Всем привет! Мы подготовили перевод данной статьи в преддверии старта курса «Разработчик C++»

Повесть о двух, казалось бы, похожих, но все же разных инструментах
Херб — автор бестселлеров и консультант по вопросам разработки программного обеспечения, а также архитектор ПО в Microsoft. Вы можете связаться с ним на www.gotw.ca.
Что означает ключевое слово volatile? Как его следует использовать? К всеобщему замешательству, существует два распространенных ответа, потому что в зависимости от языка, на котором вы пишете код, volatile относится к одной из двух различных техник программирования: lock-free программированию (без блокировок) и работе со «необычной» памятью. (См. Рисунок 1.)
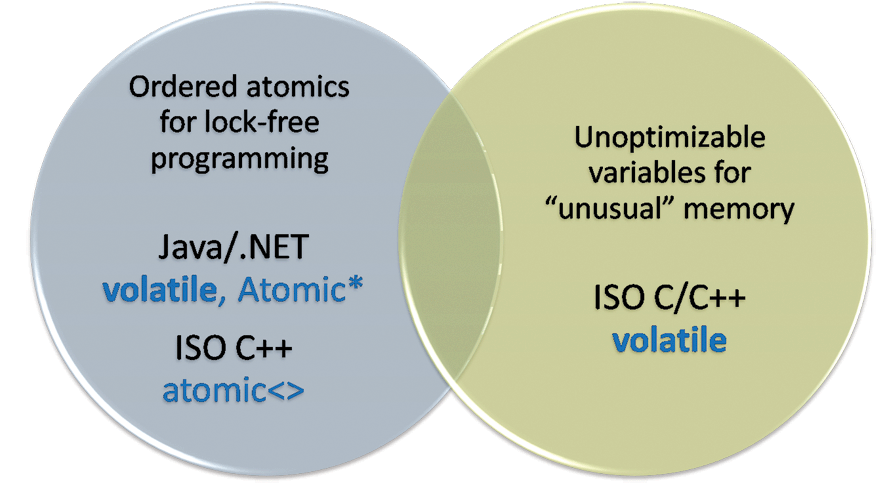
Рисунок 1: повесть о двух технических требованиях.
Усугубляет путаницу и то, что эти два различных случая использования имеют частично совпадающие предпосылки и накладываемые ограничения, что заставляет их выглядеть более схожими, нежели они являются на самом деле. Давайте же четко определим и поймем их, и разберемся, как их правильно употреблять в C, C++, Java и C# — и всегда ли именно как volatile.
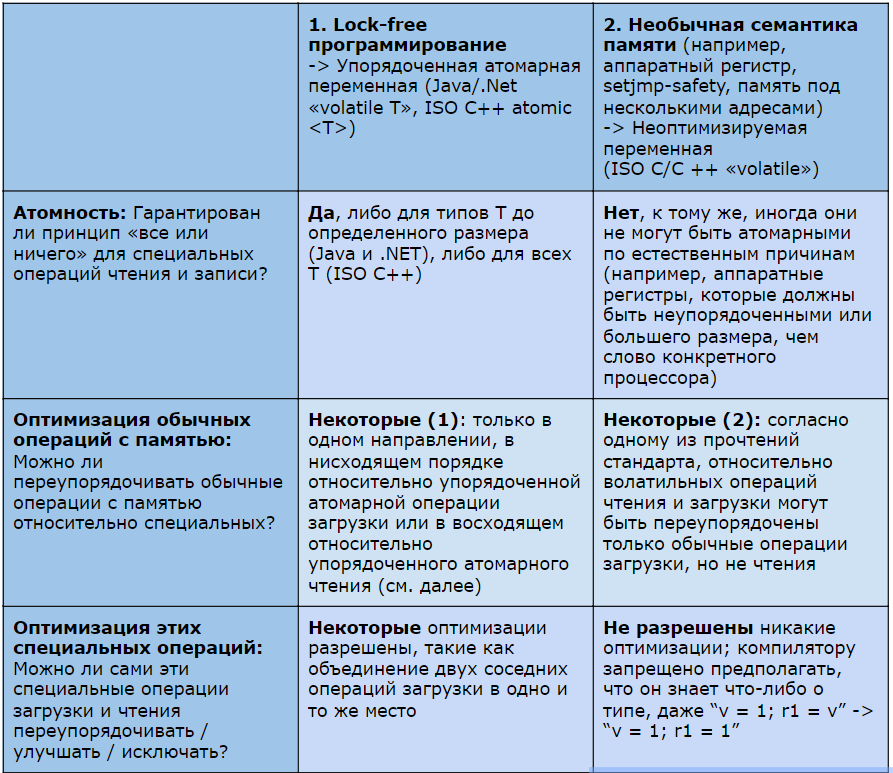
Таблица 1: Сравнение накладывающихся, но разных предпосылок.
