Добрый вечер!
От нашего курса «Разработчик C++» предлагаем вам небольшое и интересное исследование про параллельные алгоритмы.
Поехали.
С появлением параллельных алгоритмов в C++17, вы с легкостью можете обновить свой “вычислительный” код и получить выгоду от параллельного выполнения. В этой статье, я хочу рассмотреть STL алгоритм, который естественным образом раскрывает идею независимых вычислений. Можно ли ожидать 10-кратного ускорения при наличии 10-ядерного процессора? А может больше? Или меньше? Поговорим об этом.
Введение в параллельные алгоритмы

C++17 предлагает параметр политики выполнения для большинства алгоритмов:
Кратко:
В качестве быстрого примера вызовем
Обратите внимание, как просто добавить параметр параллельного выполнения в алгоритм! Но удастся ли добиться значительного улучшения производительности? Увеличит ли это скорость? Или есть случаи замедления?
Параллельный
В этой статье, я хочу обратить внимание на алгоритм
Наш тестовый код будет строиться по следующему шаблону:
Предположим, что у функции
Я бы хотел поэкспериментировать со следующими вещами:
Как видите, я хочу не только протестировать количество элементов, которые “хороши” для использования параллельного алгоритма, но и ALU-операции, которые занимают процессор.
Прочие алгоритмы, такие как сортировка, накопление (в виде std::reduce) также предлагают параллельное выполнение, но и требуют больше работы для вычисления результатов. Поэтому будем считать их кандидатами для другой статьи.
Примечание об бенчмарках
Для своих тестов я использую Visual Studio 2017, 15.8 — поскольку это единственная реализация в популярной реализации компилятора/STL на текущий момент (Ноябрь, 2018) (GCC в пути!). Более того, я сосредоточился только на
Есть два компьютера:
Код скомпилирован в x64, Release more, автовекторизация включена по-умолчанию, также я включил расширенный набор команд (SSE2) и OpenMP (2.0).
Код находится в моем github’е: github/fenbf/ParSTLTests/TransformTests/TransformTests.cpp
Для OpenMP (2.0) я использую параллельность только для циклов:
Запускаю код 5 раз и смотрю на минимальные результаты.
Предупреждение: Результаты отражают только грубые наблюдения, проверьте на своей системе/конфигурации перед использованием в продакшне. Ваши требования и окружение могут отличаться от моих.
Более подробно о MSVC реализации можно прочитать в этом посте. А вот свежий доклад Билла О’Нила с CppCon 2018 (Билл реализовал Parallel STL в MSVC).
Ну что ж, начнем с простых примеров!
Простое преобразование
Рассмотрим случай, когда вы применяете очень простую операцию к входному вектору. Это может быть копирование или умножение элементов.
Например:
В моем компьютере 6 или 4 ядра… могу ли я ожидать 4..6-кратного ускорение последовательного выполнения? Вот мои результаты (время в миллисекундах):
На более быстрой машине можем увидеть, что понадобится около 1 миллиона элементов, чтобы заметить улучшение производительности. С другой стороны, на моем ноутбуке все параллельные реализации были медленнее.
Таким образом, заметить какое-либо значительное улучшение производительности при помощи таких трансформаций сложно, даже при увеличении количества элементов.
Почему же?
Поскольку операции элементарные, ядра процессора могут вызывать его практически мгновенно, используя всего несколько циклов. Однако, ядра процессора тратят больше времени, ожидая основную память. Так что, в этом случае, по большей части они будут ждать, а не совершать вычисления.
Чтение и запись переменной в памяти занимает около 2-3 тактов, если она кэшируется, и несколько сотен тактов, если не кэшируется.
https://www.agner.org/optimize/optimizing_cpp.pdf
Можно грубо заметить, что если ваш алгоритм зависит от памяти, то не стоит ожидать улучшения производительности с параллельным вычислением.
Больше вычислений
Поскольку пропускная способность памяти крайне важна и может влиять на скорость вещей… давайте увеличим количество вычислений, влияющих на каждый элемент.
Мысль в том, что лучше использовать циклы процессора, а не тратить время на ожидание памяти.
Для начала, я использую тригонометрические функции, например,
Мы используем
Более подробно о задержках команд написано в прекрасной статье Perf Guide от Агнера Фога.
Вот бенчмарк-код:
И что же теперь? Можем ли мы рассчитывать на улучшение производительности по сравнении с предыдущей попыткой?
Вот некоторые результаты (время в миллисекундах):
Наконец-то мы видим неплохие числа :)
Для 1000 элементов (здесь не показанных), время параллельного и последовательного вычисления было схожи, поэтому для более 1000 элементов мы видим улучшение в параллельном варианте.
