
Перевод материала подготовлен в рамках онлайн-курса «Экосистема Hadoop, Spark, Hive».
Всех желающих приглашаем на бесплатный вебинар «Тестирование Spark приложений». На открытом уроке рассмотрим проблемы в тестировании Spark приложений: стат данные, частичную проверку и запуск/остановку тяжелых систем. Изучим библиотеки для решения и напишем тесты.
Проект Apache Spark стал одним из основных инструментов в наборе средств инженеров по обработке больших данных. Он включает широкий ряд возможностей: от высокопроизводительного ядра пакетной обработки до ядра потоковой передачи в режиме, близком к реальному времени.
Spark Streaming
Наша компания Clairvoyant работает с клиентами, бизнес-задачи которых требуют создания высокопроизводительных систем для обработки больших данных в режиме реального времени. В число таких задач входят, например, системы оповещения, обработка данных Интернета вещей и многие другие. Мы пробовали разные технологии, включая Apache Nifi, Apache Flume, Apache Flink и др. Однако одно из любимых наших решений — это Spark Streaming.
Spark Streaming — это расширение Core Apache Spark для масштабируемой, высокопроизводительной и устойчивой к сбоям обработки потоков данных в режиме реального времени. Некоторые возможные источники таких потоков данных приведены на схеме ниже.

Spark Streaming — ссылка на источник
Внутренние процессы Spark Streaming реализованы с использованием архитектуры микропакетов. Это означает, что периодически (каждые X секунд) Spark Streaming активирует задание для выполнения ядром Spark Engine. В течение этого времени Spark принимает сообщения из какого-то источника, обрабатывает данные с помощью определенного пользователем направленного ациклического графа (Directed Acyclic Graph, DAG) и сохраняет данные в расположении, указанном в качестве приемника.

Процесс обработки данных в Spark Streaming — ссылка на источник
При реализации решений с использованием Spark Streaming для больших данных мы обнаружили, что для эффективной работы Spark в рабочем кластере необходимы некоторые дополнительные шаги. Эти шаги описаны в данной статье.
Начальный код
Раз речь идет о том, чтобы взять задание Spark Streaming и подготовить его к использованию в рабочей среде, прежде всего нам потребуется задание Spark Streaming, которое мы будем улучшать. Ниже представлен код, который мы будем использовать как отправную точку:
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String]
(topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()Этот код выполняет следующие действия:
Создает
StreamingContextи определяет интервал между пакетами, равный 2 секундамУстанавливает соединение с Kafka и создает поток DStream
Выполняет подсчет слов на RDD в DStream
Выводит результаты на консоль
Запускает
StreamingContext
То есть это простой пример подсчета слов, использующий Apache Kafka в качестве источника.
Использование режима кластера YARN
Сначала рассмотрим, как запускается приложение Spark:
Сборка файла JAR (или файла Python)
Выполнение команды spark-submit:
$ spark-submit --class “org.apache.spark.testSimpleApp” --master
local[4] /path/to/jar/simple-project_2.11–1.0.jarВ этой команде spark-submit в качестве параметра master мы указали local[4]. Это означает, что приложение Spark запускается в локальном режиме, а не в кластере, где находятся данные.
Рассмотрим архитектуру Spark:
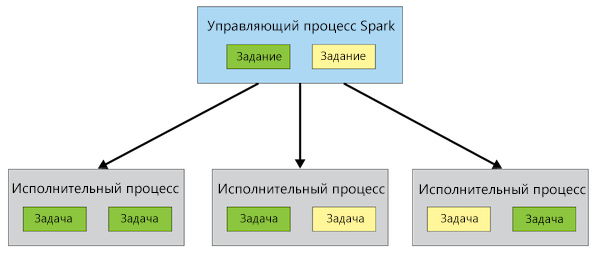
Архитектура Spark — ссылка на источник
На приведенной схеме присутствует процесс Spark Driver. Это управляющий (master) процесс, который содержит все процедуры и задания, которые надлежит выполнить (направленные ациклические графы — DAG, определенные пользователем в коде Java, Scala или Python). Управляющий процесс передает исполнительным процессам (Executor) задачи, которые надлежит выполнить, и контролирует их успешное выполнение, прежде чем будет завершен сам.
