
Мы всегда хотим писать код быстро, но за это приходится платить. На обычных высокоуровневых гибких языках можно быстро разрабатывать программы, но после запуска они работают медленно. Например, чудовищно медленно cчитать что-то тяжелое на чистом Python. Си-подобные языки работают гораздо быстрее, но в них легче наделать ошибок, поиск которых сведет весь выигрыш в скорости на нет.
Обычно эта дилемма решается так: сначала пишут прототип на чем-то гибком, например, на Python или R, а потом переписывают на C/C++ или Fortran. Но этот цикл слишком длинный, можно ли обойтись без этого?

Возможно, решение есть. Julia — высокоуровневый и гибкий, но при этом быстрый язык программирования. В Julia есть множественная диспетчеризация, встроенный умный компилятор и инструменты метапрограммирования. Подробнее о том, что есть в Julia, расскажет Глеб Ивашкевич (phtRaveller) — основатель datarythmics, которая занимается разработкой систем машинного обучения для промышленности и других отраслей, в прошлом физик.
Глеб объяснит, зачем нужны новые языки и почему иногда Python не хватает. Расскажет, что в Julia интересного, о ее сильных и слабых сторонах, сравнит с другими языками, и покажет, какая у языка перспектива в машинном обучении и вычислениях вообще.
Дисклеймер. Здесь не будет разбора синтаксиса. Хабражители опытные разработчики, поэтому нет смысла показывать, как написать цикл, например.
У специалистов по машинному обучению и Data Science есть NumPy, Sklearn, TensorFlow. Они годами решают свои задачи без единой строчки на C, и кажется, что проблема двух языков их не касается. Это не так, проблема проявляется неявно, потому что код на NumPy или на TensorFlow — это вообще-то не совсем Python. Он используется как метаязык, чтобы запустить то, что находится внутри. Внутри находится именно C/Fortran (в случае NumPy) или C++ (в случае TensorFlow).
Эта «особенность» слабо заметна, например, в PyTorch, но в Numpy хорошо видна. Например, если в расчётах возник классический питоновский цикл
При этом многим кажется, что NumPy быстрый и всё с ним отлично. Давайте посмотрим, что у NumPy под капотом, чтобы в этом убедиться.
Получается, что Numpy не такой быстрый, как кажется. Именно поэтому существуют проекты типа Cython или Numba. Первый генерирует C-код из «гибрида» Python и C, а второй компилирует код на Python и обычно это оказывается быстрее.
Простой пример: добавляем тип (good) или не добавляем (bad), и получаем два совершенно разных кода, хотя кроме типов исходные варианты ничем не отличаются.

Когда мы сгенерируем C-код, то в первом случае получим следующее:
А во втором
Когда тип указан, C-код работает молниеносно. Если тип не указан, мы видим обычный Python, но со стороны C: стандартные питоновские вызовы, где зачем-то создаются
Забавно, что когда мы что-то считаем, мы пытаемся убрать чистый Python. Есть два варианта, как это можно сделать.
Но, возможно, есть путь лучше, и я считаю, что это Julia.
Создатели утверждают, что это быстрый, высокоуровневый и гибкий язык, который по простоте написания кода сравним с Python. По моим ощущениям, Julia похожа на скриптовый язык: не нужно делать то, что приходится делать в C, где всё очень низкоуровневое, в том числе структуры данных. При этом работать можно в обычной консоли, как с Python и другими языками.
В Julia используется Just-In-Time компиляция — это один из элементов, который дает скорость. Но и с вычислениями у языка все хорошо, потому что для них он и разрабатывался. Julia используют для научных задач и получают достойную производительность.
В этом коде заметны четыре особенности.
У Julia есть три особенности, которые дают гибкость и скорость: множественная диспетчеризация, метапрограммирование и параллельность. Мы поговорим о первых двух, а параллелизацию оставим на самостоятельное изучение для продвинутых пользователей.
Вызов
Варианты одной и той же функции для разных наборов типов называются методами. В коде их два: первый для всех чисел с плавающей точкой, а второй для всего остального. Когда мы впервые вызовем функцию, Julia решит, какой метод использовать, и нужно ли его компилировать. Если его уже раньше вызывали и он скомпилирован, возьмет тот, который есть.
Поскольку в Julia все не так, как мы привыкли, тут можно добавлять в пользовательские типы функции, но это не будут методы типа в смысле ООП. Это просто будет поле, в котором прописана функция, потому что функция — это такой же полноправный объект, как и все остальное.
Чтобы узнать, что именно будет вызвано, есть специальные макросы. Они начинаются с

В первом случае Julia решила, что поскольку 2 целое число, то под
Для компиляции Julia использует инфраструктуру LLVM. Библиотека JIT-компиляции идет в пакете с языком. При первом вызове функции Julia смотрит, использовалась ли функция с данным набором типов, и компилирует её, если требуется. Первый запуск займет какое-то время, а потом все будет работать быстро.
Для иллюстрации работы компилятора приведу пример простой функции:
Макрос
В коде аргумент функции умножается на 3, к результату прибавляется 1, возвращается результат. Все прямолинейно настолько, насколько возможно. Если определить функцию чуть иначе, например, 3 заменить на 2, то все изменится.
Казалось бы, какая разница: 2, 3, 10? Но Julia и LLVM видят, что при вызове функции для целого числа можно сделать немного умнее. Умножение на двойку целого числа это сдвиг влево на один бит — это быстрее, чем произведение. Но, конечно, это работает только для целых чисел, не получится сдвинуть
Пользовательские типы в Julia такие же быстрые, как и встроенные. По ним проводится множественная диспетчеризация, и это будет также быстро, как и для встроенных типов. В этом смысле механизм множественной диспетчеризации глубоко встроен в язык.
Логично ожидать, что у переменных нет типов, они есть только у значений. Сами переменные без типа — это просто маркер, лейбл на каком-то контейнере.
Система типов иерархическая. Мы не можем создавать потомков конкретных типов, они могут быть только у абстрактных типов. При этом нельзя инстанцировать абстрактные типы. Этот нюанс понравится не всем.
Как объяснили авторы языка, когда они разрабатывали Julia, то хотели получить результат, и если что-то было сделать сложно, от этого отказывались. Такую иерархическую систему типов было разработать проще. Нельзя сказать, что это катастрофическая проблема, но если в первое время не вывернуть себе голову наизнанку, то будет неудобно.
Типы могут быть параметризированы, что немного похоже на C/C++. Например, у нас может быть структура, внутри которой есть поля, но типы этих полей не указаны — это параметры. Конкретный тип мы указываем при инстанцировании.
В большинстве случаев типы можно пропустить. Обычно они нужны, когда тип поможет компилятору угадать, как лучше скомпилировать. В этом случае типы лучше указать. Также указывать типы нужно, если хотите добиться лучшей производительности.
Посмотрим, что можно, а что нельзя инстанцировать.

Первый тип
Первый тип нельзя инстанцировать, а для всех остальных невозможно создать потомков. Кроме того, по умолчанию они иммутабельные. Чтобы появилась возможность менять поля, это нужно указать явно.
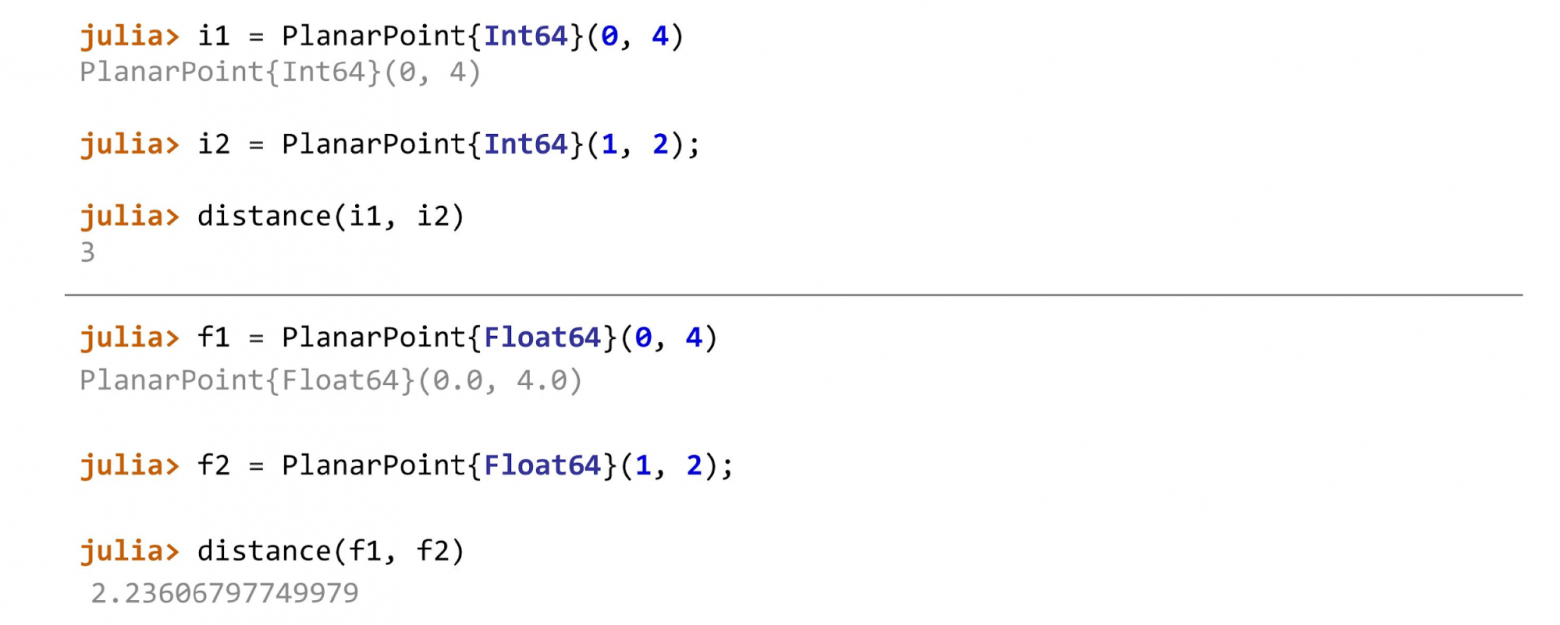
Когда все готово, можно продолжать, например, посчитать расстояние для разных типов точек. В примере первая точка на плоскости —
Для
А для целых чисел метод вычисления расстояния будет выглядеть так:
Для точек каждого типа, будут вызываться разные методы.
Если схитрить и, например, применить
Возможно, вы уже обрадовались: «Есть JIT-компиляция: писать легко, работать будет быстро. Выкидываем Python и начинаем писать на Julia!».
Но не все так просто. Не любая функция в Julia будет быстрой. Это зависит от двух факторов.
Что такое стабильность типов? Когда компилятор не может достаточно надежно угадать, что происходит с типами, ему приходится генерировать много оберточного кода, чтобы работало всё, что попадает на вход.
Простой пример, чтобы понять стабильность типов.

Специалисты по машинному обучению скажут, что это обычная relu-активация: если x > 0, возвращаем как есть, иначе возвращаем ноль. Одна проблема — ноль после знака вопроса целочисленный. Это значит, что если мы вызываем эту функцию для числа с плавающей точкой, то в одном случае вернется число с плавающей точкой, а в другом — целое число.
Компилятор не может угадать тип результата только по типу аргумента функции. Ему нужно знать еще и значение. Поэтому он генерирует много кода.
Дальше создаем массив 100 на 100 случайных чисел от 0 до 1, сдвигаем его на 0,5 для равномерного распределения положительных и отрицательных чисел, и измеряем результат. Здесь два интересных момента: точка и функция. Точка после
В точке проблем нет — проблема внутри самой функции. Расчетное время исполнения такого варианта на приличном компьютере для такой матрицы это микросекунды. Но в реальности — миллисекунды, что слишком много для такой крошечной матрицы.
