
Привет! Меня зовут Иван, я занимаюсь бэкенд-разработкой в Ozon: пишу микросервисы на Go для личного кабинета продавца. В прошлом году мы запустили новый процесс регистрации продавцов, в котором задействовано сразу несколько микросервисов. В нём стало больше шагов, при этом каждый из них выполняется в разных микросервисах. Поэтому мы задались вопросом: «А что будет, если один из шагов упадёт?».
В микросервисной архитектуре давно известен инструмент решения подобных проблем — это паттерн Saga. Мы решили взять его на вооружение и немного упростить под нашу задачу. Я расскажу о том, как мы это сделали, и покажу, что Saga может быть простой. Так что если вы давно хотели попробовать реализовать Saga, но вам казалось, что это сложно — читайте дальше.

Несколько слов о нашем процессе регистрации продавца
У нас есть HTTP-метод регистрации формы, который вызывается с набором данных, введённых пользователем. После этого мы сразу сохраняем регистрацию.
Процесс регистрации компании состоит из большого количества шагов. Для простоты описания я ограничу список действий следующими:
- Создание сущности компании.
- Привязка пользователя к компании.
- Создание заявки на проверку компании службой безопасности.
- Отправка Kafka-уведомления об успешном завершении регистрации (например, чтобы отправить письмо).
Первые три шага — это вызовы трёх разных сервисов. Нам было важно, чтобы при регистрации компании были выполнены все шаги, иначе пользователь мог бы столкнуться с неприятными побочными эффектами в работе после регистрации.
Как тут вяжется Saga и что это такое?
Паттерн Saga представляет собой способ реализации распределенных транзакций, которые состоят из вызовов разных микросервисов. То есть процесс разбивается на шаги, которые выполняются последовательно. Если на каком-то этапе что-то идёт не так, то мы выполняем ряд откатывающих действий — до тех пор, пока не откатятся все выполненные действия.
В оригинальном представлении атомарные шаги (транзакции) бывают трёх видов:
- Компенсируемые (compensatable transactions) — транзакции, для которых определена транзакция, откатывающая соответствующие изменения. Например, если бы наша транзакция прикрепления пользователя к компании была компенсируемой, мы должны были бы определить такое компенсирующее действие, как отвязывание пользователя от компании.
- Поворотная (pivot transaction) — транзакция, после успешного завершения которой сага обязательно должна выполниться до конца. И наоборот: если поворотная транзакция заканчивается ошибкой, то все выполненные шаги саги подлежат откату.