Для 100 тысяч элементов результат на более быстром компьютере почти в 9 раз лучше последовательной версии (аналогично для OpenMP версии).
В наибольшем варианте из миллиона элементов — результат быстрее в 5 или 8 раз.
Для таких вычислений я добился “линейного” ускорения, зависящего от количества ядер процессора. Чего и стоило ожидать.
Френель и трёхмерные векторы
В разделе выше я использовал “выдуманные” вычисления, но что насчет настоящего кода?
Давайте, решим уравнения Френеля, описывающие отражение и искривление света от гладкой, плоской поверхности. Это популярный метод для генерации реалистичного освещения в трехмерных играх.


Фото из Wikimedia
В качестве хорошего образца я нашел это описание и реализацию.
Об использовании библиотеки GLM
Вместо создания собственной реализации, я использовал библиотеку glm. Я часто ей пользуюсь в своих OpenGl проектах.
К библиотеке легко получить доступ через Conan Package Manager, поэтому им я тоже буду пользоваться. Ссылка на пакет.
Файл Conan:
и командная строка для установки библиотеки (она генерирует props-файлы, которые я могу использовать в проекте Visual Studio):
Библиотека состоит из заголовка, поэтому вы можете просто скачать ее вручную, если хотите.
Фактический код и бенчмарк
Я адаптировал код для glm из scratchapixel.com:
Код использует несколько математических инструкций, скалярное произведение, умножение, деление, так что процессору есть, чем заняться. Вместо вектора double мы используем вектор из 4х элементов, чтобы увеличить количество используемой памяти.
Бенчмарк:
И вот результаты (время в миллисекундах):
С “настоящими” вычислениями видим, что параллельные алгоритмы обеспечивают хорошую производительность. Для таких операций на двух моих машинах с Windows я добился ускорения с почти линейной зависимостью от количества ядер.
Для всех тестов я также показал результаты из OpenMP и двух реализаций: MSVC и OpenMP работают аналогично.
Вывод
В этой статье я разобрал три случая применения параллельного вычисления и параллельных алгоритмов. Замена стандартных алгоритмов на версию std::execution::par может показаться очень заманчивой, но делать это стоит не всегда! Каждая операция, используемая вами внутри алгоритма может работать иначе и быть более зависимой от процессора или памяти. Поэтому рассматривайте каждое изменение отдельно.
О чем стоит помнить:
Особое спасибо JFT за помощь со статьей!
Также обратите внимание на мои другие источники о параллельных алгоритмах:
Обратите внимание на другую статью, связанную с Параллельными Алгоритмами: How to Boost Performance with Intel Parallel STL and C++17 Parallel Algorithms
THE END
Ждём и комментарии, и вопросы, которые можно оставить тут или у нашего преподавателя на дне открытых дверей.
От нашего курса «Разработчик C++» предлагаем вам небольшое и интересное исследование про параллельные алгоритмы.
Поехали.
С появлением параллельных алгоритмов в C++17, вы с легкостью можете обновить свой “вычислительный” код и получить выгоду от параллельного выполнения. В этой статье, я хочу рассмотреть STL алгоритм, который естественным образом раскрывает идею независимых вычислений. Можно ли ожидать 10-кратного ускорения при наличии 10-ядерного процессора? А может больше? Или меньше? Поговорим об этом.
Введение в параллельные алгоритмы

C++17 предлагает параметр политики выполнения для большинства алгоритмов:
- sequenced_policy — тип политики выполнения, используется в качестве уникального типа для устранения перегрузки параллельного алгоритма и требования того, что распараллеливание выполнения параллельного алгоритма — невозможно: соответствующий глобальный объект —
std::execution::seq; - parallel_policy — тип политики выполнения, используемый в качестве уникального типа для устранения перегрузки параллельного алгоритма и указания на то, что распараллеливание выполнения параллельного алгоритма — возможно: соответствующий глобальный объект —
std::execution::par; - parallel_unsequenced_policy — тип политики выполнения, используемый в качестве уникального типа для устранения перегрузки параллельного алгоритма и указания на то, что распараллеливание и векторизация выполнения параллельного алгоритма — возможны: соответствующий глобальный объект —
std::execution::par_unseq;
Кратко:
- используйте
std::execution::seqдля последовательного выполнения алгоритма; - используйте
std::execution::parдля параллельного выполнения алгоритма (обычно с помощью какой-либо реализации Thread Pool (пула потоков)); - используйте
std::execution::par_unseqдля параллельного выполнения алгоритма с возможностью использования векторных команд (например, SSE, AVX).