Почти во всех случаях, с которыми мы сталкивались, приложения Spark выполнялись в кластере больших данных Hadoop, на котором доступен модуль YARN (Yet Another Resource Negotiator — «еще один ресурсный посредник»). Поэтому, когда ваш код будет протестирован и готов к переносу в рабочую среду, имеет смысл использовать YARN в качестве менеджера ресурсов для выделения исполнительных ресурсов вашим процессам Spark Driver и Executor. Для этого следует указать YARN в качестве master:
Версии Spark до 1.6.3
YARN в режиме клиента: --master yarn-client
YARN в режиме кластера: --master yarn-cluster
Версии Spark до 2.0
YARN в режиме клиента: --master yarn --deploy-mode client
YARN в режиме кластера: --master yarn --deploy-mode cluster
Доступны 2 режима: клиент и кластер. Они отличаются друг от друга местом выполнения управляющего процесса Spark Driver: на клиенте или в кластере. Рассмотрим этот момент подробнее.
YARN в режиме клиента

YARN в режиме клиента — ссылка на источник
В режиме клиента процесс Spark Driver запускается на компьютере-клиенте (или на том же компьютере, с которого выполнена команда spark-submit). Как показывает наша практика, большинство организаций запускают все свои приложения Spark в этом режиме. Это вполне подходящее решение для выполнения процессов пакетной обработки с помощью Spark. Однако если действовать так же с приложениями Spark Streaming, возникает проблема.
Приложения Spark Streaming — это процессы, которые в принципе должны выполняться бесконечно. Но что если компьютер, на котором выполняется приложение Spark Streaming, будет выключен? Это приведет к прекращению работы приложения.
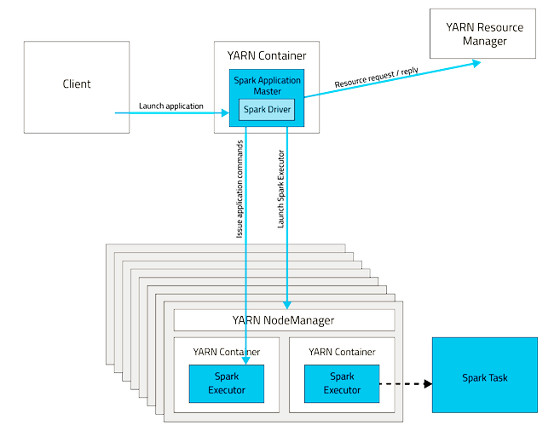
YARN в режиме кластера

YARN в режиме кластера — ссылка на источник
В режиме кластера управляющий процесс Spark Driver выполняется в контейнере в YARN. Теперь, если возникнут какие-либо сбои, YARN справится с ними. Если компьютер, на котором выполняется управляющий процесс, будет отключен, то процесс будет автоматически перезапущен на другом узле.
Полезные параметры конфигурации
spark.yarn.maxAppAttempts
Максимальное число попыток отправки приложения. Число не должно быть больше, чем общее максимальное число попыток в конфигурации YARN.
spark.yarn.am.attemptFailuresValidityInterval
Определение периода достоверности для отслеживания сбоев процесса Application Master (AM). Если процесс AM выполняется в течение этого периода, то счетчик сбоев AM обнуляется. Данная функция активна, только если настроена.
Таким образом, если задать в настройках значения:
spark.yarn.maxAppAttempts=2
spark.yarn.am.attemptFailuresValidityInterval=1h,
то каждый час программа будет выполнять две попытки запустить приложение.
Настройка параметров конфигурации
В команде spark-submit:
$ spark-submit
--class "org.apache.testSimpleApp"
--master yarn
--deploy-mode cluster
--conf spark.yarn.maxAppAttempts=2
--conf spark.yarn.am.attemptFailuresValidityInterval=1h
/path/to/jar/simple-project_2.11-1.0.jarВ коде:
val sparkConf = new SparkConf()
.setAppName("App")
.set("spark.yarn.maxAppAttempts", "1")
.set("spark.yarn.am.attemptFailuresValidityInterval", "2h")
val ssc = new StreamingContext(sparkConf, Seconds(2))Корректное завершение работы приложения потоковой передачи
Мы уже научились запускать приложение в корректном режиме, а теперь обсудим, как правильно завершить работу приложения Spark Streaming для больших данных, если мы захотим развернуть новые возможности, внести изменения в конфигурацию и т. п.