- Повторяемые (retriable transactions) — транзакции, которые повторяются до тех пор, пока не завершатся успешно.
Например, для нашего процесса шаги можно было бы распределить таким образом:
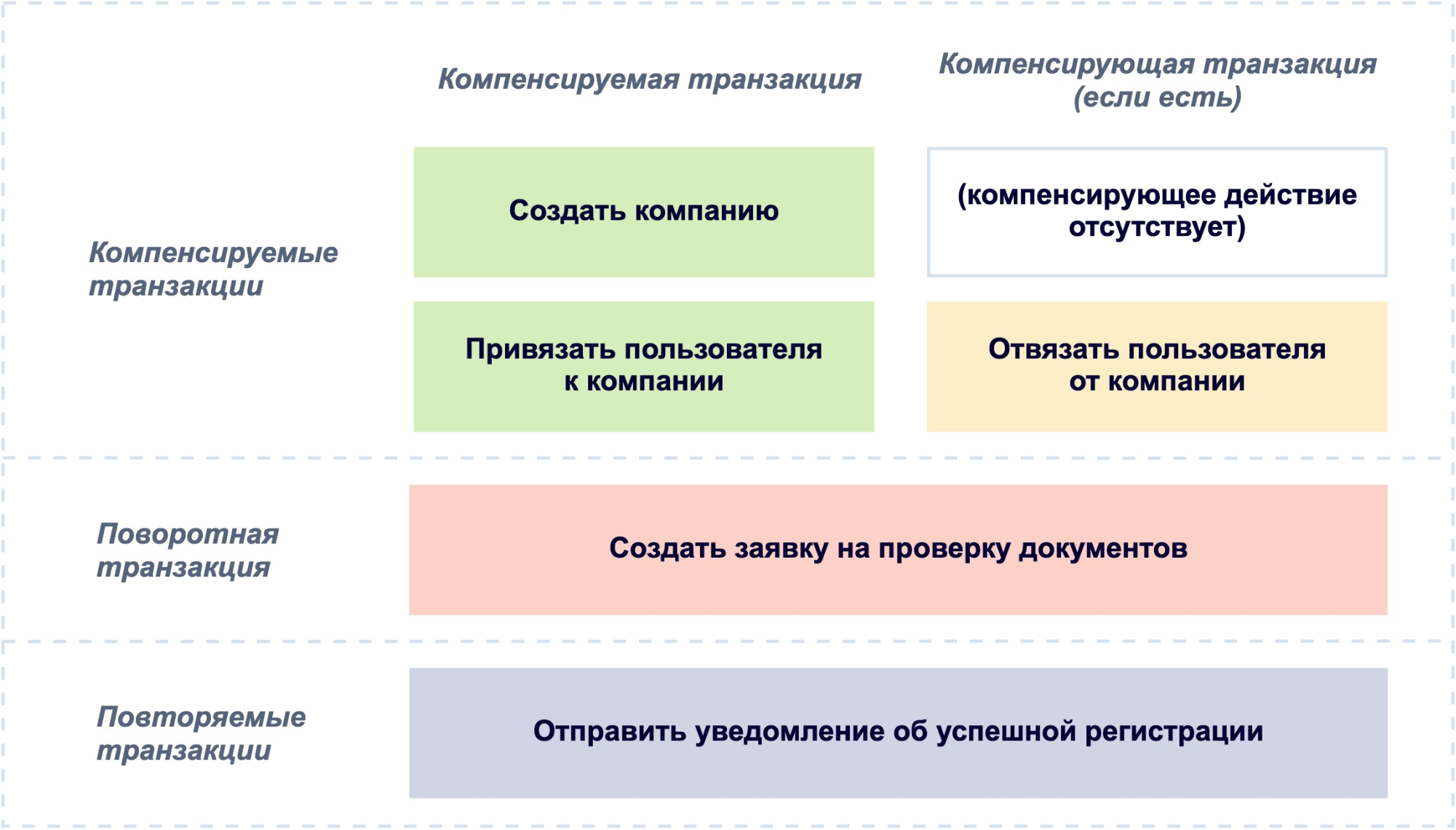
Обратите внимание, что не для всех компенсируемых транзакций обязательно реализовывать компенсирующее действие. Например, для нас может быть некритично оставить в базе пустую компанию, у которой нет пользователей и которая никем не используется.
Сами же саги бывают оркестрационные и хореографические:
- В оркестрационной саге есть оркестратор — компонент, который знает про все имеющиеся шаги. Оркестратор последовательно выполняет заранее известный набор шагов, а также откатывает их при необходимости.
- В хореографической саге каждый шаг приводит только к публикации события в очередь. При этом следующие шаги выполняются неявно на стороне других сервисов.

Плюсом хореографической саги, очевидно, является простота реализации — она сводится всего лишь к отправке событий другим сервисам о произошедших изменениях, а также к обработке входящих событий от других сервисов.
Но есть и большой минус: логика саги размазывается по разным сервисам, поэтому её сложнее понимать и ею сложнее управлять.
Плюсом же оркестрационной саги является как раз локализация логики в одном месте, за счёт чего ею проще управлять. Ещё к плюсам можно отнести то, что другие сервисы, задействованные в саге, ничего не знают о ней. Как результат — такую сагу можно реализовать без изменения участвующих сервисов.
Единственным минусом оркестрационной саги является сложность реализации.
Что же мы выбрали?
В оркестрационной саге мы полностью видим весь поток действий. А раз так, то мы можем выбирать ту реализацию оркестратора, которая нам кажется удобной. Именно по этой причине мы выбрали оркестрационную сагу. Также нас прельстила простота передачи данных в виде шагов.
Что касается транзакций, то мы захотели сделать сагу без компенсирующих действий:
- Мы не хотим откатывать регистрацию пользователя, если что-то идёт не так. Это неприятно с точки зрения бизнеса.
- Иногда в API стороннего сервиса нет возможности откатить уже выполненное действие. При этом мы не можем повлиять на владельцев сервиса и заставить их исправить это.
То есть у нас поворотной является первая транзакция — сохранение формы регистрации. Все последующие шаги мы повторяем до победного конца без отката.
Модель данных
Очевидно, для саги нам необходимы две вещи:
- Возможность каким-то образом трекать процесс выполнения шагов по конкретной регистрации.
- Некий фоновый процесс, который будет повторять упавшие шаги.
