И снова привет!
Коллеги, в последний день января мы запускаем курс «MS SQL Server разработчик», в связи с чем у нас прошёл тематический открытый урок. На нём мы поговорили о том, как MS SQL Server выполняет запрос SELECT, обсудили, в каком порядке и что анализируется, а также немного погрузились в чтение плана запроса.
Преподаватель — Кристина Кучерова, архитектор модели данных в Сбербанке России.
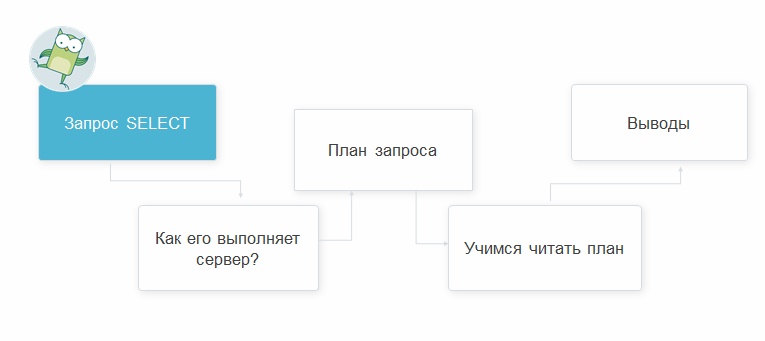
Цели и маршрут вебинара
В начале вебинара были поставлены следующие цели:
Для их достижения преподаватель подготовил простой, но эффективный маршрут:
Зачем нужен план запроса?
План запроса — очень полезный инструмент, который, к сожалению, многие разработчики не используют. На первый взгляд, может показаться, что совсем не обязательно знать механику запроса. Однако если вы будете понимать, что происходит внутри SQL Server, вы сможете написать более эффективный запрос. И это очень поможет, например, при оптимизации.
Как мы видим запрос SELECT?
Давайте посмотрим, как выглядит запрос SELECT:
Как понять, куда идти за данными?
Первое, что пытается понять сервер при поступлении запроса — куда идти за данными. На этот вопрос отвечает команда FROM, т. к. именно здесь у нас будет список таблиц (либо имя одной таблицы).
Для наглядности давайте представим, что наш сервер — это некий дворецкий, которому мы приказываем собрать нас в отпуск. Соответственно, дворецкий начинает думать, а в каком же шкафу лежат нужные вещи (в какой таблице нужно брать данные)? И чтобы наш дворецкий без затруднений выполнил свою задачу, мы используем FROM.
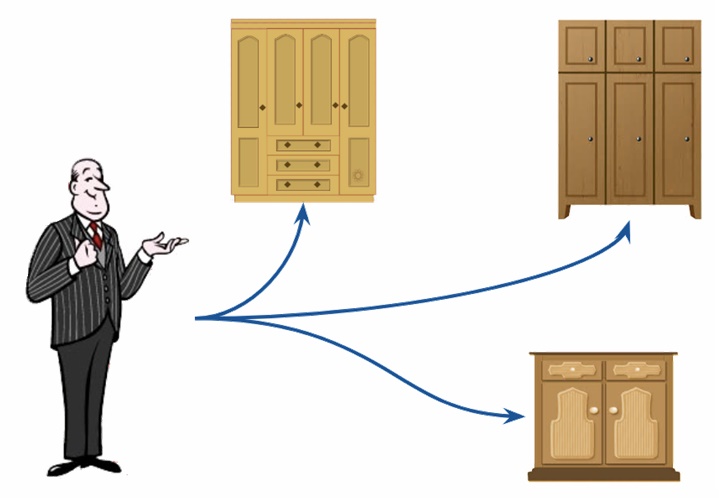
Как понять, какие данные брать?
Допустим, дворецкий нашёл нужный шкаф и открыл его. Но какие вещи брать? Может, мы едем на горнолыжный курорт? А может, на жаркий солнечный пляж? Чтобы наши вещи соответствовали погоде, нам пригодится команда WHERE, определяющая условия, то есть позволяющая отфильтровать данные. Если жарко, берём сланцы, майки и купальники, если холодно — варежки, вязаные носки, свитера)).
