

Переехать в микросервисы можно двумя способами. Можно построить платформу — это надежно, но очень сложно. Или можно поднять Kubernetes и начать в него коммитить новые сервисы. Переезд проходит быстро и легко, но редко получается то, на что вы рассчитываете. Например, вместо микросервисной структуры вы можете обнаружить распределенный монолит.
Многие при этом не задумываются, правильно ли они пилят микросервисы. Как в синдроме утенка: увиденное самым первым становится единственно верным решением.
Меня зовут Олег Федоткин, я Head of PaaS СберМаркет, мы занимаемся той самой платформой, которая помогает разработчикам лучше, удобнее и быстрее писать микросервисы. Мы стандартизируем всю разработку, стараясь снизить Time to Market для новых фич. Но это всё равно очень сложно. Поэтому сегодня я разберу самые распространенные микросервисные проблемы.
Почему компании задумываются о микросервисах?
Например, в прошлом году в СберМаркете количество заказов выросло в 15 раз, а IT-дирекция перешагнула отметку в 350 человек. Естественно, увеличились темпы добавления новых фич, начался рост заказов, клиентов, и размеров команды.
Как следствие, нагрузка на монолит (у нас два монолита, написанных на Ruby on Rails) выросла на порядок, а обеспечить стабильную и частую выкатку двух монолитов при таком потоке новых фич сложно. Потому что даже самую маленькую фичу нужно тестировать — даже просто плохой SQL запрос может повалить монолит. Из-за большого количества новых тестов может замедлиться CI/CD, а размеры БД начнут стремиться в космос. Скорость разработки начнет снижаться из-за merge-конфликтов, все-таки 350 человек на два монолита — это многовато.
В таких ситуациях существует убеждение, что микросервисы решат все проблемы, которые я перечислил. На самом деле — нет. А вот добавить новых проблем сервисы могут легко. Потому что устойчивое представление, что можно большой кубик монолита распилить на части и переложить в микросервисы, в реальности выглядит как-то так:

При распиле монолита получается не пара десятков, а огромное количество кубиков, каждый из которых по-своему устроен: у него свой код, фичи, тесты и запросы. А это значит, что порог вхождения в такую систему гораздо выше, чем порог вхождения в монолит. Микросервисы сложнее писать, нужно больше знать про распределенное взаимодействие, асинхронные транзакции, саги и прочее — масса новых вещей.
Сами сервисы становится сложнее поддерживать, для них нужно больше людей. Это накладывает определенные правила на коммуникации и межкомандное взаимодействие. Ещё сервисы сложнее мониторить. Для монолита обычно достаточно один раз написать мониторинг, метрики и алерты, а для сервисов это нужно делать каждый раз с нуля.
Каждая компания решает это по своему, но не все полностью довольны результатом. Я думаю, что мы привыкаем к некоторым проблемам и перестаем их замечать, и даже можем их проблемами не считать. Но они есть и, во-первых, снижают ключевые метрики разработки. В нашем случае это стабильность системы (аптайм, ререйт) и TTM новых фич, то есть проблема аффектит тот или иной показатель. А во-вторых, могут привести к катастрофе в будущем.
Для каждой рассматриваемой проблемы я дал оценку, как она влияет на TTM и на стабильность (если 0, то не влияет, если 10, влияет самым пагубным образом). Например: [ TTM 5/10 | Stability 2/10 ].
Структурно я разбил процесс жизни сервиса на 5 этапов:

Начнем с создания, а конкретно — с проектирования.
Проблема №1. Процесс проектирования
На этом этапе мы понимаем, зачем нам сервис, рисуем диаграммы, вычленяем события, контракты и API. Всё это нужно сделать до того, как писать код.
Мы сейчас активно нанимаем архитекторов и много их собеседуем. Когда я задаю вопрос, как у них устроена архитектура до первой строки кода, то 7 из 10 кандидатов говорят, что никак: команда получила задание и пошла его делать. Остальные рисуют диаграммы. У кого-то Whiteboard, у кого-то Miro, но целостного подхода у большинства нет.
Последствия [ TTM 5/10 | Stability 6/10 ]
Отсутствие нормального процесса проектирования приводит к тому, что разработчики начинают писать код, как им заблагорассудится. А это, в свою очередь, приводит к неоднородной архитектуре. Например, в одной части системы будут синхронные взаимодействия, а в другой — асинхронные.
