Всем привет. Подготовили перевод интересной статьи в преддверии старта базового курса «Разработчик Python».

Асинхронное программирование – это вид параллельного программирования, в котором какая-либо единица работы может выполняться отдельно от основного потока выполнения приложения. Когда работа завершается, основной поток получает уведомление о завершении рабочего потока или произошедшей ошибке. У такого подхода есть множество преимуществ, таких как повышение производительности приложений и повышение скорости отклика.
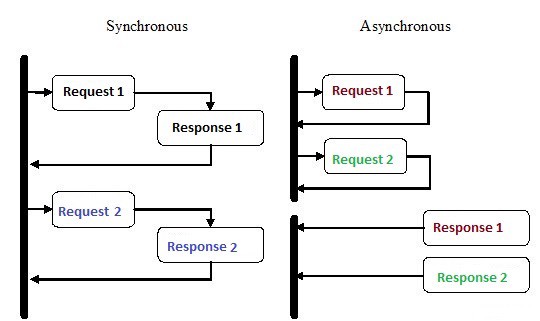
В последние несколько лет асинхронное программирование привлекло к себе пристальное внимание, и на то есть причины. Несмотря на то, что этот вид программирования может быть сложнее традиционного последовательного выполнения, он гораздо более эффективен.
Например, вместо того, что ждать завершения HTTP-запроса перед продолжением выполнения, вы можете отправить запрос и выполнить другую работу, которая ждет своей очереди, с помощью асинхронных корутин в Python.
Асинхронность – это одна из основных причин популярности выбора Node.js для реализации бэкенда. Большое количество кода, который мы пишем, особенно в приложениях с тяжелым вводом-выводом, таком как на веб-сайтах, зависит от внешних ресурсов. В нем может оказаться все, что угодно, от удаленного вызова базы данных до POST-запросов в REST-сервис. Как только вы отправите запрос в один из этих ресурсов, ваш код будет просто ожидать ответа. С асинхронным программированием вы позволяете своему коду обрабатывать другие задачи, пока ждете ответа от ресурсов.

1. Множественные процессы
Самый очевидный способ – это использование нескольких процессов. Из терминала вы можете запустить свой скрипт два, три, четыре, десять раз, и все скрипты будут выполняться независимо и одновременно. Операционная система сама позаботится о распределении ресурсов процессора между всеми экземплярами. В качестве альтернативы вы можете воспользоваться библиотекой multiprocessing, которая умеет порождать несколько процессов, как показано в примере ниже.
Вывод:
2. Множественные потоки
Еще один способ запустить несколько работ параллельно – это использовать потоки. Поток – это очередь выполнения, которая очень похожа на процесс, однако в одном процессе вы можете иметь несколько потоков, и у всех них будет общий доступ к ресурсам. Однако из-за этого написать код потока будет сложно. Аналогично, все тяжелую работу по выделению памяти процессора сделает операционная система, но глобальная блокировка интерпретатора (GIL) позволит только одному потоку Python запускаться в одну единицу времени, даже если у вас есть многопоточный код. Так GIL на CPython предотвращает многоядерную конкурентность. То есть вы насильно можете запуститься только на одном ядре, даже если у вас их два, четыре или больше.
Вывод:
3. Корутины и
Корутины – это обобщение подпрограмм. Они используются для кооперативной многозадачности, когда процесс добровольно отдает контроль (
Вывод:
4. Асинхронное программирование
Четвертый способ – это асинхронное программирование, в котором не участвует операционная система. Со стороны операционной системы у вас останется один процесс, в котором будет всего один поток, но вы все еще сможете выполнять одновременно несколько задач. Так в чем тут фокус?
Ответ:
С помощью
Переключение контекста в
В следующем примере, мы запускаем 3 асинхронных таска, которые по-отдельности делают запросы к Reddit, извлекают и выводят содержимое JSON. Мы используем aiohttp – клиентскую библиотеку http, которая гарантирует, что даже HTTP-запрос будет выполнен асинхронно.
Вывод:
Использование
В примере ниже мы добавили в очередь простую функцию
Вывод:
В качестве примера возьмем шахматную выставку, где один из лучших шахматистов соревнуется с большим количеством людей. У нас есть 24 игры и 24 человека, с которыми можно сыграть, и, если шахматист будет играть с ними синхронно, это займет не менее 12 часов (при условии, что средняя игра занимает 30 ходов, шахматист продумывает ход в течение 5 секунд, а противник – примерно 55 секунд.) Однако в асинхронном режиме шахматист сможет делать ход и оставлять противнику время на раздумья, тем временем переходя к следующему противнику и деля ход. Таким образом, сделать ход во всех 24 играх можно за 2 минуты, и выиграны они все могут быть всего за один час.
