В преддверии старта нового потока по курсу «Нейронные сети на Python» подготовили для вас перевод интересной статьи.

Одна из самых главных проблем в реализации нового поколения квантовых компьютеров заключается в их самой базовой конситуэнте: кубите. Кубиты могут взаимодействовать с любыми объектами в непосредственной близости, которые переносят энергию близко к их собственным блуждающим фотонам (т.е. нежелательные электромагнитные поля, фононы (механические колебания квантового устройства) или квантовые дефекты (неровности на поверхности чипа, появившиеся на этапе производства), которые могут непредсказуемо менять состояние кубитов самостоятельно.
Дело осложняется множеством задач, которые ставят инструменты, используемые для контроля кубитов. Обработка и считывание кубитов производится классическими методами: аналоговые сигналы в виде электромагнитных полей вкупе с физической платой, в которую встроен кубит, например, сверхпроводящая микросхема. Несовершенства в управляющей электронике (приводящие к возникновению белого шума), помехи от внешних источников излучения и флуктуации в цифроаналоговых преобразователях приводят к еще большим стохастическим ошибкам, ухудшающим работу квантовых микросхем. Эти практические вопросы влияют на точность вычислений и, таким образом, ограничивают применение грядущего поколения квантовых устройств.
Чтобы повысить вычислительную мощность квантовых компьютеров и открыть путь к масштабным квантовым вычислениям, необходимо сначала построить физические модели, которые точно описывают эти экспериментальные задачи.
В статье “Universal Quantum Control through Deep Reinforcement Learning”, опубликованной в Nature Partner Journal (npj) Quantum Information (https://www.nature.com/npjqi/articles), мы представили новую структуру квантового управления, созданную с использованием глубокого обучения с подкреплением, в которой практические проблемы оптимизации квантового управления можно инкапсулировать одной функцией потерь. Рассмотренная структура обеспечивает снижение средней ошибки квантового вентиля до двух порядков по сравнению со стандартными стохастическими решениями градиентного спуска и значительное уменьшение времени вентиля (gate) до оптимальных значений аналогов синтеза вентиля. Наши результаты открывают новые горизонты квантового моделирования, квантовой химии и тестов квантового превосходства с использованием квантовых устройств ближайшего будущего.
Инновационность этой парадигмы квантового управления основывается на разработке квантовой функции управления и эффективного метода оптимизации, основанного на глубоком обучении с подкреплением. Чтобы разработать комплексную функцию потерь, для начала нужно разработать физическую модель реалистичного квантового процесса управления, в котором мы сможем точно предсказать величину ошибки. Одной из наиболее неприятных ошибок при оценке точности квантовых вычислений является утечка: количество квантовой информации, потерянной во время вычисления. Такая утечка обычно происходит, когда квантовой состояние кубита изменяется до более высокого энергетического уровня или до более низкого за счет спонтанного излучения. Из-за ошибки-утечки теряется не только полезная квантовая информация, она также ухудшает «квантовость» и в конечном итоге снижает производительность квантового компьютера до производительности компьютера с классической архитектурой.
Обычная практика для точной оценки потерянной информации во время квантового вычисления заключается в том, чтобы сначала смоделировать все вычисление целиком. Однако это сводит на нет весь смысл создания масштабных квантовых компьютеров, поскольку их преимущество заключается в том, что они способны выполнять вычисления невозможные для классических компьютеров. С улучшением физического моделирования наша общая функция потерь позволяет совместно оптимизировать накопленные ошибки утечки, нарушения граничных условий управления, общее время вентиля и точность вентиля.
С помощью новой функции управления потерями следующим шагом будет применение эффективного инструмента оптимизации для ее минимизации. Существующие методы оптимизации оказываются недостаточно хороши для поиска высокоточных решений, которые являются надежными для управления флуктуациями. Вместо этого мы применяем метод на основе on-policy метода глубокого обучения с подкреплением (RL), RL – доверенной области. Поскольку этот метод демонстрирует хорошую производительность на всех тестовых задачах, он по своей сути устойчив к шумам выборки и умеет оптимизировать сложные задачи управления с сотнями миллионов параметров управления. Существенным отличием этого on-policy RL метода от изученных ранее off-policy RL методов является то, что политика управления представляется независимо от управления потерями. С другой стороны, все политики RL, такие как Q-обучение, используют единственную нейронную сеть для представления траектории управления и связанной награды, где траектория управления определяет управляющие сигналы, которые должны быть связаны с кубитами на разных тактах, а связанная награда оценивает насколько хорош такт квантового управления.
