
Пастух весь день зависает в смартфоне, при этом его стадо коров остаётся под присмотром. Оператор на нефтяном месторождении прогнозирует поломку сложного агрегата и заранее сообщает о проблеме, чтобы вовремя её решить. Казалось бы, что может быть общего у этих несвязанных вещей… Ответ прост. Им облегчает работу IoT. Предлагаю вам небольшую экскурсию, где мы с вами погуляем вдоль вольеров зоопарка устройств, подивимся его разным «живностям» и окунёмся в Industrial Internet of Things – промышленный интернет вещей.
Я — Владимир Плизга, занимаюсь разработкой backend IoT-платформы AggreGate. Область интернета вещей (IoT, Internet of Things) открывает много интересных и необычных кейсов применения. Сегодня я поделюсь некоторыми из них и помогу вам систематизировать знания в этой сфере.
Понятие “IoT-платформа” появилось относительно недавно, причём почти одновременно в разных и независимых кругах, поэтому общепринятого определения нет. Приведу определение, которое сформировалось в нашей компании:
IoT-платформа – это инструмент, который усиливает компании за счет извлечения ценных сведений из связанного мира.
… empowering businesses … by mining valuable insights from the connected world.
Victor Polyakov, CEO Tibbo Systems
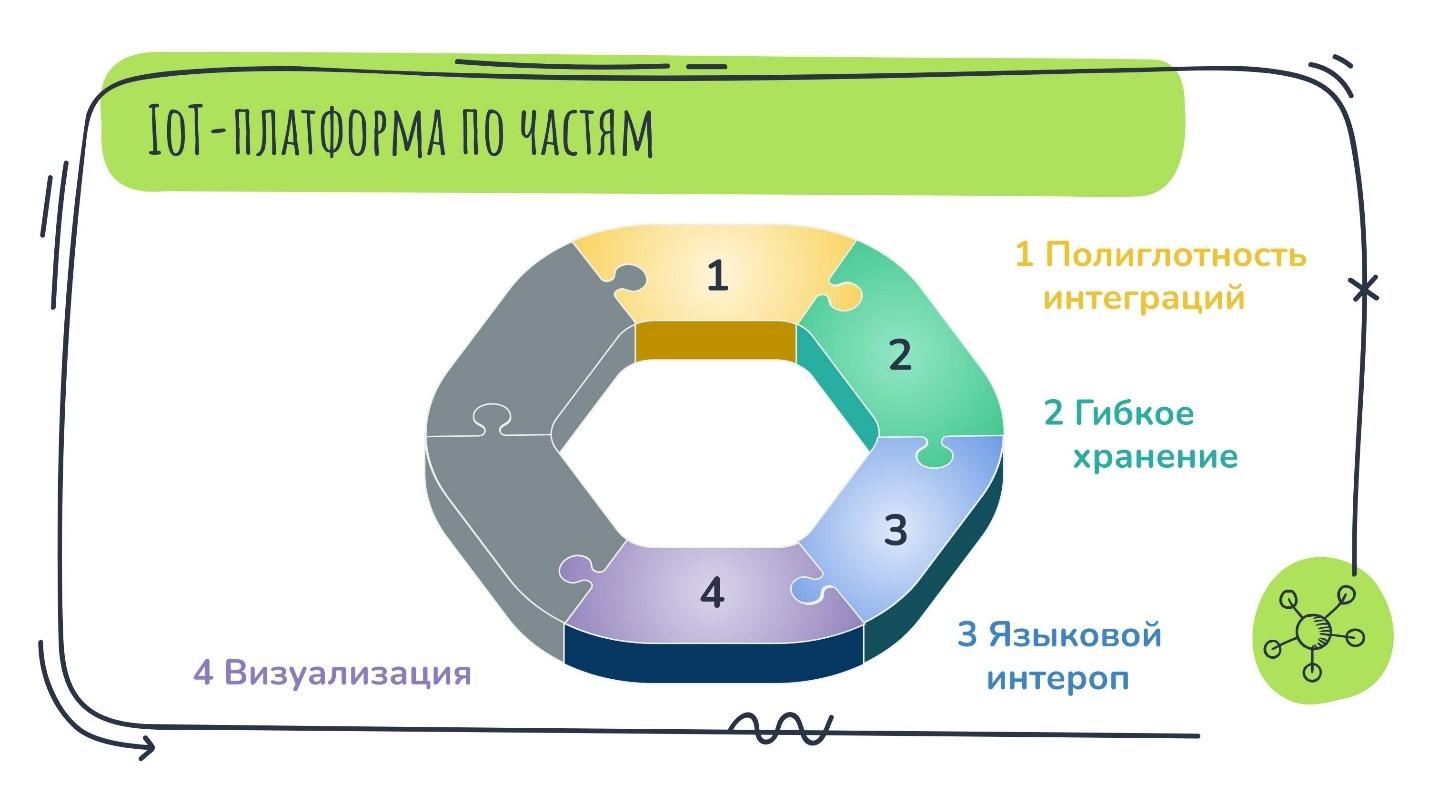
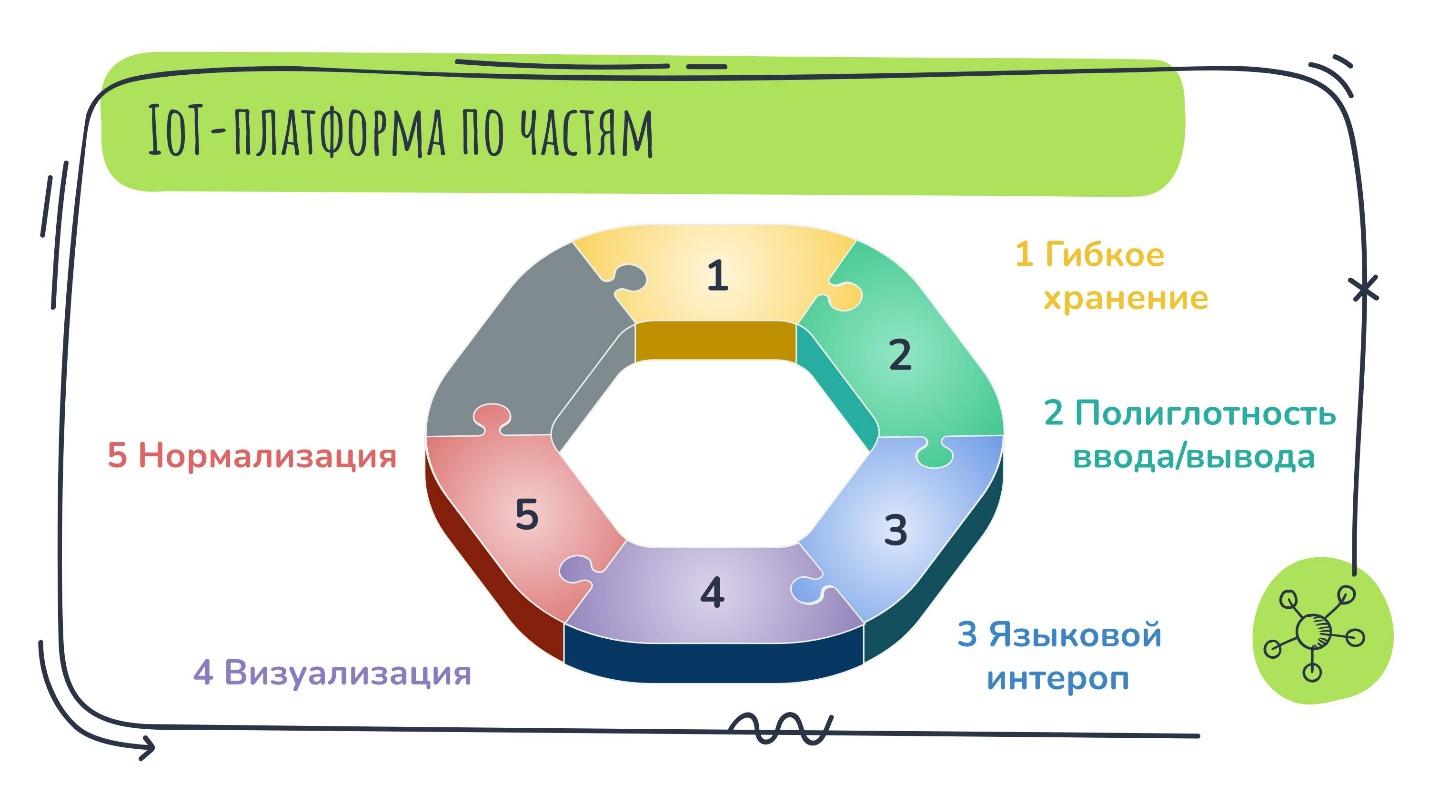
Чтобы понять, из чего состоит IoT-платформа, будем по ходу дела заполнять вот такой серый бублик различными свойствами или качествами, которыми она должна обладать как программный продукт, чтобы соответствовать своему названию.
Итак, первый кейс.
1. Fleet Management
Каким его никто не видел.
Это корова Майя. Очень интересная особа — послушная, отзывчивая, умная, всегда возвращается вовремя. В общем, мечта любого пастуха!

У пастуха таких милашек целое стадо.

