
В 1970 г. американские инженеры запустили аппарат Аполлон-13 к Луне. На борту три батареи топливных элементов, беспокоиться не о чем, всё надежно и многократно продублировано. Но никто не мог предположить, что взрыв кислородного баллона выведет из строя две батареи из трёх. Трагедия! Астронавты вернулись домой, о событии сняли художественный фильм с Томом Хэнксом, а фраза астронавта Джека Свигерта: «Хьюстон, у нас проблема!», вошла в историю.

История Аполлона-13 это еще одно доказательство известного факта, что нельзя подготовиться ко всем возможным неприятностям. Это естественное свойство окружающего мира: железо периодически ломается, код сбоит, а люди ошибаются. Полностью исключить это невозможно.
Для больших распределенных систем такое поведение нормально, это следствие эффекта масштаба и статистики. Именно поэтому Design for Failure (дизайн на отказ) — базовый принцип проектирования облачных сервисов AWS. Системы изначально строятся так, чтобы максимально быстро восстановить штатную работу и минимизировать ущерб от известных и ещё неизвестных сбоев. На HighLoad++ Василий Пантюхин на примерах реальных проблем с боевыми сервисами показал паттерны проектирования распределенных систем, которые используют разработчики AWS.
Василий Пантюхин (Hen) — архитектор Amazon Web Services в странах Европы, Ближнего Востока и Африки. Начинал Unix-админом, 6 лет работал в Sun Microsystem, преподавал технические курсы, 11 лет проповедовал дата-центричность мира в EMC. В международной команде проектировал и реализовывал проекты от Кейптауна до Осло. Сейчас помогает большим и маленьким компаниям работать в публичных облаках.
В 1949 году на одной из баз ВВС в Калифорнии проводили расследование аварий самолетов. Одного из инженеров, который этим занимался, звали Эдвард Мёрфи. Работу местных техников он охарактеризовал так: «Если существует два способа сделать что-либо и один из них ведёт к катастрофе, то кто-то выберет именно этот способ».
Позже благодаря Артуру Блоху высказывание вошло в историю, как один из законов Мёрфи. По-русски — закон подлости. Его суть в том, что не получится избежать поломок и человеческих ошибок, и придётся как-то с этим жить. Именно поэтому при проектировании мы сразу закладываем в свои системы отказы и сбои отдельных компонент.
В дизайне на отказ мы пытаемся улучшить три характеристики:
Надежность обладает свойством «known unknowns» — «известные неизвестные». Мы защищаем себя от известных проблем, но не знаем, когда они произойдут.
В отказоустойчивость добавляется «unknown unknowns» — это проблемы-сюрпризы, о которых мы ничего не знаем. Многие подобные проблемы в облаке связаны с эффектом масштаба: система разрастается до такого размера, когда появляются новые, удивительные и неожиданные эффекты.
Обычно сбой — это не бинарное явление. Его основное свойство — «blast radius» или уровень деградации сервиса, радиус поражения. Наша задача — уменьшать «blast radius» систем.
Если мы признаем, что проблем не избежать, то должны превентивно к ним готовиться. Это значит, что мы проектируем сервисы так, что в случае возникновения неприятностей (они обязательно будут), мы контролируем проблемы, а не наоборот.
Наверняка, у вас дома есть электроника, которая управляется с пульта, например, телевизор. Экран телевизора это часть Data plane — то, что непосредственно выполняет функцию. Пульт — это пользовательский интерфейс — Control plane. Он используется для управления и настройки сервиса. В облаке мы стараемся разделять Data plane и Control plane для тестирования и разработки.
Пользователи, чаще всего, не видят сложность Control plane. Но ошибки в её проектировании и реализации — самые частые причины массовых сбоев. Именно поэтому мои советы сфокусированы на Control plane — иногда явно, иногда нет.
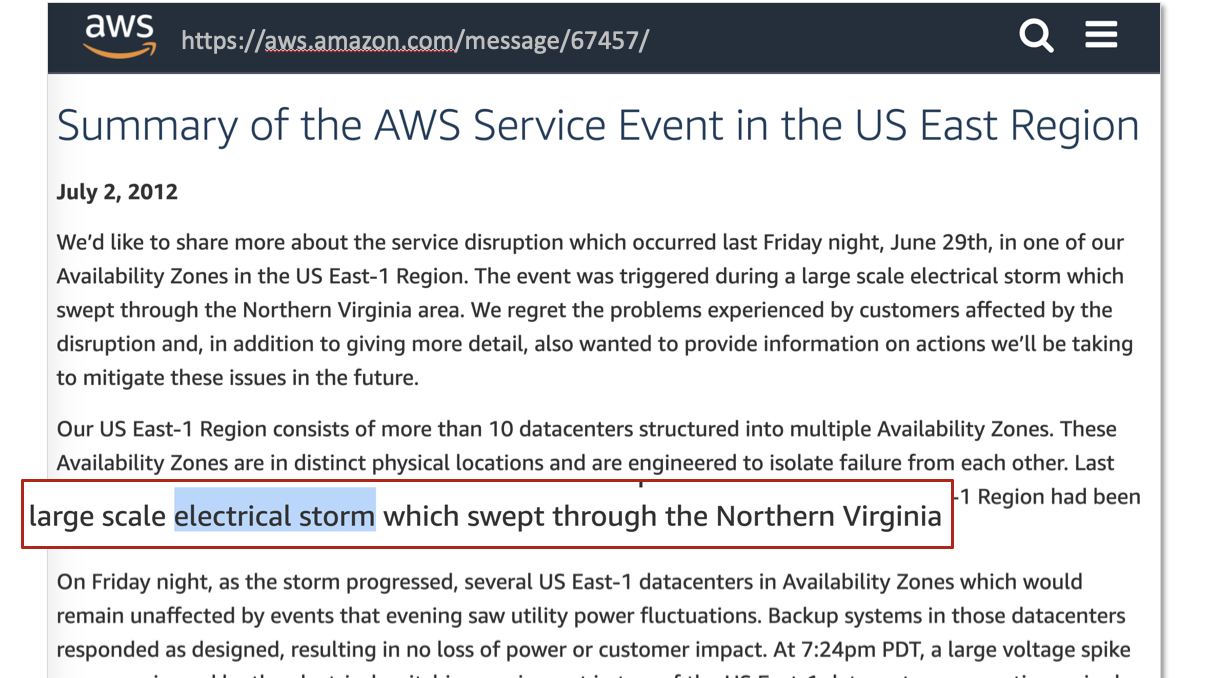
В июле 2012 года в Северной Вирджинии прошел сильный шторм. У ЦОД есть защита, дизель-генераторы и прочее, но так получилось, что в одном из дата-центров одной из зон доступности (Availability Zone, AZ) региона Северная Вирджиния пропало питание. Электричество быстро восстановили, но восстановление сервисов затянулось на часы.
Расскажу о причинах на примере одного из базовых сервисов — балансировщика нагрузки CLB (Classic Load Balancer). Он работает просто: при запуске нового балансировщика в каждой зоне доступности создаются отдельные инстансы, IP которых резолвят DNS.

Когда сбоит один из инстансов, сообщение об этом отправляется в специальную БД.

В ответ запускаются процедуры: удаление записей из DNS, запуск нового инстанса и добавление нового IP в DNS.
Примечание: Так система работала в прошлом, сейчас всё принципиально иначе.
Всё просто — ломаться нечему. Но во время массового сбоя, когда рушатся одновременно тысячи инстансов, появляется огромный Backlog в БД из сообщений на обработку.

