

Об авторах: Майк Дель Бальсо, генеральный директор и сооснователь компании Tecton Виллем Пиенаар, создатель хранилища признаков Feast
Специалисты по работе с данными постепенно понимают, что для применения машинного обучения в практических сценариях недостаточно создать конвейеры для обработки данных, но требуется решить и множество других проблем.
В предыдущей статье блога Tecton «Зачем использовать методы DevOps для обработки данных в машинном обучении?» мы рассказали об основных проблемах обработки данных, с которыми сталкиваются создатели систем машинного обучения.
Доступ к нужным исходным данным
Создание признаков на основе исходных данных
Объединение признаков в наборы обучающих данных
Вычисление значений признаков и их передача в продакшен-среду
Мониторинг признаков в продакшене
Интеллектуальные системы обработки данных уже давно и широко используются в продакшене для решения различных задач, будь то масштабная аналитика или потоковая обработка информации в режиме реального времени. Однако практическое машинное обучение, то есть аналитика на основе машинного обучения в приложениях, ориентированных на пользователя, для многих специалистов все еще в новинку. Развертывание моделей машинного обучения в продакшене для практических целей (таких как создание рекомендательных систем, выявление мошенничества, персонализация пользовательского опыта) предъявляет новые требования к инструментам обработки данных.
Специально для решения этой задачи и предназначен новый тип инфраструктуры данных, ориентированной на машинное обучение.
Дата-сайентисты и дата-инженеры начинают использовать хранилища признаков для управления наборами данных и конвейерами их обработки, которые необходимы для запуска приложений с машинным обучением в продакшене. В этой статье мы расскажем о ключевых компонентах современного хранилища признаков и о том, как эти компоненты в совокупности могут увеличить эффективность работы организации: избавить инженеров от лишней работы, ускорить цикл машинного обучения и открыть новые возможности для сотрудничества между разными командами дата-сайентистов.
Короткая справка: в машинном обучении признаком называют данные, которые используются как входные сигналы для прогнозирующей модели.
Например, если компания, обслуживающая кредитные карты, хочет спрогнозировать, является ли та или иная транзакция мошеннической, полезный признак может выглядеть так: инициирована ли транзакция из-за рубежа или каков размер этой транзакции в сравнении с типовым для данного клиента. При этом, говоря о признаке, мы обычно имеем в виду смысл сигнала (например, «зарубежная_транзакция»), а не конкретное значение данного признака («транзакция #1364 была инициирована из зарубежной страны»).

Введение в концепцию хранилища признаков
«Интерфейс, объединяющий модели и данные»
Впервые мы упомянули хранилища признаков в статье, посвященной платформе Michelangelo компании Uber. С тех пор они стали неотъемлемой частью стека технологий практического машинного обучения.
Хранилища признаков позволяют:
Вводить новые признаки в продакшен-среду без значительных усилий со стороны инженеров
Автоматизировать вычисление признаков, операции заполнения отсутствующих значений, а также ведение журналов
Повторно использовать конвейеры обработки признаков и делиться ими с другими командами специалистов
Отслеживать версии признаков, происхождение данных и метаданные
Обеспечить согласованность между обучающими и реальными данными
Вести мониторинг работоспособности конвейеров для обработки признаков в продакшен-среде
Основное предназначение хранилищ признаков — решение проблем управления данными, возникающих в ходе создания и эксплуатации практических приложений с машинным обучением.
Это специализированные системы обработки данных, ориентированные на машинное обучение, которые способны:
запускать конвейеры обработки данных для преобразования исходных данных в значения признаков;
хранить данные признаков и управлять ими;
согласованно доставлять данные признаков для обучения и формирования логических заключений.

