Салют, хабровчане! Поздравляем всех с днем программиста и делимся переводом статьи, который был подготовлен специально для студентов курса «Архитектор высоких нагрузок».

«Шардировать. Или не шардировать. Без попыток.»
— Йода
Сегодня мы погрузимся в разделение данных между несколькими MySQL серверами. Мы закончили шардинг в начале 2012 года, и эта система используется и по сей день для хранения наших основных данных.
Прежде чем мы обсудим, как разделять данные, давайте с ними познакомимся поближе. Настроим приятный свет, достанем клубнику в шоколаде, вспомним цитаты из Стар Трека…
Pinterest – это поисковый движок для всего, что вам интересно. С точки зрения данных, Pinterest является крупнейшим графом человеческих интересов во всем мире. Он содержит более 50 миллиардов пинов, которые были сохранены пользователями на более чем миллиард досок. Люди сохраняют одни пины себе и ставят лайки другим пинам, подписываются на других пиннеров, доски и интересы, просматривают домашнюю ленту всех пиннеров, досок и интересов, на которые они подписаны. Отлично! Теперь давайте сделаем это масштабируемым!
В 2011 году мы начали набирать обороты. По некоторым оценкам, мы росли быстрее, чем любой известный на то время стартап. Примерно в сентябре 2011 года каждая составляющая нашей инфраструктуры была перегружена. В нашем распоряжении было несколько NoSQL технологий, и все они катастрофически не справлялись. Также у нас было множество MySQL slave’ов, которых мы использовали для чтения, что вызывало множество неординарных ошибок, особенно при кэшировании. Мы перестроили всю нашу модель хранения данных. Чтобы работать эффективно, мы тщательно подошли к разработке требований.
Поскольку мы хотели, чтобы эти данные охватывали несколько баз данных, мы не могли использовать просто объединение, внешние ключи и индексы для сбора всех данных, хотя они могут использоваться для подзапросов, которые не охватывают базы данных.
Также нам нужно было поддерживать балансировку нагрузки на данные. Мы решили, что перемещение данных, элемент за элементом, сделает систему излишне сложной и вызовет множество ошибок. Если нам нужно было переместить данные, лучше было переместить весь виртуальный узел на другой физический узел.
Для того, чтобы наша реализация быстро вошла в оборот, нам нужно было самое и простое удобное решение и очень стабильные узлы в нашей распределенной платформе данных.
Все данные нужно было реплицировать на slave-машину для создания резервной копии, с высокой доступностью и демпингом на S3 для MapReduce. С master мы взаимодействуем только на продакшене. На продакшене вы не захотите писать или читать в slave. Slave лагают, и это вызывает странные баги. Если произведен шардинг, нет никакого смысла взаимодействовать со slave на продакшене.
Наконец, нам нужен хороший способ генерировать универсальные уникальные идентификаторы (UUID) для всех наших объектов.
То, что мы собирались создать, должно было удовлетворять требованиям, работать стабильно, в целом быть работоспособным и ремонтопригодным. Именно поэтому в качестве базовой технологии мы выбрали уже достаточно зрелую технологию MySQL. Мы намеренно остерегались новых технологий автоматического масштабирования MongoDB, Cassandra и Membase, потому что им было достаточно далеко до зрелости (и в нашем случае они ломались впечатляющими способами!).
Мы начали с восьми ЕС2 серверов по одному экземпляру MySQL на каждом:
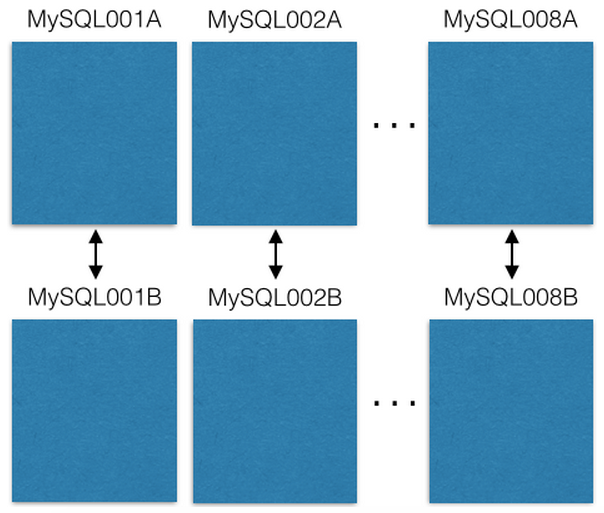
Каждый сервер MySQL master-master реплицируется на резервный хост в случае сбоя основного. Наши продакшен-сервера только читают или пишут в master. Вам я рекомендую делать также. Это многое упрощает и позволяет избежать ошибок с задержками репликации.