Когда одни общаются только через Kafka, а другие — только через Rest, разработка замедляется на стадии межсервисного взаимодействия. Стабильность системы снижается, потому что сложно подружить две негомогенные части сложно подружить, и в результате возникают баги. Мало того, эти две части (а как правило, их больше) могут сами изобретать решения под себя, так появляются дубликаты проектов, которые делают одно и то же.
Также бывает, что разработчик узнает про какую-то новую перспективную технологию — например, читая статью на Хабре — и решает ее использовать. Но проблема в том, что такие новинки не всегда поддерживаются в будущем.
Поэтому сложно переоценить влияние нормального процесса проектирования и на TTM, и на стабильность. Если вы не выстраиваете правильные процессы сами, то не факт, что вам понравится результат, выстроенный разработчиками. Это будет хаотично и разрозненно, без какой-либо гомогенности и однородности. То есть вы беретесь за разработку, не понимая, что конкретно хотите получить в итоге.
Решение
Решение на самом деле на поверхности, тут без rocket science:
Формализуем процесс «до первой строчки кода» с привлечением архитекторов, эксплуатации и ИБ. Работаем с командой, команда приносит уже устаканенные готовые диаграммы.
Выбираем инструменты для описания архитектуры. У нас, в первую очередь, это — диаграммы событий, которые получаются в процессе event storming, плюс UML в случае фулбэка.
Селим в JIRA процесс с Kanban на каждом этапе (архитекторы, безопасники).
Определяем четкий дедлайн для каждого шага процесса. Без дедлайна разработчики могут, во-первых, снижать TTM, просто потому что задача может висеть вечно в ревью. А во-вторых, у них появляется чувство, что есть какой-то пантеон небожителей-архитекторов, которые запрещают им катить сервисы.
Двигаемся дальше — к разработке.
Проблема №2. Контракты
Если представить, что сервис — это большая черная коробка, то контракт — это единственная наклейка на ней. В контракте написано, какие события сервис принимает, какие выдает в шину данных и какие эндпойнты у него есть. Проблема в том, что надо определиться с их хранением. Разберём на примере:

Чтобы совершить платеж с сервиса Payments, нужно послать пользователю нотификацию через сервис Notifications, а на Notifications отправить СМС через сервис Sms. Плюс, у нотификации и СМС есть свои контракты, которые нужно получить сервису-подписчику, чтобы воспользоваться сервисом-издателем.
Очевидным вариантом будет хранить контракты прямо в репозитории, а в Notifications и Sms — нотификации и СМС соответственно. В случае необходимости разработчик копипастит руками СМС в Notifications, а нотификации — в Payments.
В принципе, всё работает, но, во-первых, копипастить код руками в 2021 году — такая себе идея. Более того, пропадает любая гарантия актуальности, потому что мы можем забыть их скопипастить и вовремя обновить. А чтобы издателю обновить контракт, ему нужно пройтись по всем чатам и сервисам, пинганув людей, чтобы они обновились.
Поэтому есть другой, распространенный сейчас, способ хранения: общий Git-репозиторий. Например, есть склад git Repo, в котором лежат все контракты всех сервисов, и туда же допиливаются новые. Если подписчик хочет их получить, то он копирует себе сабмодуль, делает git pull и получает всё необходимое.
Этот способ частично решает прошлые проблемы, но при этом создает новые. Во-первых, при таком хранении пропадает атомарность релизов, потому что коды сервиса контракта всегда хранятся раздельно — это два репозитория с разными релизами. Во-вторых, невозможно посмотреть историю изменения контрактов git diff’ом — он пропадает на стороне издателя. И в третьих, всё еще нет гарантии, что на проде не разъедутся версии сервиса и его контрактов.
Последствия [ TTM 2/10 | Stability 9/10 ]
Огромное влияние на стабильность обусловлено быстрым устареванием контрактов. Бизнес запрашивает всё больше изменений, разработчики делают все больше новых фич, а значит, контракты должны всё чаще обновляться.
В результате у подписчиков появляется много версий одного и того же контракта. Издателю теперь необходимо их все поддерживать, чтобы ничего не сломать.