Но стало еще хуже. Control plane — это распределенная система. Из-за бага мы получили дубликаты и тысячи записей в базе распухли до сотен тысяч. С этим стало очень тяжело работать.
Когда происходит сбой на одном из инстансов, весь трафик практически мгновенно переключается на выжившие машины и нагрузка удваивается (в примере для простоты всего две зоны доступности).
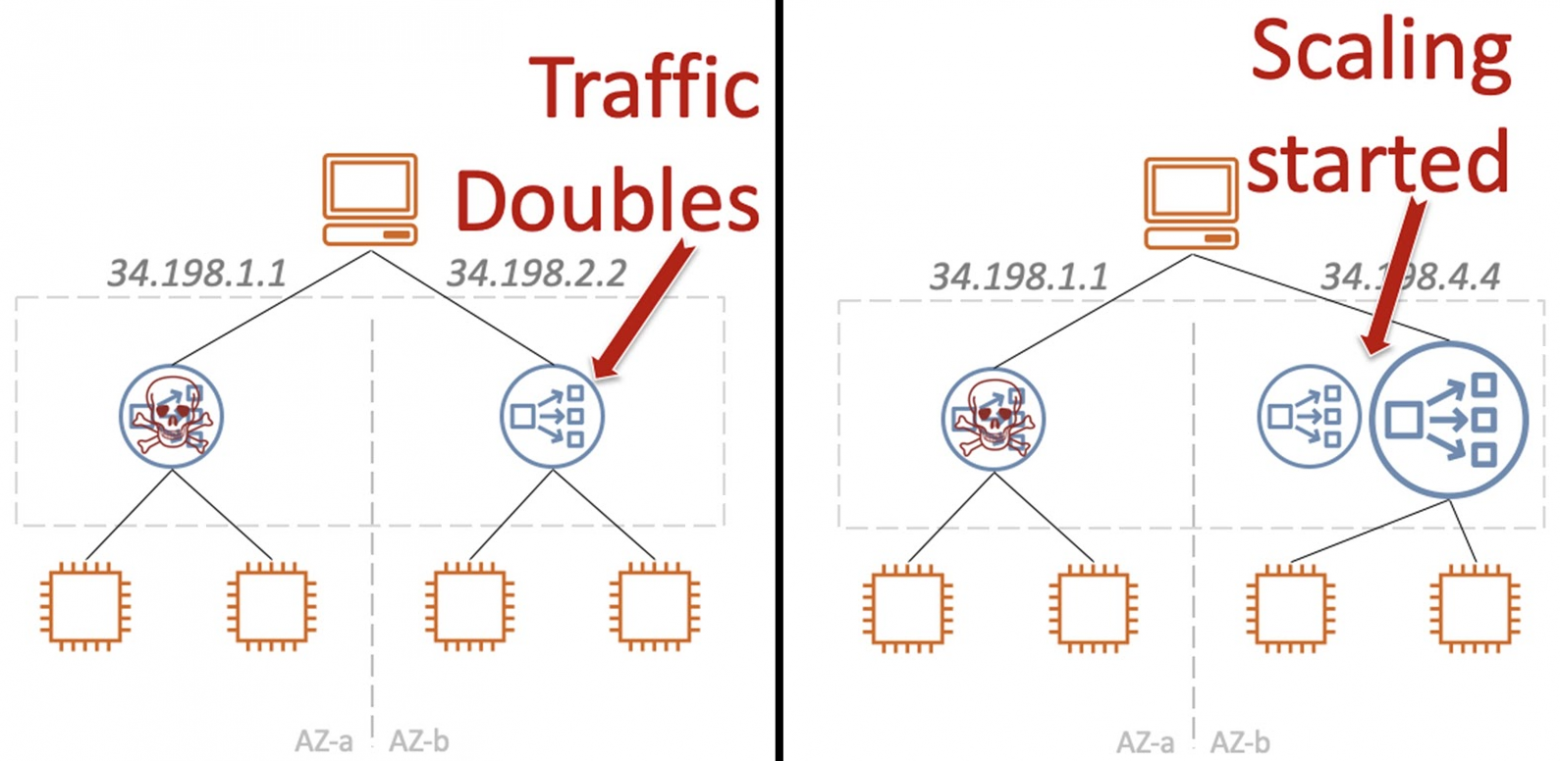
Ресурсов не хватает, живой инстанс автоматически начинает масштабироваться. Процесс занимает относительно много времени. Всё происходит пиково и одновременно с огромным количеством инстансов — свободные ресурсы зоны доступности заканчиваются. Начинается «драка» за ресурсы.
В Северной Вирджинии автоматика не справилась с массовым сбоем и инженеры вручную (скриптами) восстанавливали работоспособность сервисов. Подобные неприятности случаются редко. На разборе полетов возникли вопросы о причинах сбоя, приняли решение, что ситуация больше не должна повториться и нужно менять весь сервис.
Восемь паттернов, о которых я расскажу, это ответы на некоторые из вопросов.
Примечание. Это наш опыт дизайна сервисов, а не Вселенская мудрость для повсеместного использования. Паттерны применяются в конкретных ситуациях.
Некоторые паттерны могут противоречить друг другу — это нормально. Даже внутри AWS различные группы разработчиков используют принципиально разные подходы для решения схожих задач. Основная идея статьи — показать, как бывает. Решение всегда за вами. Если ваши условия другие — просто не применяйте наши советы. Используйте или критикуйте паттерны осмысленно!
Для минимизации влияния сбоев масса подходов. Один из них — ответить на вопрос «Как при сбое и во время восстановлении сделать так, чтобы пользователи, которые не знали о проблеме, так ничего о ней и не узнали?»
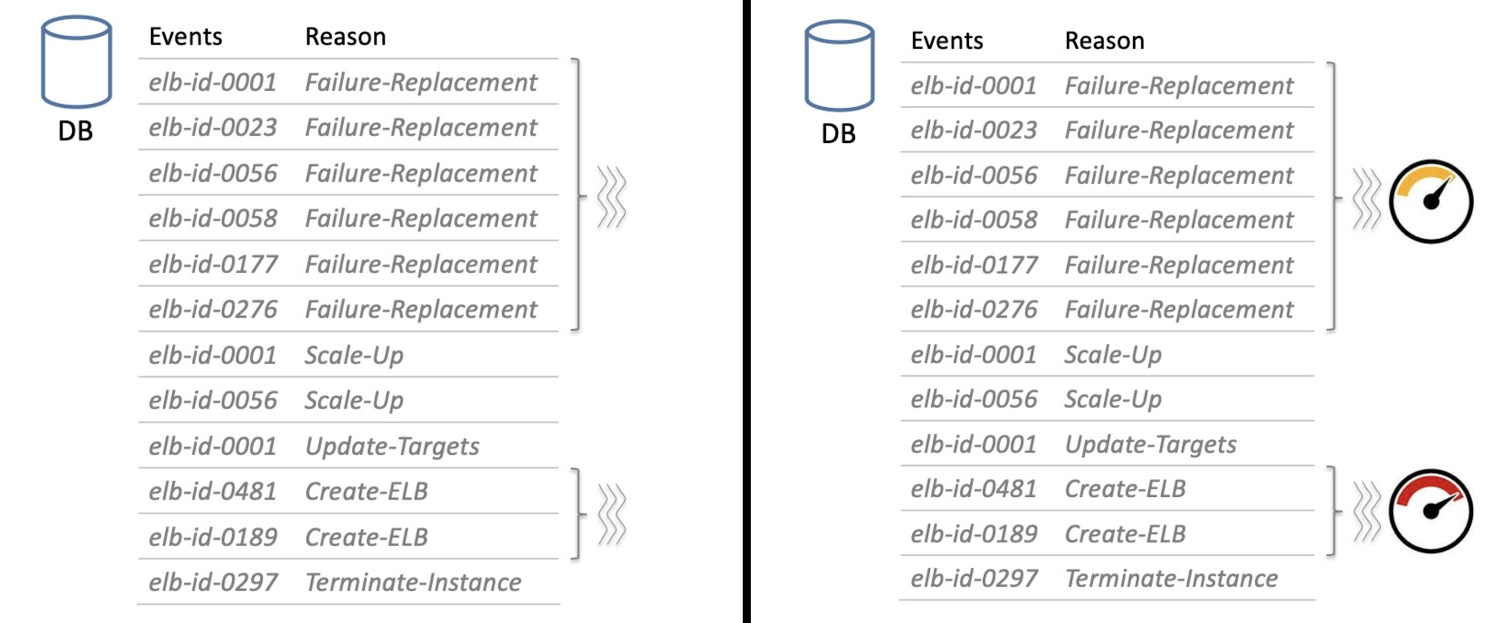
В наш огромный Backlog попадают не только сообщения о сбое, но и другие, например, о масштабировании или о том, что кто-то запускает новый балансировщик. Такие сообщения нужно изолировать друг от друга, функционально группируя: отдельная группа сообщений восстановления после сбоя, отдельно запуск нового балансировщика.
Предположим, десять пользователей заметили проблему — одна из нод их балансировщиков упала. Сервисы как-то работают на оставшихся ресурсах, но проблема чувствуется.
У нас есть десять расстроенных пользователей. Появляется одиннадцатый — он ничего не знает о проблеме, а просто хочет новый балансировщик. Если его запрос поставить вниз очереди на обработку, то, скорее всего, он не дождется. Пока другие процедуры обработки завершатся, время запроса закончится. Вместо десяти расстроенных пользователей у нас будет одиннадцать.
Чтобы этого не произошло, мы приоритезируем некоторые запросы — ставим наверх очереди, например, запросы о создании новых ресурсов. При массовом сбое относительно малое количество таких запросов никак не скажется на времени восстановления ресурсов других заказчиков. Но в процессе восстановления будем сдерживать число пользователей, вовлеченных в проблему.
Реакция на сообщения о проблеме — это запуск процедур восстановления, в частности, работа с DNS. Массовые сбои это огромные пиковые нагрузки на Control plane. Второй паттерн помогает Control plane быть стабильнее и предсказуемее в такой ситуации.

Мы используем подход, который называется Constant work — постоянная работа.

Например, DNS можно сделать чуть умнее: он будет постоянно проверять инстансы балансировщика, живые они или нет. Результатом каждый раз будет bitmap: инстанс отвечает — 1, мёртвый — 0.
DNS проверяет инстансы раз в несколько секунд, независимо от того, восстанавливается ли система после массового сбоя или работает в штатном режиме. Он выполняет одну и ту же работу — никаких пиков, всё предсказуемо и стабильно.
Другой упрощенный пример: мы хотим поменять конфигурацию на большом флоте. В нашей терминологии флот — это группа виртуальных машин, которые вместе выполняют какую-то работу.

Помещаем изменения конфигурации в S3-бакет, и каждые 10 секунд (для примера) пушим всю эту конфигурацию на наш флот виртуальных машин. Два важных момента.
Когда выполняем какую-то постоянную работу, мы за это больше платим. Например, 100 виртуальных машин запрашивают конфигурацию каждую секунду. Это стоит примерно 1200$ в год. Эта сумма принципиально меньше зарплаты программиста, которому мы можем поручить разработку Control plane с классическим подходом — реакцией на сбой и распространением только изменений конфигурации.
Если каждые несколько секунд менять конфигурацию, как в примере, то это медленно. Но во многих случаях изменение конфигурации или запуск сервисов занимают минуты — несколько секунд ничего не решают.
Секунды важны для сервисов, в которых конфигурация должна меняться мгновенно, например, при изменение настроек VPC. Здесь «постоянная работа» неприменима. Это лишь паттерн, а не правило. Если в вашем случае это не работает — не применяйте.
В нашем примере при падении инстанса балансировщика, второй выживший инстанс практически сразу получает удвоение нагрузки и начинает масштабироваться. При массовом сбое это съедает огромное количество ресурсов. Третий паттерн помогает этот процесс контролировать — масштабироваться заранее.
В случае двух зон доступности масштабируемся при утилизации меньше 50%.

Если все сделать заранее, то при сбое выжившие инстансы балансировщика уже готовы принять удвоенный трафик.
Раньше мы масштабировались лишь при высокой утилизации, например, 80%, а сейчас при 45%. Система простаивает большую часть времени и становится дороже. Но мы готовы с этим мириться и активно используем паттерн, потому что это страховка. За страховку приходится платить, но при серьезных неприятностях выигрыш покрывает все расходы. Если решите использовать паттерн, посчитайте все риски и цену заранее.
Существует два способа строить и масштабировать сервисы: монолит и ячеистая структура (cell-based).

Монолит развивается и растет как единый большой контейнер. Мы добавляем ресурсы, система распухает, мы упираемся в разные лимиты, линейные характеристики становятся нелинейными и выходят в насыщение, а «blast radius» системы — вся система целиком.
Если монолит плохо протестирован, повышается вероятность возникновения проблем-сюрпризов — «unknown unknowns». Но большой монолит нельзя полноценно тестировать. Иногда для этого придется построить отдельную зону доступности, например, для популярного сервиса, который строится как монолит в рамках зоны доступности (это много дата-центров). Кроме того, что надо как-то создать огромную тестовую нагрузку, которая похожа на настоящую, это невозможно с финансовой точки зрения.
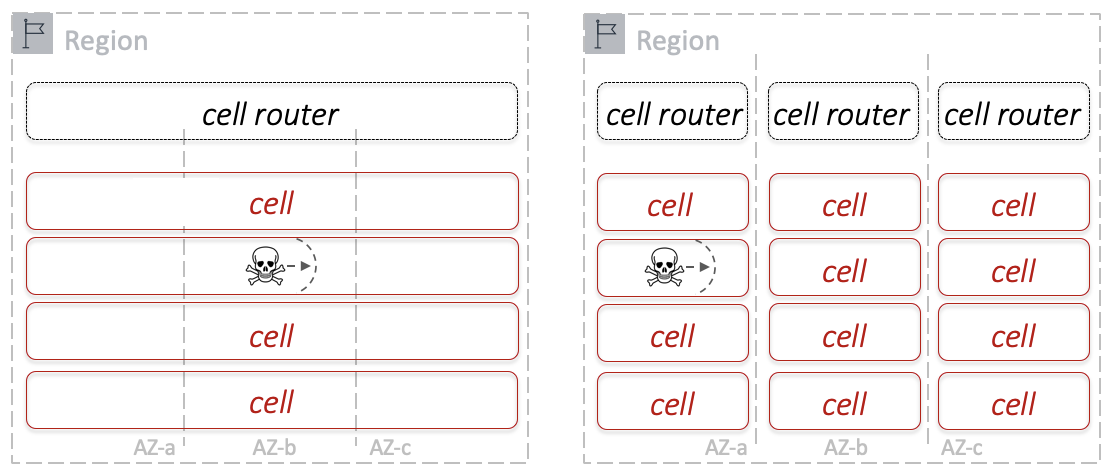
Поэтому в большинстве случаев мы используем ячеистую архитектуру — конфигурацию, в которой система строится из ячеек фиксированного размера. Добавляя ячейки, мы её масштабируем.
Ячеистая архитектура популярна в облаке AWS. Она помогает изолировать сбои и уменьшить «blast radius» до одной или нескольких ячеек. Мы можем полноценно тестировать ячейки среднего размера, это серьезно снижает риски.
Подобный подход используют в судостроении: корпус корабля или судна разделяют перегородками на отсеки. В случае пробоины затапливается один или несколько отсеков, но корабль не тонет. Да, Титанику это не помогло, но с и проблемами-айсбергами мы сталкиваемся очень редко.
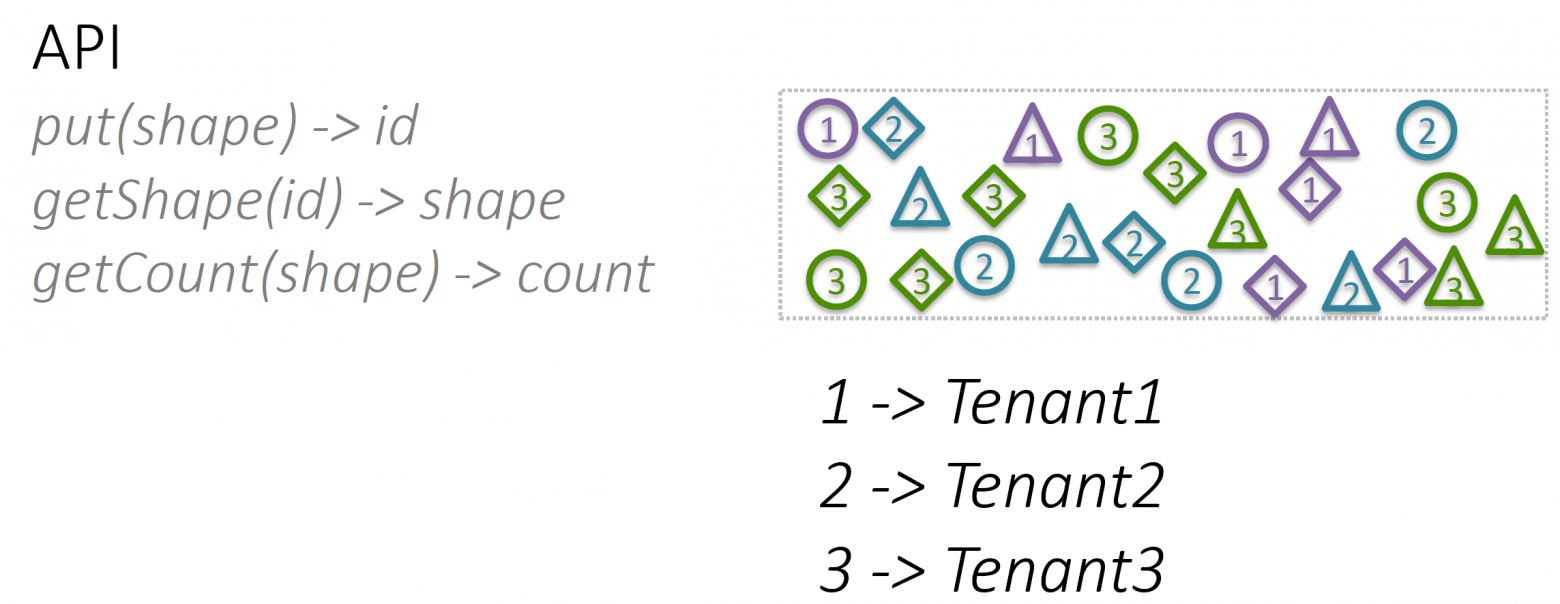
Проиллюстрирую применение ячеистого подхода на примере сервиса Simple Shapes Service. Это не сервис AWS, я его сам придумал. Это набор простых API для работы с простыми геометрическими фигурами. Можно создать экземпляр геометрической фигуры, запросить тип фигуры по ее id, или сосчитать все экземпляры заданного типа. Например, на запрос