В небольшом хозяйстве он знает их всех по именам. На промышленном предприятии все коровы пронумерованы. Независимо от масштаба, ежедневные задачи пастуха одни и те же:
отвести всех на выпас утром;
никого не потерять;
вовремя всех собрать и отвести обратно вечером.
Это частный случай задачи Fleet Management — управление флотом. Так её называют в промышленной разработке. Под флотом подразумевают парк автомашин или кораблей, в нашем случае — стадо коров.
Задача наблюдения за животным всегда решалась колокольчиком. Его вешали на шею корове. Она ходила, звенела. Пастух слышал её и мог позвать обратно в любой момент. Но цифровая трансформация пришла даже в эту консервативную область. Теперь вместо колокольчика на промышленных коровах есть маленькие коробочки.

Если посмотреть на них поближе, видны их технические характеристики.

Это трекеры двигательной активности крупного рогатого скота. Они содержат два почти независимых устройства:
датчик GPS/ГЛОНАСС/;
акселерометр.
С помощью акселерометра, детектируют паттерны движения коровы и на основе этого присылают пастуху различные сигналы. Если средняя активность животного снизилась, возможно, корова заболела. Если активности нет вообще, начался падеж скота. А если акселерометр детектирует прыжок, значит животное готово к оплодотворению. Оказывается, датчик и это умеет определять.
Этот датчик передаёт собранные данные по беспроводному протоколу LoRaWAN (Long Range Wide Area Network).

Это технология и протокол передачи, который, упрощенно говоря, бьют дальше, чем обычный Wi-Fi, но ближе, чем GSM. Они не требуют сим-карты и в чистом виде потреблять их на backend нельзя. Нужен узел, который будет собирать данные и поднимать их на более высокий уровень сетевого протокола. Это концентратор или шлюз, а по-русски, базовая станция.

Они собирают данные с множества устройств. Это небольшие коробочки с предустановленным производителем Linux, собирающим данные по LoRaWAN, а потом транслирующие их в прикладной протокол.
Вариант архитектуры backend на примере AggreGate и ThingWorx
Как это реализовано на backend:
платформа/язык – Java, так как надо запускаться где попало, чтобы обеспечить максимальную переносимость и способность развёртываться в разных окружениях;
подход – pub-sub, чтобы не поллить устройство постоянно, не сажать его батарейку и не занимать сетевой трафик зазря;
прикладной протокол – MQTT (Message Queuing Telemetry Transport), чтобы с полевых устройств забирать данные и передавать их на backend.
MQTT может работать по TCP/IP. Он не накладывает множество ограничений и сложностей как у других тяжеловесных сетевых протоколов, то есть не нагружает устройство лишней работой.
Для интеграции со стороны программного кода для этого протокола реализовано целое семейство библиотек под общим зонтиком проекта Eclipse Paho. Их здесь больше десятка, подстроенных под разные языки, в том числе под Java.
На этом шаге заполняю первый кусочек бублика.

Полиглотность интеграций — важное свойство любой IoT-платформы. MQTT и LoRaWAN — не единственные, протоколов таких устройств намного больше. Поддерживать их для IoT-платформы жизненно необходимо. Бессмысленно затачиваться под один протокол.
Как выбирают хранилище
Чтобы определиться с хранилищем на примере IoT-платформ, используют следующие аргументы:
однотипные данные поступают часто и много;
чтений значительно меньше — пастуху достаточно отслеживать только траекторию движения коровы в течение последнего времени. Зачастую нужны не все точки, а только приблизительный путь перемещения;
Транзакционность и гарантии ACID не нужны.
Вероятно, подходит колоночное NoSQL-хранилище. Но какое именно?
Когда выбирали хранилище для AggreGate, опирались, в том числе, на статью Netflix о применении Cassandra, чтобы получить более миллиона RPS (записей) в секунду на своей платформе. Вот ссылка на этот материал: Benchmarking Cassandra Scalability on AWS — Over a million writes per second (Netflix)
Хотелось, чтобы платформа оставалась коробочной и NoSQL-хранилище не ставилось отдельно. Чтобы дистрибутив был один — просто воткнул, запустил одну программу, и вуаля! При этом важно было сохранить масштабируемость, чтобы в любой момент вытащить NoSQL-хранилище и полноценно разворачивать — с отказоустойчивостью и всеми ништяками.
Поэтому была выбрана Cassandra, её можно запустить в embedded режиме прямо в приложение на Java, которым является сама платформа.
Но есть один нюанс. В официальной документации Cassandra не написано, что её можно использовать в embedded режиме. Такого кейса нет вообще, только для интеграционных кейсов. Зато в одной заявке в их Jira есть — слова разработчика и про поддерживаемый режим (потому что они не контролируют эту JVM и не могут отвечать за то, что кто-то там творит):
... it's an unsupported setup. We do not support embedding C* in a container (i.e. a JVM not controlled "by us").
IMO, supporting C* in such an environment will cause other issues.
Тем не менее, вариант вкусный с разных точек зрения. Плюсы развертывания Cassandra в вариантах:
Embedded
Только одна JVM
Нулевой сетевой лаг
Единство настроек
External
Разные JVM
Масштабируемость
Гибкость настроек
Можно спрятать настройки под интерфейс IoT-платформы, не заставляя пользователя этим грузиться, но ценой каких-то других допущений. Поэтому в случае с AggreGate было выбрано такое решение:

Поддерживаются оба режима: embedded и внешнее стороннее развертывание с подключением по сети к целому кластеру.
Мы предоставили выбор, но не сказали как выбирать. Кроме отказоустойчивости и возможности масштабироваться, есть количественные метрики. Например, потребление памяти с embedded Cassandra.
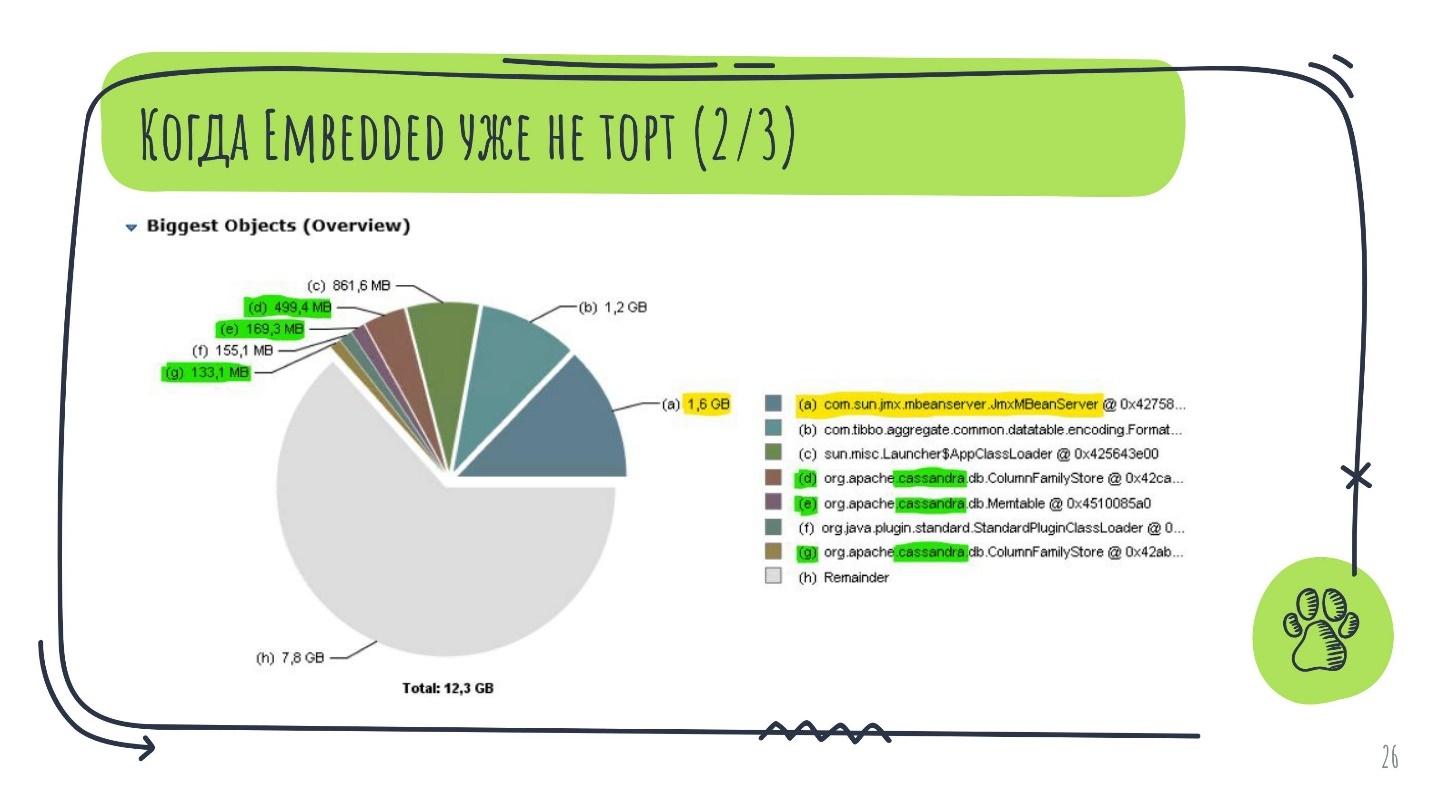
Так распределяется память наиболее крупных объектов из Heap Dump одного Java-приложения. Видно, что в топе присутствуют запчасти от Cassandra, но в сумме они занимают немного. Хотелось бы избавиться от самого крупного куска (выделен желтым), чтобы оптимизировать потребление.
Если заглянуть внутрь него, оказывается, что это JmxMBean сервер, который на 99% состоит из метрик Cassandra. Так она проявляет своё потребление и поведение в embedded режиме.