Более того, есть вариант, что на продакшен выкатят сервис, но не выкатят его контракт, и он разойдется с его кодом. Либо есть вариант, что подписчик успеет схватить новый контракт, а у вас останется старый контракт на издателя — и два сервиса просто перестанут коммуницировать.
Решение
Здесь решение не так очевидно, как для первой ошибки. Вернемся к Payments, Notifications и Sms:
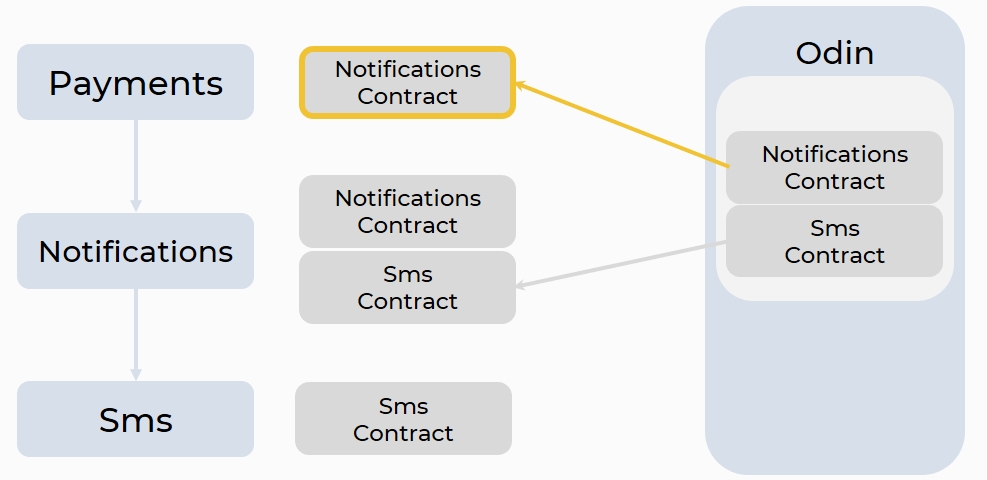
Мы положили код в репозиторий, рядом лежит код его контрактов (в нашем случае это protobuf). Мозг нашего PaaS — сервис Odin. Он умеет делать много фич, в том числе мониторить git-репозиторий (у нас это GitLab).
Как только происходит пуш в GitLab, Odin видит новые контракты и сохраняет их себе в БД. Затем нотификации могут объявить у себя в манифесте, что у них есть зависимость от сервиса Sms, а Payments объявляет зависимость от сервиса Notifications, и с помощью Odin стягивает самые актуальные контракты, либо обновляет их.
В коде это выглядит так:

В манифесте приложения хранится зависимость от какого-либо сервиса. В данном случае Payments зависит от Notifications, от такой-то ветки, такие-то контракты (grpc, open_api). А утилита sbm-cli позволяет из консоли загрузить или обновить эти контракты.
В процессе реализации этого решения мы добавили фичу branch. Это позволяет Odin определить, из какой ветки прилетел контракт, и разделить хранение Master и Branchs контрактов. Так можно брать контракт не из мастера, а из какой-то другой ветки. А значит, мы можем не мержить код в Master сразу, а подписаться на ветку, протестировать с ветки и, убедившись, что там всё хорошо, после этого смержить с Master. То есть и тестирование, и разработка становятся проще.
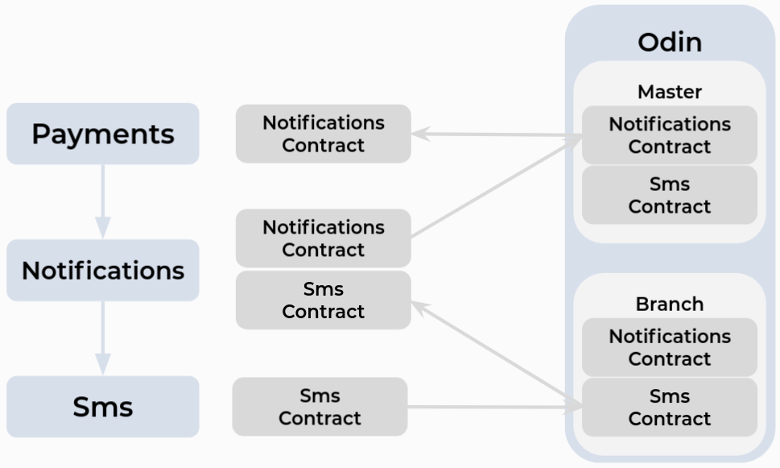
Кроме того, такой способ позволил нам, во-первых, сохранить атомарность релизов, потому что контракт лежит рядом с приложением, а git diff работает и у издателя, и у подписчика (контракты лежат рядом с кодом).