Следующий этап — вложить эти данные в группы, что происходит с помощью GROUP BY (майки отдельно, носки отдельно). По результатам группировки можно наложить ещё одно условие, используя HAVING (например, отсеиваем непарные вещи). В конечном итоге всё складываем с помощью ORDER BY, получая на выходе готовый чемодан вещей, а точнее — упорядоченный блок данных.

Кстати, тут есть нюанс, а заключается он в том, что есть разница, какие условия следует прописывать в WHERE, а какие в HAVING. Но об этом лучше посмотреть в видео.
Продолжаем. Путь выполнения запроса сохраняется в виде плана запроса в кэше, то бишь наш дворецкий всё записывает, ведь он хороший дворецкий — вдруг в следующем году вы захотите повторить свой приказ? И таких планов, в принципе, может быть много.
Виды соединений в плане запроса
Существуют три соединения, которые вы можете встретить в плане запроса:
Прежде, чем остановиться на каждом из них подробнее, давайте подытожим, а зачем нам вообще читать план запроса. На самом деле, это очень полезно, так как вы узнаете:
Nested Loop
Допустим, нам нужно соединить данные из разных таблиц. Давайте представим эти таблицы в виде… небольшого количества конфет Skittles и полной упаковки M&M’s.

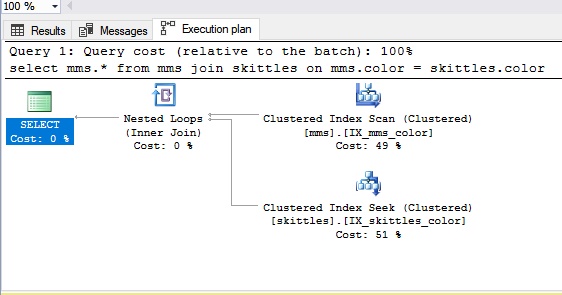
При соединении типа Nested Loop мы берём конфету Skittles, а потом достаём вслепую конфету из пакета M&M’s. Если нам не попадается конфета такого же цвета (это наше условие), мы достаём следующую, то есть происходит обычный перебор. В результате можно сказать, что соединение Nested Loop больше подходит для небольших объёмов данных. Очевидно, что если данных много, перебор — не самый оптимальный вариант.

Посмотрим, как это выглядит в SQL-панели:
Merge join
Соединение используется для больших объёмов данных. Когда у вас Merge join, у вас обе таблицы имеют индекс, по которому их можно соединить. В случае с конфетами – это как будто они у нас заранее разложены по цветам.
Выглядит всё следующим образом:

Merge join хорош в следующих случаях:
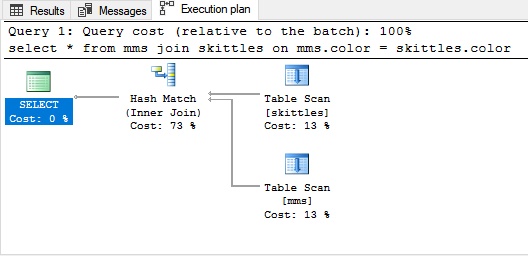
Hash join
Hash join используется при неотсортированных больших объёмах данных. Для соединения таблиц в данном случае нужно построить что-то, имитирующее индекс.
Пример соединения Hash join:
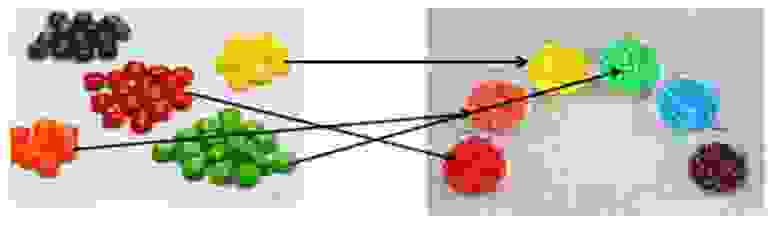
Для наглядности вспомним наши конфеты:

Применение Hash join предполагает 2 фазы действий:
Когда хорош Hash join:
Важный момент: если не хватит памяти, запись пойдёт в tempdb – на диск.