On-policy RL хорошо известна своей способностью использовать нелокальные особенности в траекториях управления, что становится критичным, когда ландшафт управления является многомерным и упакован с комбинаторно большим количеством неглобальных решений, как это часто характерно для квантовых систем.
Мы кодируем траекторию управления в трехслойную, полносвязную нейронную сеть – NN политику, и функцию потерь управления во вторую нейронную сеть – NN-значение, которая отражает дисконтированную будущую награду. Надежные решения для управления были получены с помощью агентов обучения с подкреплением, которые обучают обе нейронные сети в стохастической среде, имитирующей реалистичное управление шумом. Мы предлагаем решение для управления набором непрерывно параметризованных двухкубитовых квантовых вентилей, которые имеют особое значение в применении к квантовой химии, но являются слишком дорогостоящими для реализации с помощью стандартного универсального набора вентилей.
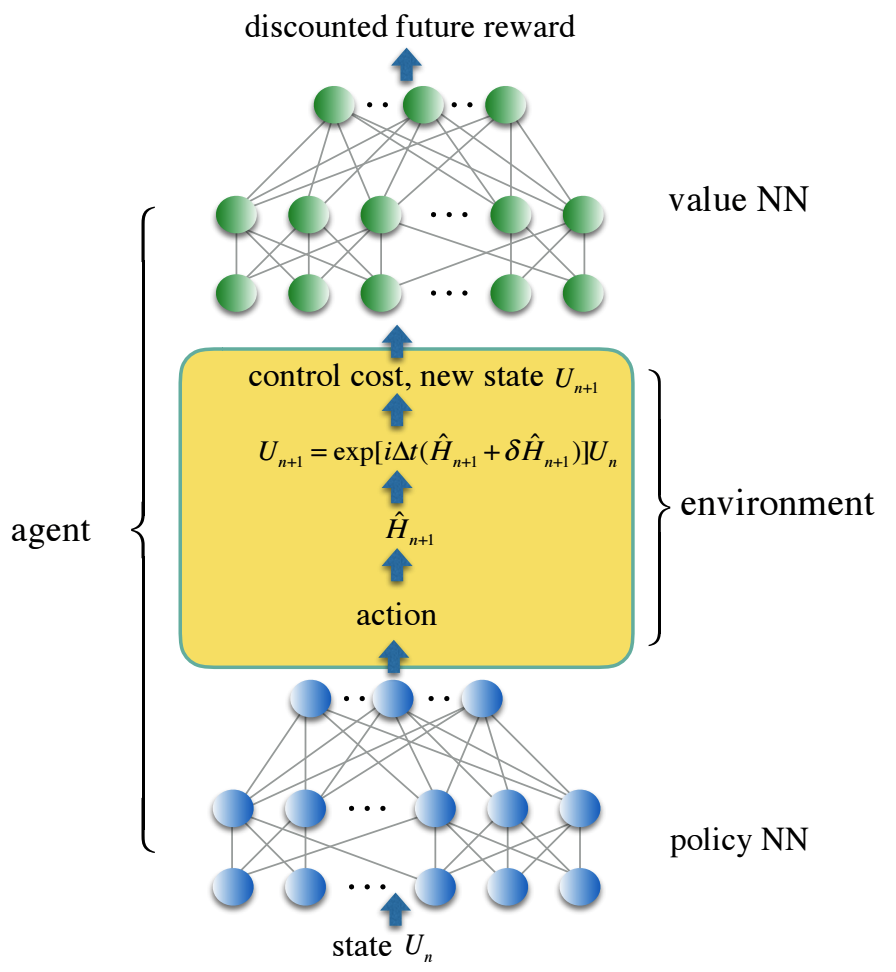
В рамках этой новой структуры наше численное моделирование показывает стократное уменьшение ошибок квантовых вентилей и сокращение времени вентилей для семейства непрерывно параметризованных имитационных квантовых вентилей в среднем на один порядок по сравнению с традиционными подходами с использованием универсального набора вентилей.
Эта работа подчеркивает важность использования новых методов машинного обучения и последних квантовых алгоритмов, которые используют гибкость и дополнительную вычислительную мощность универсальной квантовой схемы управления. Для полноценной интеграции машинного обучения и повышения вычислительных возможностей необходимо провести дополнительные эксперименты, подобные тому, что был приведен в этой работе.