Lock-free программирование связано с налаживанием коммуникации и синхронизации между потоками с помощью инструментов более низкого уровня, нежели взаимоисключающие блокировки. Как в прошлом, так и сегодня существует широкий спектр таких инструментов. В грубом историческом порядке они включают явные барьеры (explicit fences/barriers — например, mb() в Linux), специальные упорядочивающие вызовы API (например, InterlockedExchange в Windows) и различные разновидности специальных атомарных типов. Многие из этих инструментов муторны и/или сложны, и их широкое разнообразие означает, что в конечном итоге lock-free код пишется в разных средах по-разному.
Однако в последние несколько лет наблюдается значительная конвергенция между поставщиками аппаратного и программного обеспечения: вычислительная индустрия объединяется вокруг последовательно согласованных упорядоченных атомарных переменных (ordered atomic variables) в качестве стандарта или единственного способа написания lock-free кода с использованием основных языков и платформ ОС. В двух словах, упорядоченные атомарные переменные безопасны для чтения и записи в нескольких потоках одновременно без каких-либо явных блокировок, поскольку они обеспечивают две гарантии: их чтение и запись гарантированно будут выполняться в том порядке, в котором они появляются в исходном коде вашей программы; и каждое чтение или запись гарантированно будут атомарными, “все или ничего”. У них также есть специальные операции, такие как compareAndSet, которые гарантированно выполняются атомарно. См. [1] для получения дополнительной информации об упорядоченных атомарных переменных и о том, как их правильно использовать.
Упорядоченные атомарные переменные доступны в Java, C# и других языках .NET, а также в готовящемся стандарте ISO C++, но под другими именами:
Мы рассмотрим, как упорядоченные атомарные переменные ограничивают оптимизацию, которую могут выполнять компиляторы, процессоры, эффекты кэширования и другие элементы вашей среды выполнения. Итак, давайте сначала кратко рассмотрим некоторые основные правила оптимизации.
Фундаментальное правило оптимизации практически во всех языках таково: оптимизации, которые переупорядочивают («трансформируют») выполнение вашего кода, всегда являются легитимными, только если они не меняют смысла программы, так что программа не может определить разницу между выполнением исходного кода и преобразованного. В некоторых языках это также известно как правило «as-if», которое получает свое название из-за того факта, что преобразованный код имеет те же наблюдаемые эффекты, «как если бы» (as if) исходный исходный код был выполнен в том виде, в котором он был изначально написан.
Это правило имеет двоякий эффект: во-первых, оптимизация никогда не должна позволять получить результат, который раньше был невозможен, или нарушать любые гарантии, на которые исходному коду было разрешено полагаться, включая семантику языка. Если мы дадим невозможный результат, в конце концов, программа и пользователь, безусловно, смогут заметить разницу, и это уже не «как если бы» мы выполнили исходный не преобразованный код.
Во-вторых, оптимизации позволено сократить набор возможных исполнений. Например, оптимизация может привести к тому, что некоторые потенциальные (но не гарантированные) чередования (изменение порядка выполнения инструкций — интерливинг) никогда не произойдут. Это нормально, потому что программа все равно не может рассчитывать на то, что они произойдут.