Поменяем всего одну строку.

Функция
Когда компилятор может оптимизировать код, разница во времени исполнения получается на два порядка. Во втором примере аллоцировалось только ровно на новый массив, еще пара десятков байт и больше ничего. Этот вариант гораздо эффективней, чем предыдущий.
Это основное, за чем нужно следить, когда мы пишем код на Julia. Если же писать как на Python, то и работать будет, как на Python. Если эти же операции делать на NumPy, то ноль с точкой или без точки не играет роли. Но в Julia это может сильно подорвать производительность.
К счастью, существует метод, позволяющий узнать о наличии проблемы. Это макрос

В первом варианте (слева) компилятор не уверен в типе и выводит его красным. Во втором случае всегда будет
Это еще не LLVM, а размеченный код Julia,
Многие знают дисклеймер от Тима Петерса, автора книги Zen of Python: «Метаклассы — это более глубокая магия, о которой 99% пользователей никогда не должны беспокоиться. Если вы задаетесь вопросом, нужны ли метаклассы в Python, они вам не нужны. Если они вам нужны, то вы точно знаете, зачем именно и как ими пользоваться».
С метапрограммированием ситуация похожа, но в Julia оно вшито гораздо глубже, это важная особенность всего языка. Код на Julia — такая же структура данных, как и любая другая, ей можно манипулировать, комбинировать, создавать выражения, и все это будет работать.
Макросы — это один из инструментов метапрограммирования в Julia: мы им что-то передаем, они смотрят, добавляют нужное, убирают ненужное, и выдают результат. Во всех предыдущих примерах мы передавали вызов функции, а макрос внутри разбирал вызов. Всё это происходит на уровне работы с синтаксическим деревом.
Совсем простые выражения можно разобрать: если это, например,
Еще простой пример макроса:
С помощью макросов создаются, например, индикаторы выполнения или фильтры для датафреймов — это распространенный механизм в Julia.
Julia — это гибкий и быстрый язык. Но это не все его свойства.
Экосистема есть, но она немного хаотичная, потому что Julia относительно молодой язык. В языке есть функциональность, которая нужна для машинного обучения, data science и численного моделирования, но упакована она иначе, не так, как мы привыкли в Python. Например, в Python есть Pandas, и в нем есть абсолютно все, что связано с датафреймами, вплоть до отрисовки картинок, а в Julia аналогичная функциональность распределена между несколькими пакетами.
Экосистема Julia активно развивается, и находится примерно на этапе развития Python 2008 года. Как раз тогда я начал писать на Python, и мне было ненамного удобнее с численными задачами, чем сейчас на Julia. Но это нормальный этап, нужно перетерпеть неудобства молодого языка. Если вам все равно, можете уже пользоваться Julia.
Линейная алгебра. Есть в самой Julia: можно создавать, обращать, перемножать матрицы и т.д…
Датафреймы. Есть несколько библиотек.
Plotting. Если вы привыкли к Matplotlib, то можете с ним работать через интерфейс в Julia. Но есть и свои интерфейсы: к VegaLite.jl, есть универсальный Plots.jl, с выбором бэкенда для отрисовки, есть Gadfly.jl.
Глубокое обучение. Есть интерфейс к TensorFlow, и интересный и компактный Flux.jl. Но пока во Flux нет некоторых продвинутых инструментов, например, адаптивных оптимизаторов или удобных механизмов, как в Keras и TensorFlow, для подгрузки данных. Но сделать это самостоятельно не сложно.
Scikit-learn. Аналог библиотеки есть, он работает, можно использовать модели из sklearn, но пакет иначе структурирован, немного хаотично.
XGBoost. Можно использовать, в Julia есть хороший интерфейс.
Можно продолжать работать в Jupyter. IDE — или Juno, или плагин к Visual Studio, но его я не пробовал и не могу оценить.
Железо. С GPU/TPU все хорошо. Пакет CUDAnative.jl позволяет в самой Julia писать ядра для графического процессора. Пишем практически чистый Julia-код, если нужно добавить какой-нибудь хитрый слой в нейронную сеть, причем чтобы все считалось сразу на графическом процессоре. Дальше не наша забота, как это будет скомпилировано и запущено, всё будет работать уже без нас, причем, неплохо.
Совместимость языков: можно вызывать C, Fortran, Python и другие языки.
Совместимость форматов в целом работает, но бывают и исключения.
Packaging: пакетный менеджер расположен в консоли Julia: в специальном режиме можно устанавливать пакеты, удалять, обновлять и т.д.
Сейчас архитектуры нейронных сетей настолько усложнились, что иногда бывает недостаточно ни статического, ни динамических графов. Есть модели, особенно в языке, которые меняются на ходу. Динамический граф лучше, отчасти поэтому PyTorch долгое время был удобнее для исследовательских задач, чем TensorFlow, где был только статический граф, который вы написали и больше не можете изменять.
Хорошо было бы иметь нечто такое, в чем можно посчитать градиенты от произвольного кода, например, кода с циклами или условными переходами. Все это можно сделать в Julia, благодаря ее особенностям, например, компиляции на ходу или множественной диспетчеризации. Один из пакетов, который делает автоматическое дифференцирование, называется Zygote.jl. Это экспериментальный пакет к Flux.jl.
Можно написать в функции
Причем Zygote генерирует градиенты «source-to-source»: из нашего представления функции он генерирует функцию для градиента, которая точно также компилируется, а потом вызывается. Это называется differentiable programming — дифференцируемое программирование — для любой функции можно условно сделать backpropagation и использовать в любом алгоритме, который тренируется градиентным спуском.
В этом направлении у Julia есть преимущества благодаря ее особенностям: «source-to-source» можно реализовать на уровне компилятора и вшить в язык так, чтобы всегда можно было посчитать градиенты. Любая, самая безумная архитектура становится возможна.