Чтобы сервис сделать облачным, его должны одновременно использовать различные пользователи. Сделаем его мультитенантным.
Дальше нужно придумать способ партиционировать — разделять фигуры по ячейкам. Есть несколько вариантов выбора partition key. Самый простой — по геометрической фигуре: все ромбы в первую ячейку, круги во вторую, треугольники в третью.
У этого способа есть плюсы и минусы.
Второй способ — использовать id объектов по диапазонам: первая тысяча объектов в первую ячейку, вторая — во вторую. Так распределение равномернее, но зато есть другие сложности. Например, чтобы подсчитать все треугольники, нужно использовать метод
Третий способ — разделение по тенантам (пользователям). Здесь мы сталкиваемся с классической проблемой. В облаке обычно очень много «маленьких» пользователей, которые что-то пробуют и практически не нагружают сервис. При этом есть пользователи-мастодонты. Их мало, но они потребляют огромное количество ресурсов. Такие пользователи никогда не влезут ни в какую ячейку. Приходится придумывать хитрые способы, чтобы их распределять между множеством ячеек.

Идеального способа нет, каждый сервис индивидуален. Хорошая новость в том, что здесь работает житейская мудрость — колоть дрова удобнее вдоль по волокнам, а не рубить их поперек. Во многих сервисах эти «волокна» более-менее очевидны. Дальше можно экспериментировать и найти оптимальный partition key.
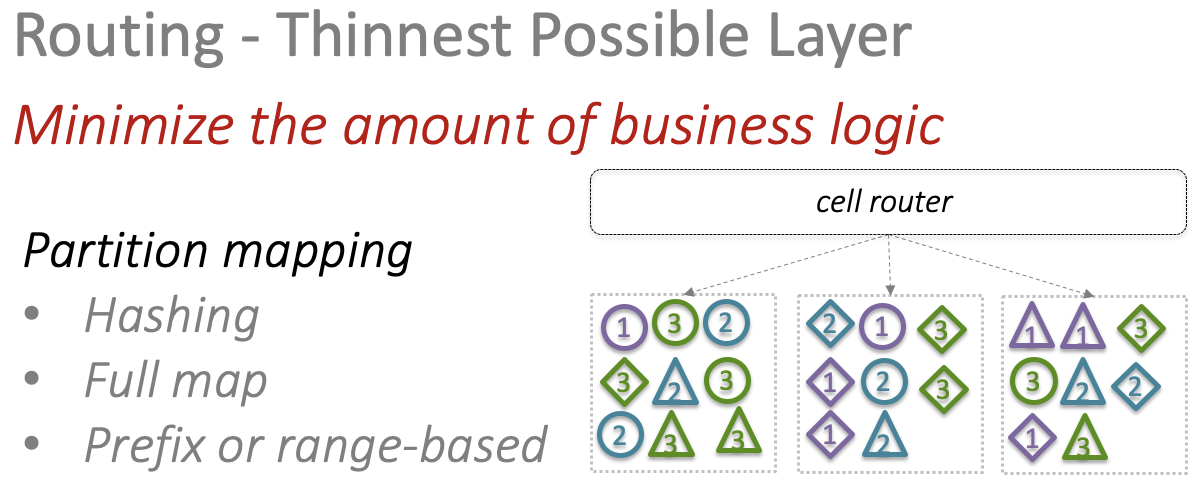
Ячейки между собой связаны (хотя и слабо). Поэтому должен быть связующий уровень. Часто его называют уровнем маршрутизации или маппирования. Он нужен чтобы понимать в какие ячейки передавать конкретные запросы. Этот уровень должен быть максимально простым. Постарайтесь не закладывать в него бизнес-логику.
Возникает вопрос размера ячеек: маленькие — плохо, большие — тоже плохо. Универсального совета нет — решайте по ситуации.
В облаке AWS мы используем логические и физические ячейки разных размеров. Есть региональные сервисы с большим размером ячейки, есть зональные сервисы, где ячейки поменьше.
Примечание. О микроячейках я рассказывал на Saint Highload++ Online в начале апреля этого года. Там я подробно обсуждал пример конкретного использования этого паттерна в нашем базовом сервисе Amazon EBS.
Когда пользователь запускает новый балансировщик, он получает инстансы в каждой зоне доступности. Независимо от того, используются ли ресурсы или нет, они выделены и принадлежат исключительно этому тенанту облака.
Для AWS, такой подход неэффективен, потому что утилизация ресурсов сервиса в среднем очень низкая. Это сказывается на стоимости. Для пользователей облака это не гибкое решение. Оно не может адаптироваться к быстро изменяющимся условиям, например, за минимальное время обеспечить ресурсами неожиданно возросшую нагрузку.

CLB был первым балансировщиком в облаке Amazon. Сервисы современнее используют мультитенантный подход, например NLB (Network Load Balancer). Основа, «движок» таких сетевых сервисов — HyperPlane. Это внутренний, невидимый конечным пользователям, огромный флот виртуальных машин (нод).

Преимущества мультитенантного подхода или пятого паттерна.
Звучит круто! Но у мультитенантного подхода есть недостатки. На рисунке флот HyperPlane с тремя тенантами (ромбики, кружочки и треугольники), которые распределены по всем нодам.

Здесь возникает классическая проблема «шумного соседа» (Noisy neighbor): деструктивное действие тенанта, который генерирует сверхвысокий или сбойный трафик, потенциально повлияет на всех пользователей.

«Blast radius» в такой системе — это все тенанты. Вероятность возникновения деструктивного «шумного соседа» в реальной зоне доступности AWS не велика. Но мы всегда должны быть готовы к худшему. Защищаемся, используя ячеистый подход, — выделяем группы нод как ячейки. В этом контексте мы их называем шардами. Ячейки, шарды, партиции — здесь это одно и тоже.
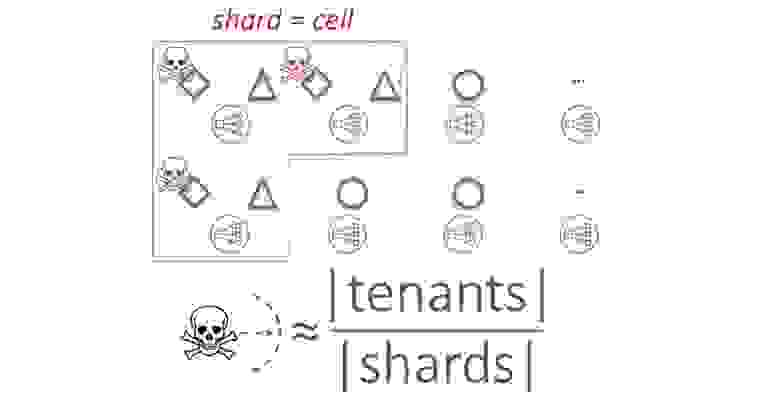
В этом примере ромб, как «шумный сосед», повлияет лишь на одного тенанта — на треугольник. Но треугольнику будет очень больно. Чтобы сгладить эффект, применим шестой паттерн — перемешивающее шардирование.
Распределяем тенанты по нодам случайным образом. Например, ромб высаживается на 1, 3 и 6 ноды, а треугольник на 2, 6 и 8. У нас 8 нод и шард размера 3.

Здесь работает простая комбинаторика. С вероятностью 54% будет всего лишь одно пересечение между тенантами.

«Шумный сосед» повлияет лишь на одного тенанта, и не всей нагрузкой, а только 30 процентами.
Рассмотрим конфигурацию приближенную к реальной — 100 нод, размер шарда 5. С вероятностью 77% пересечений не будет вообще.

Перемешивающее шардирование (Shuffle sharding) позволяет принципиально уменьшить «blast radius». Этот подход используется во многих сервисах AWS.
Восстанавливаясь после массового сбоя, мы обновляем конфигурацию многих компонентов. Типичный вопрос при этом — пушить или пулить измененную конфигурацию? Кто инициатор изменений: источник, содержащий изменения конфигурации, или его потребители? Но эти вопросы неправильны. Правильный вопрос — какой флот больше?
Рассмотрим простую ситуацию: большой флот фронтенд виртуальных машин и какое-то количество бэкендов.
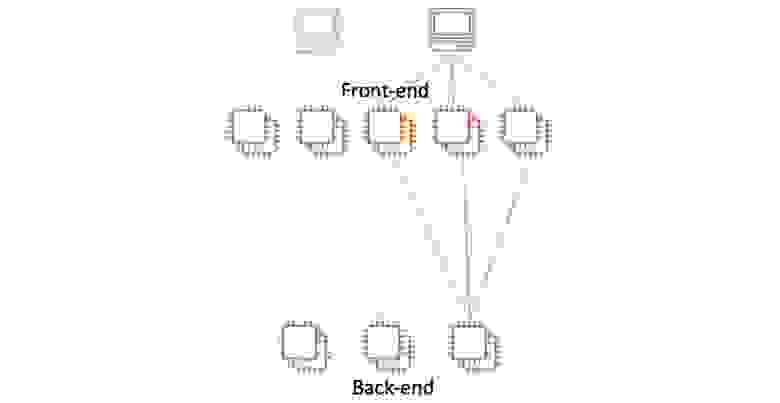
Используем ячеистый подход — группы фронтенд-инстансов будут работать с определёнными бэкендами. Для этого определить маршрутизацию — маппинг бэкендов и работающих с ними фронтендов.