В настоящее время YARN позволяет завершить работу приложения Spark Streaming следующей командой:
$ yarn application -kill {ApplicationID}Но что будет, если выполнить эту команду и завершить работу приложения в момент, когда выполняется обработка микропакета Spark Streaming?
Говоря коротко, ответ таков: данные, которые вы обрабатываете, будут потеряны.
Кроме того, учитывая, как система Spark получает сообщения от кластера Kafka (она сперва посылает в Kafka подтверждение получения сообщений, а затем обрабатывает их), при перезапуске приложения Spark Streaming оно пропустит сообщения, которые обрабатывались в момент отключения, и начнет обработку с сообщения, которое поступило следующим.
Чтобы решить эту проблему, необходимо реализовать процесс корректного завершения работы, который гарантирует, что приложение Spark Streaming может быть закрыто только в промежуток между микропакетами, чтобы не потерять данные.
Первый шаг по реализации корректного завершения работы для нашего начального кода будет следующим:
// Start the computation
ssc.start()
ssc.awaitTermination() <--- REMOVE THIS LINEВместо этого для корректного завершения работы приложения Spark Streaming мы выполним следующие шаги:
При запуске Spark Streaming: создать пустой файл в HDFS.
В коде Spark Code: периодически проверять, существует ли еще этот пустой файл. Если пустой файл не существует, запустить процесс корректного завершения работы.
Для остановки: удалить пустой файл и дождаться, пока будет выполнено корректное завершение работы.
Совет: создайте скрипт в оболочке для выполнения этих операций запуска и остановки.
Понадобится написать примерно такой код для Spark:
Первое изменение — добавление глобальной переменной, которая указывает, что мы приступаем к завершению работы приложения. Затем следует заменить процесс awaitTermination на цикл while. В этом цикле мы будем периодически проверять, существует ли еще файл в HDFS. Если файл отсутствует, то значение глобальной переменной меняется на true и заданная в цикле while логика выполняет команду остановки в контексте StreamingContext.
Мониторинг приложения для потоковой передачи больших данных
Как и с любым важным приложением, вам понадобится возможность убедиться, что ваше приложение выполняется, причем корректно. С приложением Spark Streaming это можно сделать несколькими способами.
Мониторинг в ходе выполнения
См. дополнительную информацию здесь: http://spark.apache.org/docs/latest/monitoring#metrics
Прослушиватель StreamingListener (Spark ≥ 2.1)
В версиях Apache Spark начиная с 2.1 поддерживается добавление прослушивателей, которые запускают события на различных этапах запуска и выполнения приложения Spark Streaming. Вот некоторые из доступных прослушивателей:
onBatchSubmitted
onBatchStarted
onBatchCompleted
onReceiverStarted
onReceiverStopped
onReceiverError
Эти прослушиватели позволяют вручную реализовать процесс для отправки различных метрик службе мониторинга, которую использует ваша организация. В прошлом мы использовали этот подход для отправки метрик по каждому микропакету (количество полученных сообщений, время обработки, различные ошибки и т. п.) в реляционную базу данных. Затем мы делали запросы к этой базе, чтобы убедиться, что процесс выполняется с приемлемой производительностью.
Пользовательский интерфейс Spark

Интерфейс Spark входит в комплектацию Apache Spark и содержит некоторые весьма полезные сведения. Выше приведено одно из нескольких и, пожалуй, самое важное представление интерфейса: общее представление процессов потоковой передачи. Оно содержит информацию о каждом микропакете. Отображаются сведения о том, сколько записей обработано микропакетом, сколько времени это заняло, какой была задержка при запуске микропакета и т. п. В целом это отличный способ подтвердить, что ваше приложение Spark Streaming выполняется и демонстрирует надлежащую производительность.
Использование контрольных точек
Возможно, вам уже знакомо стандартное применение контрольных точек для пакетов Apache Spark. При этой методике данные, содержащиеся в RDD или DataFrame, сохраняются на диск между выполнением задач, содержащихся в RDD. Благодаря этому в случае сбоя исполнительного процесса Spark может просто возобновить его начиная с такой контрольной точки, а не перезапускать исполнение RDD или DataFrame с начала.
Эта функция вполне применима к Spark Streaming, однако есть и другой способ использования контрольных точек, который может быть полезен для приложений Spark Streaming, — контрольные точки метаданных.
