В 2019 году в ОТР появился новый центр по работе с искусственным интеллектом (ЦИИ). Изначально он создавался как некий эксперимент по работе с новыми технологиями. Однако довольно скоро получил первую боевую задачу по автоматизации технической поддержки пользователей ГИИС «Электронный бюджет». Об этапах внедрения ИИ рассказали директор дирекции технологий и компетенций Анатолий Безрядин и сотрудники ЦИИ, принимавшие участие в амбициозном проекте.
Обращения в техподдержку представляют собой сложные технические заявки со множеством переменных — раздел, подсистема, нормативная документация, счёт и так далее. В некоторых случаях текст заявки мог составлять до 20 строк текста. Понять контекст подобной заявки порой сложно даже человеку, а для ИИ это и вовсе может стать неразрешимой задачей.
Перед нами стояла задача научить искусственный интеллект «понимать» текст заявки для последующей категоризации. Исходя из контекста запроса, ИИ должен был предложить пользователю подходящую по смыслу статью из базы знаний. Это облегчило бы работу технической поддержки, когда элементарные и часто встречающиеся проблемы решались силами пользователей после прочтения подсказок. Кроме того, хотелось автоматизировать поиск дублирующих друг друга тикетов, чтобы вовремя их удалять.
К списку трудностей добавились сжатые сроки для выполнения задачи, а также ограничения по используемым программным решениям. Так как мы работаем с государственными заказчиками, то можем использовать либо собственные наработки, либо open-source-решения.
Выбор типа нейронных сетей
Решение задачи по обработке обращений в техническую поддержку ГИИС «Электронный бюджет» мы начали с выбора подходящего типа нейронной сети. В качестве критериев выбрали скорость обучения, возможность масштабирования и качество обработки текста. Выбирали из вариантов:
логистическая регрессия;
решающие деревья;
метод опорных векторов;
рекуррентные нейронные сети;
модели типа GPT;
модели типа BERT.
Первые три модели не могли проводить анализ последовательности и сложных областей, обладали низкой точностью и не умели переносить знания между доменами. От них мы отказались ещё на предварительном этапе обсуждений.

Необходимую точность показывали только модели типа GPT и BERT. Но у первой была низкая ресурсоэффективность, поэтому остановились на последней. К тому же модели типа BERT уже хорошо известны в отрасли и их использует, например, Google. Наличие развитого сообщество в перспективе позволяет оперативно решать возникающие вопросы.
Поиск подходящих библиотек
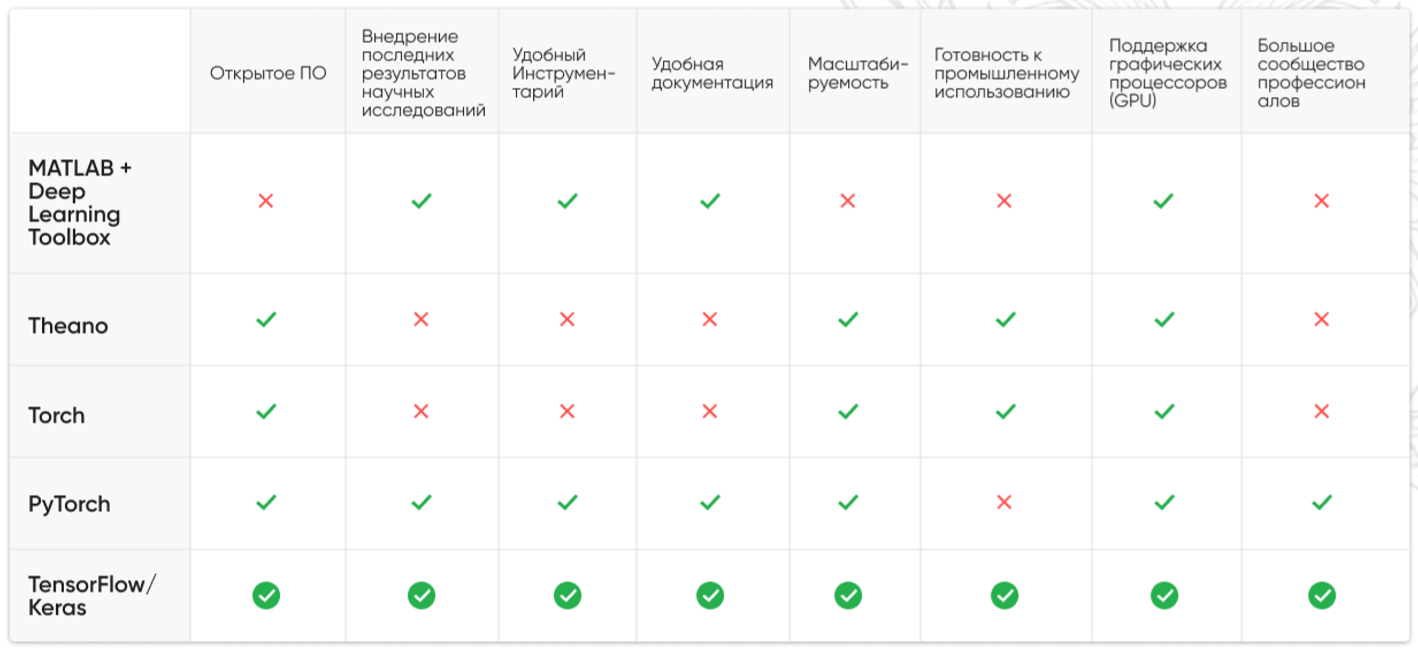
При поиске библиотеки для машинного обучения мы отталкивались от следующих критериев:
open-source-проект;
использование последних научных достижений;
удобный инструментарий и документация;
масштабируемость;
готовность к промышленному использованию;
поддержка графических процессоров;
большое сообщество профессионалов.