Во-вторых, так мы можем проверить конфликты контрактов до выкатки в прод — благодаря protobuf и Odin, которые про контракты и системы знают всё. Наш UI при этом показывает самые устаревшие контракты, и можно рассылать письма, что пора их обновить.
Проблема №3. Зоопарк
Мы сейчас пилим сервисы на Golang, но я приведу пример из Ruby, потому что большую часть времени писал на нём, и он мне как-то ближе. У Ruby есть множество адаптеров для приложения от Kafka, три самых популярных: Ruby-kafka, Rdkafka-ruby и Karafka. Есть целых три адаптера для Rabbit: AMPQ, Bunny и Sneakers. И еще пять фоновых решений для фоновых задач. Плюс вы можете рядом запилить сервис со своим набором решений.
И в результате мы получаем ситуацию, когда у нас, казалось бы, везде Rails, но под капотом настолько разные стеки технологий, что из общего у них только фреймворк:
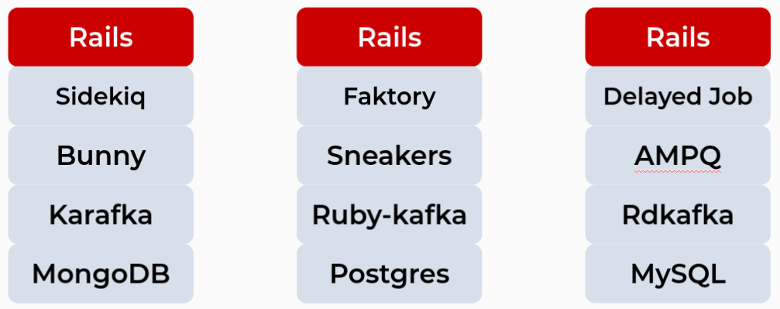
А это уже может привести к чему угодно.
Последствия [ TTM 5/10 | Stability 2/10 ]
Естественно, что переключение команды между проектами в таком случае будет долгим. Да и нанимать людей станет тяжелее, все они будут «рельсовиками», но должны будут сразу знать и Postgres, и MySQL, и что-то ещё.
Очень сложно будет восстанавливать работоспособность при сбоях. Например, если проект не ваш, и вместо Sidekiq, который вы досконально знаете, перед вами неизвестный Factory, то скорость восстановления работоспособности сильно упадёт. Вам придется сначала разобраться, что такое Factory.
Опять же помним про новые, перспективные технологии, которые вы решили использовать у себя. Всегда есть шанс, что новинка отомрет и ее придется выпиливать из проекта, либо это будет legacy. Тот же Factory в свое время был очень популярен. Но гораздо проще написать код, положив его на GitHub и написав о нем статью на Хабр, чем поддерживать и развивать его годами.
Решение
Решение, конечно, лежит на поверхности. Выбирайте стандартные решения для адаптеров, фреймворков и любых пакетов.

Если разработчику не хватает стандартных решений — например, он хочет не Postgres, а какую-то NoSQL БД — то у нас он может ее взять только после согласования с архитектурным комитетом. То же самое касается замены стандартных решений.
Проблема №4. Тестирование на стейдже
На этапе тестирования всё не так очевидно, как с предыдущей проблемой. Типичный стейдж микросервисов у большинства разработчиков выглядит так:

Например, мы хотим протестировать Sms на стейдже. QA запускает сценарии регрессионного тестирования, но Sms падают. QA делает вывод, что в них баг, и зовет разработчика. Они вместе смотрят стейт-трейсы, заходят в трейсинги, поднимают массу работы и выясняют, что до этого выкатился Price.
Его тоже проверяют, и ошибок в нем нет, но выясняется, что ещё раньше выкатили Cashback. И новая версия Price не дружит с новой версией Cashback, из-за чего, несмотря на хороший код, Sms и падает.