Такая картина потребления — звоночек к тому, чтобы здесь embedded Cassandra не использовать. Это повод сделать вторую зарубку про гибкое хранение.

Любая IoT-платформа должна предоставлять возможность конечному пользователю выбирать как сам тип хранилища, так и вариант его развертывания.
Как работает этот кейс в целом:
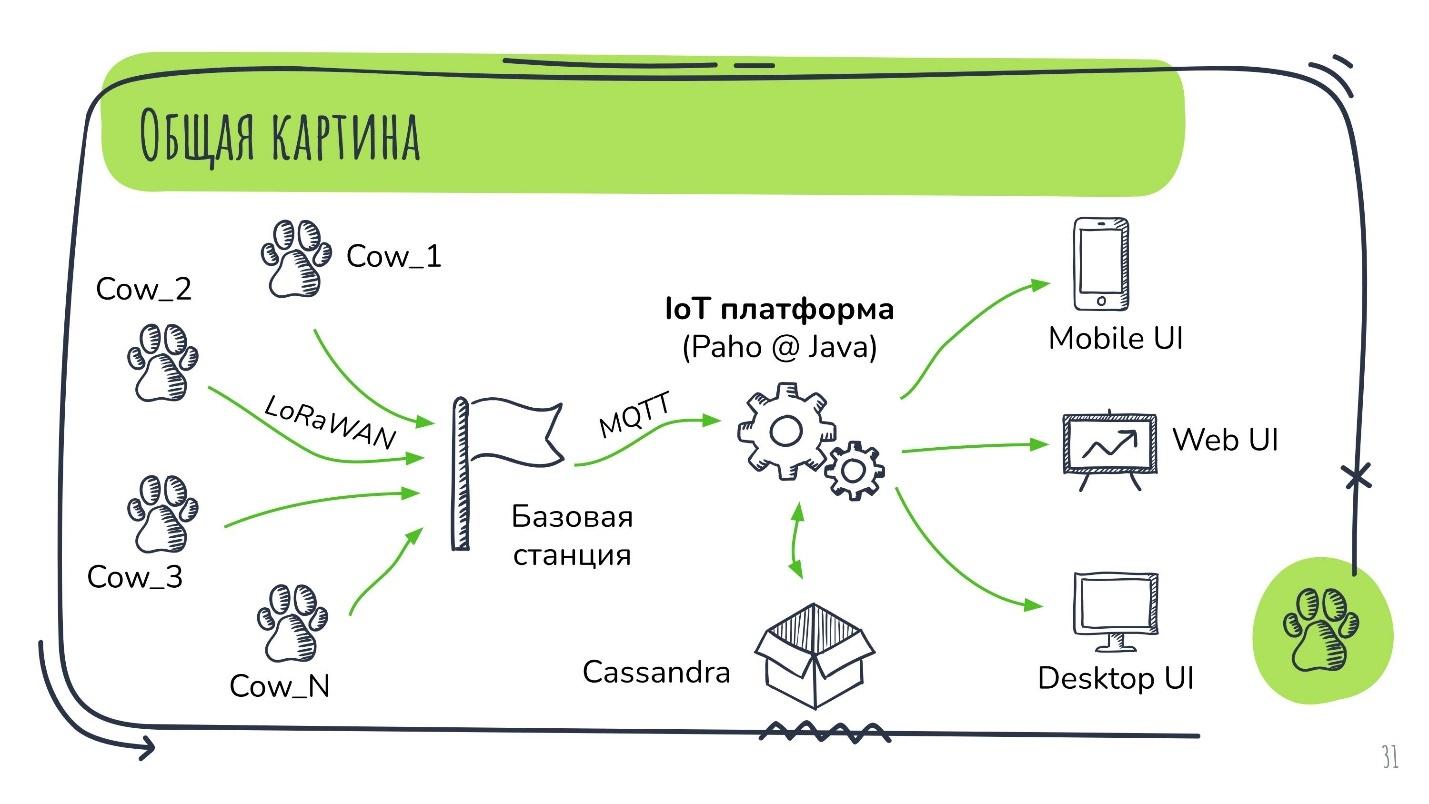
У нас есть парк коров, которые умеют передавать данные по протоколу LoRaWAN на базовую станцию. Она транслирует это всё в протокол уже прикладного уровня MQTT и передаёт это на платформу, где работает Eclipse Paho поверх Java. Всё это складывается в хранилище и затем передаётся на UI.
UI может быть разным. Это зависит от требований заказчика. Бывают web-версии, десктопные виджеты и прочее. В данном кейсе вообще было запилено мобильное приложение «Умный пастух», и в нем реально пастух залипал.

Так что, если увидите, что чувак сидит на стоге сена и тычет в мобильный, не думайте, что он там ВК листает. Он на самом деле на работе следит за флотом.
Приложение было реализовано под основные платформы, backend на AggreGate и получало данные от устройств раз в несколько минут. Этого было достаточно для тех требований.
Путевые заметки
Важен выбор не языка, а его экосистемы.
Основной смысл не в том, какой язык выбрать, а какая экосистема за ним стоит. Где всё это хозяйство разворачивать, насколько оно совместимо с разными платформами и какие библиотеки под него уже есть.
(не)Критичность данных решает многое.
Этот аспект связывает или развязывает нам руки при выборе того хранилища, куда будут валиться все наши данные.
Коровы тоже прыгают.
Не знаю, что делать с этим выводом, но на всякий случай привел.
2. Интеллектуальный анализ машинных данных
Чтобы рассмотреть второй кейс, перенесёмся уже из тёплых степей в восточную Сибирь, на Чаяндинское месторождение в Якутии.

Это месторождение, где добыча нефти производится на суше. Возьму его как пример. На месторождениях такого типа и класса главный агрегат, осуществляющий основную работу — это установка электроприводного центробежного насоса (УЭЦН).