Для хранения выполненных шагов мы поступили совсем тривиально — добавили булев флаг под каждый из шагов.
А вот для фонового процесса нам потребуются следующие данные:
- статус обработки (чтобы фоновый процесс мог искать упавшие регистрации),
- время запланированного повторного выполнения упавшего шага (очень важно, чтобы оно было),
- количество попыток доведения регистрации до конца (несмотря на заявления о повторении упавших шагов до победного конца, мы не собираемся ретраить вечно, поэтому нужно вести учёт повторений).
Поскольку оркестрация оказалась тесно связана с моделью, мы встроили все необходимые данные непосредственно в модель. В итоге получили следующее:
type Registration struct {
// Идентификатор регистрации
ID int64 `db:"id"`
// Введённые пользователем данные (для примера: всего два поля
// и ID авторизованного пользователя)
INN string `db:"inn"`
CompanyName string `db:"company_name"`
UserID int64 `db:"user_id"`
// Булевы флаги состояния транзакции
IsCompanyCreated bool `db:"is_company_created"`
IsUserAttached bool `db:"is_user_attached"`
IsApplicationCreated bool `db:"is_application_created"`
IsNotified bool `db:"is_notified"`
// Данные, необходимые для работы воркера
ProcessingStatus string `db:"processing_status"`
ExecuteAfter time.Time `db:"execute_after"`
Attempts int64 `db:"attempts"`
}Формально мы пожертвовали SRP. Однако вскоре мы увидим, что у этого решения есть свои плюсы.
Действие первое: пользователь нажал кнопку «Отправить»
Как только мы получили данные от пользователя, мы сразу же сохраняем их.
Если мы не можем сохранить данные (например, потеряли связь с базой), то ясно, что тут и ретраить нечего. Поэтому в таком случае мы сразу отвечаем пользователю отказом. Он видит, что что-то пошло не так, и нажимает на кнопку «Отправить» ещё раз.
Мы пытаемся провести все шаги саги синхронно во время выполнения запроса. Тут возможны варианты:
- Всё отработало успешно — в этом случае мы отправляем
registration_finished: trueна фронтенд и пьём шампанское. - Мы упали на одном из первых шагов. Например, если мы упали на шаге создания компании или привязки пользователя, то мы не можем сообщить об успехе: пользователь не сможет зайти в личный кабинет, потому что последний отсутствует. Поэтому мы возвращаем
registration_finished: false. - Мы упали на шаге создания заявки в службу безопасности. Процесс ещё не закончен, и пользователь может столкнуться с проблемами, если он не будет доведён до конца. Но пользователь уже может войти в личный кабинет и начать знакомиться с ним либо добавлять товары. При этом мы оптимистично надеемся на то, что воркер обязательно доведёт регистрацию до конца позже. Именно в этом проявляется graceful degradation.
Здесь хочется пару слов сказать о втором варианте (registration_finished: false). Что делать, если мы уже сохранили регистрацию, но упали на этапе создания компании? Повторить отправку формы мы не можем — у пользователя уже есть регистрация. В таких случаях мы подключаем фронтенд, а именно — мы попросили фронтенд показывать спиннер несколько секунд в надежде на то, что за это время успешные ретраи сделают своё дело. Если же после некоторого тайм-аута регистрация не дошла до шага создания заявки, мы рекомендуем пользователю открыть страницу через несколько минут или обратиться в службу поддержки.
Как происходит обработка саги?
Алгоритм выглядит как-то так:
- Восстанавливаем модель регистрации из базы данных (или сохраняем в БД, если мы получили данные формы от пользователя только что).
- Для каждого шага:
a. Если шаг уже выполнен, просто переходим к следующему.
b. Если шаг не выполнен, то выполняем его и сохраняем в модели. Тут как раз проявляется бонус от жертвования SRP: поскольку всё лежит в одной модели, мы можем сохранить в ней как статус саги, так и результат выполнения прошлых шагов. При этом всё это можно сделать одним запросом. Меньше запросов → меньше точек отказа → стабильнее система.
В итоге получаем приблизительно такой код:
func (s *Service) PerformRegistration(ctx context.Context, registration *Registration) error {
if !registration.IsCompanyCreated {
company, err := s.createCompany(ctx)
if err != nil {
// обрабатываем ошибку (об этом речь пойдёт ниже)
s.handleError(ctx, registration, err)
return err
}
registration.CompanyID = company.ID // сохраняем промежуточные данные, если они нужны для следующих шагов
registration.IsCompanyCreated = true // помечаем шаг как выполненный
err = s.repository.updateRegistration(ctx, registration)
if err != nil {
return err
}
}
if !registration.IsUserAttached {
// ...