Статическая маршрутизация не подходит. Алгоритмы хэширования плохо работают при массовых сбоях, когда нужно быстро менять бóльшую часть маршрутов. Поэтому лучше использовать динамическую маршрутизацию. Рядом с большими флотами фронтенд и бэкенд-инстансов ставим маленький сервис, который будет заниматься только маршрутизацией. Он будет знать и назначать бэкенд и фронтенд-маппинг в каждый момент времени.
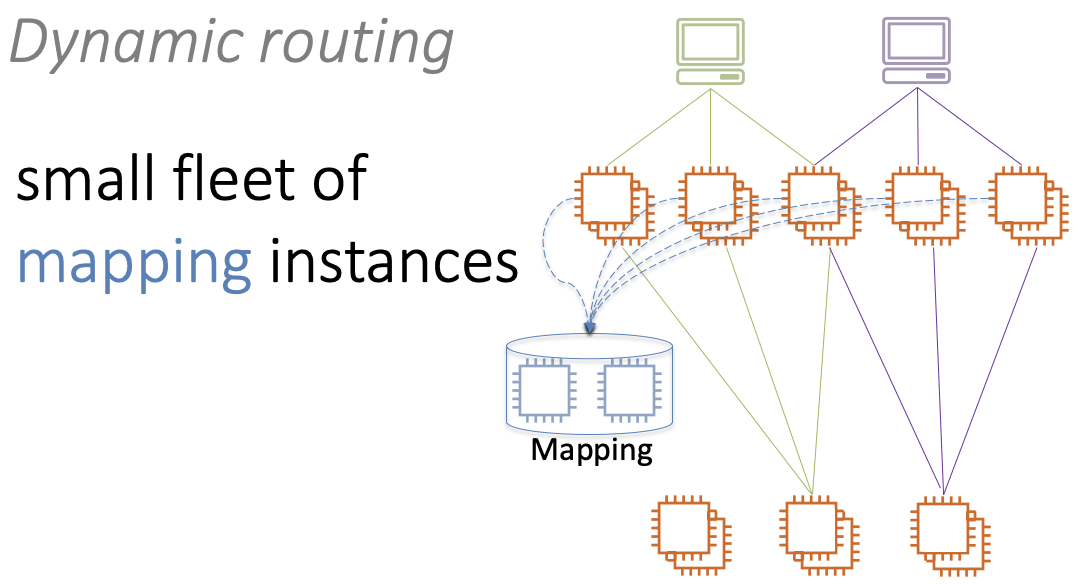
Предположим, у нас произошел большой сбой, много фронтенд инстансов упало. Они начинают массово восстанавливаться и практически одновременно запрашивают конфигурацию маппинга у сервиса маршрутизации.

Маленький сервис маршрутизации бомбардируется огромным количеством запросов. Он не справится с нагрузкой, в лучшем случае деградирует, а в худшем — умрет.
Поэтому правильно не запрашивать изменения конфигурации у маленького сервиса, а наоборот — строить свою систему так, чтобы «малыш» сам инициировал изменения конфигурации в сторону большого флота инстансов.
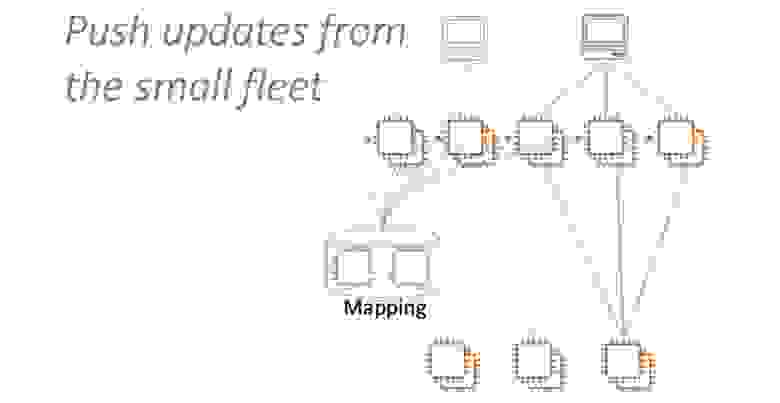
Используем паттерн постоянной работы. Маленький сервис маршрутизации будет раз в несколько секунд рассылать конфигурацию всем инстансам фронтенд флота. Он никогда не сможет перегрузить большой сервис. Седьмой паттерн помогает улучшить стабильность и отказоустойчивость.
Первые семь паттернов улучшают систему. Последний паттерн действует иначе.
Ниже — классический график зависимости задержки от нагрузки. В правой части графика находится «колено», когда при сверхвысоких нагрузках даже маленькое увеличение приводит к значительному повышению задержки (latency).

В штатном режиме мы никогда не уводим наши сервисы в правую часть графика. Простой способ это контролировать — вовремя добавлять ресурсы. Но мы готовимся к любым неприятностям. Например, в правую часть графика мы можем переместиться восстанавливаясь после массового сбоя.
Наложим на график клиентский таймаут. Клиентом может быть кто угодно, например другой компонент внутри нашего же сервиса. Для простоты нарисуем график задержки 50 процентилем.
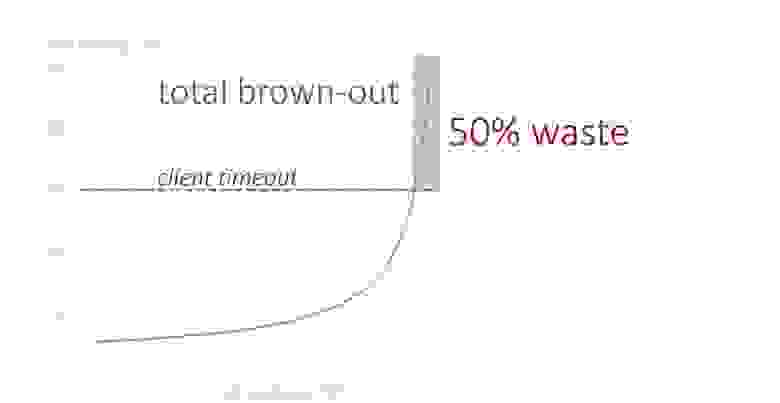
Здесь мы сталкиваемся с ситуацией, которая называется brownout. Возможно, вам знаком термин blackout, когда в городе отключается электричество. Brownout — это когда что-то работает, но настолько плохо и медленно, что, считай, и не работает совсем.
Посмотрим на коричневую зону brownout. Сервис получил запрос от клиента, обработал его и вернул результат. Однако, в половине случаев у клиентов уже закончился таймаут и результат никто не ждёт. В другой половине результат возвращается быстрее таймаута, но в медленной системе это занимает слишком много времени.
Мы столкнулись с двойной проблемой: мы уже перегружены и находимся в правой части графика, но при этом еще «греем воздух», выполняя массу бесполезной работы. Как этого избежать?
Найдём «колено» — точку перегиба на графике. Измерим или теоретически оценим.
Отбросим трафик, который заставляет нас уйти правее точки перегиба.
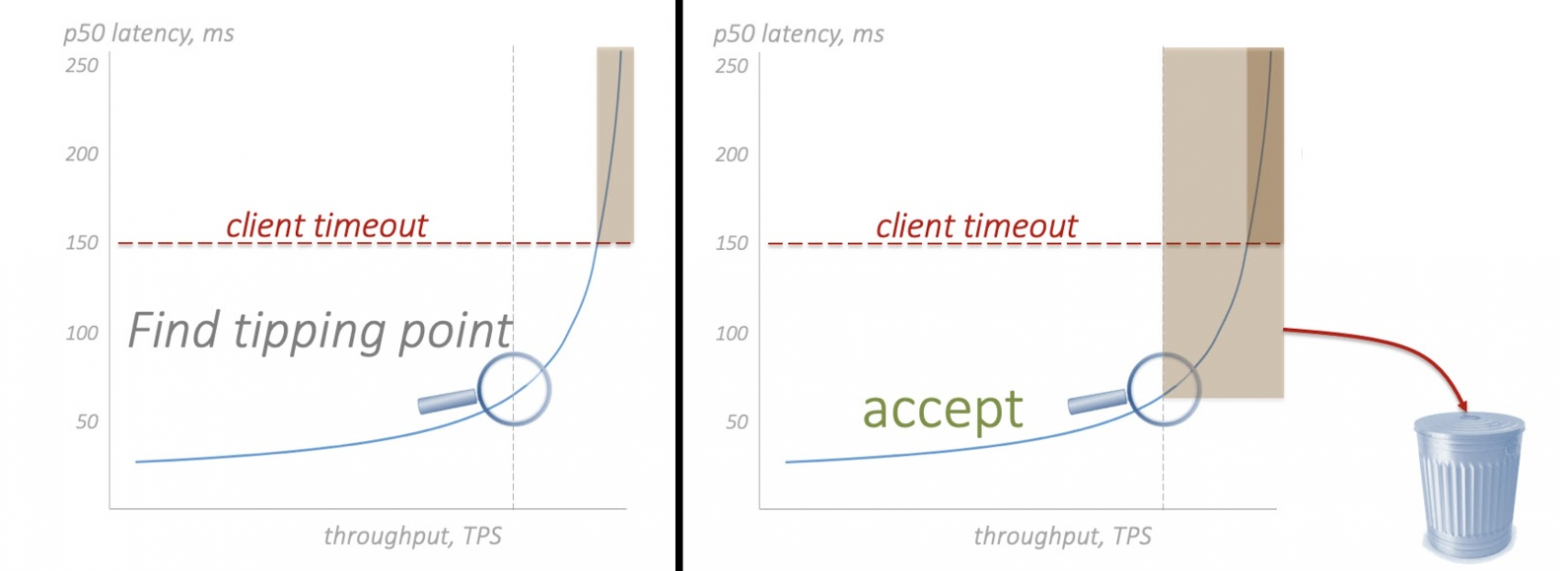
Мы должны просто игнорировать часть запросов. Мы их даже не пытаемся обработать, а сразу возвращаем клиенту ошибку. Даже при перегрузе мы можем позволить себе эту операцию — она «дешёвая». Запросы не выполняются, снижается общая доступность сервиса. Хотя и отброшенные запросы рано или поздно будут обработаны после одного или нескольких повторов (retry) со стороны клиентов.

При этом другая часть запросов обрабатывается с гарантированно низкой задержкой. В итоге, мы не выполняем бесполезной работы, а ту что делаем — делаем хорошо.
Изоляция и регулирование. Иногда имеет смысл приоритезировать определенные типы запросов. Например, при относительно небольшом объеме запросов на создание новых ресурсов их можно поставить в начало очереди. Важно, чтобы это не ущемляло других пользователей. При массовых сбоях пользователи, которые ожидают восстановления своих ресурсов, не почувствуют существенной разницы.
Постоянная работа. Уменьшаем или вообще исключаем переключения режимов сервисов. Один режим, который стабильно и постоянно работает, независимо от нештатных или рабочих ситуаций, принципиально улучшает стабильность и предсказуемость работы Control plane.
Предварительное масштабирование. Масштабируемся заранее при меньших значениях утилизации. За это придётся немного больше платить, но это страховка, которая окупается во время серьезных сбоев в системе.
Ячеистая архитектура. Много слабосвязанных ячеек предпочтительнее чем монолит. Ячеистый подход позволяет уменьшить «blast radius» и вероятность возникновения ошибок-сюрпризов.
Мультитенантный подход значительно улучшает утилизацию сервиса, снижает его стоимость и уменьшает «blast radius».
Перемешивающее шардирование. Это подход, который относится к мультитенантным сервисам. Он дополнительно позволяет контролировать «blast radius».
«Маленький флот вызывает большой, а не наоборот». Мы стараемся строить сервисы так, чтобы маленькие сервисы инициировали изменения больших конфигураций. Часто используем его совместно с паттерном постоянной нагрузки.
Отбрасывание нагрузки. В нештатных ситуациях стараемся выполнять только полезную работу, и делать её хорошо. Для этого отбрасываем часть нагрузки, с которой всё равно не справимся.