Одна из самых главных проблем в реализации нового поколения квантовых компьютеров заключается в их самой базовой конситуэнте: кубите. Кубиты могут взаимодействовать с любыми объектами в непосредственной близости, которые переносят энергию близко к их собственным блуждающим фотонам (т.е. нежелательные электромагнитные поля, фононы (механические колебания квантового устройства) или квантовые дефекты (неровности на поверхности чипа, появившиеся на этапе производства), которые могут непредсказуемо менять состояние кубитов самостоятельно.
Дело осложняется множеством задач, которые ставят инструменты, используемые для контроля кубитов. Обработка и считывание кубитов производится классическими методами: аналоговые сигналы в виде электромагнитных полей вкупе с физической платой, в которую встроен кубит, например, сверхпроводящая микросхема. Несовершенства в управляющей электронике (приводящие к возникновению белого шума), помехи от внешних источников излучения и флуктуации в цифроаналоговых преобразователях приводят к еще большим стохастическим ошибкам, ухудшающим работу квантовых микросхем. Эти практические вопросы влияют на точность вычислений и, таким образом, ограничивают применение грядущего поколения квантовых устройств.
Чтобы повысить вычислительную мощность квантовых компьютеров и открыть путь к масштабным квантовым вычислениям, необходимо сначала построить физические модели, которые точно описывают эти экспериментальные задачи.
В статье “Universal Quantum Control through Deep Reinforcement Learning”, опубликованной в Nature Partner Journal (npj) Quantum Information (https://www.nature.com/npjqi/articles), мы представили новую структуру квантового управления, созданную с использованием глубокого обучения с подкреплением, в которой практические проблемы оптимизации квантового управления можно инкапсулировать одной функцией потерь. Рассмотренная структура обеспечивает снижение средней ошибки квантового вентиля до двух порядков по сравнению со стандартными стохастическими решениями градиентного спуска и значительное уменьшение времени вентиля (gate) до оптимальных значений аналогов синтеза вентиля. Наши результаты открывают новые горизонты квантового моделирования, квантовой химии и тестов квантового превосходства с использованием квантовых устройств ближайшего будущего.
Инновационность этой парадигмы квантового управления основывается на разработке квантовой функции управления и эффективного метода оптимизации, основанного на глубоком обучении с подкреплением. Чтобы разработать комплексную функцию потерь, для начала нужно разработать физическую модель реалистичного квантового процесса управления, в котором мы сможем точно предсказать величину ошибки. Одной из наиболее неприятных ошибок при оценке точности квантовых вычислений является утечка: количество квантовой информации, потерянной во время вычисления. Такая утечка обычно происходит, когда квантовой состояние кубита изменяется до более высокого энергетического уровня или до более низкого за счет спонтанного излучения. Из-за ошибки-утечки теряется не только полезная квантовая информация, она также ухудшает «квантовость» и в конечном итоге снижает производительность квантового компьютера до производительности компьютера с классической архитектурой.
Обычная практика для точной оценки потерянной информации во время квантового вычисления заключается в том, чтобы сначала смоделировать все вычисление целиком. Однако это сводит на нет весь смысл создания масштабных квантовых компьютеров, поскольку их преимущество заключается в том, что они способны выполнять вычисления невозможные для классических компьютеров. С улучшением физического моделирования наша общая функция потерь позволяет совместно оптимизировать накопленные ошибки утечки, нарушения граничных условий управления, общее время вентиля и точность вентиля.
С помощью новой функции управления потерями следующим шагом будет применение эффективного инструмента оптимизации для ее минимизации. Существующие методы оптимизации оказываются недостаточно хороши для поиска высокоточных решений, которые являются надежными для управления флуктуациями. Вместо этого мы применяем метод на основе on-policy метода глубокого обучения с подкреплением (RL), RL – доверенной области. Поскольку этот метод демонстрирует хорошую производительность на всех тестовых задачах, он по своей сути устойчив к шумам выборки и умеет оптимизировать сложные задачи управления с сотнями миллионов параметров управления. Существенным отличием этого on-policy RL метода от изученных ранее off-policy RL методов является то, что политика управления представляется независимо от управления потерями. С другой стороны, все политики RL, такие как Q-обучение, используют единственную нейронную сеть для представления траектории управления и связанной награды, где траектория управления определяет управляющие сигналы, которые должны быть связаны с кубитами на разных тактах, а связанная награда оценивает насколько хорош такт квантового управления.
