Всем доброго!
Мы возвращаемся к нашей любимой традиции — раздача полезностей, которые мы собираем и изучаем в рамках наших курсов. Сегодня у нас на повестке дня курс по DevOps и один из его инструментов — Kubernetes.
Недавно мы создали распределенную систему планирования задач (cron jobs) на базе Kubernetes — новой, захватывающей платформы для оркестрации контейнеров. Kubernetes становится все популярней и дает много обещаний: например, инженерам не придется переживать, на каком устройстве запущено их приложение.
Распределенные системы сложны сами по себе, а управление сервисами на распределенных системах — одна из сложнейших проблем, с которыми сталкиваются команды управления. Мы очень серьезно относимся к вводу нового программного обеспечения в производство и обучению его надежному управлению. В качестве примера важности управления Kubernetes (и почему это так сложно!), почитайте отличный постмортем часового перебоя в работе, вызванного багом в Kubernetes.
В этом посте мы объясним, почему выбрали именно Kubernetes. Изучим процесс его интегрирования в существующую инфраструктуру, метод укрепления доверия (и улучшения) надежности нашего Kubernetes кластера и абстракцию созданную на основе Kubernetes.

Kubernetes — распределенная система планирования программ для запуска в кластере. Вы можете сказать Kubernetes запустить пять копий программы, и он динамически запланирует их в ваших рабочих нодах. Контейнеры должны увеличить утилизацию, тем самым экономят средства, мощные примитивы развертывания позволяют постепенно выкатывать новый код, а Security Contexts и Network Policies позволяют безопасно запускать multi-tenant рабочие нагрузки.
В Kubernetes встроено множество различных возможностей планирования. Можно планировать длительные службы HTTP, daemonsets, запущенные на всех машинах вашего кластера, задачи, запускающиеся каждый час, и другое. Kubernetes представляет собой даже больше. И если вы хотите это узнать, посмотрите отличные выступления Kelsey Hightower: можно начать с Kubernetes для сисадминов и healthz: Перестаньте заниматься реверс-инженерингом приложений и начните наблюдать их изнутри. Не стоит забывать и про хорошее сообщество в Slack.
Каждый инфраструктурный проект (я надеюсь!) начинается с потребности бизнеса, и наша задача — улучшить надежность и безопасность существующей системы планирования cron job, которая уже есть. Наши требования следующие:
И вот несколько причин, почему мы выбрали Kubernetes:
Раньше в качестве планировщика задач мы использовали Cronos, но он перестал удовлетворять нашим требованиям надежности и сейчас почти не поддерживается (1 коммит за последние 9 месяцев, и последний раз pull request был добавлен в марте 2016 года). Поэтому мы решили больше не вкладываться в улучшение нашего существующего кластера.
Если вы рассматриваете Kubernetes, имейте в виду: не используйте Kubernetes просто потому что, так делают другие компании. Создание надежного кластера требует огромного количества времени, а способ его использования в бизнесе не всегда очевиден. Инвестируйте ваше время с умом.
Когда дело доходит до управления сервисами, слово “надежный” не имеет смысла само по себе. Чтобы говорить о надежности, сначала нужно установить SLO (service level objective, то есть целевой уровень сервиса).
У нас было три основных задачи:
Это означало несколько вещей:
Базовый подход к созданию первого Kubernetes кластера заключался в создании кластера с нуля, без использования инструментов вроде kubeadm или kops. Мы создали конфигурацию с помощью Puppet, нашего стандартного инструмента управления настройкой. Создание с нуля привлекало по двум причинам: мы могли глубоко интегрировать Kubernetes в нашу архитектуру, и мы приобрели широкие знания его внутреннего устройства.
Построение с нуля позволило нам интегрировать Kubernetes в существующую инфраструктуру. Мы хотели цельную интеграцию с нашими существующими системами логирования, управления сертификатами, секретов, сетевой безопасности, мониторинга, управления инстансами AWS, развертывания, прокси баз данных, внутренних DNS серверов, управления настройками, и многими другими. Интеграция всех этих систем иногда требовала творческого подхода, но, в целом, оказалась проще потенциальных попыток заставить kubeadm/kops делать то, что нам от них нужно.
Мы уже доверяем и знаем, как управлять существующими системами, поэтому хотели продолжить их использовать в новом Kubernetes кластере. Например, надежное управление сертификатами — очень сложная проблема, но у нас уже сейчас есть способ ее решения. Нам удалось избежать создания нового CA для Kubernetes благодаря грамотной интеграции.
Мы были вынуждены понять, как именно настраиваемые параметры влияют на нашу установку Kubernetes. Например, было использовано более дюжины параметров для настройки сертификатов/CA аутентификации. Понимание всех этих параметров облегчило отладку нашей установки при нахождении проблем с аутентификацией.
В самом начале работы с Kubernetes ни у кого в команде не было опыта его использования (только для домашних проектов). Как же прийти от “Никто из нас никогда не использовал Kubernetes” к “Мы уверены в использовании Kubernetes на продакшне”?