История Аполлона-13 это еще одно доказательство известного факта, что нельзя подготовиться ко всем возможным неприятностям. Это естественное свойство окружающего мира: железо периодически ломается, код сбоит, а люди ошибаются. Полностью исключить это невозможно.
Для больших распределенных систем такое поведение нормально, это следствие эффекта масштаба и статистики. Именно поэтому Design for Failure (дизайн на отказ) — базовый принцип проектирования облачных сервисов AWS. Системы изначально строятся так, чтобы максимально быстро восстановить штатную работу и минимизировать ущерб от известных и ещё неизвестных сбоев. На HighLoad++ Василий Пантюхин на примерах реальных проблем с боевыми сервисами показал паттерны проектирования распределенных систем, которые используют разработчики AWS.
Василий Пантюхин (Hen) — архитектор Amazon Web Services в странах Европы, Ближнего Востока и Африки. Начинал Unix-админом, 6 лет работал в Sun Microsystem, преподавал технические курсы, 11 лет проповедовал дата-центричность мира в EMC. В международной команде проектировал и реализовывал проекты от Кейптауна до Осло. Сейчас помогает большим и маленьким компаниям работать в публичных облаках.
В 1949 году на одной из баз ВВС в Калифорнии проводили расследование аварий самолетов. Одного из инженеров, который этим занимался, звали Эдвард Мёрфи. Работу местных техников он охарактеризовал так: «Если существует два способа сделать что-либо и один из них ведёт к катастрофе, то кто-то выберет именно этот способ».
Позже благодаря Артуру Блоху высказывание вошло в историю, как один из законов Мёрфи. По-русски — закон подлости. Его суть в том, что не получится избежать поломок и человеческих ошибок, и придётся как-то с этим жить. Именно поэтому при проектировании мы сразу закладываем в свои системы отказы и сбои отдельных компонент.
Дизайн на отказ
В дизайне на отказ мы пытаемся улучшить три характеристики:
- доступность (те самые «девятки»);
- надежность — свойство системы предоставлять необходимый уровень сервиса;
- отказоустойчивость — свойство системы препятствовать возникновению проблем и быстро после них восстанавливаться.
Надежность обладает свойством «known unknowns» — «известные неизвестные». Мы защищаем себя от известных проблем, но не знаем, когда они произойдут.
В отказоустойчивость добавляется «unknown unknowns» — это проблемы-сюрпризы, о которых мы ничего не знаем. Многие подобные проблемы в облаке связаны с эффектом масштаба: система разрастается до такого размера, когда появляются новые, удивительные и неожиданные эффекты.
Обычно сбой — это не бинарное явление. Его основное свойство — «blast radius» или уровень деградации сервиса, радиус поражения. Наша задача — уменьшать «blast radius» систем.
Если мы признаем, что проблем не избежать, то должны превентивно к ним готовиться. Это значит, что мы проектируем сервисы так, что в случае возникновения неприятностей (они обязательно будут), мы контролируем проблемы, а не наоборот.
Когда мы реагируем на проблему — она контролирует нас.
Data plane и Control plane
Наверняка, у вас дома есть электроника, которая управляется с пульта, например, телевизор. Экран телевизора это часть Data plane — то, что непосредственно выполняет функцию. Пульт — это пользовательский интерфейс — Control plane. Он используется для управления и настройки сервиса. В облаке мы стараемся разделять Data plane и Control plane для тестирования и разработки.
Пользователи, чаще всего, не видят сложность Control plane. Но ошибки в её проектировании и реализации — самые частые причины массовых сбоев. Именно поэтому мои советы сфокусированы на Control plane — иногда явно, иногда нет.
История одной неприятности
В июле 2012 года в Северной Вирджинии прошел сильный шторм. У ЦОД есть защита, дизель-генераторы и прочее, но так получилось, что в одном из дата-центров одной из зон доступности (Availability Zone, AZ) региона Северная Вирджиния пропало питание. Электричество быстро восстановили, но восстановление сервисов затянулось на часы.

Расскажу о причинах на примере одного из базовых сервисов — балансировщика нагрузки CLB (Classic Load Balancer). Он работает просто: при запуске нового балансировщика в каждой зоне доступности создаются отдельные инстансы, IP которых резолвят DNS.
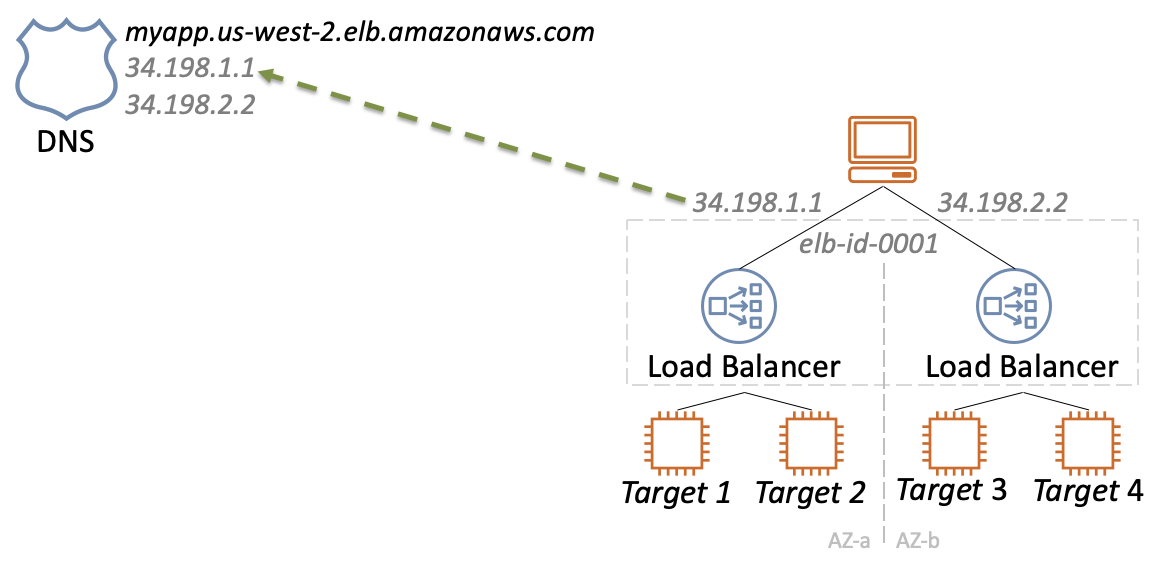
Когда сбоит один из инстансов, сообщение об этом отправляется в специальную БД.

В ответ запускаются процедуры: удаление записей из DNS, запуск нового инстанса и добавление нового IP в DNS.
Примечание: Так система работала в прошлом, сейчас всё принципиально иначе.
Всё просто — ломаться нечему. Но во время массового сбоя, когда рушатся одновременно тысячи инстансов, появляется огромный Backlog в БД из сообщений на обработку.
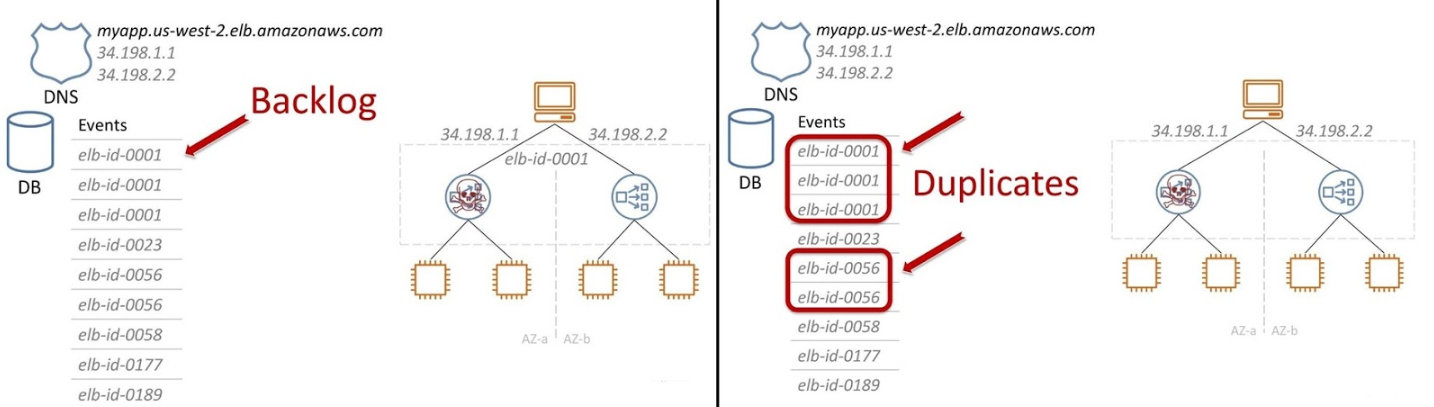
Но стало еще хуже. Control plane — это распределенная система. Из-за бага мы получили дубликаты и тысячи записей в базе распухли до сотен тысяч. С этим стало очень тяжело работать.
Когда происходит сбой на одном из инстансов, весь трафик практически мгновенно переключается на выжившие машины и нагрузка удваивается (в примере для простоты всего две зоны доступности).

Ресурсов не хватает, живой инстанс автоматически начинает масштабироваться. Процесс занимает относительно много времени. Всё происходит пиково и одновременно с огромным количеством инстансов — свободные ресурсы зоны доступности заканчиваются. Начинается «драка» за ресурсы.
В Северной Вирджинии автоматика не справилась с массовым сбоем и инженеры вручную (скриптами) восстанавливали работоспособность сервисов. Подобные неприятности случаются редко. На разборе полетов возникли вопросы о причинах сбоя, приняли решение, что ситуация больше не должна повториться и нужно менять весь сервис.
Восемь паттернов, о которых я расскажу, это ответы на некоторые из вопросов.
Примечание. Это наш опыт дизайна сервисов, а не Вселенская мудрость для повсеместного использования. Паттерны применяются в конкретных ситуациях.
Некоторые паттерны могут противоречить друг другу — это нормально. Даже внутри AWS различные группы разработчиков используют принципиально разные подходы для решения схожих задач. Основная идея статьи — показать, как бывает. Решение всегда за вами. Если ваши условия другие — просто не применяйте наши советы. Используйте или критикуйте паттерны осмысленно!
Изоляция и регулирование
Для минимизации влияния сбоев масса подходов. Один из них — ответить на вопрос «Как при сбое и во время восстановлении сделать так, чтобы пользователи, которые не знали о проблеме, так ничего о ней и не узнали?»
В наш огромный Backlog попадают не только сообщения о сбое, но и другие, например, о масштабировании или о том, что кто-то запускает новый балансировщик. Такие сообщения нужно изолировать друг от друга, функционально группируя: отдельная группа сообщений восстановления после сбоя, отдельно запуск нового балансировщика.
Предположим, десять пользователей заметили проблему — одна из нод их балансировщиков упала. Сервисы как-то работают на оставшихся ресурсах, но проблема чувствуется.
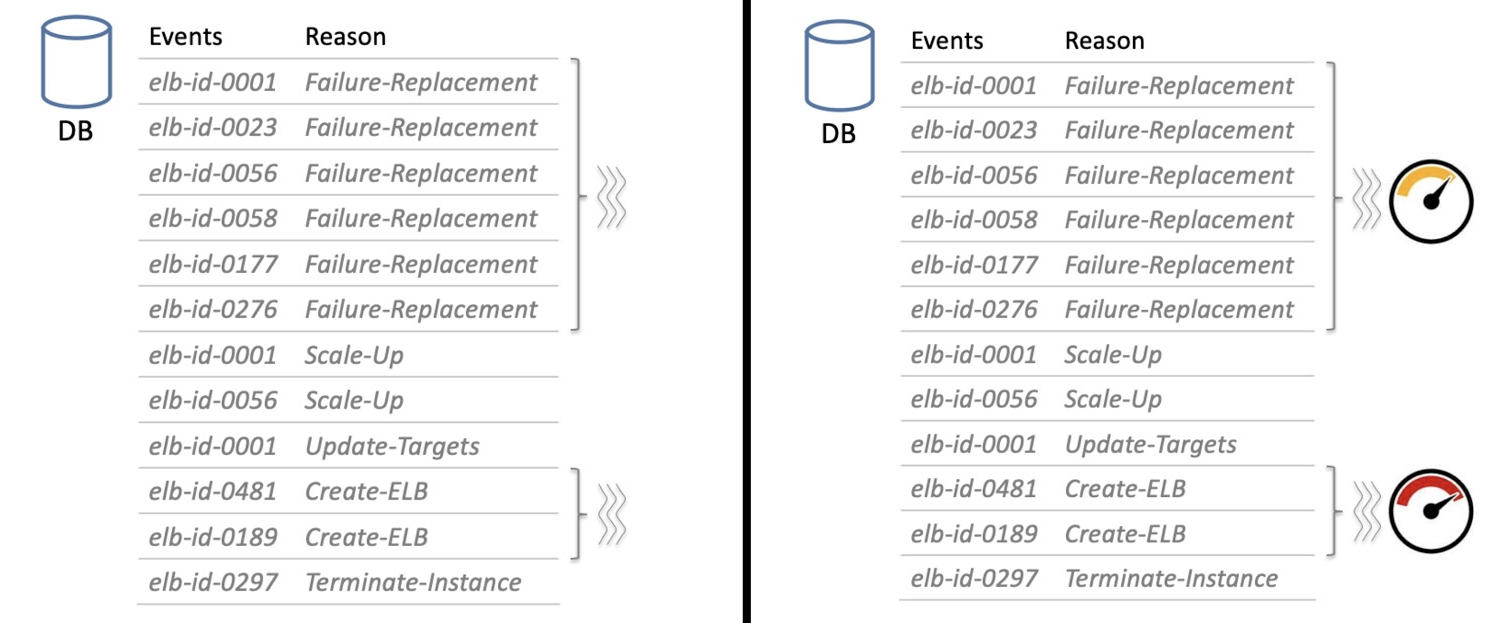
У нас есть десять расстроенных пользователей. Появляется одиннадцатый — он ничего не знает о проблеме, а просто хочет новый балансировщик. Если его запрос поставить вниз очереди на обработку, то, скорее всего, он не дождется. Пока другие процедуры обработки завершатся, время запроса закончится. Вместо десяти расстроенных пользователей у нас будет одиннадцать.
Чтобы этого не произошло, мы приоритезируем некоторые запросы — ставим наверх очереди, например, запросы о создании новых ресурсов. При массовом сбое относительно малое количество таких запросов никак не скажется на времени восстановления ресурсов других заказчиков. Но в процессе восстановления будем сдерживать число пользователей, вовлеченных в проблему.
Постоянная работа
Реакция на сообщения о проблеме — это запуск процедур восстановления, в частности, работа с DNS. Массовые сбои это огромные пиковые нагрузки на Control plane. Второй паттерн помогает Control plane быть стабильнее и предсказуемее в такой ситуации.

Мы используем подход, который называется Constant work — постоянная работа.

Например, DNS можно сделать чуть умнее: он будет постоянно проверять инстансы балансировщика, живые они или нет. Результатом каждый раз будет bitmap: инстанс отвечает — 1, мёртвый — 0.
DNS проверяет инстансы раз в несколько секунд, независимо от того, восстанавливается ли система после массового сбоя или работает в штатном режиме. Он выполняет одну и ту же работу — никаких пиков, всё предсказуемо и стабильно.
Другой упрощенный пример: мы хотим поменять конфигурацию на большом флоте. В нашей терминологии флот — это группа виртуальных машин, которые вместе выполняют какую-то работу.

Помещаем изменения конфигурации в S3-бакет, и каждые 10 секунд (для примера) пушим всю эту конфигурацию на наш флот виртуальных машин. Два важных момента.
- Делаем это регулярно и никогда не нарушаем правило. Если выбрали отрезок в 10 секунд, то пушим только так, независимо от ситуации.
- Отдаем всегда всю конфигурацию, независимо от того, изменилась она или нет. Data plane (виртуальные машины) сами принимают решение, что с этим делать. Мы не пушим дельту. Она может стать очень большой при массовых сбоях или изменениях. Потенциально это может внести нестабильность и непредсказуемость.
Когда выполняем какую-то постоянную работу, мы за это больше платим. Например, 100 виртуальных машин запрашивают конфигурацию каждую секунду. Это стоит примерно 1200$ в год. Эта сумма принципиально меньше зарплаты программиста, которому мы можем поручить разработку Control plane с классическим подходом — реакцией на сбой и распространением только изменений конфигурации.
Если каждые несколько секунд менять конфигурацию, как в примере, то это медленно. Но во многих случаях изменение конфигурации или запуск сервисов занимают минуты — несколько секунд ничего не решают.
Секунды важны для сервисов, в которых конфигурация должна меняться мгновенно, например, при изменение настроек VPC. Здесь «постоянная работа» неприменима. Это лишь паттерн, а не правило. Если в вашем случае это не работает — не применяйте.
Предварительное масштабирование
В нашем примере при падении инстанса балансировщика, второй выживший инстанс практически сразу получает удвоение нагрузки и начинает масштабироваться. При массовом сбое это съедает огромное количество ресурсов. Третий паттерн помогает этот процесс контролировать — масштабироваться заранее.
В случае двух зон доступности масштабируемся при утилизации меньше 50%.

Если все сделать заранее, то при сбое выжившие инстансы балансировщика уже готовы принять удвоенный трафик.
Раньше мы масштабировались лишь при высокой утилизации, например, 80%, а сейчас при 45%. Система простаивает большую часть времени и становится дороже. Но мы готовы с этим мириться и активно используем паттерн, потому что это страховка. За страховку приходится платить, но при серьезных неприятностях выигрыш покрывает все расходы. Если решите использовать паттерн, посчитайте все риски и цену заранее.
Ячеистая архитектура
Существует два способа строить и масштабировать сервисы: монолит и ячеистая структура (cell-based).

Монолит развивается и растет как единый большой контейнер. Мы добавляем ресурсы, система распухает, мы упираемся в разные лимиты, линейные характеристики становятся нелинейными и выходят в насыщение, а «blast radius» системы — вся система целиком.
Если монолит плохо протестирован, повышается вероятность возникновения проблем-сюрпризов — «unknown unknowns». Но большой монолит нельзя полноценно тестировать. Иногда для этого придется построить отдельную зону доступности, например, для популярного сервиса, который строится как монолит в рамках зоны доступности (это много дата-центров). Кроме того, что надо как-то создать огромную тестовую нагрузку, которая похожа на настоящую, это невозможно с финансовой точки зрения.
Поэтому в большинстве случаев мы используем ячеистую архитектуру — конфигурацию, в которой система строится из ячеек фиксированного размера. Добавляя ячейки, мы её масштабируем.
Ячеистая архитектура популярна в облаке AWS. Она помогает изолировать сбои и уменьшить «blast radius» до одной или нескольких ячеек. Мы можем полноценно тестировать ячейки среднего размера, это серьезно снижает риски.
Подобный подход используют в судостроении: корпус корабля или судна разделяют перегородками на отсеки. В случае пробоины затапливается один или несколько отсеков, но корабль не тонет. Да, Титанику это не помогло, но с и проблемами-айсбергами мы сталкиваемся очень редко.
Проиллюстрирую применение ячеистого подхода на примере сервиса Simple Shapes Service. Это не сервис AWS, я его сам придумал. Это набор простых API для работы с простыми геометрическими фигурами. Можно создать экземпляр геометрической фигуры, запросить тип фигуры по ее id, или сосчитать все экземпляры заданного типа. Например, на запрос
put(triangle) создается объект «треугольник» с некоторым id. getShape(id) возвращает тип «треугольник», «круг» или «ромб».
Чтобы сервис сделать облачным, его должны одновременно использовать различные пользователи. Сделаем его мультитенантным.

Дальше нужно придумать способ партиционировать — разделять фигуры по ячейкам. Есть несколько вариантов выбора partition key. Самый простой — по геометрической фигуре: все ромбы в первую ячейку, круги во вторую, треугольники в третью.
У этого способа есть плюсы и минусы.
- Если кругов заметно меньше, чем других фигур, то соответствующая ячейка останется недоутилизированной (неравномерное распределение).
- Некоторые API-запросы реализовывать легко. Например, считая все объекты во второй ячейке, найдем количество кругов в системе.
- Другие запросы сделать сложнее. Например, чтобы найти по id геометрическую фигуру, придется пройтись по всем ячейкам.
Второй способ — использовать id объектов по диапазонам: первая тысяча объектов в первую ячейку, вторая — во вторую. Так распределение равномернее, но зато есть другие сложности. Например, чтобы подсчитать все треугольники, нужно использовать метод
scatter/gather: распределяем запросы в каждую ячейку, она подсчитывает внутри себя треугольники, потом собирает ответы, суммирует и выдаёт результат.Третий способ — разделение по тенантам (пользователям). Здесь мы сталкиваемся с классической проблемой. В облаке обычно очень много «маленьких» пользователей, которые что-то пробуют и практически не нагружают сервис. При этом есть пользователи-мастодонты. Их мало, но они потребляют огромное количество ресурсов. Такие пользователи никогда не влезут ни в какую ячейку. Приходится придумывать хитрые способы, чтобы их распределять между множеством ячеек.

Идеального способа нет, каждый сервис индивидуален. Хорошая новость в том, что здесь работает житейская мудрость — колоть дрова удобнее вдоль по волокнам, а не рубить их поперек. Во многих сервисах эти «волокна» более-менее очевидны. Дальше можно экспериментировать и найти оптимальный partition key.
Ячейки между собой связаны (хотя и слабо). Поэтому должен быть связующий уровень. Часто его называют уровнем маршрутизации или маппирования. Он нужен чтобы понимать в какие ячейки передавать конкретные запросы. Этот уровень должен быть максимально простым. Постарайтесь не закладывать в него бизнес-логику.

Возникает вопрос размера ячеек: маленькие — плохо, большие — тоже плохо. Универсального совета нет — решайте по ситуации.
В облаке AWS мы используем логические и физические ячейки разных размеров. Есть региональные сервисы с большим размером ячейки, есть зональные сервисы, где ячейки поменьше.
Примечание. О микроячейках я рассказывал на Saint Highload++ Online в начале апреля этого года. Там я подробно обсуждал пример конкретного использования этого паттерна в нашем базовом сервисе Amazon EBS.
Мультитенантность
Когда пользователь запускает новый балансировщик, он получает инстансы в каждой зоне доступности. Независимо от того, используются ли ресурсы или нет, они выделены и принадлежат исключительно этому тенанту облака.
Для AWS, такой подход неэффективен, потому что утилизация ресурсов сервиса в среднем очень низкая. Это сказывается на стоимости. Для пользователей облака это не гибкое решение. Оно не может адаптироваться к быстро изменяющимся условиям, например, за минимальное время обеспечить ресурсами неожиданно возросшую нагрузку.

CLB был первым балансировщиком в облаке Amazon. Сервисы современнее используют мультитенантный подход, например NLB (Network Load Balancer). Основа, «движок» таких сетевых сервисов — HyperPlane. Это внутренний, невидимый конечным пользователям, огромный флот виртуальных машин (нод).

Преимущества мультитенантного подхода или пятого паттерна.
- Отказоустойчивость принципиально выше. В HyperPlane огромное количество нод уже запущены и стоят в ожидании нагрузки. Ноды знают состояние друг друга — при выходе из строя части ресурсов нагрузка мгновенно распределяется между оставшимися. Пользователи не замечают даже массовые сбои.
- Защита от пиковых нагрузок. Тенанты живут собственной жизнью и их нагрузки обычно не коррелируют друг с другом. Суммарная средняя нагрузка на HyperPlane достаточно сглаженная.
- Утилизация таких сервисов принципиально лучше. Поэтому, обеспечивая лучшие характеристики, они дешевле.
Звучит круто! Но у мультитенантного подхода есть недостатки. На рисунке флот HyperPlane с тремя тенантами (ромбики, кружочки и треугольники), которые распределены по всем нодам.