Если вы берете готовые модели, накладываете сверху свою классификацию и отправляете в продакшн — не берите. При таком сценарии использования вы не получите преимуществ.
Если занимаетесь чем-то сложнее, например, архитектурами, для которых нет готовых предтренированных моделей — попробуйте.
Если занимаетесь численным моделированием, то попробуйте обязательно, вам понравится.
Чтобы начать пользоваться Julia, учтите два нюанса.
Обычно эта дилемма решается так: сначала пишут прототип на чем-то гибком, например, на Python или R, а потом переписывают на C/C++ или Fortran. Но этот цикл слишком длинный, можно ли обойтись без этого?

Возможно, решение есть. Julia — высокоуровневый и гибкий, но при этом быстрый язык программирования. В Julia есть множественная диспетчеризация, встроенный умный компилятор и инструменты метапрограммирования. Подробнее о том, что есть в Julia, расскажет Глеб Ивашкевич (phtRaveller) — основатель datarythmics, которая занимается разработкой систем машинного обучения для промышленности и других отраслей, в прошлом физик.
Глеб объяснит, зачем нужны новые языки и почему иногда Python не хватает. Расскажет, что в Julia интересного, о ее сильных и слабых сторонах, сравнит с другими языками, и покажет, какая у языка перспектива в машинном обучении и вычислениях вообще.
Дисклеймер. Здесь не будет разбора синтаксиса. Хабражители опытные разработчики, поэтому нет смысла показывать, как написать цикл, например.
Проблема двух языков
Если писать код быстро, программы работают медленно. Если программы работают быстро, писать их долго.Классический Python относится к первой категории. Если убрать NumPy, считать что-то на чистом Python медленно. С другой стороны стоят языки вроде C и C++. Найти баланс трудно, поэтому чаще всего сначала пишут прототип на чем-то гибком, а после отладки алгоритма переписывают на язык побыстрее. Это пример явной проблемы двух языков: длинный цикл, когда приходится писать на Python, а переписывать на С или на Cython, например.
У специалистов по машинному обучению и Data Science есть NumPy, Sklearn, TensorFlow. Они годами решают свои задачи без единой строчки на C, и кажется, что проблема двух языков их не касается. Это не так, проблема проявляется неявно, потому что код на NumPy или на TensorFlow — это вообще-то не совсем Python. Он используется как метаязык, чтобы запустить то, что находится внутри. Внутри находится именно C/Fortran (в случае NumPy) или C++ (в случае TensorFlow).
Эта «особенность» слабо заметна, например, в PyTorch, но в Numpy хорошо видна. Например, если в расчётах возник классический питоновский цикл
for, значит, что-то пошло не так. В производительном коде циклы не нужны, придется переписать все так, чтобы NumPy мог это векторизовать и быстро вычислить.При этом многим кажется, что NumPy быстрый и всё с ним отлично. Давайте посмотрим, что у NumPy под капотом, чтобы в этом убедиться.
- NumPy пытается исправить проблему гибкости типов Python, поэтому в нём довольно строгая система типов. Если массив имеет определенный тип, то ничего другого в нём быть не может, если там лежит
Float64, ничего с этим не сделать. - Диспетчеризация. В зависимости от типов массивов и того, какую операцию нужно выполнить, NumPy внутри сам решит, какую функцию вызвать, чтобы вычисления были максимально быстрыми. Библиотека попытается выбросить классический Python из петли вычислений.
Получается, что Numpy не такой быстрый, как кажется. Именно поэтому существуют проекты типа Cython или Numba. Первый генерирует C-код из «гибрида» Python и C, а второй компилирует код на Python и обычно это оказывается быстрее.
Если бы NumPy действительно был таким быстрым, как многим кажется, то существование Cython и Numba не имело бы смысла.Мы переписываем все на Cython, если хотим побыстрее посчитать что-то большое и сложное. Один из критериев качества обертки на Cython — это наличие или отсутствие чистых Python-вызовов в сгенерированном коде.
Простой пример: добавляем тип (good) или не добавляем (bad), и получаем два совершенно разных кода, хотя кроме типов исходные варианты ничем не отличаются.

Когда мы сгенерируем C-код, то в первом случае получим следующее:
__pyx_t_4 = __pyx_v_i;
__pyx_v_result = (__pyx_v_result + (*((double *) ( /* dim=0 */ (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));А во втором
result =0. превратится в это:__pyx_t_6 = PyFloat_FromDouble((*((double *) ( /* dim=0 */ (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_6);
__pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_7);
__Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
__Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7);
__pyx_t_7 = 0;Когда тип указан, C-код работает молниеносно. Если тип не указан, мы видим обычный Python, но со стороны C: стандартные питоновские вызовы, где зачем-то создаются
float из double, считаются ссылки, и много другого мусорного кода. Этот код работает медленно, потому что вызывает Python для каждой операции.Можно ли решить все проблемы сразу
Забавно, что когда мы что-то считаем, мы пытаемся убрать чистый Python. Есть два варианта, как это можно сделать.
- Используя Cython или другие инструменты. Можно оптимизировать код на Cython множеством способов, чтобы в итоге получить код практически без Python-вызовов. Но это не самая приятная деятельность: в Cython не все настолько очевидно, а времени тратится лишь немного меньше, чем если все писать просто на C. Полученный модуль можно использовать в Python, но все равно это долго, возникают ошибки, код не всегда очевидный и не всегда понятно, как его оптимизировать.
- С помощью Numba, которая делает JIT-компиляцию.
Но, возможно, есть путь лучше, и я считаю, что это Julia.
Julia
Создатели утверждают, что это быстрый, высокоуровневый и гибкий язык, который по простоте написания кода сравним с Python. По моим ощущениям, Julia похожа на скриптовый язык: не нужно делать то, что приходится делать в C, где всё очень низкоуровневое, в том числе структуры данных. При этом работать можно в обычной консоли, как с Python и другими языками.