Это и подразумевается, когда говорят о том, что асинхронность ускоряет работу. О такой быстроте идет речь. Хороший шахматист не начинает играть в шахматы быстрее, просто время более оптимизировано, и оно не тратится впустую на ожидание. Так это работает.
По этой аналогии шахматист будет процессором, а основная идея будет заключаться в том, чтобы процессор простаивал как можно меньше времени. Речь о том, чтобы у него всегда было занятие.
На практике асинхронность определяется как стиль параллельного программирования, в котором одни задачи освобождают процессор в периоды ожидания, чтобы другие задачи могли им воспользоваться. В Python есть несколько способов достижения параллелизма, отвечающих вашим требованиям, потоку кода, обработке данных, архитектуре и вариантам использования, и вы можете выбрать любой из них.
Узнать о курсе подробнее.

Введение
Асинхронное программирование – это вид параллельного программирования, в котором какая-либо единица работы может выполняться отдельно от основного потока выполнения приложения. Когда работа завершается, основной поток получает уведомление о завершении рабочего потока или произошедшей ошибке. У такого подхода есть множество преимуществ, таких как повышение производительности приложений и повышение скорости отклика.
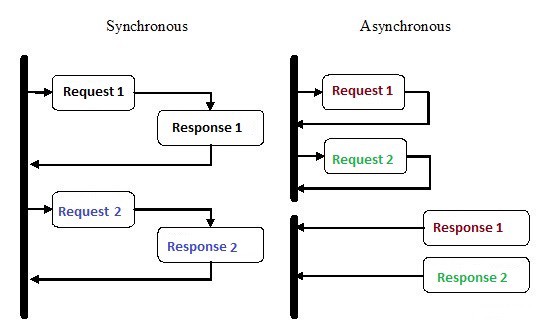
В последние несколько лет асинхронное программирование привлекло к себе пристальное внимание, и на то есть причины. Несмотря на то, что этот вид программирования может быть сложнее традиционного последовательного выполнения, он гораздо более эффективен.
Например, вместо того, что ждать завершения HTTP-запроса перед продолжением выполнения, вы можете отправить запрос и выполнить другую работу, которая ждет своей очереди, с помощью асинхронных корутин в Python.
Асинхронность – это одна из основных причин популярности выбора Node.js для реализации бэкенда. Большое количество кода, который мы пишем, особенно в приложениях с тяжелым вводом-выводом, таком как на веб-сайтах, зависит от внешних ресурсов. В нем может оказаться все, что угодно, от удаленного вызова базы данных до POST-запросов в REST-сервис. Как только вы отправите запрос в один из этих ресурсов, ваш код будет просто ожидать ответа. С асинхронным программированием вы позволяете своему коду обрабатывать другие задачи, пока ждете ответа от ресурсов.
Как Python умудряется делать несколько вещей одновременно?

1. Множественные процессы
Самый очевидный способ – это использование нескольких процессов. Из терминала вы можете запустить свой скрипт два, три, четыре, десять раз, и все скрипты будут выполняться независимо и одновременно. Операционная система сама позаботится о распределении ресурсов процессора между всеми экземплярами. В качестве альтернативы вы можете воспользоваться библиотекой multiprocessing, которая умеет порождать несколько процессов, как показано в примере ниже.
from multiprocessing import Process
def print_func(continent='Asia'):
print('The name of continent is : ', continent)
if __name__ == "__main__": # confirms that the code is under main function
names = ['America', 'Europe', 'Africa']
procs = []
proc = Process(target=print_func) # instantiating without any argument
procs.append(proc)
proc.start()
# instantiating process with arguments
for name in names:
# print(name)
proc = Process(target=print_func, args=(name,))
procs.append(proc)
proc.start()
# complete the processes
for proc in procs:
proc.join()Вывод:
The name of continent is : Asia
The name of continent is : America
The name of continent is : Europe
The name of continent is : Africa2. Множественные потоки
Еще один способ запустить несколько работ параллельно – это использовать потоки. Поток – это очередь выполнения, которая очень похожа на процесс, однако в одном процессе вы можете иметь несколько потоков, и у всех них будет общий доступ к ресурсам. Однако из-за этого написать код потока будет сложно. Аналогично, все тяжелую работу по выделению памяти процессора сделает операционная система, но глобальная блокировка интерпретатора (GIL) позволит только одному потоку Python запускаться в одну единицу времени, даже если у вас есть многопоточный код. Так GIL на CPython предотвращает многоядерную конкурентность. То есть вы насильно можете запуститься только на одном ядре, даже если у вас их два, четыре или больше.