Чтобы облегчить управление признаками, хранилища признаков предоставляют абстракции данных, которые упрощают создание, развертывание и анализ конвейеров в различных средах. Например, они позволяют единожды определить преобразование признака, а затем вычислять его значения и согласованно использовать их как в среде разработки (для обучения на основе предыдущих значений признаков), так и в продакшене (для формирования логических заключений с использованием новых значений).
На протяжении всего жизненного цикла проекта машинного обучения хранилища признаков выступают центральным узлом для хранения данных и метаданных признаков. Данные в таких хранилищах используются для:
поиска и разработки признаков;
доработки, обучения и отладки моделей;
обнаружения признаков и предоставления доступа к ним;
доставки данных моделям, работающим в продакшене, с целью формирования логических заключений;
оперативного мониторинга состояния системы.
Организациям, занятым разработкой моделей машинного обучения, хранилища признаков помогают добиться экономии при масштабировании систем за счет расширения возможностей совместной работы специалистов. Признак, зарегистрированный в хранилище, немедленно становится доступным для повторного использования в обучении других моделей, созданных организацией. Это позволяет избавить дата-инженеров от лишней работы и обеспечить новые проекты библиотекой тщательно отобранных признаков, готовых к применению в продакшене.

Эффективные хранилища признаков — это модульные системы, способные адаптироваться к той среде, в которой они развернуты. Типовое хранилище включает пять основных компонентов. Далее в статье мы подробнее расскажем о каждом из них и о том, как они помогают увеличить эффективность практических приложений с машинным обучением.
Компоненты хранилища признаков
Пять основных компонентов современного хранилища признаков реализуют следующие функции: преобразование, хранение, доставка, мониторинг и ведение реестра признаков.

Далее мы расскажем об их предназначении, а также о типовых возможностях каждой из этих составляющих.
Доставка
Хранилища признаков доставляют данные признаков моделям машинного обучения. Такие модели нуждаются в согласованном представлении признаков на этапе обучения модели и во время доставки данных при эксплуатации модели. Другими словами, определения признаков, которые используются во время обучения модели и доставки данных в режиме онлайн, должны быть одинаковыми. В ином случае возникнут расхождения между обучением и эксплуатацией (англ. training-serving skew), способные привести к катастрофическим последствиям для эффективности модели, которые будет сложно устранить.

Абстрагируясь от логики и процессов обработки, применяемых для генерации признаков, хранилища признаков предоставляют пользователям простой и стандартизированный путь доступа ко всем признакам, которые использует компания, во всех средах, где это необходимо.
При извлечении данных в режиме офлайн (то есть для обучения) доступ к значениям признаков обычно можно получить с помощью библиотек SDK, входящих в состав хранилища признаков. Эти библиотеки совместимы с инструментами вроде Jupyter Notebook и позволяют получать информацию о «состоянии мира» в конкретный момент времени для каждого образца, использованного в обучении модели (эту операцию также называют «путешествием во времени»).
Для доставки данных в режиме онлайн хранилище признаков предоставляет единый вектор признаков, составленный из их последних значений. Ответы передаются через высокопроизводительный API, работа которого поддерживается базой данных с низкой задержкой.

Хранение
Хранилища признаков сохраняют данные признаков для их последующего извлечения на разных уровнях доставки. Как правило, они имеют как онлайн-, так и офлайн-уровни хранения, чтобы соответствовать требованиям разных систем доставки.

На офлайн-уровнях хранятся накопленные за месяцы или годы данные признаков, которые используются в обучении моделей. Роль подобных уровней часто выполняют хранилища или озера данных, такие как S3, BigQuery, Snowflake или Redshift. Для этих целей рекомендуется расширять существующие репозитории, чтобы не допустить разрозненного хранения данных.
На онлайн-уровнях хранятся значения признаков, доступные для извлечения с низкой задержкой в процессе формирования логических заключений. Чаще всего это последние значения признаков для каждой сущности, которые воспроизводят текущее «состояние мира». Онлайн-уровни обычно обретают согласованность по прошествии некоторого времени, и в большинстве сценариев машинного обучения к ним не предъявляется строгих требований в смысле согласованности. Как правило, они реализуются на основе хранилищ пар «ключ — значение», таких как DynamoDB, Redis или Cassandra.