Контрольные точки метаданных
Речь идет о сохранении метаданных, которые определяют вычисления, связанные с потоковой передачей, в устойчивом к сбоям хранилище, например HDFS. Этот способ используется для восстановления после сбоя узла, на котором выполняется управляющий процесс приложения Spark Streaming. Метаданные включают, в частности, следующее:
конфигурации. Настройки конфигурации, которые использовались для создания приложения потоковой передачи;
операции DStream. Набор операций DStream, которые определяют приложение потоковой передачи;
незавершенные пакеты. Пакеты, задания которых поставлены в очередь, но еще не выполнены.
Этот способ применения контрольных точек требуется также в случае, когда нужно выполнять трансформации с сохранением состояния, например updateStateByKey или reduceByKeyAndWindow.
Включить использование контрольных точек в коде можно следующим образом:
val checkpointDirectory = "hdfs://..." // define checkpoint directory
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc // Return the StreamingContext
}
// Get StreamingContext from checkpoint data or create a new one
val ssc = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
ssc.start() // Start the contextПроблемы с контрольными точками метаданных
При использовании контрольных точек метаданных необходимо помнить о нескольких проблемных моментах.
Контрольные точки ломаются после обновления версии Spark
При обновлении версии Spark вам придется удалить контрольную точку вручную.
Контрольные точки необходимо удалять перед обновлением кода
Поскольку в контрольные точки метаданных входят контрольные точки реальных операций DStream, которые должны выполняться для входящих записей, для загрузки новых операций из обновленного кода необходимо удалить имеющиеся контрольные точки. В случае незначительной правки кода для использования чуть отличающихся операций, если вы развернете код заново, но не удалите контрольную точку, из старой контрольной точки будут загружаться старые операции, и внесенные вами изменения не будут применены.
Создание нескольких разделов в темах Kafka
Если вы используете Kafka в качестве источника данных для приложения Spark Streaming, целесообразно определить при создании темы Kafka несколько разделов. Ниже с помощью схем я объясню, как это сделать.
В команде для создания темы Kafka можно указать количество разделов (параметр выделен жирным шрифтом):
kafka-topics --zookeeper <host>:2181 --create --topic <topic-name> --partitions <number-of-partitions> --replication-factor <number-of-replicas>

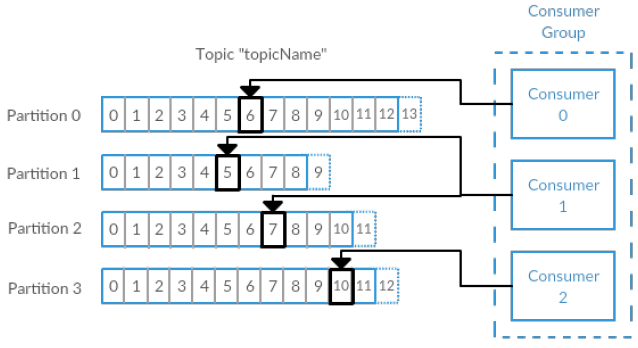
Записи Kafka — ссылка на источник
Когда данные передаются в тему Kafka, они автоматически распределяются между разделами согласно ключу, который вы определили в сообщении Kafka. Каждое сообщение добавляется в тему Kafka с определенным смещением или с идентификатором, указывающим его позицию в разделе. Если в качестве ключа задать null, то сообщение будет автоматически равномерно распределяться между разделами.

Считывание из Kafka — ссылка на источник
На схеме выше показано, как приложение Spark Streaming может действовать при обработке сообщений из темы Kafka с несколькими разделами. Каждого «потребителя» можно рассматривать как один из исполнительных процессов Spark. Каждый исполнительный процесс Spark может независимо загружать данные из определенной темы Kafka, вместо того чтобы использовать единый источник. При этом каждый раздел может существовать на отдельном экземпляре брокера Kafka (отдельном узле), что позволяет снизить нагрузку на узлы.
Использование прямых потоков с кластером Kafka
Если вы используете кластер Kafka, то стоит помнить, что существует 2 типа соединителей: поток через приемник и прямой поток. И если название этого раздела еще не дало ответ, вы можете спросить: «Какой из них мне следует использовать?», а также, возможно, «А в чем разница?». Разберем, чем они отличаются друг от друга.