Использование упорядоченных атомарных переменных ограничивает виды оптимизации, которые может выполнять ваш компилятор, процессор и система кэширования. [3] Стоит отметить два вида оптимизаций:
Во-первых, все упорядоченные атомарные операции чтения и записи в заданном потоке должны выполняться строго в порядке исходного кода, потому что это одна из фундаментальных гарантий упорядоченных атомарных переменных. Тем не менее, мы все еще можем выполнить некоторые оптимизации, в частности, оптимизации, которые имеют такой же эффект, как если бы этот поток просто всегда выполнялся так быстро, что в некоторых точках не возникало бы чередования с другим потоком.
Например, рассмотрим этот код, где a — упорядоченная атомарная переменная:
Допустимо ли для компилятора, процессора, кэша или другой части среды выполнения преобразовывать приведенный выше код в следующий, исключая избыточную запись в строке A?
Ответ: «Да». Это легитимно, потому что программа не может определить разницу; это “как если бы” этот поток всегда работал так быстро, что никакой другой поток, работающий параллельно, в принципе не может чередоваться между строками A и B, чтобы увидеть промежуточное значение. [4]
Аналогично, если a — упорядоченная атомарная переменная, а local — неразделяемая локальная переменная, допустимо преобразовать
в
что исключает чтение из a. Даже если другой поток одновременно пытается выполнить запись в a, это “как если бы” этот поток всегда работал так быстро, что другому потоку никогда не удавалось чередовать строки C и D, чтобы изменить значение, прежде чем мы успеем записать наше собственное обратно в local.
Во-вторых, близлежащие обычные операции чтения и записи все еще могут быть переупорядочены вокруг упорядоченных атомарных, но с некоторыми ограничениями. В частности, как описано в [3], обычные операции чтения и записи не могут перемещаться вверх по отношению к упорядоченному атомарному чтению (от “после” к “до”) и не могут перемещаться вниз по отношению к упорядоченной атомарной записи (от “до” к “после”). Короче говоря, это может вывести их из критического раздела кода, и вы сможете писать программы, которые выиграют от этого в производительности. Для получения более подробной информации см. [3].
На этом все касательно lock-free программирования и упорядоченных атомарных переменных. А как насчет другого случая, в котором рассматриваются какие-то «волатильные» адреса?
Переменные в таких местах памяти являются неоптимизируемыми переменными, потому что компилятор не может безопасно делать какие-либо предположения о них вообще. Иными словами, компилятору нужно сказать, что такая переменная не участвует в обычной системе типов, даже если она имеет конкретный тип. Например, если ячейка памяти M или A1/A2 в вышеупомянутых примерах в программе объявлена как «int», то что это в действительности означает? Самое большее, что это может означать, это то, что она имеет размер и расположение int, но это не может означать, что он ведет себя как int — в конце концов, int не автоинкрементируют себя, когда вы записываете в него, или таинственным образом не изменяет свое значение, когда вы совершите запись во что-то похожее на другую переменную по другому адресу.
Нам нужен способ отключить все оптимизации для их чтения и записи. ISO C и C++ имеют портативный, стандартный способ сообщить компилятору, что это такая специальная переменная, которую он не должен оптимизировать: volatile.
Java и .NET не имеют сопоставимой концепции. В конце концов, управляемые среды должны знать полную семантику программы, которую они выполняют, поэтому неудивительно, что они не поддерживают память с «непознаваемой» семантикой. Но и Java, и .NET предоставляют аварийные шлюзы для выхода из управляемой среды и вызова нативного кода: Java предоставляет Java Native Interface (JNI), а .NET предоставляет Platform Invoke (P/Invoke). Однако в спецификации JNI [5] о volatile ничего не говорится и вообще не упоминается ни Java volatile, ни C/C++ volatile; аналогично, в документации P/Invoke не упоминается взаимодействие с .NET volatile или C/C++ volatile. Таким образом, для правильного доступа к неоптимизируемой области памяти в Java или .NET вы должны написать функции C/C++, которые используют C/C++ volatile для выполнения необходимой работы от имени вызывающего их уравляющего кода, чтобы они полностью инкапсулировали и скрывали volatile память (т. е. не принимали и не возвращали ничего volatile) и вызывать эти функции через JNI и P/Invoke.
