
Мессенджер Авито – это:
Александр Емелин из компании Авито — автор проекта Centrifugo — open-source сервера real-time сообщений, где основной протокол передачи данных как раз WebSocket. Сервер используется в проектах Mail.Ru (в том числе в Юле), а также во внутренних проектах Badoo, ManyChat, частично Авито и за рубежом (например, Spot.im). Сейчас сервер базируется на доступной всем Go-разработчикам библиотеке Centrifuge.
На конференции Golang Conf 2019 Александр рассказал, как команда Авито решала проблемы при работе с WebSocket — как про детали, касающиеся Go в частности, так и вообще про работу с большим количеством постоянных соединений.

WebSocket — это полнодуплексное соединение между клиентом и сервером. Полнодуплексное означает, что в него можно писать с двух сторон и при этом не опасаться коллизий. WebSocket-протокол хорош, когда нужен быстрый обмен сообщениями между клиентом и сервером — например, чаты, multiplayer-игры, коллаборативные приложения, отображение котировок акций в реальном времени:

WebSocket соединение стартует с HTTP запроса версии 1.1, и это важно, так как HTTP/2 не имеет механизма Upgrade. Существуют, конечно, спецификации, которые позволяют стартовать WebSocket и работать через HTTP/2, мультиплексируя WebSocket-соединения внутри отдельных стримов HTTP/2, но из драфта они так и не вышли.
Итак, клиент по HTTP обменивается с сервером специализированными заголовками — так называемый апгрейд соединения, и в случае успешной операции остается чистая TCP-сессия, по которой передаются WebSocket-фреймы. То есть, WebSocket — это фреймовый протокол, при этом через фреймы можно передавать как текстовые, так и бинарные данные.
Почему вы вообще можете захотеть использовать WebSocket в своих приложениях:
Я считаю, что WebSocket-сервер должен решать в реальном мире такие задачи:
Понятно, что в зависимости от приложения важность того или иного пункта варьируется.
Прежде, чем на ваш сервер придут тысячи соединений по WebSocket, вам нужно затюнить операционную систему.
Лимит файловых дескрипторов
Наверное, это первое, на что все натыкаются. Каждое соединение отъедает файловый дескриптор у ОС. По умолчанию лимит не такой уж большой — от 256 до 1024 файловых дескрипторов. Хотите больше соединений — поднимайте лимит.
Совет: Ограничивайте максимальное количество соединений. Если вы знаете, что у вас ОС не позволит принимать соединений больше, чем, например, 65535 (такой лимит выставлен), то не принимайте в своем WebSocket-сервере соединений свыше этого лимита:
Иначе, когда у вас все пойдет плохо (а оно пойдет), вы не сможете даже зайти в pprof для анализа проблемы, потому что поход в pprof — это еще один файловый дескриптор, которого у вас нет. Вы также можете посмотреть в сторону netutil.LimitListener для этой задачи, но тогда pprof имеет смысл запускать на другом порту, отдельном от WebSocket сервера.
Ephemeral ports. Следующая проблема — это эфемерные порты. Обычно проблема появляется на связке load balancer – WebSocket-сервер и проявляется в том, что балансировщик не может открыть еще одно WebSocket-соединение до вашего WebSocket сервера, потому что у него исчерпались порты. Портов, с которых можно открыть соединение, по умолчанию не так много — около 10-15 тысяч. Плюс у сокета есть состояние time wait, когда его нельзя переиспользовать — смотрите, чтобы получить больше информации и узнать о способах решения.
Conntrack table. На каждой Linux-машине стоит iptables, в состав которого входит фреймворк netfilter. В нем каждое соединение трекается отдельной записью для контроля за тем, какие соединения установлены с сервером. Размер этой информации по умолчанию ограничен, как его затюнить — смотрите здесь.
Sysctl. Возможно, вы захотите затюнить sysctl — сетевой стек Linux — размер памяти, которое отводится под TCP-соединения и многое другое. Об этом можно прочитать, например, здесь.
Перейдем к уровню приложения (которое в нашем случае написано на Go). Что мы вообще знаем про WebSocket в Go:
Посмотрим на простой WebSocket-сервер:
Все начинается с того, что есть HTTP-обработчик. Как я сказал, WebSocket стартует с HTTP. Мы вызываем метод Upgrade:
Внутри Upgrade библиотека gorilla/websocket делает Hijack соединения, то есть берет его под свой контроль и отдает нам *websocket.Conn. На самом деле эта структура — wrapper над сетевым соединением.
Далее мы передаем настройки upgrader: ReadBufferSize и WriteBufferSize. Это размер буферов, которые будут использоваться для ввода-вывода, для записи и для чтения для того, чтобы уменьшить количество системных вызовов (syscalls). И эти буферы будут прибиты к вашему соединению железно, то есть они увеличивают размер потребления памяти. Мы к этому еще вернемся.
Обычно мы оборачиваем соединение в какую-то нашу структуру уровня приложения, назовем ее client:
В конце хендлера мы закрываем клиента и не забываем там же закрывать соединение:
Стартуем отдельную горутину на запись (кстати нужно помнить о том, что gorilla/websocket не поддерживает конкурентное чтение и конкурентную запись — единовременно только одна горутина может писать данные в соединение, и только одна горутина может читать из него):
Блокируем HTTP хендлер методом read (read вычитывает данные из WebSocket до тех пор, пока не случится ошибка. Как только случается ошибка, вы выходите из цикла read и HTTP-хендлер завершается):
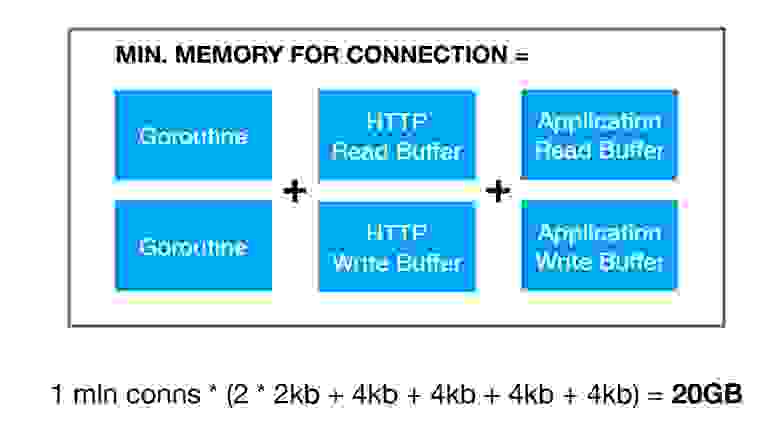
В работе WebSocket-соединения есть известная проблема: они требовательны к оперативной памяти. Эта тема поднималась не так давно в GO-community Сергеем Камардиным (Миллион WebSocket и pub/sub). Даже если тема WebSocket вам не интересна, рекомендую эту статью для ознакомления — там в каждой строчке инженерная мысль. Сергей говорит о том, что потребление памяти на WebSocket-соединение складывается из следующих факторов:
Если аппроксимировать, то на миллион соединений нужно минимум 20 GB RAM. Достаточно большая цифра, не правда ли?
Также стоит посмотреть выступление Going Infinite, handling 1 millions websockets connections in Go израильтянина Eran Yanay, который по сути взял идеи Сергея и переложил их на иностранный лад, дописав примеры.
Но на самом деле это самый плохой сценарий. Плюс оперативная память стоит относительно дешево, и современный сервер, например, в Avito имеет 378 GB RAM. Такой сервер позволяет держать много соединений, и в большинстве случаев первым лимитирующим фактором для приложения станет CPU, а не RAM. Тем не менее, экономить память, конечно, нужно, и ниже мы посмотрим на кое-какие трюки с Gorilla WebSocket, которые позволят сократить потребление RAM.
С gorilla/websocket мы можем переиспользовать буферы, которые аллоцируются HTTP-сервером стандартной библиотеки. Для этого мы ReadBufferSize и WriteBufferSize передаем нулями:
Gorilla/websocket может переиспользовать буфер, используя Hijack соединения:
Если посмотреть внутрь функции Upgrade, то когда происходит Hijack, возвращается объект bufio.ReadWriter, который содержит именно те буферы, которые HTTP-сервер аллоцировал для обработки изначального запроса:
При всем этом у нас все равно остаются две горутины, а буферы прибиты к соединениям.
Библиотека от Сергея Камардина позволяет отойти от этих проблем и сделать две оптимизации:
Кстати от буфера, прибитого на чтение к WebSocket-соединениям, может помочь избавиться issue на GitHub в репозитории Go: #15735 net: add mechanism to wait for readability on a TCPConn (правда, движения по ней в последнее время нет). Как только она закроется, у нас будет возможность буферы переиспользовать.
От Write Buffer Pool уже сейчас в gorilla/websocket мы можем избавиться, используя sync.Pool в upgrader. Тогда буферы на запись будут переиспользоваться:
Есть еще один трюк, который со стандартной библиотекой Go позволит сократить потребление памяти — мы даем поработать GC:
Это значит, что в последний момент, когда происходит чтение, мы начинаем читать в отдельной горутине, и тем самым HTTP-хендлер завершается:
Обратите внимание, что мы используем буферы 1024, потому что на самом деле те буферы, которые использует стандартная библиотека — это 4 Кб на чтение и на запись. Но у WebSocket-приложений сообщения обычно гораздо меньше, поэтому мы можем использовать буферы поменьше.
Как только HTTP-хендлер завершается, мы даем возможность garbage collector прибрать за нами — убрать те объекты, на которые уже ссылки не нужны. Например, это профиль inuse_space, то есть памяти, потребляемой процессом, в случае, когда мы не стартовали читающую горутину в последний момент:

А это профиль, когда мы стартовали отдельную горутину:

Кажется, что разница видна невооруженным глазом. Но если подсветить, то именно столько объектов garbage collector получает возможность собрать:
Вы можете посмотреть больше примеров и цифр в этом репозитории. Такой техникой можно сэкономить до 40% оперативной памяти.
ОК, вы сделали так, как я сказал — стартанули работу с WebSocket-соединением в отдельных горутинах. Но при этом хендлер завершится и в этот момент контекст, который содержится в HTTP-запросе, отменится:

Вообще контекст проникает во все уголки нашей разработки. Кажется естественным, что можно взять и прокинуть контекст далее по стеку приложения — ведь он может содержать какие-то полезные данные, которые вы в него положили в рамках middleware. Скорее всего, вы захотите отменять тяжелые действия, которые у вас есть в WebSocket-сервере, основываясь на том, когда отменяется контекст. Кажется, что вы ожидаете, что контекст отменится, когда соединение закрывается.
В данном случае контекст закроется сразу, как только завершится HTTP-хендлер. Но на самом деле это не проблема. Мы можем воспользоваться крутой фичей Go — оборачивать интерфейсы и менять реализацию методов. Посмотрим на интерфейс Context:
Здесь нас в первую очередь интересует метод Done(), который у него есть. Нам нужно создать свой контекст:
Мы назвали его customCancelContext, и далее:
В этом методе Done() мы возвращаем как раз тот канал, закрытием которого управляем. Все, что нам нужно дальше сделать — создать такой контекст и прокинуть его по стеку нашей программы. Для других частей программы этот контекст будет все тем же интерфейсом context.Context, однако отменяться он будет тогда, когда нам нужно.
Перейдем к тому, что надо рассылать много сообщений. Тут я Америку не открою — вам нужно использовать эффективный формат сериализации. Выбор на самом деле большой, сами выбирайте:
Но помимо стандартных реализаций посмотрите также в сторону библиотек, которые генерируют код. Яркий пример — gogo/protobuf, который позволяет ускорить сериализацию protobuf и сам по себе достаточно быстрый (в 5 раз), потому что использует не модуль reflect, а кодогенерацию:

Правда, на данный момент использовать gogo/protobuf я бы не рекомендовал. Подобные библиотеки есть и для Json, думаю, вы их знаете — easyjson, ffjson, — и на этом можно много сэкономить.
Еще одна проблема, которую мы в мессенджере Авито успешно побороли — это инвалидация соединения. Вообще откуда эта проблема? Приходит WebSocket-соединение от пользователя. Оно устанавливается и может висеть неделю. Что может произойти? Пользователь может открыть несколько табов браузера и в одном из них разлогиниться. В админке могут заблокировать учетную запись пользователя за какое-то нарушение, а WebSocket-соединение продолжает жить. Какой тут может быть выход?
Не все пользователи могут подключиться по WebSocket даже сейчас. Проблема далеко не в том, что где-то все еще существуют старые браузеры (Internet Explorer 8, 9), которые не поддерживают WebSocket. Основные проблемы связаны с корпоративными пользователями. Работодатель ставит своим сотрудникам доверенный рутовый сертификат на компьютер, а далее имеет возможность перешифровывать TLS-трафик — даже TLS-трафик! — на своих прокси. Причем прокси режет WebSocket-соединение, намеренно или потому, что там старое ПО. Такие примеры сплошь и рядом (например, в банках).
Когда я работал в Mail.ru, был случай, когда браузерное расширение Adblock заблочило все WebSocket-соединения на домены и поддомены Mail.ru. Почему? Потому что мои коллеги рассылали через WebSocket-соединение рекламу. И нас спас тогда только HTTP-Fallback.
Самый простой способ добавить HTTP-Fallback в приложение на Go — это библиотека SockJS-Go, и на стороне браузера использовать SockJS client. SockJS-Go — это серверная реализация для клиента SockJS. Если нет соединения по WebSocket, то соединение будет установлено через один из HTTP-транспортов: XHR-streaming, Eventsource, XHR-polling и т.д. Недостаток — все эти транспорты однонаправленные (сервер -> клиент), поэтому для работы с SockJS в двунаправленном режиме и масштабировании на несколько серверов придется еще включать sticky сессии на балансере.
Понятно, что fallback можно реализовать и вручную – например, через long-polling. Это не так сложно сделать, и, если вы храните стрим сообщений в быстром хранилище, можно обойтись без sticky сессий (об этом мы еще поговорим далее).
Стоит упомянуть, что для общения между клиентом и сервером многие используют GRPC (правда в данный момент GRPC нельзя использовать из браузера без дополнительного прокси). В этом докладе мы GRPC обходим стороной, но для вашего сценария это может быть неплохим вариантом. Пока же для двустороннего общения клиента и сервера из браузера альтернатив WebSocket пока нет. Также при использовании WebSocket + Protobuf вы можете ожидать гораздо более низкое потребление CPU на сервере (смотрите статью про Centrifugo v2).
Интересной технологией, на которую стоит обратить внимание в будущем является WebTransport (начать знакомство можно здесь). Если коротко — это эффективная клиент-сервер коммуникация поверх QUIC или HTTP/3 (который базируется на QUIC). Сейчас это еще драфты, но с технологией уже можно поэкспериментировать. Из самого вкусного — у разработчиков появится возможность использовать UDP из браузера, что ранее было невозможно без WebRTC обвеса с его STUN, ICE и т.д.
Производительность — это не масштабируемость. Как бы мы ни оптимизировали приложение, ни тюнили ОС, сколько бы ни экономили на оперативной памяти, все равно настанет момент, когда нам нужно будет масштабировать WebSocket-сервер на несколько инстансов. Даже в плане отказоустойчивости нам все равно нужно иметь несколько серверов с самого начала. Например, если упал один, то соединения перетекут на другой.
Мы добавили WebSocket-серверов. Какая здесь основная проблема? Пользователи могут быть подключены к любому инстансу WebSocket-сервера, а мы в этот момент хотим отправить пользователю сообщение — что нам делать?

Наверное, первое, что приходит на ум — публиковать на все. Но это неудобно, потому что нужно знать обо всех инстансах нашего WebSocket-сервера, которые к тому же могут динамически меняться. Тут в дело вступает PUB/SUB брокер сообщений.
Центральный брокер работает по модели PUB/SUB: когда соединения приходят на WebSocket-сервера, они инициализируют подписку на свой персональный топик в брокере. Брокер знает о всех таких подписках, и когда вы делаете публикацию сообщения, вы делаете ее через брокера. В этот момент через механизм PUB/SUB сообщение долетает только до тех WebSocket-серверов, до которых оно должно долететь, где есть клиенты, реально заинтересованные в этом событии. Далее оно доставляется по WebSocket клиенту:

Про центральный PUB/SUB-брокер для масштабирования WebSocket рассказывается в большинстве статей. Однако конкретики нет. Часто говорят: «Ну, а для брокера используйте RabbitMQ или Redis», и на этом повествование завершается.
Я добавил больше конкретики в этот вопрос. Посмотрим, что нам нужно от брокера:
Он будет работать, пока у вас небольшая нагрузка. На каждое соединение вы создаете очередь. На самом деле это не масштабируется, когда появляется множество пользователей, когда большой коннект-дисконнект рейт, при этом вы часто делаете bind/unbind очереди. Например, когда я пришел в мессенджер Авито, там использовался RabbitMQ, и было 100 тысяч подключений. На 100 тысячах подключений RabbitMQ потреблял 70 CPU. Забегая вперед, мы заменили RabbitMQ на Redis, и получили 0,3 ядра CPU — в 200 раз лучше для нашей задачи!
Кажется вполне естественным попробовать Kafka для этого. Моё мнение, что это оверкилл для многих приложений, потому что Kafka сохраняет стрим на диск, а консьюмер Kafka работает по pull-модели, что может быть неэффективным, когда у вас миллионы топиков и вам надо пулить данные из всех. Kafka предпочитает более стабильную конфигурацию своих топиков, потому что в динамике, когда у вас появляется subscribe/unsubscribe, топики создаются и удаляются на лету, и кажется, что во многих случаях лучше с Kafka так не делать.
Это еще один кандидат, но мне сложно рассуждать о его преимуществах/недостатках, так как я с ним не работал. Возможно при условии использования in-memory очередей Pulsar может быть неплохим кандидатом.
Мне кажется, что Nats вы вполне можете использовать, если нужен unreliable at most once PUB/SUB. Это производительное решение, написанное на Go. Nats-streaming я бы не использовал, потому что посмотрел его код и в достаточно критичных для себя местах нашел todo, которые не имплементируют определенную логику при восстановлении сообщений. Для меня это показалось критичным.
Tarantool кажется хорошей альтернативой в качестве брокера, потому что он мега-производительный, у него есть LuaJIT на стороне сервера и можно гибко писать логику. С недавней версии он поддерживает пуш со стороны брокера в соединении.
Мы в мессенджере Авито остановились на Redis, потому что:
Тут есть несколько очевидных советов — если вы делаете центральный PUB/SUB брокер, то:
К брокерам мы еще вернемся. Поговорим о другой проблеме.
Массовый реконнект случается в тот момент, когда у вас сотни тысяч, миллионы пользователей онлайн подключены по WebSocket-соединению, а вы, например, деплоите свой WebSocket-сервер, выкатываете новую версию, или у вас релоадятся внешние балансеры. При этом соединения рвутся и лавина пользователей приходит к вам на бэкенд переподключаться. Причем они не просто хотят переустановить пересоединение, а еще и восстановить свое состояние, потому что WebSocket-приложения stateful как тот же мессенджер: я как пользователь хочу получить все сообщения, которые пропустил, пока отсутствовал:
Часто такая пиковая нагрузка — это большая проблема. Посмотрим, как с ней можно бороться с помощью нескольких техник:
Exponential backoff на клиенте. Первая, всем известная практика — это обязательный Exponential backoff на клиенте. Клиенты должны переподключаться с экспоненциально увеличивающимися интервалами.
Rate limiter на WebSocket-сервере. Если вы знаете, что у вас на бэкенде какой-то ресурс деградирует при конкурентном доступе, поставьте туда самый простейший bounded семафор и ограничьте конкурентный доступ. Делается на Go элементарно — канал с буфером, и все. Зато у вас не деградирует система. То, что пользователь, предположим, переключится чуть позже — обычно не так критично.
JWT-аутентификация как способ не нагружать бэкенд сессий. Часто происходит следующее. Приходит коннект на сервер, его нужно аутентифицировать, а аутентифицируете вы его через бэкенд сессий. Причем бэкенд сессий может быть развернут как локально, так и отдельно в виде сервиса. JSON Web Token позволяет избавиться от большой нагрузки на бэкенд сессий, потому что у JWT есть expiration time.
Когда к вам приходит пользователь и пытается аутентифицироваться, используя JWT, и он валиден, вы можете не ходить в ваш бэкенд сессий. Если вы разумно выберете время, через которое JWT истекают, то большая часть из них при реконнекте окажется валидной, и вы обрабатываете всё внутри процесса на Go:

Добивайтесь максимальной производительности соединений. У вас сотни тысяч пользователей приходят и хотят переподписаться. В этот момент вы точно хотите переподписать их как можно скорее. Это хорошо и вам, и пользователям. Например, в случае с Redis мы можем это делать, используя Redis пайплайнинг. Это отправка нескольких запросов Redis за один запрос. Мы это делаем и в Centrifugo, и мессенджере Авито. Мы используем пайплайнинг на полную в этот момент. С этим помогает техника Smart batching — паттерн, который позволяет из нескольких независимых источников горутин собирать запросы и делать один batch запрос:
У нас есть каналы, из которых приходит какая-то работа. Мы знаем, что эту работу эффективней выполнять пачками. Мы читаем из канала, записываем объект, который нам нужно обработать, в batch (например, в слайс):
Далее продолжаем вычитывать из этого канала данные до тех пор, пока batch не перерастет свой максимальный размер или пока в канале не останется данных:
Select в Go это позволяет сделать. В итоге копим batch:
На выходе у нас получается пачка объектов, с которыми мы можем работать, например, послать пайплайн запрос в Redis. Пример со smart-batching на play.golang.org. Также в моем репозитории на GitHub вы можете посмотреть, как Smart batching и пайплайнинг помогают во взаимодействии с Redis — там есть набор бенчмарков.
Кэш сообщений, чтобы убрать пиковую нагрузку с СУБД. Как я уже сказал, пользователи хотят восстановить свое состояние и не пропускать сообщения, которые были в момент реконнекта. Вы можете хранить стрим сообщений, которые опубликовали, в каком-то быстром и горячем кэше. Мы их храним в Redis в структуре данных LIST. Как вариант, начиная с Redis 5.0, можно использовать Redis STREAM. Происходит публикация, идет запрос в Redis. Там работает LUA процедура, которая нам позволяет атомарно, в один RTT, сделать следующее:

На самом деле Redis PUB/SUB — это at most once гарантия доставки. В мессенджере Авито и в Centrifugo мы дополнительно на уровне кода приложения нивелируем потери, сверяя номер входящего PUB/SUB сообщения с ожидаемым, а затем периодически синхронизируя позицию клиента с ожидаемой в случае долгого отсутствия сообщений из PUB/SUB. Если обнаружили потерю — закрываем соединение клиента, давая ему переподключиться и выполнить всю необходимую логику для восстановления состояния.
На таком стриме можно сделать и fallback для WebSocket. В мессенджере Авито мы так и делаем. У нас есть стрим таких сообщений для каждого топика, и когда наш пользователь приходит, мы используем HTTP polling для fallback, чтобы он забрал данные из этого стрима и отдал их клиенту. Как бонус от кэша сообщений на этом же механизме можно построить и long-polling.
Время ответа RPC при раскладке. Такой график мы наблюдали при раскладке нашего сервиса, когда у нас был RabbitMQ и 100 тысяч пользователей. Видно, что ничего хорошего:

Так стало, когда у нас появился Redis и уже 500 тысяч пользователей. Видно, что раскладка происходит совершенно бесшовно для наших клиентов, а время ответа «RPC-ручек» совсем не растет:

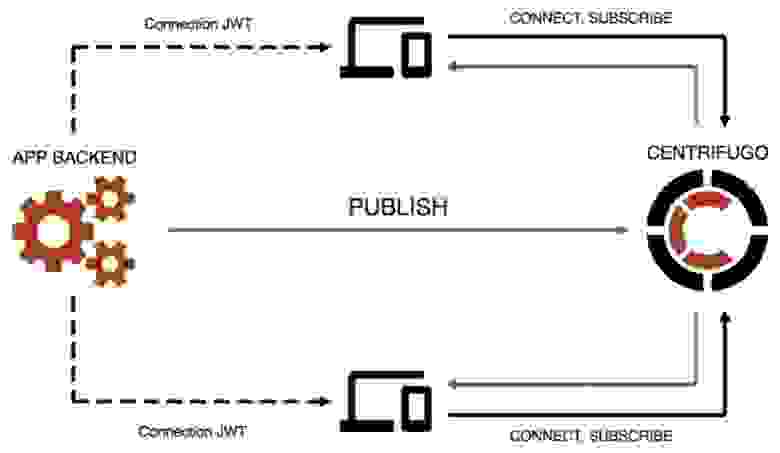
Многое из того, что я рассказывал, присутствует внутри Centrifugo. Если вам не хочется заморачиваться самим и писать, то можете его использовать. Это отдельно стоящий сервер, который принимает коннекты от пользователей и имеет API, чтобы отправлять сообщения пользователям. При этом он хорошо встраивается как в монолитную, так и в микросервисную архитектуру:
Как я говорил, основа сервера — библиотека Centrifuge, хотя это уже не совсем библиотека, а уже к фреймворку, потому что Centrifuge задумывается о масштабируемости за вас, имеет встроенный Redis и кэш сообщений. Плюс диктует клиент-серверный протокол. Так как Go-разработчики (и я в том числе) не очень любят фреймворки, то проще всего ее описать как альтернативу socket.io на Go — со всеми сопутствующими за и против.
Чтобы не быть голословным, я сделал демо-стенд на миллион WebSockets в Kubernetes, который использует библиотеку Centrifuge на сервере. На этом стенде я добился следующих цифр:
Хочу подчеркнуть, что это не нагрузочное тестирование, где мы доводим систему до полки (отказа), а просто демо-стенд. У меня было ограниченное количество железа и данные цифры — это далеко не потолок возможного масштабирования, поэтому был небольшой time-lapse. Что мы видим?
Number of connections быстро дорастает до миллиона. Мы ждем какое-то время, и видим, что система ведет себя стабильно. Затем начинаем публиковать сообщения (график Messages delivered) и доходим до 30 млн сообщений в минуту. При этом смотрим на серверный CPU, на память, и в том числе на брокер (Redis). В данном случае используется 5 инстансов Redis, мы шардируем Redis по имени топика (консистентное шардирование jump). Мы видим, что latency дорастает до 200 мс и там примерно останавливается, когда рейт сообщений достиг 30 млн:

Вот здесь можно посмотреть процесс в GIF-формате (3 Mb).
Чуть больше цифр о использованных ресурсах:
Чуть подробнее про стенд можно почитать здесь.
Итак, что вы можете использовать:
Как со мной связаться: GitHub, Telegram, Facebook.
- 12 m уникальных пользователей в месяц;
- Версии для всех современных платформ (Web, iOS, Android);
- Достаточно нагруженное приложение – около 800 тысяч подключений онлайн по WebSocket (основной протокол общения с пользователями).
Александр Емелин из компании Авито — автор проекта Centrifugo — open-source сервера real-time сообщений, где основной протокол передачи данных как раз WebSocket. Сервер используется в проектах Mail.Ru (в том числе в Юле), а также во внутренних проектах Badoo, ManyChat, частично Авито и за рубежом (например, Spot.im). Сейчас сервер базируется на доступной всем Go-разработчикам библиотеке Centrifuge.
На конференции Golang Conf 2019 Александр рассказал, как команда Авито решала проблемы при работе с WebSocket — как про детали, касающиеся Go в частности, так и вообще про работу с большим количеством постоянных соединений.

Что такое WebSocket
WebSocket — это полнодуплексное соединение между клиентом и сервером. Полнодуплексное означает, что в него можно писать с двух сторон и при этом не опасаться коллизий. WebSocket-протокол хорош, когда нужен быстрый обмен сообщениями между клиентом и сервером — например, чаты, multiplayer-игры, коллаборативные приложения, отображение котировок акций в реальном времени:
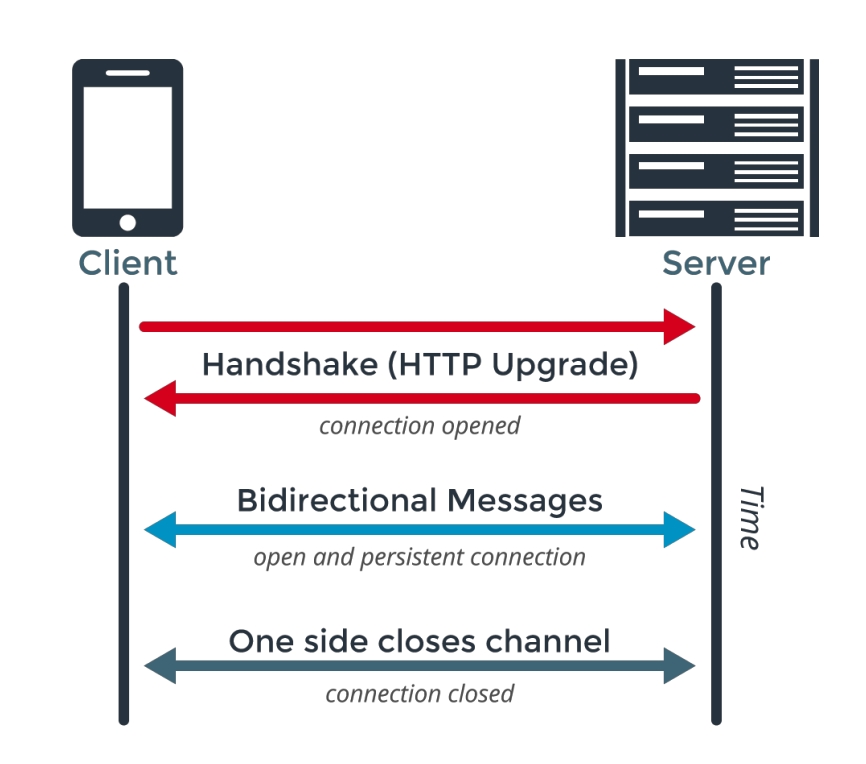
WebSocket соединение стартует с HTTP запроса версии 1.1, и это важно, так как HTTP/2 не имеет механизма Upgrade. Существуют, конечно, спецификации, которые позволяют стартовать WebSocket и работать через HTTP/2, мультиплексируя WebSocket-соединения внутри отдельных стримов HTTP/2, но из драфта они так и не вышли.
Итак, клиент по HTTP обменивается с сервером специализированными заголовками — так называемый апгрейд соединения, и в случае успешной операции остается чистая TCP-сессия, по которой передаются WebSocket-фреймы. То есть, WebSocket — это фреймовый протокол, при этом через фреймы можно передавать как текстовые, так и бинарные данные.
Почему WebSocket
Почему вы вообще можете захотеть использовать WebSocket в своих приложениях:
- Это достаточно простой протокол. Но дьявол, как известно, в деталях – например, известный питонист Армин Ронахер в своей статье рассказывает о некоторых неочевидных переусложнениях WebSocket-протокола.
- WebSocket работает на всех современных платформах и, что немаловажно, в браузере. Часто это становится решающим фактором, чтобы его выбрать как основной транспорт (ниже я расскажу чуть больше об альтернативах)
- У WebSocket небольшой оверхед по сравнению с чистой TCP-сессией, то есть фрейминг WebSocket-протокола добавляет всего от 2 до 8 байт к вашим данным — смотрите исследование на эту тему.
Задачи WebSocket-сервера
Я считаю, что WebSocket-сервер должен решать в реальном мире такие задачи:
- Держать большое количество соединений;
- Отправлять большое количество сообщений;
- Обеспечивать fallback WebSocket-соединения. Но даже сейчас не все пользователи могут соединиться по протоколу WebSocket. Мы об этом сегодня поговорим.
- Аутентификация соединений, причем как мы увидим ниже, WebSocket-приложения обладают своей спецификой.
- Инвалидация соединений (иначе соединение может быть установлено один раз и висеть неделями).
- Переживать массовый реконнект — WebSocket-приложения отличаются от стандартных HTTP-серверов тем, что у вас масса постоянных соединений: не stateful-запросы, а stateful-приложения. Также есть проблема массового реконнекта от тысяч, сотен тысяч, миллионов пользователей.
- Не терять сообщения при реконнекте. Если в чате/мессенджере потеряется сообщение при реконнекте, пользователи счастливы не будут. Часто восстанавливают состояние из основной СУБД приложения, но мы посмотрим на некоторые нюансы.
Понятно, что в зависимости от приложения важность того или иного пункта варьируется.
Тюнинг ОС — основные моменты
Прежде, чем на ваш сервер придут тысячи соединений по WebSocket, вам нужно затюнить операционную систему.
Лимит файловых дескрипторов
Наверное, это первое, на что все натыкаются. Каждое соединение отъедает файловый дескриптор у ОС. По умолчанию лимит не такой уж большой — от 256 до 1024 файловых дескрипторов. Хотите больше соединений — поднимайте лимит.
Совет: Ограничивайте максимальное количество соединений. Если вы знаете, что у вас ОС не позволит принимать соединений больше, чем, например, 65535 (такой лимит выставлен), то не принимайте в своем WebSocket-сервере соединений свыше этого лимита:
// ulimit -n == 65535
if conns.Len() >= 65500 {
return errors.New("connection limit reached")
}
conns.Add(conn)Иначе, когда у вас все пойдет плохо (а оно пойдет), вы не сможете даже зайти в pprof для анализа проблемы, потому что поход в pprof — это еще один файловый дескриптор, которого у вас нет. Вы также можете посмотреть в сторону netutil.LimitListener для этой задачи, но тогда pprof имеет смысл запускать на другом порту, отдельном от WebSocket сервера.
Ephemeral ports. Следующая проблема — это эфемерные порты. Обычно проблема появляется на связке load balancer – WebSocket-сервер и проявляется в том, что балансировщик не может открыть еще одно WebSocket-соединение до вашего WebSocket сервера, потому что у него исчерпались порты. Портов, с которых можно открыть соединение, по умолчанию не так много — около 10-15 тысяч. Плюс у сокета есть состояние time wait, когда его нельзя переиспользовать — смотрите, чтобы получить больше информации и узнать о способах решения.
Conntrack table. На каждой Linux-машине стоит iptables, в состав которого входит фреймворк netfilter. В нем каждое соединение трекается отдельной записью для контроля за тем, какие соединения установлены с сервером. Размер этой информации по умолчанию ограничен, как его затюнить — смотрите здесь.
Sysctl. Возможно, вы захотите затюнить sysctl — сетевой стек Linux — размер памяти, которое отводится под TCP-соединения и многое другое. Об этом можно прочитать, например, здесь.
Что мы знаем о WebSocket в Go
Перейдем к уровню приложения (которое в нашем случае написано на Go). Что мы вообще знаем про WebSocket в Go:
- Пакет websocket считается deprecated — использовать его не рекомендуется.
- Стандартом де-факто является пакет Gorilla Websocket — практически все WebSocket-приложения на Go, которые сейчас есть, используют его для работы с WebSocket. Большинство моих примеров будут основаны именно на нём.
- Библиотека от Сергея Камардина дает возможность делать некоторые оптимизации (в основном касающиеся эффективного использования оперативной памяти и оптимизаций аллокаций памяти при апгрейде соединения), на которые gorilla/websocket не способна.
- Также есть библиотека от Anmol Sethi (nhooyr). Автор активен и даже сделал попытку мейнтейнить gorilla/websocket, чтобы новых пользователей перенаправлять на свою библиотеку :) Из преимуществ этой библиотеки можно отметить goroutine-safe API, встроенную поддержку graceful закрытия WebSocket-соединения (что достаточно нетривиально сделать с Gorilla WebSocket). Сейчас темп разработки этой библиотеки замедлился, а несколько неприятных багов в issue-трекере осталось. И несмотря на заявления автора о том, что пакет имеет внутри некоторые оптимизации — на моих бенчмарках Gorilla WebSocket давал более производительный результат.
Простой WebSocket сервер
Посмотрим на простой WebSocket-сервер:
var upgrader = websocket.Upgrader{
ReadBufferSize: 1024,
WriteBufferSize: 1024,
}
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
conn, _ := upgrader.Upgrade(w, r, nil)
client := newClient(conn)
defer client.Close()
go client.write()
client.read()
}Все начинается с того, что есть HTTP-обработчик. Как я сказал, WebSocket стартует с HTTP. Мы вызываем метод Upgrade:
conn, _ := upgrader.Upgrade(w, r, nil)Внутри Upgrade библиотека gorilla/websocket делает Hijack соединения, то есть берет его под свой контроль и отдает нам *websocket.Conn. На самом деле эта структура — wrapper над сетевым соединением.
Далее мы передаем настройки upgrader: ReadBufferSize и WriteBufferSize. Это размер буферов, которые будут использоваться для ввода-вывода, для записи и для чтения для того, чтобы уменьшить количество системных вызовов (syscalls). И эти буферы будут прибиты к вашему соединению железно, то есть они увеличивают размер потребления памяти. Мы к этому еще вернемся.
Обычно мы оборачиваем соединение в какую-то нашу структуру уровня приложения, назовем ее client:
client := newClient(conn)В конце хендлера мы закрываем клиента и не забываем там же закрывать соединение:
defer client.Close()Стартуем отдельную горутину на запись (кстати нужно помнить о том, что gorilla/websocket не поддерживает конкурентное чтение и конкурентную запись — единовременно только одна горутина может писать данные в соединение, и только одна горутина может читать из него):
go client.write()Блокируем HTTP хендлер методом read (read вычитывает данные из WebSocket до тех пор, пока не случится ошибка. Как только случается ошибка, вы выходите из цикла read и HTTP-хендлер завершается):
client.read()Оптимизации потребления RAM
Формула Камардина
В работе WebSocket-соединения есть известная проблема: они требовательны к оперативной памяти. Эта тема поднималась не так давно в GO-community Сергеем Камардиным (Миллион WebSocket и pub/sub). Даже если тема WebSocket вам не интересна, рекомендую эту статью для ознакомления — там в каждой строчке инженерная мысль. Сергей говорит о том, что потребление памяти на WebSocket-соединение складывается из следующих факторов:
- Две горутины (одна читает, другая пишет);
- HTTP-буферы на чтение и на запись от стандартной библиотеки Go, которая аллоцируется, потому что WebSocket-соединение начинается с HTTP;
- Буферы, которые мы в приложении используем для ввода-вывода.
Если аппроксимировать, то на миллион соединений нужно минимум 20 GB RAM. Достаточно большая цифра, не правда ли?