Он состоит из множества узлов, которые обеспечивают откачку пластовой жидкости (воды, нефти, газа) и подъем её наверх. Погружная часть достигает длины 50 м.
Поломка такого агрегата очень дорого обходится. Её нужно диагностировать, вызвать специалистов с большой земли, извлечь агрегат, заказать нужные запчасти, отремонтировать, погрузить снова. И это не считая фактической стоимости простоя. Для таких устройств крайне важно предупредить поломку и сделать всё возможное, чтобы её не было, заранее.
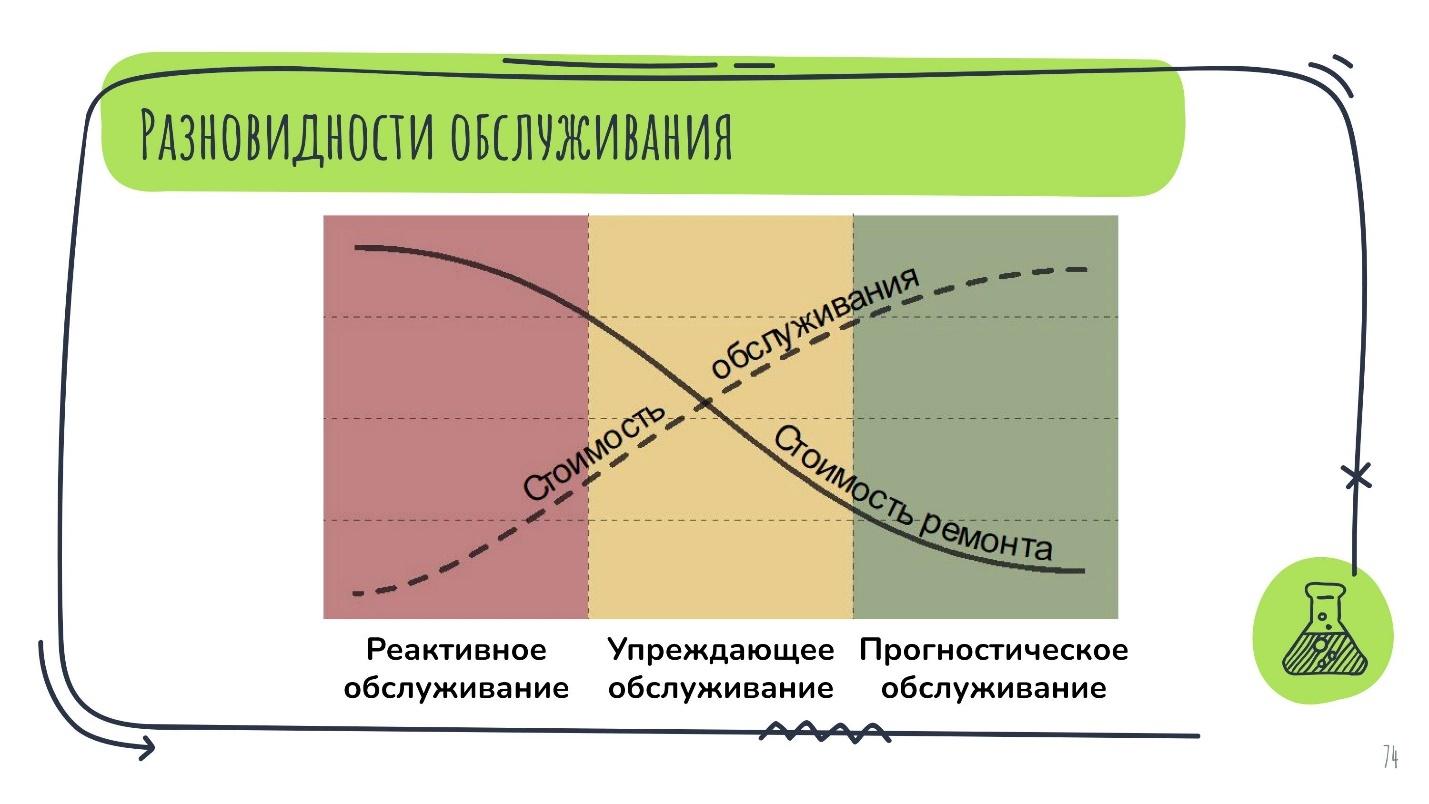
Здесь максимально отходят от реактивного обслуживания — когда среагировали после того как всё сломалось, к прогностическому — когда по косвенным признакам поломки определяют, с какой вероятностью и за какое время выйдет из строя тот или иной узел агрегата.
Но здесь возникает вопрос — причём здесь IoT-платформа? Фишка в том, что все узлы на современных установках — это тоже цифровые устройства, способные передавать свои данные по многочисленным протоколам. Их нужно потреблять, обрабатывать и осуществлять на их основе аналитику, а после – выдачу, то есть, представлять эти вероятности нужным людям для принятия решений о ремонте.
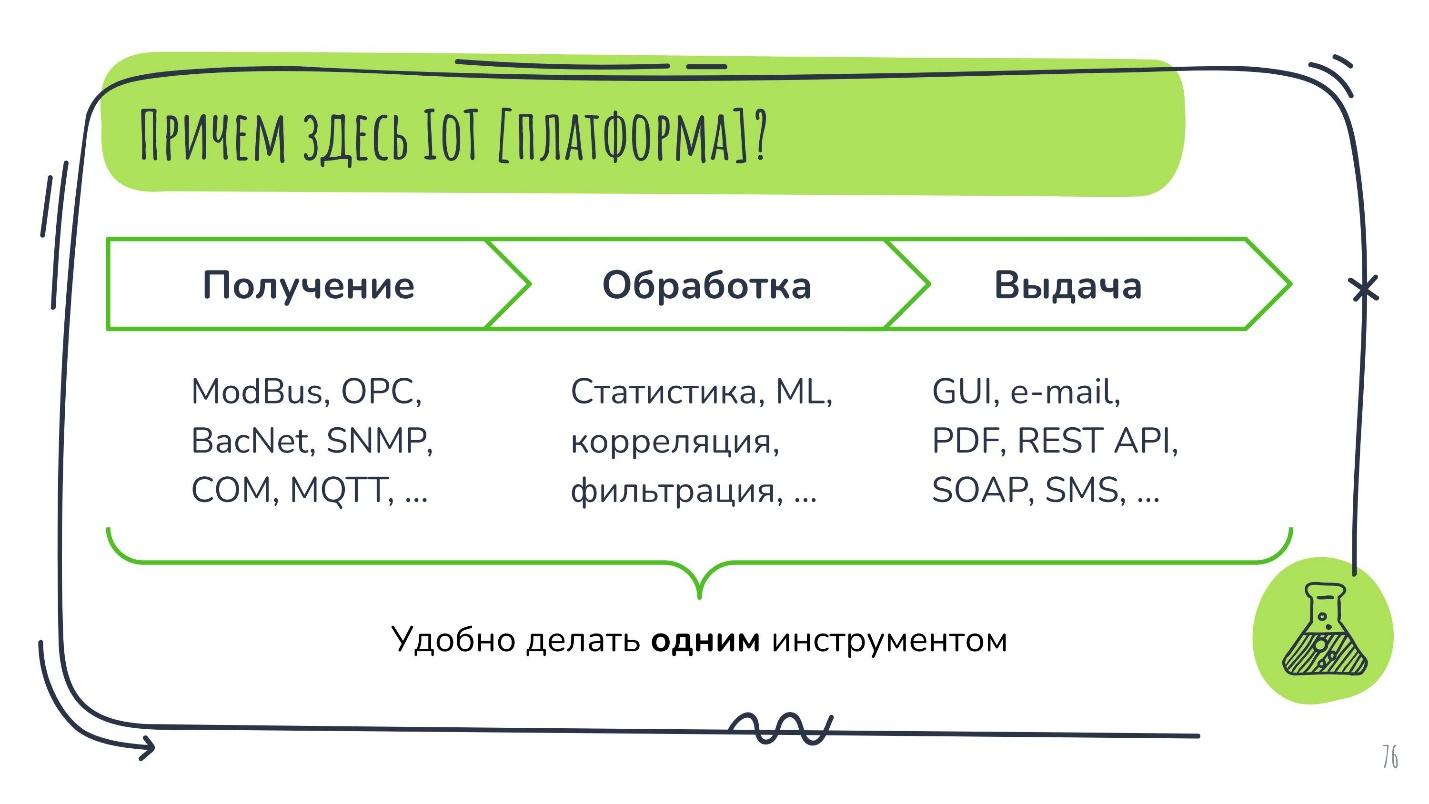
Удобнее это делать единым инструментом, например, на IoT-платформе. Поэтому я здесь представляю этот кейс.
Прогностическое обслуживание в случае с AggreGate реализуется, так:
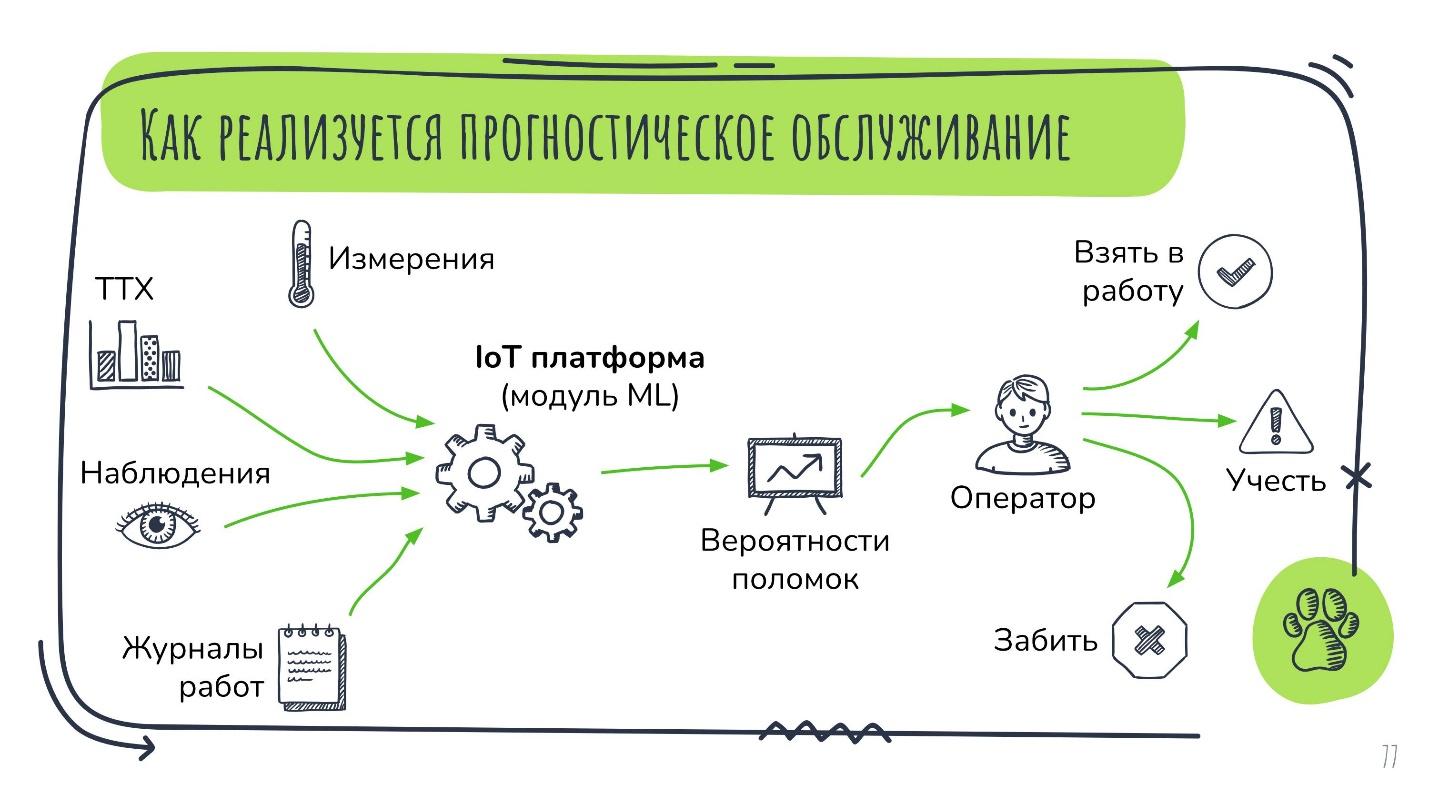
На входе есть набор динамически меняющихся и пополняющихся данных — это измерения, текущие наблюдения. Также есть статичные данные — паспортные характеристики агрегата или его журнал работы за предыдущие периоды. Все они подаются в IoT-платформу, где есть модуль машинного обучения, способный обучаться на этих реальных данных, собранных заранее. На выходе он выдаёт наборы вероятностей поломок в разрезе различных узлов агрегатов.
Затем человек анализирует эти данные и на их основе принимает решения, точнее, как правило, одно из трёх:
взять в работу и осуществить заблаговременную замену того или иного узла;
просто принять проблему во внимание;
вообще проигнорировать.
Присутствие оператора необходимо. В таких кейсах сама модель не может быть полностью автоматизированной, много приходится учитывать за счёт опыта операторов и технологов.
А что под капотом AggreGate?
В AggreGate поддерживаются три типа задач машинного обучения:
регрессия;
классификация;
обнаружение аномалий.
Это реализовано на библиотеке Weka. Её разработали в институте Новой Зеландии и назвали в честь местной нелетающей птички, которая водится только там. Отсюда и название базы знаний — Weka Wiki.