Все операции чтения и записи неоптимизируемых переменных в заданном потоке должны выполняться точно так, как написаны; никакие оптимизации не допускаются вообще, потому что компилятор не может знать полную семантику переменной и когда и как ее значение может измениться. Это более строгие выражения (по сравнению с упорядоченными атомарными переменными), которую нужно выполнять только в порядке исходного кода.
Рассмотрим снова два преобразования, которые мы рассматривали ранее, но на этот раз заменим упорядоченную атомарную переменную a на неоптимизируемую (C/C++ volatile) переменную v:
Легитимно ли это преобразовать следующим образом, чтобы удалить явно лишнюю запись в строке A?
Ответ — нет, потому что компилятор не может знать, что исключение записи строки A в v не изменит смысла программы. Например, v может быть местоположением, к которому обращается пользовательское оборудование, которое ожидает увидеть значение 1 перед значением 2 и иначе не будет работать правильно.
Аналогично, если v неоптимизируемая переменная, а local — неразделяемая локальная переменная, преобразование недопустимо
в
для упразднения чтение из v. Например, v может быть аппаратным адресом, который автоматически увеличивается каждый раз при записи, так что запись 1 даст значение 2 при следующем считывании.
Во-вторых, что насчет соседних обычных операций чтения и записи — можно ли их переупорядочить вокруг неоптимизируемых? Сегодня нет практического портативного ответа, потому что реализации компилятора C/C++ сильно различаются и вряд ли в скором времени начнут движение к единообразию. Например, одна интерпретация Стандарта C++ гласит, что обычные операции чтения могут свободно перемещаться в любом направлении относительно чтения или записи volatile C/C++, а вот обычная запись вообще не может перемещаться относительно чтения или записи volatile C/C++ — что делает volatile C/C++ в то же время и менее и более ограничительным, чем упорядоченные атомарные операции. Некоторые поставщики компиляторов поддерживают эту интерпретацию; другие вообще не оптимизируют чтение или запись volatile; а третьи имеют свою собственную семантику.
Для написания безопасного lock-free кода, который коммуницирует между потоками без использования блокировок, предпочитайте использовать упорядоченные атомарные переменные: Java/.NET volatile, C++0x atomic
Чтобы безопасно обмениваться данными со специальным оборудованием или другой памятью с необычной семантикой, используйте неоптимизируемые переменные: ISO C/C++ volatile. Помните, что чтение и запись этих переменных не обязательно должны быть атомарными.
И наконец, чтобы объявить переменную, которая имеет необычную семантику и обладает какой-либо из или же сразу всеми гарантиями атомарности и/или упорядочения, необходимыми для написания lock-free кода, только черновик стандарта ISO C++0x предоставляет прямой способ ее реализации: volatile atomic
Бесплатный вебинар: «Hello, World!» на фарси или как использовать Unicode в C++"

Повесть о двух, казалось бы, похожих, но все же разных инструментах
Херб — автор бестселлеров и консультант по вопросам разработки программного обеспечения, а также архитектор ПО в Microsoft. Вы можете связаться с ним на www.gotw.ca.
Что означает ключевое слово volatile? Как его следует использовать? К всеобщему замешательству, существует два распространенных ответа, потому что в зависимости от языка, на котором вы пишете код, volatile относится к одной из двух различных техник программирования: lock-free программированию (без блокировок) и работе со «необычной» памятью. (См. Рисунок 1.)
Рисунок 1: повесть о двух технических требованиях.
Усугубляет путаницу и то, что эти два различных случая использования имеют частично совпадающие предпосылки и накладываемые ограничения, что заставляет их выглядеть более схожими, нежели они являются на самом деле. Давайте же четко определим и поймем их, и разберемся, как их правильно употреблять в C, C++, Java и C# — и всегда ли именно как volatile.
