В преддверии старта курса «Deep Learning. Basic» подготовили для вас перевод интересного материала.

Глубокое обучение внесло огромный вклад в прогресс и подъем в искусственном интеллекте, который мы сегодня наблюдаем во всем мире. Задачи, с которыми сейчас справляется искусственный интеллект, такие как классификация текста и изображений, instance segmentation, ответы на вопросы на основе текстовых данных, понимание прочитанного и многое другое, — в прошлом были научной фантастикой, а теперь становятся все более полезными и все лучше подражают человеку благодаря использованию глубоких нейронных сетей.
Как же нейронным сетям удается справляться с этими сложными задачами? Что происходит под бесконечными слоями битов математических операций, которые наполняют эти сети?

Простая нейронная сеть
Давайте копнем глубже и концептуально разберемся с основами глубоких нейронных сетей.
Для начала, давайте поговорим об алгоритме, который используется большинством (если не всеми) нейронных сетей для обучения на основе обучающих данных. Обучающие данные – это не что иное, как данные, аннотированные человеком, то есть размеченные изображения в случае с классификацией изображений или же размеченные тональности в анализе тональностей.
И называется он — алгоритм обратного распространения ошибки.
Ниже приведем краткий обзор структуры нейронных сетей:
Нейронные сети определенным образом преобразовывают входные данные в выходные. Входными данными могут быть изображения, фрагменты текста и т.д. Входные данные преобразуются в их числовое представление: например, в изображениях каждый пиксель кодируется числовым значением в зависимости от позиции, а в тексте каждое слово – это вектор из чисел, который является векторным представлением слова (в таком векторе каждое число – оценка конкретной характеристики слова) или одномерный вектор (вектор размерности n, состоящий из n-1 нулей и одной единицы, где позиция единицы будет указывать на выбранное слово).
Дальше эти числовые входные данные проходят через нейронную сеть (с помощью метода, известного как обратное распространение ошибки), которая под капотом имеет несколько шагов умножения на веса в сети, сложения смещений и проход через нелинейную функцию активации. Такой шаг с прямым распространением выполняется для каждого входного сигнала в размеченных обучающих данных, а точность сети вычисляется с помощью функции, известной как функция потерь или функция затрат. Цель сети – минимизировать функцию потерь, то есть максимизировать ее точность. Изначально сеть начинает работать со случайным значением параметров (весов и смещений), а затем постепенно повышает свою точность и минимизирует потери, продолжая улучшать эти параметры на каждой итерации путем прямого распространения на обучающих данных. Обновление весов и смещений (величины и положительного или отрицательного направления) определяется алгоритмом обратного распространения ошибки. Давайте рассмотрим алгоритм обратного распространения ошибки и поймем, как он помогает нейронным сетям «учиться» и минимизировать потери обучающих данных.
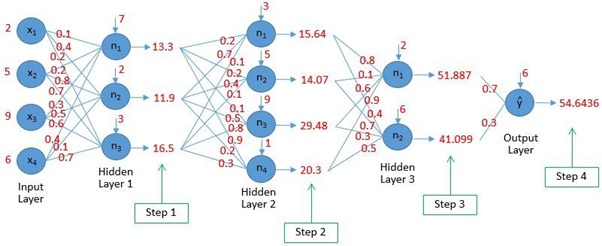
Прямое распространение в глубокой нейронной сети
Суть обратного распространения ошибки состоит в том, чтобы выяснить, как должен измениться каждый параметр, чтобы лучше соответствовать обучающим данным (т.е. минимизировать потери и максимизировать точность прогнозирования). Метод определения этих величин довольно прост:

На рисунке выше ось Y – это функция потерь, а ось Х – некоторый параметр (вес) в сети. Изначальное значение веса нужно уменьшить, чтобы добраться до локального минимума. Но как же сети понять, что вес нужно уменьшить, чтобы это сделать? Сеть будет опираться на наклон функции в начальной точке.
Как же получить наклон? Если вы изучали математику, то знаете, что наклон функции в точке задается ее производной. Вуаля! Теперь мы можем рассчитать наклон, а следовательно, и направление изменения (положительное или отрицательно) веса. Значение веса обновляется итеративно и в конечном итоге мы получаем минимум.
Сложность возникает, когда веса не связаны напрямую с функцией потерь, как в случае с глубокими нейронными сетями. Здесь на помощь приходит знакомое правило цепи.