Хранилища признаков используют модель данных на основе сущностей, в которой каждое значение признака связано с определенной сущностью (например, пользователем) и временной меткой. В рамках этой модели создается минимальная структура, необходимая для стандартизированного управления признаками. Она совместима с большинством процессов разработки признаков и позволяет делать простые запросы на извлечение данных в ходе эксплуатации модели в продакшене.
Преобразование
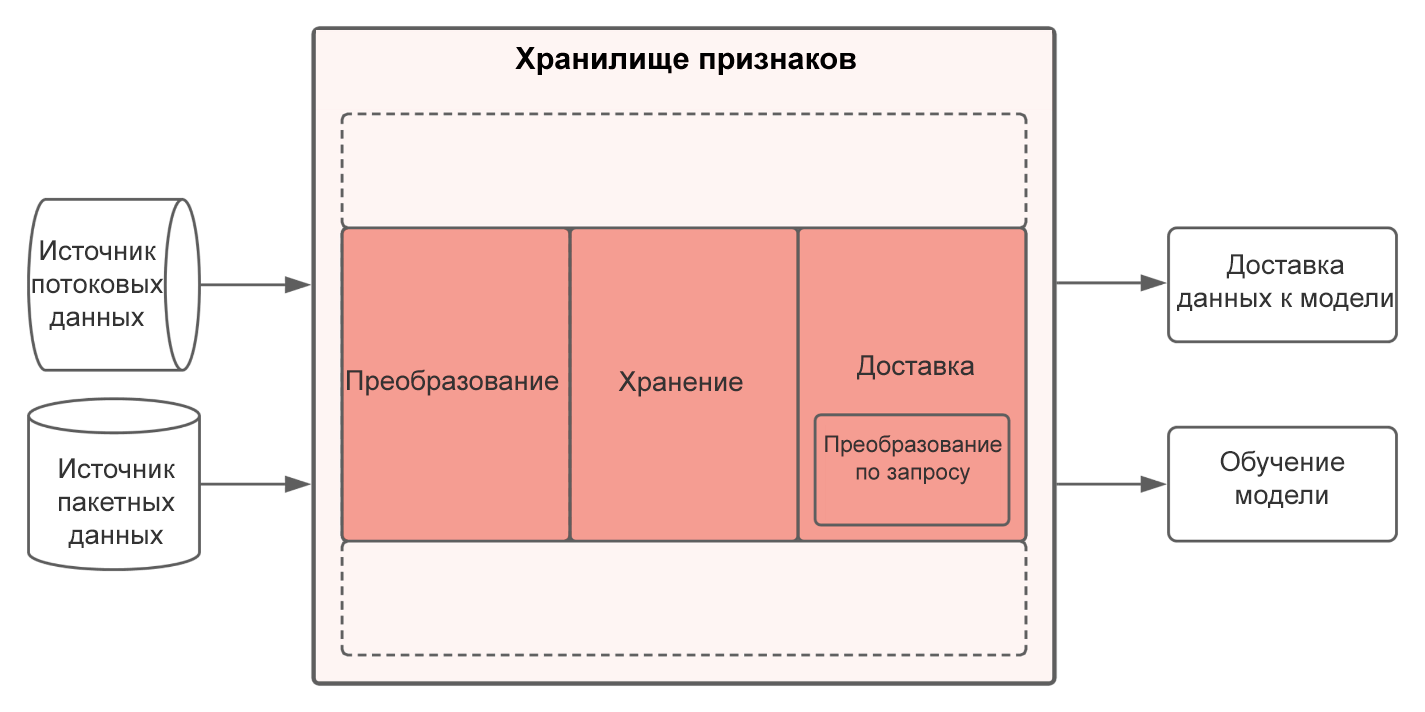
Практические приложения с машинным обучением должны постоянно преобразовывать новые данные в значения признаков, чтобы модель могла делать прогнозы на основе актуальной информации о «состоянии мира». Хранилища признаков управляют этими преобразованиями и координируют их, а также принимают значения, произведенные внешними системами. Процесс преобразования конфигурируется определениями признаков, которые содержатся в общем реестре (о нем далее).
У большинства команд, которые начинают работать с хранилищами признаков, как правило, уже есть конвейеры обработки данных, производящие значения признаков. Поэтому очень важно, чтобы хранилища имели возможность постепенной интеграции и отличную совместимость с существующими платформами обработки данных. Это позволит специалистам сразу же начать использовать действующие ETL-конвейеры для машинного обучения.
Обычно хранилища признаков предоставляют средства для трех основных типов преобразования данных:
Тип признака | Определение | Типовой источник входящих данных | Пример |
Пакетное преобразование | Преобразование, которое применяется только во время хранения данных | Хранилище данных, озеро данных, база данных | Страна нахождения пользователя, категория продукта |
Потоковое преобразование | Преобразование, которое применяется к данным, получаемым из источника потоковой передачи | Kafka, Kinesis, PubSub | Количество щелчков по отраслевой вертикали на одного пользователя за последние 30 минут, количество просмотров списка за последний час |
Преобразование по запросу | Преобразование, которое используется для создания признаков на основе данных, доступных только во время прогнозирования. Значения таких признаков нельзя вычислить заранее | Приложение, ориентированное на пользователя | Находится ли пользователь в данный момент в поддерживаемом местоположении?Оценка совпадений между списком и поисковым запросом |
Ключевое преимущество здесь — возможность совместно использовать признаки разных типов в одной и той же модели.

