
На собеседовании:
- Вы работали с Кафкой?
- Нет, только читали.
За несколько десятилетий развития ИТ систем разработчики накопили огромный опыт хранения и обработки данных. Различные СУБД позволяют с помощью запросов извлекать нужные данные за определенный период и обрабатывать их так как необходимо. Однако, со временем увеличились вычислительные мощности серверов, пропускная способность каналов связи, и соответственно, возникла необходимость обрабатывать бОльшие объемы данных за единицу времени. И тут выяснилось, что при всем многообразии различных решений для хранения данных, отсутствуют решения для обработки непрерывных потоков больших объемов данных. Для решения этой проблемы стали появляться различные системы, такие как системы обмена сообщениями и агрегирования журналов. Но они не могли в полной мере обеспечить нужную производительность на больших, непрерывных потоках данных.
Для решения этой проблемы в LinkedIn решили создать нужное решение что называется с нуля. Разработчики решили отказаться от хранения больших объемов данных, как в реляционных базах данных, хранилищ пар «ключ/значение», поисковых индексов или кэшей, а рассматривать данные как непрерывно развивающийся и постоянно растущий поток и проектировать информационные системы и архитектуру данных — на этой основе. Так появилось решение Apache Kafka, которое изначально использовалось для обеспечения функционирования работающих в реальном масштабе времени приложений и потоков данных социальной сети. Но сейчас это решение используется во многих крупных компаниях. Посмотрим подробнее как оно устроено.
Укрощение потока
Прежде всего введем термин Потоковая платформа (streaming platform) – система которая дает возможность публикации потоков данных и подписки на них, их хранения и обработки. Для тех, кто много работал с СУБД такой подход к взаимодействию с данными может показаться непривычным, но на практике такая абстракция дает гораздо большие возможности при создании различных приложений. При этом, Kafka имеет некоторые сходства с такими решениями, как RabbitMQ, так как здесь тоже используются публикации и подписки. И прежде, чем перейти к обсуждению нюансов Apache Kafka, важно разобраться в обмене сообщениями по типу «публикация/подписка» и причине, по которой оно столь важно.
Обмен сообщениями по типу «публикация/подписка» это один из шаблонов проектирования, отличающийся тем, что отправитель данных не направляет его конкретному потребителю. Вместо этого он проводит классификацию сообщения, а подписчик подписывается на определенные классы сообщений. В системы такого типа для упрощения этих действий часто включают брокер — центральный пункт публикации сообщений.
В прежние времена все было довольно просто. Если нам надо было передать какие-либо данные на сервер, например метрики мониторинга с источника на сервер системы мониторинга, то мы просто создавали соединение и передавали данные. Но со временем в вашу систему мониторинга стали добавляться новые возможности, вы стали собирать новые виды метрик, увеличилось количество приложений, работающих с данными мониторинга. В итоге вам проще создать единое приложение, которое получает метрики со всех имеющихся источников и предоставляет данные всем системам, которым они нужны, например средствам визуализации, аналитики метрик и т.д.
В результате мы получим что-то похожее на архитектуру, представленную на рисунке.

Здесь у нас единое приложение собирает метрики с различных источников и затем публикует их для того, чтобы системы мониторинга, анализа и визуализации могли с ними работать. Примерно таким образом и работает Apache Kafka.
Сообщения и схемы
Рассмотрим основные элементы системы Kafka. Начнем с основной единицы данных – сообщений. Наиболее подходящим сравнением для тех, кто много работал с СУБД является аналогия со строками или записями. Но по сути сообщение это просто массив байтов, не имеющее какого-то определенного формата. В этом сообщении тоже может быть ключ, то есть набор неких метаданных, но в отличие от СУБД, здесь ключ не является обязательным и не несет для Kafka никакого смысла.
Для того, чтобы увеличить производительность при обработке сообщений, Kafka обрабатывает их пакетами (batch). По сути, пакет представляет собой просто набор сообщений, относящихся к одному топику и одному разделу.
Еще, для упрощения разбора сообщений рекомендуется использовать дополнительную структуру – схему. Это могут быть и всем известные форматы JSON и XML, и специальный фреймворк Avro, использующий формат сериализации.
Топики в Kafka
Сообщения в Kafka тоже надо где-то группировать и здесь для этого используют топики (topic). Топики можно сравнить с базами данных в обычных СУБД. Топики в свою очередь разбиваются на разделы, представляющие собой отдельные журналы. Раздел - это отдельный журнал, работающий по принципу FIFO (First In First Out, Первый вошел, первым вышел), а если по простому, то по принципу очереди.
На схеме ниже представлен процесс записи сообщений по разделам в одному топику.