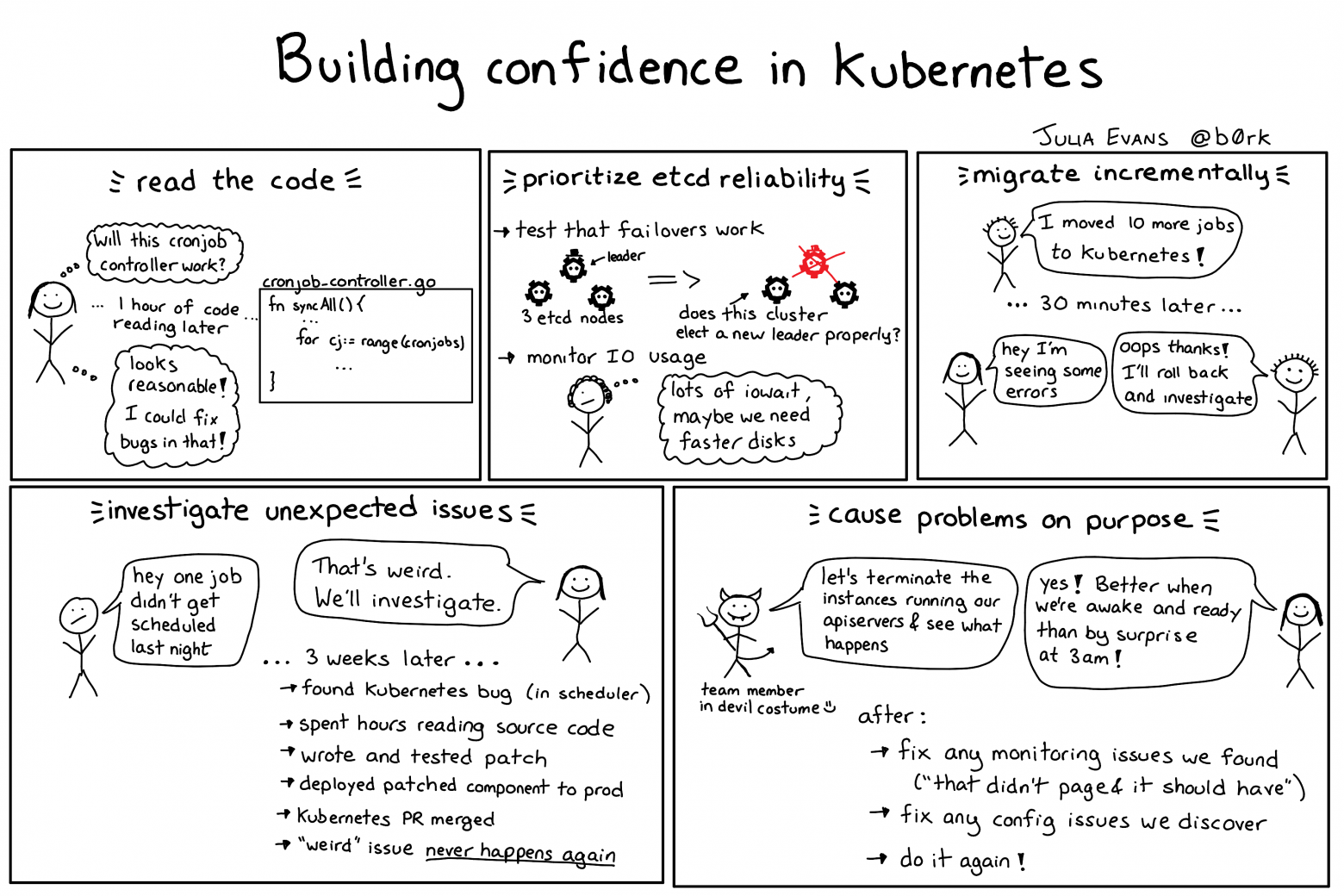
Мы спросили несколько человек из других компаний об их опыте с Kubernetes. Все они использовали его по-разному и в разных окружениях (для запуска HTTP сервисов, на голом железе, на Google Kubernetes Engine и т.д.).
Когда речь идет о больших и сложных системах как Kubernetes, особенно важно думать именно о ваших кейсах применения, экспериментировать, находить уверенность в вашем окружении и решать за себя. Например, не стоит после чтения этого поста решать “Ну, в Stripe успешно пользуются Kubernetes, значит и мы сможем!”.
Вот что мы узнали из бесед с различными компаниями, управляющих кластерами Kubernetes:
Беседы с другими компаниями, конечно, не дали четкого ответа, подходит ли нам Kubernetes, зато обеспечили нас вопросами и поводами для беспокойств.
Мы планировали сильно зависеть от одного компонента Kubernetes — контроллера cron job. В то время он находился в альфе, что стало небольшим поводом для волнения. Мы проверили его на тестовом кластере, но как можно сказать наверняка, будет ли он нас устраивать на продакшне? К счастью, весь код функционала контроллера состоит из 400 строк Go. Чтение исходного кода быстро показало, что:
Базовая логика была проста для понимания. Что более важно, если бы в контроллере обнаружился баг, скорее всего мы бы смогли его починить самостоятельно.
Перед тем как начать строить наш кластер, мы провели нагрузочное тестирование. Нас не беспокоило количество нодов, с которыми мог справиться кластер Kubernetes (планировали разворачивать около 20 нодов), было важно убедиться, что Kubernetes способен выдерживать столько задач, сколько нам нужно (около 20 в минуту).
Мы провели тест на трёхнодовом кластере, где было создано 1000 cron jobs, каждая из которых запускалась раз в минуту. Все задачи просто запускали bash -c 'echo hello world'. Мы выбрали простые задачи, потому что хотели протестировать возможности планирования и оркестрации кластера, а не его общую вычислительную мощность.
Тестовый кластер не смог выдержать 1000 задач в минуту. Мы выяснили, что каждый нод запускает максимум один под в секунду, и кластер мог без проблем запустить 200 задач в минуту. Учитывая, что нам нужно примерно 50 задач в минуту, было решено, что такое ограничение нас не блокировало (и что при необходимости мы могли их решить позже). Вперед!
Очень важно при настройке Kubernetes — правильно запустить etcd. Etcd — сердце вашего Kubernetes кластера, именно там хранятся все данным о нем. Все кроме etcd не имеет состояний. Если etcd не запущен, вы не можете внести изменения в ваш Kubernetes кластер (хотя существующие сервисы продолжат работать!).