}
if !registration.IsApplicationCreated {
// ...
}
if !registration.IsNotified {
// ...
}
// В конце сохраняем успешный статус регистрации
registration.ProcessingStatus = "SUCCESS"
return s.repository.updateRegistration(ctx, registration)
}А что, если?
Если шаг не выполнится, мы попробуем выполнить его в следующий раз.
Если же шаг успел выполниться, но упал в процессе сохранения статуса регистрации (то есть саги), то мы опять же выполним его повторно. Поэтому важно, чтобы:
- либо действие было атомарным (например, если в другом сервисе действие состоит из одного запроса к БД),
- либо действие было идемпотентным (например, обновление какого-нибудь параметра),
- либо нам было некритично, что действие можно выполнить несколько раз (в нашем случае это публикация уведомления о регистрации или создание ещё одной компании).
Однако на практике бывает так, что действие в другом сервисе выглядит атомарным, но таковым не является. В этом случае система переходит в невалидное состояние. Тогда разработчик должен разобраться в проблеме и перевести систему в валидное состояние, а также сделать действие атомарным или идемпотентным. Поэтому в случае неуспешного шага очень желательно залогировать ошибку (а ещё лучше — сохранить её в базу).
Как мы обрабатываем ошибки
Теперь детальнее рассмотрим, что происходит в случае, если упал какой-нибудь шаг.
Во-первых, нам нужно пометить регистрацию как упавшую: мы меняем её статус на FAILED и планируем следующее время выполнения с учётом бэкоффа, то есть экспоненциально увеличиваем время, через которое мы выполним следующую попытку.
Во-вторых, если данную регистрацию после нескольких попыток не удается довести до конца, мы извещаем разработчиков в Slack — чтобы они могли вмешаться и исправить проблему до того, как её заметит пользователь. Например, в нашем случае разработчикам приходит уведомление с ID регистрации и текстом ошибки, если регистрация не отрабатывала до конца в течение часа (в то время как первая повторная попытка происходит через 10 секунд, а в целом на завершение флоу регистрации предусмотрено около 36 часов).
В итоге получаем приблизительно такой код:
func (s *Service) handleError(
ctx context.Context,
registration *Registration,
errToLog error,
) {
now := time.Now()
registration.Attempts++
if registration.Attempts > maxAttemptsBeforeNotify {
err := s.sendRegistrationErrorToSlack(ctx, registration, errToLog)
if err != nil {
logger.ErrorKV(ctx, "failed to send message to slack", "err", err)
}
}
registration.ProcessingStatus = "FAILED"
registration.ExecuteAfter = now.Add(getBackoffTimeoutFromAttemptNumber(registration.Attempts))
err := s.repo.updateRegistration(ctx, registration)
if err != nil {
logger.ErrorKV(ctx, "failed to update registration", "registration", registration, "err", err)
}
}Сразу хочу сказать, что это минимальная версия кода. Вы можете сохранять больше данных. Мы, например, впоследствии с целью упрощения отладки завели отдельную таблицу с историей ошибок, в которую складывали:
- Идентификатор регистрации.
- Номер попытки.
- Ошибку.
- Время ошибки.
Действие второе: пользователь засыпает, просыпается воркер
Теперь, когда мы всё залогировали, нам нужно написать воркер, который будет с некоторым интервалом пытаться допройти упавшие регистрации (например, раз в минуту). Здесь важно, чтобы каждая регистрация в один момент времени выполнялась только одним воркером. В случае если воркер — это Cron-задача, проблем нет — у нас и так будет выполняться только одна обработка регистрации.
Однако иногда по инфраструктурным причинам оказывается проще запускать воркер внутри реплики приложения. Именно этот способ широко распространён в нашей команде, но из-за этого нам приходится думать об описанном выше условии. Здесь есть четыре варианта:
- Использовать распределённые блокировки (PostgreSQL Advisory Lock, etcd или Redis lock), а именно — брать блокировку на время выполнения одной конкретной регистрации.
- Использовать leader election (например, через etcd) и выполнять обработку регистраций только на реплике-мастере.
- Блокировать регистрацию в транзакции на время обработки (
SELECT FOR UPDATE). - Реализовать одновременное выполнение нескольких воркеров путём размечания состояния в регистрации без транзакций.