На одной Java не принято делать ML, для этого есть и другие языки, например, Python. Можно загружать в IoT-платформу скрипты и целые модули на Python. Сделано это через JEP, только это не Java Enhancement Proposal, а Java Embedded Python.
Это одна из разновидностей сращивания Java с Python, которая работает через JNI и вызывает под капотом тот самый CPython API. По сути, это обычный Python, который бы мы установили отдельно. Здесь не использован нативный для Java Python (Jython) в основном из соображений производительности. Потому что Python, который сделан на C, существенно быстрее работает.
В данном случае, нам не важно, чтобы пользователь быстро получал обратную связь от минимальных изменений. Обычно приходят готовые скрипты, написанные и отлаженные в отдельной среде, только потом они здесь запускаются. Поэтому такое решение вполне приемлемо.
Для работы со структурами данных (матрицами, кортежами и пр.) используется библиотека Pandas.
Это повод отметить ещё один пунктик в общем бублике про IoT-платформу:
Чтобы платформа была переиспользуемой в разных задачах, у неё должен быть языковой интероп. Это возможность вызывать из Java скрипты или модули на других языках и то же самое в обратную сторону.
Всё это технические подробности под капотом, а что видит снаружи конечный пользователь?
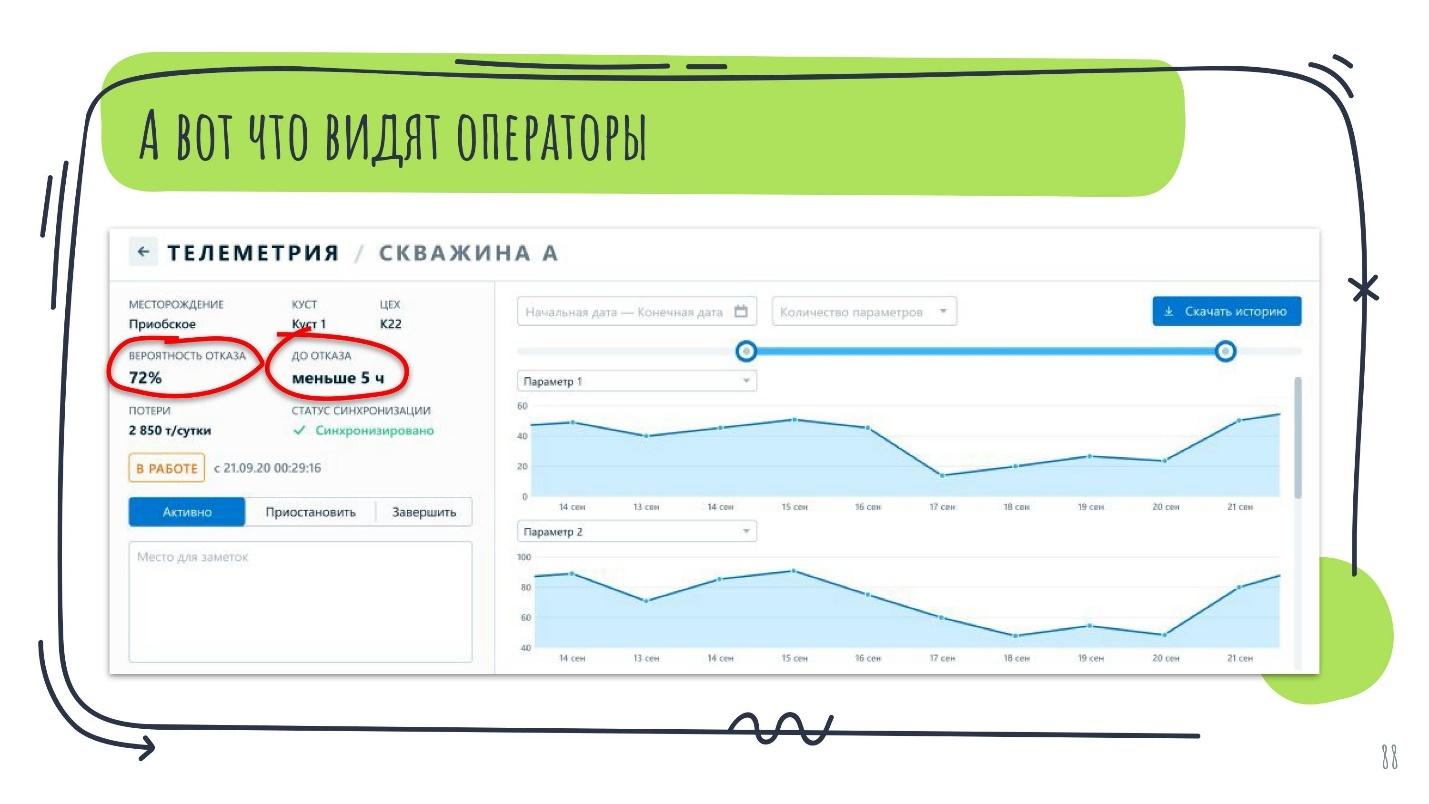
Оператор или технолог на нефтяном месторождении видит данные в разрезе по каждому показателю, а также такие параметры как:
вероятность отказа;
максимальное расчётное время, которое осталось до отказа.
Путевые заметки
Прогностические ТО и ремонт применяются не от хорошей жизни;
И не потому, что нефтяным компаниям деньги девать некуда, просто они не хотят эти деньги терять. Это действительно очень дорого и важно.
Обработка машинных данных — богатая область для методов ML;
Машинное обучение хорошо зарекомендовало себя в области обработки подобных данных.
Искусственный интеллект — это хорошо, но
Михалыч знает лучшегибридные модели надёжнее.
В гибридных моделях решение принимается на основе обучаемого модуля с предобработкой человеком. Эти требования базовые по умолчанию, и не потому, что не смогли сделать лучше, просто человеческое участие здесь по-прежнему остаётся обязательным.
Я представил два разрозненных кейса. Упомянул, как получать данные с устройств, как их обрабатывать, затронул тему визуализации. Если интересно посмотреть, как ещё можно визуализировать производственные процессы, рекомендую поиграться с демкой, которую запилили наши low-code инженеры.