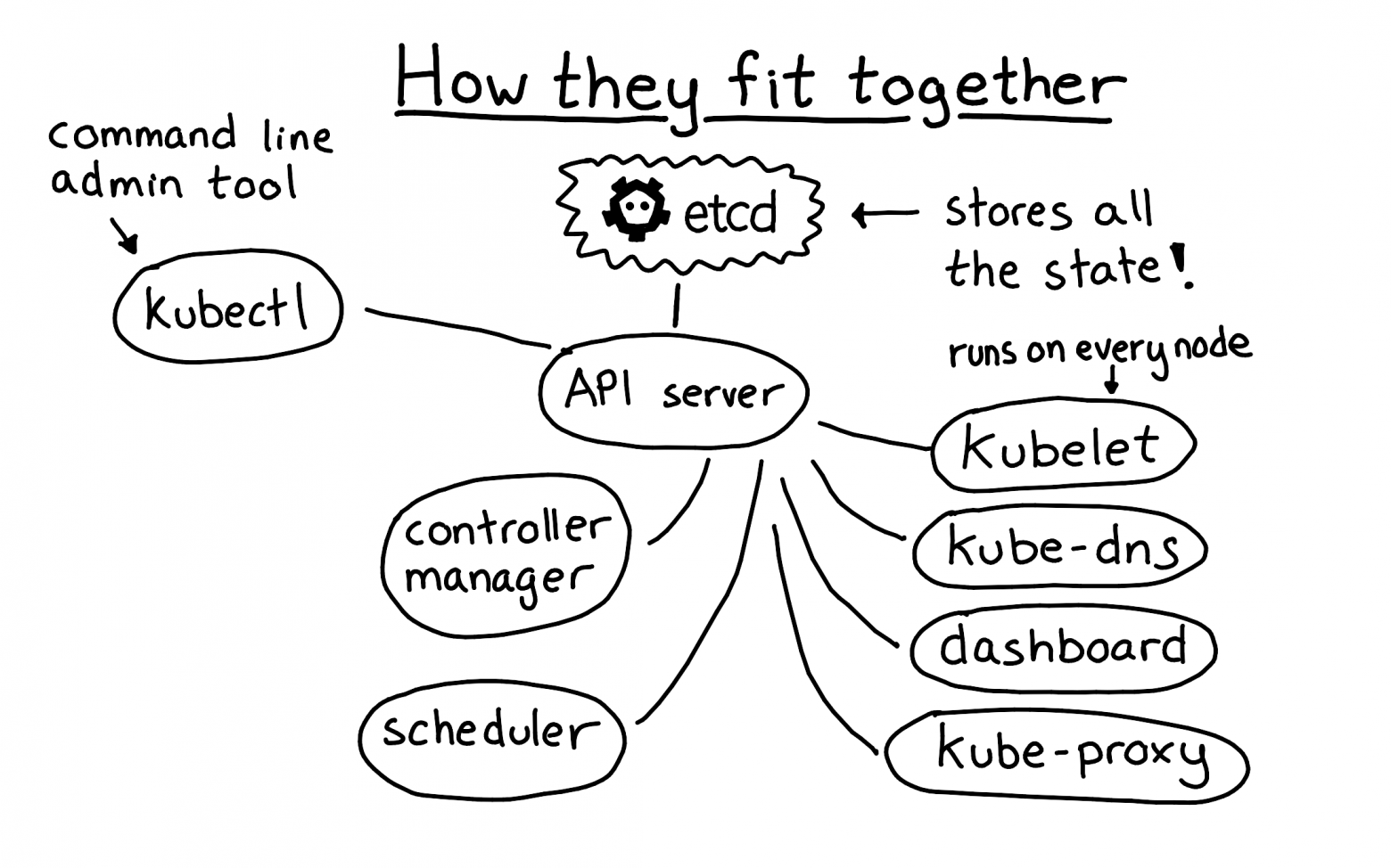
При запуске стоит держать в голове два важных момента:
Настройка репликации — задача не из разряда сделал-и-забыл. Мы внимательно протестировали, что при потере нода etcd, кластер все равно изящно восстанавливается.
Вот некоторые задачи, которые мы выполнили для настройки etcd кластера:
Мы очень рады, что рано провели тестирование. Одним пятничным утром, в нашем производственном кластере перестал пинговаться один из etcd нодов. Мы получили предупреждение об этом, уничтожили нод, подняли новый, добавили его в кластер и все это время Kubernetes продолжал работать без перебоев. Удивительно.
Одной из наших основных целей было перенести задачи в Kubernetes, не вызвав перебоев в работе. Секрет успешного производственного переноса заключается не в безошибочном процессе (это невозможно), а в проектировании процесса таким образом, чтобы снизить вред от ошибок.
Мы были счастливыми обладателями большого разнообразия задач, требующих миграции в новый кластер, поэтому среди них оказались те, что обладали низким уровнем влияния — пара-тройка ошибок в их переносе была приемлемой.
Перед началом миграции мы создали простой в использовании инструмент, позволяющий перемещать задачи между старой и новой системами, менее, чем за пять минут. Этот инструмент снизил ущерб от ошибок — если мы перенесли задачу, обладающую зависимостью, которую мы не планировали, не проблема! Можно просто вернуть ее обратно, исправить проблему и попробовать снова.
Мы придерживались такой стратегии миграции:
В самом начале проекта мы установили правило: если Kubernetes делает что-то неожиданное, нужно понять почему и предложить исправление.
Разбор каждого бага занимает много времени, но очень важен. Если бы мы просто отмахнулись от странного поведения Kubernetes, решив, что виновата сложность работы распределенной системы, то каждый новый баг заставлял бы думать, что только мы в нем виноваты.
После принятия этого подхода, мы нашли (и пофиксили!) несколько багов в Kubernetes.
Вот несколько проблем, которые мы нашли во время этих тестов:
Исправление этих багов помогло нам лучше относиться к использованию Kubernetes в проекте — он не только работал достаточно хорошо, но и принимал патчи и обладал хорошим процессом ревью PR.
Kubernetes полон багов, как и любой софт. К примеру, мы усиленно используем планировщик (потому что наши задачи постоянно создают новые поды), а использование планировщиком кэширования иногда оборачивается багами, регрессией и падениями. Кэширование — это сложно! Но codebase доступный и мы смогли справиться со всеми багами, с которыми столкнулись.