Для формирования логических заключений моделям необходим доступ к актуальным значениям признаков. Хранилища признаков обеспечивают такой доступ благодаря регулярному пересчету значений. Операции по преобразованию позволяют гарантировать, что все данные своевременно обрабатываются и переводятся в новые значения признаков. Выполняются они движками обработки данных (например, Spark или Pandas), подключенными к хранилищу признаков.
При разработке моделей предъявляются разные требования к преобразованию данных. Так, при итеративной доработке модели часто создаются новые признаки для использования в составе наборов обучающих данных, соответствующих прошедшим событиям (например, «все покупки за последние шесть месяцев»). Хранилища признаков поддерживают упрощенный запуск операций заполнения отсутствующих значений, которые позволяют генерировать и сохранять предыдущие значения признаков для использования в подобных сценариях. Некоторые хранилища автоматически выполняют заполнение отсутствующих значений для новых зарегистрированных признаков, чтобы заранее настроить временные диапазоны для обучающих наборов данных.
Чтобы предотвратить появление расхождений между обучением и эксплуатацией модели и избавить специалистов от лишней работы, в разных средах используется один и тот же код преобразования данных.
Хранилища признаков осуществляют комплексное управление всеми ресурсами, имеющими отношение к признаку (то есть ресурсами, обеспечивающими вычисление значений, хранение признака и его доставку), на протяжении всего его жизненного цикла. Автоматизация повторяющихся инженерных операций позволяет упростить и ускорить введение новых признаков в продакшен-среду. А средства оптимизации управления признаками (такие как вывод из эксплуатации неиспользуемых признаков или дедупликация преобразований признаков в разных моделях) помогают значительно увеличить эффективность этого процесса, так как по мере роста команды выполнять его вручную становится все сложнее.
Мониторинг
Неполадки в системе машинного обучения, как правило, возникают из-за проблем с данными. Уникальное преимущество хранилищ признаков состоит в том, что они способны выявлять такие проблемы и делать их видимыми для специалистов. Так, они могут вычислять метрики хранимых признаков и снабжать модель информацией об их достоверности и качестве. Хранилища ведут мониторинг этих метрик и отправляют уведомления об общей работоспособности приложения с машинным обучением.

Валидация данных, используемых как признаки, может происходить в соответствии со схемой, заданной пользователем, или согласно другим структурным критериям. Качество данных отслеживается посредством мониторинга дрейфа данных или расхождений между обучением и эксплуатацией. Так, например, данные, которые доставляются модели, сравниваются с данными, на которых ее обучали, чтобы выявить несоответствия, угрожающие ее эффективности.
В процессе эксплуатации системы в продакшене также очень важно вести мониторинг операционных метрик. Хранилища признаков отслеживают операционные метрики, связанные с их основными задачами: например, с хранением признаков («доступность», «вместительность», «уровень использования», «риск переобучения») или с их доставкой («быстродействие», «задержка», «частота возникновения ошибок»). Другие метрики описывают операции, выполняемые важными смежными компонентами системы. Например, для внешних движков обработки данных это могут быть такие операционные метрики, как «количество успешно выполненных заданий», «пропускная способность», «задержки и скорость процесса обработки данных».
Хранилища признаков делают эти метрики доступными для действующей инфраструктуры мониторинга. Это позволяет отслеживать и контролировать работоспособность приложения для машинного обучения с помощью средств наблюдения, имеющихся в стеке продакшен-среды.
Зная, какие признаки используются в конкретных моделях машинного обучения, хранилища автоматически собирают уведомления и метрики работоспособности и предоставляют их в форме, актуальной для определенных пользователей, моделей или потребителей.
Не у всех хранилищ есть встроенные инструменты для таких операций, но они должны, по крайней мере, иметь интерфейсы, к которым можно подключить системы мониторинга качества данных. Это важно, поскольку разные сценарии машинного обучения могут предъявлять особые, специализированные требования к мониторингу.
Реестр
Централизованный реестр стандартизированных определений и метаданных признаков является критически важным компонентом любого хранилища признаков. Он выступает единым источником достоверной информации о признаках на уровне организации.

Реестр — это центральный интерфейс, обеспечивающий взаимодействие пользователей с хранилищем признаков. Специалисты из разных команд используют реестр как общий каталог для обнаружения, разработки, публикации новых определений и совместной работы над ними.
Определения, внесенные в реестр, конфигурируют поведение системы хранилища признаков. В автоматизированных операциях реестр используется для планирования и настройки процессов получения, преобразования и хранения данных. Все это определяет, какие данные могут находиться в хранилище и как они будут организованы. API доставки данных используют реестр для формирования согласованного представления о том, какие значения признаков должны быть доступны пользователям, кто может получить доступ к этим данным и как именно они должны доставляться.
Реестр позволяет добавить к определениям признаков важные метаданные. С его помощью можно отследить принадлежность данных, получить специфическую информацию о предметной области или проекте и без лишних затрат провести интеграцию со смежными системами. Он также содержит сведения о зависимостях и версиях, которые используются для отслеживания происхождения данных.
В рабочих процессах по отладке, обеспечению соответствия требованиям и проведению аудита реестр выступает как неизменяемая запись о том, какие признаки доступны аналитически и какие уже работают в продакшене.
Итак, мы описали необходимый минимум основных компонентов хранилища признаков. Однако на практике компаниям часто необходим особый функционал для управления, обеспечения соответствия требованиям и безопасности, который требует подключения дополнительных возможностей корпоративного уровня. О них мы расскажем в дальнейших статьях.
С чего начать работу с хранилищами признаков?
По нашим представлениям хранилище признаков должно являться центральным компонентом потока данных в любом современном приложении с машинным обучением. Они стремительно становятся критически важной частью инфраструктуры для дата-сайентистов, занятых внедрением технологий машинного обучения в продакшен. Поскольку машинное обучение становится ключевым преимуществом технологических компаний, мы ожидаем, что скоро они начнут повсеместно внедрять хранилища признаков.
Вот несколько решений, которые помогут вам начать работу с этими инструментами:
Feast — отличный выбор, если у вас уже есть конвейеры преобразований для вычисления значений признаков, но для их использования в продакшене вам требуется мощное хранилище и уровень доставки данных. Сейчас Feast доступен только на Google Cloud Platform, но мы работаем над тем, чтобы превратить его в компактное хранилище признаков, совместимое с любыми средами. Следите за новостями.
Tecton — это хранилище признаков как услуга. Его основное отличие от Feast — поддержка преобразований, благодаря которой обеспечивается сквозное управление конвейерами признаков. Tecton — это управляемое решение и отличный вариант для тех, кому необходимы инструменты для выполнения условий SLA, хостинга, эффективной совместной работы, управляемых преобразований данных (пакетных, потоковых или в реальном времени) и (или) корпоративные возможности.
В этой статье мы хотели дать общее определение хранилища признаков как основного компонента стека технологий практического машинного обучения. Мы верим, что в ближайшем будущем это направление ждет настоящий взрыв активности.
Материал подготовлен в рамках курса «MLOps».
Всех желающих приглашаем на бесплатный двухдневный интенсив «end2end Fraud Detection». На занятиях мы:
— Сформулируем бизнес цели и метрика проекта.
— Загрузим данные в HDFS и проведем разведывательный анализ данных с помощью spark.
— Выстроим каскад метрик, сформулируем задачу для ML.
— Обучим модель и проверим гипотезы по улучшению качества.
— Автоматизируем переобучение на новых данных и сохранение артефактов с помощью Airflow и MLFlow.
>> РЕГИСТРАЦИЯ
