
Резервное копирование является одной из основных задач администрирования баз данных. Отсутствие бэкапа может привести к катастрофическим последствиям при эксплуатации базы данных. Однако недостаточно только настроить регулярное создание резервных копий, необходимо также регулярно проверять созданные копии на способность к восстановлению БД. В этой статье мы поговорим от том, как правильно настраивать резервное копирование в БД PostgreSQL.
Начнем с напоминания о некоторых очевидных вещах, которые неустанно повторяют во всех публикациях, посвященных бекапу всего, однако пользователи и администраторы по-прежнему наступают на одни и те же грабли.
Сколько терять и за сколько восстанавливать
Итак, вспомним такие понятия как RPO и RTO.
Recovery Point Objective – максимально допустимый интервал за который мы можем позволить себе потерять данные. Например, если у нас RPO равно двум часам, то в случае сбоя мы потеряем данные максимум за последние два часа.
Recovery Time Objective - промежуток времени, в течение которого БД может оставаться недоступной в случае сбоя. То есть это то время за которое мы обязуемся восстановить наши данные из бэкапа.
На картинке расстояние до сбоя это RPO (обычно измеряется в часах) а RTO это то расстояние-время, которое у нас останется на восстановление.

Однако, RTO и RPO нельзя назвать чисто техническим понятиями, в определенной степени это характеристики, позволяющие обеспечивать непрерывность бизнес процессов. Значения величин RTO и RPO должны указываться владельцами бизнес систем, а ИТ специалисты должны в ответ выдвинуть свои требования относительно оборудования и программного обеспечения для выполнения этих требований. Например, если бизнесу необходимо, чтобы в случае аварии данные были потеряны не более чем за час, а процесс восстановления должен занимать не более 30 минут, то админы в ответ должны сказать хранилища какого размера им необходимы, с какими характеристиками по скорости работы дисков и каналов передачи данных. То есть ИТ готовит спецификацию на необходимое оборудование и ПО с ценами, а бизнес посмотрев на все это понимает, что может быть два или даже три часа простоя это не так уж и страшно, да и восстанавливаться можно подольше. В результате согласовываются новые значения RTO и RPO и стоимость спецификации снижается. Такой подход позволяет разделить ответственность между всеми сторонами. Однако очень часто присутствует другой подход к политике резервного копирования, когда ИТ сами устанавливают значения RTO и RPO и сами пытаются их выполнять без согласования с бизнесом, что является в корне неверным.
Также несколько слов о том, как и куда нужно делать бэкапы. В зависимости от того, сколько времени требуется на восстановление, бэкап может делаться на быстрый (диски) или не очень быстрый носитель (ленты) носитель. Но, независимо от того на какой носитель мы бэкапимся важно то, что этот носитель должен размещаться на другой площадке, то есть физическим он не должен находиться там же, где и основная система с которой делается бэкап. В случае, если копия хранится на той же площадке мы конечно защищены от логических сбоев (например заражения шифровальщиком или нарушения целостности индексов) но в случае физического уничтожения оборудования (и такое бывает например при пожаре) мы лишимся и целевой системы и бэкапов. Так что бэкап всегда должен размещаться на другой площадке. Ну а теперь закончим с теорией и вернемся к основной теме резервному копированию в PostgreSQL.
Штатные возможности бэкапа
Рассмотрение функционала по резервному копированию мы начнем с штатных функций PostgreSQL. Утилита pg_dump предназначена для создания резервных копий, причем ее можно использовать для бэкапа работающей базы, то есть, утилита не блокирует доступ к базе. При этом, pg_dump позволяет делать дамп только одной базы.

Если для нас критичны данные только в какой-то конкретной таблице, то мы можем сделать бэкап только ее с помощью ключа -t.

Важным моментом является используемая для резервного копирования учетная запись, так как возможна ситуация, когда используется учетка, отличная от postgres. При этом, важно понимать, что должен использоваться служебный аккаунт, который имеет права на запись в папку с бэкапами. Но для других пользователей папка с бэкапами должна быть недоступна даже на чтение, так как получив доступ к бэкапам злоумышленник получит доступ ко всему содержимому базы данных.

Опция -U это имя пользователя, под которым мы подключаемся, а -W обязывает ввести пароль при подключении. Естественно, у пользователя otus должны быть права на запись в каталог /tmp.
В приведенном примере мы делаем резервную копию только одной базы otus. Но что делать, если нам необходимо сделать бэкап всех имеющихся БД, включая системные базы?
В таком случае проще всего воспользоваться командой pg_dumpall

Полученные файлы резервных копий будут содержать набор команд, которые необходимо выполнить для восстановления всех баз.
Так как полученные файлы бэкапов представляют собой по сути текстовые файлы, их можно эффективно сжимать. Для этого необходимо просто подать результаты работы pg_dump на вход архиватору gzip. Пустая база сжалась более чем в четыре раза.