Такие ситуации в тестировании на стейджах крупных систем происходят постоянно.
Последствия [ TTM 7/10 | Stability 2/10 ]
Здесь нет тайны, что TTM страдает максимально, потому что QA не может сам разобраться из-за какого сервиса упал сценарий и вынужден привлекать разработчика. А разработчик, вместо того, чтобы делать новые фичи, ковыряется в стейдже. Естественно, сроки растут, а некоторые фичи начнут улетать в прод без (полноценного) тестирования
Решение
Наш стейдж устроен по-другому. При той же системе с пятью сервисами, мы не выкатываем, например Sms. Вместо Master-pods (который выкачен из мастера), мы поднимаем рядом новые поды. У них есть лейбл, совпадающий с названием тикета в Jira. QA кладет в хедер Sms-12 (это тоже название тикета в Jira) и отправляет запрос, который попадет не в Master-pods, а в Feature-pods (так мы назвали дополнительную систему):

Если нам нужно протестировать Price и Cashback в связке, то QA кладет себе в хедеры Price-91 с Cashback-44, и наша система роутит его запрос через Feature-podsPrice и Feature-podsCashback. Но при этом в Sms он попадает в Master-pods, потому что такого хедера нет.
Feature-pods обеспечивает нам то, что стейдж никогда не ломается и на нем всегда работает изолированное тестирование новых сценариев.
Теперь перейдем к релизу и процессам выкатки.
Проблема №5. Сервисы катятся по-разному
Рассмотрим снова наши примеры, только не самих сервисов, а их скриптов деплоя.
Например, сначала появился Orders, для него изобрели Helm chart и gitlab-ci. Потом для сервиса Price Helm chart модифицировали, а gitlab-ci переписали заново. Для Cashback, Payments и Sms был такой же процесс. Получили такую картину:

Если, например, девопсу нужно выкатить новый сервис, то он сначала пилит новый деплой или собирает его по кусочкам из старого деплоя. Из-за этого вырастает количество скриптов в деплое и поддерживать их становится сложнее.
Со временем старые деплои начинают ломаться, либо перестают поддерживать новые фичи. И тогда девопс пилит новый деплой, потому что старые не работают. Получается замкнутый круг!

Последствия [ TTM 7/10 | Stability 4/10 ]
Во-первых, так невозможно централизованно добавить новый шаг в CI. Скажем, у вас не получится привести новые линтеры, потому что придется обновлять gitlab-ci руками по всему проекту.
То же самое касается добавления канареечных релизов всем сервисам, ввода метрики на весь CI/CD и исправления багов каждого скрипта деплоя. Если есть баги, то у каждого скрипта деплоя их надо чинить отдельно. Даже если есть общие, то их всё равно придется чинить руками.
То есть девопсы, вместо того, чтобы улучшать вашу инфраструктуру, занимаются просто поддержкой старых деплоев. Добавьте к этому bus factor — хранителем тайных знаний о самых старых деплоях является небольшая группа девопсов-сторожилов — и без них вы можете остаться без информации, как выкатывать ваш главный legacy-монолит. Это даже не плохо, это отвратительно.
Решение
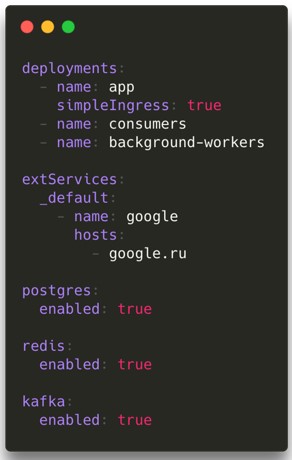
Решение более-менее на поверхности. Во-первых, отвяжите скрипты выкатки (Helm, gitlab-ci) и CI/CD от кода сервиса. Сам CI/CD должен быть общим на всю компанию и изменяться в едином месте. Скрипты должны жить в отдельном репозитории и выкатывать в прод только сервисы, и больше ничего.
Например, у нас есть декларативное описание: как мы хотим видеть сервисы в проде или в стейдже, какие нужно запускать поды и нужен ли Postgres и Kafka. Но это декларативное описание, которое в случае чего — например, если перейдем от Helm на customize — легко можно поменять. То есть мы не зашиваемся на конкретную технологию.