В качестве быстрого примера вызовем
std::sort параллельно:std::sort(std::execution::par, myVec.begin(), myVec.end());
// ^^^^^^^^^^^^^^^^^^^
// политика выполненияОбратите внимание, как просто добавить параметр параллельного выполнения в алгоритм! Но удастся ли добиться значительного улучшения производительности? Увеличит ли это скорость? Или есть случаи замедления?
Параллельный
std::transformВ этой статье, я хочу обратить внимание на алгоритм
std::transform, который потенциально может быть основой для других параллельных методов (наравне с std::transform_reduce, for_each, scan, sort...).Наш тестовый код будет строиться по следующему шаблону:
std::transform(execution_policy, // par, seq, par_unseq
inVec.begin(), inVec.end(),
outVec.begin(),
ElementOperation);Предположим, что у функции
ElementOperation нет никаких методов синхронизации, в таком случае у кода есть потенциал параллельного выполнения или даже векторизации. Каждое вычисление элемента независимо, порядок не имеет значения, поэтому реализация может порождать несколько потоков (возможно в пуле потоков) для независимой обработки элементов.Я бы хотел поэкспериментировать со следующими вещами:
- размер векторного поля — большое или маленькое;
- простое преобразование, которое тратит бОльшую часть времени на доступ к памяти;
- больше арифметических (ALU) операций;
- ALU в более реалистичном сценарии.
Как видите, я хочу не только протестировать количество элементов, которые “хороши” для использования параллельного алгоритма, но и ALU-операции, которые занимают процессор.
Прочие алгоритмы, такие как сортировка, накопление (в виде std::reduce) также предлагают параллельное выполнение, но и требуют больше работы для вычисления результатов. Поэтому будем считать их кандидатами для другой статьи.
Примечание об бенчмарках
Для своих тестов я использую Visual Studio 2017, 15.8 — поскольку это единственная реализация в популярной реализации компилятора/STL на текущий момент (Ноябрь, 2018) (GCC в пути!). Более того, я сосредоточился только на
execution::par, так как execution::par_unseq недоступна в MSVC (работает аналогично execution::par).Есть два компьютера:
- i7 8700 — ПК, Windows 10, i7 8700 — тактовая частота 3.2 GHz, 6 ядер/12 потоков (Hyperthreading);
- i7 4720 — Ноутбук, Windows 10, i7 4720, тактовая частота 2.6GHz, 4 ядра/8 потоков (Hyperthreading).
Код скомпилирован в x64, Release more, автовекторизация включена по-умолчанию, также я включил расширенный набор команд (SSE2) и OpenMP (2.0).
Код находится в моем github’е: github/fenbf/ParSTLTests/TransformTests/TransformTests.cpp
Для OpenMP (2.0) я использую параллельность только для циклов:
#pragma omp parallel for
for (int i = 0; ...)Запускаю код 5 раз и смотрю на минимальные результаты.
Предупреждение: Результаты отражают только грубые наблюдения, проверьте на своей системе/конфигурации перед использованием в продакшне. Ваши требования и окружение могут отличаться от моих.
Более подробно о MSVC реализации можно прочитать в этом посте. А вот свежий доклад Билла О’Нила с CppCon 2018 (Билл реализовал Parallel STL в MSVC).
Ну что ж, начнем с простых примеров!
Простое преобразование
Рассмотрим случай, когда вы применяете очень простую операцию к входному вектору. Это может быть копирование или умножение элементов.
Например:
std::transform(std::execution::par,
vec.begin(), vec.end(), out.begin(),
[](double v) { return v * 2.0; }
);
В моем компьютере 6 или 4 ядра… могу ли я ожидать 4..6-кратного ускорение последовательного выполнения? Вот мои результаты (время в миллисекундах):
| Операция | Размер вектора | i7 4720 (4 ядра) | i7 8700 (6 ядер) |
|---|---|---|---|
| execution::seq | 10k | 0.002763 | 0.001924 |
| execution::par | 10k | 0.009869 | 0.008983 |
| openmp parallel for | 10k | 0.003158 | 0.002246 |
| execution::seq | 100k | 0.051318 | 0.028872 |
| execution::par | 100k | 0.043028 | 0.025664 |
| openmp parallel for | 100k | 0.022501 | 0.009624 |
| execution::seq | 1000k | 1.69508 | 0.52419 |
| execution::par | 1000k | 1.65561 | 0.359619 |
| openmp parallel for | 1000k | 1.50678 | 0.344863 |
На более быстрой машине можем увидеть, что понадобится около 1 миллиона элементов, чтобы заметить улучшение производительности. С другой стороны, на моем ноутбуке все параллельные реализации были медленнее.