Конечно, для выполнения резервного копирования на регулярной основе необходимо использование скриптов. Я не буду засорять статью примерами скриптов и вместо этого предлагаю воспользоваться рекомендациями с официальной wiki PostgreSQL где приводятся примеры нескольких скриптов для бекапа и ротации файлов резервных копий https://wiki.postgresql.org/wiki/Automated_Backup_on_Linux. На просторах сети имеется множество других примеров, как правило дополненных различными механизмами уведомления администратора о результатах выполнения бэкапа.
Физика против логики
Для практически любой БД существует два способа выполнения резервных копий: физический и логический. Второй мы уже рассмотрели. Теперь поговорим о физическом методе бэкапирования. Логическая резервная копия представляет собой файл с набором инструкций SQL с помощью которого можно полностью восстановить базу. К достоинствам логических бэкапов можно отнести их совместимость с разными версиями СУБД PostgreSQL. Необходимо, чтобы та версия БД, на которой производится восстановление поддерживала используемые в бэкапе команды SQL.
К недостаткам можно отнести долгое время восстановления, так как на большой БД (порядка нескольких терабайт) восстановление с помощью логического бэкапа может занять не один час.
И здесь нам на помощь приходит возможность сделать физический бэкап. В PostgreSQL штатным средством создания физического бэкапа является утилита pg_basebackup, которая создает резервные копии всего кластера.
В приведенном ниже примере мы создаем полную копию для локального сервера с сохранением в /tmp/ph_backup.bak.

Физический бэкап в отличии от логического выполняется быстрее, также может использоваться для создания базовой резервной копии работающего кластера базы данных PostgreSQL. Резервная копия создается, не затрагивая других клиентов базы данных, и может использоваться как для восстановления на определенный момент времени. Также резервное копирование выполняется через обычное соединение PostgreSQL, использующее протокол репликации. Подробнее о репликации в PostgreSQL мы будем говорить в следующей статье.
О восстановлении
Резервное копирование без регулярной проверки сделанных бэкапов это не более чем хранение данных. Только регулярная проверка созданных бэкапов позволяет быть уверенными в том, что наши резервные копии данных не подведут в нужный момент.
Для проведения проверки бэкапа прежде всего необходимо развернуть сервер СУБД PostgreSQL. Данный процесс является достаточно простым и был подробно описан в предыдущей статье. Единственное, что хотелось бы заметить: надеюсь для проверки бэкапа вы будете использовать тестовый сервер, а не восстанавливать данные на упавшем сервере в продакшене.
Прежде всего, рассмотрим ручное восстановление из бэкапа. Будем считать, что файлы бэкапов помещены на нужный сервер и распакованы.
Для логических резервных копий мы можем просто перенаправить ввод для команды psql:

Можно также воспользоваться командой pg_restore.
pg_restore -U username -d dbname -1 filename.dump
Однако здесь следует помнить, что восстановление из такого бэкапа может занять довольно много времени.
В случае восстановления из физического бэкапа нам потребуется только сам файл резервной копии и единственными моментом, который может потребовать некоторых продолжительных временных затрат является копирование и распаковка файлов бэкапа.
Так как физический бэкап представляет собой по сути набор файлов, которые просто объединены и заархивированы в одном файле нам необходимо скопировать эти файлы в нужные каталоге нашей новой БД.
Для этого необходимо прежде всего остановить СУБД.
Далее необходимо удалить (или хотя бы переместить) все файлы из каталога в котором размещаются базы /var/lib/postgresql/номер_версии/main/* и заменить их теми файлами и каталогами, которые мы получили после восстановления из бэкапа.
Перед запуском СУБД нам необходимо еще создать файл конфига восстановления recovery.conf. Этот файл создается в каталоге /var/lib/postgresql/номер_версии/main/ и содержит следующую строку.
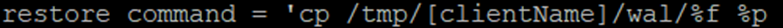
Write-Ahead Logging (WAL) – журнал предзаписи предназначенный для обеспечения целостности данных. Изменения в файлах с данных происходят только после того, как они записаны в это журнал.
Далее необходимо сменить владельца и выдать необходимые права на этот файл, иначе после запуска базы у нас будут проблемы.

Затем запускаем СУБД и смотрим логи, что получилось после бэкапа.

Здесь уже возможны различные варианты развития событий в зависимости от того, каких именно файлов не хватает СУБД для корректного запуска. После запуска СУБД обнаружит файл recovery.conf СУБД войдет в режим восстановления и начнет заново применять содержимое файлов журналов предзаписи (WAL-файлов). По окончании файл recovery.conf будет переименован в recovery.done и PostgreSQL будет готов к работе.
Заключение
В этой статье были рассмотрены только штатные средства резервного копирования и восстановления, которые поставляются вместе с СУБД. На просторах глобальной сети можно найти множество различных статей и скриптов, предлагающих использовать сторонние средства для выполнения бэкапа, начиная от утилит операционной системы Linux (rsync и прочие) и заканчивая использованием полноценных решений для бэкапирования баз данных таких как Percona. Поэтому те, кого не устраивают представленные штатные средства также могут найти подходящее для себя решение.
В конце хочу пригласить всех на бесплатный вебинар курса "PostgreSQL для администраторов баз данных и разработчиков" посвященный маленьким хитростям GROUP BY. На вебинаре вспомним, как устроен GROUP BY и рассмотрим его на наглядных примерах, оптимизируем работу группировки в связке с индексами, разберемся с особенностями группировки строк в PostgreSQL, а также изучим несколько полезных приемов для работы с GROUP BY.