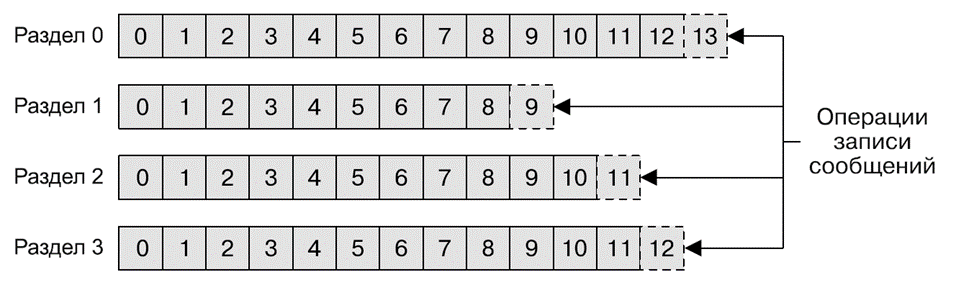
С помощью нескольких разделов Kafka обеспечивает избыточность и масштабируемость. Любой из разделов можно разместить на отдельном сервере, что дает возможность горизонтального масштабирования системы на несколько серверов, что позволит существенно увеличить производительность. В начале статьи мы уже упоминали термин Поток данных. В Kafka поток данных обычно является отдельным топиком, независимо от количества разделов.
О терминологии. В статье сознательно не используются переводы таких терминов, как producer, consumer, topic и т.д. Вместо перевода используются англицизмы (консьюмер, продьюсер), принятые в сообществе Kafka.
Генерируем и потребляем
Так как Kafka работает по принципу публикация/подписка, то совершенно очевидно, что здесь должно быть две сущности: те, кто генерирует новые сообщения (продьюсеры, producers) и те кто, эти сообщения читают (консьюмеры, consumers). Как правило, продьюсеры создают сообщения для конкретного топика и по умолчанию консьюмеру не важно в какой раздел записывается конкретное сообщение, все сообщения поставляются равномерно во все разделы топика. Хотя в некоторых случаях продьюсер может направить сообщение в конкретный топик.
Консьюмер подписывается на один или более топик и читает сообщения в порядке их создания. При этом, для того, чтобы помечать прочитанные сообщения, используются специальные смещения, то есть целочисленные, постоянно возрастающие значения. Благодаря смещениям консьюмер может приостанавливать и возобновлять свою работу, не забывая, на каком сообщении он остановил чтение.
Консьюмеры в свою очередь работают в составе групп консьюмеров, объединившихся для обработки топика. Организация в группы гарантирует чтение каждого раздела только одним членом группы. Благодаря этому, консьюмеры могут осуществлять горизонтальное масштабирование для чтения топика с большим количеством сообщений. Кроме того, в случае сбоя отдельного консьюмера оставшиеся члены группы перераспределят разделы так, чтобы взять на себя его задачу.
Про отказоустойчивость
Kafka не получила бы такое широкое распространение, если бы не ее функционал по обеспечению отказоустойчивости и масштабируемости. Но начнем с рассмотрения одного сервера, который в терминах системы называется брокером. В его задачи входит получение сообщений от продьюсеров, присвоение им смещения и отправка в дисковое хранилище. Также он отвечает на запросы выборки из разделов, возвращая записанные на диск сообщения.
Конечно, производительность одного брокера может быть довольно высокой и он может обрабатывать миллионы сообщений в секунду, но рано или поздно все-равно возникает необходимость в горизонтальном масштабировании и тогда мы можем развернуть несколько брокеров и объединить их в кластеры. При этом, один из брокеров должен функционировать в качестве контроллера кластера. Выбор этого контроллера осуществляется автоматически из числа работающих членов кластера. В задачи контроллера входит распределение разделов по брокерам, мониторинг отказов брокеров и выполнение других административных операций.
Каждый раздел принадлежит одному из брокеров кластера, но раздел можно назначить нескольким брокерам, в результате чего он будет реплицирован. Таким образом мы можем обеспечить избыточность сообщений в разделе, потому что, в случае сбоя основного брокера другой сможет занять его место. Но в процессе работы основного брокера все продьюсеры и консьюмеры подключаются только к нему.
Долгие темы и продолжение масштабирования
Пожалуй, основным преимуществом Kafka является возможность хранить информацию в течении длительного времени. Мы можем указать в настройках хранение топиков в течении определенного периода времени или до достижения топиком определенного размера байтах. Превысившие эти пределы сообщения становятся недействительными и удаляются. Можно также задавать настройки сохранения и для отдельных топиков, чтобы сообщения хранились только до тех пор, пока они нужны.
В случае, когда поток сообщений стал еще больше и одного кластера уже явно недостаточно, мы можем развернуть несколько кластеров. Такое может потребоваться например, если у нас несколько ЦОД и необходимо копировать информацию между ними. Либо требования по доступности информации обязывают нам иметь полную копию данных в каждом ЦОД. Но механизмы репликации в кластерах Kafka предназначены только для работы внутри одного кластера, репликация между несколькими кластерами не осуществляется. И для этой цели мы должны использовать утилиту Mirror Maker из состава Kafka, которая просто связывает очередью продьюсера и консьюмера. То есть она получает сообщения из одного кластера и публикует их в другом.
Ниже показан пример использования MirrorMaker, где сообщения из двух локальных кластеров агрегируются в составной кластер, который затем копируется в другие ЦОД.

Заключение
На этом мы завершим первую статью, посвященную Apache Kafka. В следующей статье мы рассмотрим установку и настройку Kafka.
А прямо сейчас приглашаю вас на бесплатный урок по теме: "KRaft: новый контроллер Kafka на основе Raft". На уроке поговорим о том, что не так с Zookeeper, что такое KRaft. Обсудим особенности работы Kafka с KRaft.