Еще одна достойная упоминания проблема — логика переноса подов в Kubernetes. В Kubernetes есть компонент под названием контроллер нодов, который отвечает за ликвидацию подов и их перенос в другие ноды в случае неотзывчивости. Возможен случай отсутствия ответа от всех нодов (например, при проблеме с сетью и настройкой), тогда Kubernetes может уничтожить все поды в кластере. Мы с этим сталкивались уже в начале тестирования.
Если вы запускаете большой кластер Kubernetes, внимательно прочитайте документацию контроллера нодов, обдумайте настройку и усиленно тестируйте. Каждый раз, когда мы тестировали изменения в конфигурации этой настройки (например, --pod-eviction-timeout) с помощью создания ограничения сети, происходили удивительные вещи. Лучше узнавать о таких сюрпризах из тестирования, а не в 3 утра на продакшне.
Мы и раньше обсуждали запуск упражнений игрового дня в Stripe, и продолжаем это делать сейчас. Идея заключается в том, чтобы придумать ситуации, которые могут произойти в производстве (например, потеря сервера Kubernetes API), а затем специально создать их (во время рабочего дня, с предупреждением), чтобы убедиться в возможности их исправить.
Проведение нескольких упражнений на нашем кластере выявило некоторые проблемы вроде пробелов в мониторинге и ошибок конфигурации. Мы были очень рады найти эти проблемы заранее и в контролируемой среде, а не случайно шесть месяцев спустя.
Некоторые игровые упражнения, которые мы провели:
Мы были очень рады увидеть, что Kubernetes достойно выстоял наши поломки. Kubernetes спроектирован быть устойчивым к ошибкам — у него один etcd кластер, в котором хранятся все состояния, API сервер, представляющий собой простой REST интерфейс для базы данных и набор контроллеров без состояний, который координирует управление кластером.
Если любой из корневых компонентов Kubernetes (сервер API, управление контроллеров, планировщик) прерван и перезапущен, то сразу после восстановления он читает состояние из etcd и продолжает работать. Это одна из тех вещей, которая привлекла в теории, и на практике показала себя не хуже.
Вот некоторые проблемы, которые мы нашли во время тестов:
После запуска этих тестов мы внесли правки для найденных проблем: улучшили мониторинг, исправили найденные настройки конфигурации, задокументировали баги Kubernetes.
Кратко ознакомимся, как мы сделали нашу систему на базе Kubernetes простой в использовании.
Нашей изначальной целью было проектирование системы для запуска задач, которыми наша команда могла с уверенностью управлять. Когда мы стали уверены в Kubernetes, возникла необходимость в простой настройке и добавлении новых cron jobs нашими инженерами. Мы разработали конфигурационный YAML формат, чтобы наши пользователи не нуждались в понимании внутреннего строения Kubernetes для использования нашей системы. Вот этот формат:
Ничего сложного — просто написали программу, которая берет этот формат и переводит его в конфигурацию cron job Kubernetes, который мы применяем с kubectl.
Также мы написали тестовый набор для проверки длины (названия задач Kubernetes не может превышать 52 символа) и уникальности названий задач. Сейчас мы не используем cgroups для ограничения объемов памяти в большинстве наших задач, но это есть в планах на будущее.
Наш формат был прост в использовании, а, учитывая, что мы автоматически сгенерировали и cron job’ы Chronos, и cron job’ы Kubernetes, переместить задачи между двумя системами было легко. Это было ключевым элементом в хорошей работе нашей постепенной миграции. Как только перенос задачи в Kubernetes вызывал ошибку, мы могли перенести его обратно простым трехстрочным изменением в конфигурации, менее чем за 10 минут.
Мониторинг внутренних состояний нашего Kubernetes кластера оказался приятным. Мы используем пакет kube-state-metrics для мониторинга и небольшую программу на Go под названием veneur-prometheus для сбора метрик Prometheus, которые выдает kube-state-metrics и их публикации в виде statsd метрики в нашей системе мониторинга.
Вот, например, график количества Pending подов в нашем кластере за последний час. Pending означает, что они ждут назначения рабочему ноду для запуска. Можно увидеть пик значения в 11 утра, потому что многие задачи запускаются в нулевую минуту часа.
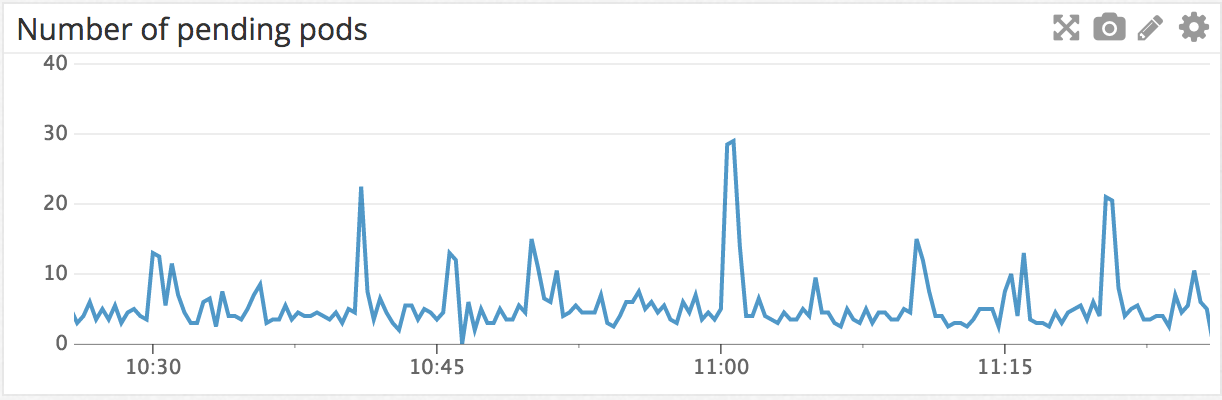
Кроме этого, мы следим, что нет подов, застрявших в состоянии Pending — проверяем, что каждый под запускается в рабочем ноде в течение 5 минут, а иначе получаем предупреждение.