Таким образом, заметить какое-либо значительное улучшение производительности при помощи таких трансформаций сложно, даже при увеличении количества элементов.
Почему же?
Поскольку операции элементарные, ядра процессора могут вызывать его практически мгновенно, используя всего несколько циклов. Однако, ядра процессора тратят больше времени, ожидая основную память. Так что, в этом случае, по большей части они будут ждать, а не совершать вычисления.
Чтение и запись переменной в памяти занимает около 2-3 тактов, если она кэшируется, и несколько сотен тактов, если не кэшируется.
https://www.agner.org/optimize/optimizing_cpp.pdf
Можно грубо заметить, что если ваш алгоритм зависит от памяти, то не стоит ожидать улучшения производительности с параллельным вычислением.
Больше вычислений
Поскольку пропускная способность памяти крайне важна и может влиять на скорость вещей… давайте увеличим количество вычислений, влияющих на каждый элемент.
Мысль в том, что лучше использовать циклы процессора, а не тратить время на ожидание памяти.
Для начала, я использую тригонометрические функции, например,
sqrt(sin*cos) (это условные вычисления в неоптимальной форме, просто чтобы занять процессор).Мы используем
sqrt, sin и cos, которые могу занять ~20 на sqrt и ~100 на тригонометрическую функцию. Такое количество вычислений может покрыть задержку на доступ к памяти.Более подробно о задержках команд написано в прекрасной статье Perf Guide от Агнера Фога.
Вот бенчмарк-код:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(),
[](double v) {
return std::sqrt(std::sin(v)*std::cos(v));
}
);И что же теперь? Можем ли мы рассчитывать на улучшение производительности по сравнении с предыдущей попыткой?
Вот некоторые результаты (время в миллисекундах):
| Операция | Размер вектора | i7 4720 (4 ядра) | i7 8700 (6 ядер) |
|---|---|---|---|
| execution::seq | 10k | 0.105005 | 0.070577 |
| execution::par | 10k | 0.055661 | 0.03176 |
| openmp parallel for | 10k | 0.096321 | 0.024702 |
| execution::seq | 100k | 1.08755 | 0.707048 |
| execution::par | 100k | 0.259354 | 0.17195 |
| openmp parallel for | 100k | 0.898465 | 0.189915 |
| execution::seq | 1000k | 10.5159 | 7.16254 |
| execution::par | 1000k | 2.44472 | 1.10099 |
| openmp parallel for | 1000k | 4.78681 | 1.89017 |
Наконец-то мы видим неплохие числа :)
Для 1000 элементов (здесь не показанных), время параллельного и последовательного вычисления было схожи, поэтому для более 1000 элементов мы видим улучшение в параллельном варианте.
Для 100 тысяч элементов результат на более быстром компьютере почти в 9 раз лучше последовательной версии (аналогично для OpenMP версии).
В наибольшем варианте из миллиона элементов — результат быстрее в 5 или 8 раз.
Для таких вычислений я добился “линейного” ускорения, зависящего от количества ядер процессора. Чего и стоило ожидать.
Френель и трёхмерные векторы
В разделе выше я использовал “выдуманные” вычисления, но что насчет настоящего кода?
Давайте, решим уравнения Френеля, описывающие отражение и искривление света от гладкой, плоской поверхности. Это популярный метод для генерации реалистичного освещения в трехмерных играх.
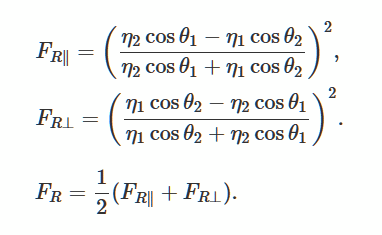

Фото из Wikimedia
В качестве хорошего образца я нашел это описание и реализацию.
Об использовании библиотеки GLM
Вместо создания собственной реализации, я использовал библиотеку glm. Я часто ей пользуюсь в своих OpenGl проектах.
К библиотеке легко получить доступ через Conan Package Manager, поэтому им я тоже буду пользоваться. Ссылка на пакет.
Файл Conan:
[requires]
glm/0.9.9.1@g-truc/stable
[generators]
visual_studio
и командная строка для установки библиотеки (она генерирует props-файлы, которые я могу использовать в проекте Visual Studio):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64Библиотека состоит из заголовка, поэтому вы можете просто скачать ее вручную, если хотите.