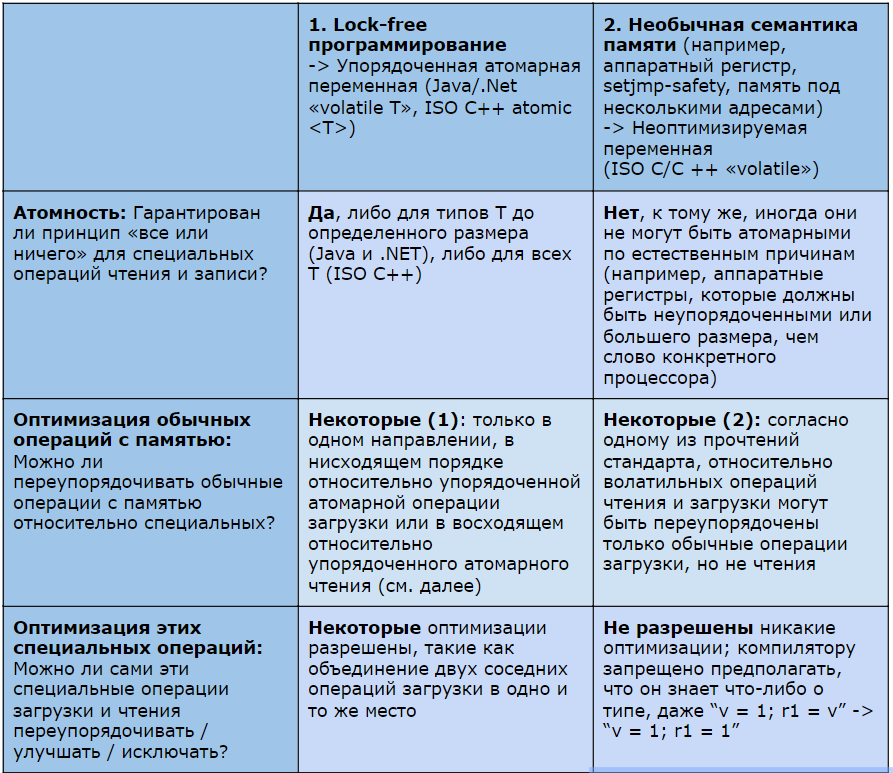
Таблица 1: Сравнение накладывающихся, но разных предпосылок.
Случай 1: Упорядоченные атомарные переменные для lock-free программирования
Lock-free программирование связано с налаживанием коммуникации и синхронизации между потоками с помощью инструментов более низкого уровня, нежели взаимоисключающие блокировки. Как в прошлом, так и сегодня существует широкий спектр таких инструментов. В грубом историческом порядке они включают явные барьеры (explicit fences/barriers — например, mb() в Linux), специальные упорядочивающие вызовы API (например, InterlockedExchange в Windows) и различные разновидности специальных атомарных типов. Многие из этих инструментов муторны и/или сложны, и их широкое разнообразие означает, что в конечном итоге lock-free код пишется в разных средах по-разному.
Однако в последние несколько лет наблюдается значительная конвергенция между поставщиками аппаратного и программного обеспечения: вычислительная индустрия объединяется вокруг последовательно согласованных упорядоченных атомарных переменных (ordered atomic variables) в качестве стандарта или единственного способа написания lock-free кода с использованием основных языков и платформ ОС. В двух словах, упорядоченные атомарные переменные безопасны для чтения и записи в нескольких потоках одновременно без каких-либо явных блокировок, поскольку они обеспечивают две гарантии: их чтение и запись гарантированно будут выполняться в том порядке, в котором они появляются в исходном коде вашей программы; и каждое чтение или запись гарантированно будут атомарными, “все или ничего”. У них также есть специальные операции, такие как compareAndSet, которые гарантированно выполняются атомарно. См. [1] для получения дополнительной информации об упорядоченных атомарных переменных и о том, как их правильно использовать.
Упорядоченные атомарные переменные доступны в Java, C# и других языках .NET, а также в готовящемся стандарте ISO C++, но под другими именами:
- Java предоставляет упорядоченные атомарные переменные под ключевым словом volatile (например, volatile int), полностью поддерживая это с Java 5 (2004). Java дополнительно предоставляет несколько именованных типов в java.util.concurrent.atomic, например, AtomicLongArray, который вы можете использовать для тех же целей.
- .NET добавил их в Visual Studio 2005, также под ключевым словом volatile (например, volatile int). Они подходят почти для любого варианта использования lock-free кода, за исключением редких примеров, подобных алгоритму Деккера. .NET исправляет оставшиеся ошибки в Visual Studio 2010, которая находится на стадии бета-тестирования на момент написания этой статьи.