Настройка Kubernetes, достижение момента готовности запустить продакшн код и миграция наших cron jobs в новый кластер, заняли у трёх программистов на full-time пять месяцев. Одна из значимых причин, по которой мы вложились в изучение Kubernetes — ожидание более широкого использования Kubernetes в Stripe.
Вот некоторые принципы управления Kubernetes (и любой другой сложной распределенной системой):
Сохраняя фокус на этих принципах, мы можем с уверенностью использовать Kubernetes в производстве. Наше использование Kubernetes продолжит расти и развиваться — например, с интересом смотрим AWS релизы EKS. Мы завершаем работу над другой системой тренировки моделей машинного обучения, а также рассматриваем вариант перенести некоторые HTTP сервисы на Kubernetes. И в процессе использования Kubernetes в производстве, мы планируем внести свой вклад в open-source проект.
Как всегда ждём ваши комментарии, вопросы тут или на нашем Дне открытых дверей.
Мы возвращаемся к нашей любимой традиции — раздача полезностей, которые мы собираем и изучаем в рамках наших курсов. Сегодня у нас на повестке дня курс по DevOps и один из его инструментов — Kubernetes.
Недавно мы создали распределенную систему планирования задач (cron jobs) на базе Kubernetes — новой, захватывающей платформы для оркестрации контейнеров. Kubernetes становится все популярней и дает много обещаний: например, инженерам не придется переживать, на каком устройстве запущено их приложение.
Распределенные системы сложны сами по себе, а управление сервисами на распределенных системах — одна из сложнейших проблем, с которыми сталкиваются команды управления. Мы очень серьезно относимся к вводу нового программного обеспечения в производство и обучению его надежному управлению. В качестве примера важности управления Kubernetes (и почему это так сложно!), почитайте отличный постмортем часового перебоя в работе, вызванного багом в Kubernetes.
В этом посте мы объясним, почему выбрали именно Kubernetes. Изучим процесс его интегрирования в существующую инфраструктуру, метод укрепления доверия (и улучшения) надежности нашего Kubernetes кластера и абстракцию созданную на основе Kubernetes.

Что такое Kubernetes?
Kubernetes — распределенная система планирования программ для запуска в кластере. Вы можете сказать Kubernetes запустить пять копий программы, и он динамически запланирует их в ваших рабочих нодах. Контейнеры должны увеличить утилизацию, тем самым экономят средства, мощные примитивы развертывания позволяют постепенно выкатывать новый код, а Security Contexts и Network Policies позволяют безопасно запускать multi-tenant рабочие нагрузки.
В Kubernetes встроено множество различных возможностей планирования. Можно планировать длительные службы HTTP, daemonsets, запущенные на всех машинах вашего кластера, задачи, запускающиеся каждый час, и другое. Kubernetes представляет собой даже больше. И если вы хотите это узнать, посмотрите отличные выступления Kelsey Hightower: можно начать с Kubernetes для сисадминов и healthz: Перестаньте заниматься реверс-инженерингом приложений и начните наблюдать их изнутри. Не стоит забывать и про хорошее сообщество в Slack.
Почему именно Kubernetes?
Каждый инфраструктурный проект (я надеюсь!) начинается с потребности бизнеса, и наша задача — улучшить надежность и безопасность существующей системы планирования cron job, которая уже есть. Наши требования следующие:
- Реализация и управление проектом возможны сравнительно небольшой командой (всего 2 человека, работающих full time на этом проекте);
- Возможность планирования около 500 различных задач на 20 машинах;
И вот несколько причин, почему мы выбрали Kubernetes:
- Желание создавать на базе уже существующего open-source проекта;
- Kubernetes включает в себя распределенный планировщик задач, поэтому нам не придется писать свой;
- Kubernetes — активно развивающийся проект, в котором можно принять участие;
- Kubernetes написан на Go, который прост в изучении. Почти все багфиксы по части Kubernetes были произведены программистами, не имеющими предыдущего опыта с Go;
- Если нам удастся управлять Kubernetes, то в будущем мы сможем создавать уже на базе Kubernetes (например, сейчас мы работаем над системой на базе Kubernetes для тренировки моделей машинного обучения).
Раньше в качестве планировщика задач мы использовали Cronos, но он перестал удовлетворять нашим требованиям надежности и сейчас почти не поддерживается (1 коммит за последние 9 месяцев, и последний раз pull request был добавлен в марте 2016 года). Поэтому мы решили больше не вкладываться в улучшение нашего существующего кластера.
Если вы рассматриваете Kubernetes, имейте в виду: не используйте Kubernetes просто потому что, так делают другие компании. Создание надежного кластера требует огромного количества времени, а способ его использования в бизнесе не всегда очевиден. Инвестируйте ваше время с умом.
Что значит “надежный”?
Когда дело доходит до управления сервисами, слово “надежный” не имеет смысла само по себе. Чтобы говорить о надежности, сначала нужно установить SLO (service level objective, то есть целевой уровень сервиса).
У нас было три основных задачи:
- 99.99% задач нужно планировать и запускать в течение 20 минут их запланированного времени работы. 20 минут — довольно большой временной промежуток, но мы опросили наших внутренних клиентов и никто не потребовал большей точности;
- Задания должны быть выполнены в 99.99% случаев (без прерывания);
- Наш переезд на Kubernetes не должен вызвать инцидентов на стороне клиента.
Это означало несколько вещей:
- Короткие периоды простоя в API Kubernetes — приемлемы (если оно упало на 10 минут — не критично, если возможно восстановиться в течение 5 минут);
- Планирование багов (когда уже запущенная задача падает или не может запуститься вовсе) — неприемлемо. Мы очень серьезно отнеслись к отчетам планирования багов;
- Нужно быть осторожным с удалением подов и уничтожением инстансов, чтобы задачи не прерывались слишком часто;
- Нам нужен хороший план переезда.
Создание Kubernetes кластера
Базовый подход к созданию первого Kubernetes кластера заключался в создании кластера с нуля, без использования инструментов вроде kubeadm или kops. Мы создали конфигурацию с помощью Puppet, нашего стандартного инструмента управления настройкой. Создание с нуля привлекало по двум причинам: мы могли глубоко интегрировать Kubernetes в нашу архитектуру, и мы приобрели широкие знания его внутреннего устройства.
Построение с нуля позволило нам интегрировать Kubernetes в существующую инфраструктуру. Мы хотели цельную интеграцию с нашими существующими системами логирования, управления сертификатами, секретов, сетевой безопасности, мониторинга, управления инстансами AWS, развертывания, прокси баз данных, внутренних DNS серверов, управления настройками, и многими другими. Интеграция всех этих систем иногда требовала творческого подхода, но, в целом, оказалась проще потенциальных попыток заставить kubeadm/kops делать то, что нам от них нужно.
Мы уже доверяем и знаем, как управлять существующими системами, поэтому хотели продолжить их использовать в новом Kubernetes кластере. Например, надежное управление сертификатами — очень сложная проблема, но у нас уже сейчас есть способ ее решения. Нам удалось избежать создания нового CA для Kubernetes благодаря грамотной интеграции.
Мы были вынуждены понять, как именно настраиваемые параметры влияют на нашу установку Kubernetes. Например, было использовано более дюжины параметров для настройки сертификатов/CA аутентификации. Понимание всех этих параметров облегчило отладку нашей установки при нахождении проблем с аутентификацией.
Укрепление уверенности в Kubernetes
В самом начале работы с Kubernetes ни у кого в команде не было опыта его использования (только для домашних проектов). Как же прийти от “Никто из нас никогда не использовал Kubernetes” к “Мы уверены в использовании Kubernetes на продакшне”?

Стратегия 0: Поговорить с другими компаниями
Мы спросили несколько человек из других компаний об их опыте с Kubernetes. Все они использовали его по-разному и в разных окружениях (для запуска HTTP сервисов, на голом железе, на Google Kubernetes Engine и т.д.).
Когда речь идет о больших и сложных системах как Kubernetes, особенно важно думать именно о ваших кейсах применения, экспериментировать, находить уверенность в вашем окружении и решать за себя. Например, не стоит после чтения этого поста решать “Ну, в Stripe успешно пользуются Kubernetes, значит и мы сможем!”.
Вот что мы узнали из бесед с различными компаниями, управляющих кластерами Kubernetes:
- Приоритезируйте работу над надежностью вашего etcd кластера (именно в etcd будут храниться состояния вашего Kubernetes кластера);
- Некоторые функции Kubernetes более стабильны, чем другие, так что осторожнее с альфа-функциями. Некоторые компании используют стабильные альфа-функции, после того, как их стабильность подтвердилась более одного релиза подряд (то есть, если функция становится стабильной в 1.8, они ждут 1.9 или 1.10, прежде чем начать ее использовать);
- Присмотритесь к размещенным Kubernetes системам вроде GKE/AKS/EKS. Самостоятельная установка отказоустойчивой системы Kubernetes с нуля — сложная задача. В AWS не было управляемого Kubernetes сервиса во время этого проекта, поэтому мы его не рассматривали;
- Будьте осторожны с дополнительной задержкой сети, вызванной overlay-сетями/программными сетями.
Беседы с другими компаниями, конечно, не дали четкого ответа, подходит ли нам Kubernetes, зато обеспечили нас вопросами и поводами для беспокойств.
Стратегия 1: Прочитать код
Мы планировали сильно зависеть от одного компонента Kubernetes — контроллера cron job. В то время он находился в альфе, что стало небольшим поводом для волнения. Мы проверили его на тестовом кластере, но как можно сказать наверняка, будет ли он нас устраивать на продакшне? К счастью, весь код функционала контроллера состоит из 400 строк Go. Чтение исходного кода быстро показало, что:
- Контроллер — сервис без состояний (как и любой другой компонент Kubernetes, за исключением etcd);
- Каждые 10 секунд этот контроллер вызывает syncAll function: go wait.Until(jm.syncAll, 10*time.Second, stopCh);
- Функция syncAll возвращает все задачи из Kybernetes API, проходит через этот список, определяет, какие задачи должны быть запущены следующими, а затем запускает их.
Базовая логика была проста для понимания. Что более важно, если бы в контроллере обнаружился баг, скорее всего мы бы смогли его починить самостоятельно.
Стратегия 2: Провести нагрузочное тестирование
Перед тем как начать строить наш кластер, мы провели нагрузочное тестирование. Нас не беспокоило количество нодов, с которыми мог справиться кластер Kubernetes (планировали разворачивать около 20 нодов), было важно убедиться, что Kubernetes способен выдерживать столько задач, сколько нам нужно (около 20 в минуту).
Мы провели тест на трёхнодовом кластере, где было создано 1000 cron jobs, каждая из которых запускалась раз в минуту. Все задачи просто запускали bash -c 'echo hello world'. Мы выбрали простые задачи, потому что хотели протестировать возможности планирования и оркестрации кластера, а не его общую вычислительную мощность.
Тестовый кластер не смог выдержать 1000 задач в минуту. Мы выяснили, что каждый нод запускает максимум один под в секунду, и кластер мог без проблем запустить 200 задач в минуту. Учитывая, что нам нужно примерно 50 задач в минуту, было решено, что такое ограничение нас не блокировало (и что при необходимости мы могли их решить позже). Вперед!
Стратегия 3: Приоритезировать создание и тестирование отказоустойчивого etcd кластера
Очень важно при настройке Kubernetes — правильно запустить etcd. Etcd — сердце вашего Kubernetes кластера, именно там хранятся все данным о нем. Все кроме etcd не имеет состояний. Если etcd не запущен, вы не можете внести изменения в ваш Kubernetes кластер (хотя существующие сервисы продолжат работать!).

При запуске стоит держать в голове два важных момента:
- Задайте репликацию, чтобы ваш кластер не умер при потере нода. Сейчас у нас есть три копии etcd;
- Убедитесь, что у вас достаточная пропускная способность I/O. В нашей версии etcd была проблема, что один нод с высокой fsync задержкой мог вызвать длительный выбор лидера, оборачивающийся недоступностью кластера. Мы исправили это, убедившись, что пропускной способностью I/O наших нодов выше, чем количество записей, совершаемых etcd.
Настройка репликации — задача не из разряда сделал-и-забыл. Мы внимательно протестировали, что при потере нода etcd, кластер все равно изящно восстанавливается.
Вот некоторые задачи, которые мы выполнили для настройки etcd кластера:
- Настройка репликации;
- Проверка доступности etcd кластера (если etcd упал, мы сразу должны об этом знать);
- Написание простых инструментов для легкого создания новых etcd нодов и добавления их в кластер;
- Добавление etcd Consul интеграции, чтобы можно было запустить более одного etsd кластера в нашем производственном окружении;
- Тестирование восстановления из резервной копии etcd;
- Тестирование возможности перестроить кластер полностью без простоев.
Мы очень рады, что рано провели тестирование. Одним пятничным утром, в нашем производственном кластере перестал пинговаться один из etcd нодов. Мы получили предупреждение об этом, уничтожили нод, подняли новый, добавили его в кластер и все это время Kubernetes продолжал работать без перебоев. Удивительно.
Стратегия 4: Постепенно перенести задачи в Kubernetes
Одной из наших основных целей было перенести задачи в Kubernetes, не вызвав перебоев в работе. Секрет успешного производственного переноса заключается не в безошибочном процессе (это невозможно), а в проектировании процесса таким образом, чтобы снизить вред от ошибок.
Мы были счастливыми обладателями большого разнообразия задач, требующих миграции в новый кластер, поэтому среди них оказались те, что обладали низким уровнем влияния — пара-тройка ошибок в их переносе была приемлемой.
Перед началом миграции мы создали простой в использовании инструмент, позволяющий перемещать задачи между старой и новой системами, менее, чем за пять минут. Этот инструмент снизил ущерб от ошибок — если мы перенесли задачу, обладающую зависимостью, которую мы не планировали, не проблема! Можно просто вернуть ее обратно, исправить проблему и попробовать снова.
Мы придерживались такой стратегии миграции:
- Примерно распределите задачи по степени их важности;
- Неоднократно перенесите несколько задач в Kubernetes. При обнаружении новых проблемных мест, быстро откатите, исправьте проблему и попытайтесь еще раз.
Стратегия 5: Исследовать баги Kubernetes (и исправить их)
В самом начале проекта мы установили правило: если Kubernetes делает что-то неожиданное, нужно понять почему и предложить исправление.
Разбор каждого бага занимает много времени, но очень важен. Если бы мы просто отмахнулись от странного поведения Kubernetes, решив, что виновата сложность работы распределенной системы, то каждый новый баг заставлял бы думать, что только мы в нем виноваты.
После принятия этого подхода, мы нашли (и пофиксили!) несколько багов в Kubernetes.
Вот несколько проблем, которые мы нашли во время этих тестов:
- Cronjobs с именами длиннее 52 символов молча не справляются с планированием задач (исправлено здесь);
- Поды могут навсегда зависнуть в Pending состоянии (исправлено здесь и здесь);
- Планировщик падает каждые три часа (исправлено здесь);
- Бэкэнд Flannel hostgw не заменил устаревшие корневые значения (исправлено здесь).
Исправление этих багов помогло нам лучше относиться к использованию Kubernetes в проекте — он не только работал достаточно хорошо, но и принимал патчи и обладал хорошим процессом ревью PR.
Kubernetes полон багов, как и любой софт. К примеру, мы усиленно используем планировщик (потому что наши задачи постоянно создают новые поды), а использование планировщиком кэширования иногда оборачивается багами, регрессией и падениями. Кэширование — это сложно! Но codebase доступный и мы смогли справиться со всеми багами, с которыми столкнулись.
Еще одна достойная упоминания проблема — логика переноса подов в Kubernetes. В Kubernetes есть компонент под названием контроллер нодов, который отвечает за ликвидацию подов и их перенос в другие ноды в случае неотзывчивости. Возможен случай отсутствия ответа от всех нодов (например, при проблеме с сетью и настройкой), тогда Kubernetes может уничтожить все поды в кластере. Мы с этим сталкивались уже в начале тестирования.
Если вы запускаете большой кластер Kubernetes, внимательно прочитайте документацию контроллера нодов, обдумайте настройку и усиленно тестируйте. Каждый раз, когда мы тестировали изменения в конфигурации этой настройки (например, --pod-eviction-timeout) с помощью создания ограничения сети, происходили удивительные вещи. Лучше узнавать о таких сюрпризах из тестирования, а не в 3 утра на продакшне.
Стратегия 6: намеренно создавайте проблемы для Kubernets кластера
Мы и раньше обсуждали запуск упражнений игрового дня в Stripe, и продолжаем это делать сейчас. Идея заключается в том, чтобы придумать ситуации, которые могут произойти в производстве (например, потеря сервера Kubernetes API), а затем специально создать их (во время рабочего дня, с предупреждением), чтобы убедиться в возможности их исправить.
Проведение нескольких упражнений на нашем кластере выявило некоторые проблемы вроде пробелов в мониторинге и ошибок конфигурации. Мы были очень рады найти эти проблемы заранее и в контролируемой среде, а не случайно шесть месяцев спустя.
