаблона:
Дойдя до этого места в шаблоне, инженер пишет: «В нашей блог-платформе миллион пользователей, мы потеряли все записи одного из них». Это гораздо проще, чем писать сочинение с нуля, как на уроке литературы.
Раздел «Количественная оценка»:
Набор таких вопросов и есть шаблон.
Пример одного из заполненных шаблонов.

Еще один лайфхак для отчетов об авариях, который я не видел в книжку у гуру. Когда пишете отчет, удобно оперировать терминами, которые вы хорошо знаете. Например, если я работаю с Graphite, в котором хранятся метрики, то хорошо знаю, что такое «relay». Но тот инженер, который будет читать отчет через год, возможно, не знаком с термином. Вряд ли он сможет прочитать отчет, который состоит из незнакомых слов. С другой стороны, если внутри отчета постоянно разжевывать каждый термин и определение, то лень просто отпугнет, и отчет не будет закончен.

Если прикладываете к отчету артефакты: снапшоты в Grafana, историю сообщений в чате, в котором разбирали инцидент с другими инженерами, — делайте копии. Метрики имеют свойство «протухать», а чаты меняться. Год назад вы были в Slack, сейчас в Telegram — ссылка на чат устарела и не работает, а метрики по retention отвалятся — они хранятся год.
Самый большой и непонятный вопрос, который задают инженеры: «Кто эти отчеты будет читать?» Допустим, я поборол лень и написал хронологию событий во время аварии. Потом собрался с силами и дописал многостраничный отчет о том, что произошло, и причинах аварии. Но если нет понимания того, кто это все будет читать и кому принесет пользу, то заполнять отчеты нет желания.
В любой книжке гуру, например, в Atlassian Incident Handbook, написано, что по результатам каждого постмортема требуется:
Обратная связь замыкается: вот постмортем, вот в нем action items — задачи, которые требуется выполнить, чтобы авария больше не повторилась. Задачи попадают в бэклог команде, команда их разрабатывает, выкатывает — снова факап и постмортем. Колесо сансары замкнулось.
Это то, в чем сходятся все гуру. Возразить нечего — польза очевидна.
Пример задач action items из реального постмортема.

Но мы в Контуре добавили к этому аналитику.
Раньше мы анализировали инцидент в изоляции. Сбой произошел сам по себе в одной команде, в одной системе хостинга — что-то сломалось, мы починили.
Но инцидентов много. За три года в Контуре накопилось больше 1000 отчетов об инцидентах. Хочется знать, можно ли получить пользу от всей массы накопленных отчетов, а не только от каждого по отдельности. Можно ли на их основе посчитать статистику работы системы и увидеть, что улучшать в системе в целом.
В Контуре работает специальная инфраструктурная команда, которая занимается анализом постмортемов и публикует результаты и выводы на основе всей массы накопленных отчетов. Мы это называем «диванной аналитикой». Приведу фрагменты одной из статей команды, которая опубликована в нашей внутренней сети для сотрудников.
Что мы анализируем в диванной аналитике?

На диаграмме, кроме последнего столбика, где время неизвестно, есть еще два явных пика.
Длительность порядка часа — оранжевый и красный столбики. Большая часть из этого времени потрачена на передачу информации о том, что произошло, от инженера, который заметил аварию, до инженера, который знает, как все исправить. Проблема в коммуникации.
Если мы поправим наши инструменты так, что инженер, который исправляет проблему, будет получать информацию быстрее, то длительность факапов и ущерб от них сильно сократится. Это то, что мы бы не узнали, посмотрев на любой факап в отдельности.
Длительность порядка 12 часов — желтый столбик. Объяснение тому, что есть много факапов, которые длятся больше 12 часов, простое: выкатили релиз вечером, а утром пришли пользователи, и все сломалось. Вывод, что делать, чтобы таких факапов было меньше, очевиден.

Качественный ущерб разделяем на несколько категорий. В топ-3 входят:
По аналитике видно, что подобных ошибок подавляющее большинство. С одной стороны, это хорошая новость. Три вида самых частых ошибок легко обнаружить — настраиваем метрики на latency и количество ошибок, и быстро замечаем подобные вещи.
Плохая новость — таких ошибок больше всего. Это простые технические ошибки, значит, мы могли бы что-то улучшить в pipeline тестирования, проводить больше нагрузочных тестов и улучшать систему мониторинга.
Это то, что непосредственно привело к поломке, то есть не первопричина аварии, а «последняя капля»: логи заполнили диск и из-за этого все сломалось, выложили в релиз — все взорвалось.
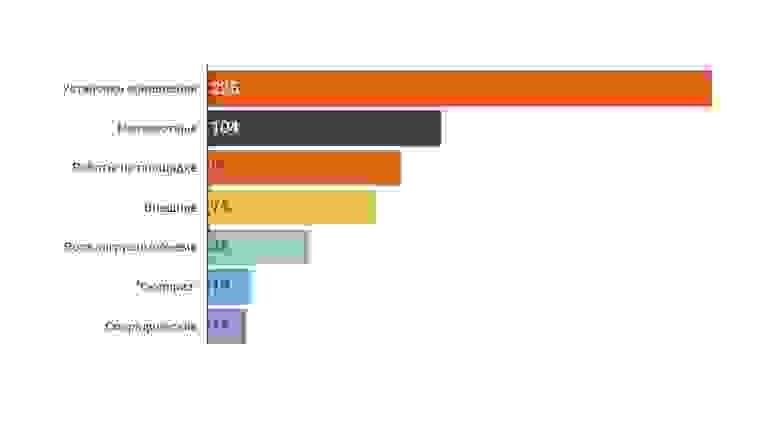
На первом месте — «установка обновления». Эта причина позволяет понять, куда нам как инфраструктурной команде вкладывать усилия. Например, улучшать систему деплоя и внедрять канареечный деплой. Это точка приложения усилий, которая окажет наибольшее воздействие на качество наших систем.
Что улучшить — алёртинг или деплой? Чем заняться — хостингом или красотой графиков?
Здесь есть еще один неплохой инсайт. На втором месте — «причина неизвестна». Это показатель некачественного заполнения отчетов об инцидентах.
То, что позволяет простым техническим решением сократить количество аварий определённого типа. Например, мы знаем, что самые важные вещи, которые уменьшают количество факапов — это уведомления от системы мониторинга. Если бы алертов в мониторинге на эти события было больше, то сколько инцидентов мы могли бы предотвратить? В процентах указано, сколько:
Если бы алерт был правильно настроен, а нужный инженер вовремя получил уведомление, 24% инцидентов либо не произошли, либо имели бы гораздо меньшую продолжительность. Этот вывод можно сделать на основании анализа всей массы инцидентов.
Здесь еще раз прорекламирую нашу систему алертинга Moira, которая находится в Open Source.

Если у вас Graphite, можете ее скачать и пользоваться. Надеюсь, инцидентов станет меньше.
Организационные рекомендации, которым команда может следовать, и тоже уменьшать количество аварий. Наш топ-3.
Подчеркну, что это не инструкция, а рассказ о том, как мы собирали аналитику. Ваша аналитика может быть другой.
Если вы осознали, что аналитика инцидентов — классная штука, и отчеты нужно писать, расскажу, как это делать.
В багтрекере, в отличие от Google Docs или Wiki, есть фиксированные поля, у которых можно задавать набор значений. Это облегчает анализ построения графиков статистики позже.
В книге SRE Google приводит шаблон в Google Docs, в котором они пишут отчеты в своем внутреннем документе. Я не представляю, как можно собрать по неструктурированным Google-документам аналитику, которую собираем мы.
Мы пишем отчеты в том же багтрекер, что и основные задачи, потому что можем связать задачу с постмортемом. Заглянем в постмортем и сразу видим, какие задачи закрыты, какие нет, а какие еще осталось сделать.
Я уже рассказывал про специальные поля. У нас есть следующие.
Все данные из специальных полей позволяют понимать, как работает ваша инфраструктура.
Пример нашего заполненного отчета по инциденту.
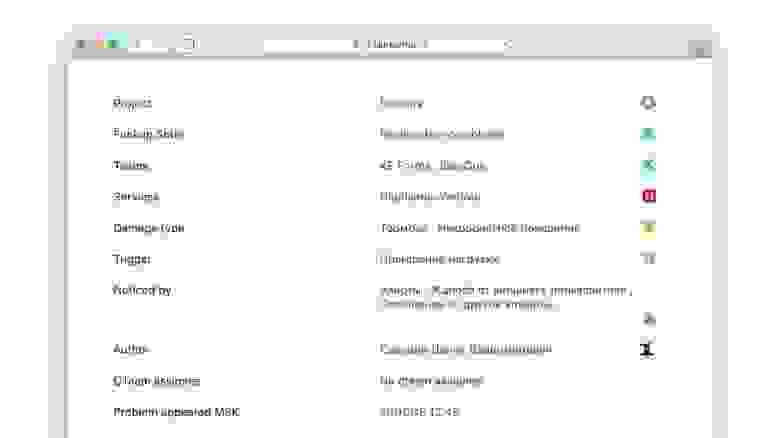
Поля правого столбца как раз заполняются через выбор из выпадающих списков.
Чтобы получить отчеты, которые помогут понять, как развивать инфраструктуру, вам понадобятся люди, которых волнует качество ваших сервисов. Не обязательно это будут инженеры, которые full-time занимаются только анализом постмортемов. Важно, чтобы это были люди, которых очень волнует происходящее. Время от времени они будут собираться, анализировать всю массу инцидентов, писать большие статьи и приносить пользу — замыкать кольцо обратной связи.
Наша команда называется Q-team — от слова «Quality». В ней 3 человека — одни из самых талантливых инженеров компании, которые работают в инфраструктуре.
Читайте гуру — статью John Allspaw и книги, посвященные инцидент-менеджменту: Site Reliability Engineering, PagerDuty Post-Mortem Process, Atlassian Incident Handbook.
А когда придете завтра на работу, просто сделайте первые шаги:
В тот момент, когда вы напишете первый, второй, третий отчет, у вас не будет красивой аналитики с разноцветными столбиками. Но через год–два, когда накопятся данные, вы посмотрите назад и поблагодарите себя за первый шаг.
Алексей Кирпичников (BeeVee) с 2008 года программировал в Яндекс. Пробки, работал над спортивными спецпроектами, был тимлидом команды бэкенда Яндекс.Такси. С 2014 года занимается DevOps и инфраструктурой в Контуре — разрабатывает инструменты, которые облегчают жизнь разработчиков из продуктовых команд. Идея писать и анализировать постмортемы появилась пять лет назад, и за это время постмортемы обросли шаблонами, глоссарием, памятками, скриншотами и аналитикой. Но не это самое сложное — труднее было преодолеть инертность, страхи и непонимание смысла отчетов об инцидентах среди инженеров. Что в итоге получилось и какую непоправимую пользу может нанести «диванная аналитика» — в расшифровке доклада Алексея.
Обратите внимание — под ножки стола разной длины подложены книжки «Метрики», «Тесты» и «Деплой».
В Контуре после приема на работу дают набор сувениров: ручка, кружка, блокнот. Я пришел в СКБ Контур в новую инфраструктурную команду 5 лет назад, когда компании как раз исполнилось 25 лет.

Контур тех времен, да и сейчас тоже — это продуктовая компания, в которой несколько десятков продуктов разрабатывало столько же команд, независимых друг от друга в плане выбора технологий и инструментов.
В то время я впервые прочитал «Проект ’’Феникс’’» и был окрылен новомодными идеями DevOps-практик. Я стал записывать в блокнот свои идеи улучшений, и сейчас это артефакт с пятнами от кофе и историческими записями.
- «Мониторинг! Давайте поставим Grafana, будем собирать метрики и строить графики. Станем лучше понимать, что происходит в продакшн». Для 2014 года это довольно свежая, новая идея и солидная DevOps-практика».
- «Автодеплой! Сколько можно выкладывать zip-файлы в расшаренную папку, разархивировать их на сервере и в task-scheduler в Windows запускать exe? Давайте внедрим промышленную систему деплоя и будем проводить через нее релизы, CI!»
- «Постмортемы! Если в продакшн какая-то авария, давайте все вместе разберемся, что это было, найдем причину, напишем отчет и изменим наши процессы разработки, тестирования, CI так, чтобы подобных инцидентов в будущем не было»
За 5 лет мы далеко шагнули вперед во всех этих направлениях. У нас появилась своя система алертинга Moira, система оркестрации приложений и куча инструментов. Но из всего перечисленного написание отчетов об инцидентах оказалось самой сложной для внедрения инженерной практикой. Инженеры любят всякие инструменты — прикрутить какую-то систему хостинга или CI, что-то заскриптовать, автоматизировать, а писать отчеты не любят, хотя в этой практике много пользы.
Я расскажу, как мы внедряли у себя постмортемы и какую пользу получаем. Возможно, наши грабли помогут пройти этот путь быстрее и набить меньше шишек. Прежде, чем начать рассказывать про постмортемы, разберемся с определением.
Что такое инцидент?
Что из этого — инцидент?
- Пример №1. На блог-платформе с миллионом пользователей в результате какой-то ошибки потеряны все записи одного пользователя.
- Пример №2. Сервис для офисных сотрудников работает в будние дни с 9 до 6, а в другое время в нем пользователей нет. Сервис был недоступен в ночь с субботы на воскресенье два часа подряд, этого никто не заметил.
- Пример №3. Grafana с метриками с продакшн упала на 15 минут. В продакшн ничего не сломалось, но графики были недоступны.
Чтобы понять, что из этого факапы, обратимся к опыту гуру — Google, Atlassian, PagerDuty. Гуру знают, как готовить дежурства, on-call инженеров и как писать отчеты, чтобы их понять. В их онлайн-гайдах есть определения инцидентов.
Определение от PagerDuty.
Инцидент — это любой незапланированный перерыв в обслуживании или деградация сервиса, которая отразилась на доступности сервиса для пользователей. Серьёзный инцидент — любой, который требует координированной реакции от нескольких команд.
Звучит логично, но определение расплывчатое. На практике слабо помогает понять, что инцидент, а что нет.
В книге Site Reliability Engineering от Google есть четкие критерии:
- Пользователи заметили деградацию сервиса.
- Были потеряны любые данные.
- Потребовалось вмешательство дежурного инженера, например, чтобы вручную откатить релиз.
- Решение проблемы заняло слишком много времени. Если какая-то задача решалась за 2 часа, а тут на нее потратили неделю — это инцидент, который требует разбирательства.
- Мониторинг не сработал. Например, о проблеме вы узнали от пользователей.
У Контура нет опубликованного определения факапа, но мы сформулировали свои критерии для определения, что является инцидентом.
Внешние или внутренние пользователи заметили деградацию сервиса. Пример №3 с Grafana, которая лежала, однозначный инцидент. Продакшн не сломался и внешние пользователи этого не заметили, но несмотря на это, для Контура это факап, так как не работали внутренние инструменты.
Везение. В примере №2 сервис для офисных работников лежал ночью 2 часа — повезло, что он упал ночью. В следующий раз может не повезти, и поэтому ночной инцидент тоже требует разбирательства, как если бы произошел днем.
Инцидент касается нескольких команд. Это определение мы берем из PagerDuty. Разбор инцидента — хорошая причина нескольким командам вместе поработать. Культура «С нашей стороны пуля вылетела, а у вас что-то сломалось — это вы виноваты» искореняется совместным разбором.
Минимум один инженер считает, что это инцидент. Самое расплывчатое, но и самое важное определение. Простое правило: если инженер считает, что это стоит отчета, значит, это стоит отчета. Если вас пугает, что инженеры начнут на любой чих писать отчеты и любую мелочь называть аварией, это не так. Инженеры — разумные люди, доверяйте им.
С определением и разными видами ущерба разобрались. Перейдем к тому, как извлекать пользу из инцидентов.
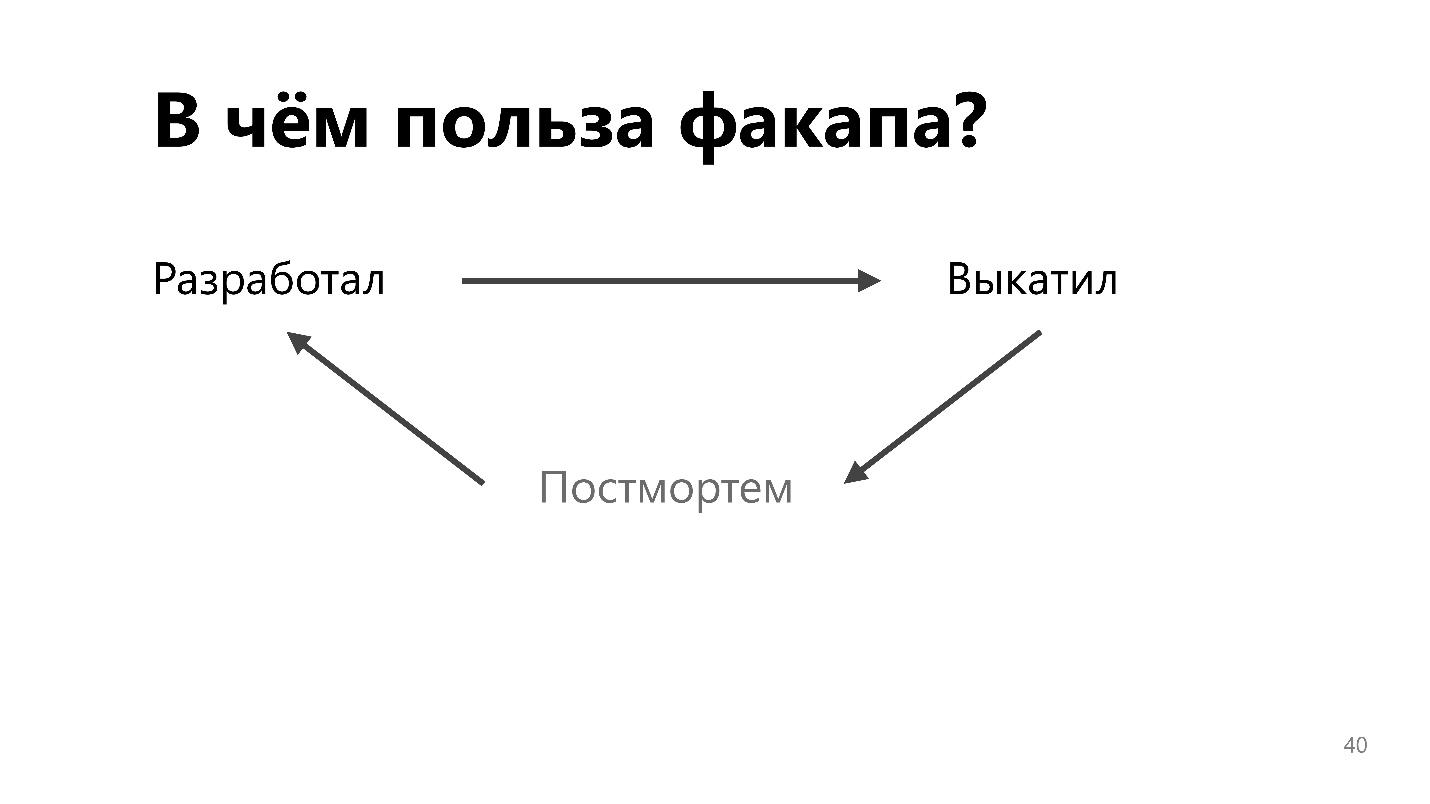
В чем польза факапа?
Простую инструкцию, которую я дам дальше, вы сможете применить у себя, даже не пройдя статью до конца. Но все-таки до конца дочитайте.
Классическая инструкция
Сначала найдите виновных. Затем проведите с инженерами «воспитательную» работу.
- Попросите быть внимательнее в следующий раз.
- Если не помогло — отправьте на курсы переподготовки. Возможно, там научат быть внимательнее.
- Если и это не помогло — отстраните виновных от работы с критичными участками системы. Перестаньте пускать разработчиков в продакшн, если они там все портят.
- Если не помогает ничего — увольте плохих и наймите компетентных.
Если инструкция вас раздражает — это хорошие новости.
Такой подход считается традиционным для классических вертикально -ориентированных корпораций с начальником, который всех ругает и может увольнять. Одна из основ DevOps-движения и DevOps-идеологии — это уход от вертикально интегрированных организаций к горизонтальным, к большему доверию к сотрудникам.
Проиллюстрирую эту смену парадигмы инструкцией Джона Олспоу, одного из лидеров DevOps-движения, который раньше работал CTO в Etsy. Инструкция взята из его канонической статьи 2013 года «Blameless Post Mortem and a Just Culture».
Спросите инженеров:
- какие события они наблюдали;
- когда и какие действия предпринимали;
- какого результата ожидали от этих действий;
- из каких предположений исходили;
- как понимают последовательность событий, которая произошла.
Инженеров нужно спрашивать без угрозы наказания.
Это главное в рекомендации Джона.
Угроза наказания: переобучение, устранение от продакшн или увольнение, мотивирует людей врать. А нам важна истина. Отчет об инциденте — это и есть то самое недостающее звено обратной связи в процессе разработки и выкладывания фич в продакшн.
В старой парадигме разработчики разработали, перекинули поделку через забор operations-инженерам, а те как-то пытаются заставить ее работать. Их раздражает любое обновление, потому что оно может все сломать, а инженеры с таким трудом все запустили.
Процесс обратной связи помогает менять процесс, инфраструктуру, инструменты и подход к разработке так, чтобы аварий в продакшн становилось меньше.
Это убедит тимлидов и менеджеров разработки в полезности постмортемов. Но загвоздка в том, что трудно заставить инженеров делать то, что они считают бессмысленным и бесполезным. У нас в компании есть инженерная культура, и я не могу просто прийти, помахать указом генерального директора и потребовать, чтобы все писали постмортемы. Мне нужно убедить инженеров в этом.
Как «продать» инженерам идею постмортемов? Обойти возражения, показать, почему постмортемы — круто, продемонстрировать пользу от отчетов, что это не просто отписка, лишь бы начальник отстал.
Возражение № 1: некогда
Это первая проблема инженера, который разбирает факап — вот кончится война, тогда и поговорим! Когда происходит факап, хочется быстро его починить, а писать непонятные нудные и длинные отчеты не хочется.
Для решения проблемы есть лайфхак, как что-то писать прямо во время аварии. Его популяризовал Артемий Лебедев:
«Существует простой способ организации времени — метод «прогрессивного джипега». В любую секунду любой проект готов на 100%, хотя проработанность может быть и на 4%. В зависимости от имеющегося времени, проект можно прорабатывать до пикселя, а можно оставить на стадии концептуальной зарисовки».
Проиллюстрирую метод прогрессивного джипега с помощью картинки. На медленном интернете картинка загружается не сразу, а этапами.

Во время пожара вам не нужно писать крутой и длинный отчет. Вам достаточно того, что в левом верхнем углу. Достаточно пометить те вещи, которые сложно будет восстановить по памяти. Не пытайтесь писать связный литературный текст в тот момент, когда на продакшене все сломано.
Выполните простое действие — запишите хронологию событий.
Хронология событий
Хронологию потом очень трудно восстановить, если не записать сразу. Пример записи из реального постмортема в Контуре.
15.01.18 17:25 YEKT
В логах много PrefixSearch с 50к документов в ответе.
Видно, что запросы отваливаются по троттлингу.Это короткое и простое наблюдение с меткой времени. По этой хронологии позже легко восстановить последовательность событий и найти причину поломки. Но если ничего не записывать прямо во время пожара, то будет сложно или вообще невозможно восстановить события позднее.
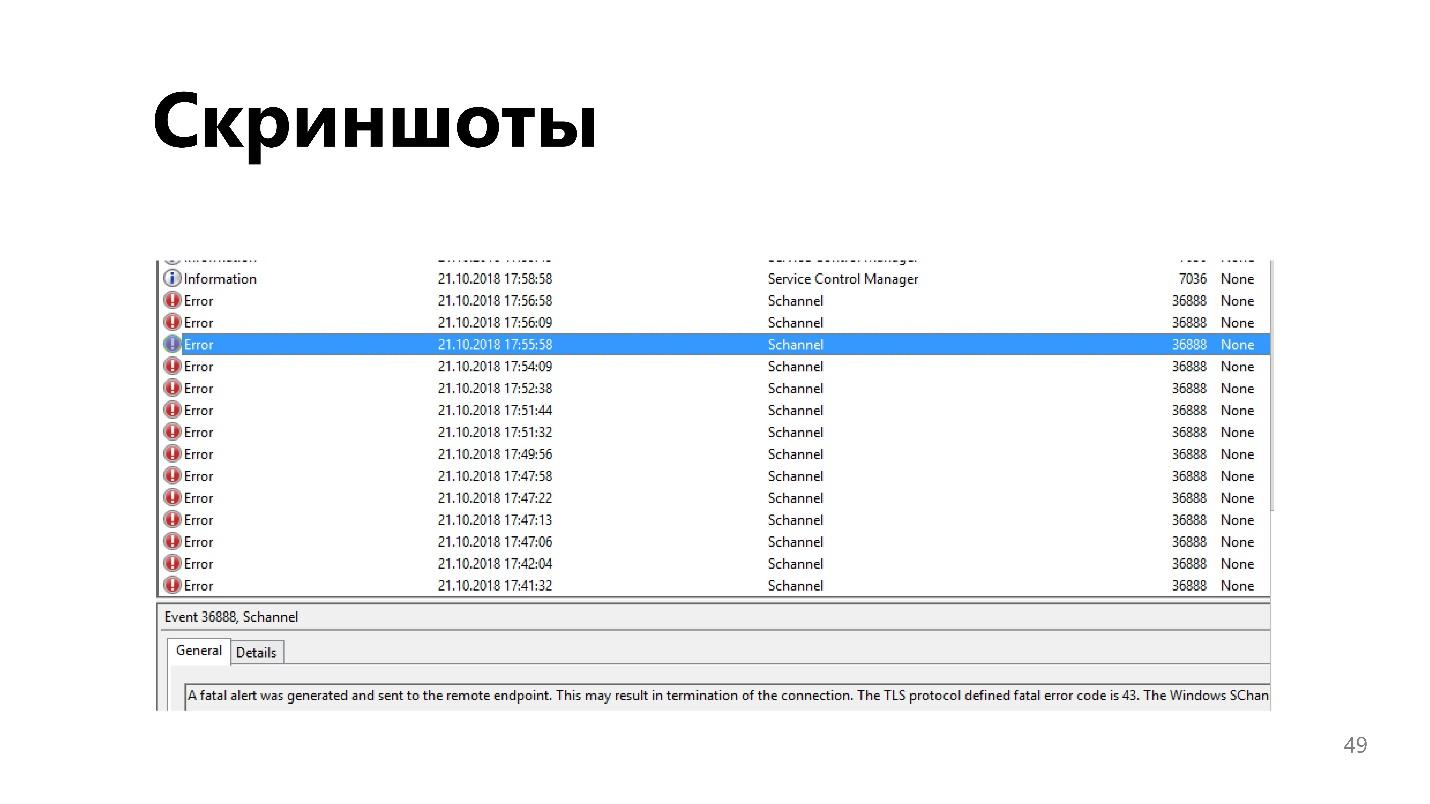
Скриншоты
Удобная вещь, особенно при работе с веб-сайтом или десктопным приложением. Ситуацию иногда сложно описать словами, а скриншот — это одно нажатие горячей клавиши.
Первое возражение отработали. Записать минимальные сведения, небольшой отчет во время инцидента не сложно и не отнимает драгоценное время. Когда все закончится, его нужно заполнить и оформить в понятный и связный документ.
Возражение № 2: лень
Вы два дня не спали и чинили серьезную аварию, фатально отстали по всем задачам, которые собирались выполнить за эту неделю. Но оказывается нужно еще что-то делать, а ведь пожар уже потушен! В этот момент настигает невообразимая лень.
Полностью победить проблему не получится. Но можно заранее облегчить себе работу.
Шаблон
Это первое и главное. Велик страх пустого документа, который требуется заполнить осмысленным текстом. Гораздо легче, если заготовлен шаблон. Обычно он состоит из разделов и вопросов в них. Вписываем ответы на вопросы в каждый раздел, и шаблон заполняется.
Шаблоны отчета об инциденте большие. Подробно о них почитайте у гуру. Во всех документах и книгах, на которые я ссылаюсь, есть шаблоны инцидента, которые используются в компаниях. По нашему опыту могу добавить следующее.
Создайте памятку с примерами
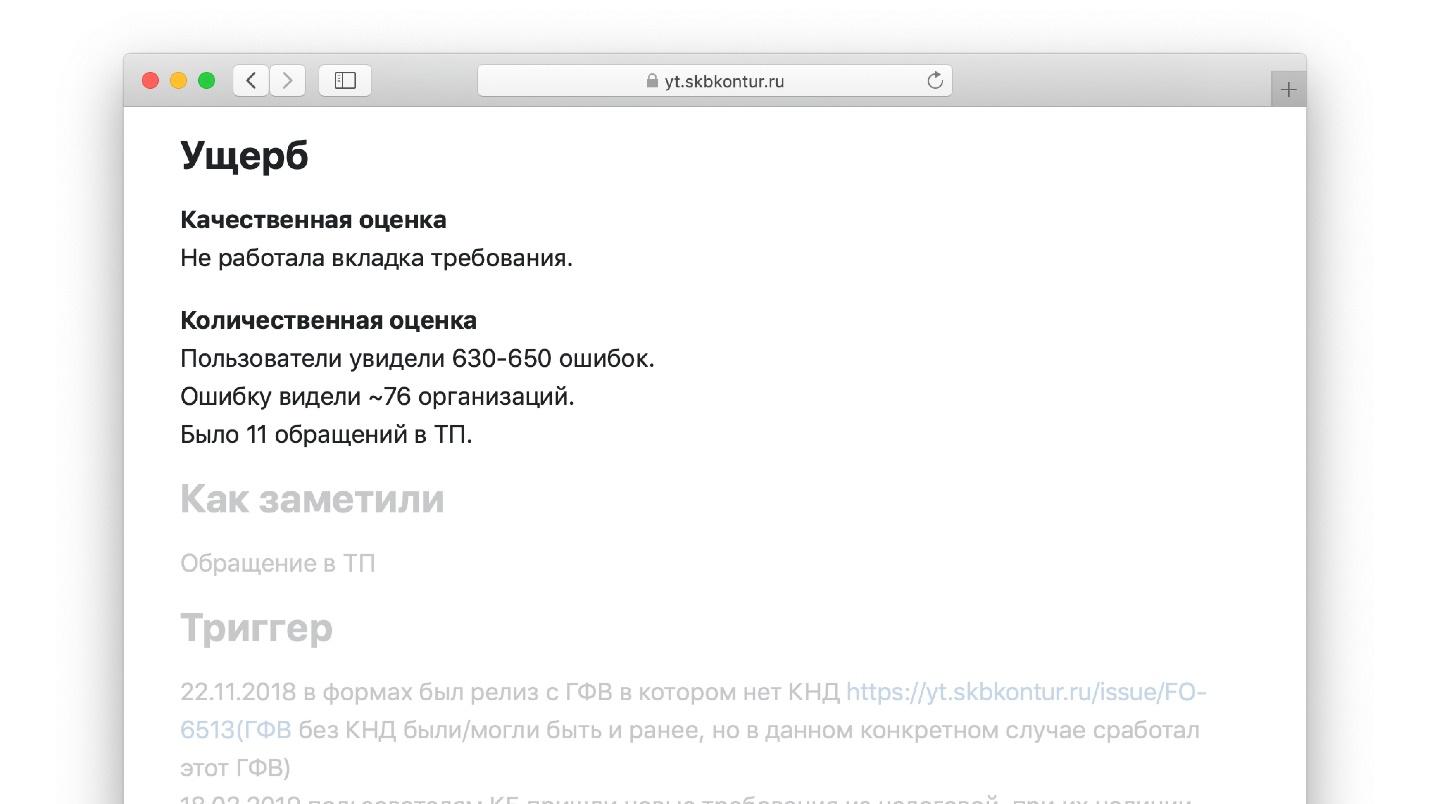
В нашем шаблоне есть раздел «Ущерб» с подразделами.
Раздел «Качественная оценка». В нем описывается, что видит перед собой инженер, когда заполняет эту часть шаблона:
- какая функциональность не работала, как долго и у кого;
- была ли потеря или порча данных.
Дойдя до этого места в шаблоне, инженер пишет: «В нашей блог-платформе миллион пользователей, мы потеряли все записи одного из них». Это гораздо проще, чем писать сочинение с нуля, как на уроке литературы.
Раздел «Количественная оценка»:
- сколько запросов отпало;
- насколько выросла latency по метрикам приложения и приложений-клиентов;
- сколько звонков потеряно;
- размер очереди обращений пользователей в техподдержку по проблеме.
Набор таких вопросов и есть шаблон.
Пример одного из заполненных шаблонов.
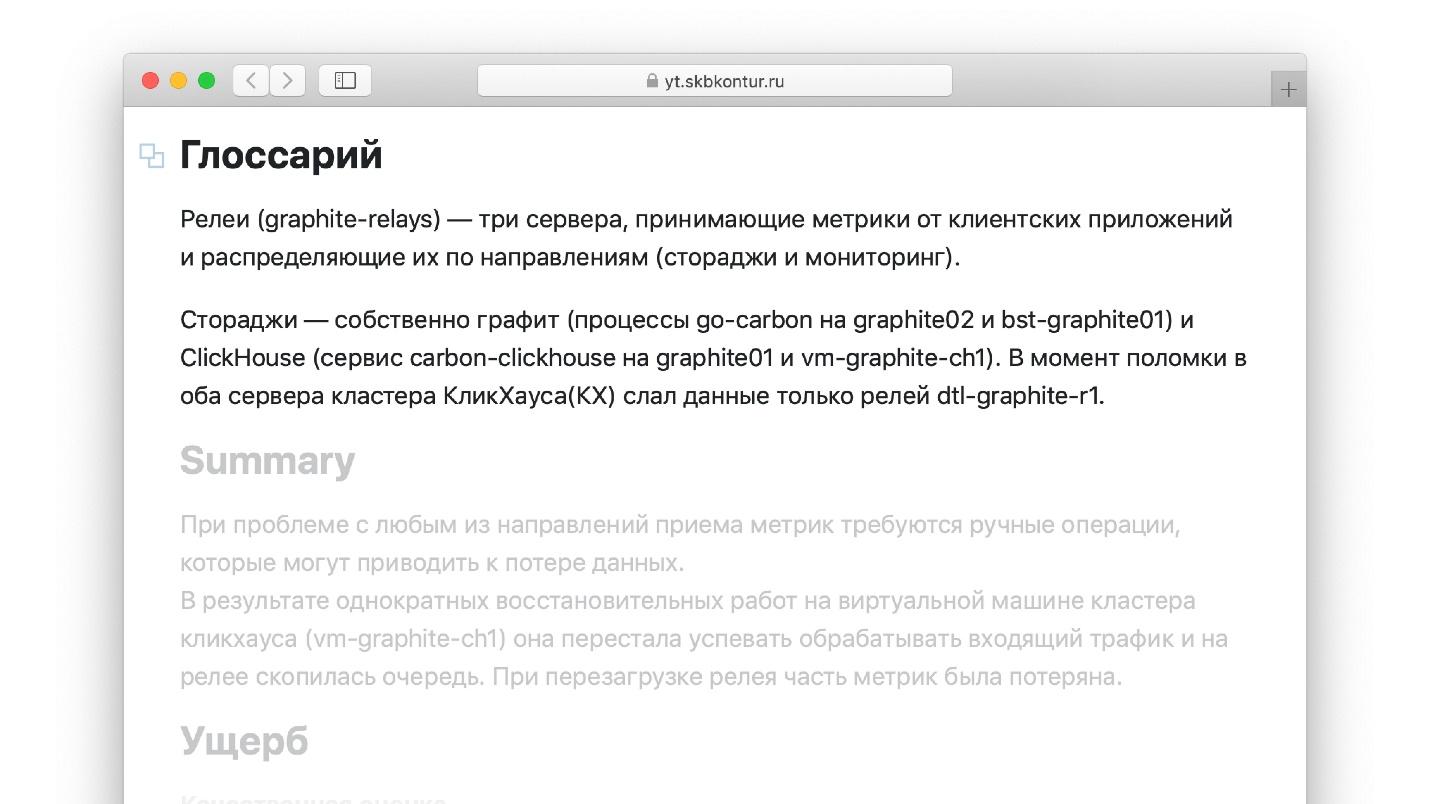
Добавьте глоссарий
Еще один лайфхак для отчетов об авариях, который я не видел в книжку у гуру. Когда пишете отчет, удобно оперировать терминами, которые вы хорошо знаете. Например, если я работаю с Graphite, в котором хранятся метрики, то хорошо знаю, что такое «relay». Но тот инженер, который будет читать отчет через год, возможно, не знаком с термином. Вряд ли он сможет прочитать отчет, который состоит из незнакомых слов. С другой стороны, если внутри отчета постоянно разжевывать каждый термин и определение, то лень просто отпугнет, и отчет не будет закончен.
Напишите небольшой глоссарий, в котором будут описаны все термины, используемые в отчете.
Копируйте все артефакты
Если прикладываете к отчету артефакты: снапшоты в Grafana, историю сообщений в чате, в котором разбирали инцидент с другими инженерами, — делайте копии. Метрики имеют свойство «протухать», а чаты меняться. Год назад вы были в Slack, сейчас в Telegram — ссылка на чат устарела и не работает, а метрики по retention отвалятся — они хранятся год.
Копируйте артефакты — этот лайфхак упрощает заполнение отчетов.
Возражение № 3: никто не будет читать
Самый большой и непонятный вопрос, который задают инженеры: «Кто эти отчеты будет читать?» Допустим, я поборол лень и написал хронологию событий во время аварии. Потом собрался с силами и дописал многостраничный отчет о том, что произошло, и причинах аварии. Но если нет понимания того, кто это все будет читать и кому принесет пользу, то заполнять отчеты нет желания.
Постмортем — это обратная связь в процессе непрерывного улучшения процессов разработки.
В любой книжке гуру, например, в Atlassian Incident Handbook, написано, что по результатам каждого постмортема требуется:
- сформулировать задачи в разработку;
- создать задачи в багтрекере, из которого ваши разработчики их возьмут;
- поставить на эти задачи ссылки из постмортема.
Обратная связь замыкается: вот постмортем, вот в нем action items — задачи, которые требуется выполнить, чтобы авария больше не повторилась. Задачи попадают в бэклог команде, команда их разрабатывает, выкатывает — снова факап и постмортем. Колесо сансары замкнулось.
Это то, в чем сходятся все гуру. Возразить нечего — польза очевидна.
Пример задач action items из реального постмортема.
Но мы в Контуре добавили к этому аналитику.
Диванная аналитика
Раньше мы анализировали инцидент в изоляции. Сбой произошел сам по себе в одной команде, в одной системе хостинга — что-то сломалось, мы починили.
Но инцидентов много. За три года в Контуре накопилось больше 1000 отчетов об инцидентах. Хочется знать, можно ли получить пользу от всей массы накопленных отчетов, а не только от каждого по отдельности. Можно ли на их основе посчитать статистику работы системы и увидеть, что улучшать в системе в целом.
В Контуре работает специальная инфраструктурная команда, которая занимается анализом постмортемов и публикует результаты и выводы на основе всей массы накопленных отчетов. Мы это называем «диванной аналитикой». Приведу фрагменты одной из статей команды, которая опубликована в нашей внутренней сети для сотрудников.
Что мы анализируем в диванной аналитике?
Длительность факапов
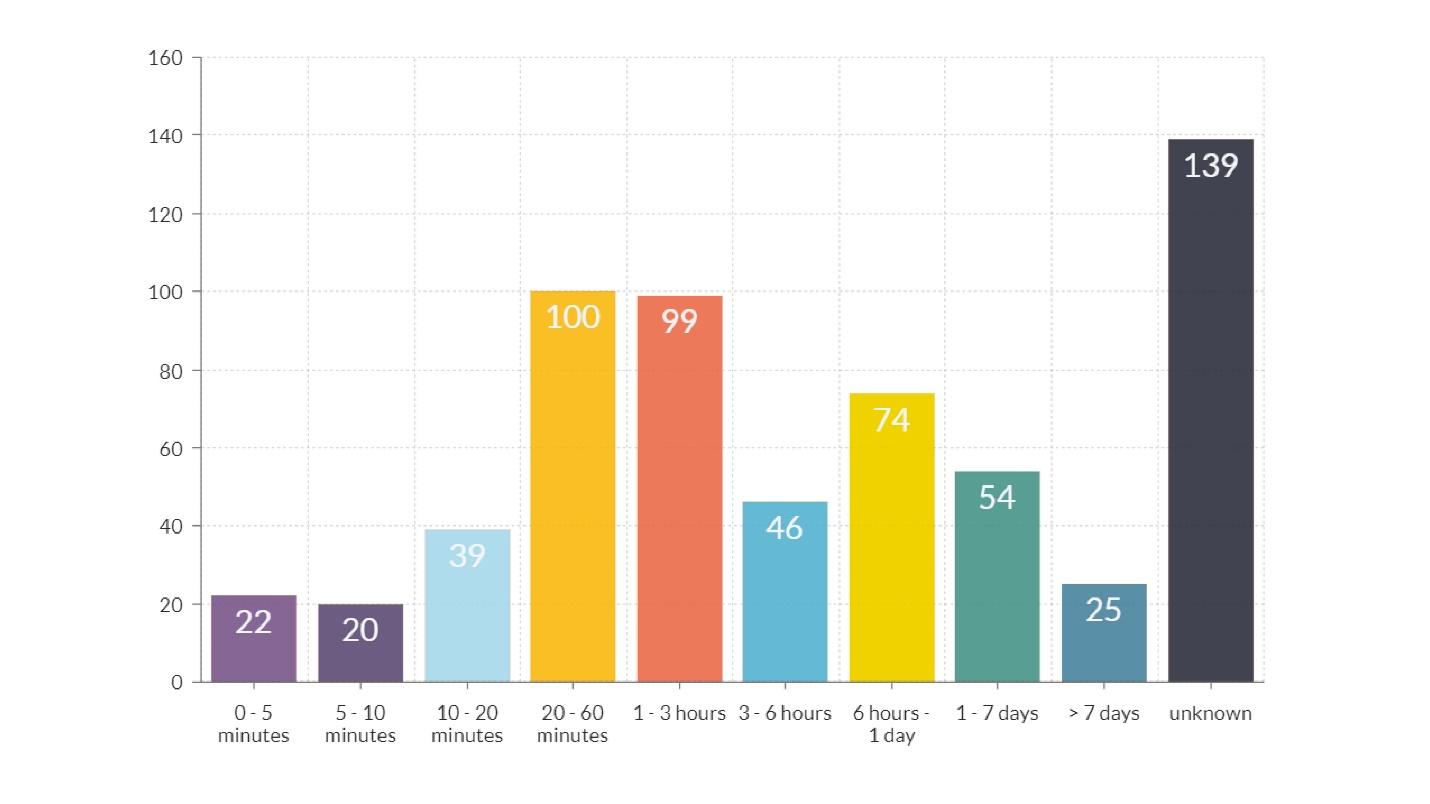
На диаграмме, кроме последнего столбика, где время неизвестно, есть еще два явных пика.
Длительность порядка часа — оранжевый и красный столбики. Большая часть из этого времени потрачена на передачу информации о том, что произошло, от инженера, который заметил аварию, до инженера, который знает, как все исправить. Проблема в коммуникации.
Если мы поправим наши инструменты так, что инженер, который исправляет проблему, будет получать информацию быстрее, то длительность факапов и ущерб от них сильно сократится. Это то, что мы бы не узнали, посмотрев на любой факап в отдельности.
Длительность порядка 12 часов — желтый столбик. Объяснение тому, что есть много факапов, которые длятся больше 12 часов, простое: выкатили релиз вечером, а утром пришли пользователи, и все сломалось. Вывод, что делать, чтобы таких факапов было меньше, очевиден.
Качественный ущерб

Качественный ущерб разделяем на несколько категорий. В топ-3 входят:
- недоступность, ошибки;
- тормоза, рост latency;
- видимое некорректное поведение.
По аналитике видно, что подобных ошибок подавляющее большинство. С одной стороны, это хорошая новость. Три вида самых частых ошибок легко обнаружить — настраиваем метрики на latency и количество ошибок, и быстро замечаем подобные вещи.
Плохая новость — таких ошибок больше всего. Это простые технические ошибки, значит, мы могли бы что-то улучшить в pipeline тестирования, проводить больше нагрузочных тестов и улучшать систему мониторинга.
Триггеры
Это то, что непосредственно привело к поломке, то есть не первопричина аварии, а «последняя капля»: логи заполнили диск и из-за этого все сломалось, выложили в релиз — все взорвалось.

На первом месте — «установка обновления». Эта причина позволяет понять, куда нам как инфраструктурной команде вкладывать усилия. Например, улучшать систему деплоя и внедрять канареечный деплой. Это точка приложения усилий, которая окажет наибольшее воздействие на качество наших систем.
В этом смысл всей аналитики — понимать, куда небольшой инфраструктурной команде вкладывать усилия прямо сейчас в условиях ограниченных ресурсов.
Что улучшить — алёртинг или деплой? Чем заняться — хостингом или красотой графиков?
Здесь есть еще один неплохой инсайт. На втором месте — «причина неизвестна». Это показатель некачественного заполнения отчетов об инцидентах.
Возможные «таблетки»
То, что позволяет простым техническим решением сократить количество аварий определённого типа. Например, мы знаем, что самые важные вещи, которые уменьшают количество факапов — это уведомления от системы мониторинга. Если бы алертов в мониторинге на эти события было больше, то сколько инцидентов мы могли бы предотвратить? В процентах указано, сколько:
- на число HTTP-ошибок со стороны клиента — 10 %;
- на появление новых типов ошибок в логах: установка, настройка уведомлений — 8 %;
- на системные ресурсы: CPU, memory, disk, threads, GC — 6 %.
Если бы алерт был правильно настроен, а нужный инженер вовремя получил уведомление, 24% инцидентов либо не произошли, либо имели бы гораздо меньшую продолжительность. Этот вывод можно сделать на основании анализа всей массы инцидентов.
Здесь еще раз прорекламирую нашу систему алертинга Moira, которая находится в Open Source.
Если у вас Graphite, можете ее скачать и пользоваться. Надеюсь, инцидентов станет меньше.
Рекомендации
Организационные рекомендации, которым команда может следовать, и тоже уменьшать количество аварий. Наш топ-3.
- Схожесть тестовой и боевой площадки. 5 % инцидентов произошли из-за того, что тестовая площадка была недостаточно похожа на боевую.
- Обратная совместимость в релизах. Релиз был выкачен, не был обратно совместим с предыдущим, возникли миграции данных — 4% ошибок.
- Отказ от ночных релизов. Если перестать выкладывать релизы, которые ломаются, вечером, пропадет еще 4% инцидентов.
Подчеркну, что это не инструкция, а рассказ о том, как мы собирали аналитику. Ваша аналитика может быть другой.
Как писать
Если вы осознали, что аналитика инцидентов — классная штука, и отчеты нужно писать, расскажу, как это делать.
Ведите постмортемы и задачи в одном багтрекере
В багтрекере, в отличие от Google Docs или Wiki, есть фиксированные поля, у которых можно задавать набор значений. Это облегчает анализ построения графиков статистики позже.
В книге SRE Google приводит шаблон в Google Docs, в котором они пишут отчеты в своем внутреннем документе. Я не представляю, как можно собрать по неструктурированным Google-документам аналитику, которую собираем мы.
Мы пишем отчеты в том же багтрекер, что и основные задачи, потому что можем связать задачу с постмортемом. Заглянем в постмортем и сразу видим, какие задачи закрыты, какие нет, а какие еще осталось сделать.
Заведите специальные поля
Я уже рассказывал про специальные поля. У нас есть следующие.
- Начало и конец факапа можно автоматически анализировать. Если поставите машиночитаемые time-stamps, то сможете построить график продолжительности факапа.
- Начало и конец расследования.
- Триггер. Настройте выпадающий список триггеров, так удобнее.
- Как заметили.
- Количественный и качественный ущерб.
- Затронутые команды и сервисы.
Все данные из специальных полей позволяют понимать, как работает ваша инфраструктура.
Пример нашего заполненного отчета по инциденту.

Поля правого столбца как раз заполняются через выбор из выпадающих списков.
Соберите команду инженеров, которых волнует качество
Чтобы получить отчеты, которые помогут понять, как развивать инфраструктуру, вам понадобятся люди, которых волнует качество ваших сервисов. Не обязательно это будут инженеры, которые full-time занимаются только анализом постмортемов. Важно, чтобы это были люди, которых очень волнует происходящее. Время от времени они будут собираться, анализировать всю массу инцидентов, писать большие статьи и приносить пользу — замыкать кольцо обратной связи.
Наша команда называется Q-team — от слова «Quality». В ней 3 человека — одни из самых талантливых инженеров компании, которые работают в инфраструктуре.
Итого
Читайте гуру — статью John Allspaw и книги, посвященные инцидент-менеджменту: Site Reliability Engineering, PagerDuty Post-Mortem Process, Atlassian Incident Handbook.
А когда придете завтра на работу, просто сделайте первые шаги:
- заведите проект для факапов в багтрекере, в котором вы ведете задачи;
- возьмите любой шаблон — не пытайтесь писать свой, возьмите наш, или у Google в SRE;
- когда что-то взорвется, просто пишите.
В тот момент, когда вы напишете первый, второй, третий отчет, у вас не будет красивой аналитики с разноцветными столбиками. Но через год–два, когда накопятся данные, вы посмотрите назад и поблагодарите себя за первый шаг.
Надеемся, тогда же вы вспомните и поблагодарите и Алексея за рассказ о таком опыте. А мы в свою очередь постараемся собрать в программу DevOpsConf новые полезные доклады, рекомендации из которых можно идти и применять. Конференция состоится 30.09–1.10.2019, до 20 августа мы еще ждём заявки от приверженцев DevOps, но 12 тем уже утвердили, то есть ближе к дедлайну конкуренция будет выше.
Хотите поделиться опытом — решайтесь и присылайте тезисы. Хотите получать новости программы — подпишитесь на нашу рассылку и telegram-канал.