У нас получился такой список библиотек:
MATLAB + Deep Learning Toolbox;
Theano:
Torch;
PyTorch:
TensorFlow/Keras.
MATLAB — известный пакет прикладных программ для решения задач технических вычислений от The MathWorks. Изначально в нём не заложена функциональность по работе с нейронными сетями. Однако проблема решается надстройкой Deep Learning Toolbox. Она используется для проектирования, внедрения и предварительного обучения нейросетей.
Существенным минусом этого сочетания является закрытость кода. Особенность работы с госпроектами требует открытого кода, чтобы можно было убедиться в его безопасности. Кроме того, известно о проблемах с масштабируемостью и промышленным использованием.
Theano — библиотека для глубокого обучения и быстрых численных вычислений в Python. Её разработали в Монреальском институте алгоритмов обучения. Официально поддержка библиотеки закончена, но создатели поддерживают продукт для сохранения работоспособности.
К сожалению, Theano не предлагает удобной документации и инструментария. После отказа от развития библиотеки говорить о применении современных наработок в области нейросетей также не приходится.
Torch — библиотека для глубинного обучения нейронных сетей и научных расчётов. Создана группой энтузиастов на языке Lua. Она также применяется для проектов компьютерного зрения, обработки изображений и видеофайлов.
Как и в случае с Theano, библиотека Torch сейчас находится в полузаброшенном состоянии. Последние глобальные обновления кода были проведены четыре года назад. Недостатки её использования совпадают с предыдущим проектом.
PyTorch — библиотека для машинного и глубинного обучения от энтузиастов. Как понятно из названия, она создана на базе Torch. Однако написано уже на понятном для большинства разработчиков языке Python.
У PyTorch большое количество поклонников, она отличается полной документацией и удобным инструментарием, хорошо масштабируется. Но к промышленному использованию пока не готова.
TensorFlow — библиотека для машинного обучения, разработанная компанией Google. Она хорошо сочетается с надстройкой Keras, которая нацелена на оперативную работу с нейросетями глубинного обучения. Обе библиотеки регулярно обновляются и предлагают новые возможности для разработчиков.
Сочетание TensorFlow и Keras оказалось идеальным для решения нашей задачи. Они разработаны мировыми передовиками по работе с искусственным интеллектом, имеют понятную и богатую документацию, а также большое комьюнити разработчиков. Поэтому реализовывать проект мы начали с помощью инструментов Google.
ИИ в бою
Для работы с библиотеками Google TensorFlow и Keras у нас уже был готовый датасет из более чем миллиона обращений. Для узкоспециализированной системы — это большая цифра, которая равняется 10 годам работы службы технической поддержки.
После первоначальной настройки мы получили точность 75% в определении контекста запроса. Для повышения точности удаляли шум в текстах. Для этого с помощью регулярных выражений находили определённые паттерны и избавлялись от них. Занимались оптимизацией архитектуры модели. Всё это позволило повысить точность до 85%.
ИИ ускорил работу с обращениями в службу технической поддержки ГИИС «Электронный бюджет». Пользователи оценили удобство и скорость реакции на запросы. Обслуживающие специалисты смогли сконцентрироваться на более сложных заявках по решению проблем.
Для центра по работе с искусственным интеллектом это была дебютная задача, с которой удалось эффективно справиться. Сейчас команда решает задачи по внедрению нейросетей и машинного обучения на других проектах, используя выработанный алгоритм.