У каждой сущности MySQL есть множество баз данных:
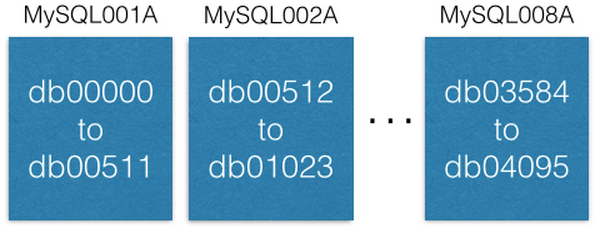
Заметьте, что каждая база данных названа уникально: db00000, db00001 до dbNNNNN. Каждая база данных – это шард наших данных. Мы приняли архитектурное решение, исходя из которого только часть данных попадает в шард, и она никогда не выходит за пределы этого шарда. Однако вы можете получить большую емкость, перемещая шарды на другие машины (об этом мы поговорим позже).
Мы работаем с таблицей конфигурации, которая указывает, на каких машинах находятся шарды:
Эта конфигурация меняется только тогда, когда нам нужно переместить шарды или заменить хост. Если
В каждом шарде один и тот же набор таблиц:
Как мы распределяем данные по этим шардам?
Мы создаем 64-х битное ID, которое содержит ID шарда, тип содержащихся в нем данных и место, где эти данные находятся в таблице (локальное ID). ID шарда состоит из 16 бит, ID типа – 10 бит и локальное ID – 36 бит. Продвинутые математики заметят, что здесь только 62 бита. Мой прошлый опыт разработчика компиляторов и плат научил меня, что резервные биты стоят на вес золота. Итак, таких битов у нас два (установленных в ноль).
Возьмем вот этот пин: https://www.pinterest.com/pin/241294492511762325/, разберем его ID 241294492511762325:
Таким образом, объект-пин живет в 3429 шарде. Его тип «1» (то есть “Pin”), и он в строке 7075733 в таблице пинов. Например, давайте представим, что этот шард в MySQL012A. Мы можем добраться до него следующим образом:
Есть два типа данных: объекты и маппинги. Объекты содержат детали, такие как данные пина.
Таблицы объектов, такие как Pins, users, boards и comments имеют ID (локальный ID, с автоматически увеличивающимся первичным ключом) и блобом (blob), который содержит JSON со всеми данными объекта.
Например, объекты-пины выглядят так:
Чтобы создать новый пин, мы собираем все данные и создаем JSON блоб. Затем выбираем ID шарда (мы предпочитаем выбирать такой же ID шарда, как и доски, на которую он помещается, но это не обязательно). Для пина тип 1. Мы подключаемся к этой базе данных и вставляем JSON в таблицу пинов. MySQL вернет автоматически увеличенный локальный ID. Теперь у нас есть шард, тип и новый локальный ID, поэтому мы можем составить полный 64-х битный идентификатор!
Чтобы отредактировать пин мы читаем-изменяем-записываем JSON с помощью MySQL транзакции:
Чтобы удалить пин, вы можете удалить его строку в MySQL. Однако лучше добавить в JSON поле “active” и установить его в “false”, а также отфильтровать результаты на стороне клиента.
Таблица маппингов связывает один объект с другим, например доску с пинами на ней. Таблица MySQL для маппингов содержит три колонки: 64-бита на ID «откуда», 64-бита на ID «куда» и ID последовательности. В этой тройке (откуда, куда, последовательность) есть ключи индекса, и они находятся на шарде идентификатора «откуда».
Таблицы маппингов являются однонаправленными, например, как таблица
Это выдаст вам более 50 pin_id, которые затем можно использовать для поиска объектов-пинов.
То, что мы только что сделали, — это join прикладного уровня (board_id -> pin_id -> объекты-пины). Одно из удивительных свойств соединений на прикладном уровне заключается в том, что вы можете кэшировать изображение отдельно от объекта. Мы сохраняем pin_id в кэш объекта-пина в кластере memcache, однако мы сохраняем board_id в pin_id в кластере redis. Это позволяет нам правильно выбрать технологию, которая наилучшим образом соответствует кэшируемому объекту.
В нашей системе есть три основных способа увеличить емкость. Проще всего обновить машины (увеличить место, поставить более быстрые жесткие диски, больше оперативной памяти).
Следующий способ увеличить емкость – открыть новые диапазоны. Изначально мы создавали всего 4096 шардов, несмотря на то что ID шарда состоял из 16 бит (всего 64к шардов). Новые объекты могут быть созданы только в этих первых 4к шардах. В определенный момент мы решили создать новые MySQL-серверы с шардами от 4096 до 8191 и начали заполнять их.
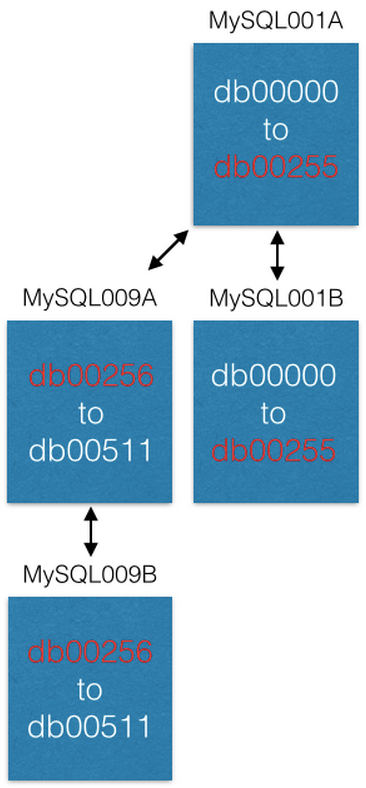
Последний способ, которым мы увеличивали емкость – это перемещение некоторых шардов на новые машины. Если мы хотим увеличить емкость MySQL001A (с шардами от 0 до 511), мы создаем новую пару master-master со следующими максимально возможными именами (скажем MySQL009A и B) и начинаем репликацию из MySQL001A.
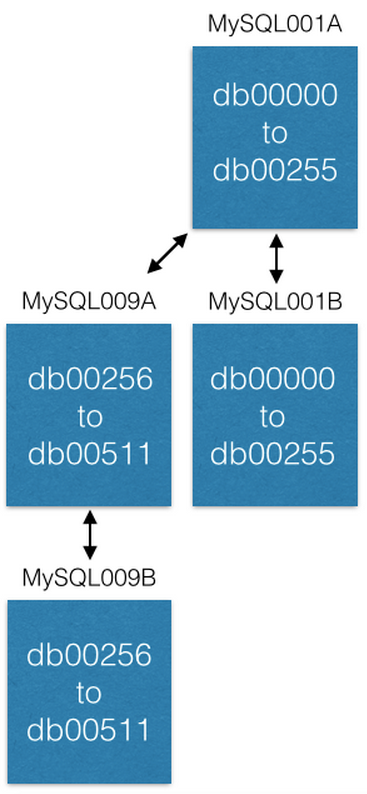
Как только репликация завершена, мы изменяем нашу конфигурацию таким образом, чтобы в MySQL001A были только шарды с 0 по 255, а в MySQL009A с 256 по 511. Теперь каждый сервер должен обрабатывать только половину из тех шардов, что он обрабатывал раньше.
Те, у кого уже были системы для генерации новых UUID, поймут, что в этой системе мы получаем их без затрат! Когда вы создаете новый объект и вставляете его в таблицу объектов, он возвращает новый локальный идентификатор. Этот локальный ID в сочетании с ID шарда и ID типа дает вам UUID.
Те из вас, кто выполнял ALTER’ы, чтобы добавить больше столбцов в таблицы MySQL, знают, что они могут работать крайне медленно и стать большой проблемой. Наш подход не требует каких-либо изменений уровня MySQL. В Pinterest мы, вероятно, сделали лишь один ALTER за последние три года. Чтобы добавить новые поля в объекты, просто скажите вашим сервисам, что в схеме JSON есть несколько новых полей. Вы можете изменить значение по умолчанию, чтобы при десериализации JSON из объекта без нового поля вы получали значение по умолчанию. Если вам нужна таблица маппингов, создайте новую таблицу маппингов и начните заполнять ее, когда захотите. А когда закончите, можете отправлять!
Это почти как Mod Squad, только полностью отличается.
Некоторые объекты нужно находить без ID. Например, если пользователь входит с помощью аккаунта Facebook, нам понадобится маппинг из ID Facebook в ID Pinterest. Для нас ID Facebook — это просто биты, поэтому мы храним их в отдельной шард-системе, называемой mod shard.
Другие примеры включают IP-адреса, имя пользователя и адрес электронной почты.
Mod Shard очень похож на систему шардинга, описанную в предыдущем разделе, с той лишь разницей, что вы можете искать данные с помощью произвольных входных данных. Эти входные данные хэшируются и модифицируются в соответствии с общим количеством шардов в системе. В результате будет получен шард, на котором будут находиться или уже находятся данные. Например:
В этом случае shard будет равен 1524. Мы обрабатываем файл конфигурации, соответствующий ID шарда:
Таким образом, чтобы найти данные об IP адресе 1.2.3.4, нам нужно будет сделать следующее:
Вы теряете некоторые хорошие свойства ID шарда, такие как пространственная локальность. Вам придется начать со всех шардов созданных в самом начале и создать ключ самостоятельно (он не будет сгенерирован автоматически). Всегда лучше представлять объекты в вашей системе с неизменяемыми ID. Таким образом, вам не понадобится обновлять много ссылок, когда, например, пользователь меняет свое «имя пользователя».
Эта система работает на продакшене в Pinterest уже 3.5 года, и вероятно, останется там навсегда. Реализация ее была относительно простой, но вводить ее в эксплуатацию и перемещать все данные со старых машин было тяжко. Если вы сталкиваетесь с проблемой, когда вы только создали новый шард, подумайте о создании кластера машин фоновой обработки данных (подсказка: используйте pyres) для перемещения ваших данных скриптами из старых баз данных в ваш новый шард. Я гарантирую, что часть данных пропадет, независимо от того насколько сильно вы стараетесь (это все гремлины, я клянусь), поэтому повторяйте передачу данных снова и снова, пока количество новой информации в шарде не станет очень маленьким или ее не будет совсем.
К этой системе были приложены все усилия. Но она не обеспечивает атомарность, изолированность или согласованность в любом случае. Воу! Это звучит плохо! Но не переживайте. Наверняка, вы будете себя превосходно чувствовать и без них. Вы всегда можете нарастить эти слои другими процессами/системами, если это необходимо, но по умолчанию и без затрат вы уже просто получаете достаточно много: работоспособность. Надежность, достигнутая через простоту, да еще и работает быстро!
Но как насчет отказоустойчивости? Мы создали сервис для обслуживания шардов MySQL, сохранили таблицу конфигурации шардов в ZooKeeper. Когда master-сервер падает, мы поднимаем slave-машину, а затем поднимаем машину, которая ее заменит (всегда в актуальном состоянии). Мы не используем автоматическую обработку отказа и по сей день.

«Шардировать. Или не шардировать. Без попыток.»
— Йода
Сегодня мы погрузимся в разделение данных между несколькими MySQL серверами. Мы закончили шардинг в начале 2012 года, и эта система используется и по сей день для хранения наших основных данных.
Прежде чем мы обсудим, как разделять данные, давайте с ними познакомимся поближе. Настроим приятный свет, достанем клубнику в шоколаде, вспомним цитаты из Стар Трека…
Pinterest – это поисковый движок для всего, что вам интересно. С точки зрения данных, Pinterest является крупнейшим графом человеческих интересов во всем мире. Он содержит более 50 миллиардов пинов, которые были сохранены пользователями на более чем миллиард досок. Люди сохраняют одни пины себе и ставят лайки другим пинам, подписываются на других пиннеров, доски и интересы, просматривают домашнюю ленту всех пиннеров, досок и интересов, на которые они подписаны. Отлично! Теперь давайте сделаем это масштабируемым!
Болезненный рост
В 2011 году мы начали набирать обороты. По некоторым оценкам, мы росли быстрее, чем любой известный на то время стартап. Примерно в сентябре 2011 года каждая составляющая нашей инфраструктуры была перегружена. В нашем распоряжении было несколько NoSQL технологий, и все они катастрофически не справлялись. Также у нас было множество MySQL slave’ов, которых мы использовали для чтения, что вызывало множество неординарных ошибок, особенно при кэшировании. Мы перестроили всю нашу модель хранения данных. Чтобы работать эффективно, мы тщательно подошли к разработке требований.
