
DDD — одна из моих основных рабочих методологий, я применяю её больше пяти лет. Хотя она довольна сложная, в том числе потому что это верхнеуровневый набор практик. DDD - это не фреймворк, когда нет опыта, его немного сложно применять. Тем не менее мы переводили на DDD работающие проекты, запускали с помощью нее новые — и у нас сложились некоторые практики и подходы.
Хотелось бы рассказать про те, что доказали у нас свою эффективность. Сегодня это будет стратегическое верхнеуровневое проектирование — о том, как разрабатывать программы с точки зрения моделей и требований. А в следующей части я расскажу про практики для работы с кодом и архитектурой, то есть более приближенные к разработке. Надеюсь, что вы сможете ими воспользоваться, а если вы еще не используете DDD у себя в проектах, то попробуете.

Проект, с которого всё началось
В один прекрасный момент мы начали поддерживать достаточно большой и тяжеловесный проект. Он автоматизировал работу банковского оператора в отделении, включал в себя процессы из 10+ областей бизнесовых знаний (поддоменов). На момент, когда мы в него пришли, в нем было уже больше 1000 пользовательских историй, а код писался не первый год. При этом у нас был не один заказчик, а несколько десятков, и все они хотели что-то доработать. Выглядел код проекта примерно так:

Проблемы этого приложения привели нас к пониманию: нужно что-то более структурированное в разработке, чем просто брать требования и реализовывать их, добавляя в проект куски кода. Кратко опишу проблемы, с которыми мы столкнулись.
Запутанная бизнес-логика
Первой и основной проблемой была запутанная бизнес-логика. Она и так в банке непростая, а в этом проекте процессы часто автоматизировались, как есть, а потом перерабатывались. И процессов, как я уже говорил, было много. Контексты и классы были переплетены так, что исправления в одном месте приводили к неожиданным ошибкам в другом.
Думаю, что многие, кто работает в больших компаниях либо в разросшихся стартапах, сталкивались с проблемой, когда проект очень большой и сложный, и его основная сложность — это запутанная бизнес-логика, которая мешает выдавать фичи, в результате быстро растет техдолг. Так, что в итоге вы не можете разобраться, как и что поменять, чтобы выдать свой компонент.
Частые серьезные изменения
Бизнес-логика в проекте была не только запутанной, но и очень важной: она влияла непосредственно на бизнес банка и ее приходилось постоянно дорабатывать. Часто доработки были серьезные, при этом те решения, которые принимались несколько лет назад, теряли актуальность.
То есть нам приходилось делать серьезные проекты как с точки зрения инфраструктурной автоматизации, так и точки зрения бизнес-логики. И, конечно, мы хотели делать это как можно быстрее, чтобы не терять конкурентное преимущество на рынке.
Сложность технического решения
Само техническое решение было сложным — в том числе и потому, что оно было большим. В некоторых местах у него страдало качество кода. Думаю, любой, кто сталкивался с legacy проектом, знает, что такие проекты, как правило, не состоят из идеально написанных исходных кодов. Конечно, нас это не устраивало. Мы хотели, чтобы то, что мы поддерживаем, стремилось к идеалу, а у нас было бы меньше негатива в работе.
И всё же, главным драйвером перехода на DDD стало другое.
Наша работа не была прозрачна для заказчиков
Нашу организацию, как и многих, настигла Agile-трансформация. Мы увидели, что наша работа с заказчиками не выглядит прозрачной ни для нас, ни для них. Как будто это была стена между бизнесом и нами. Мы общались через формальные требования, которые нужно было изначально согласовать. После чего заказчик на выходе что-то получал — и не всегда это было именно то, что он хотел. Не говоря уже, что за время реализации больших и сложных проектов требования в принципе могут измениться.