On-policy RL хорошо известна своей способностью использовать нелокальные особенности в траекториях управления, что становится критичным, когда ландшафт управления является многомерным и упакован с комбинаторно большим количеством неглобальных решений, как это часто характерно для квантовых систем.
Мы кодируем траекторию управления в трехслойную, полносвязную нейронную сеть – NN политику, и функцию потерь управления во вторую нейронную сеть – NN-значение, которая отражает дисконтированную будущую награду. Надежные решения для управления были получены с помощью агентов обучения с подкреплением, которые обучают обе нейронные сети в стохастической среде, имитирующей реалистичное управление шумом. Мы предлагаем решение для управления набором непрерывно параметризованных двухкубитовых квантовых вентилей, которые имеют особое значение в применении к квантовой химии, но являются слишком дорогостоящими для реализации с помощью стандартного универсального набора вентилей.
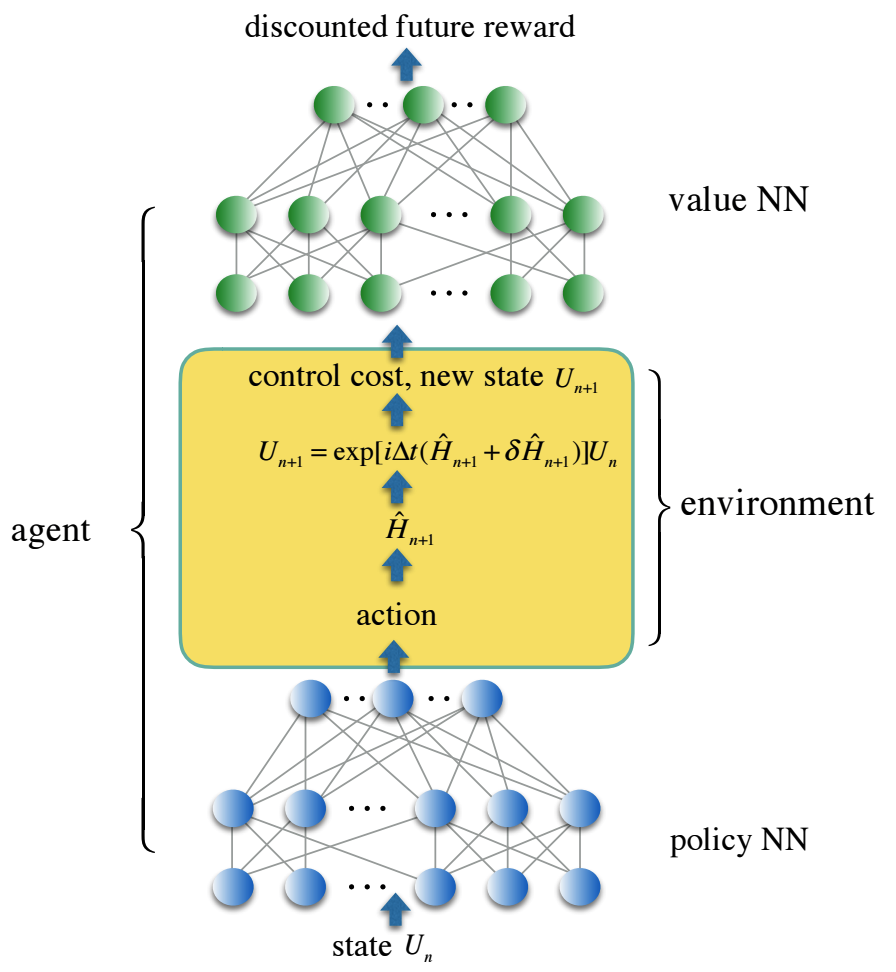
В рамках этой новой структуры наше численное моделирование показывает стократное уменьшение ошибок квантовых вентилей и сокращение времени вентилей для семейства непрерывно параметризованных имитационных квантовых вентилей в среднем на один порядок по сравнению с традиционными подходами с использованием универсального набора вентилей.
Эта работа подчеркивает важность использования новых методов машинного обучения и последних квантовых алгоритмов, которые используют гибкость и дополнительную вычислительную мощность универсальной квантовой схемы управления. Для полноценной интеграции машинного обучения и повышения вычислительных возможностей необходимо провести дополнительные эксперименты, подобные тому, что был приведен в этой работе.