Например, на рисунке выше показано, что результат Y не зависит напрямую от входного значения Х, однако Х проходит через F, а потом через G перед тем, как дать выходное значение Y. С помощью правила цепи можно записать производную от G по Х, указав на зависимость G от F, где F зависит от X. Применять это правило можно для сетей любой длины с результирующей производной и, следовательно, наклоном для любого выходного значения по отношению к входному, полученному как произведение производных всех шагов, через которые проходит входное значение. В этом и заключается суть обратного распространения ошибки, где производная/наклон выходного значения по отношению к каждому параметру получается путем перемножения производных при обратном проходе через сеть до тех пор порка не найдется прямая производная параметра, именно поэтому метод и называется обратным распространением.
На этом все. Чтоб узнать о курсе подробнее, приглашаем вас записаться на день открытых дверей по ссылке ниже:


Глубокое обучение внесло огромный вклад в прогресс и подъем в искусственном интеллекте, который мы сегодня наблюдаем во всем мире. Задачи, с которыми сейчас справляется искусственный интеллект, такие как классификация текста и изображений, instance segmentation, ответы на вопросы на основе текстовых данных, понимание прочитанного и многое другое, — в прошлом были научной фантастикой, а теперь становятся все более полезными и все лучше подражают человеку благодаря использованию глубоких нейронных сетей.
Как же нейронным сетям удается справляться с этими сложными задачами? Что происходит под бесконечными слоями битов математических операций, которые наполняют эти сети?

Простая нейронная сеть
Давайте копнем глубже и концептуально разберемся с основами глубоких нейронных сетей.
Для начала, давайте поговорим об алгоритме, который используется большинством (если не всеми) нейронных сетей для обучения на основе обучающих данных. Обучающие данные – это не что иное, как данные, аннотированные человеком, то есть размеченные изображения в случае с классификацией изображений или же размеченные тональности в анализе тональностей.
И называется он — алгоритм обратного распространения ошибки.
Ниже приведем краткий обзор структуры нейронных сетей:
Нейронные сети определенным образом преобразовывают входные данные в выходные. Входными данными могут быть изображения, фрагменты текста и т.д. Входные данные преобразуются в их числовое представление: например, в изображениях каждый пиксель кодируется числовым значением в зависимости от позиции, а в тексте каждое слово – это вектор из чисел, который является векторным представлением слова (в таком векторе каждое число – оценка конкретной характеристики слова) или одномерный вектор (вектор размерности n, состоящий из n-1 нулей и одной единицы, где позиция единицы будет указывать на выбранное слово).
Дальше эти числовые входные данные проходят через нейронную сеть (с помощью метода, известного как обратное распространение ошибки), которая под капотом имеет несколько шагов умножения на веса в сети, сложения смещений и проход через нелинейную функцию активации. Такой шаг с прямым распространением выполняется для каждого входного сигнала в размеченных обучающих данных, а точность сети вычисляется с помощью функции, известной как функция потерь или функция затрат. Цель сети – минимизировать функцию потерь, то есть максимизировать ее точность. Изначально сеть начинает работать со случайным значением параметров (весов и смещений), а затем постепенно повышает свою точность и минимизирует потери, продолжая улучшать эти параметры на каждой итерации путем прямого распространения на обучающих данных. Обновление весов и смещений (величины и положительного или отрицательного направления) определяется алгоритмом обратного распространения ошибки. Давайте рассмотрим алгоритм обратного распространения ошибки и поймем, как он помогает нейронным сетям «учиться» и минимизировать потери обучающих данных.

Прямое распространение в глубокой нейронной сети
Суть обратного распространения ошибки состоит в том, чтобы выяснить, как должен измениться каждый параметр, чтобы лучше соответствовать обучающим данным (т.е. минимизировать потери и максимизировать точность прогнозирования). Метод определения этих величин довольно прост:

На рисунке выше ось Y – это функция потерь, а ось Х – некоторый параметр (вес) в сети. Изначальное значение веса нужно уменьшить, чтобы добраться до локального минимума. Но как же сети понять, что вес нужно уменьшить, чтобы это сделать? Сеть будет опираться на наклон функции в начальной точке.
Как же получить наклон? Если вы изучали математику, то знаете, что наклон функции в точке задается ее производной. Вуаля! Теперь мы можем рассчитать наклон, а следовательно, и направление изменения (положительное или отрицательно) веса. Значение веса обновляется итеративно и в конечном итоге мы получаем минимум.
Сложность возникает, когда веса не связаны напрямую с функцией потерь, как в случае с глубокими нейронными сетями. Здесь на помощь приходит знакомое правило цепи.

Например, на рисунке выше показано, что результат Y не зависит напрямую от входного значения Х, однако Х проходит через F, а потом через G перед тем, как дать выходное значение Y. С помощью правила цепи можно записать производную от G по Х, указав на зависимость G от F, где F зависит от X. Применять это правило можно для сетей любой длины с результирующей производной и, следовательно, наклоном для любого выходного значения по отношению к входному, полученному как произведение производных всех шагов, через которые проходит входное значение. В этом и заключается суть обратного распространения ошибки, где производная/наклон выходного значения по отношению к каждому параметру получается путем перемножения производных при обратном проходе через сеть до тех пор порка не найдется прямая производная параметра, именно поэтому метод и называется обратным распространением.
На этом все. Чтоб узнать о курсе подробнее, приглашаем вас записаться на день открытых дверей по ссылке ниже:

