
Инфраструктура — это то, от чего зависит работа и прибыль IT-бизнеса. Все процессы, которые происходят с кодом от компьютера разработчика и до продакшена, зависят от бесперебойной работы серверов, ПО, внешних сервисов. Если инфраструктура не работает как надо, бизнес теряет прибыль.
Стартапы не особо уделяют внимание инфраструктуре — надо продукт пилить, пока деньги инвесторов не кончились. В больших компаниях уже не до нее — у нас тут тысячи задач, работать надо.
До понимания, что инфраструктура IT-компании это тоже продукт, что у нее есть цель, что надо считать затраты и отслеживать метрики, дело часто не доходит.
Знаете ли вы сколько стоит ваша инфраструктура: серверы, ПО, внешние сервисы? Как вы считаете затраты на нее, по каким метрикам? Сколько вы потеряете, если что-то упадет или не будет бэкапа? Ответы на эти вопросы знает Артём Науменко (@entsu) из Skyeng. Он работал как в компаниях с двумя разработчиками в штате, так и в корпорациях с тысячей сотрудников. Сейчас руководит инфраструктурой в Skyeng и, одновременно, СТО детского обучения Skyeng. Артем расскажет как в компании строят инфраструктуру, как зарабатывают на ней деньги и какие ошибки не стоит допускать.
Skyeng — это молодая компания, ей всего 6 лет. Но все это время она растет в 3 раза каждый год.
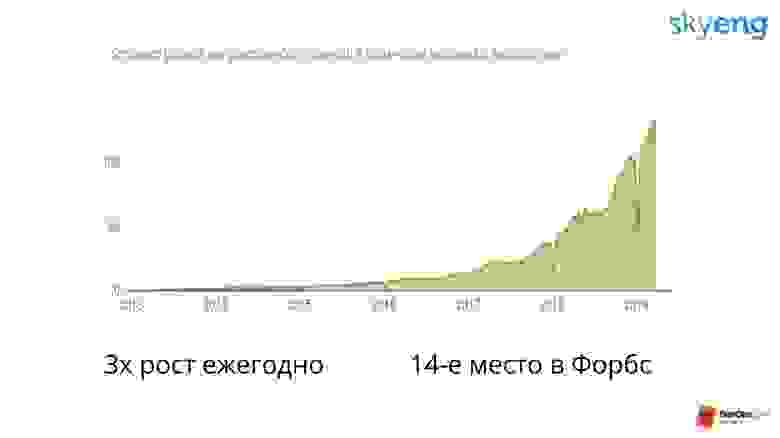
Это значит, что инфраструктура также каждый год растет троекратно. Сегодня у нас 100 серверов, через год 300, а через два — 900. Это непросто, мы напрягаемся, чтобы обеспечить такой рост.
Skyeng — это IT-компания. Компания молодая, большого количества legacy еще нет, все стандартно для PHP-стека:
Разработчиков около сотни. Компания растет и к концу года будет уже больше.

Большинство наших сервисов написаны нами, и весь бизнес компании крутится на собственной инфраструктуре. За ней следит команда инфраструктуры из 6 человек. Мы обеспечиваем все процессы, которые происходят с кодом от компьютера разработчика и до продакшн. Код разрабатывается на наших виртуалках и серверах, деплой — с помощью настроенного нами Jenkins и наших средств деплоя, эксплуатация на продакшн тоже на наших серверах, которыми мы заведуем.
Цель компании — вырасти за 2 года в 7 раз. Инфраструктура должна вырасти аналогично. Чтобы достичь цели, каждый участник команды девопсов работает как вол. Каждый год мы должны быть лучше, чем в прошлом году в 3 раза, а в будущем — в 7 раз. В Skyeng никому не интересны красивые истории, что «старался, но не получилось». Важен результат, а не процесс.
Бизнес любой IT-компании работает на инфраструктуре. Если она не работает — не работает бизнес, будь это Яндекс, Амазон или Skyeng. Мы это осознаем, поэтому первое, что важно для крутой инфраструктуры — поставить цель. Звучит как речь Тони Роббинса, но без поставленной цели ничего не получится.
Цель нужно ставить по двум причинам.
Одной лишь постановки цели недостаточно. Цель компании — это рост в 7 раз за 2 год. Во время роста будут встречаться проблемы. Они различаются, в зависимости от размера и типа компании.
Первый тип компаний и людей — стартапы. На картинке ниже «типичный стартап» — плот и маленькая команда, которая пытается на нем куда-то уплыть. Достоинства стартапа это то, что каждый член команды понимает, куда команда движется, кто чем занимается, и что он должен сделать для достижения общей цели.

Проблема стартапов — это отсутствие денег. Когда на девопса сваливается большой объем задач, он не успевает и просит себе помощника. Обычно на это получает ответ: «Зачем? Ты справляешься, все норм — продолжай!»
Следующий тип — огромные корабли. Отдельные члены команды корабля не видят, куда он плывет. Они выполняют свою маленькую функцию, например, забрасывают уголь в топку, а что происходит глобально, не понимают.

Главная проблема кораблей — нужно все больше и больше задач. Сто заказчиков, у каждого проблемы, непонятно как приоритезировать, общая картина размыта, но мы «работаем дальше»! Времени никогда не хватает, а задач требуется все больше и больше. Команда никогда не сможет построить конвейер, который бы забрасывал уголь в топку, чтобы работать над важными задачами.
Третий тип — руководители. Главная проблема руководителей инфраструктуры — дорогие серверы, дорогая инфраструктура и непонимание, как расходы на инфраструктуру отражаются на доходах бизнеса в целом. Руководителю нужно как-то отвечать на вопросы о том, почему столько миллионов за серверы, будем ли меньше лежать, если больше платить, и что будет, если платить меньше.

Опишу, какие цели в Skyeng мы ставим перед своей инфраструктурой в разрезе глобальных целей компании, и как их достигаем. У инфраструктуры есть 4 цели.
Следить за бюджетом. Компания — это коммерческая структура для заработка денег, поэтому мы должны их считать.
Решать задачи быстро. Не подняли сервер вовремя, не запустится новый сервис компании и не будет зарабатывать деньги. Вовремя не восстановили бэкап — опять что-то не будет работать, и компания будет терять прибыль.
Удобство разработчиков. Этот пункт требует отдельного пояснения. В прошлом году Skyeng потратил 600 млн рублей на разработку. Если бы мы, как инфраструктура, хотя бы на 1% повысили скорость разработчиков, то заработали бы 6 млн. Если посадить двух ребят на фуллтайм, которые повысят производительность на 1% — это будет выгодно.
Долгосрочный результат. Мы не должны один раз напрячься, сделать что-то крутое, чтобы все порадовались, а дальше бы все порушилось. То, что мы делаем, должно работать долго.
Чтобы это все заработало, к целям нужно придумать метрики. Они должны быть измеримы, иначе это не цели, а ерунда. Цели должны выражаться цифрами и графиками.
Рассмотрим пункты подробнее.
Измерение инфраструктуры в разрезе компании — это то, какая часть из расходов компании уходит на инфраструктуру.

Skyeng — это школа, а главная ценность — урок. Средний урок стоит 800 рублей. Из них 12 идет на инфраструктуру: на серверы и работу девопсов.
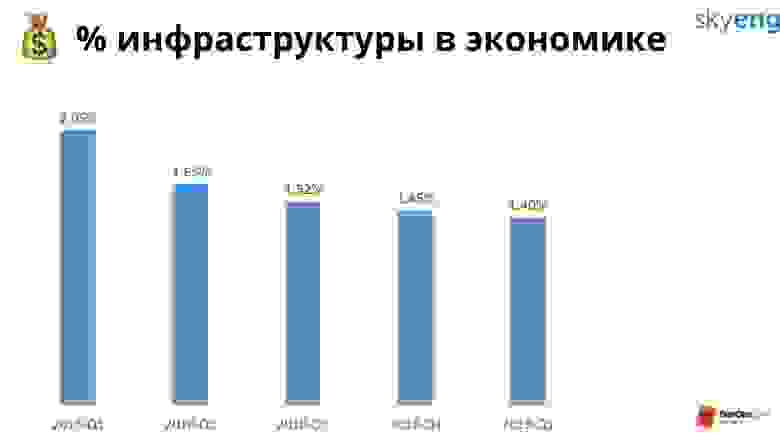
Процент инфраструктуры падает, мы работаем над этим. Это выгодно нам, бизнесу и клиентам. Можно взять дешевые серверы, не делать бэкапы и еще сильнее уронить этот график. Но это неправильно, нужно считать не просто расходы на инфраструктуру, а расходы на инфраструктуру и ожидаемые убытки от падений.
Для каждого сервиса считаем, сколько денег в час мы теряем от его падения. Мы ведем подробный лог того, когда и какой сервис лежал, и сколько мы на этом потеряли.

График убытков от падений за прошлый год.
Больше всего потерь во втором квартале 2018 года — привет Роскомнадзору! Расходов на инфраструктуру в прошлом году было 20 млн, расходов на падение — 5 млн. Если бы мы все зарезервировали, то это спасло бы нас от Роскомнадзора, но мы бы все равно были в минусе на 15 млн.
Мы дублируем те сервисы, для которых расходы на дополнительный сервер или БД ниже, чем ожидаемые риски от падений.
Мы измеряем процент задач, которые выполнены в день постановки. В инфраструктуру приходит много задач, которые требуется решить прямо здесь и сейчас. От этого зависят другие команды, которые не могут выполнять свою работу. Большие задачи, на которые требуются недели, считаются отдельно.

График задач в день постановки.
По графику вероятность выполнения задачи в день постановки примерно 80%. Мы видим этот график и считаем, что все круто. Но другие команды могут так не думать и оценивать иначе. Поэтому мы проводим опросы других команд.

Пример опроса.
Опросы проводим через обычную Google-форму с вопросами. Разработчики и другие наши заказчики регулярно на них отвечают.

Результат опроса по скорости работы инфраструктуры.
Текущее состояние дел отлично описывается опросами, но не будущее. Для оценки вероятности положения дел в будущем мы измеряем количество задач, выполненных с помощью pull request. Это то, что принесет пользу через год или два.
Полгода назад мы решили, что пойдем в «инфраструктуру как код». Здесь мы измеряем все запросы в инфраструктуру: залить dump или кусочек логов, поправить точку nginx на проде или создать новый сервер. Это все запросы, и мы их все оцениваем по количеству pull requests. В будущем хотим, чтобы любой запрос решался с помощью pull request или, чтобы нам его просто не задавали.
Мы знаем, что подход «инфраструктура как код» дает три главных бонуса:
Нам нужны все три из трех, поэтому мы двигаемся в эту сторону и измеряем, насколько близко подошли.

Для логов есть система визуализации, для выдачи доступов есть Terraform. Можно сделать систему, при которой все будет автоматизировано. В идеале этот график должен уйти в 100%. Когда любое обращение будет сделано с помощью кода, мы сможем его быстро выполнять и разворачивать в другой инфраструктуре так же быстро.
Это важно для Skyeng. Сейчас у нас 100 разработчиков, к концу года их будет 120. Важно, чтобы они работали эффективно. Мы хотим нанимать людей не просто так, нам нужны те, кто будет улучшать компанию.

В целом все ОК.
Большинство оценивает нас хорошо. Но если спросить, насколько они довольны окружением разработки, то все не так приятно.

Окружение разработки — наша головная боль. Это точка роста, которую нужно улучшать. Поэтому мы лично опрашиваем сотрудников, которые ответили хуже всего: в чем проблема, что у него тормозило или не работало? Зная, что происходит, можно улучшить положение дел.
Любую из наших метрик можно увеличить, просто сконцентрировавшись на ней. Например, для увеличения процента задач, выполненных в тот же день, можно все бросить и решать только задачи, которые прилетели. Можно делать все задачи с помощью кода.
Например, в некотором городе «N» все силы тратят на развитие дорог. Они делают ровные, широкие, многополосные трассы в городе. Это круто первый, второй год. Но все остальные сферы деградируют: доступной среды нет, деревья вырубают, машин все больше, парковок не хватает, а экология уже уехала из города по этим дорогам. Через 5-10 лет в соседнем городе уже появятся автономные такси и гиперлупы, а здесь все еще просто ровные дороги. Понятно, что это путь в никуда.
Мы не должны такого допускать, нам нужно смотреть наперед. Поэтому мы измеряем количество времени, которое тратим на разработку и на поддержку.

На графике видно, что последние месяцы мало времени уходит на разработку. Для меня, как для руководителя, это признак того, что нужны люди или автоматизация процессов. По графику я даже могу рассчитать, через сколько месяцев все ресурсы будут уходить на поддержку, когда мы не будем успевать и наступит коллапс.
Мы поставили цель и подумали над метриками, но пока не приступим к реализации руками, ничего не изменится. Делать нужно не просто что-то, а самые выгодные задачи с точки зрения метрик и времени.
Любые две задачи можно сравнить по времени: на первую уйдет неделя, на вторую — 3 часа. Это не зависит от того, из какого отдела поступила задача. С метриками сложнее — их много. Как просчитать, какую задачу делать выгоднее: первую или вторую, если одна оптимизирует одни метрики, а другая другие?
Для себя мы это решили просто — придумали универсальную единицу, которая описывает любые задачи. Наша универсальная единица — рубль. Мы оцениваем пользу от любой задачи по прибыли, которая она принесет и делим на время, которое потребуется на выполнение этой задачи. Так мы оцениваем каждую задачу с точки зрения метрик (рублей) и времени.

Наши квартальные задачи.
На скриншоте ниже в двух последних колонках записано сколько денег мы заработаем на задаче и сколько времени потратим на выполнение. Команда инфраструктуры зарабатывает деньги тем, что улучшает условия для разработчиков, оптимизирует процессы в компании и работу серверов. Мы переходим на Docker не потому, что это круто, а потому что мы посчитали, что это выгодно.