Друзья, кроме вышесказанного, в открытый урок вошли и другие интересные моменты, с которыми лучше всего ознакомиться, посмотрев видео. Мы же предлагаем посетить День открытых дверей курса «MS SQL Server разработчик», где можно будет задать преподавателю все интересующие вопросы.
P. S. Преподаватель Кристина Кучерова выражает признательность Jes Schultz Borland за её презентацию с PASS Summitt Execution Plans: The Secret to Query Tuning Success, которая была использована при подготовке открытого урока.
Коллеги, в последний день января мы запускаем курс «MS SQL Server разработчик», в связи с чем у нас прошёл тематический открытый урок. На нём мы поговорили о том, как MS SQL Server выполняет запрос SELECT, обсудили, в каком порядке и что анализируется, а также немного погрузились в чтение плана запроса.
Преподаватель — Кристина Кучерова, архитектор модели данных в Сбербанке России.
Цели и маршрут вебинара
В начале вебинара были поставлены следующие цели:
- Посмотреть, как сервер выполняет запрос, и почему это происходит именно так.
- Научиться читать план запроса.
Для их достижения преподаватель подготовил простой, но эффективный маршрут:
Зачем нужен план запроса?
План запроса — очень полезный инструмент, который, к сожалению, многие разработчики не используют. На первый взгляд, может показаться, что совсем не обязательно знать механику запроса. Однако если вы будете понимать, что происходит внутри SQL Server, вы сможете написать более эффективный запрос. И это очень поможет, например, при оптимизации.
Как мы видим запрос SELECT?
Давайте посмотрим, как выглядит запрос SELECT:
| SELECT [поле1], [поле2]… |
Какие поля выбираем? |
| FROM [таблица] |
Откуда? |
| WHERE [условия] |
Где условия такие-то |
| GROUP BY [поле1] |
Сгруппируй по полям |
| HAVING [условия] |
Имеющим такие-то условия |
| ORDER BY [поле1] |
Упорядочи (отсортируй) |
Как понять, куда идти за данными?
Первое, что пытается понять сервер при поступлении запроса — куда идти за данными. На этот вопрос отвечает команда FROM, т. к. именно здесь у нас будет список таблиц (либо имя одной таблицы).
Для наглядности давайте представим, что наш сервер — это некий дворецкий, которому мы приказываем собрать нас в отпуск. Соответственно, дворецкий начинает думать, а в каком же шкафу лежат нужные вещи (в какой таблице нужно брать данные)? И чтобы наш дворецкий без затруднений выполнил свою задачу, мы используем FROM.
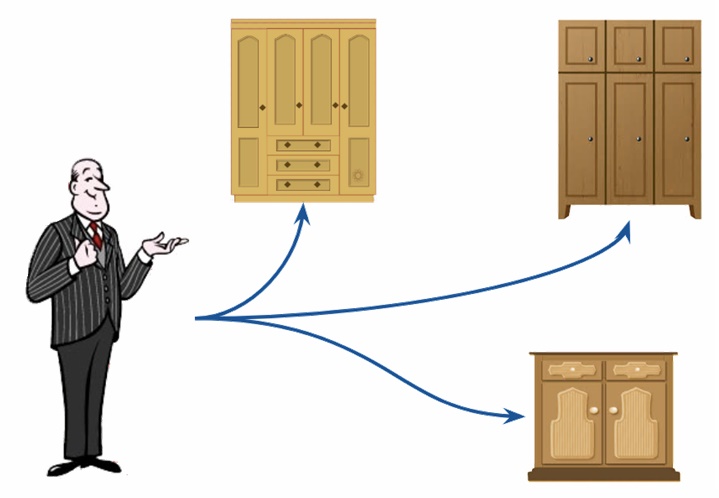
Как понять, какие данные брать?