import threading
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating thread
t1 = threading.Thread(target=print_square, args=(10,))
t2 = threading.Thread(target=print_cube, args=(10,))
# starting thread 1
t1.start()
# starting thread 2
t2.start()
# wait until thread 1 is completely executed
t1.join()
# wait until thread 2 is completely executed
t2.join()
# both threads completely executed
print("Done!")Вывод:
Square: 100
Cube: 1000
Done!3. Корутины и
yield:Корутины – это обобщение подпрограмм. Они используются для кооперативной многозадачности, когда процесс добровольно отдает контроль (
yield) с какой-то периодичностью или в периоды ожидания, чтобы позволить нескольким приложениям работать одновременно. Корутины похожи на генераторы, но с дополнительными методами и небольшими изменениями в том, как мы используем оператор yield. Генераторы производят данные для итерации, в то время как корутины могут еще и потреблять данные.def print_name(prefix):
print("Searching prefix:{}".format(prefix))
try :
while True:
# yeild used to create coroutine
name = (yield)
if prefix in name:
print(name)
except GeneratorExit:
print("Closing coroutine!!")
corou = print_name("Dear")
corou.__next__()
corou.send("James")
corou.send("Dear James")
corou.close()Вывод:
Searching prefix:Dear
Dear James
Closing coroutine!!4. Асинхронное программирование
Четвертый способ – это асинхронное программирование, в котором не участвует операционная система. Со стороны операционной системы у вас останется один процесс, в котором будет всего один поток, но вы все еще сможете выполнять одновременно несколько задач. Так в чем тут фокус?
Ответ:
asyncioAsyncio – модуль асинхронного программирования, который был представлен в Python 3.4. Он предназначен для использования корутин и future для упрощения написания асинхронного кода и делает его почти таким же читаемым, как синхронный код, из-за отсутствия callback-ов. Asyncio использует разные конструкции: event loop, корутины и future.- event loop управляет и распределяет выполнение различных задач. Он регистрирует их и обрабатывает распределение потока управления между ними.
- Корутины (о которых мы говорили выше) – это специальные функции, работа которых схожа с работой генераторов в Python, с помощью await они возвращают поток управления обратно в event loop. Запуск корутины должен быть запланирован в event loop. Запланированные корутины будут обернуты в Tasks, что является типом Future.
- Future отражает результат таска, который может или не может быть выполнен. Результатом может быть exception.
С помощью
asyncio вы можете структурировать свой код так, чтобы подзадачи определялись как корутины и позволяли планировать их запуск так, как вам заблагорассудится, в том числе и одновременно. Корутины содержат точки yield, в которых мы определяем возможные точки переключения контекста. В случае, если в очереди ожидания есть задачи, то контекст будет переключен, в противном случае – нет.Переключение контекста в
asyncio представляет собой event loop, который передает поток управления от одной корутины к другой.В следующем примере, мы запускаем 3 асинхронных таска, которые по-отдельности делают запросы к Reddit, извлекают и выводят содержимое JSON. Мы используем aiohttp – клиентскую библиотеку http, которая гарантирует, что даже HTTP-запрос будет выполнен асинхронно.