Требования
- Вся система должна быть очень стабильной, простой в эксплуатации и масштабироваться от размеров небольшой коробки до размеров луны по мере роста сайта.
- Весь контент сгенерированный пиннером должен быть доступен на сайте в любое время.
- Система должна поддерживать запрос N пинов на доске в детерминированном порядке (например, в обратном порядке по времени создания или в порядке, указанном пользователем). То же самое для лайков пиннеров, их пинов и т.д.
- Для простоты, следует всячески стремиться к обновлениям. Чтобы получить необходимую согласованность, понадобятся дополнительные игрушки, такие как журнал распределенных транзакций. Это весело и (не слишком) просто!
Философия архитектуры и примечания
Поскольку мы хотели, чтобы эти данные охватывали несколько баз данных, мы не могли использовать просто объединение, внешние ключи и индексы для сбора всех данных, хотя они могут использоваться для подзапросов, которые не охватывают базы данных.
Также нам нужно было поддерживать балансировку нагрузки на данные. Мы решили, что перемещение данных, элемент за элементом, сделает систему излишне сложной и вызовет множество ошибок. Если нам нужно было переместить данные, лучше было переместить весь виртуальный узел на другой физический узел.
Для того, чтобы наша реализация быстро вошла в оборот, нам нужно было самое и простое удобное решение и очень стабильные узлы в нашей распределенной платформе данных.
Все данные нужно было реплицировать на slave-машину для создания резервной копии, с высокой доступностью и демпингом на S3 для MapReduce. С master мы взаимодействуем только на продакшене. На продакшене вы не захотите писать или читать в slave. Slave лагают, и это вызывает странные баги. Если произведен шардинг, нет никакого смысла взаимодействовать со slave на продакшене.
Наконец, нам нужен хороший способ генерировать универсальные уникальные идентификаторы (UUID) для всех наших объектов.
Как мы делали шардинг
То, что мы собирались создать, должно было удовлетворять требованиям, работать стабильно, в целом быть работоспособным и ремонтопригодным. Именно поэтому в качестве базовой технологии мы выбрали уже достаточно зрелую технологию MySQL. Мы намеренно остерегались новых технологий автоматического масштабирования MongoDB, Cassandra и Membase, потому что им было достаточно далеко до зрелости (и в нашем случае они ломались впечатляющими способами!).
Кроме того: Я по-прежнему рекомендую стартапам избегать новых причудливых штук – постарайтесь просто использовать MySQL. Доверьтесь мне. Я могу доказать это «шрамами».MySQL – технология проверенная, стабильная, да и просто – она работает. Мало того, что мы используем ее, она популярна и в других компаниях с масштабами еще более внушительными. MySQL вполне отвечает нашей потребности в упорядочивании запросов данных, выборе определенных диапазонов данных и транзакций на уровне строк. На самом деле, в его арсенале гораздо больше возможностей, но нам они все не нужны. Но MySQL – это «коробочное» решение, поэтому данные необходимо было шардировать. Вот так выглядит наше решение:
Мы начали с восьми ЕС2 серверов по одному экземпляру MySQL на каждом:
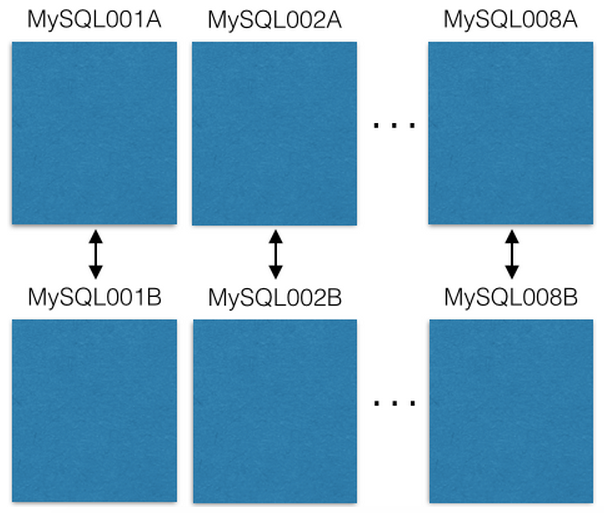
Каждый сервер MySQL master-master реплицируется на резервный хост в случае сбоя основного. Наши продакшен-сервера только читают или пишут в master. Вам я рекомендую делать также. Это многое упрощает и позволяет избежать ошибок с задержками репликации.