Мы хотели взять что-то, что поможет нам устранить все эти проблемы. И можно сказать, что, у нас не было проблемы выбора методологии, потому что в нашем поле зрения всеобъемлющей была только одна — предметно-ориентированное проектирование или DDD (Domain Driven Design). Забегая вперед, скажу, что это действительно сработало: DDD полностью может покрыть разработку проекта со сложной бизнес-логикой.
Предметно-ориентированное проектирование со стратегической точки зрения можно представить в виде двух больших блоков:

Дальше расскажу более детально про каждый блок, как мы их используем и какую пользу они могут принести.
Единый язык
Единый язык — достаточно уникальная штука для методологии разработки, он играет в DDD важную роль, и неспроста. Если мы вообще не общаемся с заказчиком (бизнесом), либо общаемся, но не понимаем, что он говорит — наше ПО будет не адаптировано к идеям, которые у него постоянно возникают. Достаточно сложно построить программу на обрывочном наборе требований.
Единый язык, выстроенный между командой разработки и представителями бизнеса, позволяет выудить из бизнеса полное понимание требований и сделать нашу работу не сказать, что проще — но более нацеленной на будущее. Он позволяет делать так, чтобы эту модель мы каким-то образом могли построить.
Расскажу, что мы делаем, чтобы построить единый язык и более живое и подробное общения без задержек. Это тоже очень важно, потому что сейчас все спешат и хотят делать продукты максимально быстро.
Отслеживаем в речи термины
Мы можем не замечать в наших разговорах, что периодически нам требуются перевод с одного языка на другой. Это происходит не только с заказчиком, но и внутри команды, когда разработчик до конца не понимает, что говорит тестировщик. Причем даже если мы постоянно используем какой-то термин, в какой-то момент может оказаться, что он недостаточно понятен другим.
Последите за своей речью на ежедневных митингах или когда вы разговариваете между собой — нет ли у вас каких-то терминов, которые вы не понимаете? Если они есть, постепенно добавляйте их в словарик.
Как только у вас возникает какое-то слово, которое вы не понимаете, обсудите его подробно. Тогда вы сможете четко понять, что оно для вас означает. После чего вся команда договаривается, что будет использовать этот термин именно в этом контексте — и заносит его в словарь.
Составляем словарь
Это абстрагированный пример словарика, чтобы было понятно, что можно заносить в словарь:

Несмотря на то, что в нашем словаре есть все термины, которые возникают при общении команды, словарь все же делается на ограниченный контекст. И он постоянно пополняется, это живой документ.
Мы активно используем сервисы поиска адресов, поэтому у нас есть термин DaData. Обратите внимание, что так как мы программируем на английском, а говорим на русском, то обычно термины имеют перевод, но в некоторых случаях его нет. DaData у нас никто никогда не переводит, этот термин так и употребляется.
Также это может быть связано с процессом с точки зрения бизнеса, но не являться сущностью. Например, тип документа — если говорить о клиенте — вполне может иметь именно такой смысл. Элементами единого языка могут стать и сторонние команды с подразделениями. Сейчас очень мало систем, которые изолированы от внешнего мира, и в наших системах тоже много интеграций.
Если говорить про инфраструктуру, то в единый язык могут попадать имена артефактов. Например, очень типично встретить в системе понятие «отчет» — и желательно понимать, что оно значит, чтобы потом не включить в отчет то, что для вашей системы на данный момент отчетом не является.
Также в этот словарь могут входить имена различных инфраструктурных компонентов. Например, у нас часто в словарь входит понятие «внутренняя шина данных». Потому что понимать, что она из себя представляет, должны понимать не только мы, но и доменный эксперт — чтобы разбираться в вопросах, которые касаются передачи данных внутри системы и снаружи.
Согласовывайте термины с доменным экспертом, если они родились в команде разработки — нужно, чтобы он их тоже понимал.
Так как всё общение у нас происходит на русском, в коде мы выбираем один английский перевод. Иначе код будет выглядеть очень рыхлым, без четкой и стройной концепции, а кроме того в различных частях кода не будет полностью понятно, что значит этот термин.
Рефакторинг при замене термина или значения
Если термины были выбраны неверно, то мы стараемся не ждать, пока в коде накопится неконсистентое состояние. Например, если мы получили новое название термина, то стараемся код сразу отрефакторить. Благо, у нас это происходит автоматически, практически ничего не стоит и мы можем себе это позволить, особенно учитывая нашу тенденцию к тому, чтобы дробить системы на сервисы.
Что мы не делаем в работе с единым языком?
Мы стараемся избегать многозначных терминов. Например, политика или операция в бизнесе имеют множество определений. И, если эти термины не сильно нужны в едином языке, то лучше от них избавиться, чтобы новые члены команды в них не путались.
Мы не используем специфические термины разработчиков, например, транзакцию или поток. Мы знаем, что наш код должен быть более-менее понятен доменному эксперту, в роли которого у нас часто выступает владелец продукта. За счет этого ему намного проще передавать требования команде разработки, и здесь появляется выгода.
В идеале хочется добиться, чтобы доменный эксперт умел читать код. Понятно, что он это, скорее всего, делать не будет, но, например, системные аналитики, которые работают в проекте, вполне могут это делать. Для них желательно, чтобы там было поменьше специфических терминов. По этой же причине мы отказываемся от имен паттернов проектирования в модели.
Если резюмировать, то единый язык очень важен в предметно-ориентированном проектировании. В итоге и заказчик, и разработчики начинают намного лучше понимать друг друга.
Разработка, ведомая моделью
MDD — это всё, что касается тактических шаблонов проектирования, моделирования и абстрагирования подходов к тому, как это делать. Есть много вопросов, которые пересекаются с моделированием, например, impact mapping или event storming.
Но я хочу поговорить не о формальном описании MDD со стандартными шагами, а посмотреть на MDD как на более общее понятие, которое подразумевает: прежде чем превращать требования в код и в готовый продукт, вы стараетесь все-таки понять, как они выглядят с точки зрения модели. То есть сначала превращаете требования в модель, а потом уже на их основе начинаете разработку.
При этом представление модели не играет глобальной роли. В стандартных методологиях часто говорят, что обязательно писать UML, по которому сгенерится код. Я думаю, что это излишне и даже вредно, когда вы работаете с продуктами, которые постоянно меняются. Здесь лучшим представлением модели будет хороший, качественный исходный код.
Разберем небольшой пример, который покажет, что может произойти, если вы не думаете о модели, когда разрабатываете свои продукты. Представим, что вы идеальный техлид (архитектор или ведущий разработчик). В какой-то момент вам приходит задача разработать новый проект — приложение для автоматизации работы с картами лояльности. Пользователи смогут избавиться от ненавистных карт в кошельке, а заказчик — захватить какую-то часть рынка и получить некоторые денежные плюшки.
У команды есть некоторые предварительные требования от заказчика:
Прикрепление карты по штрих-коду и типу;
Считывание карты камерой;
Прикрепление карты с неизвестным типом;
Отображение карты со штрих-кодом;
Поиск карты по типу и штрих-коду.
Видим, что требований не так много, и нужно создать приложение, которое будет выполнять одну, достаточно четко используемую, функцию: вы загружаете в свой телефон пластиковую карточку в электронном виде и можете ею пользоваться в магазинах, чтобы по штрих-коду сканировали ваши скидки.
Сущность: Карта лояльности
Когда вы разрабатываете такое приложение, то в корне получается некоторая сущность — например, «Карта лояльности»:

По большому счету в «Карте лояльности» нет ничего интересного. Она содержит в себе тип. Вы знаете справочник организаций, карты лояльностей которых подключены к вашему приложению. У них есть штрих-коды. Вот всё, что нужно, чтобы эту карточку считать.
Вы это приложение выпускаете, люди начинают его скачивать и пользоваться, приложение взлетает.
Новое требование
Обычно такое приложение не до конца понятно, как монетизировать, но можно сделать так, чтобы интегрировать в него отображение специальных предложений от партнеров. И у заказчика появляется такая идея для доработки.
Разработчики просто берут готовую модель и расширяют ее, так как в таких проектах обычно важны сроки. И, с точки зрения предметно-ориентированного проектирования, допускают некоторую ошибку.
Обновление модели
Они добавляют к сущности «Карта лояльности» нарямую связанную с ней подсущность «Специальное предложение»:

И всё будет достаточно хорошо, пока не придут новые требования. Поначалу вас даже устраивает внесение спецпредложений вручную через excel-файлы. Но в процессе интеграции оказывается, что при доработке системы этих предложений вы невольно ломаете уже созданные пользовательские истории. Поэтому вам требуется регресс, чему бизнес не очень рад.
Внешняя система
Я видел в реальных проектах, когда в какой-то момент компания решает, что лучше интегрироваться с внешним провайдером, который предоставляет эти специальные предложения, и таким образом сделать этот модуль более поддерживаемым и развиваемым. Но вам теперь нужно построить интеграцию не внутри вашего решения, — например, внутри одной базы данных — а уже с совершенно отдельной подсистемой через API:
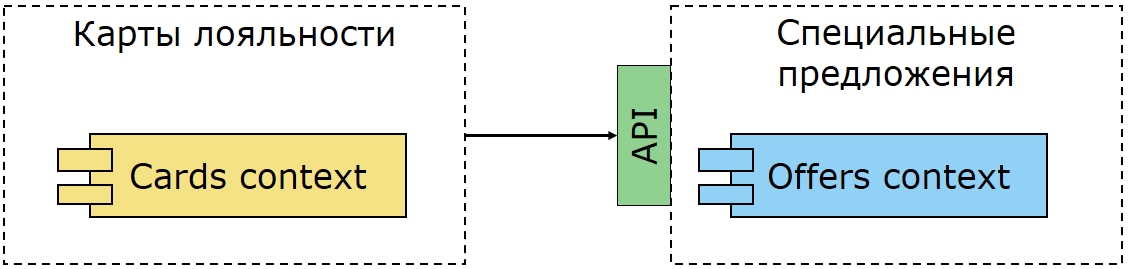
Для интеграции с внешней системой вам придется переписать и прорегрессить все решение. То есть вам потребуется написать достаточно большое количество нового кода и изменить столько же старого. В приложении придется перелопатить по крайней мере половину всех исходных кодов, и таким затратам бизнес будет совсем не рад.
По сути, это та цена, которую он заплатит, если в самом начале работы разработчики сделают приложение монолитным не только с точки зрения деплоя, но и с точки зрения бизнес-логики. И я видел на практике, когда компания теряла конкурентное преимущество из-за того, что у них не получилось быстро провести такую интеграцию.
Это был пример разработки без модели, когда вы получаете пользовательские истории и сразу реализуете в готовое приложение. DDD выступает против такого подхода. Посмотрим, что здесь можно сделать с точки зрения предметно-ориентированного проектирования.
DDD-алгоритм работы над задачей
Предметно-ориентированное проектирование говорит, что перед тем, как пользовательские истории превращать в приложение, нужно подумать над моделью:

Если бы разработчики из нашего примера это сделали, то всерьез бы задумались: а стоит ли отображение карт лояльностей перемешивать со специальными предложениями? Действительно ли они являются настолько связанными сущностями, что никогда в будущем не будут разделяться?
Чтобы это учесть, я хочу предложить некоторый алгоритм работы над задачей с точки зрения предметно ориентированного проектирования.
1. Определяем поддомены, которые затрагивают требования
Поддомены — это области знаний с точки зрения бизнеса. Можно сказать, что мы просто разбиваем всю область знаний на небольшие подобласти и говорим: здесь у нас важная часть, которая приносит максимальную ценность, а там — не очень важная, и она приносит меньше ценности:

Домен, как правило, определен до того, как вы пришли в организацию. Но, если вы запускаете стартап, то важно понимать, в какой области вы работаете. Это поможет сфокусироваться на основных целях и задачах.
В нашем примере вместо того, чтобы вставлять в один поддомен и карты лояльности, и специальные предложения, их стоит разделить, проведя в них логические границы и работая с ними несколько отдельно:

С точки зрения будущего развития это нужно, чтобы не испытывать проблем с доработками, идущими совершенно с разных сторон в одной и той же части кода.
2. Определяем тип подобласти
Если некая подобласть очень ценна для нас, то в ней мы будем максимально затрагивать проектирование. А если эта подобласть, например, чисто инфраструктурная и не имеет отношения к продукту, то мы можем ее даже не писать, а взять готовое решение, уделив ей меньше времени.
Кстати, это может подойти и для проектов, которые работают с MVP. Потому что мы можем четко выделить, в какой области нас действительно не интересует качество продукта и качество модели, а в какой области все-таки стоит подумать получше и постараться модель проработать перед тем, как ее реализовывать.
3. Определяем ограниченные контексты для внесения изменений
Дальше подобласти нужно смаппить на ограниченные контексты. Ограниченные контексты — термин, больше касающийся разработки. Он предполагает часть решения, в которой термины единого языка имеют однозначное определение. В ограниченный контекст могут входить системы и процессы, которые уже автоматизированы. Контексты ограничивают модели предметной области.
В идеальном мире ограниченный контекст совпадает с выбранной подобластью - одна подобласть, одна модель, один ограничивающий ее контекст. Если в нашем приложении будет 2 поддомена, то будет и 2 ограниченных контекста. И желательно сделать так, чтобы эти ограниченные контексты не были между собой связаны напрямую, например, вызовами внутри исходного кода, переходами по ссылкам и т.п. То есть мы хотим здесь иметь некоторую изоляцию.
Понятно, что в нашем примере мы бы уже на этом этапе не допустили ситуации, когда в сущность «Карта лояльности» входит сущность «Специальные предложения». А если будет принято решение заменить существующую часть покупной, то это можно будет сделать с заменой команды, а освободившихся людей перенести на другие проекты:

4. Определяем агрегаты, подверженные изменениям
В конце концов, основываясь на выделении ограниченного контекста, мы можем определить те агрегаты, которые будут подвержены изменениям. В нашем примере мы бы решили, что агрегат карты лояльности не будет подвержен глобальным изменениям, а появится новый агрегат.
Если по такому принципу вести доработки уже существующего продукта, то можно намного лучше понять, каким образом он внутри разбивается по границам подобластей. Так можно делать доработки более контролируемыми.
А можно пойти еще дальше и на основе агрегатов создать микросервисы
5. Микросервисы на основе агрегатов
От выделения агрегатов — буквально один шаг до перехода вашей системы из монолитного состояния в микросервисное:

Если ориентироваться на пункты этого алгоритма при разработке задач внутри вашего процесса, то вы можете получить намного более контролируемое внедрение требований в исходный код. Ваш код не превратится в аморфную массу. У вас не будет антипаттерна Big ball of mud, который приводит к тому, что разработка продукта останавливается и продукт умирает не от того, что он плохо работает, а потому что в него невозможно встроить новые требования.
Представление моделей
Разработка, ведомая моделью, еще хороша тем, что эту модель можно потом по-разному представлять. Так модель выглядит у нас в документации:

Мы стараемся делать документацию в Confluence максимально похожей на представление в коде, чтобы они практически совпадали. И, например, аналитики начинают намного лучше понимать то, каким образом устроен код и процессы, работающие в нем. Тем самым системная аналитика становится более глубокой. Она уходит от вариантов бизнес-аналитики только с user story, когда всё описано абсолютно верхнеуровнево и отдано на откуп разработчику. Совокупное количество знаний в команде увеличивается.
Резюме
DDD содержит подходы для решения большого количества вопросов разработки. Особенно DDD полезен, когда у проекта сложная, запутанная бизнес-логика и нет серьёзныхтребований к производительности. К таким проектам относится много программ, которые что-то автоматизируют. DDD позволяет делать бизнес-логику максимально гибкой и модифицируемой, не давая проекту уйти в состояние технического долга, приводящее к смерти проекта.
Единый язык DDD помогает команде разработки и бизнесу понимать друг друга за счет того, что разработчики интересуются устройством процессов и стараются построить максимально подходящие конкретной задаче модели.
И наконец, DDD позволяет четко ограничить зоны ответственности команд и приложений. Это тоже очень важный момент. Из моего опыта разработки больших корпоративных систем, всегда очень плохо, если команда разработки и менеджмент не понимают их границ. Из-за чего иногда стараются тянуть ненужные требования, выбрасывая нужные и делая продукт несфокусированным.
Стратегическая часть в DDD самая важная, именно она определит, будет ли развитие приложения успешным. Если задуматься о границах до того, как вы начнете делать непосредственно вашу разработку, это может привести к тому, что ваш продукт будет намного лучше отвечать исходным требованиям.
В следующей части я расскажу, как приручить непосредственно исходные коды программ и каким образом они архитектурно представляются.
13 и 14 июня конференция TechLead Conf 2022 пройдет совместно с конференцией DevOpsConf 2022. Место проведения — кампус Сколково, самая инновационная и технологичная площадка в Москве.
Обсудим инженерные процессы в IT от XP до DevOps & Beyond, must have инструменты и практики изменений в командах для быстрых и качественных релизов. Программа практически сформирована. Билеты можно купить здесь.