Мы решили реализовать последний вариант, поскольку он не требует дополнительной инфраструктуры в виде etcd либо взятия каких-либо блокировок и транзакций.
Давайте определим, какие у нас будут состояния:
- PROCESSING — регистрация проходит обработку прямо сейчас;
- SUCCESS — регистрация успешно завершена;
- FAILED — последняя попытка закончить регистрацию завершилась ошибкой.
Обратите внимание, что в списке нет состояния PENDING, поскольку мы всегда начинаем выполнять регистрацию сразу после сохранения модели в БД.
Вытаскиваем записи из БД
Как я упоминал выше, у нас одновременно работают несколько воркеров. При этом мы не хотим никаких блокировок. К счастью, в постгресе есть конструкция SELECT FOR UPDATE — она берёт блокировку на выбранную строку и держит её до конца транзакции.
Держать долгоживущую транзакцию мы не хотим, поэтому поступаем следующим образом:
- Блокируем пачку регистраций, используя
SELECT FOR UPDATE. - Сразу помечаем эти регистрации как обрабатываемые.
- Возвращаем данные.
Поскольку мы не берём транзакции, сразу после выполнения запроса блокировка строк будет снята. Как итог, воркеры смогут разделить работу между собой. Однако, чтобы исключить ненужные ожидания блокировок, мы можем использовать конструкцию SELECT FOR UPDATE SKIP LOCKED. Она создана специально для таких случаев и приводит к повышению производительности за счёт устранения времени ожидания снятия блокировки.
В итоге мы имеем вот такой запрос для получения пачки регистраций:
UPDATE registration
SET status = 'PROCESSING', updated_at = NOW()
WHERE id IN (
SELECT id
FROM registration
WHERE status = 'FAILED' AND execute_after < NOW() AND attempts < 10
LIMIT 1000
FOR UPDATE SKIP LOCKED
) RETURNING *Поскольку у нас данные хранятся в одной модели, мы уже можем начинать допроходить шаги регистрации, просто вызвав метод PerformRegistration у каждой полученной модели.
Обработка ошибок зависших воркеров
Но что будет, если мы упали в процессе обработки и мы не сможем записать статус FAILED? Если оставить как есть, то такая регистрация зависнет навсегда. Поэтому мы добавили ещё один воркер, который «отпускает» зависшие транзакции. Мы опирались на предположение, что, если с момента последнего обновления регистрации прошло более 10 минут, а она все ещё в статусе PROCESSING, значит, она зависла. Чтобы «отпустить» такие транзакции, достаточно с определённым интервалом выполнять следующий запрос:
UPDATE registration
SET status = 'FAILED', updated_at = NOW()
WHERE status = 'PROCESSING' AND updated_at < NOW() - '10 minutes'::intervalТеперь у нас всё готово! Можем тестировать и отправлять в прод :)
Подводим итоги
Итак, мы рассмотрели минимальную версию оркестрационной саги — сагу, которая состоит только из повторяемых транзакций.
Сам процесс выполнения саги выглядит достаточно тривиально: мы просто выполняем все невыполненные шаги, сохраняя промежуточный статус в БД. Вся сложность состоит именно в написании воркера, который будет выполнять действия до конца.
Этот подход особенно хорошо ложится на асинхронные действия, и у него есть важные плюсы:
- он максимально прост,
- он отвечает интересам пользователя, поскольку старается довести планируемое действие до конца,
- он не требует от других сервисов реализации логики откатывающих действий (чего иногда бывает сложно достичь в большой организации).
Однако есть и серьёзный минус:
- нам потребовалось предусмотреть компромисс по ожиданию на фронтенде (к счастью, насколько мы знаем, он ни разу не был задействован).
Отдельно отмечу, что использование саги требует ряда условий: действия должны быть либо атомарны, либо идемпотентны. К сожалению, так бывает не всегда. Но наш опыт показывает, что при грамотном оповещении разработчиков об упавших транзакциях неатомарные и неидемпотентные действия быстро опознаются и исправляются.
Что почитать/посмотреть по теме
Если вас заинтересовала тема, посмотрите замечательный доклад “Applying the Saga Pattern”. Среди прочего автор рассказывает, почему она, так же, как и мы, выбрала сагу без откатываемых действий и дала ей название Forward-Recovery Saga.
А если вы любите читать, то паттерн Сага подробно описан в книге «Микросервисы» Криса Ричардсона.