У каждой сущности MySQL есть множество баз данных:

Заметьте, что каждая база данных названа уникально: db00000, db00001 до dbNNNNN. Каждая база данных – это шард наших данных. Мы приняли архитектурное решение, исходя из которого только часть данных попадает в шард, и она никогда не выходит за пределы этого шарда. Однако вы можете получить большую емкость, перемещая шарды на другие машины (об этом мы поговорим позже).
Мы работаем с таблицей конфигурации, которая указывает, на каких машинах находятся шарды:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]Эта конфигурация меняется только тогда, когда нам нужно переместить шарды или заменить хост. Если
master умирает, мы можем использовать существующий slave, а затем поднять новый. Конфигурация находится в ZooKeeper и, при обновлении, отправляется в службы, которые обслуживают шард MySQL.В каждом шарде один и тот же набор таблиц:
pins, boards, users_has_pins, users_likes_pins, pin_liked_by_user и т.д. Об этом я расскажу чуть позже.Как мы распределяем данные по этим шардам?
Мы создаем 64-х битное ID, которое содержит ID шарда, тип содержащихся в нем данных и место, где эти данные находятся в таблице (локальное ID). ID шарда состоит из 16 бит, ID типа – 10 бит и локальное ID – 36 бит. Продвинутые математики заметят, что здесь только 62 бита. Мой прошлый опыт разработчика компиляторов и плат научил меня, что резервные биты стоят на вес золота. Итак, таких битов у нас два (установленных в ноль).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)Возьмем вот этот пин: https://www.pinterest.com/pin/241294492511762325/, разберем его ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429
Type ID = (241294492511762325 >> 36) & 0x3FF = 1
Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733Таким образом, объект-пин живет в 3429 шарде. Его тип «1» (то есть “Pin”), и он в строке 7075733 в таблице пинов. Например, давайте представим, что этот шард в MySQL012A. Мы можем добраться до него следующим образом:
conn = MySQLdb.connect(host=”MySQL012A”)
conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)Есть два типа данных: объекты и маппинги. Объекты содержат детали, такие как данные пина.
Таблицы объектов
Таблицы объектов, такие как Pins, users, boards и comments имеют ID (локальный ID, с автоматически увеличивающимся первичным ключом) и блобом (blob), который содержит JSON со всеми данными объекта.
CREATE TABLE pins (
local_id INT PRIMARY KEY AUTO_INCREMENT,
data TEXT,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;Например, объекты-пины выглядят так:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}Чтобы создать новый пин, мы собираем все данные и создаем JSON блоб. Затем выбираем ID шарда (мы предпочитаем выбирать такой же ID шарда, как и доски, на которую он помещается, но это не обязательно). Для пина тип 1. Мы подключаемся к этой базе данных и вставляем JSON в таблицу пинов. MySQL вернет автоматически увеличенный локальный ID. Теперь у нас есть шард, тип и новый локальный ID, поэтому мы можем составить полный 64-х битный идентификатор!
Чтобы отредактировать пин мы читаем-изменяем-записываем JSON с помощью MySQL транзакции:
> BEGIN
> SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE
[Modify the json blob]
> UPDATE db03429.pins SET blob=’<modified blob>’ WHERE local_id=7075733
> COMMITЧтобы удалить пин, вы можете удалить его строку в MySQL. Однако лучше добавить в JSON поле “active” и установить его в “false”, а также отфильтровать результаты на стороне клиента.
Таблицы маппингов
Таблица маппингов связывает один объект с другим, например доску с пинами на ней. Таблица MySQL для маппингов содержит три колонки: 64-бита на ID «откуда», 64-бита на ID «куда» и ID последовательности. В этой тройке (откуда, куда, последовательность) есть ключи индекса, и они находятся на шарде идентификатора «откуда».