Некоторые игровые упражнения, которые мы провели:
- Выключение одного сервера Kubernetes API;
- Выключение всех серверов Kubernetes API и их поднятие (на удивление, все сработало хорошо);
- Выключение etcd нода;
- Обрыв рабочих нодов в нашем Kubernetes кластере от API серверов (чтобы они потеряли возможность общаться). В результате все поды из этих нодов были перенесены в другие ноды.
Мы были очень рады увидеть, что Kubernetes достойно выстоял наши поломки. Kubernetes спроектирован быть устойчивым к ошибкам — у него один etcd кластер, в котором хранятся все состояния, API сервер, представляющий собой простой REST интерфейс для базы данных и набор контроллеров без состояний, который координирует управление кластером.
Если любой из корневых компонентов Kubernetes (сервер API, управление контроллеров, планировщик) прерван и перезапущен, то сразу после восстановления он читает состояние из etcd и продолжает работать. Это одна из тех вещей, которая привлекла в теории, и на практике показала себя не хуже.
Вот некоторые проблемы, которые мы нашли во время тестов:
- “Странно, мне не сообщили об это, хотя должны были. Нужно поправить тут наблюдение”;
- “Когда мы уничтожили инстансы API сервера и подняли их обратно, они потребовали человеческого вмешательства. Лучше исправить это”;
- “Иногда, когда мы проверяем отказоустойчивость etcd, API сервер начинает тайм-аутить запросы до тех пор, пока мы его не перезапустим”.
После запуска этих тестов мы внесли правки для найденных проблем: улучшили мониторинг, исправили найденные настройки конфигурации, задокументировали баги Kubernetes.
Делаем cron jobs легкими в использовании
Кратко ознакомимся, как мы сделали нашу систему на базе Kubernetes простой в использовании.
Нашей изначальной целью было проектирование системы для запуска задач, которыми наша команда могла с уверенностью управлять. Когда мы стали уверены в Kubernetes, возникла необходимость в простой настройке и добавлении новых cron jobs нашими инженерами. Мы разработали конфигурационный YAML формат, чтобы наши пользователи не нуждались в понимании внутреннего строения Kubernetes для использования нашей системы. Вот этот формат:
name: job-name-here
kubernetes:
schedule: '15 */2 * * *'
command:
- ruby
- "/path/to/script.rb"
resources:
requests:
cpu: 0.1
memory: 128M
limits:
memory: 1024MНичего сложного — просто написали программу, которая берет этот формат и переводит его в конфигурацию cron job Kubernetes, который мы применяем с kubectl.
Также мы написали тестовый набор для проверки длины (названия задач Kubernetes не может превышать 52 символа) и уникальности названий задач. Сейчас мы не используем cgroups для ограничения объемов памяти в большинстве наших задач, но это есть в планах на будущее.
Наш формат был прост в использовании, а, учитывая, что мы автоматически сгенерировали и cron job’ы Chronos, и cron job’ы Kubernetes, переместить задачи между двумя системами было легко. Это было ключевым элементом в хорошей работе нашей постепенной миграции. Как только перенос задачи в Kubernetes вызывал ошибку, мы могли перенести его обратно простым трехстрочным изменением в конфигурации, менее чем за 10 минут.
Мониторинг Kubernetes
Мониторинг внутренних состояний нашего Kubernetes кластера оказался приятным. Мы используем пакет kube-state-metrics для мониторинга и небольшую программу на Go под названием veneur-prometheus для сбора метрик Prometheus, которые выдает kube-state-metrics и их публикации в виде statsd метрики в нашей системе мониторинга.
Вот, например, график количества Pending подов в нашем кластере за последний час. Pending означает, что они ждут назначения рабочему ноду для запуска. Можно увидеть пик значения в 11 утра, потому что многие задачи запускаются в нулевую минуту часа.

Кроме этого, мы следим, что нет подов, застрявших в состоянии Pending — проверяем, что каждый под запускается в рабочем ноде в течение 5 минут, а иначе получаем предупреждение.
Будущие планы для Kubernetes
Настройка Kubernetes, достижение момента готовности запустить продакшн код и миграция наших cron jobs в новый кластер, заняли у трёх программистов на full-time пять месяцев. Одна из значимых причин, по которой мы вложились в изучение Kubernetes — ожидание более широкого использования Kubernetes в Stripe.
Вот некоторые принципы управления Kubernetes (и любой другой сложной распределенной системой):
- Определите четкую бизнес-причину для вашего Kubernetes проекта (и всех инфраструктурных проектов!). Понимание кейса и нужд пользователей значительно упростило наш проект;
- Агрессивно сокращайте объемы. Мы решили не использовать многие базовые функции Kubernetes для упрощения кластера. Это позволило нам запуститься быстрее — например, с учетом того, что pod-to-pod сеть не была обязательной для нашего проекта, мы смогли ограничить все сетевые соединения между нодами и отложить размышления о сетевой безопасности в Kubernetes до будущего проекта.
- Отведите много времени изучению правильного управления Kubernetes кластера. Внимательно тестируйте острые кейсы. Распределенные системы очень сложны, поэтому многие вещи могут пойти не так. Возьмем пример, описанный ранее: контроллер нодов может убить всех подов в вашем кластере, если они потеряют контакт с API серверами, в зависимости от вашей конфигурации. Изучение поведения Kubernetes после каждого изменения настройки, требует времени и внимательности.
Сохраняя фокус на этих принципах, мы можем с уверенностью использовать Kubernetes в производстве. Наше использование Kubernetes продолжит расти и развиваться — например, с интересом смотрим AWS релизы EKS. Мы завершаем работу над другой системой тренировки моделей машинного обучения, а также рассматриваем вариант перенести некоторые HTTP сервисы на Kubernetes. И в процессе использования Kubernetes в производстве, мы планируем внести свой вклад в open-source проект.
THE END
Как всегда ждём ваши комментарии, вопросы тут или на нашем Дне открытых дверей.