Здесь возникает классическая проблема «шумного соседа» (Noisy neighbor): деструктивное действие тенанта, который генерирует сверхвысокий или сбойный трафик, потенциально повлияет на всех пользователей.
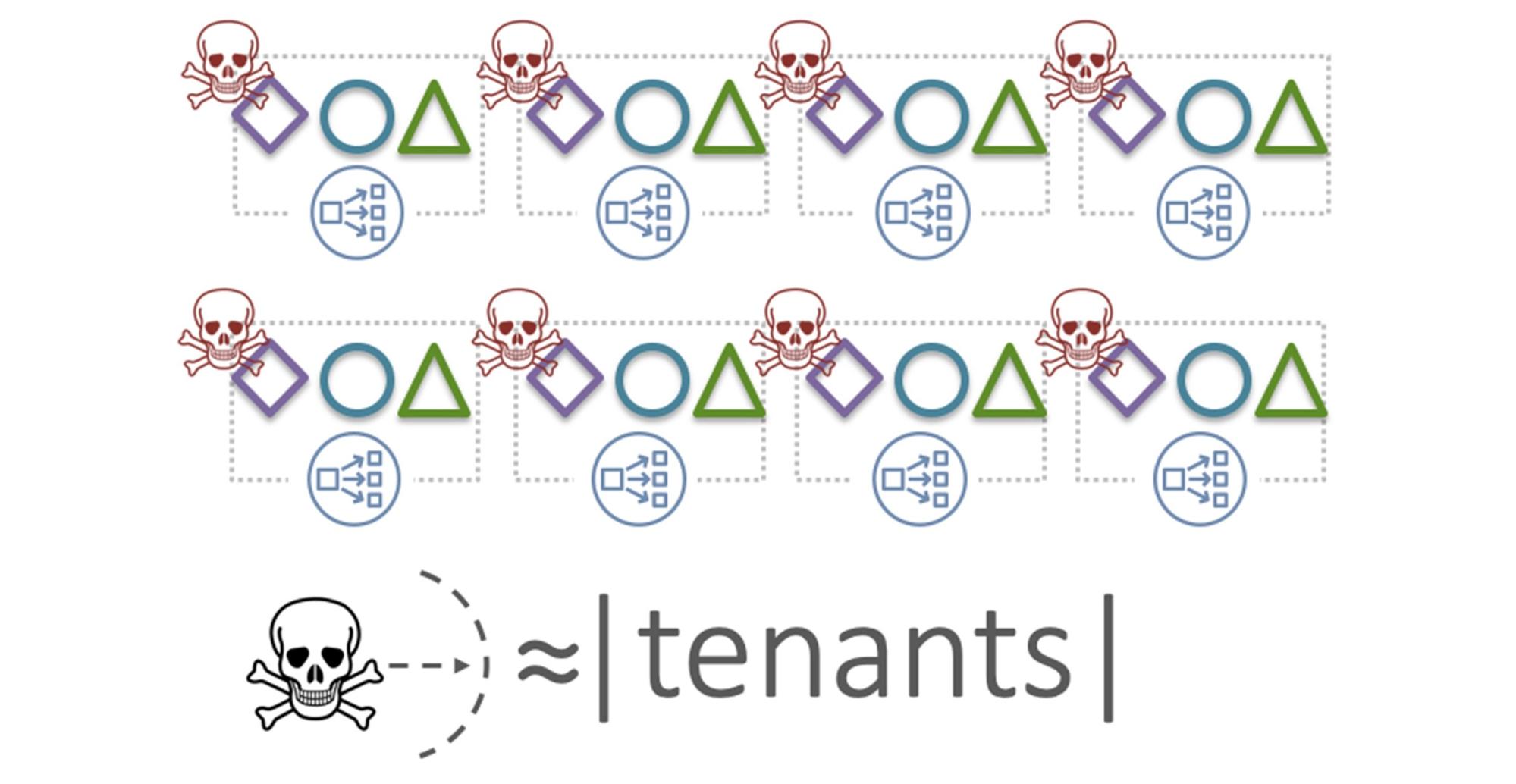
«Blast radius» в такой системе — это все тенанты. Вероятность возникновения деструктивного «шумного соседа» в реальной зоне доступности AWS не велика. Но мы всегда должны быть готовы к худшему. Защищаемся, используя ячеистый подход, — выделяем группы нод как ячейки. В этом контексте мы их называем шардами. Ячейки, шарды, партиции — здесь это одно и тоже.

В этом примере ромб, как «шумный сосед», повлияет лишь на одного тенанта — на треугольник. Но треугольнику будет очень больно. Чтобы сгладить эффект, применим шестой паттерн — перемешивающее шардирование.
Перемешивающее шардирование
Распределяем тенанты по нодам случайным образом. Например, ромб высаживается на 1, 3 и 6 ноды, а треугольник на 2, 6 и 8. У нас 8 нод и шард размера 3.

Здесь работает простая комбинаторика. С вероятностью 54% будет всего лишь одно пересечение между тенантами.

«Шумный сосед» повлияет лишь на одного тенанта, и не всей нагрузкой, а только 30 процентами.
Рассмотрим конфигурацию приближенную к реальной — 100 нод, размер шарда 5. С вероятностью 77% пересечений не будет вообще.
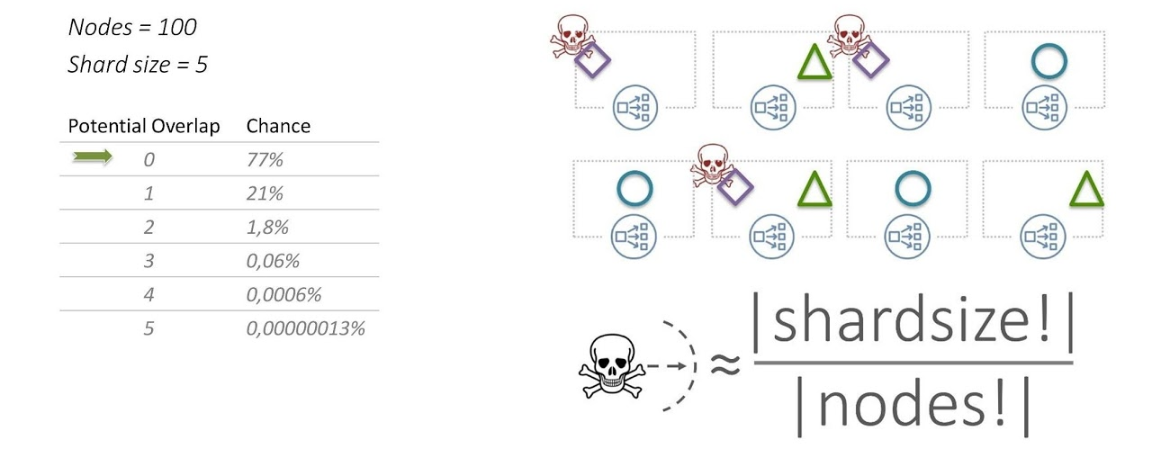
Перемешивающее шардирование (Shuffle sharding) позволяет принципиально уменьшить «blast radius». Этот подход используется во многих сервисах AWS.
«Маленький флот вызывает большой, а не наоборот»
Восстанавливаясь после массового сбоя, мы обновляем конфигурацию многих компонентов. Типичный вопрос при этом — пушить или пулить измененную конфигурацию? Кто инициатор изменений: источник, содержащий изменения конфигурации, или его потребители? Но эти вопросы неправильны. Правильный вопрос — какой флот больше?
Рассмотрим простую ситуацию: большой флот фронтенд виртуальных машин и какое-то количество бэкендов.

Используем ячеистый подход — группы фронтенд-инстансов будут работать с определёнными бэкендами. Для этого определить маршрутизацию — маппинг бэкендов и работающих с ними фронтендов.

Статическая маршрутизация не подходит. Алгоритмы хэширования плохо работают при массовых сбоях, когда нужно быстро менять бóльшую часть маршрутов. Поэтому лучше использовать динамическую маршрутизацию. Рядом с большими флотами фронтенд и бэкенд-инстансов ставим маленький сервис, который будет заниматься только маршрутизацией. Он будет знать и назначать бэкенд и фронтенд-маппинг в каждый момент времени.