В Julia используется Just-In-Time компиляция — это один из элементов, который дает скорость. Но и с вычислениями у языка все хорошо, потому что для них он и разрабатывался. Julia используют для научных задач и получают достойную производительность.
Хотя Julia и пытается казаться языком общего назначения, но для вычислений Julia подходит хорошо, а для веб-сервисов — не очень. Применять Julia вместо Django, например, — не лучший выбор.Посмотрим на особенности языка на примере примитивной функции.
function f(x)
α = 1 + 2x
end
julia> methods(f)
# 1 method for generic function "f":
[1] f(x) in Main at mpconf.jl:2В этом коде заметны четыре особенности.
- Практически нет ограничений на использование Unicode. Можно взять формулы из статьи по глубокому обучению или численному моделированию, переписать с теми же символами, и все будет работать — Unicode вшит практически везде.
- Нет знака умножения. Однако, не всегда возможно обойтись без него, например, на 2.x (число с плавающей точкой умножить на x) Julia будет ругаться.
- Нет
return. Вообще, рекомендуется писатьreturn, чтобы было видно, что происходит, но в примере вернетсяα, потому что присваивание это выражение. - Нет типов. Казалось бы, если есть скорость, то в какой-то момент должны появиться типы? Да, они появятся, но позже.
У Julia есть три особенности, которые дают гибкость и скорость: множественная диспетчеризация, метапрограммирование и параллельность. Мы поговорим о первых двух, а параллелизацию оставим на самостоятельное изучение для продвинутых пользователей.
Множественная диспетчеризация
Вызов
methods(f) в примере выше выглядит неожиданно — что за методы у функции? Мы привыкли, что у нас есть объекты классов, у классов есть методы. Но в Julia все вывернуто наизнанку: методы есть у функций, потому что в языке используется множественная диспетчеризация.Множественная диспетчеризация означает, что вариант определенной функции, который будет исполнен, определяется всем набором типов параметров этой функции.Кратко опишу, как это работает на уже знакомом примере.
function f(x)
α = 1 + 2x
end
function f(x::AbstractFloat)
α = 1 + sin(x)
end
julia> methods(f)
# 2 methods for generic function "f":
[1] f(x::AbstractFloat) in Main at mpconf.jl:6
[2] f(x) in Main at mpconf.jl:2Варианты одной и той же функции для разных наборов типов называются методами. В коде их два: первый для всех чисел с плавающей точкой, а второй для всего остального. Когда мы впервые вызовем функцию, Julia решит, какой метод использовать, и нужно ли его компилировать. Если его уже раньше вызывали и он скомпилирован, возьмет тот, который есть.
Поскольку в Julia все не так, как мы привыкли, тут можно добавлять в пользовательские типы функции, но это не будут методы типа в смысле ООП. Это просто будет поле, в котором прописана функция, потому что функция — это такой же полноправный объект, как и все остальное.
Чтобы узнать, что именно будет вызвано, есть специальные макросы. Они начинаются с
@. В примере макрос @which позволяет узнать, какой метод вызывался для конкретного случая.
В первом случае Julia решила, что поскольку 2 целое число, то под
AbstractFloat не подходит, и вызвала первый вариант. Во втором случае она решила, что это все-таки Float и вызвала уже специализированный вариант. Приблизительно так это будет работать, если добавить и другие методы для каких-то специфических типов.LLVM и JIT
Для компиляции Julia использует инфраструктуру LLVM. Библиотека JIT-компиляции идет в пакете с языком. При первом вызове функции Julia смотрит, использовалась ли функция с данным набором типов, и компилирует её, если требуется. Первый запуск займет какое-то время, а потом все будет работать быстро.
Функция будет скомпилирована в момент первого вызова для данного набора параметров.Особенности компилятора.
- Компилятор достаточно разумный, потому что LLVM — это хороший продукт.
- Совсем продвинутые разработчики могут заглянуть в процесс компиляции и посмотреть, что он генерирует.
- Компиляция Julia и Numba похожи. В Numba вы тоже создаете декоратор JIT, но в Numba нельзя настолько «влезть» внутрь и решать, что оптимизировать или менять.
Для иллюстрации работы компилятора приведу пример простой функции:
function f(x)
α = 1 + 3x
end
julia> @code_llvm f(2)
define i64 @julia_f_35897(i64) {
top:
%1 = mul i64 %0, 3
%2 = add i64 %1, 1
ret i64 %2
}
Макрос
@code_llvm позволяет посмотреть результат генерации. Это LLVM IR — промежуточное представление, что-то вроде ассемблера.В коде аргумент функции умножается на 3, к результату прибавляется 1, возвращается результат. Все прямолинейно настолько, насколько возможно. Если определить функцию чуть иначе, например, 3 заменить на 2, то все изменится.
function f(x)
α = 1 + 2x
end
julia> @code_llvm f(2)
define i64 @julia_f_35894(i64) {
top:
%1 = shl i64 %0, 1
%2 = or i64 %1, 1
ret i64 %2
}Казалось бы, какая разница: 2, 3, 10? Но Julia и LLVM видят, что при вызове функции для целого числа можно сделать немного умнее. Умножение на двойку целого числа это сдвиг влево на один бит — это быстрее, чем произведение. Но, конечно, это работает только для целых чисел, не получится сдвинуть
Float влево на 1 бит и получить результат умножения на 2.Пользовательские типы
Пользовательские типы в Julia такие же быстрые, как и встроенные. По ним проводится множественная диспетчеризация, и это будет также быстро, как и для встроенных типов. В этом смысле механизм множественной диспетчеризации глубоко встроен в язык.
Логично ожидать, что у переменных нет типов, они есть только у значений. Сами переменные без типа — это просто маркер, лейбл на каком-то контейнере.
Система типов иерархическая. Мы не можем создавать потомков конкретных типов, они могут быть только у абстрактных типов. При этом нельзя инстанцировать абстрактные типы. Этот нюанс понравится не всем.