Потоковая передача через приемник

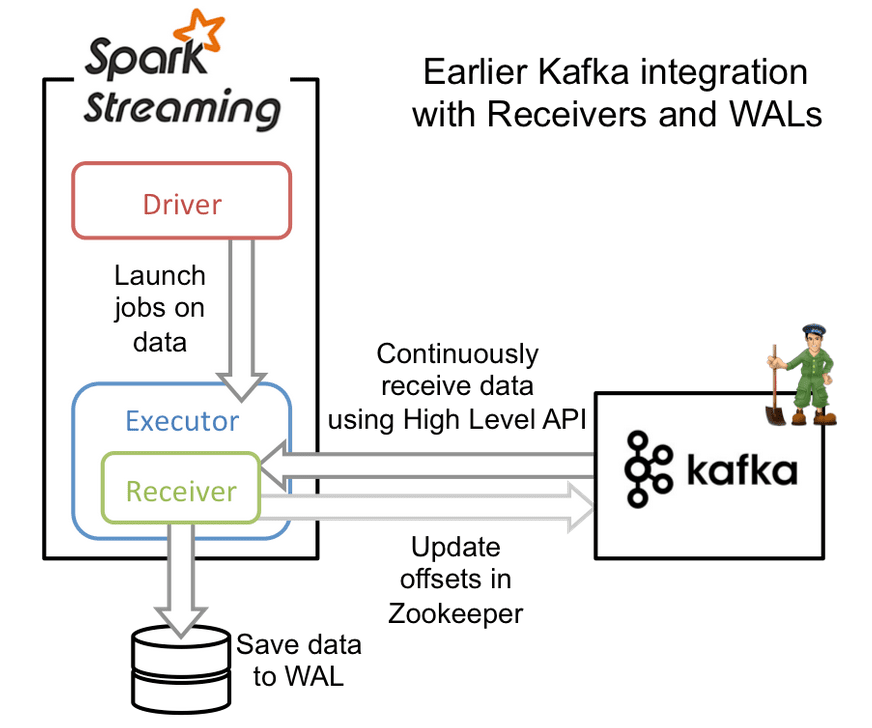
Потоковая передача Spark Streaming через приемник — ссылка на источник
На самом деле, потоковая передача через приемник — это стандартная для Spark Streaming реализация получения данных из любого источника (она одинаковым образом используется для таких источников, как Twitter, Kinesis и др.). В каждом исполнительном процессе запущен и выполняется экземпляр приемника. В начале микропакета управляющий процесс запускает задание для исполнительного процесса. При этом активируется процесс-приемник в таком исполнительном процессе, использующий высокоуровневый API Kafka для загрузки последних данных из темы Kafka. Затем данные из приемника сохраняются в журнале упреждающего протоколирования (Write Ahead Log — WAL). Перед обновлением Kafka выполняется получение данных (это защищает их от потери). Когда данные благополучно сохранены в WAL, исполнительные процессы Spark переходят к обработке сообщений.
Такая стратегия обеспечивает защиту следующим образом: если в одном из исполнительных процессов возникает сбой, то вместо него порождается новый исполнительный процесс. Этот исполнительный процесс загружает данные, которые процесс, завершившийся сбоем, предварительно сохранил в WAL.
Примечание. Если вы хотите использовать поток, направляемый через приемник, надлежит сделать следующее:
активировать использование контрольных точек — это позволит записывать журналы упреждающего протоколирования WAL в каталог контрольных точек;
активировать WAL — упреждающее протоколирование не включено при потоковой передаче с использованием приемника по умолчанию. Чтобы включить его, задайте в конфигурации следующую настройку: spark.streaming.receiver.wrteAheadLog.enable=true;
задать необходимый уровень StorageLevel для WAL — поскольку данные уже сохранены в HDFS, можно отключить репликацию в памяти, чтобы не дублировать сохранение: StorageLevel.MEMROY_AND_DISK_SER.
Такой была первая реализация, доступная в Spark Streaming, и сейчас она по-прежнему работает. Почему же понадобилась другая реализация?
По следующим соображениям: кластер Kafka уже сохранял реплицированные копии данных в циклическом буфере, обеспечивая их высокую доступность. Зачем тогда нужен журнал WAL? Действительно: использование WAL несколько снижает производительность, так как после получения данных из кластера Kafka их требуется записать на диск. Поэтому была добавлена следующая возможность: прямой поток.