Допустим, дворецкий нашёл нужный шкаф и открыл его. Но какие вещи брать? Может, мы едем на горнолыжный курорт? А может, на жаркий солнечный пляж? Чтобы наши вещи соответствовали погоде, нам пригодится команда WHERE, определяющая условия, то есть позволяющая отфильтровать данные. Если жарко, берём сланцы, майки и купальники, если холодно — варежки, вязаные носки, свитера)).
Следующий этап — вложить эти данные в группы, что происходит с помощью GROUP BY (майки отдельно, носки отдельно). По результатам группировки можно наложить ещё одно условие, используя HAVING (например, отсеиваем непарные вещи). В конечном итоге всё складываем с помощью ORDER BY, получая на выходе готовый чемодан вещей, а точнее — упорядоченный блок данных.

Кстати, тут есть нюанс, а заключается он в том, что есть разница, какие условия следует прописывать в WHERE, а какие в HAVING. Но об этом лучше посмотреть в видео.
Продолжаем. Путь выполнения запроса сохраняется в виде плана запроса в кэше, то бишь наш дворецкий всё записывает, ведь он хороший дворецкий — вдруг в следующем году вы захотите повторить свой приказ? И таких планов, в принципе, может быть много.
Виды соединений в плане запроса
Существуют три соединения, которые вы можете встретить в плане запроса:
- Nested Loop.
- Merge join.
- Hash join.
Прежде, чем остановиться на каждом из них подробнее, давайте подытожим, а зачем нам вообще читать план запроса. На самом деле, это очень полезно, так как вы узнаете:
- какой индекс используется;
- в каком порядке делается join;
- что выбирается из буффера;
- сколько сервер тратит ресурса на операцию;
- какая разница между гипотетическим и реальным планом.
Nested Loop
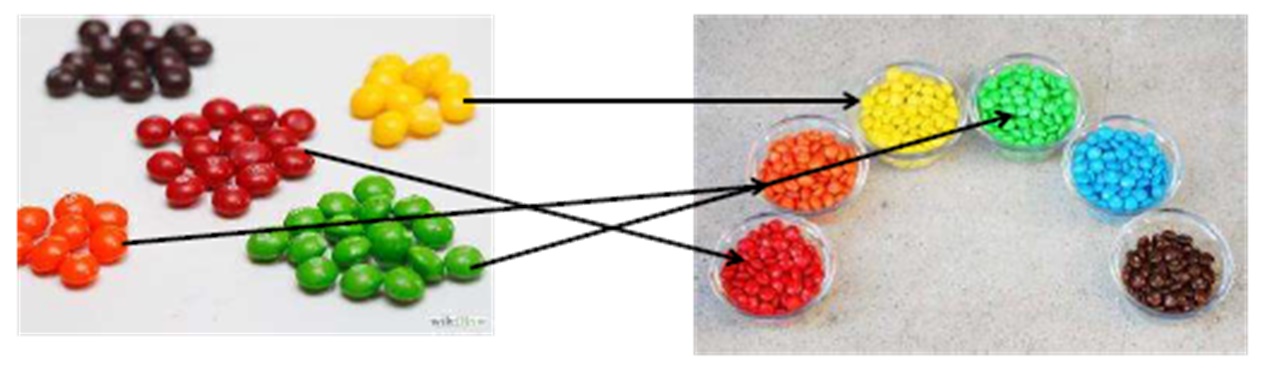
Допустим, нам нужно соединить данные из разных таблиц. Давайте представим эти таблицы в виде… небольшого количества конфет Skittles и полной упаковки M&M’s.

При соединении типа Nested Loop мы берём конфету Skittles, а потом достаём вслепую конфету из пакета M&M’s. Если нам не попадается конфета такого же цвета (это наше условие), мы достаём следующую, то есть происходит обычный перебор. В результате можно сказать, что соединение Nested Loop больше подходит для небольших объёмов данных. Очевидно, что если данных много, перебор — не самый оптимальный вариант.