Как объяснили авторы языка, когда они разрабатывали Julia, то хотели получить результат, и если что-то было сделать сложно, от этого отказывались. Такую иерархическую систему типов было разработать проще. Нельзя сказать, что это катастрофическая проблема, но если в первое время не вывернуть себе голову наизнанку, то будет неудобно.
Типы могут быть параметризированы, что немного похоже на C/C++. Например, у нас может быть структура, внутри которой есть поля, но типы этих полей не указаны — это параметры. Конкретный тип мы указываем при инстанцировании.
В большинстве случаев типы можно пропустить. Обычно они нужны, когда тип поможет компилятору угадать, как лучше скомпилировать. В этом случае типы лучше указать. Также указывать типы нужно, если хотите добиться лучшей производительности.
Посмотрим, что можно, а что нельзя инстанцировать.

Первый тип
AbstractPoint инстанцировать нельзя. Это просто общий родитель для всех, который мы можем указать в методах, например. Вторая строка говорит о том, что PlanarPoint{T} — это потомок этой абстрактной точки. Ниже начинаются поля — здесь видна параметризация. Сюда можно поставить float, int или другой тип.Первый тип нельзя инстанцировать, а для всех остальных невозможно создать потомков. Кроме того, по умолчанию они иммутабельные. Чтобы появилась возможность менять поля, это нужно указать явно.
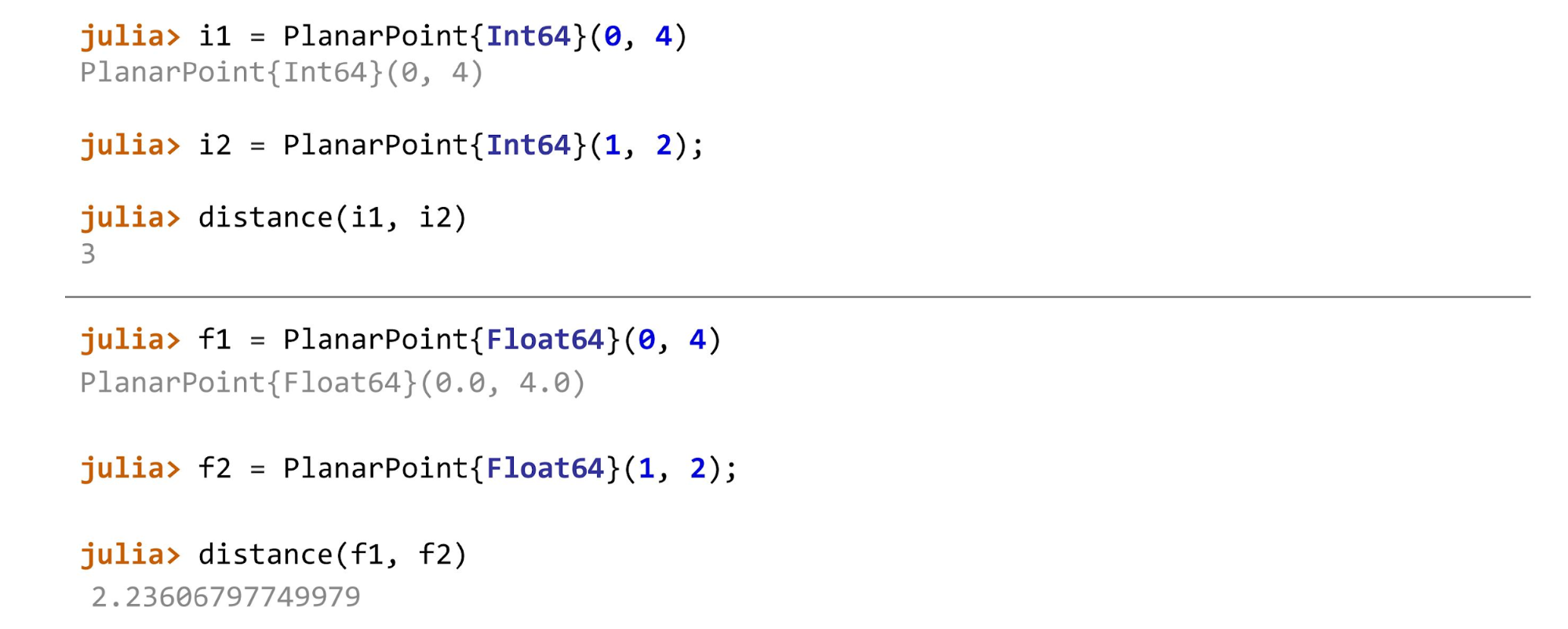
Когда все готово, можно продолжать, например, посчитать расстояние для разных типов точек. В примере первая точка на плоскости —
PlanarPoint, потом на сфере и на цилиндре. В зависимости от того, между какими двумя точками мы вычисляем расстояние, нужно использовать разные методы. В общем виде функция будет выглядеть так:function describe(p::AbstractPoint)
println("Point instance: $p")
endДля
Float64, Float32, Float16 это будет:function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat
sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2)
endА для целых чисел метод вычисления расстояния будет выглядеть так:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer
abs(pf.x-ps.x) + abs(pf.y-ps.y)
endДля точек каждого типа, будут вызываться разные методы.
Если схитрить и, например, применить
distance(f1, i2), Julia будет ругаться: «Я не знаю этот метод! Вы мне задали вот такие методы, и сказали, что они оба одного типа. Вы мне не рассказали, как это считать, когда один параметр float, а другой int».Скорость
Возможно, вы уже обрадовались: «Есть JIT-компиляция: писать легко, работать будет быстро. Выкидываем Python и начинаем писать на Julia!».
Но не все так просто. Не любая функция в Julia будет быстрой. Это зависит от двух факторов.
- От разработчика. Не существует языков, в которых любая функция будет быстрой. Неопытный разработчик даже на C напишет код, который будет работать гораздо медленнее, чем код на Python от опытного разработчика. В любом языке есть свои трюки и нюансы, от которых зависит производительность. Компилятор, будь то обычный статический или JIT, не может предусмотреть все мыслимые варианты и оптимизировать вообще всё.