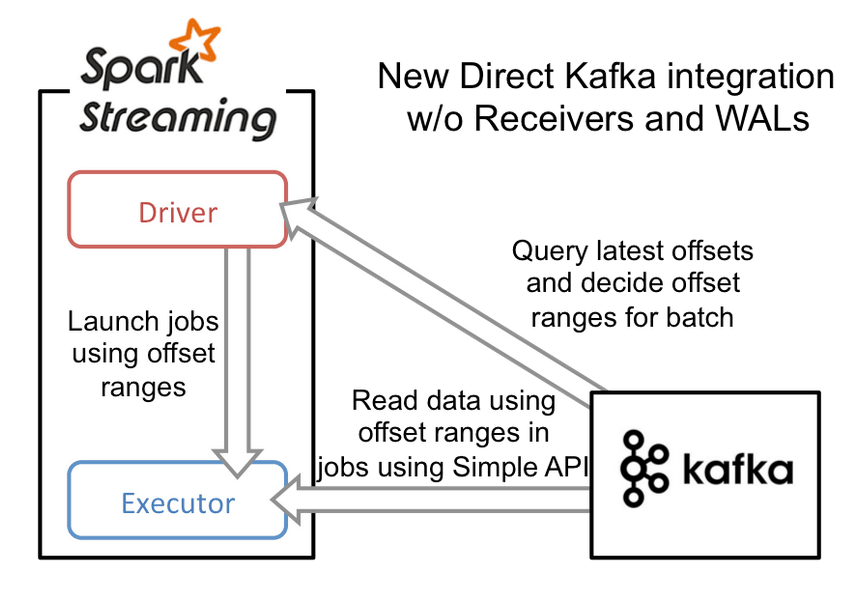
Прямой поток

Прямой поток Spark Streaming — ссылка на источник
При использовании прямого потока мы отказываемся от WAL, и роль WAL выполняет Kafka. Исполнение начинается с того, что управляющий процесс загружает задания в исполнительные процессы. Также он передает каждому из исполнительных процессов диапазон смещений, которые тот должен обрабатывать. Например, исполнительный процесс 1 может получить диапазон смещений 2000–2050, а исполнительный процесс 2 — диапазон смещений 2051–2100. Каждый исполнительный процесс выполняет загрузку в назначенный для него диапазон смещений и обрабатывает эти данные.
Такая стратегия обеспечивает защиту следующим образом: если в одном из исполнительных процессов возникает сбой, то вместо него порождается новый исполнительный процесс. Управляющий процесс назначает новому исполнительному процессу тот же диапазон смещений, что и предыдущему, и выполняется повторная попытка обработки этих данных.
Сохранение смещений Kafka
Большинство организаций и отдельных групп в составе организаций, с которыми мы сталкивались, рассчитывают получить с помощью Spark Streaming семантику доставки «только один раз». К сожалению, в распределенной системе, устойчивой к сбоям, добиться этого очень сложно. И уж во всяком случае, Spark Streaming не предоставляет такую семантику в качестве готовой возможности (доступные варианты — либо «минимум один раз», либо «максимум один раз»). Тем не менее Spark Streaming позволяет получить нужный результат с помощью определенных изменений.
Главное, что для этого требуется, — сохранить смещения Kafka, которые были успешно обработаны, после завершения обработки микропакета и загрузить при запуске приложения Spark Streaming последние завершенные смещения Kafka. Такое сохранение должно выполняться в том и только в том случае, если транзакция с входящими сообщениями была завершена успешно. Говоря конкретнее, вы должны сохранять смещения после идемпотентного вывода ИЛИ сохранять их посредством атомарной транзакции параллельно выводу.
В результате вы будете переходить от текущего набора данных к следующему только после того, как данные будут трансформированы и сохранены на ваш источник вывода. Используя прямые потоки с описанными выше изменениями, вы обеспечите устойчивость к сбоям при обработке всех данных в составе микропакета и реализуете желаемую семантику доставки «только один раз».
На схеме ниже показано, как при этом будет работать ваше приложение.