Дополнительные метрики, которые мы измеряем.
Опережающие:
Запаздывающие:
Это лишь часть метрик, у нас их больше.
Мы не оцениваем баги. Если мы взяли какую-то систему на поддержку и поддерживаем ее, то фиксим баги просто потому, что их там быть не должно.
Это же относится к поддержке. Мы измеряем в целом, сколько времени уходит на поддержку, и не допускаем, чтобы его было слишком много. Мы оцениваем каждую систему в целом на предмет пользы или вреда от нее. Задачи, которые проще сделать или они очень срочные, мы не оцениваем. Все, о чем я говорил, к ним не относится — мы просто их делаем.
Премии и достижения. С бизнесом всегда нужно говорить на языке денег. Он понимает только деньги. Если вы скажете, что у вас есть проект, вы его запилите, он принесет 5 млн, и попросите премию миллион на команду — с вами согласятся. Для бизнеса это понятно.
Найм. Не предлагайте бизнесу нанимать сотрудников и внедрять новые технологии, а предлагайте вместе заработать деньги. Тогда он точно пойдет навстречу. Как минимум, обсуждение начнется не по пути «успеваешь ты или не успеваешь, нужен тебе человек или нет», а насколько крутой проект, для которого нужен человек, справится ли он, и реально ли проект принесет столько миллионов. Разговор пойдет в другом русле, и вы сами заранее поймете, достоин ли этот проект затрат или проще выбросить и искать другой?
Оптимизация затрат. Если мы понимаем, на что уходят деньги, мы легко их можем считать и оптимизировать расходы.
Административные решения. Этот пункт я осознал недавно. Инфраструктура начала разрастаться и я решил разбить команду на подкоманды. Встал вопрос о том, как именно это сделать, с целью дальнейшего наращивания персонала. Решение появилось исходя именно из метрик — поделил все метрики нашей инфраструктуры на блоки, и каждая команда отвечает за свои метрики. У меня получилось 3 подкоманды. По каждой понятна общая зона ответственности и все участники в ней понимают, за что отвечают лично. Это понятная зона ответственности.
Тогда вас обязательно ждет успех!
Стартапы не особо уделяют внимание инфраструктуре — надо продукт пилить, пока деньги инвесторов не кончились. В больших компаниях уже не до нее — у нас тут тысячи задач, работать надо.
До понимания, что инфраструктура IT-компании это тоже продукт, что у нее есть цель, что надо считать затраты и отслеживать метрики, дело часто не доходит.
Знаете ли вы сколько стоит ваша инфраструктура: серверы, ПО, внешние сервисы? Как вы считаете затраты на нее, по каким метрикам? Сколько вы потеряете, если что-то упадет или не будет бэкапа? Ответы на эти вопросы знает Артём Науменко (@entsu) из Skyeng. Он работал как в компаниях с двумя разработчиками в штате, так и в корпорациях с тысячей сотрудников. Сейчас руководит инфраструктурой в Skyeng и, одновременно, СТО детского обучения Skyeng. Артем расскажет как в компании строят инфраструктуру, как зарабатывают на ней деньги и какие ошибки не стоит допускать.
О компании
Skyeng — это молодая компания, ей всего 6 лет. Но все это время она растет в 3 раза каждый год.
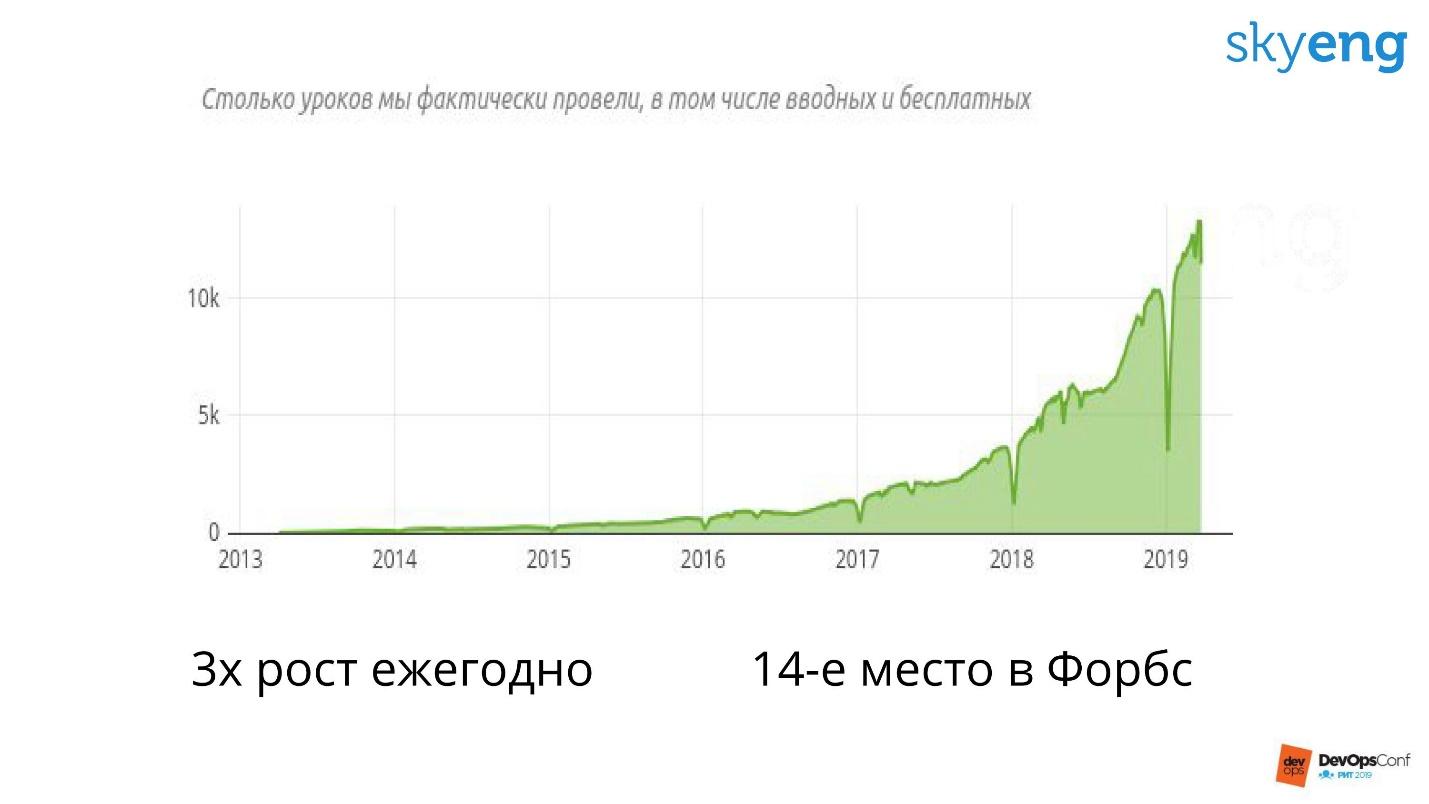
Это значит, что инфраструктура также каждый год растет троекратно. Сегодня у нас 100 серверов, через год 300, а через два — 900. Это непросто, мы напрягаемся, чтобы обеспечить такой рост.
Skyeng — это IT-компания. Компания молодая, большого количества legacy еще нет, все стандартно для PHP-стека:
- PHP;
- Angular;
- PostgreSQL;
- Linux, на котором все крутится.
Разработчиков около сотни. Компания растет и к концу года будет уже больше.

Большинство наших сервисов написаны нами, и весь бизнес компании крутится на собственной инфраструктуре. За ней следит команда инфраструктуры из 6 человек. Мы обеспечиваем все процессы, которые происходят с кодом от компьютера разработчика и до продакшн. Код разрабатывается на наших виртуалках и серверах, деплой — с помощью настроенного нами Jenkins и наших средств деплоя, эксплуатация на продакшн тоже на наших серверах, которыми мы заведуем.
Цель компании — вырасти за 2 года в 7 раз. Инфраструктура должна вырасти аналогично. Чтобы достичь цели, каждый участник команды девопсов работает как вол. Каждый год мы должны быть лучше, чем в прошлом году в 3 раза, а в будущем — в 7 раз. В Skyeng никому не интересны красивые истории, что «старался, но не получилось». Важен результат, а не процесс.
Принципы построения инфраструктуры
Бизнес любой IT-компании работает на инфраструктуре. Если она не работает — не работает бизнес, будь это Яндекс, Амазон или Skyeng. Мы это осознаем, поэтому первое, что важно для крутой инфраструктуры — поставить цель. Звучит как речь Тони Роббинса, но без поставленной цели ничего не получится.
Цель нужно ставить по двум причинам.
- Если у вас есть цель, вы будете к ней двигаться.
- Если цели нет, то идти некуда. Даже если куда-то придете, вы не сможете получить кайф от достигнутой цели.
Если нет цели, ее невозможно достичь.
Проблемы компании
Одной лишь постановки цели недостаточно. Цель компании — это рост в 7 раз за 2 год. Во время роста будут встречаться проблемы. Они различаются, в зависимости от размера и типа компании.
Первый тип компаний и людей — стартапы. На картинке ниже «типичный стартап» — плот и маленькая команда, которая пытается на нем куда-то уплыть. Достоинства стартапа это то, что каждый член команды понимает, куда команда движется, кто чем занимается, и что он должен сделать для достижения общей цели.

Проблема стартапов — это отсутствие денег. Когда на девопса сваливается большой объем задач, он не успевает и просит себе помощника. Обычно на это получает ответ: «Зачем? Ты справляешься, все норм — продолжай!»
Следующий тип — огромные корабли. Отдельные члены команды корабля не видят, куда он плывет. Они выполняют свою маленькую функцию, например, забрасывают уголь в топку, а что происходит глобально, не понимают.

Главная проблема кораблей — нужно все больше и больше задач. Сто заказчиков, у каждого проблемы, непонятно как приоритезировать, общая картина размыта, но мы «работаем дальше»! Времени никогда не хватает, а задач требуется все больше и больше. Команда никогда не сможет построить конвейер, который бы забрасывал уголь в топку, чтобы работать над важными задачами.
Третий тип — руководители. Главная проблема руководителей инфраструктуры — дорогие серверы, дорогая инфраструктура и непонимание, как расходы на инфраструктуру отражаются на доходах бизнеса в целом. Руководителю нужно как-то отвечать на вопросы о том, почему столько миллионов за серверы, будем ли меньше лежать, если больше платить, и что будет, если платить меньше.

Цели инфраструктуры
Опишу, какие цели в Skyeng мы ставим перед своей инфраструктурой в разрезе глобальных целей компании, и как их достигаем. У инфраструктуры есть 4 цели.
Следить за бюджетом. Компания — это коммерческая структура для заработка денег, поэтому мы должны их считать.
Решать задачи быстро. Не подняли сервер вовремя, не запустится новый сервис компании и не будет зарабатывать деньги. Вовремя не восстановили бэкап — опять что-то не будет работать, и компания будет терять прибыль.
Удобство разработчиков. Этот пункт требует отдельного пояснения. В прошлом году Skyeng потратил 600 млн рублей на разработку. Если бы мы, как инфраструктура, хотя бы на 1% повысили скорость разработчиков, то заработали бы 6 млн. Если посадить двух ребят на фуллтайм, которые повысят производительность на 1% — это будет выгодно.
Долгосрочный результат. Мы не должны один раз напрячься, сделать что-то крутое, чтобы все порадовались, а дальше бы все порушилось. То, что мы делаем, должно работать долго.
Чтобы это все заработало, к целям нужно придумать метрики. Они должны быть измеримы, иначе это не цели, а ерунда. Цели должны выражаться цифрами и графиками.
Рассмотрим пункты подробнее.
Бюджет
Измерение инфраструктуры в разрезе компании — это то, какая часть из расходов компании уходит на инфраструктуру.
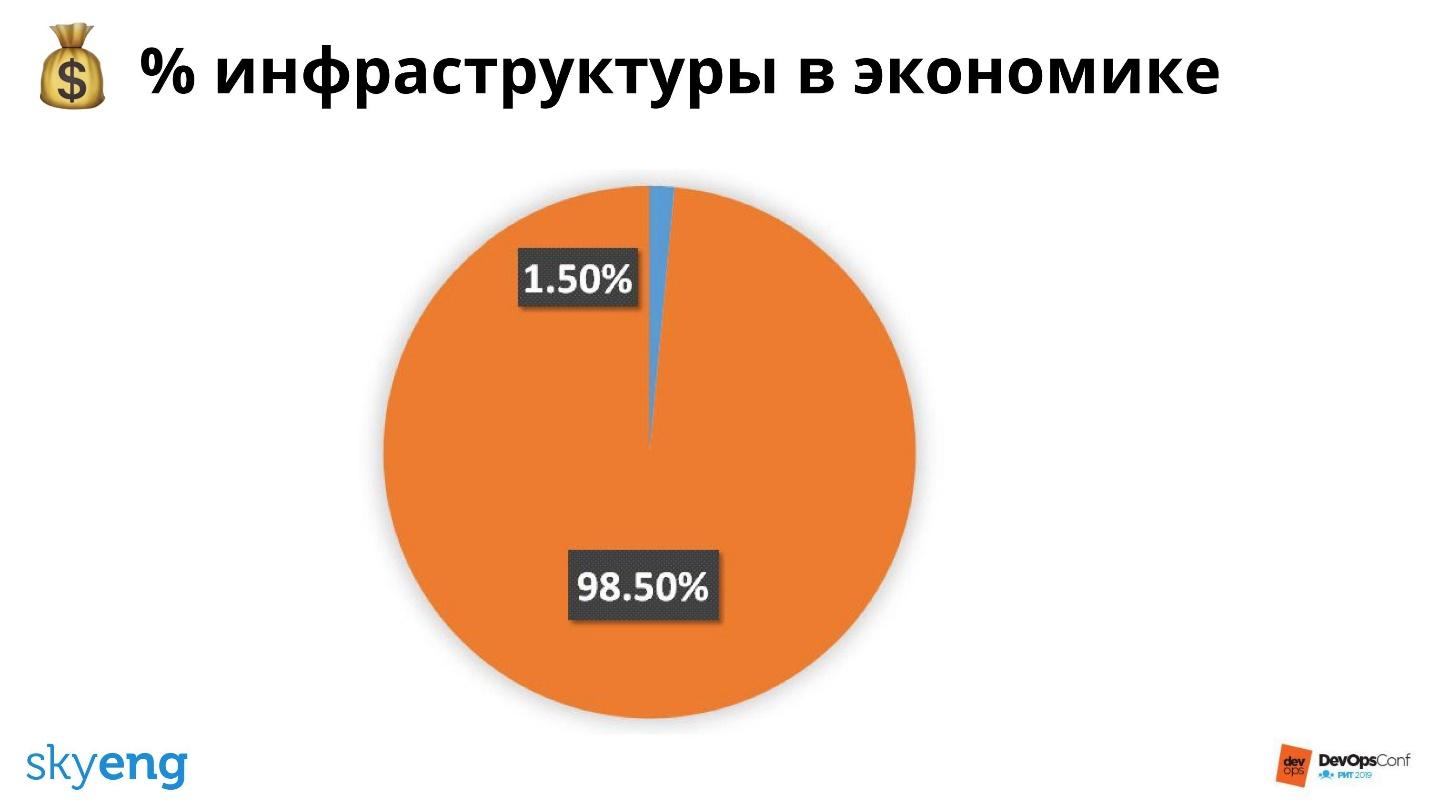
Skyeng — это школа, а главная ценность — урок. Средний урок стоит 800 рублей. Из них 12 идет на инфраструктуру: на серверы и работу девопсов.
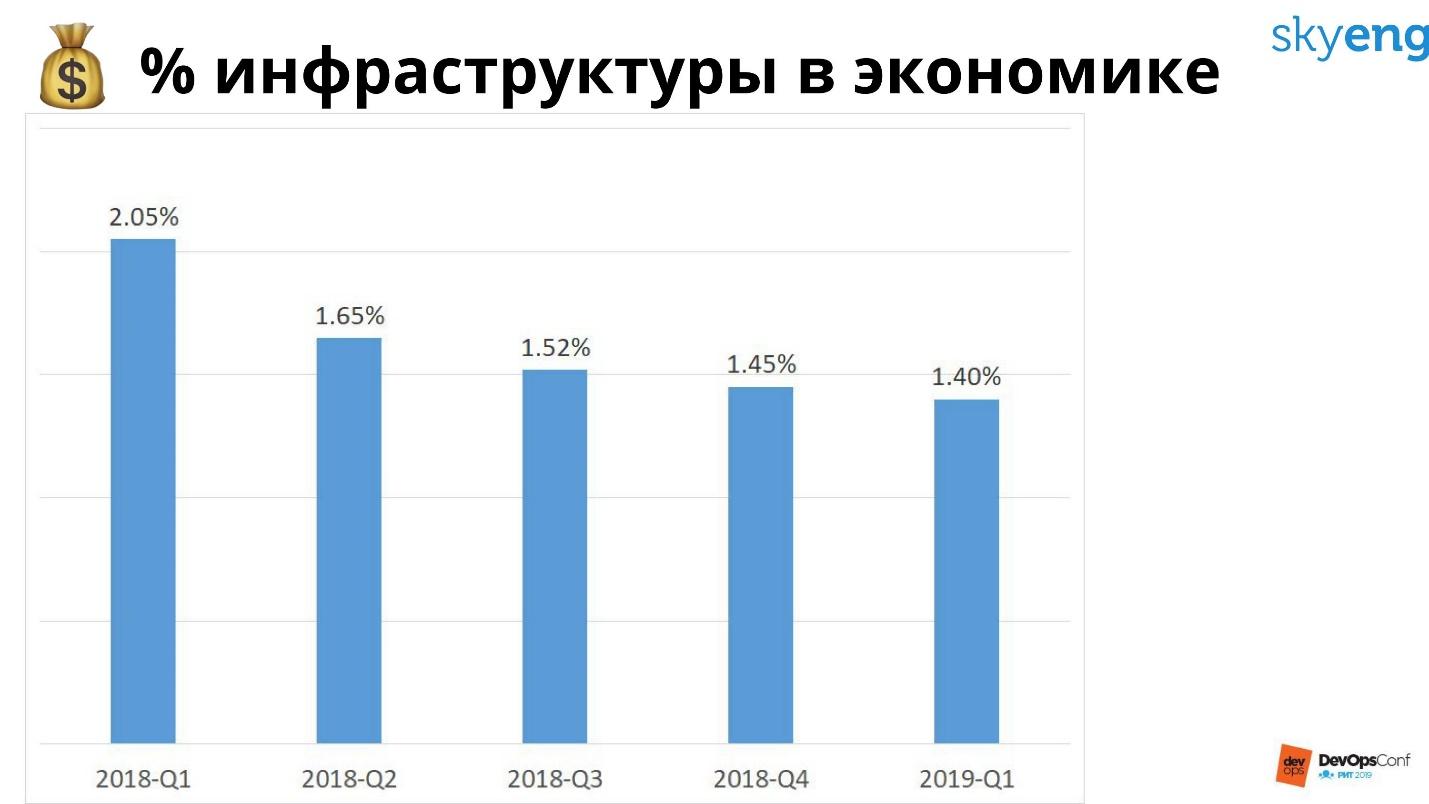
Процент инфраструктуры падает, мы работаем над этим. Это выгодно нам, бизнесу и клиентам. Можно взять дешевые серверы, не делать бэкапы и еще сильнее уронить этот график. Но это неправильно, нужно считать не просто расходы на инфраструктуру, а расходы на инфраструктуру и ожидаемые убытки от падений.
Для каждого сервиса считаем, сколько денег в час мы теряем от его падения. Мы ведем подробный лог того, когда и какой сервис лежал, и сколько мы на этом потеряли.
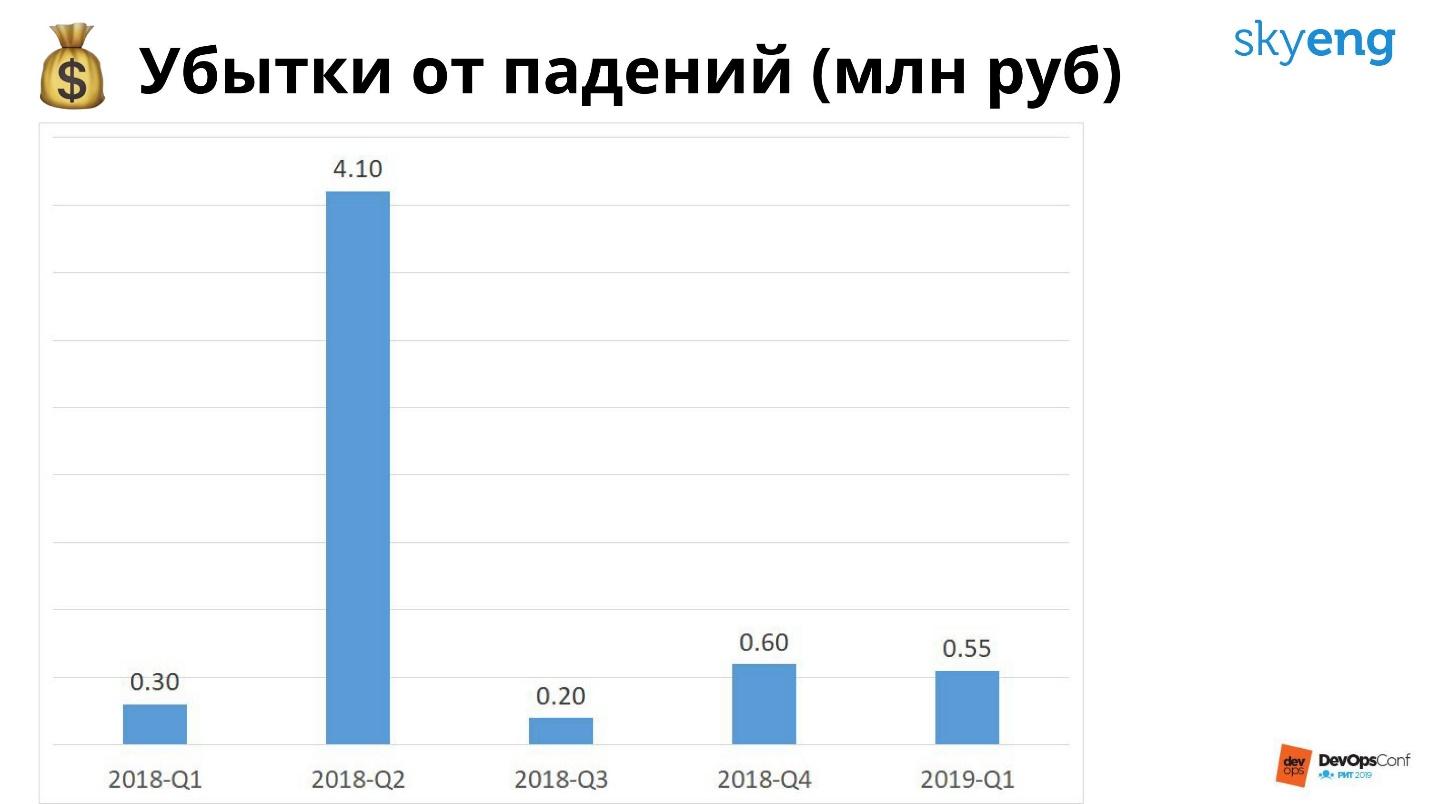
График убытков от падений за прошлый год.
Больше всего потерь во втором квартале 2018 года — привет Роскомнадзору! Расходов на инфраструктуру в прошлом году было 20 млн, расходов на падение — 5 млн. Если бы мы все зарезервировали, то это спасло бы нас от Роскомнадзора, но мы бы все равно были в минусе на 15 млн.
Бизнесу невыгодно дублировать все подряд. Надо думать, что дублировать, а что нет.
Мы дублируем те сервисы, для которых расходы на дополнительный сервер или БД ниже, чем ожидаемые риски от падений.
Делаем быстро
Мы измеряем процент задач, которые выполнены в день постановки. В инфраструктуру приходит много задач, которые требуется решить прямо здесь и сейчас. От этого зависят другие команды, которые не могут выполнять свою работу. Большие задачи, на которые требуются недели, считаются отдельно.

График задач в день постановки.
По графику вероятность выполнения задачи в день постановки примерно 80%. Мы видим этот график и считаем, что все круто. Но другие команды могут так не думать и оценивать иначе. Поэтому мы проводим опросы других команд.

Пример опроса.
Опросы проводим через обычную Google-форму с вопросами. Разработчики и другие наши заказчики регулярно на них отвечают.
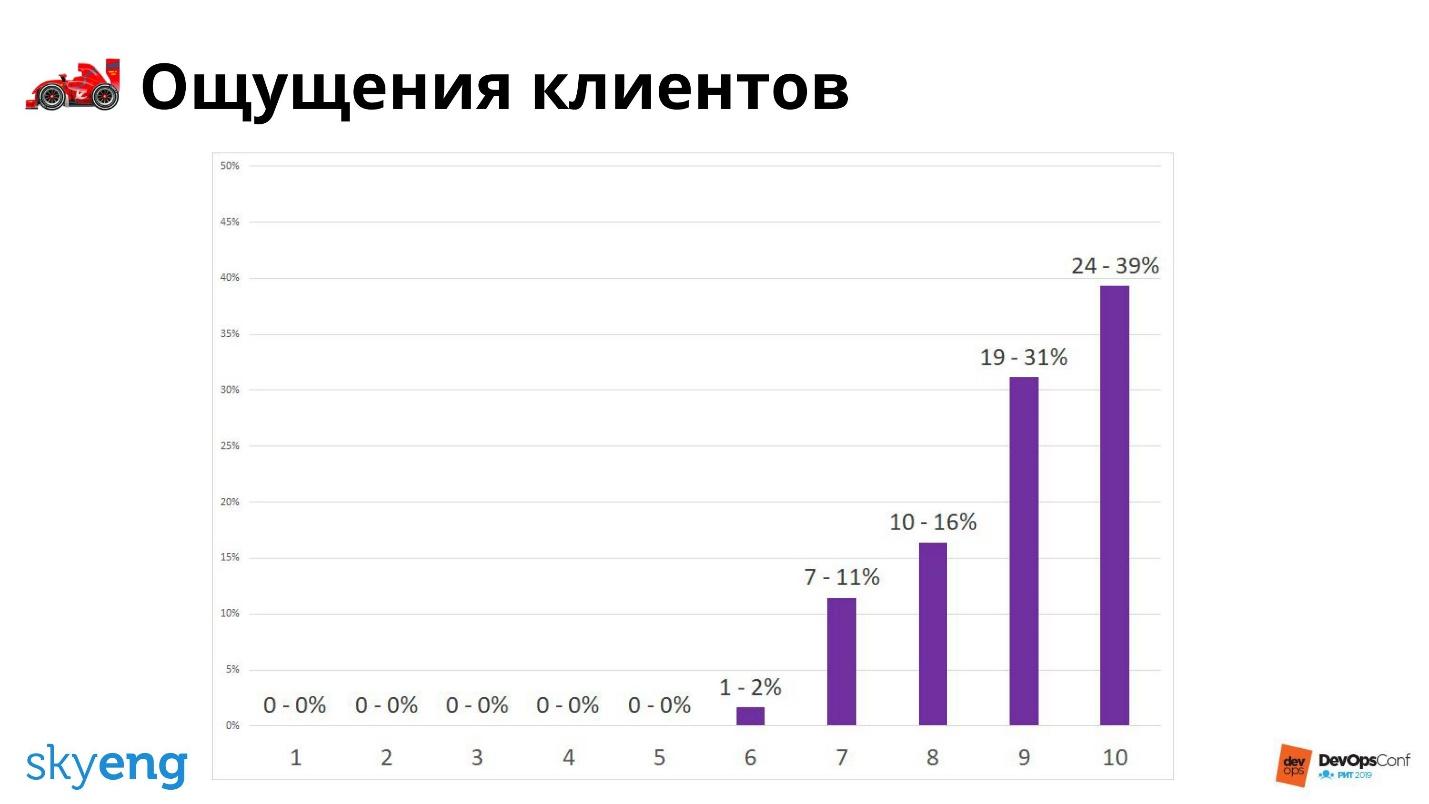
Результат опроса по скорости работы инфраструктуры.
Текущее состояние дел отлично описывается опросами, но не будущее. Для оценки вероятности положения дел в будущем мы измеряем количество задач, выполненных с помощью pull request. Это то, что принесет пользу через год или два.
Полгода назад мы решили, что пойдем в «инфраструктуру как код». Здесь мы измеряем все запросы в инфраструктуру: залить dump или кусочек логов, поправить точку nginx на проде или создать новый сервер. Это все запросы, и мы их все оцениваем по количеству pull requests. В будущем хотим, чтобы любой запрос решался с помощью pull request или, чтобы нам его просто не задавали.
Мы знаем, что подход «инфраструктура как код» дает три главных бонуса:
- снижение стоимости изменений;
- повышение скорости изменений;
- снижение рисков.
Нам нужны все три из трех, поэтому мы двигаемся в эту сторону и измеряем, насколько близко подошли.
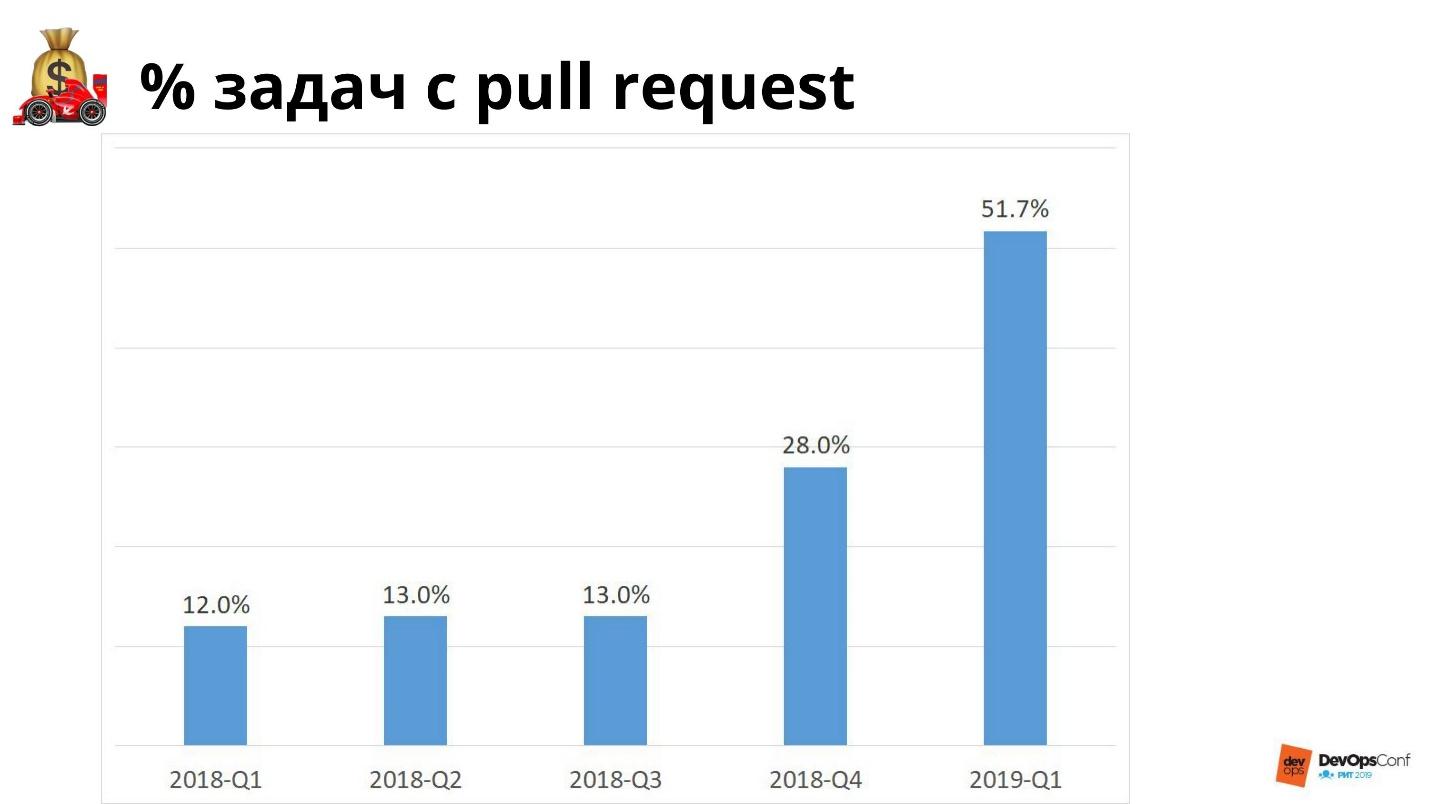
Для логов есть система визуализации, для выдачи доступов есть Terraform. Можно сделать систему, при которой все будет автоматизировано. В идеале этот график должен уйти в 100%. Когда любое обращение будет сделано с помощью кода, мы сможем его быстро выполнять и разворачивать в другой инфраструктуре так же быстро.
Разработчикам удобно
Это важно для Skyeng. Сейчас у нас 100 разработчиков, к концу года их будет 120. Важно, чтобы они работали эффективно. Мы хотим нанимать людей не просто так, нам нужны те, кто будет улучшать компанию.
Единственная и главная метрика для разработчиков — это результат опроса удовлетворенности командой инфраструктуры.
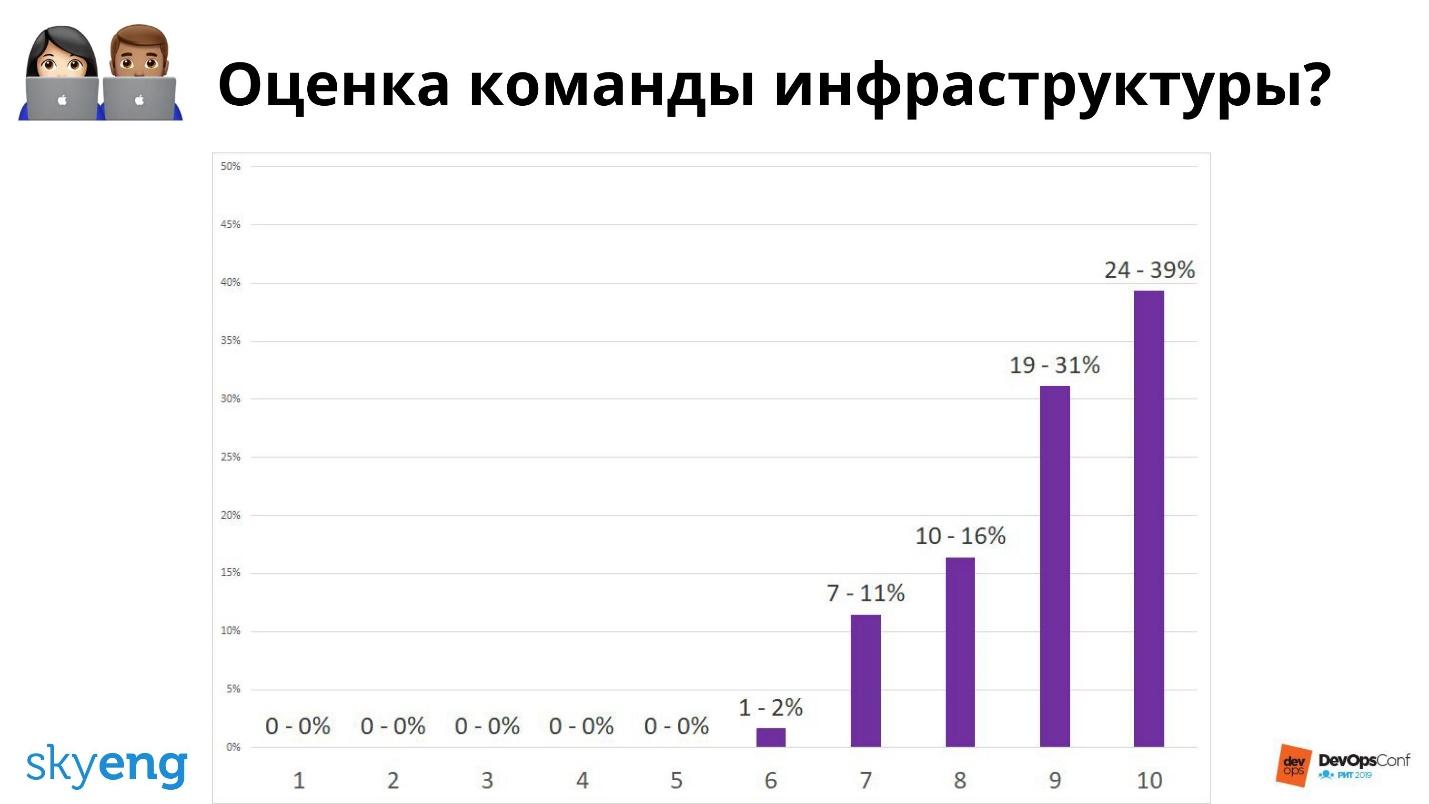
В целом все ОК.
Большинство оценивает нас хорошо. Но если спросить, насколько они довольны окружением разработки, то все не так приятно.
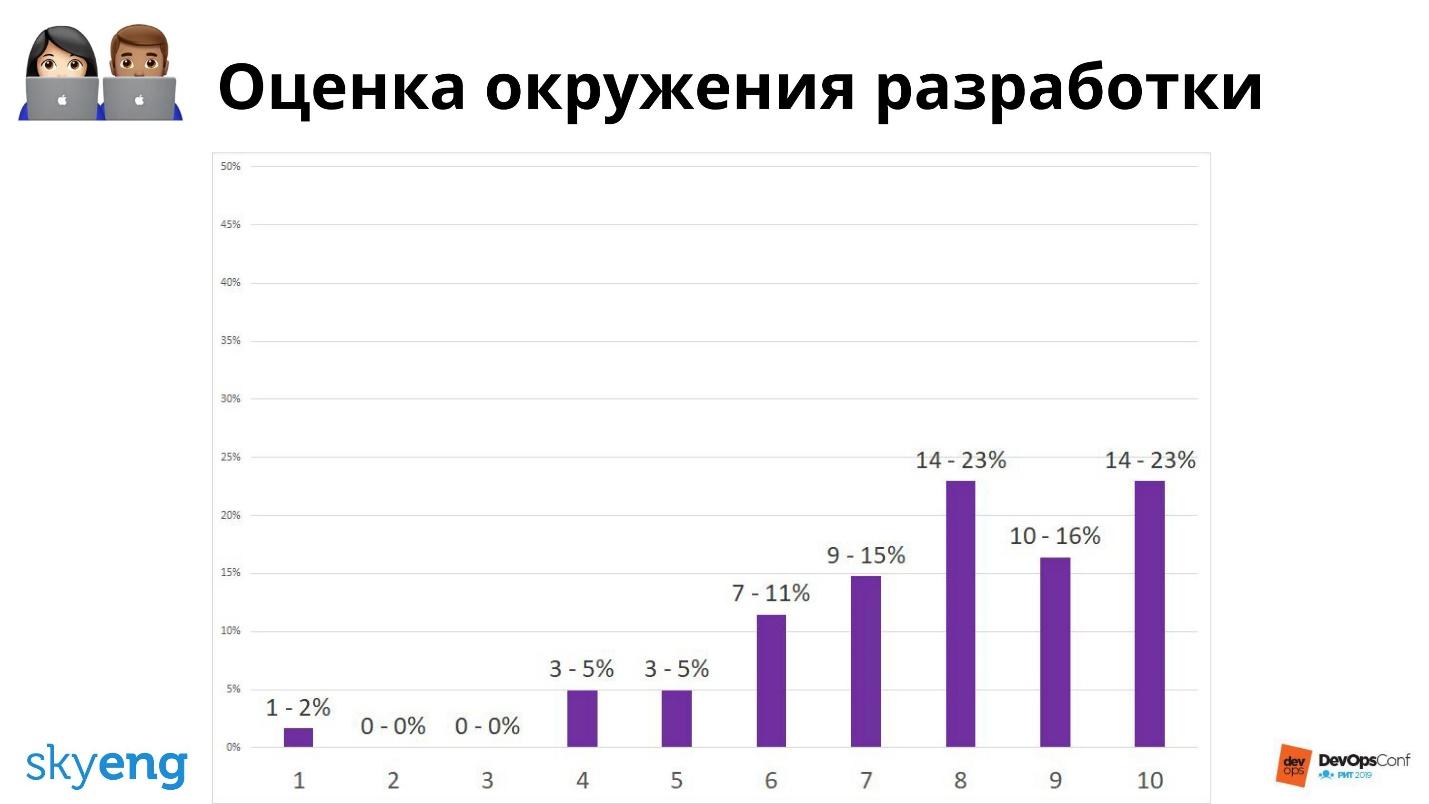
Окружение разработки — наша головная боль. Это точка роста, которую нужно улучшать. Поэтому мы лично опрашиваем сотрудников, которые ответили хуже всего: в чем проблема, что у него тормозило или не работало? Зная, что происходит, можно улучшить положение дел.
Пока вы не знаете, что происходит, вы не можете ничего изменить.
Долгосрочный результат
Любую из наших метрик можно увеличить, просто сконцентрировавшись на ней. Например, для увеличения процента задач, выполненных в тот же день, можно все бросить и решать только задачи, которые прилетели. Можно делать все задачи с помощью кода.
Например, в некотором городе «N» все силы тратят на развитие дорог. Они делают ровные, широкие, многополосные трассы в городе. Это круто первый, второй год. Но все остальные сферы деградируют: доступной среды нет, деревья вырубают, машин все больше, парковок не хватает, а экология уже уехала из города по этим дорогам. Через 5-10 лет в соседнем городе уже появятся автономные такси и гиперлупы, а здесь все еще просто ровные дороги. Понятно, что это путь в никуда.