Предположим, у нас произошел большой сбой, много фронтенд инстансов упало. Они начинают массово восстанавливаться и практически одновременно запрашивают конфигурацию маппинга у сервиса маршрутизации.
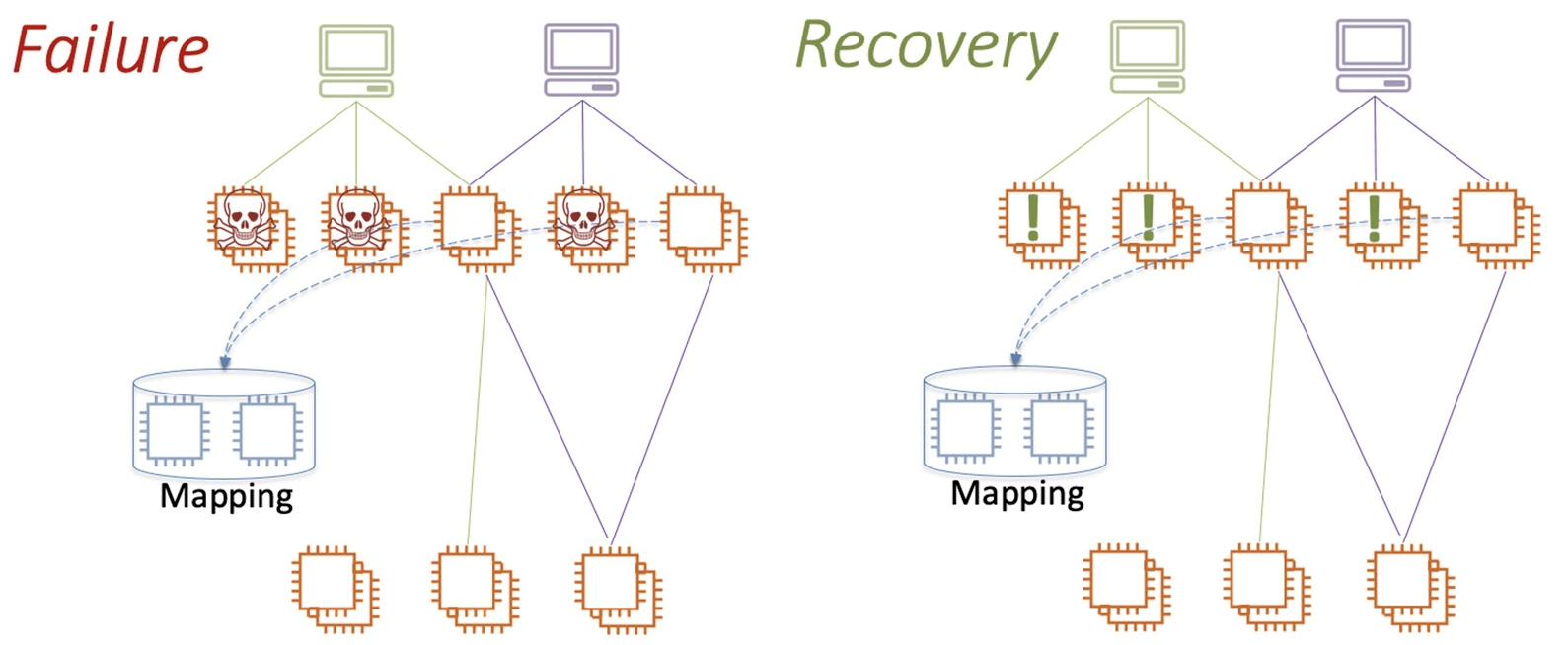
Маленький сервис маршрутизации бомбардируется огромным количеством запросов. Он не справится с нагрузкой, в лучшем случае деградирует, а в худшем — умрет.
Поэтому правильно не запрашивать изменения конфигурации у маленького сервиса, а наоборот — строить свою систему так, чтобы «малыш» сам инициировал изменения конфигурации в сторону большого флота инстансов.
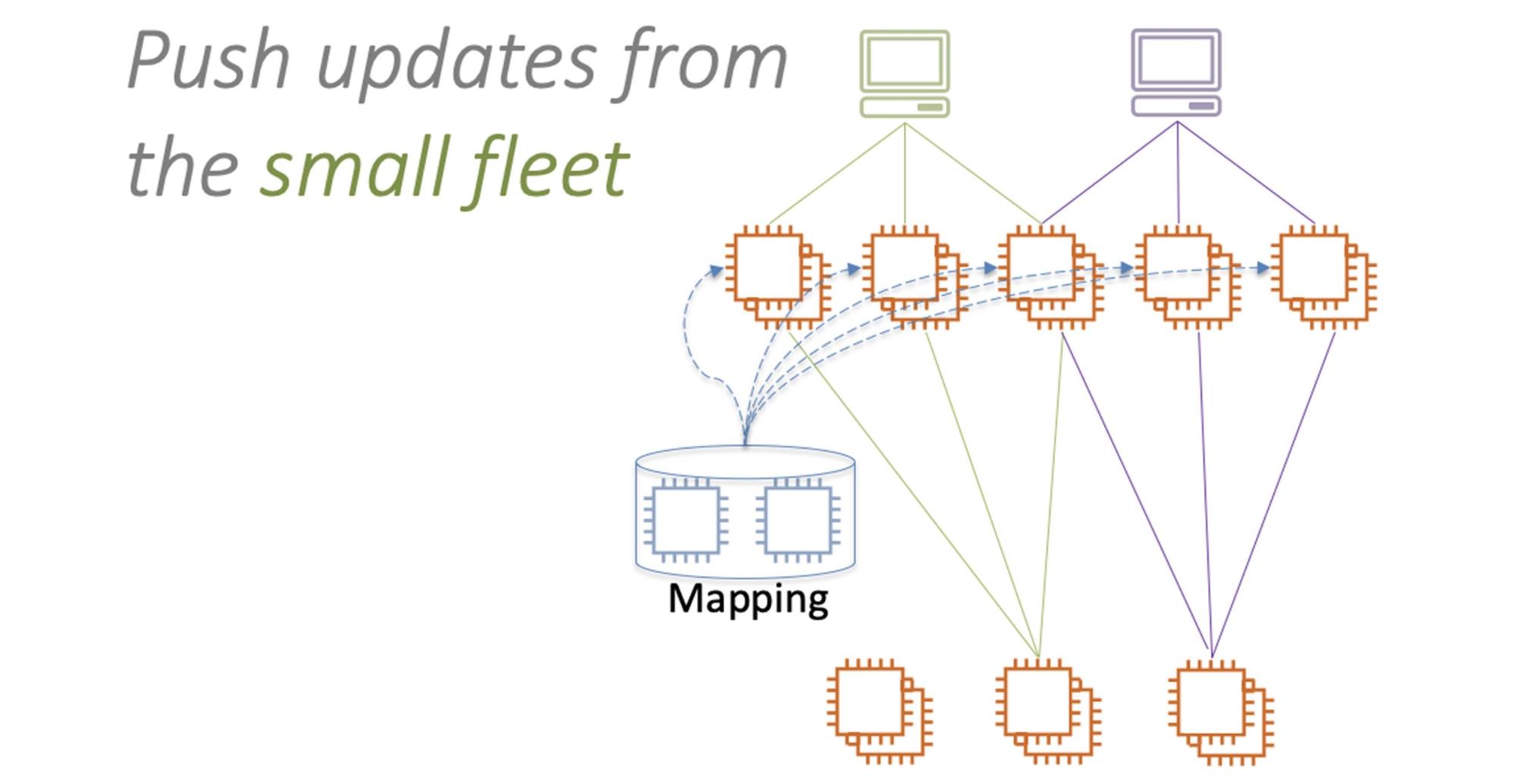
Используем паттерн постоянной работы. Маленький сервис маршрутизации будет раз в несколько секунд рассылать конфигурацию всем инстансам фронтенд флота. Он никогда не сможет перегрузить большой сервис. Седьмой паттерн помогает улучшить стабильность и отказоустойчивость.
Первые семь паттернов улучшают систему. Последний паттерн действует иначе.
Отбрасывание нагрузки
Ниже — классический график зависимости задержки от нагрузки. В правой части графика находится «колено», когда при сверхвысоких нагрузках даже маленькое увеличение приводит к значительному повышению задержки (latency).

В штатном режиме мы никогда не уводим наши сервисы в правую часть графика. Простой способ это контролировать — вовремя добавлять ресурсы. Но мы готовимся к любым неприятностям. Например, в правую часть графика мы можем переместиться восстанавливаясь после массового сбоя.
Наложим на график клиентский таймаут. Клиентом может быть кто угодно, например другой компонент внутри нашего же сервиса. Для простоты нарисуем график задержки 50 процентилем.

Здесь мы сталкиваемся с ситуацией, которая называется brownout. Возможно, вам знаком термин blackout, когда в городе отключается электричество. Brownout — это когда что-то работает, но настолько плохо и медленно, что, считай, и не работает совсем.
Посмотрим на коричневую зону brownout. Сервис получил запрос от клиента, обработал его и вернул результат. Однако, в половине случаев у клиентов уже закончился таймаут и результат никто не ждёт. В другой половине результат возвращается быстрее таймаута, но в медленной системе это занимает слишком много времени.
Мы столкнулись с двойной проблемой: мы уже перегружены и находимся в правой части графика, но при этом еще «греем воздух», выполняя массу бесполезной работы. Как этого избежать?
Найдём «колено» — точку перегиба на графике. Измерим или теоретически оценим.
Отбросим трафик, который заставляет нас уйти правее точки перегиба.

Мы должны просто игнорировать часть запросов. Мы их даже не пытаемся обработать, а сразу возвращаем клиенту ошибку. Даже при перегрузе мы можем позволить себе эту операцию — она «дешёвая». Запросы не выполняются, снижается общая доступность сервиса. Хотя и отброшенные запросы рано или поздно будут обработаны после одного или нескольких повторов (retry) со стороны клиентов.
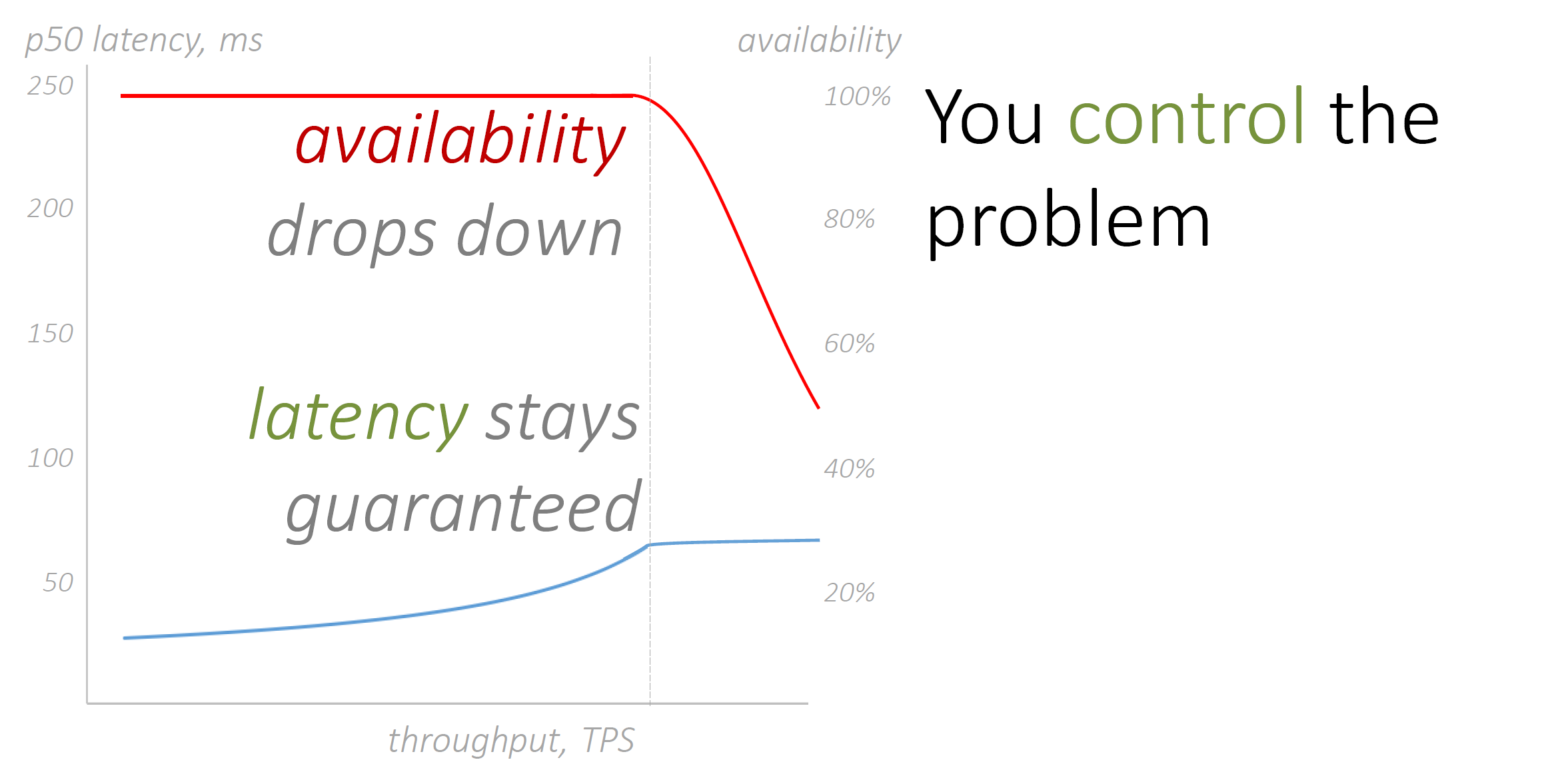
При этом другая часть запросов обрабатывается с гарантированно низкой задержкой. В итоге, мы не выполняем бесполезной работы, а ту что делаем — делаем хорошо.
Краткая выжимка паттернов проектирования систем на отказ
Изоляция и регулирование. Иногда имеет смысл приоритезировать определенные типы запросов. Например, при относительно небольшом объеме запросов на создание новых ресурсов их можно поставить в начало очереди. Важно, чтобы это не ущемляло других пользователей. При массовых сбоях пользователи, которые ожидают восстановления своих ресурсов, не почувствуют существенной разницы.
Постоянная работа. Уменьшаем или вообще исключаем переключения режимов сервисов. Один режим, который стабильно и постоянно работает, независимо от нештатных или рабочих ситуаций, принципиально улучшает стабильность и предсказуемость работы Control plane.
Предварительное масштабирование. Масштабируемся заранее при меньших значениях утилизации. За это придётся немного больше платить, но это страховка, которая окупается во время серьезных сбоев в системе.
Ячеистая архитектура. Много слабосвязанных ячеек предпочтительнее чем монолит. Ячеистый подход позволяет уменьшить «blast radius» и вероятность возникновения ошибок-сюрпризов.
Мультитенантный подход значительно улучшает утилизацию сервиса, снижает его стоимость и уменьшает «blast radius».
Перемешивающее шардирование. Это подход, который относится к мультитенантным сервисам. Он дополнительно позволяет контролировать «blast radius».
«Маленький флот вызывает большой, а не наоборот». Мы стараемся строить сервисы так, чтобы маленькие сервисы инициировали изменения больших конфигураций. Часто используем его совместно с паттерном постоянной нагрузки.
Отбрасывание нагрузки. В нештатных ситуациях стараемся выполнять только полезную работу, и делать её хорошо. Для этого отбрасываем часть нагрузки, с которой всё равно не справимся.
Василий Пантюхин — один из шести спикеров, которые помогли состояться Saint HighLoad++ Online. На мини-онлайн-конференции были доклады, Q&A-сессии, стихийные дискуссии, включения партнеров и розыгрыши. К большим онлайн-конференциям мая и июня мы доработаем платформу и разовьем преимущества онлайна. Например, что со всех-всех обсуждений остаются записи.
Следите за рассылкой или telegram-каналом @HighLoadChannel — будем держать в курсе новинок и таких больших новостей, как эта.