- ISO C++ добавил их в черновик стандарта C++ 0x в 2007 году под шаблонным именем atomic
<T>(например, atomic). С 2008 года они стали доступны в Boost и некоторых других реализациях. [2]. Библиотека atomic ISO C++ также предоставляет C-совместимый способ написания этих типов и их операций (например, atomic_int), и они, вероятно, будут приняты ISO C в ближайшем будущем.
Пару слов об оптимизации
Мы рассмотрим, как упорядоченные атомарные переменные ограничивают оптимизацию, которую могут выполнять компиляторы, процессоры, эффекты кэширования и другие элементы вашей среды выполнения. Итак, давайте сначала кратко рассмотрим некоторые основные правила оптимизации.
Фундаментальное правило оптимизации практически во всех языках таково: оптимизации, которые переупорядочивают («трансформируют») выполнение вашего кода, всегда являются легитимными, только если они не меняют смысла программы, так что программа не может определить разницу между выполнением исходного кода и преобразованного. В некоторых языках это также известно как правило «as-if», которое получает свое название из-за того факта, что преобразованный код имеет те же наблюдаемые эффекты, «как если бы» (as if) исходный исходный код был выполнен в том виде, в котором он был изначально написан.
Это правило имеет двоякий эффект: во-первых, оптимизация никогда не должна позволять получить результат, который раньше был невозможен, или нарушать любые гарантии, на которые исходному коду было разрешено полагаться, включая семантику языка. Если мы дадим невозможный результат, в конце концов, программа и пользователь, безусловно, смогут заметить разницу, и это уже не «как если бы» мы выполнили исходный не преобразованный код.
Во-вторых, оптимизации позволено сократить набор возможных исполнений. Например, оптимизация может привести к тому, что некоторые потенциальные (но не гарантированные) чередования (изменение порядка выполнения инструкций — интерливинг) никогда не произойдут. Это нормально, потому что программа все равно не может рассчитывать на то, что они произойдут.
Упорядоченные атомарные переменные и оптимизация
Использование упорядоченных атомарных переменных ограничивает виды оптимизации, которые может выполнять ваш компилятор, процессор и система кэширования. [3] Стоит отметить два вида оптимизаций:
- Оптимизации упорядоченных атомарных операций чтения и записи.
- Оптимизации соседних обычных операций чтения и записи.
Во-первых, все упорядоченные атомарные операции чтения и записи в заданном потоке должны выполняться строго в порядке исходного кода, потому что это одна из фундаментальных гарантий упорядоченных атомарных переменных. Тем не менее, мы все еще можем выполнить некоторые оптимизации, в частности, оптимизации, которые имеют такой же эффект, как если бы этот поток просто всегда выполнялся так быстро, что в некоторых точках не возникало бы чередования с другим потоком.
Например, рассмотрим этот код, где a — упорядоченная атомарная переменная:
a = 1; // A
a = 2; // BДопустимо ли для компилятора, процессора, кэша или другой части среды выполнения преобразовывать приведенный выше код в следующий, исключая избыточную запись в строке A?
// A ': OK: полностью исключить строку A
a = 2; // B
Ответ: «Да». Это легитимно, потому что программа не может определить разницу; это “как если бы” этот поток всегда работал так быстро, что никакой другой поток, работающий параллельно, в принципе не может чередоваться между строками A и B, чтобы увидеть промежуточное значение. [4]
Аналогично, если a — упорядоченная атомарная переменная, а local — неразделяемая локальная переменная, допустимо преобразовать
a = 1; // C: запись в a
local = a; // D: чтение из aв
a = 1; // C: запись в a
local = 1; // D': OK, применить "подстановку константы"что исключает чтение из a. Даже если другой поток одновременно пытается выполнить запись в a, это “как если бы” этот поток всегда работал так быстро, что другому потоку никогда не удавалось чередовать строки C и D, чтобы изменить значение, прежде чем мы успеем записать наше собственное обратно в local.