Проблемы эксплуатации
Подбираемся к финальному этапу. Как правило, проблемы эксплуатации самые тяжелые: каскадные сбои и разнообразные ошибки. Опыт в эксплуатации можно получить, набив шишки самостоятельно или обменявшись с коллегами, благо в сети много различных постмортемов крупных компаний.
Приведу 4 разных кейса:

Они не похожи друг на друга, но я поставил их рядом, потому что у них есть timestamps. То есть в постмортеме поэтапно расписан процесс, как сервис упал, как его поднимали и что получилось. Эти timestamps меня натолкнули на интересную мысль: время первой реакции на сбой у всех достаточно большое — 5-10 минут. Почему? Думаю, это связано с тремя финальными проблемами, с которыми рано или поздно на этапе эксплуатации сталкиваются все.
Проблема №6. Метрики
Что может быть не так с метриками? Во-первых, метрик очень много — на железо, сеть, очереди, задачи, БД, кэши — и все их нужно писать руками. Во-вторых, их все нужно показывать, например, отображать в Grafana. Нарисовать панельки, а в панельках построить красивые графики и поставить линии. И в третьих, это нужно делать каждый раз для каждого сервиса, а микросервисов, как мы помним, может быть очень много.
Последствия [ TTM 5/10 | Stability 7/10 ]
При создании сервиса вы неизбежно пишете метрики, потому что без них в большой системе нет жизни на проде. У нас было 100+ метрик, которые каждый раз приходилось вбивать руками. При этом от проекта к проекту у одних и тех же метрик могут быть разные названия. Потому что разные команды называют одни и те же вещи по-разному, а ещё может закрасться опечатка.
Если вы захотите добавить новую метрику во все проекты, то опять — добро пожаловать к ручному копипасту по всем проектам. И помним дашборды: их рисовать и исправлять тоже будет нужно руками. Если вы не будете делать эту массу работы, это повлияет на стабильность. Если будете — на ваш TTM, потому что вместо фич вы займетесь теми же самыми метриками в сотый раз.
Решение
Мы собрали все наши метрики и вынесли их в отдельный проект, который разработчик подключает к своему приложению. Этот пакет метрик обязателен для всех проектов, которые поддерживает команда PaaS.
Дашборды для этого пакета идут по дефолту, достаточно подключить их в Grafana. Обновляются они самостоятельно. Так что разработчик пишет только свои бизнесовые метрики.
Проблема №7. Алерты
Другой причиной 5-10 минутной реакции может быть отсутствие алертов. Либо алерты есть, но разработчики им не доверяют или игнорируют их.
Последствия [ TTM 0/10 | Stability 11/10 ]
Об упавшем проде вы обычно узнаете не из системы, а от ваших клиентов. Результат обычно ужасен. Помимо минуса к бизнес-показателям и репутации, у вас появляется риск деградации всей системы и денежных потерь — потому что вы обязались поддерживать SLA в договоре.
Решение
Мы ввели у себя систему Alerts as a Code. У нас есть файл alerts.yaml, который живет в коде каждого сервиса, и в нем описаны его алерты:

Это решает первую часть проблемы с алертами: у нас их писать просто. Не нужно ходить к девопсам и безопасникам, не нужен UI — просто написали код, закоммитили, пушнули, и алерты появились.
Гораздо сложнее сделать так, чтобы алерты не игнорировали. Всё дело в том, что их слишком много. Это проблема мальчика, который все время кричал: «Волки! Волки!», а когда пришли реальные волки, ему уже никто не поверил. Если алерты падают часто, на них перестают обращать внимание. Бывает и наоборот: сервис ломается, а алерт не падает. Это тоже подрывает доверие разработчиков к сообщениям.
Чтобы этого избежать, мы стали требовать автотеста на каждый алерт. Благо, у нас Prometheus Alerts может сам тестировать свои алерты. Вам надо только подать на вход sequence, а он вам ответит: сработало или нет.
Каждое срабатывание алерта мы записываем и выводим в Odin, чтобы потом проводить учебные тревоги для проверки каждого написанного алерта. У нас есть список, в котором записано, когда алерт последний раз падал, и если такого давно не происходило, то есть повод усомниться в его жизнеспособности.