Посмотрим, как это выглядит в SQL-панели:
--drop table skittles
--drop table mms
--запрос для окна слева
create table mms
(id int identity(1,1),
color varchar(25),
taste varchar(15))
insert into mms (color, taste)
values ('yellow', 'chocolate')
insert into mms (color, taste)
values ('red', 'nuts')
create clustered index IX_mms_color ON mms(color);
create table skittles
(id int identity(1,1),
color varchar(25),
taste varchar(15))
create index IX_skittles_id ON skittles(id);
create clustered index IX_skittles_color ON skittles(color);
insert into skittles (color, taste)
values ('red', 'cherry')
insert into skittles (color, taste)
values ('blue', 'strange')
insert into skittles (color, taste)
values ('yellow', 'lemon')
insert into skittles (color, taste)
values ('green', 'apple')
insert into skittles (color, taste)
values ('orange', 'orange')
--запрос для правого окна
select mms.*
from mms join skittles on
mms.color = skittles.color
select *
from mms join skittles on
mms.color = skittles.color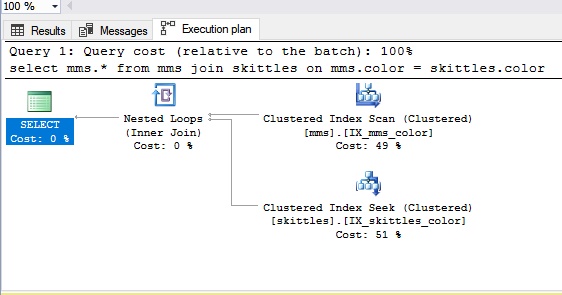
Merge join
Соединение используется для больших объёмов данных. Когда у вас Merge join, у вас обе таблицы имеют индекс, по которому их можно соединить. В случае с конфетами – это как будто они у нас заранее разложены по цветам.
Выглядит всё следующим образом:

--2 tables 50000 rows, only clustered index by color, color is not unique
select COUNT(*)
from mms_big join skittles_big on
mms_big.color = skittles_big.color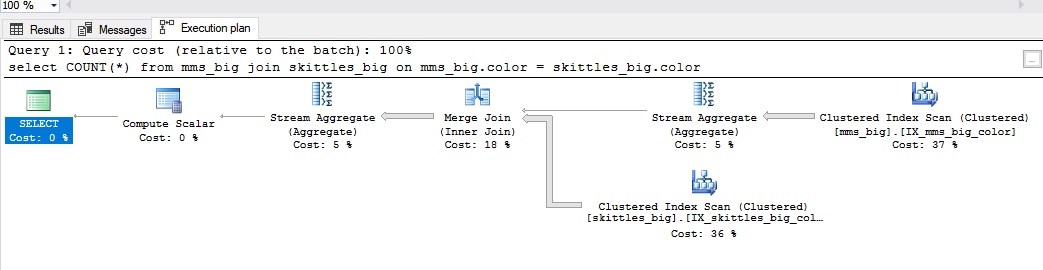
Merge join хорош в следующих случаях:
- большие наборы данных;
- одинаковые поля соединения одного типа;
- по полям соединения есть индексы.
Hash join
Hash join используется при неотсортированных больших объёмах данных. Для соединения таблиц в данном случае нужно построить что-то, имитирующее индекс.