CREATE TABLE board_has_pins (
board_id INT,
pin_id INT,
sequence INT,
INDEX(board_id, pin_id, sequence)
) ENGINE=InnoDB;Таблицы маппингов являются однонаправленными, например, как таблица
board_has_pins. Если вам нужно противоположное направление, вам понадобится отдельная таблица pin_owned_by_board. ID последовательности задает последовательность (наши ID не могут сравниваться между шардами, поскольку новые локальные ID отличаются). Обычно мы вставляем новые пины на новую доску с ID последовательности равным времени в unix (unix timestamp). В последовательности могут быть любые цифры, но unix-время – это хороший способ хранить новые материалы последовательно, поскольку этот показатель монотонно увеличивается. Вы можете взглянуть на данные в таблице маппингов:SELECT pin_id FROM board_has_pins
WHERE board_id=241294561224164665 ORDER BY sequence
LIMIT 50 OFFSET 150Это выдаст вам более 50 pin_id, которые затем можно использовать для поиска объектов-пинов.
То, что мы только что сделали, — это join прикладного уровня (board_id -> pin_id -> объекты-пины). Одно из удивительных свойств соединений на прикладном уровне заключается в том, что вы можете кэшировать изображение отдельно от объекта. Мы сохраняем pin_id в кэш объекта-пина в кластере memcache, однако мы сохраняем board_id в pin_id в кластере redis. Это позволяет нам правильно выбрать технологию, которая наилучшим образом соответствует кэшируемому объекту.
Увеличиваем емкость
В нашей системе есть три основных способа увеличить емкость. Проще всего обновить машины (увеличить место, поставить более быстрые жесткие диски, больше оперативной памяти).
Следующий способ увеличить емкость – открыть новые диапазоны. Изначально мы создавали всего 4096 шардов, несмотря на то что ID шарда состоял из 16 бит (всего 64к шардов). Новые объекты могут быть созданы только в этих первых 4к шардах. В определенный момент мы решили создать новые MySQL-серверы с шардами от 4096 до 8191 и начали заполнять их.
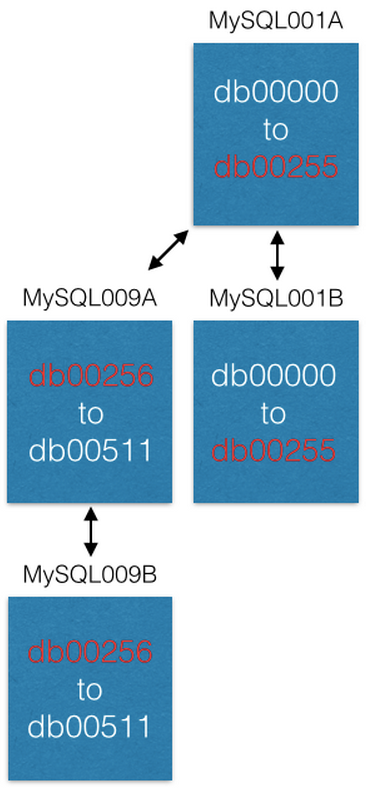
Последний способ, которым мы увеличивали емкость – это перемещение некоторых шардов на новые машины. Если мы хотим увеличить емкость MySQL001A (с шардами от 0 до 511), мы создаем новую пару master-master со следующими максимально возможными именами (скажем MySQL009A и B) и начинаем репликацию из MySQL001A.
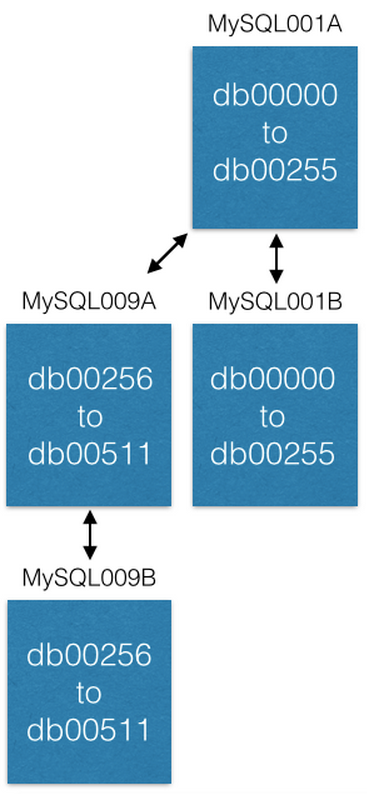
Как только репликация завершена, мы изменяем нашу конфигурацию таким образом, чтобы в MySQL001A были только шарды с 0 по 255, а в MySQL009A с 256 по 511. Теперь каждый сервер должен обрабатывать только половину из тех шардов, что он обрабатывал раньше.