Для меня это максима, которую я хочу к вам принести: алерт — повод бросить все дела и идти смотреть, что случилось. Иначе он не имеет смысла. Потому что только так вы успеете, пока не слишком поздно. Почему бывает поздно, поговорим дальше.
Проблема №8. Hope Driven Development
Чем больше шкаф, тем громче он падает, а микросервисы — это очень большой шкаф.
Если представить систему с аптаймом 99.95%, то это будет 270 минут в год даунтайма одного сервиса, или 44 секунды в день. Если в вашей системе 100 сервисов, и они начнут падать друг за другом, даже никого не аффектя рядом — у вас будет даунтайм 73 минуты в день, а если у вас 1000 сервисов — 12 часов в день. Но сервисы, конечно, живут не в вакууме — если упал один сервис, то есть риск, что упадет и второй. Поэтому картина может быть ещё печальнее, чем я описал.
Случаи бывают разные. Возьмем сервис, который обрабатывает СМС и очередь, прикрученную к нему. Внезапно моргает сеть, и очередь вырастает: СМС не могут достучаться до провайдера, а провайдер не может обработать СМС. По цепочке растет latency на отправку СМС и количество неотправленных СМС во всей системе. Из-за этого прогают ретраи, а из-за них снова растет очередь на отправку СМС:
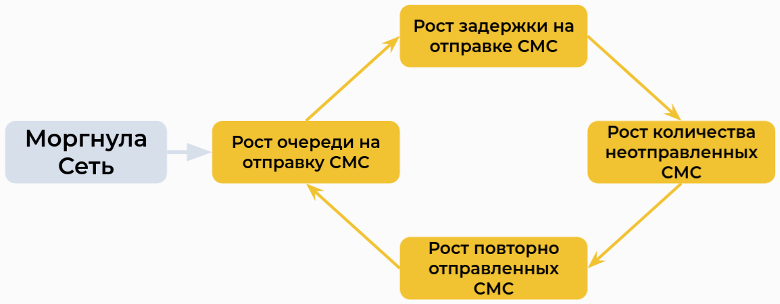
Получается замкнутый цикл под названием Reinforcing Feedback Loop. Он самостоятельно раскрутится в течении всего нескольких минут, и если его не затормозить, то повалит все СМС (и даже другие сервисы) в результате каскадных сбоев.
Последствия [ TTM 0/10 | Stability 11/10 ]
Пока не придумали других методов предотвращения каскадного сбоя, кроме масштабирования. Если вы успели быстро отскейлиться, то у вас поднимутся и СМС, и сеть. Делая 100 подов вместо 10, вы быстро прожуете очередь, чтобы она не перевалила критический объем.
Если не успели, то речь пойдет о 5-10 минутах, что снова означает: минус бизнес-показатели, возможные денежные и репутационные потери. Мы придумали два способа борьбы с этой проблемой.