Фактический код и бенчмарк
Я адаптировал код для glm из scratchapixel.com:
// реализация адаптирована из https://www.scratchapixel.com
float fresnel(const glm::vec4 &I, const glm::vec4 &N, const float ior)
{
float cosi = std::clamp(glm::dot(I, N), -1.0f, 1.0f);
float etai = 1, etat = ior;
if (cosi > 0) { std::swap(etai, etat); }
// Вычислить sini с помощью закона Снеллиуса
float sint = etai / etat * sqrtf(std::max(0.f, 1 - cosi * cosi));
// Полное внутреннее отражение
if (sint >= 1)
return 1.0f;
float cost = sqrtf(std::max(0.f, 1 - sint * sint));
cosi = fabsf(cosi);
float Rs = ((etat * cosi) - (etai * cost)) /
((etat * cosi) + (etai * cost));
float Rp = ((etai * cosi) - (etat * cost)) /
((etai * cosi) + (etat * cost));
return (Rs * Rs + Rp * Rp) / 2.0f;
}Код использует несколько математических инструкций, скалярное произведение, умножение, деление, так что процессору есть, чем заняться. Вместо вектора double мы используем вектор из 4х элементов, чтобы увеличить количество используемой памяти.
Бенчмарк:
std::transform(std::execution::par,
vec.begin(), vec.end(), vecNormals.begin(), // векторы ввода
vecFresnelTerms.begin(), // вывод
[](const glm::vec4& v, const glm::vec4& n) {
return fresnel(v, n, 1.0f);
}
);И вот результаты (время в миллисекундах):
| Операция | Размер вектора | i7 4720 (4 ядра) | i7 8700 (6 ядер) |
|---|---|---|---|
| execution::seq | 1k | 0.032764 | 0.016361 |
| execution::par | 1k | 0.031186 | 0.028551 |
| openmp parallel for | 1k | 0.005526 | 0.007699 |
| execution::seq | 10k | 0.246722 | 0.169383 |
| execution::par | 10k | 0.090794 | 0.067048 |
| openmp parallel for | 10k | 0.049739 | 0.029835 |
| execution::seq | 100k | 2.49722 | 1.69768 |
| execution::par | 100k | 0.530157 | 0.283268 |
| openmp parallel for | 100k | 0.495024 | 0.291609 |
| execution::seq | 1000k | 25.0828 | 16.9457 |
| execution::par | 1000k | 5.15235 | 2.33768 |
| openmp parallel for | 1000k | 5.11801 | 2.95908 |
С “настоящими” вычислениями видим, что параллельные алгоритмы обеспечивают хорошую производительность. Для таких операций на двух моих машинах с Windows я добился ускорения с почти линейной зависимостью от количества ядер.
Для всех тестов я также показал результаты из OpenMP и двух реализаций: MSVC и OpenMP работают аналогично.
Вывод
В этой статье я разобрал три случая применения параллельного вычисления и параллельных алгоритмов. Замена стандартных алгоритмов на версию std::execution::par может показаться очень заманчивой, но делать это стоит не всегда! Каждая операция, используемая вами внутри алгоритма может работать иначе и быть более зависимой от процессора или памяти. Поэтому рассматривайте каждое изменение отдельно.
О чем стоит помнить:
- параллельное выполнение, обычно, делает больше, чем последовательное, так как библиотека должна подготовиться к параллельному выполнению;
- важно не только количество элементов, но и количество команд, которыми занят процессор;
- лучше брать задачи, которые не зависят друг от друга и других общих ресурсов;
- параллельные алгоритмы предлагают простой способ разделять работу на отдельные потоки;
- если ваши операции зависят от памяти, не стоит ожидать улучшения производительности, а в некоторых случаях, алгоритмы могут быть медленнее;
- чтобы получить приличное улучшение производительности, всегда измеряйте тайминги каждой проблемы, в некоторых случаях результаты могут быть совершенно другими.
Особое спасибо JFT за помощь со статьей!
Также обратите внимание на мои другие источники о параллельных алгоритмах:
- Свежая глава в моей книге C++17 In Detail о Параллельных Алгоритмах;
- Parallel STL And Filesystem: Files Word Count Example;
- Примеры параллельных алгоритмов из C++17.
Обратите внимание на другую статью, связанную с Параллельными Алгоритмами: How to Boost Performance with Intel Parallel STL and C++17 Parallel Algorithms
THE END
Ждём и комментарии, и вопросы, которые можно оставить тут или у нашего преподавателя на дне открытых дверей.

{kind=link}