Управление смещениями Kafka — ссылка на источник
Приведенный ниже пример кода демонстрирует, как инициализировать прямой поток Kafka DStream, загружая смещения из команды loadOffsets:
val storedOffsets: Option[mutable.Map[TopicPartition, Long]] = loadOffsets(spark, kuduContext)
val kafkaDStream = storedOffsets match {
case None =>
LOGGER.info("storedOffsets was None")
kafkaParams += ("auto.offset.reset" -> "latest")
KafkaUtils.createDirectStream[String, Array[Byte]]
(ssc, PreferConsistent, ConsumerStrategies.Subscribe[String, Array[Byte]]
(topicsSet, kafkaParams)
)
case Some(fromOffsets) =>
LOGGER.info("storedOffsets was Some(" + fromOffsets + ")")
kafkaParams += ("auto.offset.reset" -> "none")
KafkaUtils.createDirectStream[String, Array[Byte]]
(ssc, PreferConsistent, ConsumerStrategies.Assign[String, Array[Byte]]
(fromOffsets.keys.toList, kafkaParams, fromOffsets)
)
}Здесь предполагается, что для сохранения смещений используется Kudu (поэтому указан контекст kuduContext), но общая процедура будет работать с любой системой, в которой сохраняются смещения: Zookeeper, HBase, HDFS, Hive, Impala и др.
Стабилизация приложения для потоковой передачи больших данных
Прежде чем выпустить приложение в рабочую среду, стоит потратить немного времени на тестирование производительности. Главное, что вы должны при этом обеспечить, —
среднее время обработки пакета должно быть меньше интервала между пакетами.
Например, если вы установили интервал между пакетами, равный 30 секундам, то среднее время обработки одного микропакета должно быть менее 30 секунд.
В каждый момент времени обрабатывается только один микропакет. Поэтому, если обработка первого микропакета займет 40 секунд, то перед фактическим началом обработки второго пакета возникнет задержка. Если время обработки микропакетов постоянно будет составлять около 40 секунд, они будут прибывать быстрее, чем обрабатываться. В скором времени у вас скопятся десятки микропакетов, ожидающих обработки.
Опасность этой ситуации состоит в том, что микропакеты будут поступать, пока не заполнят всю динамическую память. В конце концов произойдет сбой приложения Spark.
В пользовательском интерфейсе Spark можно посмотреть, сколько времени занимает обработка микропакетов. На изображениях ниже показано задание, для которого задан интервал между пакетами 10 секунд, а время обработки иногда превышает 10 секунд, в результате чего возникает скачок времени задержки.

Если окажется, что время обработки ваших микропакетов постоянно превышает интервал между пакетами, можно применить описанные ниже стратегии.
Оптимизация операций (трансформации, присоединения и записи)
Стоит проанализировать, какие операции выполняются вашим приложением Spark Streaming. Если вы сохраняете данные во внешнюю базу данных, которая требует индексации, то операция сохранения может оказывать критическое влияние на производительность приложения. Также можно проверить, насколько эффективно выполняются присоединения (join) и можно ли оптимизировать производительность, расположив те или иные наборы данных справа или слева при присоединении.
Реализация кэширования
Если вы несколько раз обрабатываете один и тот же источник RDD/DataFrame, значительно улучшить ситуацию может кэширование результата RDD/DataFrame в памяти.
Повышение объемов параллельной обработки
Пропускная способность приложения при работе с Kafka может страдать, если используется недостаточное количество разделов. Если в теме определен только один раздел или слишком мало брокеров, это может сократить время доставки данных исполнительным процессам Spark.
Также может оказаться, что в приложении Spark Streaming не хватает исполнительных процессов для максимально эффективной обработки всех поступающих данных. Добавление исполнительных процессов может помочь в такой ситуации.
Перераспределение данных по разделам
Если выяснится, что данные несбалансированны (то есть практически все данные распределяются на один исполнительный процесс), следует вернуться к оптимизации операций и подобрать более эффективное присоединение или другую операцию, которая обеспечит баланс. В худшем варианте этого сценария можно переопределить разделы, чтобы изменить распределение данных:
dstream.repartition(100)Увеличение длительности пакета
Если все остальные способы не дадут результата, попробуйте увеличить длительность пакета. Конечно, это приведет к увеличению количества обрабатываемых данных, но может оказаться так, что вы выполняете какую-нибудь операцию, которая всегда занимает около 10 секунд, независимо от объема данных. В этом случае увеличение длительности пакета может помочь.
Успешной работы со Spark Streaming!
Подробнее о курсе «Экосистема Hadoop, Spark, Hive»
Смотреть открытый вебинар «Тестирование Spark приложений»

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}