Мы не должны такого допускать, нам нужно смотреть наперед. Поэтому мы измеряем количество времени, которое тратим на разработку и на поддержку.
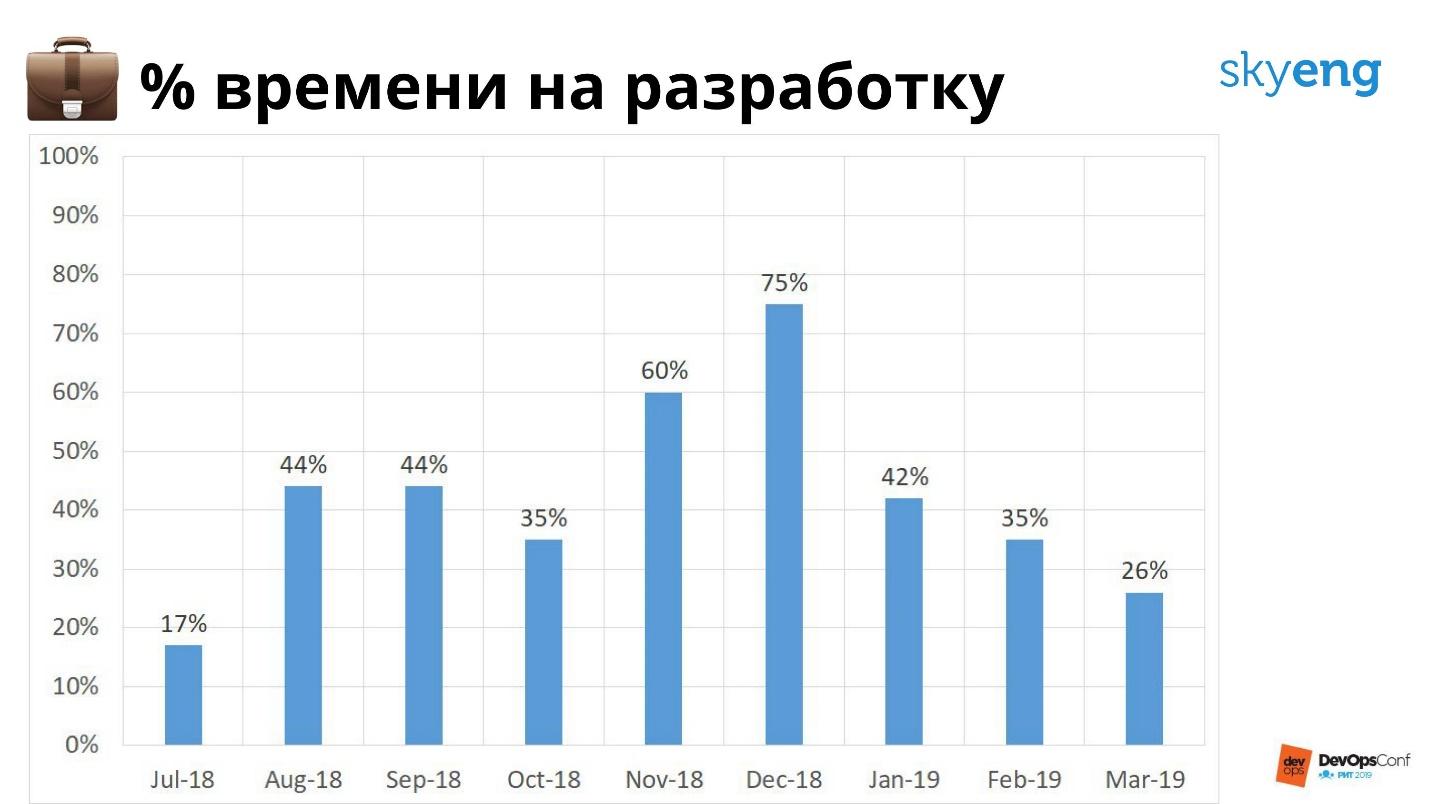
На графике видно, что последние месяцы мало времени уходит на разработку. Для меня, как для руководителя, это признак того, что нужны люди или автоматизация процессов. По графику я даже могу рассчитать, через сколько месяцев все ресурсы будут уходить на поддержку, когда мы не будем успевать и наступит коллапс.
Выгодные задачи
Мы поставили цель и подумали над метриками, но пока не приступим к реализации руками, ничего не изменится. Делать нужно не просто что-то, а самые выгодные задачи с точки зрения метрик и времени.
Со временем все упрощается.
Любые две задачи можно сравнить по времени: на первую уйдет неделя, на вторую — 3 часа. Это не зависит от того, из какого отдела поступила задача. С метриками сложнее — их много. Как просчитать, какую задачу делать выгоднее: первую или вторую, если одна оптимизирует одни метрики, а другая другие?
Для себя мы это решили просто — придумали универсальную единицу, которая описывает любые задачи. Наша универсальная единица — рубль. Мы оцениваем пользу от любой задачи по прибыли, которая она принесет и делим на время, которое потребуется на выполнение этой задачи. Так мы оцениваем каждую задачу с точки зрения метрик (рублей) и времени.

Наши квартальные задачи.
На скриншоте ниже в двух последних колонках записано сколько денег мы заработаем на задаче и сколько времени потратим на выполнение. Команда инфраструктуры зарабатывает деньги тем, что улучшает условия для разработчиков, оптимизирует процессы в компании и работу серверов. Мы переходим на Docker не потому, что это круто, а потому что мы посчитали, что это выгодно.

Дополнительные метрики, которые мы измеряем.
Опережающие:
- % поддержки;
- % задач с PR;
- % задач, закрытых за сутки.
Запаздывающие:
- % прибыли компании;
- убытки от падений;
- отзывы разработчиков.
Это лишь часть метрик, у нас их больше.
Задачи, которые мы не оцениваем
Мы не оцениваем баги. Если мы взяли какую-то систему на поддержку и поддерживаем ее, то фиксим баги просто потому, что их там быть не должно.
Это же относится к поддержке. Мы измеряем в целом, сколько времени уходит на поддержку, и не допускаем, чтобы его было слишком много. Мы оцениваем каждую систему в целом на предмет пользы или вреда от нее. Задачи, которые проще сделать или они очень срочные, мы не оцениваем. Все, о чем я говорил, к ним не относится — мы просто их делаем.
Почему полезно и важно оценивать задачи
Премии и достижения. С бизнесом всегда нужно говорить на языке денег. Он понимает только деньги. Если вы скажете, что у вас есть проект, вы его запилите, он принесет 5 млн, и попросите премию миллион на команду — с вами согласятся. Для бизнеса это понятно.
Найм. Не предлагайте бизнесу нанимать сотрудников и внедрять новые технологии, а предлагайте вместе заработать деньги. Тогда он точно пойдет навстречу. Как минимум, обсуждение начнется не по пути «успеваешь ты или не успеваешь, нужен тебе человек или нет», а насколько крутой проект, для которого нужен человек, справится ли он, и реально ли проект принесет столько миллионов. Разговор пойдет в другом русле, и вы сами заранее поймете, достоин ли этот проект затрат или проще выбросить и искать другой?
Оптимизация затрат. Если мы понимаем, на что уходят деньги, мы легко их можем считать и оптимизировать расходы.
Административные решения. Этот пункт я осознал недавно. Инфраструктура начала разрастаться и я решил разбить команду на подкоманды. Встал вопрос о том, как именно это сделать, с целью дальнейшего наращивания персонала. Решение появилось исходя именно из метрик — поделил все метрики нашей инфраструктуры на блоки, и каждая команда отвечает за свои метрики. У меня получилось 3 подкоманды. По каждой понятна общая зона ответственности и все участники в ней понимают, за что отвечают лично. Это понятная зона ответственности.
Чтобы все было круто
- Ставьте цель — без нее никуда.
- Разбейте цель на метрики и измеряйте.
- Оценивайте задачи и выполняйте самые крутые.
Тогда вас обязательно ждет успех!
На DevOps Conf 2019 об «инфраструктуре как код» мы поговорим отдельно. Будущее подхода, паттерны в Terraform, развертывание и управление BareMetal-инфраструктуры и Kubernetes — четыре доклада по теме. Конференция, сближающая процесс и технологии, пройдет в Москве 30 сентября и 1 октября. Расписание уже готово, можно изучить программу, тезисы докладов или забронировать билеты.
Подписывайтесь на рассылку и Telegram-канал и следите за новостями и новыми публикациями докладов.