Пример соединения Hash join:
--drop table skittles
--drop table mms
--запрос для окна слева
create table mms
(id int identity(1,1),
color varchar(25),
taste varchar(15))
insert into mms (color, taste)
values ('yellow', 'chocolate')
insert into mms (color, taste)
values ('red', 'nuts')
insert into mms (color, taste)
values ('blue', 'strange')
insert into mms (color, taste)
values ('green', 'chocolate')
insert into mms (color, taste)
values ('orange', 'chocolate')
create table skittles
(id int identity(1,1),
color varchar(25),
taste varchar(15))
insert into skittles (color, taste)
values ('red', 'cherry')
insert into skittles (color, taste)
values ('blue', 'strange')
insert into skittles (color, taste)
values ('yellow', 'lemon')
insert into skittles (color, taste)
values ('green', 'apple')
insert into skittles (color, taste)
values ('orange', 'orange')
--запрос для правого окна
select *
from mms join skittles on
mms.color = skittles.color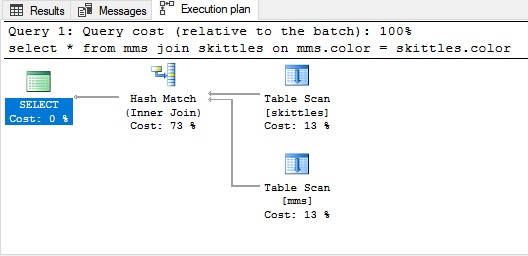
Для наглядности вспомним наши конфеты:

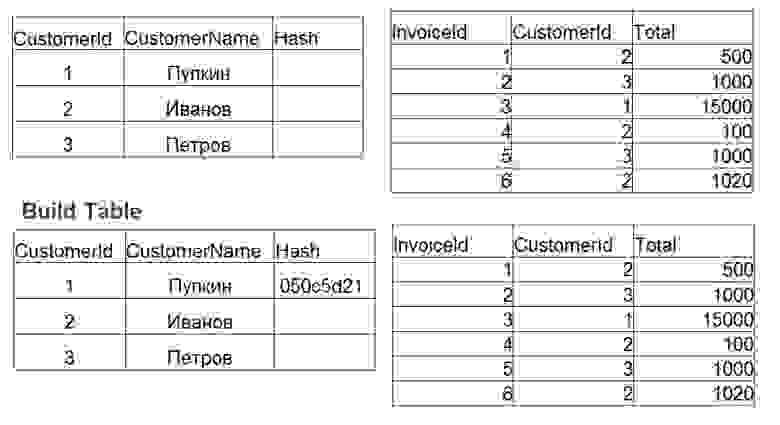
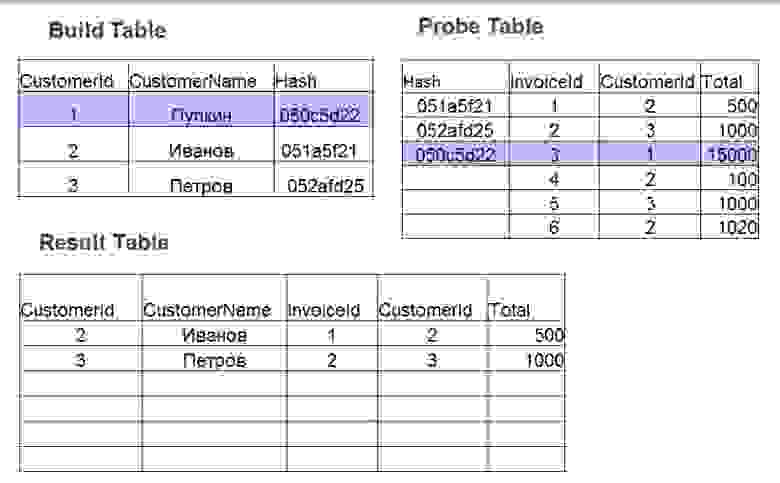