Во-вторых, близлежащие обычные операции чтения и записи все еще могут быть переупорядочены вокруг упорядоченных атомарных, но с некоторыми ограничениями. В частности, как описано в [3], обычные операции чтения и записи не могут перемещаться вверх по отношению к упорядоченному атомарному чтению (от “после” к “до”) и не могут перемещаться вниз по отношению к упорядоченной атомарной записи (от “до” к “после”). Короче говоря, это может вывести их из критического раздела кода, и вы сможете писать программы, которые выиграют от этого в производительности. Для получения более подробной информации см. [3].
На этом все касательно lock-free программирования и упорядоченных атомарных переменных. А как насчет другого случая, в котором рассматриваются какие-то «волатильные» адреса?
Случай 2: Свободные от семантики переменные для памяти с «необычной» семантикой
- Вторая необходимость — работать с «необычной» памятью, которая выходит за рамки модели памяти данного языка, где компилятор должен предполагать, что переменная может изменить значение в любое время и/или что чтение и запись могут иметь непознаваемую семантику и следствия. Классические примеры:
- Аппаратные регистры, часть 1: Асинхронные изменения. Например, рассмотрим ячейку памяти М на пользовательской плате, которая подключена к прибору, который производит запись непосредственно в M. В отличие от обычной памяти, которая изменяется только самой программой, значение, хранящееся в M, может измениться в любое время, даже если ни один программный поток не пишет в нее; следовательно, компилятор не может делать никаких предположений о том, что значение будет стабильным.
- Аппаратные регистры, часть 2: Семантика. Например, рассмотрим область памяти M на пользовательской плате, где запись в эту позицию всегда автоматически увеличивается на единицу. В отличие от обычного места в RAM памяти, компилятор даже не может предположить, что выполнение записи в M и последующее сразу после нее чтение из M обязательно прочитает то же значение, которое было записано.
- Память, имеющая более одного адреса. Если данная ячейка памяти доступна с использованием двух разных адресов А1 и А2, компилятор или процессор может не знать, что запись в ячейку А1 может изменить значение в ячейке А2. Любая оптимизация, предполагающая? что запись в A1, не изменяет значение A2, будет ломать программу, и должна быть предотвращена.
Переменные в таких местах памяти являются неоптимизируемыми переменными, потому что компилятор не может безопасно делать какие-либо предположения о них вообще. Иными словами, компилятору нужно сказать, что такая переменная не участвует в обычной системе типов, даже если она имеет конкретный тип. Например, если ячейка памяти M или A1/A2 в вышеупомянутых примерах в программе объявлена как «int», то что это в действительности означает? Самое большее, что это может означать, это то, что она имеет размер и расположение int, но это не может означать, что он ведет себя как int — в конце концов, int не автоинкрементируют себя, когда вы записываете в него, или таинственным образом не изменяет свое значение, когда вы совершите запись во что-то похожее на другую переменную по другому адресу.
Нам нужен способ отключить все оптимизации для их чтения и записи. ISO C и C++ имеют портативный, стандартный способ сообщить компилятору, что это такая специальная переменная, которую он не должен оптимизировать: volatile.
Java и .NET не имеют сопоставимой концепции. В конце концов, управляемые среды должны знать полную семантику программы, которую они выполняют, поэтому неудивительно, что они не поддерживают память с «непознаваемой» семантикой. Но и Java, и .NET предоставляют аварийные шлюзы для выхода из управляемой среды и вызова нативного кода: Java предоставляет Java Native Interface (JNI), а .NET предоставляет Platform Invoke (P/Invoke). Однако в спецификации JNI [5] о volatile ничего не говорится и вообще не упоминается ни Java volatile, ни C/C++ volatile; аналогично, в документации P/Invoke не упоминается взаимодействие с .NET volatile или C/C++ volatile. Таким образом, для правильного доступа к неоптимизируемой области памяти в Java или .NET вы должны написать функции C/C++, которые используют C/C++ volatile для выполнения необходимой работы от имени вызывающего их уравляющего кода, чтобы они полностью инкапсулировали и скрывали volatile память (т. е. не принимали и не возвращали ничего volatile) и вызывать эти функции через JNI и P/Invoke.