Также стоит посмотреть выступление Going Infinite, handling 1 millions websockets connections in Go израильтянина Eran Yanay, который по сути взял идеи Сергея и переложил их на иностранный лад, дописав примеры.
Но на самом деле это самый плохой сценарий. Плюс оперативная память стоит относительно дешево, и современный сервер, например, в Avito имеет 378 GB RAM. Такой сервер позволяет держать много соединений, и в большинстве случаев первым лимитирующим фактором для приложения станет CPU, а не RAM. Тем не менее, экономить память, конечно, нужно, и ниже мы посмотрим на кое-какие трюки с Gorilla WebSocket, которые позволят сократить потребление RAM.
Переиспользуем HTTP-буферы
С gorilla/websocket мы можем переиспользовать буферы, которые аллоцируются HTTP-сервером стандартной библиотеки. Для этого мы ReadBufferSize и WriteBufferSize передаем нулями:
var upgrader = websocket.Upgrader{
ReadBufferSize: 0,
WriteBufferSize: 0,
}
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
conn, _ := upgrader.Upgrade(w, r, nil)
client := newClient(conn)
defer client.Close()
go client.write()
client.read()
} Gorilla/websocket может переиспользовать буфер, используя Hijack соединения:
func Upgrade(w http.ResponseWriter, r *http.Request) (*websocket.Conn, error) {
hj, ok := w.(http.Hijacker)
if !ok {
http.Error(w, "error hijacking", http.StatusInternalServerError)
return
}
conn, bufrw, err := hj.Hijack()
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
...
}
Если посмотреть внутрь функции Upgrade, то когда происходит Hijack, возвращается объект bufio.ReadWriter, который содержит именно те буферы, которые HTTP-сервер аллоцировал для обработки изначального запроса:
conn, bufrw, err := hj.Hijack()При всем этом у нас все равно остаются две горутины, а буферы прибиты к соединениям.
Gobwas/ws: beyond std lib
Библиотека от Сергея Камардина позволяет отойти от этих проблем и сделать две оптимизации:
- Zero-copy upgrade. Мы убираем использование стандартного HTTP-сервера Go и сами парсим HTTP, при этом не аллоцируя дополнительной памяти.
- Возможность использовать epoll/kqueue (см. netpoll, gnet, evio, gaio), используя syscalls и минуя рантайм и Go netpoller. Тем самым можно даже отойти от двух горутин, одна из которых пишет, а другая читает. Также можно переиспользовать все буферы, о которых шла речь.
Кстати от буфера, прибитого на чтение к WebSocket-соединениям, может помочь избавиться issue на GitHub в репозитории Go: #15735 net: add mechanism to wait for readability on a TCPConn (правда, движения по ней в последнее время нет). Как только она закроется, у нас будет возможность буферы переиспользовать.
Write Buffer Pool
От Write Buffer Pool уже сейчас в gorilla/websocket мы можем избавиться, используя sync.Pool в upgrader. Тогда буферы на запись будут переиспользоваться:
var upgrader = websocket.Upgrader{
ReadBufferSize: 1024,
WriteBufferPool: &sync.Pool{},
}
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
conn, _ := upgrader.Upgrade(w, r, nil)
client := newClient(conn)
defer client.Close()
go client.write()
client.read()
}
Даем поработать GC
Есть еще один трюк, который со стандартной библиотекой Go позволит сократить потребление памяти — мы даем поработать GC:
var upgrader = websocket.Upgrader{
ReadBufferSize: 1024,
WriteBufferSize: 1024,
}
func (hub *Hub) ServeHTTP(w http.ResponseWriter, r *http.Request) {
conn, _ := upgrader.Upgrade(w, r, nil)
...
// Allow collection of memory referenced by the caller
// by doing all work in new goroutines.
go client.write()
go client.read()
} Это значит, что в последний момент, когда происходит чтение, мы начинаем читать в отдельной горутине, и тем самым HTTP-хендлер завершается:
go client.write()
go client.read()Обратите внимание, что мы используем буферы 1024, потому что на самом деле те буферы, которые использует стандартная библиотека — это 4 Кб на чтение и на запись. Но у WebSocket-приложений сообщения обычно гораздо меньше, поэтому мы можем использовать буферы поменьше.
Как только HTTP-хендлер завершается, мы даем возможность garbage collector прибрать за нами — убрать те объекты, на которые уже ссылки не нужны. Например, это профиль inuse_space, то есть памяти, потребляемой процессом, в случае, когда мы не стартовали читающую горутину в последний момент:

А это профиль, когда мы стартовали отдельную горутину:
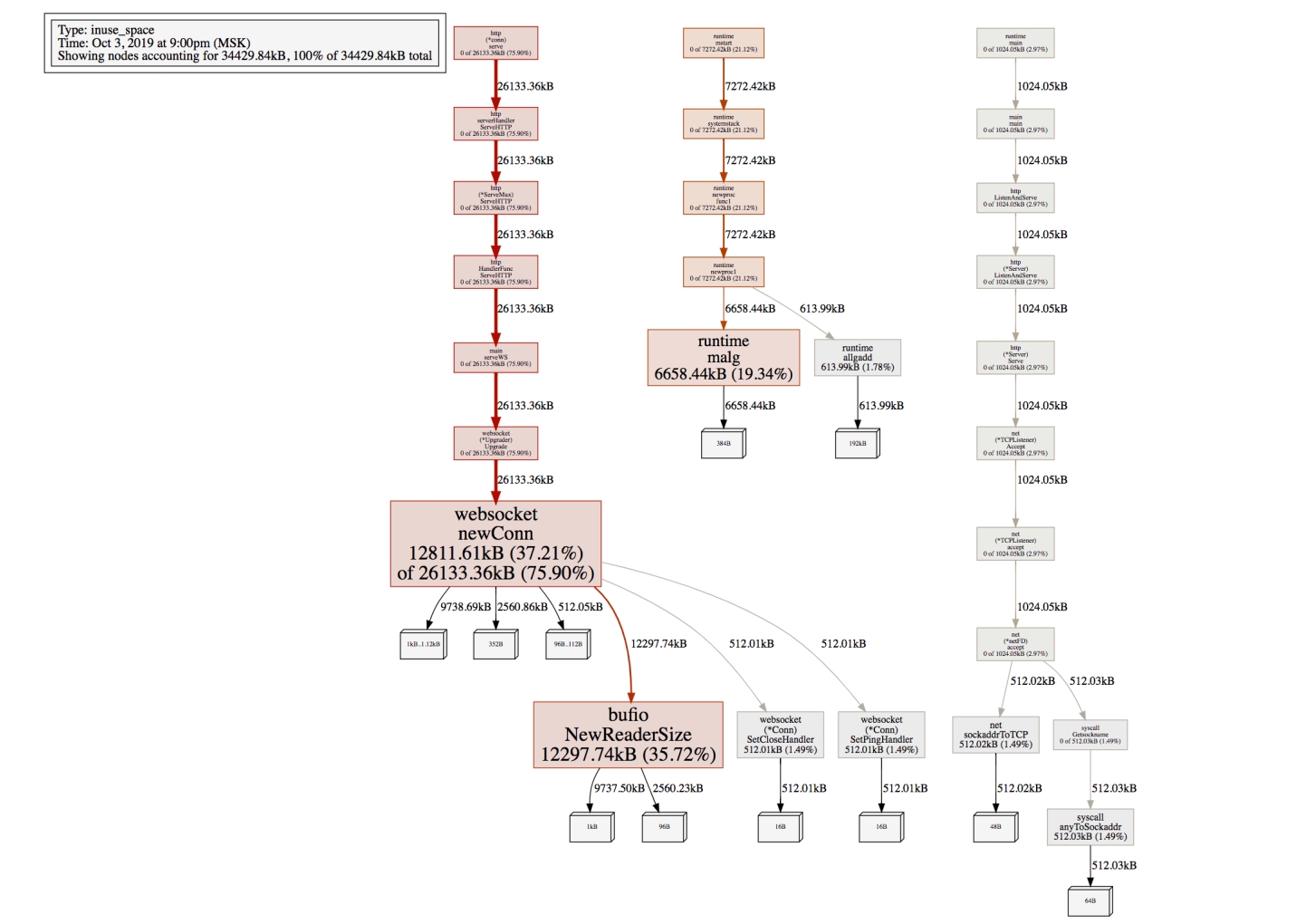
Кажется, что разница видна невооруженным глазом. Но если подсветить, то именно столько объектов garbage collector получает возможность собрать:
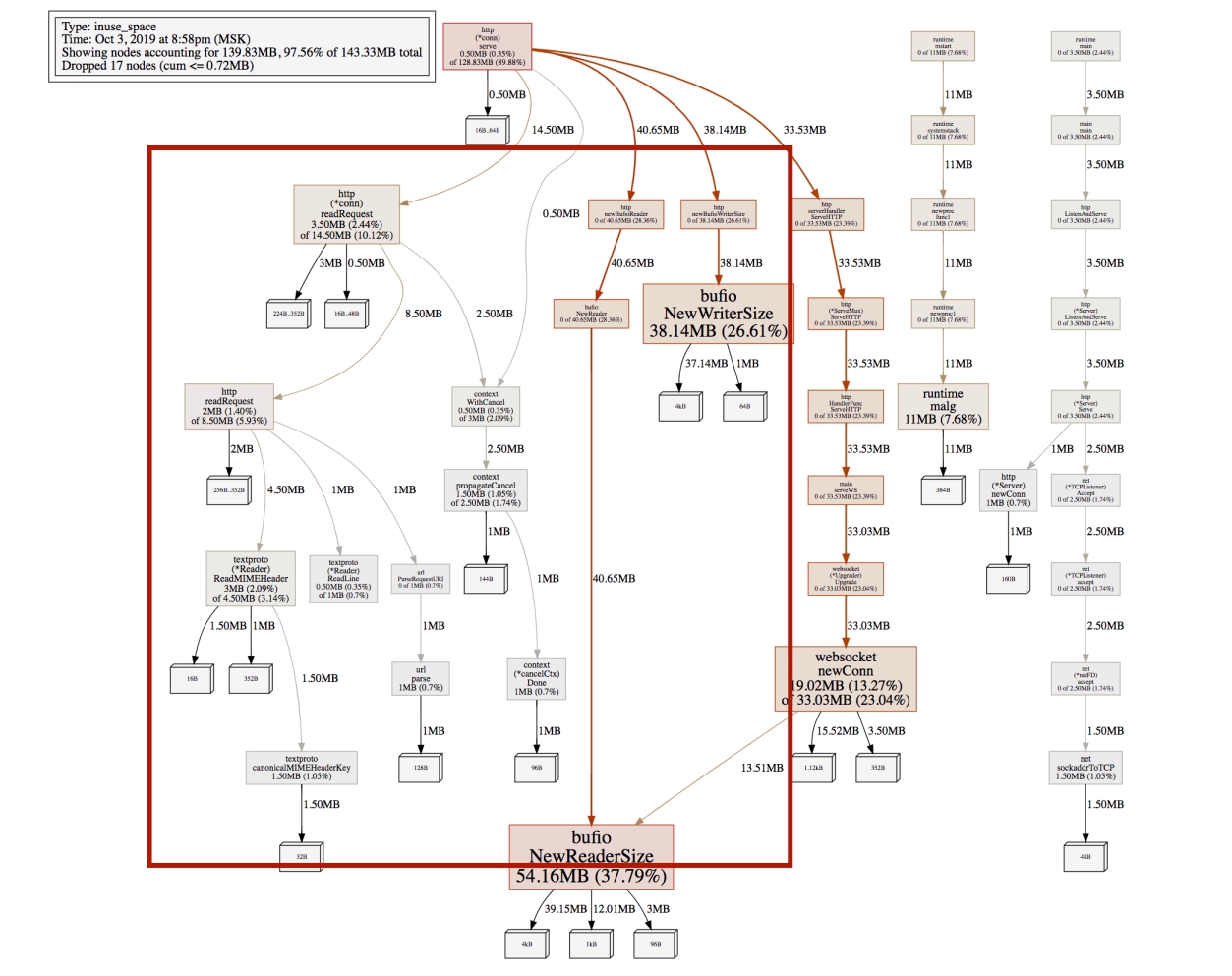
Вы можете посмотреть больше примеров и цифр в этом репозитории. Такой техникой можно сэкономить до 40% оперативной памяти.
Отмена сontext
ОК, вы сделали так, как я сказал — стартанули работу с WebSocket-соединением в отдельных горутинах. Но при этом хендлер завершится и в этот момент контекст, который содержится в HTTP-запросе, отменится:

Вообще контекст проникает во все уголки нашей разработки. Кажется естественным, что можно взять и прокинуть контекст далее по стеку приложения — ведь он может содержать какие-то полезные данные, которые вы в него положили в рамках middleware. Скорее всего, вы захотите отменять тяжелые действия, которые у вас есть в WebSocket-сервере, основываясь на том, когда отменяется контекст. Кажется, что вы ожидаете, что контекст отменится, когда соединение закрывается.
В данном случае контекст закроется сразу, как только завершится HTTP-хендлер. Но на самом деле это не проблема. Мы можем воспользоваться крутой фичей Go — оборачивать интерфейсы и менять реализацию методов. Посмотрим на интерфейс Context:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
Здесь нас в первую очередь интересует метод Done(), который у него есть. Нам нужно создать свой контекст:
type customCancelContext struct {
context.Context
ch <-chan struct{}
}
...
func (c customCancelContext) Done() <-chan struct{} {
return c.ch
}
func (c customCancelContext) Err() error {
select {
case <-c.ch:
return context.Canceled
default:
return nil
}
} Мы назвали его customCancelContext, и далее:
- Обернули изначальный контекст:
context.Context- Передали в него канал, который будет закрываться тогда, когда соединение реально закроется (мы сами это знаем, сами управляем):
ch <-chan struct{}- Переопределили метод Done():
func (c customCancelContext) Done() <-chan struct{} {
return c.ch
}В этом методе Done() мы возвращаем как раз тот канал, закрытием которого управляем. Все, что нам нужно дальше сделать — создать такой контекст и прокинуть его по стеку нашей программы. Для других частей программы этот контекст будет все тем же интерфейсом context.Context, однако отменяться он будет тогда, когда нам нужно.
Формат сериализации сообщений
Перейдем к тому, что надо рассылать много сообщений. Тут я Америку не открою — вам нужно использовать эффективный формат сериализации. Выбор на самом деле большой, сами выбирайте:
- JSON
- Protobuf
- Msgpack, CBOR
- Свой протокол
Но помимо стандартных реализаций посмотрите также в сторону библиотек, которые генерируют код. Яркий пример — gogo/protobuf, который позволяет ускорить сериализацию protobuf и сам по себе достаточно быстрый (в 5 раз), потому что использует не модуль reflect, а кодогенерацию:

Правда, на данный момент использовать gogo/protobuf я бы не рекомендовал. Подобные библиотеки есть и для Json, думаю, вы их знаете — easyjson, ffjson, — и на этом можно много сэкономить.
Инвалидация соединения
Еще одна проблема, которую мы в мессенджере Авито успешно побороли — это инвалидация соединения. Вообще откуда эта проблема? Приходит WebSocket-соединение от пользователя. Оно устанавливается и может висеть неделю. Что может произойти? Пользователь может открыть несколько табов браузера и в одном из них разлогиниться. В админке могут заблокировать учетную запись пользователя за какое-то нарушение, а WebSocket-соединение продолжает жить. Какой тут может быть выход?
- Push. Вы можете подписаться на события, если у вас есть какая-то шина данных. Например, у нас в Авито есть Kafka как шина данных. Мы подписались на такие события и отключаем WebSocket.
- Pull. Но если такой шины данных нет, можно просто периодически проверять, что WebSocket-соединение активно (периодическая валидация). Это дороже, но тут нужно найти trade-off между производительностью и тем интервалом, с которым вы проверяете каждое висящее соединение.
Fallback для WebSocket
Не все пользователи могут подключиться по WebSocket даже сейчас. Проблема далеко не в том, что где-то все еще существуют старые браузеры (Internet Explorer 8, 9), которые не поддерживают WebSocket. Основные проблемы связаны с корпоративными пользователями. Работодатель ставит своим сотрудникам доверенный рутовый сертификат на компьютер, а далее имеет возможность перешифровывать TLS-трафик — даже TLS-трафик! — на своих прокси. Причем прокси режет WebSocket-соединение, намеренно или потому, что там старое ПО. Такие примеры сплошь и рядом (например, в банках).
Когда я работал в Mail.ru, был случай, когда браузерное расширение Adblock заблочило все WebSocket-соединения на домены и поддомены Mail.ru. Почему? Потому что мои коллеги рассылали через WebSocket-соединение рекламу. И нас спас тогда только HTTP-Fallback.
Самый простой способ добавить HTTP-Fallback в приложение на Go — это библиотека SockJS-Go, и на стороне браузера использовать SockJS client. SockJS-Go — это серверная реализация для клиента SockJS. Если нет соединения по WebSocket, то соединение будет установлено через один из HTTP-транспортов: XHR-streaming, Eventsource, XHR-polling и т.д. Недостаток — все эти транспорты однонаправленные (сервер -> клиент), поэтому для работы с SockJS в двунаправленном режиме и масштабировании на несколько серверов придется еще включать sticky сессии на балансере.
Понятно, что fallback можно реализовать и вручную – например, через long-polling. Это не так сложно сделать, и, если вы храните стрим сообщений в быстром хранилище, можно обойтись без sticky сессий (об этом мы еще поговорим далее).
Стоит упомянуть, что для общения между клиентом и сервером многие используют GRPC (правда в данный момент GRPC нельзя использовать из браузера без дополнительного прокси). В этом докладе мы GRPC обходим стороной, но для вашего сценария это может быть неплохим вариантом. Пока же для двустороннего общения клиента и сервера из браузера альтернатив WebSocket пока нет. Также при использовании WebSocket + Protobuf вы можете ожидать гораздо более низкое потребление CPU на сервере (смотрите статью про Centrifugo v2).
Интересной технологией, на которую стоит обратить внимание в будущем является WebTransport (начать знакомство можно здесь). Если коротко — это эффективная клиент-сервер коммуникация поверх QUIC или HTTP/3 (который базируется на QUIC). Сейчас это еще драфты, но с технологией уже можно поэкспериментировать. Из самого вкусного — у разработчиков появится возможность использовать UDP из браузера, что ранее было невозможно без WebRTC обвеса с его STUN, ICE и т.д.
Performance is not scalability
Производительность — это не масштабируемость. Как бы мы ни оптимизировали приложение, ни тюнили ОС, сколько бы ни экономили на оперативной памяти, все равно настанет момент, когда нам нужно будет масштабировать WebSocket-сервер на несколько инстансов. Даже в плане отказоустойчивости нам все равно нужно иметь несколько серверов с самого начала. Например, если упал один, то соединения перетекут на другой.
Горизонтальное масштабирование
Мы добавили WebSocket-серверов. Какая здесь основная проблема? Пользователи могут быть подключены к любому инстансу WebSocket-сервера, а мы в этот момент хотим отправить пользователю сообщение — что нам делать?
Наверное, первое, что приходит на ум — публиковать на все. Но это неудобно, потому что нужно знать обо всех инстансах нашего WebSocket-сервера, которые к тому же могут динамически меняться. Тут в дело вступает PUB/SUB брокер сообщений.
Центральный брокер работает по модели PUB/SUB: когда соединения приходят на WebSocket-сервера, они инициализируют подписку на свой персональный топик в брокере. Брокер знает о всех таких подписках, и когда вы делаете публикацию сообщения, вы делаете ее через брокера. В этот момент через механизм PUB/SUB сообщение долетает только до тех WebSocket-серверов, до которых оно должно долететь, где есть клиенты, реально заинтересованные в этом событии. Далее оно доставляется по WebSocket клиенту:
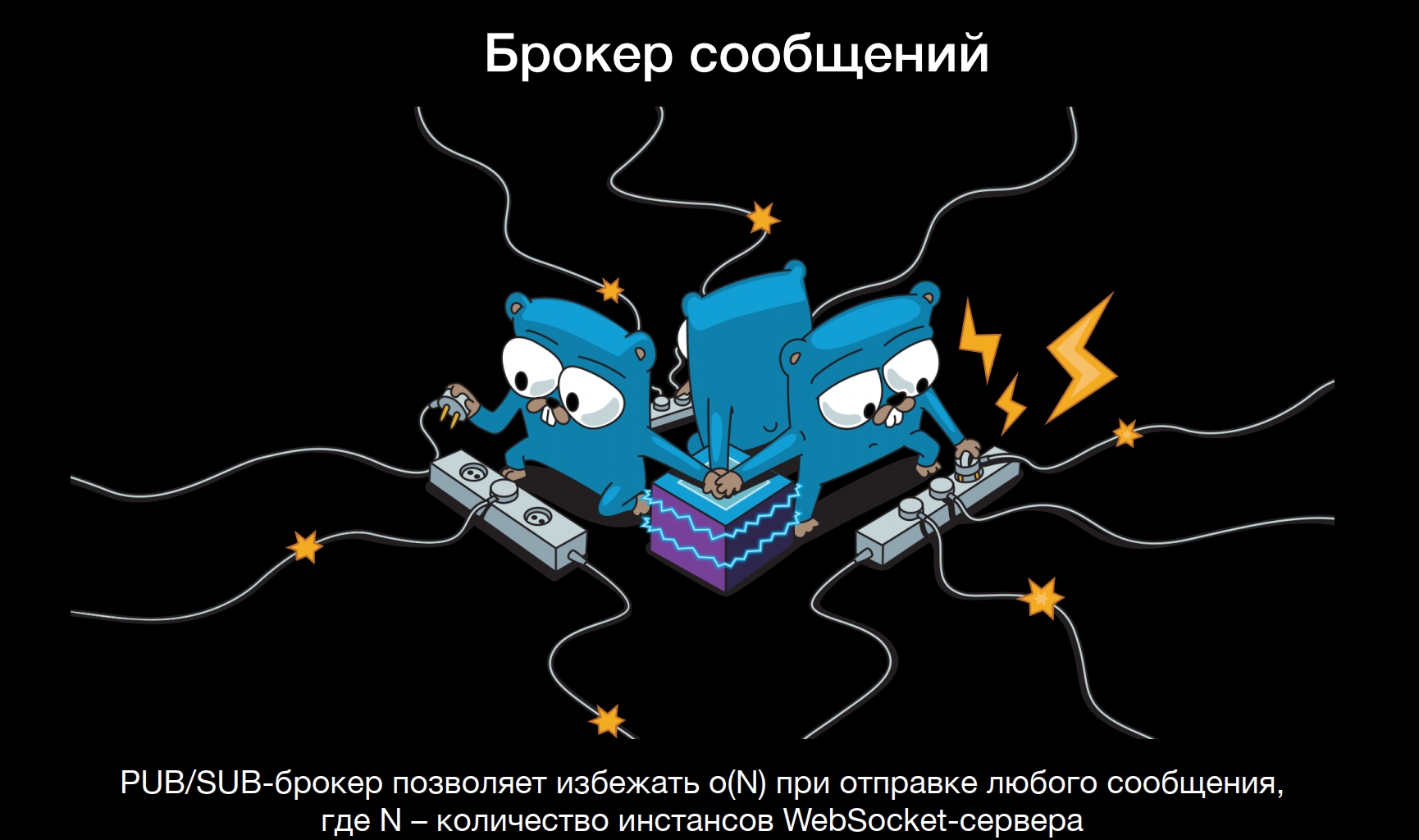
Про центральный PUB/SUB-брокер для масштабирования WebSocket рассказывается в большинстве статей. Однако конкретики нет. Часто говорят: «Ну, а для брокера используйте RabbitMQ или Redis», и на этом повествование завершается.
Я добавил больше конкретики в этот вопрос. Посмотрим, что нам нужно от брокера:
- Производительность — конечно, это первое требование, это логично.
- Сохранение порядка сообщений — тоже важное свойство, которое нам нужно.
- Масштабируемость брокера. Мы хотим, чтобы брокер сам по себе масштабировался и был бы отказоустойчивым.
- Миллионы топиков. Мы хотим, чтобы он поддерживал миллионы топиков одновременно, потому что это частый use case — когда у каждого соединения есть свой персональный канал. Мы хотим рассылать сообщения конкретному пользователю. И если у вас миллион WebSocket-соединений, появляется миллион топиков в брокере.
- Кэш/стрим сообщений. Мы хотим, чтобы брокер поддерживал кэш или стрим сообщений в топике/канале. Что это такое и от чего это спасает, поговорим чуть позже.
- Возможность писать процедуры — и это большой бонус. Я расскажу, как мне это помогло в Centrifugo и в мессенджере Авито.
Опции брокера сообщений
RabbitMQ
Он будет работать, пока у вас небольшая нагрузка. На каждое соединение вы создаете очередь. На самом деле это не масштабируется, когда появляется множество пользователей, когда большой коннект-дисконнект рейт, при этом вы часто делаете bind/unbind очереди. Например, когда я пришел в мессенджер Авито, там использовался RabbitMQ, и было 100 тысяч подключений. На 100 тысячах подключений RabbitMQ потреблял 70 CPU. Забегая вперед, мы заменили RabbitMQ на Redis, и получили 0,3 ядра CPU — в 200 раз лучше для нашей задачи!
Kafka
Кажется вполне естественным попробовать Kafka для этого. Моё мнение, что это оверкилл для многих приложений, потому что Kafka сохраняет стрим на диск, а консьюмер Kafka работает по pull-модели, что может быть неэффективным, когда у вас миллионы топиков и вам надо пулить данные из всех. Kafka предпочитает более стабильную конфигурацию своих топиков, потому что в динамике, когда у вас появляется subscribe/unsubscribe, топики создаются и удаляются на лету, и кажется, что во многих случаях лучше с Kafka так не делать.
Pulsar
Это еще один кандидат, но мне сложно рассуждать о его преимуществах/недостатках, так как я с ним не работал. Возможно при условии использования in-memory очередей Pulsar может быть неплохим кандидатом.
Nats, Nats-streaming
Мне кажется, что Nats вы вполне можете использовать, если нужен unreliable at most once PUB/SUB. Это производительное решение, написанное на Go. Nats-streaming я бы не использовал, потому что посмотрел его код и в достаточно критичных для себя местах нашел todo, которые не имплементируют определенную логику при восстановлении сообщений. Для меня это показалось критичным.
Tarantool
Tarantool кажется хорошей альтернативой в качестве брокера, потому что он мега-производительный, у него есть LuaJIT на стороне сервера и можно гибко писать логику. С недавней версии он поддерживает пуш со стороны брокера в соединении.
Redis
Мы в мессенджере Авито остановились на Redis, потому что:
- Redis производительный, в том числе у него производительный PUB/SUB;
- Он стабильный и, самое главное, предсказуемый;
- У него есть Sentinel для High Availability;
- Он позволяет писать атомарные LUA-процедуры;
- Структуры данных позволяют хранить кэш сообщений. Опять возник этот магический кэш сообщений, но мы к нему скоро вернемся.
Соединения между сервером и брокером
Тут есть несколько очевидных советов — если вы делаете центральный PUB/SUB брокер, то:
- Используйте одно или пул соединений между WebSocket-сервером и вашим брокером.
- Не используйте новое соединение на каждый коннект! Я видел часто в примерах на GitHub, как пишут код: пришло новое WebSocket-соединение, открываем новое PUB/SUB соединение с Redis или с каким-то другим брокером. Так делать не надо, это антипаттерн и это не масштабируется.
- Используйте максимально эффективный формат сериализации сообщений для общения между WebSocket-сервером и вашим брокером. Здесь не надо задумываться о том, чтобы формат был человеко-читаемым, потому что его не увидят ни ваши фронтенд-разработчики, ни тестировщики. Это сугубо внутренняя вещь, и вы можете делать ее максимально эффективной.
К брокерам мы еще вернемся. Поговорим о другой проблеме.
Массовый реконнект
Массовый реконнект случается в тот момент, когда у вас сотни тысяч, миллионы пользователей онлайн подключены по WebSocket-соединению, а вы, например, деплоите свой WebSocket-сервер, выкатываете новую версию, или у вас релоадятся внешние балансеры. При этом соединения рвутся и лавина пользователей приходит к вам на бэкенд переподключаться. Причем они не просто хотят переустановить пересоединение, а еще и восстановить свое состояние, потому что WebSocket-приложения stateful как тот же мессенджер: я как пользователь хочу получить все сообщения, которые пропустил, пока отсутствовал:

Часто такая пиковая нагрузка — это большая проблема. Посмотрим, как с ней можно бороться с помощью нескольких техник:
Exponential backoff на клиенте. Первая, всем известная практика — это обязательный Exponential backoff на клиенте. Клиенты должны переподключаться с экспоненциально увеличивающимися интервалами.
Rate limiter на WebSocket-сервере. Если вы знаете, что у вас на бэкенде какой-то ресурс деградирует при конкурентном доступе, поставьте туда самый простейший bounded семафор и ограничьте конкурентный доступ. Делается на Go элементарно — канал с буфером, и все. Зато у вас не деградирует система. То, что пользователь, предположим, переключится чуть позже — обычно не так критично.
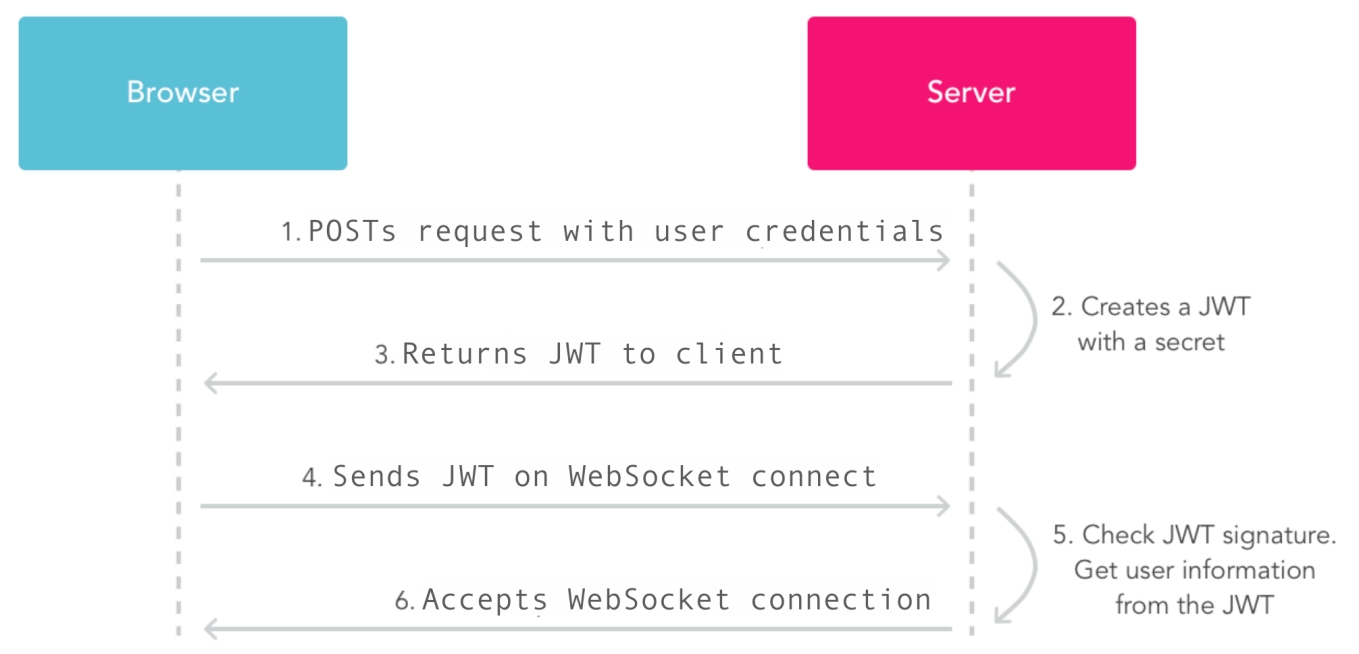
JWT-аутентификация как способ не нагружать бэкенд сессий. Часто происходит следующее. Приходит коннект на сервер, его нужно аутентифицировать, а аутентифицируете вы его через бэкенд сессий. Причем бэкенд сессий может быть развернут как локально, так и отдельно в виде сервиса. JSON Web Token позволяет избавиться от большой нагрузки на бэкенд сессий, потому что у JWT есть expiration time.
Когда к вам приходит пользователь и пытается аутентифицироваться, используя JWT, и он валиден, вы можете не ходить в ваш бэкенд сессий. Если вы разумно выберете время, через которое JWT истекают, то большая часть из них при реконнекте окажется валидной, и вы обрабатываете всё внутри процесса на Go:
Добивайтесь максимальной производительности соединений. У вас сотни тысяч пользователей приходят и хотят переподписаться. В этот момент вы точно хотите переподписать их как можно скорее. Это хорошо и вам, и пользователям. Например, в случае с Redis мы можем это делать, используя Redis пайплайнинг. Это отправка нескольких запросов Redis за один запрос. Мы это делаем и в Centrifugo, и мессенджере Авито. Мы используем пайплайнинг на полную в этот момент. С этим помогает техника Smart batching — паттерн, который позволяет из нескольких независимых источников горутин собирать запросы и делать один batch запрос:
maxBatchSize := 50
for {
select {
case channel := <-subCh:
batch := []string{channel}
loop:
for len(batch) < maxBatchSize {
select {
case channel := <-subCh:
batch = append(batch, channel)
default:
break loop
}
}
// Do sth with collected batch – send
// pipeline request to Redis for ex.
}
} У нас есть каналы, из которых приходит какая-то работа. Мы знаем, что эту работу эффективней выполнять пачками. Мы читаем из канала, записываем объект, который нам нужно обработать, в batch (например, в слайс):
batch := []string{channel}Далее продолжаем вычитывать из этого канала данные до тех пор, пока batch не перерастет свой максимальный размер или пока в канале не останется данных:
for len(batch) < maxBatchSize {
select {
case channel := <-subCh:Select в Go это позволяет сделать. В итоге копим batch:
batch = append(batch, channel)На выходе у нас получается пачка объектов, с которыми мы можем работать, например, послать пайплайн запрос в Redis. Пример со smart-batching на play.golang.org. Также в моем репозитории на GitHub вы можете посмотреть, как Smart batching и пайплайнинг помогают во взаимодействии с Redis — там есть набор бенчмарков.
Кэш сообщений, чтобы убрать пиковую нагрузку с СУБД. Как я уже сказал, пользователи хотят восстановить свое состояние и не пропускать сообщения, которые были в момент реконнекта. Вы можете хранить стрим сообщений, которые опубликовали, в каком-то быстром и горячем кэше. Мы их храним в Redis в структуре данных LIST. Как вариант, начиная с Redis 5.0, можно использовать Redis STREAM. Происходит публикация, идет запрос в Redis. Там работает LUA процедура, которая нам позволяет атомарно, в один RTT, сделать следующее:

- Мы добавляем сообщения в структуру данных List. Как вы видите, здесь уже три сообщения. У каждого сообщения при этом есть инкрементальный номер. Мы его увеличиваем атомарно.
- Далее мы публикуем сообщение в PUB/SUB Redis и в этот момент оно улетает в PUB/SUB. В свою очередь, PUB/SUB долетает до клиента (если он подключен). Как только клиент реконнектится, они передают номер сообщения, которое видели последним.
- Идем в Redis, смотрим в Lists. Если есть сообщения, восстанавливаем их клиенту из этой структуры данных, как будто он даже не был отключен.
- Так клиент получает весь стрим сообщений, которые ему были высланы в интервале отсутствия и так снимается пиковая нагрузка с СУБД.
На самом деле Redis PUB/SUB — это at most once гарантия доставки. В мессенджере Авито и в Centrifugo мы дополнительно на уровне кода приложения нивелируем потери, сверяя номер входящего PUB/SUB сообщения с ожидаемым, а затем периодически синхронизируя позицию клиента с ожидаемой в случае долгого отсутствия сообщений из PUB/SUB. Если обнаружили потерю — закрываем соединение клиента, давая ему переподключиться и выполнить всю необходимую логику для восстановления состояния.
На таком стриме можно сделать и fallback для WebSocket. В мессенджере Авито мы так и делаем. У нас есть стрим таких сообщений для каждого топика, и когда наш пользователь приходит, мы используем HTTP polling для fallback, чтобы он забрал данные из этого стрима и отдал их клиенту. Как бонус от кэша сообщений на этом же механизме можно построить и long-polling.
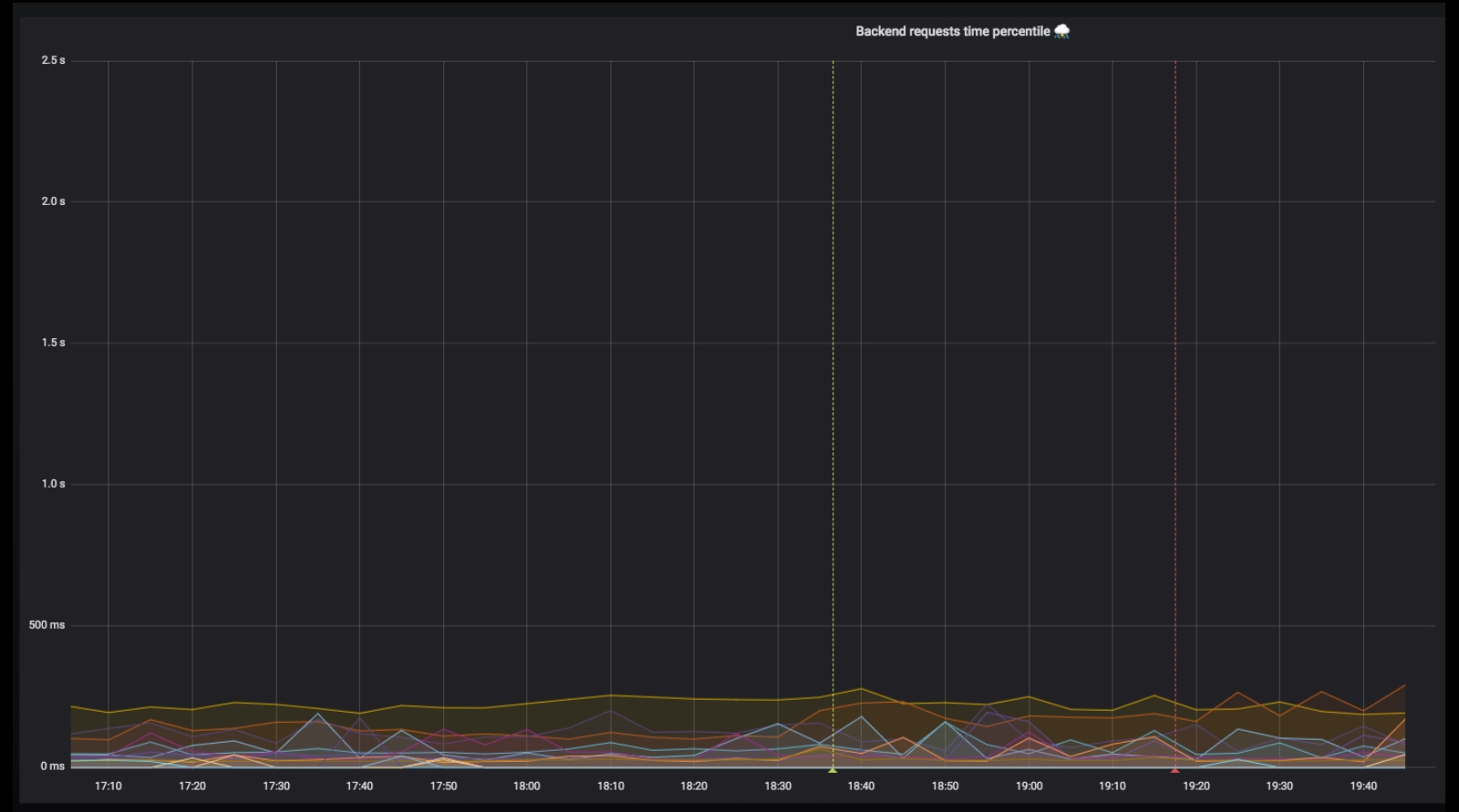
Время ответа RPC при раскладке. Такой график мы наблюдали при раскладке нашего сервиса, когда у нас был RabbitMQ и 100 тысяч пользователей. Видно, что ничего хорошего:

Так стало, когда у нас появился Redis и уже 500 тысяч пользователей. Видно, что раскладка происходит совершенно бесшовно для наших клиентов, а время ответа «RPC-ручек» совсем не растет:
Centrifugo
Многое из того, что я рассказывал, присутствует внутри Centrifugo. Если вам не хочется заморачиваться самим и писать, то можете его использовать. Это отдельно стоящий сервер, который принимает коннекты от пользователей и имеет API, чтобы отправлять сообщения пользователям. При этом он хорошо встраивается как в монолитную, так и в микросервисную архитектуру:
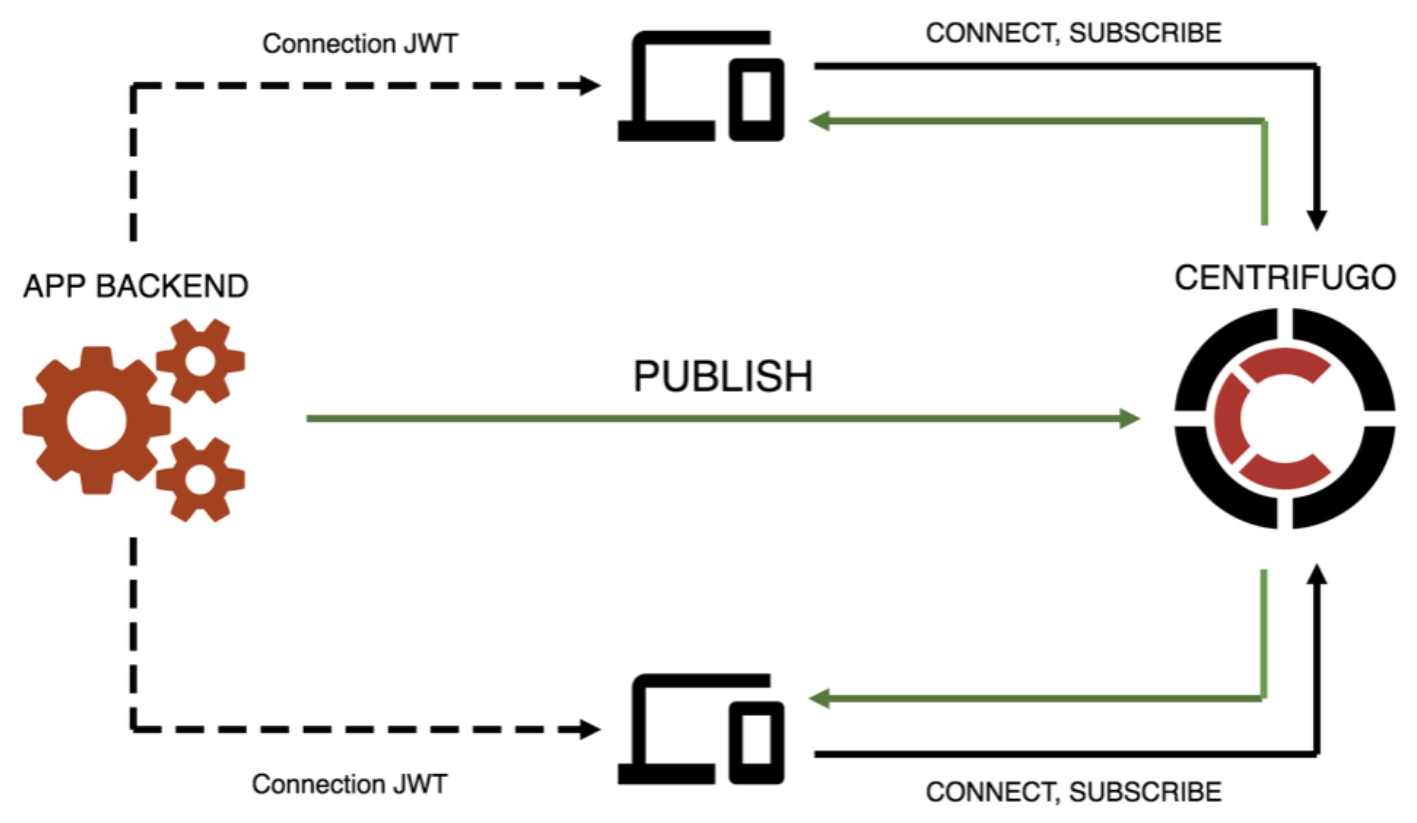
Как я говорил, основа сервера — библиотека Centrifuge, хотя это уже не совсем библиотека, а уже к фреймворку, потому что Centrifuge задумывается о масштабируемости за вас, имеет встроенный Redis и кэш сообщений. Плюс диктует клиент-серверный протокол. Так как Go-разработчики (и я в том числе) не очень любят фреймворки, то проще всего ее описать как альтернативу socket.io на Go — со всеми сопутствующими за и против.
Демо стенд
Чтобы не быть голословным, я сделал демо-стенд на миллион WebSockets в Kubernetes, который использует библиотеку Centrifuge на сервере. На этом стенде я добился следующих цифр:
- 1 mln соединений;
- 30 mln сообщений в минуту, которые будут доставлены пользователям (это 500 тысяч сообщений в секунду);
- 200 k коннектов в минуту — приблизил к тем цифрам, которые у нас в мессенджере Авито есть;
- 200 ms latency доставки в 99 персентиле.
Хочу подчеркнуть, что это не нагрузочное тестирование, где мы доводим систему до полки (отказа), а просто демо-стенд. У меня было ограниченное количество железа и данные цифры — это далеко не потолок возможного масштабирования, поэтому был небольшой time-lapse. Что мы видим?
Number of connections быстро дорастает до миллиона. Мы ждем какое-то время, и видим, что система ведет себя стабильно. Затем начинаем публиковать сообщения (график Messages delivered) и доходим до 30 млн сообщений в минуту. При этом смотрим на серверный CPU, на память, и в том числе на брокер (Redis). В данном случае используется 5 инстансов Redis, мы шардируем Redis по имени топика (консистентное шардирование jump). Мы видим, что latency дорастает до 200 мс и там примерно останавливается, когда рейт сообщений достиг 30 млн:
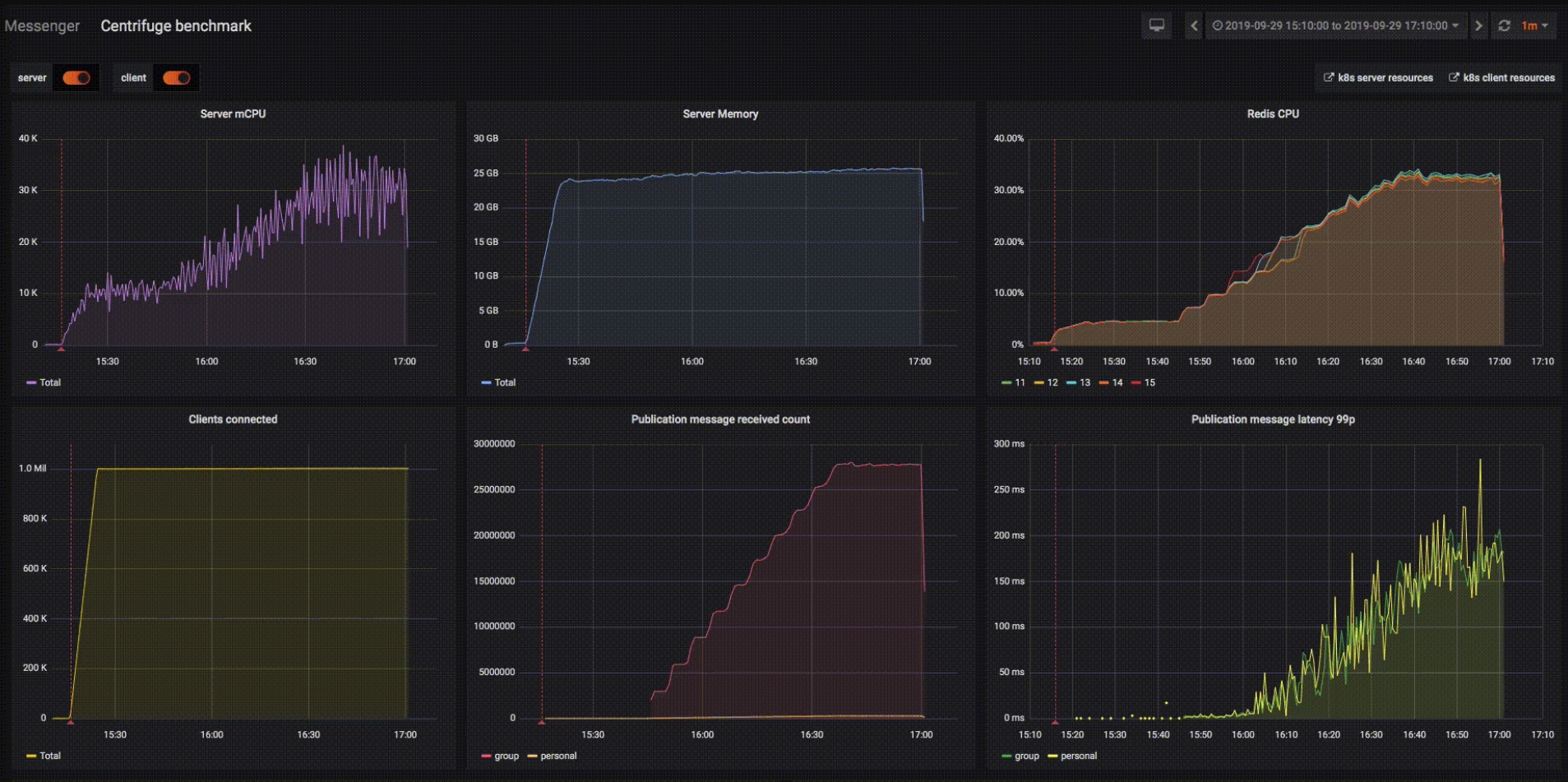
Вот здесь можно посмотреть процесс в GIF-формате (3 Mb).
Чуть больше цифр о использованных ресурсах:
- 40 ядер CPU total – 20 подов в Kubernetes (~ 2 ядра CPU каждый);
- 27 GB RAM total;
- 32% ядра CPU утилизировано на каждом из 5 инстансов Redis;
- 100 mbit/sec rx и 150 mbit/sec tx на каждом из подов.
Чуть подробнее про стенд можно почитать здесь.
Takeaways
Итак, что вы можете использовать:
- Дайте GC поработать на благо потребления RAM, сказав: «Старичок, приберись за нами! Мы тут немножко намусорили». И чем раньше мы это сделаем, тем лучше. Ему (garbage collector’у) все равно работать после того, как соединение завершится, поэтому не откладывай на завтра то, что можно сделать сегодня.
- Используйте эффективный и компактный формат сериализации.
- Используйте брокер сообщений для горизонтального масштабирования. Причем выбирайте тот, что подходит именно для вашей задачи.
- Подумайте над необходимостью HTTP-fallback.
- Лавину реконнектов нужно и можно переживать.
- Посмотрите в сторону Centrifugo. Если вам нужно рабочее решение, сейчас вторая версия очень даже хороша — JSON протокол, protobuf протокол, масштабируется с Redis.
Как со мной связаться: GitHub, Telegram, Facebook.
Конференция по Golang пройдёт уже в 2021 году, за новостями можно следить в Телеграм-канале. А пока в оставшиеся дни ноября и в декабре этого года у нас будет целая серия онлайн митапов.
Ближайшие:
- Встречаем PHP 8 в онлайне — о новинках PHP 8, развитии языка и советах по обновлению — 25 ноября (то есть уже сегодня) в 19 часов.
- Эволюция через боль. Как устроен СберБанк Онлайн изнутри? — об архитектуре банковских систем — 30 ноября в 18 часов.
- Безопасность и надёжность в финтехе — о не самых приятных и стандартных инцидентах в финтех-компаниях — 3 декабря, начало в 17 часов.
Следите за новостями — Telegram, Twitter, VK и FB и присоединяйтесь к обсуждениям.

{kind=link}