Здесь можно почувствовать себя оператором на заводе по производству сахара из свеклы. На входе задаёте, сколько у вас тонн свеклы, и прямо по шагам видите обработку на разных этапах. Эта игрушка сделана по мотивам реального проекта, где совместно с корпорацией РусАгро автоматизировали производственную линию по производству сахара.
Кстати, визуализация — это тоже отдельный кусочек IoT-платформы:
3. Нормализация, или как связать несвязуемое
Эти отдельные кусочки не отвечают на вопрос, как собирать интеграционные решения, которые охватывали бы всё вместе.
Например, мы хотим получить полноценную цифровую шину предприятия, чтобы туда можно было сваливать данные со всех узлов, участков, устройств. Потом отправлять их в разные подразделения на постобработку, дополнительную аналитику и т.д. Должен быть единый интерфейс, нечто связующее эти отдельные модули. Нужна нормализация данных, которая и станет тем самым клеем или связкой.

Идея проста — информация снаружи поступает в разном виде. Внутри, в ядре она нормализованная, а когда выдаётся наружу, то конвертируется из этого представления в конечное.
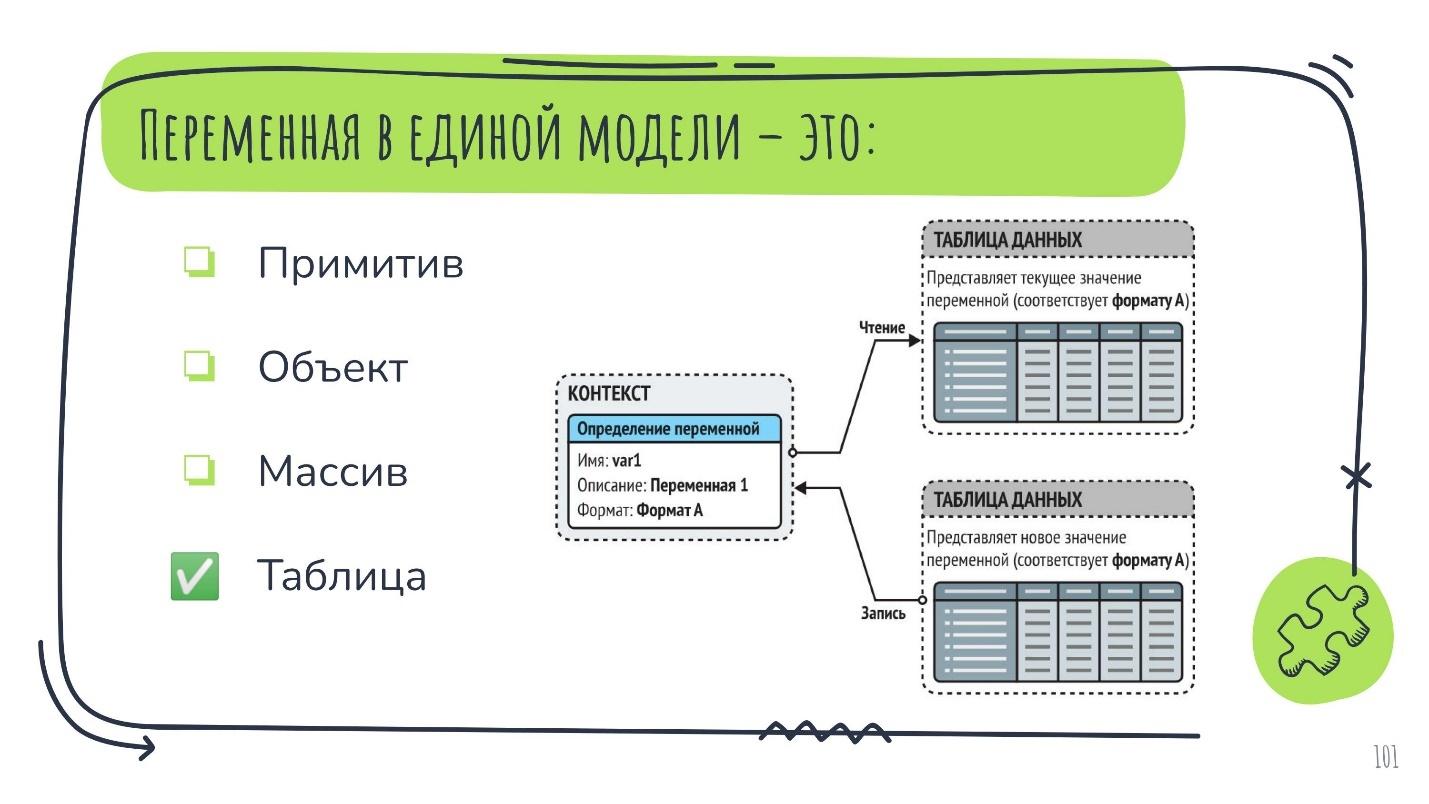
В случае с AggreGate это называется «единая модель данных». Она содержит нормализованные данные и организует их, в так называемые, «контексты». В каждом контексте, который как-то представляет устройство в системе, есть:
функции — это то, что мы можем сделать с устройством, что можно вызвать у него;
события — то, что происходит с устройством, что оно может вызвать у нас;
переменные — его данные, свойства, состояния или аргументы событий и функций.
Чтобы представить такие переменные на программном уровне, могут использоваться разные : примитив, объект, массив, таблица. У каждого есть свои плюсы и минусы, своя гибкость и профиты по производительности. В AggreGate выбран самый тяжелый вариант — это таблица. Каждая переменная по дефолту представлена целой таблицей.
Это может выглядеть как большой overhead, ведь таблица — это не только двумерная структура данных. Можно валидировать каждую колонку отдельно на соответствие типу, на общее количество строк. Поддерживается вложенность этих таблиц.
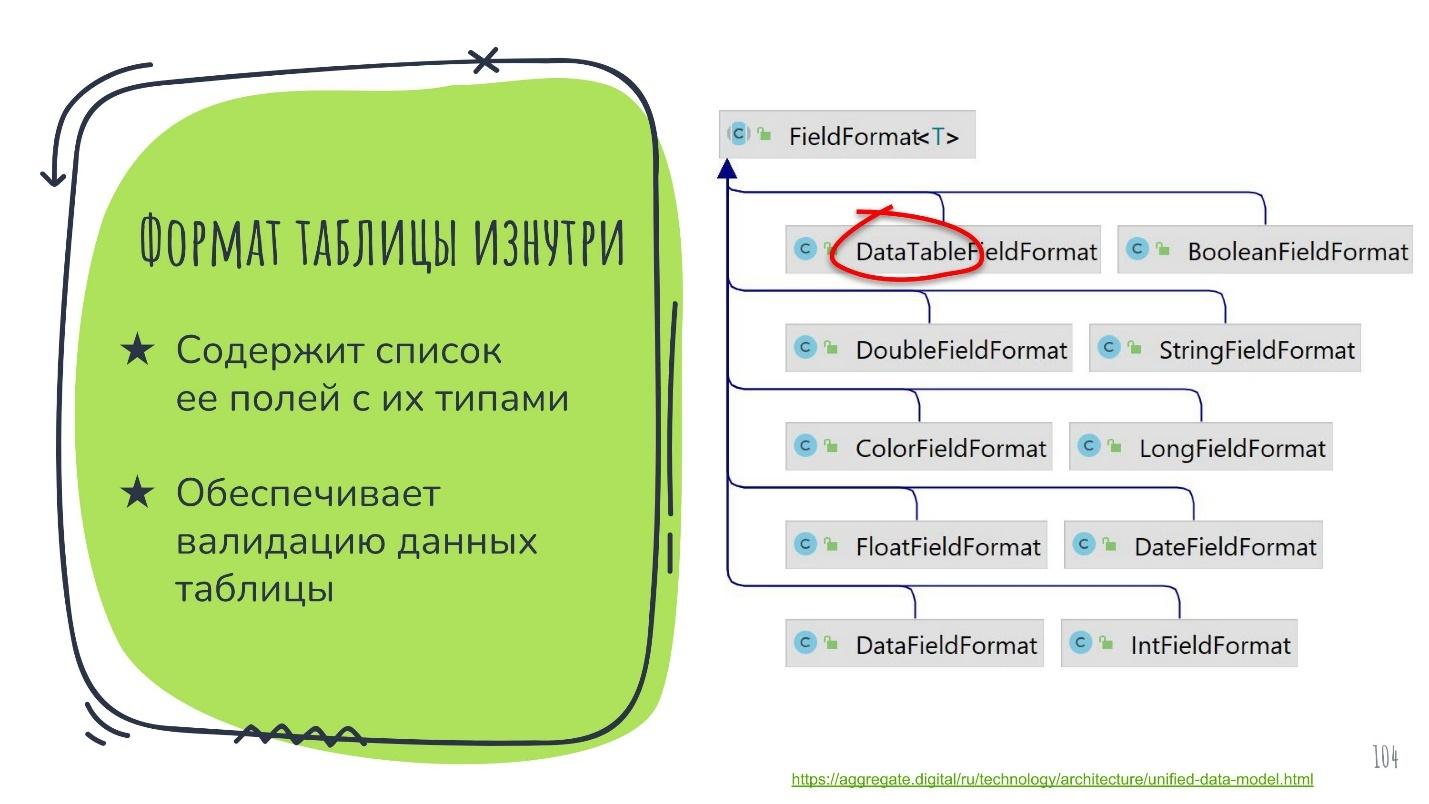
Однако такая структура полностью себя оправдывает. Во-первых, это позволяет представить любой другой тип данных. Например, если нужно представить скаляр, мы сводим табличку до единой ячейки. Для однотипного кортежа, берём одну колонку таблицы, для разнотипного — одну строчку. Во-вторых, всё это нивелируется за счёт оптимизаций.
За чей счёт банкет?
В частности, за счёт кэширования. Чтобы данные быстрее считывались, используется два уровня кэша:
Транзиентный кэш в оперативной памяти (на SoftReference).
Кто особо не знаком с Java поясню, SoftReference — это ссылки, которые подчищаются сборщиком мусора, как только памяти начинает не хватать. Часто используются как раз в кэшах. Пока память есть, они там хранятся. Как только памяти начинает не хватать, garbage collector сам их подчищает.
Персистентный кэш.
На выбор того, кто настраивает платформу, может быть представлен на файловой системе или на любой реляционной базе, для которой есть JDBC-драйвер (RDBMS), либо в NoSQL хранилище (Cassandra).
Это то, что касается хранения. Касаемо передачи, скорость достигается за счёт собственной строковой сериализации (не JSON, не XML), которая подвергается прозрачному сжатию на лету. Так даже тяжеловесные таблицы шустро передаются в больших объемах.
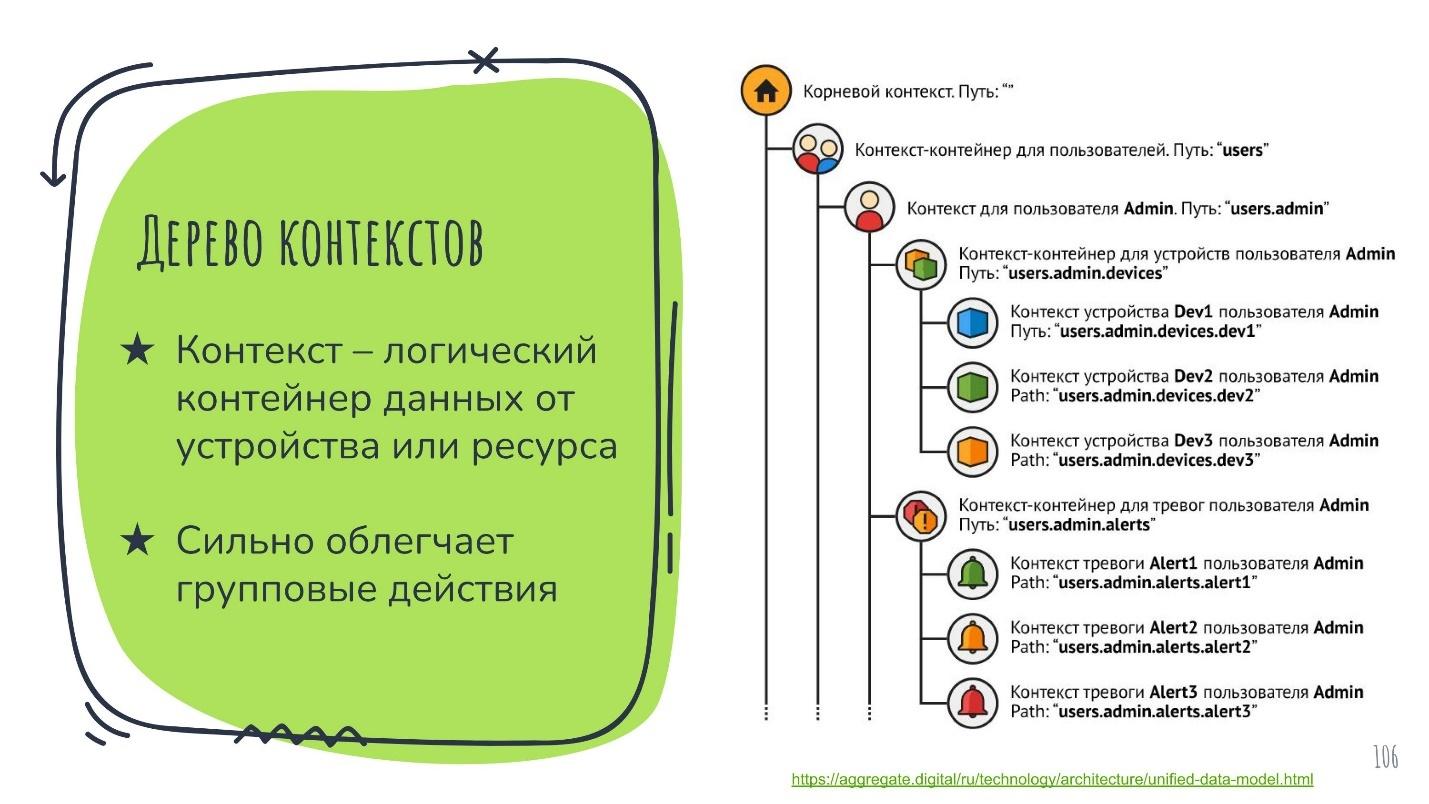
Перейдём к контекстам. Контекст — это логический контейнер, который упрощает групповые операции над устройствами. Допустим, мы хотим задать одни и те же настройки всем датчикам парковки в конкретном ряду. Выделяем их и назначаем. Но это не всё. Представление контекстами позволяет решать задачи масштабирования.
Если нам нужно заставить один сервер работать например, с десятками тысяч устройств, то подключать непосредственно все эти устройства к нему опрометчиво. Они его повалят своими данными. Например, если это нагруженные сетевые маршрутизаторы. Чтобы решить эту проблему, в AggreGate есть так называемая «распределённая архитектура».