Неоптимизируемые переменные и (не) оптимизация
Все операции чтения и записи неоптимизируемых переменных в заданном потоке должны выполняться точно так, как написаны; никакие оптимизации не допускаются вообще, потому что компилятор не может знать полную семантику переменной и когда и как ее значение может измениться. Это более строгие выражения (по сравнению с упорядоченными атомарными переменными), которую нужно выполнять только в порядке исходного кода.
Рассмотрим снова два преобразования, которые мы рассматривали ранее, но на этот раз заменим упорядоченную атомарную переменную a на неоптимизируемую (C/C++ volatile) переменную v:
v = 1; // A
v = 2; // BЛегитимно ли это преобразовать следующим образом, чтобы удалить явно лишнюю запись в строке A?
// A ': невалидно, нельзя исключить запись
v = 2; // B
Ответ — нет, потому что компилятор не может знать, что исключение записи строки A в v не изменит смысла программы. Например, v может быть местоположением, к которому обращается пользовательское оборудование, которое ожидает увидеть значение 1 перед значением 2 и иначе не будет работать правильно.
Аналогично, если v неоптимизируемая переменная, а local — неразделяемая локальная переменная, преобразование недопустимо
v = 1; // C: запись в v
local = v; // C: чтение из vв
a = 1; // C: запись в v
local = l; // D': невалидно, нельзя совершить
// "подстановку константы"для упразднения чтение из v. Например, v может быть аппаратным адресом, который автоматически увеличивается каждый раз при записи, так что запись 1 даст значение 2 при следующем считывании.
Во-вторых, что насчет соседних обычных операций чтения и записи — можно ли их переупорядочить вокруг неоптимизируемых? Сегодня нет практического портативного ответа, потому что реализации компилятора C/C++ сильно различаются и вряд ли в скором времени начнут движение к единообразию. Например, одна интерпретация Стандарта C++ гласит, что обычные операции чтения могут свободно перемещаться в любом направлении относительно чтения или записи volatile C/C++, а вот обычная запись вообще не может перемещаться относительно чтения или записи volatile C/C++ — что делает volatile C/C++ в то же время и менее и более ограничительным, чем упорядоченные атомарные операции. Некоторые поставщики компиляторов поддерживают эту интерпретацию; другие вообще не оптимизируют чтение или запись volatile; а третьи имеют свою собственную семантику.
Резюме
Для написания безопасного lock-free кода, который коммуницирует между потоками без использования блокировок, предпочитайте использовать упорядоченные атомарные переменные: Java/.NET volatile, C++0x atomic
<T>и C-совместимый atomic_T.Чтобы безопасно обмениваться данными со специальным оборудованием или другой памятью с необычной семантикой, используйте неоптимизируемые переменные: ISO C/C++ volatile. Помните, что чтение и запись этих переменных не обязательно должны быть атомарными.
И наконец, чтобы объявить переменную, которая имеет необычную семантику и обладает какой-либо из или же сразу всеми гарантиями атомарности и/или упорядочения, необходимыми для написания lock-free кода, только черновик стандарта ISO C++0x предоставляет прямой способ ее реализации: volatile atomic
<T>.
Примечания
- Г. Саттер. «Writing Lock-Free Code: A Corrected Queue» (DDJ, октябрь 2008 г.). Доступно online тут.
- [2] См. www.boost.org.
- [3] Г. Саттер. «Apply Critical Sections Consistently» (DDJ, ноябрь 2007 г.). Доступно в Интернете тут.
- [4] Существует распространенное возражение: «В исходном коде другой поток мог видеть промежуточное значение, но это невозможно в преобразованном коде. Разве это не изменение наблюдаемого поведения?» ответ: «Нет», потому что программе никогда не гарантировалось, что она будет фактически чередоваться как раз вовремя, чтобы увидеть это значение; для этого потока уже был легитимный результат — он всегда работал так быстро, что чередование никогда не случалось. Опять же, то, что следует из этой оптимизации, так это уменьшает набор возможных исполнений, что всегда является легитимным.
- [5] С. Лянг. Java Native Interface: Руководство программиста и спецификация. (Прентис Холл, 1999). Доступно online тут.
Бесплатный вебинар: «Hello, World!» на фарси или как использовать Unicode в C++"