Несколько классных свойств
Те, у кого уже были системы для генерации новых UUID, поймут, что в этой системе мы получаем их без затрат! Когда вы создаете новый объект и вставляете его в таблицу объектов, он возвращает новый локальный идентификатор. Этот локальный ID в сочетании с ID шарда и ID типа дает вам UUID.
Те из вас, кто выполнял ALTER’ы, чтобы добавить больше столбцов в таблицы MySQL, знают, что они могут работать крайне медленно и стать большой проблемой. Наш подход не требует каких-либо изменений уровня MySQL. В Pinterest мы, вероятно, сделали лишь один ALTER за последние три года. Чтобы добавить новые поля в объекты, просто скажите вашим сервисам, что в схеме JSON есть несколько новых полей. Вы можете изменить значение по умолчанию, чтобы при десериализации JSON из объекта без нового поля вы получали значение по умолчанию. Если вам нужна таблица маппингов, создайте новую таблицу маппингов и начните заполнять ее, когда захотите. А когда закончите, можете отправлять!
Mod Shard
Это почти как Mod Squad, только полностью отличается.
Некоторые объекты нужно находить без ID. Например, если пользователь входит с помощью аккаунта Facebook, нам понадобится маппинг из ID Facebook в ID Pinterest. Для нас ID Facebook — это просто биты, поэтому мы храним их в отдельной шард-системе, называемой mod shard.
Другие примеры включают IP-адреса, имя пользователя и адрес электронной почты.
Mod Shard очень похож на систему шардинга, описанную в предыдущем разделе, с той лишь разницей, что вы можете искать данные с помощью произвольных входных данных. Эти входные данные хэшируются и модифицируются в соответствии с общим количеством шардов в системе. В результате будет получен шард, на котором будут находиться или уже находятся данные. Например:
shard = md5(“1.2.3.4") % 4096В этом случае shard будет равен 1524. Мы обрабатываем файл конфигурации, соответствующий ID шарда:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”},
{“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”},
{“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”},
…]Таким образом, чтобы найти данные об IP адресе 1.2.3.4, нам нужно будет сделать следующее:
conn = MySQLdb.connect(host=”msdb003a”)
conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)Вы теряете некоторые хорошие свойства ID шарда, такие как пространственная локальность. Вам придется начать со всех шардов созданных в самом начале и создать ключ самостоятельно (он не будет сгенерирован автоматически). Всегда лучше представлять объекты в вашей системе с неизменяемыми ID. Таким образом, вам не понадобится обновлять много ссылок, когда, например, пользователь меняет свое «имя пользователя».
Последние мысли
Эта система работает на продакшене в Pinterest уже 3.5 года, и вероятно, останется там навсегда. Реализация ее была относительно простой, но вводить ее в эксплуатацию и перемещать все данные со старых машин было тяжко. Если вы сталкиваетесь с проблемой, когда вы только создали новый шард, подумайте о создании кластера машин фоновой обработки данных (подсказка: используйте pyres) для перемещения ваших данных скриптами из старых баз данных в ваш новый шард. Я гарантирую, что часть данных пропадет, независимо от того насколько сильно вы стараетесь (это все гремлины, я клянусь), поэтому повторяйте передачу данных снова и снова, пока количество новой информации в шарде не станет очень маленьким или ее не будет совсем.
К этой системе были приложены все усилия. Но она не обеспечивает атомарность, изолированность или согласованность в любом случае. Воу! Это звучит плохо! Но не переживайте. Наверняка, вы будете себя превосходно чувствовать и без них. Вы всегда можете нарастить эти слои другими процессами/системами, если это необходимо, но по умолчанию и без затрат вы уже просто получаете достаточно много: работоспособность. Надежность, достигнутая через простоту, да еще и работает быстро!
Но как насчет отказоустойчивости? Мы создали сервис для обслуживания шардов MySQL, сохранили таблицу конфигурации шардов в ZooKeeper. Когда master-сервер падает, мы поднимаем slave-машину, а затем поднимаем машину, которая ее заменит (всегда в актуальном состоянии). Мы не используем автоматическую обработку отказа и по сей день.