Это когда мы на каждый сервер направляем только умеренное подмножество этих устройств. Всё, что он с них собрал и скомпоновал, монтируем как поддерево контекстов к другому центральному серверу, который всё вместе собирает. Центральный сервер не работает напрямую с устройствами, а только собирает их аватары. Это гораздо легче, так он может затащить весь парк устройств, а быть может, и больше.
Это же может сочетаться с отказоустойчивым кластером. Когда рядом с каждым из этих серверов установлен failover сервер, который смотрит на мастера. Если тот отваливается, подменяет его на лету.
Это нас подводит ещё к одному кусочку бублика — нормализации:
Реальные примеры применения единой модели данных
Казалось бы, зачем эти абстракции из универа, если они не имеют отношения к реальному миру? На самом деле имеют, и самое непосредственное.

В Нижнем Новгороде есть большое производственное предприятие, на котором на IoT-платформе сделан мониторинг загрязнения воздуха различными газами. Переменные, которые получаются с датчиков по измерению содержания газов в воздухе, отлично ложатся на скаляры, то есть на переменные в терминах единой модели данных — те самые таблички из одной ячейки.
Второй пример чуть сложнее.

Это промышленный порт в Индии, с кучей стационарных и подвижных объектов. Все они постоянно сообщают своё географическое положение. Координаты — это типичный пример кортежа, то есть двух значений, хорошо укладывающихся в одну переменную.
Пример посложнее.
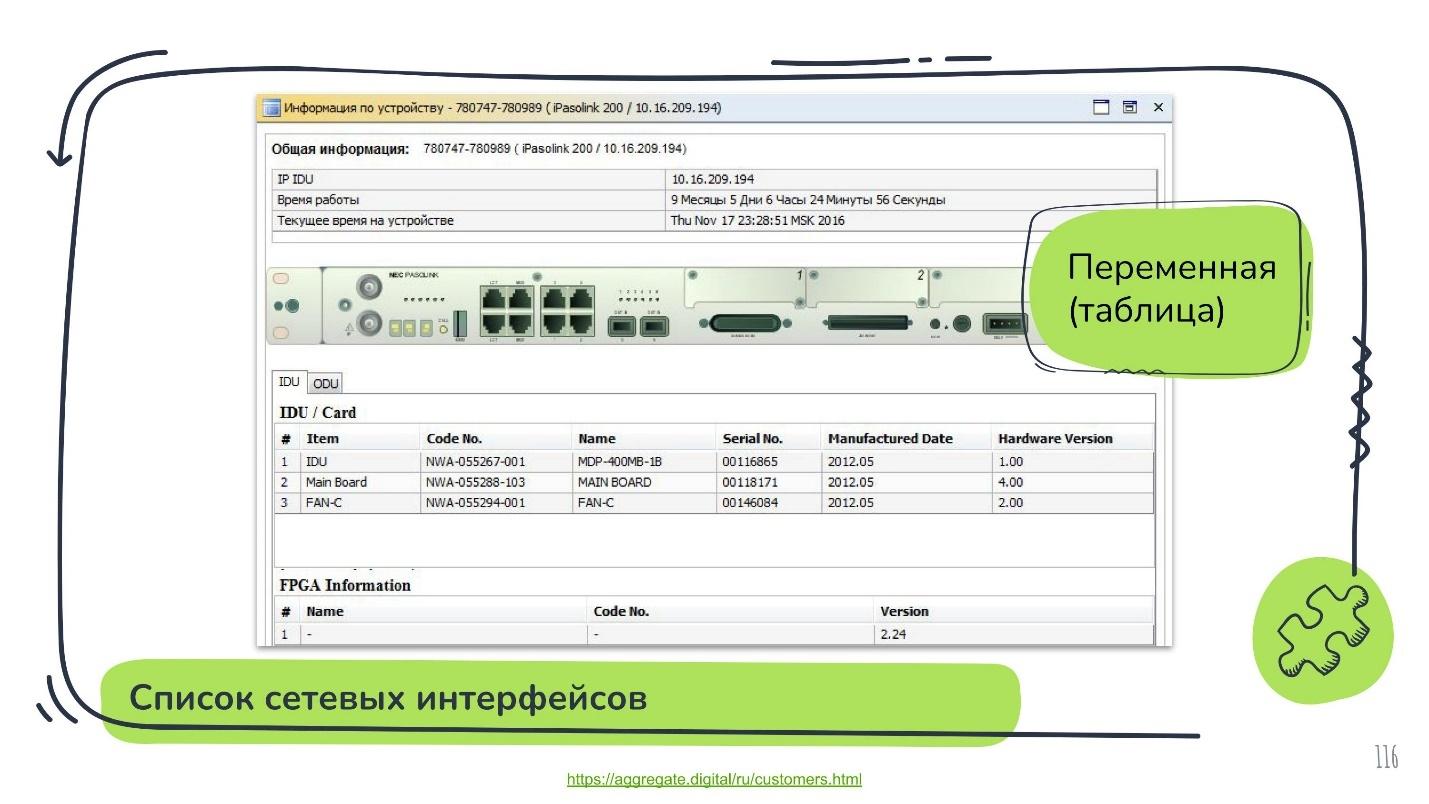
Один из провайдеров радиорелейной связи в России использует IoT-платформу, чтобы мониторить свои маршрутизаторы. Содержимое переменных iftable — то, что мы видим, когда вбиваем ifconfig или ipconfig у себя в консоли, в сериализованном виде передаются в IoT-платформу. Это в чистом виде таблица. Здесь даже подгонять и подтюнивать ничего не надо.
Есть другой пример:

Федеральная сеть автозаправочных станций купила умные кофемашины. Они напичканы всевозможными датчиками. Один из них измеритель окончания зерна. Там реализована такая логика — когда заканчивается запас зерна в машине, датчик проверяет наличие сырья в танкере на самой станции. Если есть, то оператору на планшет приходит уведомление, что надо досыпать кофе. Если нет, то автоматически формируется заявка в ближайший пункт поставки. Сам факт исчерпания запаса — это событие, которое происходит с устройством. Мы обрабатываем его в единой модели данных с аргументом, например, адресом машины.
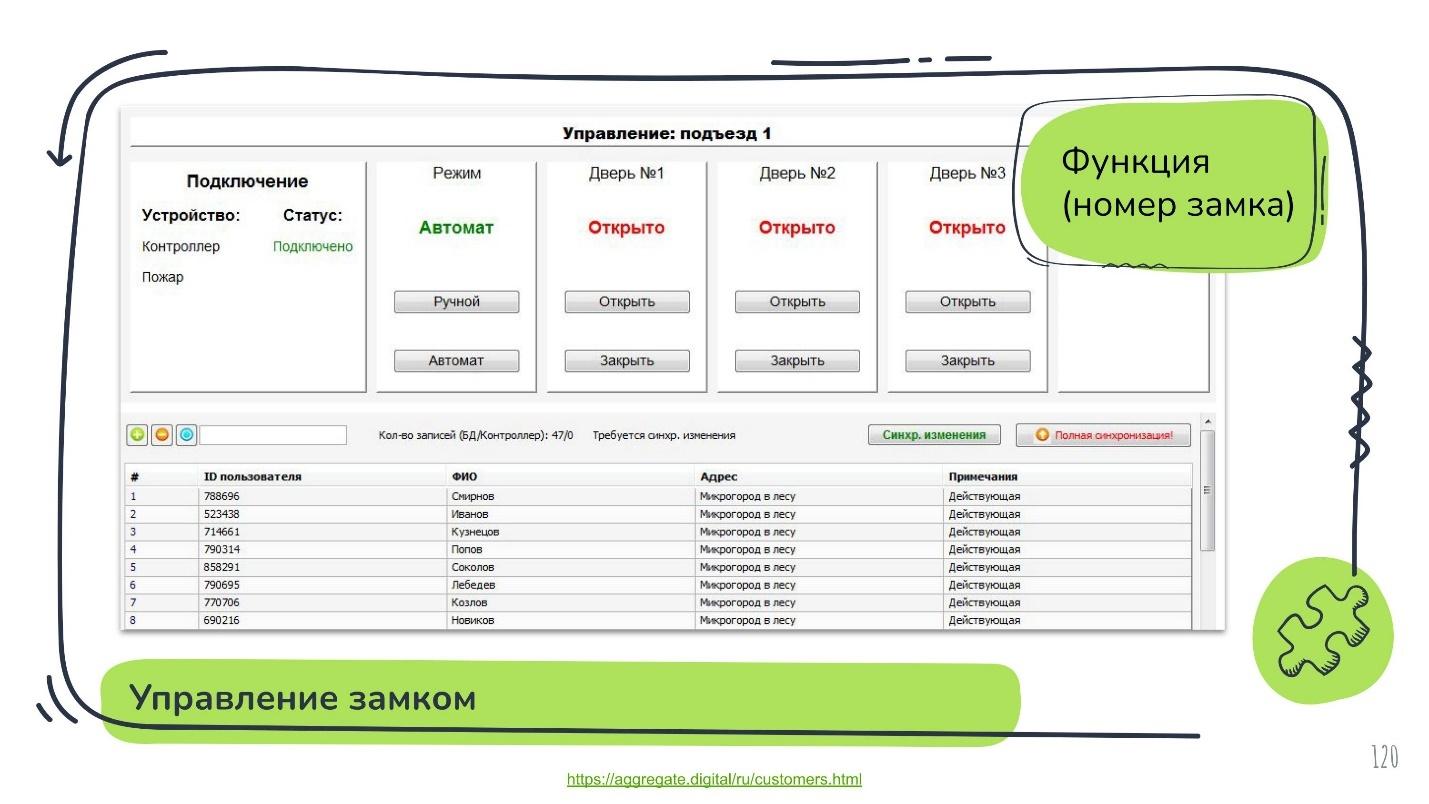
Пример в обратную сторону. В Подмосковье есть престижный жилой комплекс. Он оснащён полностью автоматизированной системой управления инфраструктурой. Можно управлять всеми дверями, замками, калитками. Управление — это отличный пример функции, когда оператор может выбрать любой замок, сказать ему «откройся» или «закройся». Здесь аргументом будет номер замка или его IP.
Добавляю последний кусочек — модульность.
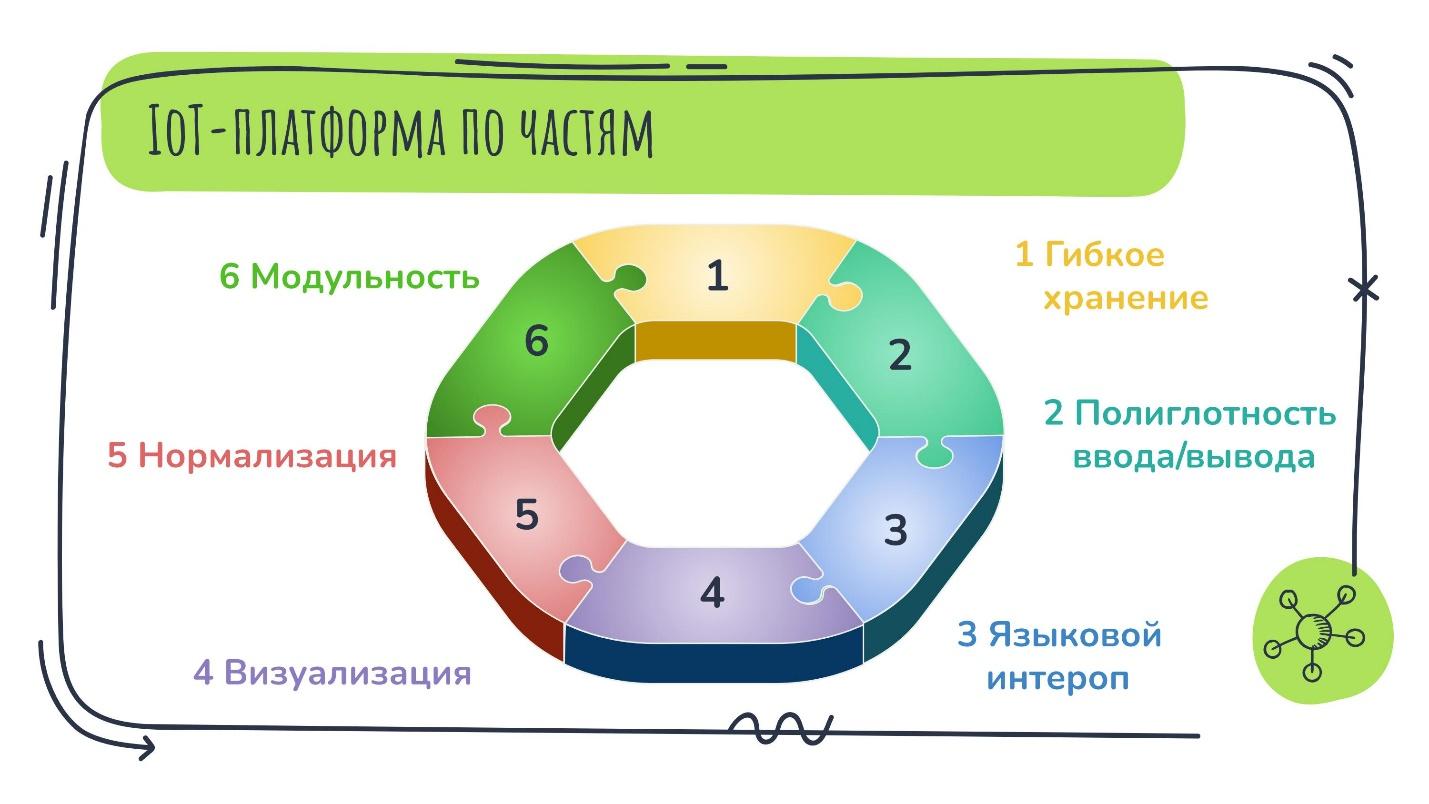
Я представил разрозненные примеры. Для них должны быть предусмотрены свои модули в IoT-платформе. Поэтому она и должна быть именно модульной, чтобы не таскать за собой весь набор кубиков Лего, а использовать для конкретной задачи только маленькое подмножество из них.
Путевые заметки
Нормализация — основа гибкости платформы. Ею определяется, насколько легко кубики совмещаются между собой.
Избыточность базовых структур данных оправдана, даже если это матрицы или таблицы.
Большинство устройств можно представить в единой модели данных.
Выводы
Наша экскурсия подошла к концу. Я привел несколько кейсов применения промышленного интернета вещей. Сельское хозяйство на примере NoSQL-хранилища, нефтегазовая промышленность на примере применения машинного обучения. Каждый кейс я обобщил единой моделью данных и переменных.
Если хочется получше представить, где и как применяются устройства IoT, как промышленные, так и бытовые, рекомендую источники:
О типах IoT-устройств вообще (англ.)
Сайт изначально был задуман как маркетплейс, чтобы люди там друг друга находили и заключали сделки. Чтобы это сделать, они реализовали хорошую иерархическую схему всех областей применения IoT.
О значении терминов в IoT (рус)
Если многие слова показались незнакомыми, а хочется узнать побольше о терминологии, то на этом портале есть хороший справочник по терминам на русском.
Если не удалось что-то нагуглить, на помощь приходит привычный программистам StackOverflow, но в двух ипостасях:
Уже скоро (24 и 25 ноября 2022) начнется HighLoad++ в Крокус-Экспо Москва. Если вы еще не успели приобрести билеты или посмотреть программу, переходите на официальный сайт. 1 октября будет повышение цены, пока ещё есть время оформить билет по сниженному прайсу.