import signal
import sys
import asyncio
import aiohttp
import json
loop = asyncio.get_event_loop()
client = aiohttp.ClientSession(loop=loop)
async def get_json(client, url):
async with client.get(url) as response:
assert response.status == 200
return await response.read()
async def get_reddit_top(subreddit, client):
data1 = await get_json(client, 'https://www.reddit.com/r/' + subreddit + '/top.json?sort=top&t=day&limit=5')
j = json.loads(data1.decode('utf-8'))
for i in j['data']['children']:
score = i['data']['score']
title = i['data']['title']
link = i['data']['url']
print(str(score) + ': ' + title + ' (' + link + ')')
print('DONE:', subreddit + '\n')
def signal_handler(signal, frame):
loop.stop()
client.close()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
asyncio.ensure_future(get_reddit_top('python', client))
asyncio.ensure_future(get_reddit_top('programming', client))
asyncio.ensure_future(get_reddit_top('compsci', client))
loop.run_forever()Вывод:
50: Undershoot: Parsing theory in 1965 (http://jeffreykegler.github.io/Ocean-of-Awareness-blog/individual/2018/07/knuth_1965_2.html)
12: Question about best-prefix/failure function/primal match table in kmp algorithm (https://www.reddit.com/r/compsci/comments/8xd3m2/question_about_bestprefixfailure_functionprimal/)
1: Question regarding calculating the probability of failure of a RAID system (https://www.reddit.com/r/compsci/comments/8xbkk2/question_regarding_calculating_the_probability_of/)
DONE: compsci
336: /r/thanosdidnothingwrong -- banning people with python (https://clips.twitch.tv/AstutePluckyCocoaLitty)
175: PythonRobotics: Python sample codes for robotics algorithms (https://atsushisakai.github.io/PythonRobotics/)
23: Python and Flask Tutorial in VS Code (https://code.visualstudio.com/docs/python/tutorial-flask)
17: Started a new blog on Celery - what would you like to read about? (https://www.python-celery.com)
14: A Simple Anomaly Detection Algorithm in Python (https://medium.com/@mathmare_/pyng-a-simple-anomaly-detection-algorithm-2f355d7dc054)
DONE: python
1360: git bundle (https://dev.to/gabeguz/git-bundle-2l5o)
1191: Which hashing algorithm is best for uniqueness and speed? Ian Boyd's answer (top voted) is one of the best comments I've seen on Stackexchange. (https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed)
430: ARM launches “Facts” campaign against RISC-V (https://riscv-basics.com/)
244: Choice of search engine on Android nuked by “Anonymous Coward” (2009) (https://android.googlesource.com/platform/packages/apps/GlobalSearch/+/592150ac00086400415afe936d96f04d3be3ba0c)
209: Exploiting freely accessible WhatsApp data or “Why does WhatsApp web know my phone’s battery level?” (https://medium.com/@juan_cortes/exploiting-freely-accessible-whatsapp-data-or-why-does-whatsapp-know-my-battery-level-ddac224041b4)
DONE: programmingИспользование Redis и Redis Queue RQ
Использование
asyncio и aiohttp не всегда хорошая идея, особенно если вы пользуетесь более старыми версиями Python. К тому же, бывают моменты, когда вам нужно распределить задачи по разным серверам. В этом случае можно использовать RQ (Redis Queue). Это обычная библиотека Python для добавления работ в очередь и обработки их воркерами в фоновом режиме. Для организации очереди используется Redis – база данных ключей/значений.В примере ниже мы добавили в очередь простую функцию
count_words_at_url с помощью Redis.from mymodule import count_words_at_url
from redis import Redis
from rq import Queue
q = Queue(connection=Redis())
job = q.enqueue(count_words_at_url, 'http://nvie.com')
******mymodule.py******
import requests
def count_words_at_url(url):
"""Just an example function that's called async."""
resp = requests.get(url)
print( len(resp.text.split()))
return( len(resp.text.split()))Вывод:
15:10:45 RQ worker 'rq:worker:EMPID18030.9865' started, version 0.11.0
15:10:45 *** Listening on default...
15:10:45 Cleaning registries for queue: default
15:10:50 default: mymodule.count_words_at_url('http://nvie.com') (a2b7451e-731f-4f31-9232-2b7e3549051f)
322
15:10:51 default: Job OK (a2b7451e-731f-4f31-9232-2b7e3549051f)
15:10:51 Result is kept for 500 secondsЗаключение
В качестве примера возьмем шахматную выставку, где один из лучших шахматистов соревнуется с большим количеством людей. У нас есть 24 игры и 24 человека, с которыми можно сыграть, и, если шахматист будет играть с ними синхронно, это займет не менее 12 часов (при условии, что средняя игра занимает 30 ходов, шахматист продумывает ход в течение 5 секунд, а противник – примерно 55 секунд.) Однако в асинхронном режиме шахматист сможет делать ход и оставлять противнику время на раздумья, тем временем переходя к следующему противнику и деля ход. Таким образом, сделать ход во всех 24 играх можно за 2 минуты, и выиграны они все могут быть всего за один час.
Это и подразумевается, когда говорят о том, что асинхронность ускоряет работу. О такой быстроте идет речь. Хороший шахматист не начинает играть в шахматы быстрее, просто время более оптимизировано, и оно не тратится впустую на ожидание. Так это работает.
По этой аналогии шахматист будет процессором, а основная идея будет заключаться в том, чтобы процессор простаивал как можно меньше времени. Речь о том, чтобы у него всегда было занятие.
На практике асинхронность определяется как стиль параллельного программирования, в котором одни задачи освобождают процессор в периоды ожидания, чтобы другие задачи могли им воспользоваться. В Python есть несколько способов достижения параллелизма, отвечающих вашим требованиям, потоку кода, обработке данных, архитектуре и вариантам использования, и вы можете выбрать любой из них.
Узнать о курсе подробнее.