Решение: Circuit Breaker или Rate Limiter
Прерывание (Circuit Breaker) — это паттерн, который просто отключает часть этой схемы. Например, вы описываете правило, что в случае повторных отправок СМС канал закрывается и СМС не принимаются в очередь на повторную отправку. Вы запланировано деградируете, чтобы полностью не обвалиться, но тем самым спасаете систему:

Второй вариант — Rate Limiter. Схема работы похожая, но вместо того, чтобы отключать часть системы, мы устанавливаем максимальный размер очереди — например, 1000 сообщений. Это описывается в конфиге тем же yaml-файлом. Если количество сообщений превышает 1000, они просто перестают отправляться:
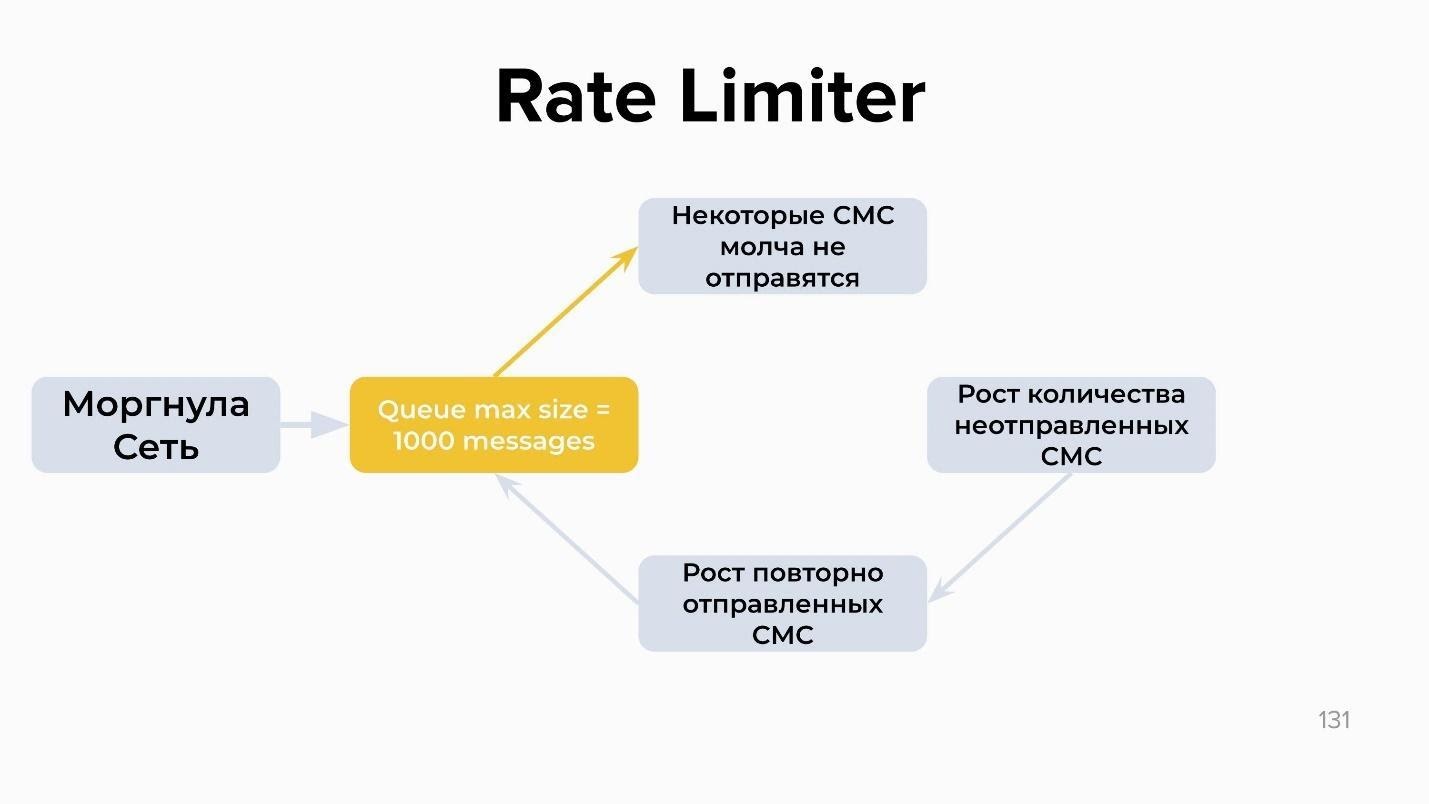
Это, конечно, тоже запланированная деградация и есть риск выкинуть СМС, которая, например, 3DS на оплату, но об этом надо просто думать заранее. От каскадных сбоев еще не придумали серебряную пулю, это тема отдельного разговора.
Итоги
Закончить я хочу фразой из книги Google SRE 133, которая мне очень нравится: «Надежда — это плохая стратегия».
Это касается всех перечисленных проблем: сбоев, архитектуры, и вообще всего. Распиливайте монолиты на микросервисы корректно. Сервисы предъявляют в общем более высокие требования к уровню разработки и пониманию происходящего, то есть что вы хотите от системы, зачем вы ее делаете и почему принимаете те или иные решения.
Видео моего выступления на TechLead Conf 2021:
В 2022 году конференция TechLead пройдет на одной площадке с конференцией DevOps Conf 2022 — 9 и 10 июня в Москве, в Крокус-Экспо. Подать заявку на выступление для техлидов вы можете здесь, а для devops-коммьюнити — здесь.
Если у вас есть идеи и мысли по выступлению, но есть и много вопросов, то можно встретиться в прямом эфире с Программным комитетом и расспросить их обо всем. Встреча с ПК DevOps Conf будет 13 , а с ПК TechLead Conf — 16 декабря в 16:00екабря в 19:00. Присоединяйтесь! :)