- От стабильности типов. В более быстрый вариант будут скомпилированы функции стабильные по типам.
Стабильность типов
Что такое стабильность типов? Когда компилятор не может достаточно надежно угадать, что происходит с типами, ему приходится генерировать много оберточного кода, чтобы работало всё, что попадает на вход.
Простой пример, чтобы понять стабильность типов.

Специалисты по машинному обучению скажут, что это обычная relu-активация: если x > 0, возвращаем как есть, иначе возвращаем ноль. Одна проблема — ноль после знака вопроса целочисленный. Это значит, что если мы вызываем эту функцию для числа с плавающей точкой, то в одном случае вернется число с плавающей точкой, а в другом — целое число.
Компилятор не может угадать тип результата только по типу аргумента функции. Ему нужно знать еще и значение. Поэтому он генерирует много кода.
Дальше создаем массив 100 на 100 случайных чисел от 0 до 1, сдвигаем его на 0,5 для равномерного распределения положительных и отрицательных чисел, и измеряем результат. Здесь два интересных момента: точка и функция. Точка после
rand(100,100) означает «применить к каждому элементу». Если у вас есть какая-то коллекция и скалярная функция, вы ставите точку, и Julia все остальное выполнит сама. Можно считать, что это также эффективно, как нормальный цикл в нормальном компилируемом языке. Не нужно писать for — всё будет сделано за вас.В точке проблем нет — проблема внутри самой функции. Расчетное время исполнения такого варианта на приличном компьютере для такой матрицы это микросекунды. Но в реальности — миллисекунды, что слишком много для такой крошечной матрицы.
Поменяем всего одну строку.

Функция
zero(x) выполняет генерирует ноль того же типа, что и аргумент (x). Это означает, что независимо от того, какое значение у x, тип результата всегда будет известен по типу самого x.Когда мы смотрим только на тип аргументов и уже знаем тип результата — это функции стабильные по типам.Если нам нужно смотреть еще и на значение аргументов, это не стабильные функции.
Когда компилятор может оптимизировать код, разница во времени исполнения получается на два порядка. Во втором примере аллоцировалось только ровно на новый массив, еще пара десятков байт и больше ничего. Этот вариант гораздо эффективней, чем предыдущий.
Это основное, за чем нужно следить, когда мы пишем код на Julia. Если же писать как на Python, то и работать будет, как на Python. Если эти же операции делать на NumPy, то ноль с точкой или без точки не играет роли. Но в Julia это может сильно подорвать производительность.
К счастью, существует метод, позволяющий узнать о наличии проблемы. Это макрос
@code_warntype, который позволяет узнать, может ли компилятор угадать, где какие типы, и оптимизировать, если все нормально.
В первом варианте (слева) компилятор не уверен в типе и выводит его красным. Во втором случае всегда будет
Float64 для такого аргумента, поэтому можно сгенерировать код гораздо короче.Это еще не LLVM, а размеченный код Julia,
return 0 или return 0.0 дает разницу в производительности на два порядка.Метапрограммирование
Метапрограммирование — это когда мы в программе создаем программы и на ходу их запускаем.Это мощный метод, который позволяет сделать много разных интересных вещей. Классический пример — Django ORM, в котором создаются поля с помощью метаклассов.
Многие знают дисклеймер от Тима Петерса, автора книги Zen of Python: «Метаклассы — это более глубокая магия, о которой 99% пользователей никогда не должны беспокоиться. Если вы задаетесь вопросом, нужны ли метаклассы в Python, они вам не нужны. Если они вам нужны, то вы точно знаете, зачем именно и как ими пользоваться».
С метапрограммированием ситуация похожа, но в Julia оно вшито гораздо глубже, это важная особенность всего языка. Код на Julia — такая же структура данных, как и любая другая, ей можно манипулировать, комбинировать, создавать выражения, и все это будет работать.
julia> x = 4;
julia> typeof(:(x+1))
Expr
julia> expr = :(x+1)
:(x + 1)
julia> expr.head
:call
julia> expr.args
3-element Array{Any,1}:
:+
:x
1Макросы — это один из инструментов метапрограммирования в Julia: мы им что-то передаем, они смотрят, добавляют нужное, убирают ненужное, и выдают результат. Во всех предыдущих примерах мы передавали вызов функции, а макрос внутри разбирал вызов. Всё это происходит на уровне работы с синтаксическим деревом.
Совсем простые выражения можно разобрать: если это, например,
(x+1), то это вызов функции + (сложение — не оператор, как во многих других языках, а функция) и два аргумента: один символьный (двоеточие означает, что это символ), а второй просто константа.Еще простой пример макроса:
macro named(name, expr)
println("Starting $name")
return quote
$(esc(expr))
end
end
julia> @named "some process" x=5;
Starting some process
julia> x
5С помощью макросов создаются, например, индикаторы выполнения или фильтры для датафреймов — это распространенный механизм в Julia.
Макросы выполняются не в момент вызова, а при парсинге кода.Это главная особенность макросов в Julia. Если где-то внутри функции есть макрос, он будет обработан во время просмотра кода. Поэтому есть нюансы, в каком контексте, в каком скопе будет развернут ваш макрос.
Итого, что мы знаем о языке
Julia — это гибкий и быстрый язык. Но это не все его свойства.
- Julia это динамический язык. Вы можете менять типы переменных на ходу.
- Высокоуровневый язык, как и многие интерпретируемые. Даже такие простые функции, как в примерах, на C выглядели бы более нагруженными.
- В Julia JIT-компилятор достаточно умен. Он обеспечивает скорость, но все, конечно, зависит от того, кто нажимает на кнопки.
- Еще один фактор скорости — стабильность типов. Кастомные типы работают с множественной диспетчеризацией.