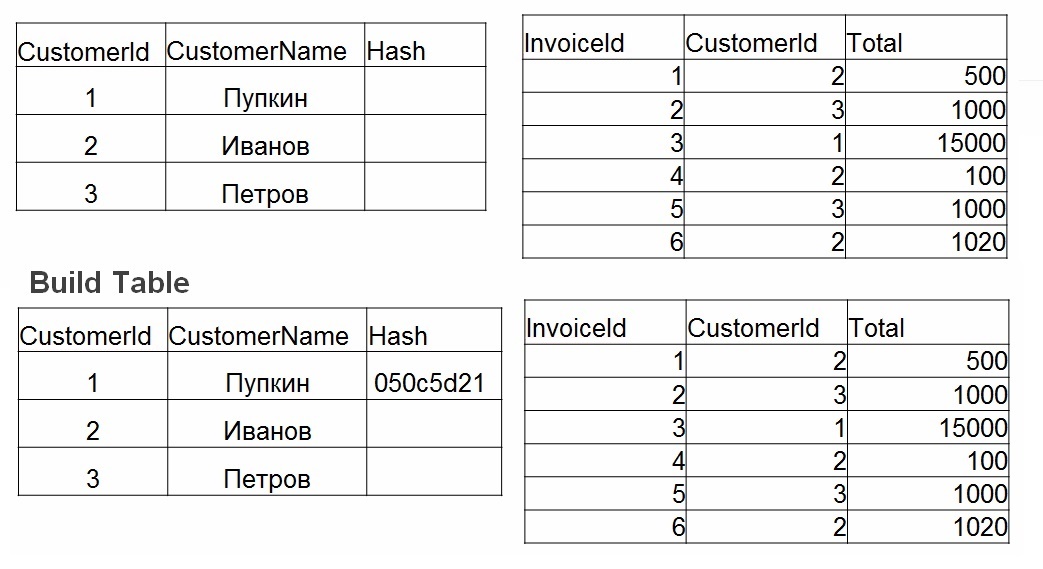
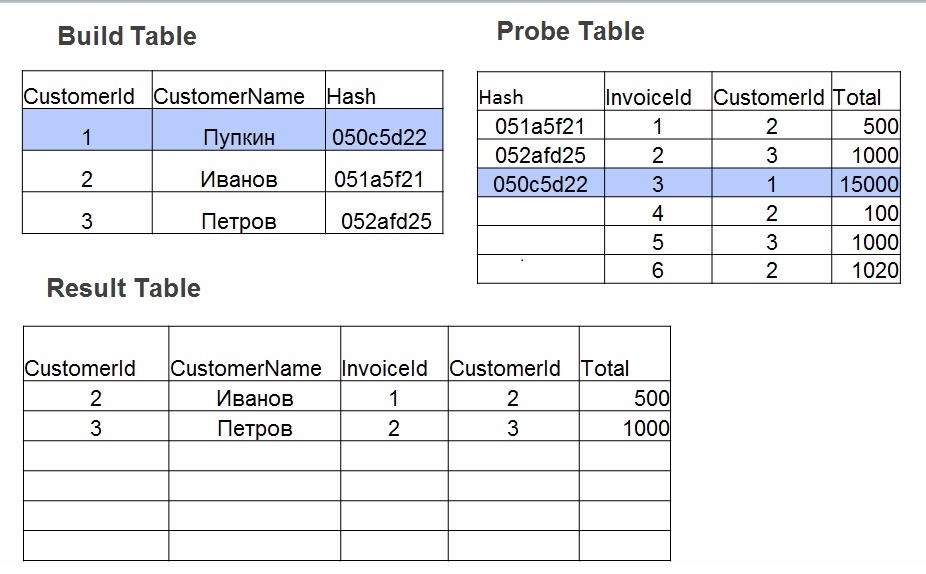
Применение Hash join предполагает 2 фазы действий:
- Build – строится хэш-таблица по наименьшей таблице. Для каждого значения в таблице № 1 считается хэш. Сохраняется значение в хэш-таблицу, а высчитанный хэш используется как ключ.
- Probe. Для каждой строки из таблицы № 2 считается значение хэш по полям, которые указаны в join (оператор =). Ищется хэш в хэш-таблице, проверяются значения полей.
Когда хорош Hash join:
- большой набор данных;
- нет индексов на полях.
Важный момент: если не хватит памяти, запись пойдёт в tempdb – на диск.
Друзья, кроме вышесказанного, в открытый урок вошли и другие интересные моменты, с которыми лучше всего ознакомиться, посмотрев видео. Мы же предлагаем посетить День открытых дверей курса «MS SQL Server разработчик», где можно будет задать преподавателю все интересующие вопросы.
P. S. Преподаватель Кристина Кучерова выражает признательность Jes Schultz Borland за её презентацию с PASS Summitt Execution Plans: The Secret to Query Tuning Success, которая была использована при подготовке открытого урока.