- Множественная диспетчеризация и пользовательские типы служат строительными блоками архитектуры (не единственными). Здесь нет ООП в его классическом варианте, поэтому архитектурными блоками становятся методы функций и иерархия типов. Теперь это ваша архитектура, а не система классов, как в обычных языках.
- Julia поддерживает метапрограммирование — это одна из важных фич языка.
Экосистема
Экосистема есть, но она немного хаотичная, потому что Julia относительно молодой язык. В языке есть функциональность, которая нужна для машинного обучения, data science и численного моделирования, но упакована она иначе, не так, как мы привыкли в Python. Например, в Python есть Pandas, и в нем есть абсолютно все, что связано с датафреймами, вплоть до отрисовки картинок, а в Julia аналогичная функциональность распределена между несколькими пакетами.
Экосистема Julia активно развивается, и находится примерно на этапе развития Python 2008 года. Как раз тогда я начал писать на Python, и мне было ненамного удобнее с численными задачами, чем сейчас на Julia. Но это нормальный этап, нужно перетерпеть неудобства молодого языка. Если вам все равно, можете уже пользоваться Julia.
Условные эквиваленты (не все) Python и Julia
Линейная алгебра. Есть в самой Julia: можно создавать, обращать, перемножать матрицы и т.д…
Датафреймы. Есть несколько библиотек.
- DataFrames.jl.
- Мощная библиотека JuliaDB может работать с распределенными датафреймами, которые лежат на разных узлах вашего кластера.
- Язык запросов для датафреймов находится отдельно в Query.jl. Это аналог масок в Pandas — отбор элементов по какому-либо критерию, агрегация и т.д.
Plotting. Если вы привыкли к Matplotlib, то можете с ним работать через интерфейс в Julia. Но есть и свои интерфейсы: к VegaLite.jl, есть универсальный Plots.jl, с выбором бэкенда для отрисовки, есть Gadfly.jl.
Глубокое обучение. Есть интерфейс к TensorFlow, и интересный и компактный Flux.jl. Но пока во Flux нет некоторых продвинутых инструментов, например, адаптивных оптимизаторов или удобных механизмов, как в Keras и TensorFlow, для подгрузки данных. Но сделать это самостоятельно не сложно.
Scikit-learn. Аналог библиотеки есть, он работает, можно использовать модели из sklearn, но пакет иначе структурирован, немного хаотично.
XGBoost. Можно использовать, в Julia есть хороший интерфейс.
Как со всем этим жить?
Можно продолжать работать в Jupyter. IDE — или Juno, или плагин к Visual Studio, но его я не пробовал и не могу оценить.
Железо. С GPU/TPU все хорошо. Пакет CUDAnative.jl позволяет в самой Julia писать ядра для графического процессора. Пишем практически чистый Julia-код, если нужно добавить какой-нибудь хитрый слой в нейронную сеть, причем чтобы все считалось сразу на графическом процессоре. Дальше не наша забота, как это будет скомпилировано и запущено, всё будет работать уже без нас, причем, неплохо.
Совместимость языков: можно вызывать C, Fortran, Python и другие языки.
Совместимость форматов в целом работает, но бывают и исключения.
Packaging: пакетный менеджер расположен в консоли Julia: в специальном режиме можно устанавливать пакеты, удалять, обновлять и т.д.
Дифференцируемое программирование
Сейчас архитектуры нейронных сетей настолько усложнились, что иногда бывает недостаточно ни статического, ни динамических графов. Есть модели, особенно в языке, которые меняются на ходу. Динамический граф лучше, отчасти поэтому PyTorch долгое время был удобнее для исследовательских задач, чем TensorFlow, где был только статический граф, который вы написали и больше не можете изменять.
Хорошо было бы иметь нечто такое, в чем можно посчитать градиенты от произвольного кода, например, кода с циклами или условными переходами. Все это можно сделать в Julia, благодаря ее особенностям, например, компиляции на ходу или множественной диспетчеризации. Один из пакетов, который делает автоматическое дифференцирование, называется Zygote.jl. Это экспериментальный пакет к Flux.jl.
julia> using Zygote
julia> φ(x) = x*sin(x)
julia> Zygote.gradient(φ, π/2.)
(1.0,)
julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax)
julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model))
julia> optimizer = ADAM(0.001)
julia> Flux.train!(loss, params(model), data, optimizer)
julia> model = Chain(x -> sqrt(x), x->x-1)Можно написать в функции
φ что угодно, например, условия, и пакет почти всегда сможет посчитать градиент.Причем Zygote генерирует градиенты «source-to-source»: из нашего представления функции он генерирует функцию для градиента, которая точно также компилируется, а потом вызывается. Это называется differentiable programming — дифференцируемое программирование — для любой функции можно условно сделать backpropagation и использовать в любом алгоритме, который тренируется градиентным спуском.
В этом направлении у Julia есть преимущества благодаря ее особенностям: «source-to-source» можно реализовать на уровне компилятора и вшить в язык так, чтобы всегда можно было посчитать градиенты. Любая, самая безумная архитектура становится возможна.
Использовать Julia или нет?
Если вы берете готовые модели, накладываете сверху свою классификацию и отправляете в продакшн — не берите. При таком сценарии использования вы не получите преимуществ.
Если занимаетесь чем-то сложнее, например, архитектурами, для которых нет готовых предтренированных моделей — попробуйте.
Если занимаетесь численным моделированием, то попробуйте обязательно, вам понравится.
Чтобы начать пользоваться Julia, учтите два нюанса.
- Если вы отдаете клиенту код, то подумайте, кто будет его поддерживать. Julia пока достаточно «бутиковый» язык.
- Если вы разрабатываете сервис, то он отдается по API, а дальше уже не важно, как он устроен внутри.
Следующая Moscow Python Conf++ уже не за горами, и 27 марта Глеб расскажет, что получилось из миграции системы для промышленного оборудования с Python на Julia. А чтобы узнать, что еще будет на конференции, подписывайтесь на telegram-канал или на рассылку сообщества MoscowPython.
